




Context Engineering Strategies for AI Agents: A Developer’s Guide
Building reliable AI agents is harder than it looks. They often start strong, but as tasks grow more complex, cracks appear. Agents often lose track of previous steps, contradict their own reasoning, or become overwhelmed by the complexity of too much context.
This challenge has sparked lively debate across the industry. Recently, Anthropic (Claude) and Cognition (Devin) squared off over whether multi-agent collaboration or single-agent design is the better path forward. Anthropic pointed to experiments showing multi-agent setups achieving 90.2% higher success rates, while Cognition countered that single agents with long-context compression deliver greater stability and lower costs.
Both sides have good points, and as a matter of fact, are debating the same core issue: how to manage agent context effectively.
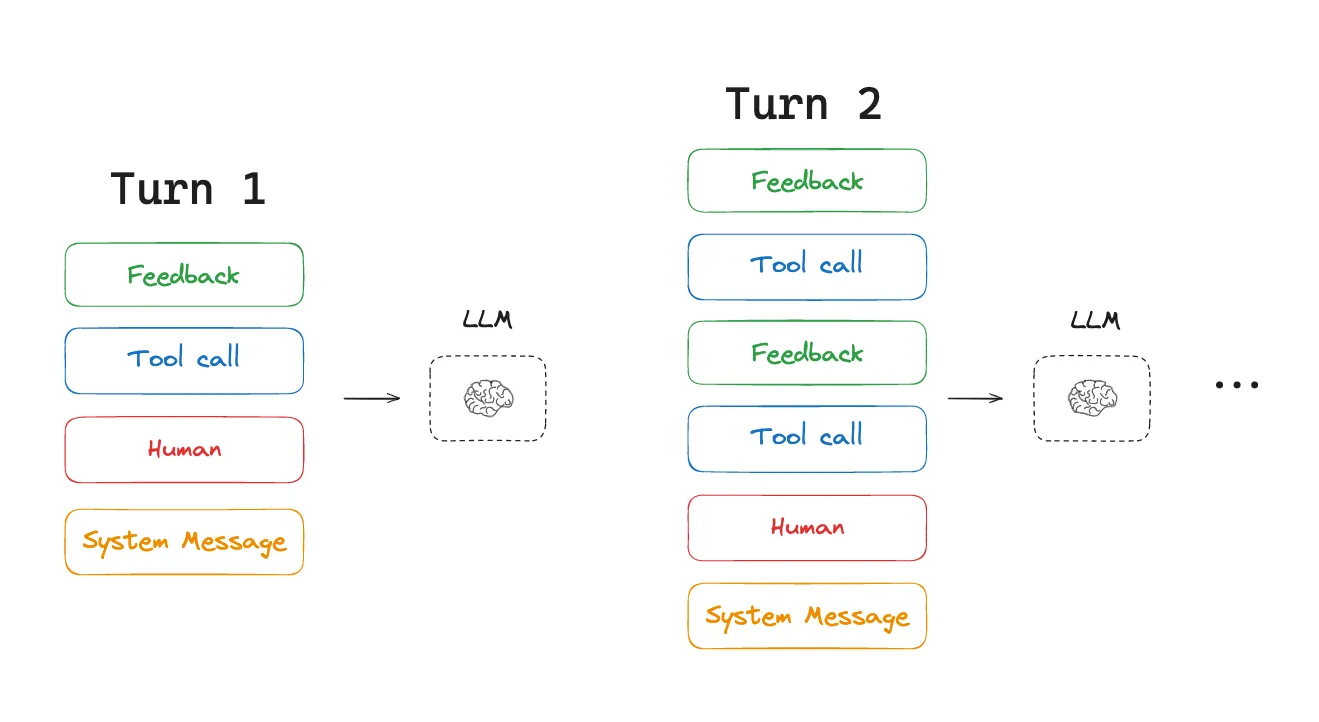
Think of LLMs as CPUs and their context windows as RAM. But here’s a catch: with hardware, you can always add more RAM. With LLMs, context length is capped by design, and extending it further comes with steep costs in terms of speed and accuracy. Agents, meanwhile, generate massive amounts of information during multi-step workflows, quickly running into those limits. This creates critical issues:
Information overload: context exceeds capacity → agent crashes
Escalating costs: more tokens processed means higher spend and latency
Performance drag: excess information doesn’t make agents smarter—it makes them slower and less accurate
That’s why context engineering has become a central design challenge for next-generation agents. Industry leaders have already tried different ways to address this challenge and many of which actually work very well.
In this blog, we’ll explore how LangChain, Lossfunk, and Manus approach the problem from different angles—offering complementary strategies for keeping agents both capable and cost-efficient.
LangChain’s 4 Strategies for Solving Agent Context Challenges
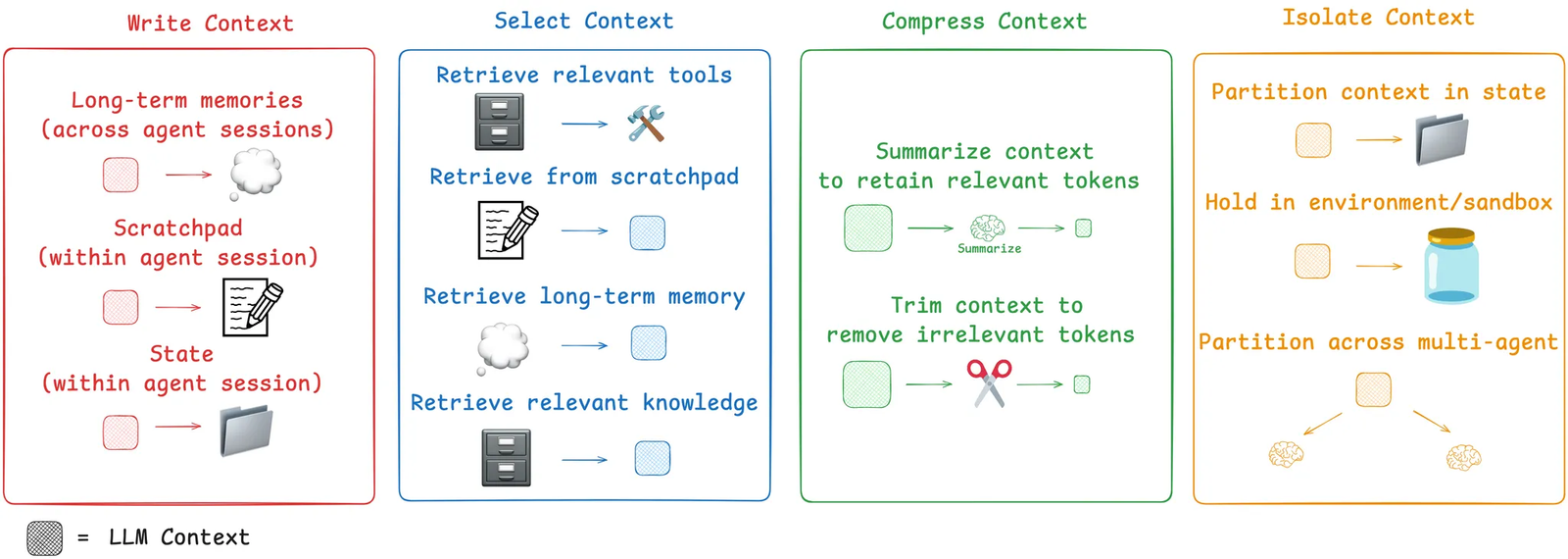
LangChain groups the challenges of agent context into four common failure modes:
Context Poisoning: irrelevant or incorrect details slip in, leading to nonsense outputs.
Context Distraction: critical information gets buried under noise.
Context Confusion: too much unrelated data makes the agent lose focus.
Context Clash: contradictory inputs lead to inconsistent behavior.
To address these challenges, LangChain introduced a four-strategy framework for agent context engineering: Write, Select, Compress, and Isolate.
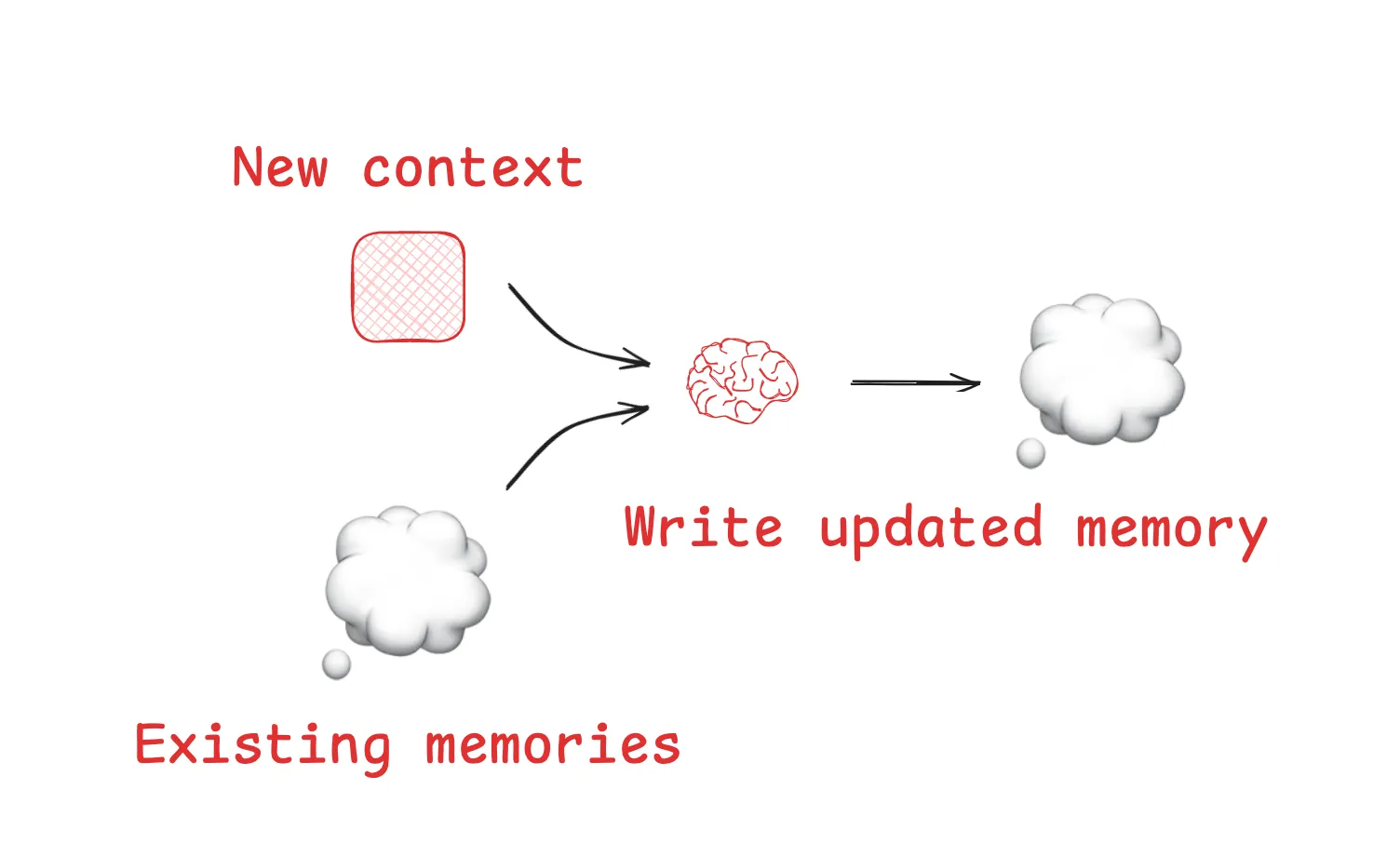
#1 Write Context: Giving Agents External Memory
Humans solve problems by taking notes and carrying knowledge forward. Agents are learning to do the same. One common approach is the “scratchpad,” where intermediate reasoning and discoveries are saved outside the context window. For instance, during code reviews, instead of rescanning the entire codebase, an agent can log issues and fixes per file. Over time, this builds a persistent, queryable memory that grows with experience.
#2 Select Context: Filtering for Relevance
Not every piece of information deserves attention. The Windsurf team demonstrated that navigating large codebases requires combining syntax analysis with knowledge graph retrieval, ensuring agents surface only the relevant snippets instead of drowning in irrelevant lines.

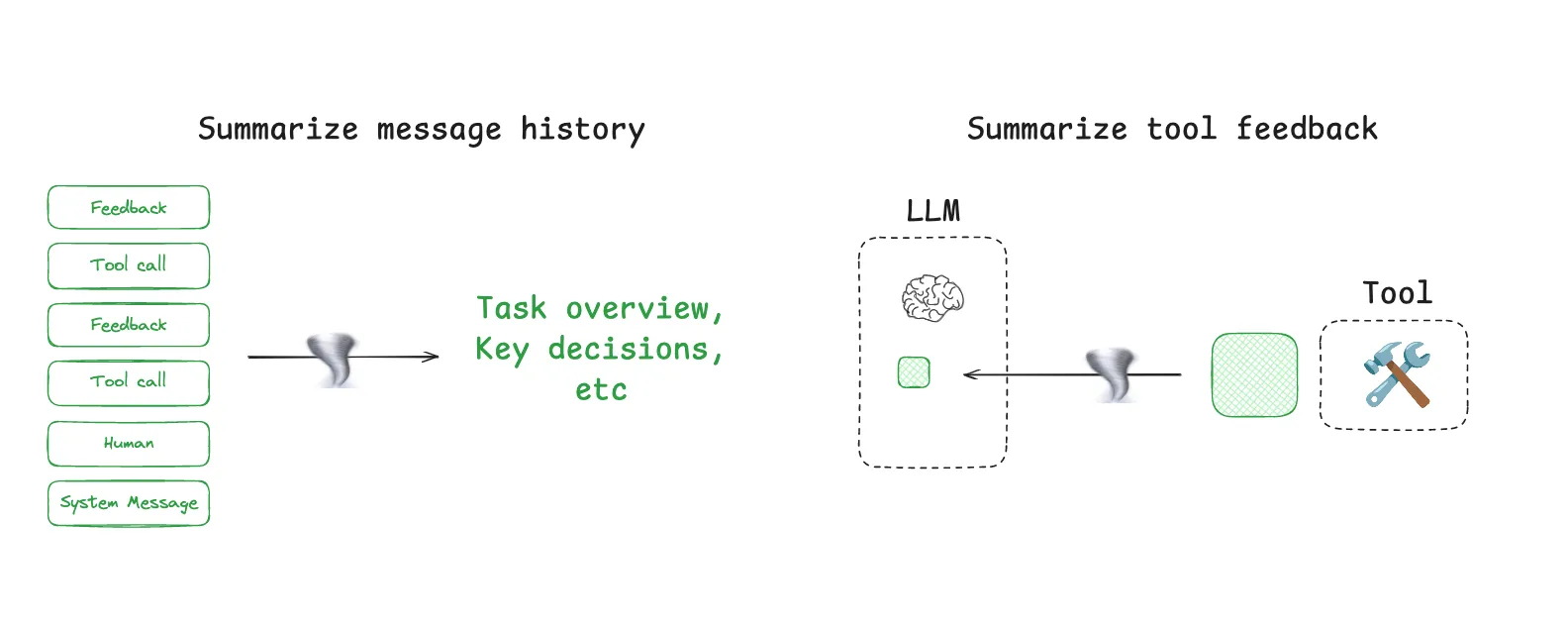
#3 Compress Context: Summarization on Demand
Claude Code demonstrates this approach well with its “auto-compact” feature. When a conversation nears the context limit, the system compresses hundreds of turns into a concise summary, preserving task-critical details while freeing space for new reasoning.
#4 Isolate Context: Modular Context Management
LangGraph applies this principle through a multi-agent architecture. Complex tasks are divided into modules, with each sub-agent operating within its own context space. This separation prevents interference: one agent can explore alternatives without contaminating another’s reasoning path.
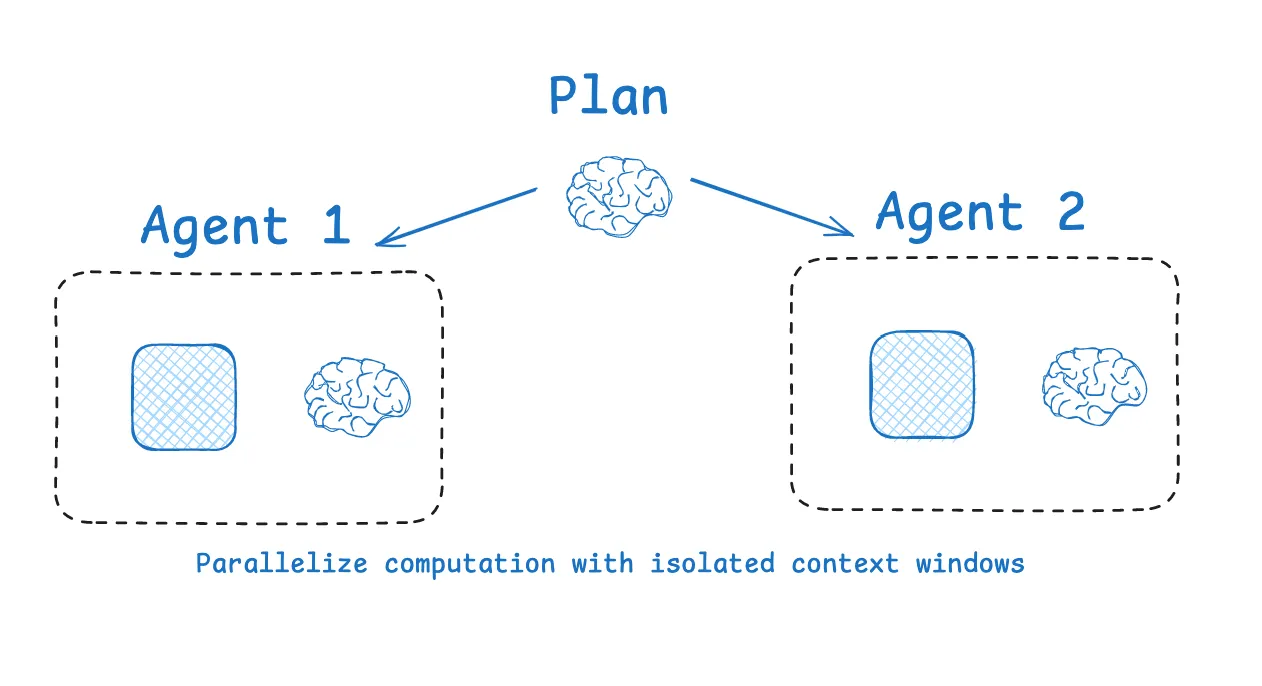
For more details, see LangChain’s blog about context engineering.
Lossfunk’s 6 Practical Tips on Context Engineering
Another perspective comes from Lossfunk, which treats context management as an engineering discipline grounded in real-world deployment. Their approach emphasizes balancing three constraints that every production team faces: performance, reliability, and cost. Paras Chopra, founder of Lossfunk, has outlined six practical tips for building effective LLM agents with context.
#1 Smaller Tasks, Higher Success
Complex tasks can overwhelm agents just as they do humans. Research from METR shows that LLMs achieve their highest success rates — around 90% — when tasks are scoped to 10–15 minutes of work. Instead of asking an agent to refactor an entire application in one run, break the project into smaller, atomic steps: analyze the authentication module, identify potential security issues, and then propose targeted fixes. This mirrors how experienced developers operate: one focused step at a time, with progress building incrementally.
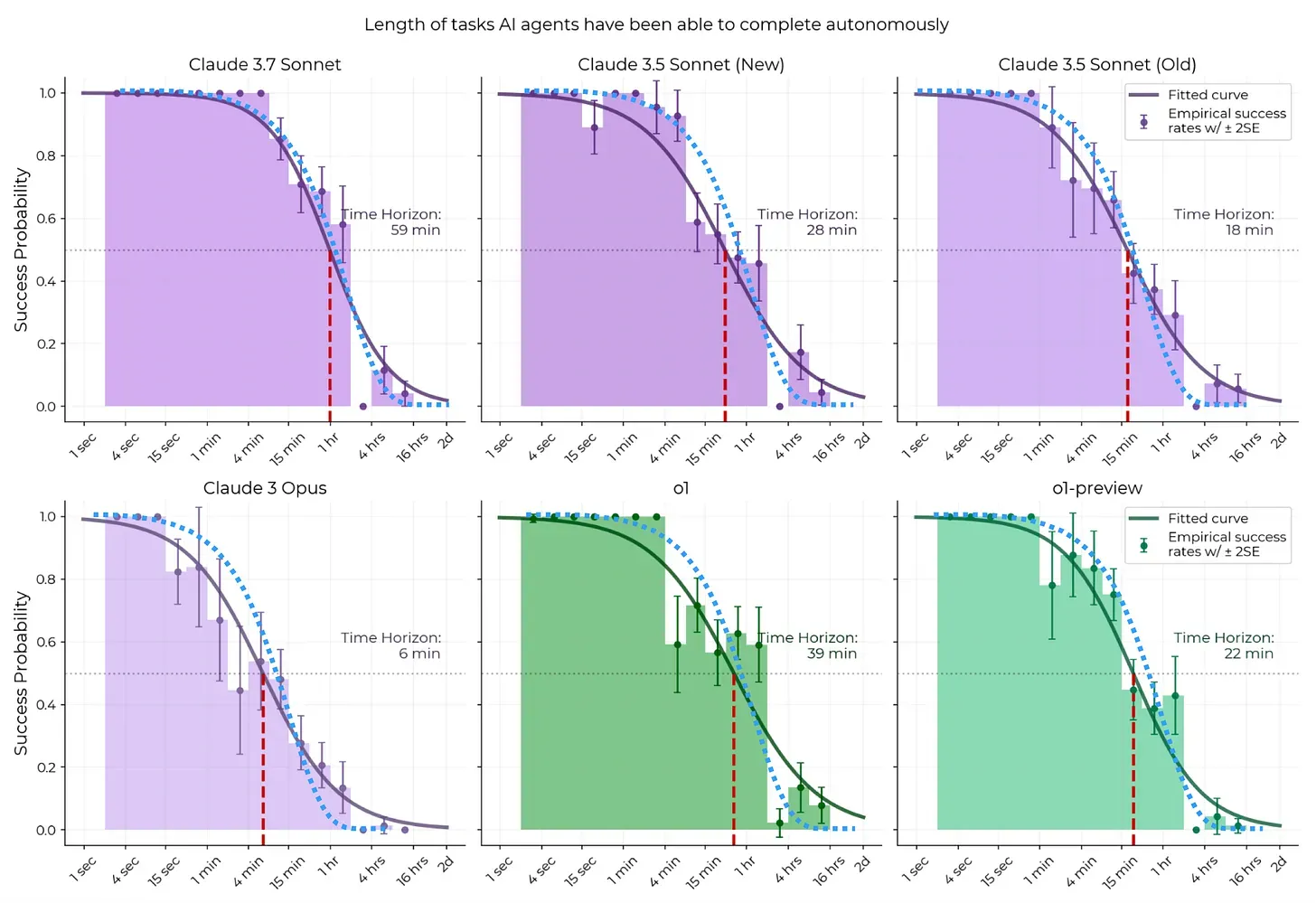
Source: Measuring AI Ability to Complete Long Tasks
#2 Whole Files > Fragmented Retrieval
In contrast to LangChain’s emphasis on filtering and compression, Paras argues that more context is usually better. His view is that RAG systems often fragment information into small, incomplete chunks, which can leave agents confused or uncertain. Instead, he suggests loading complete files or datasets directly into the context window, giving the model the full picture.
Lossfunk supports this perspective with benchmark evidence. On SWE-bench-Verified, approaches that used full-file context achieved around 95% accuracy, compared to about 80% for fragmented retrieval. The difference comes from coherence: with full files, the model sees relationships across the entire document rather than stitching together disjointed pieces.
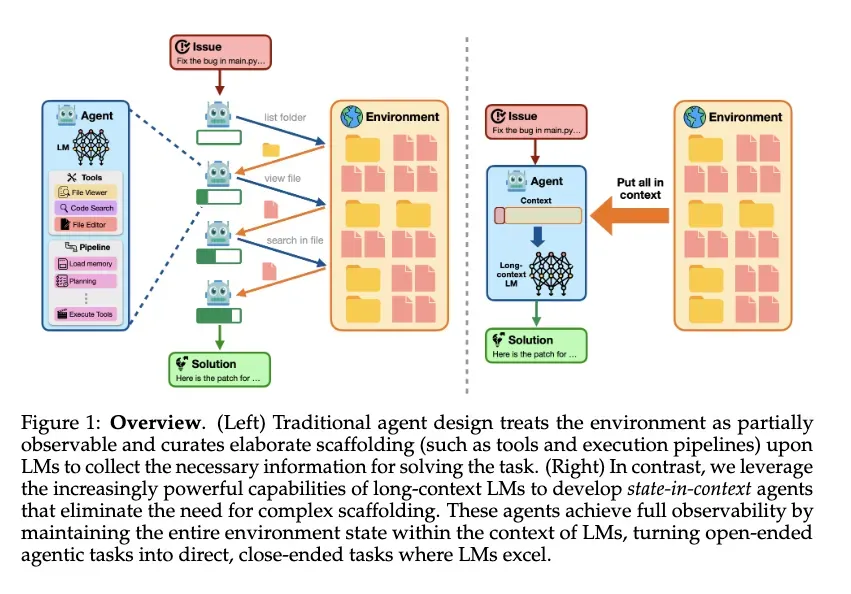
Of course, this comes with trade-offs. Supplying more context to LLM agents increases both cost and latency. Teams must weigh the benefits of completeness against the expense of longer prompts — a balance that depends on the task and production constraints.
#3 Add a Verification Step After Each Task
Errors tend to compound across long reasoning chains. To reduce this risk, Lossfunk suggests designing each step as a stateless function with explicit success/failure checks. After every tool call or reasoning action, the agent should confirm whether the operation succeeded and clearly state the next step.
This pattern is similar to unit testing in software development: catch small errors early before they cascade into larger failures. By building in verification, developers create natural recovery points that make agents more resilient in production workflows.
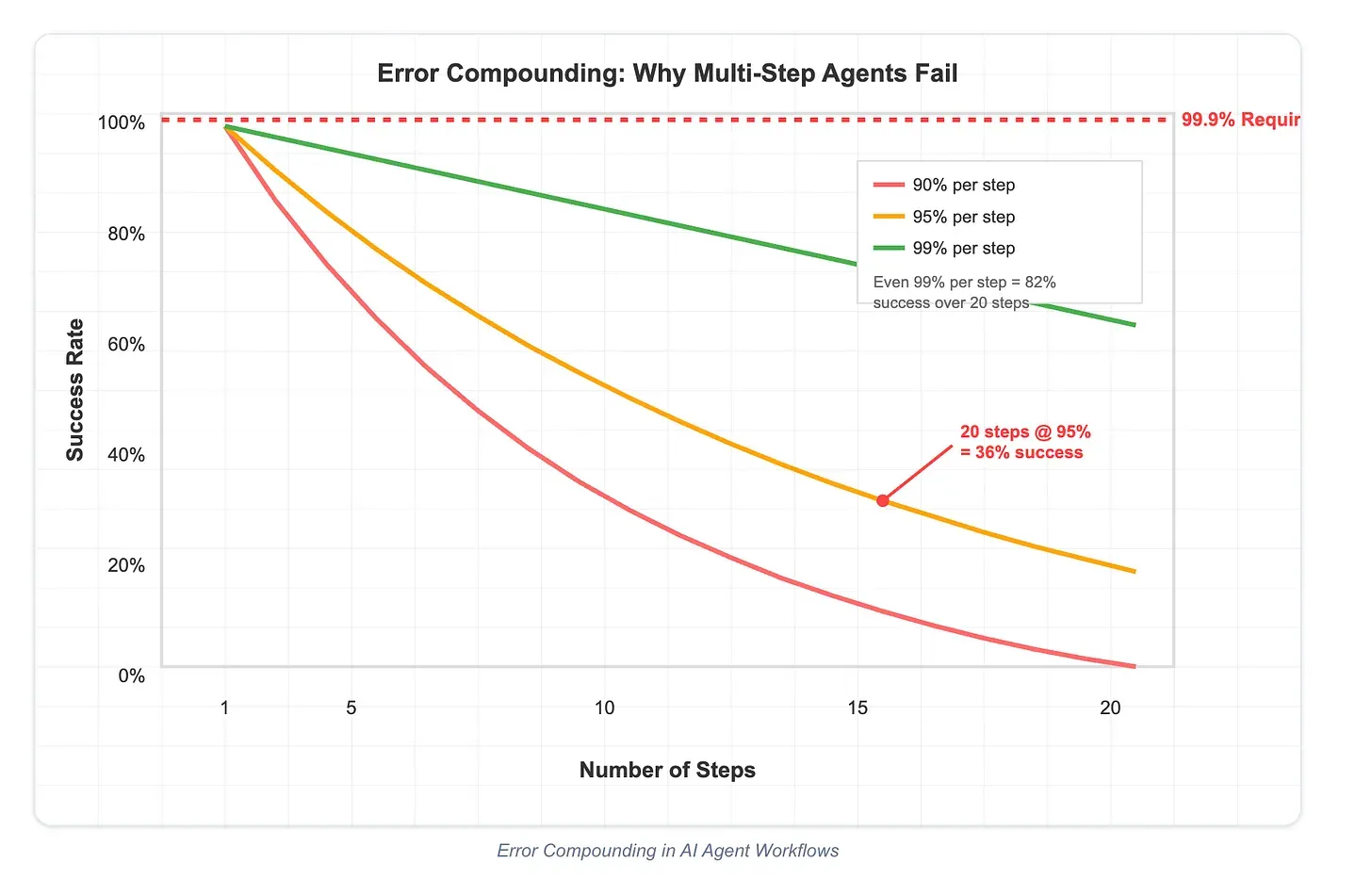
#4 Remind the Model Frequently
Models often forget early instructions in long conversations, so it is essential to continuously reinforce task objectives and the current state. Regularly inject task summaries and current objectives into your prompts. Don't assume the model remembers what it was supposed to do 50 exchanges ago. This isn't a limitation—it's simply how human cognition works. We utilize external memory aids, such as notes and reminders, to stay on track during complex tasks.
#5 Equip Agents with Read/Write Tools to Build Context on Demand
Cramming every piece of information into the context window quickly leads to overload. A better approach is to give agents read/write tools so they can fetch or record information as needed. Instead of pre-loading entire documentation sets, equip your agent with file readers or database connectors and let it pull in the relevant details on demand.
This mirrors how experienced developers operate: they don’t memorize an entire codebase, but they know how to find the right function or file when the need arises. By extending agents with the ability to query and update external sources, developers can keep context lean while still ensuring the agent has access to the knowledge it needs.
#6 Keep Context Immutable to Leverage KV Cache
Each conversation turn with a heavily changing context can become extremely expensive — sometimes exceeding $100 per response. To take advantage of KV cache optimizations, keep as much of the context immutable as possible. Instead of replacing context at every step, append new information and maintain consistent, structured formats across interactions.
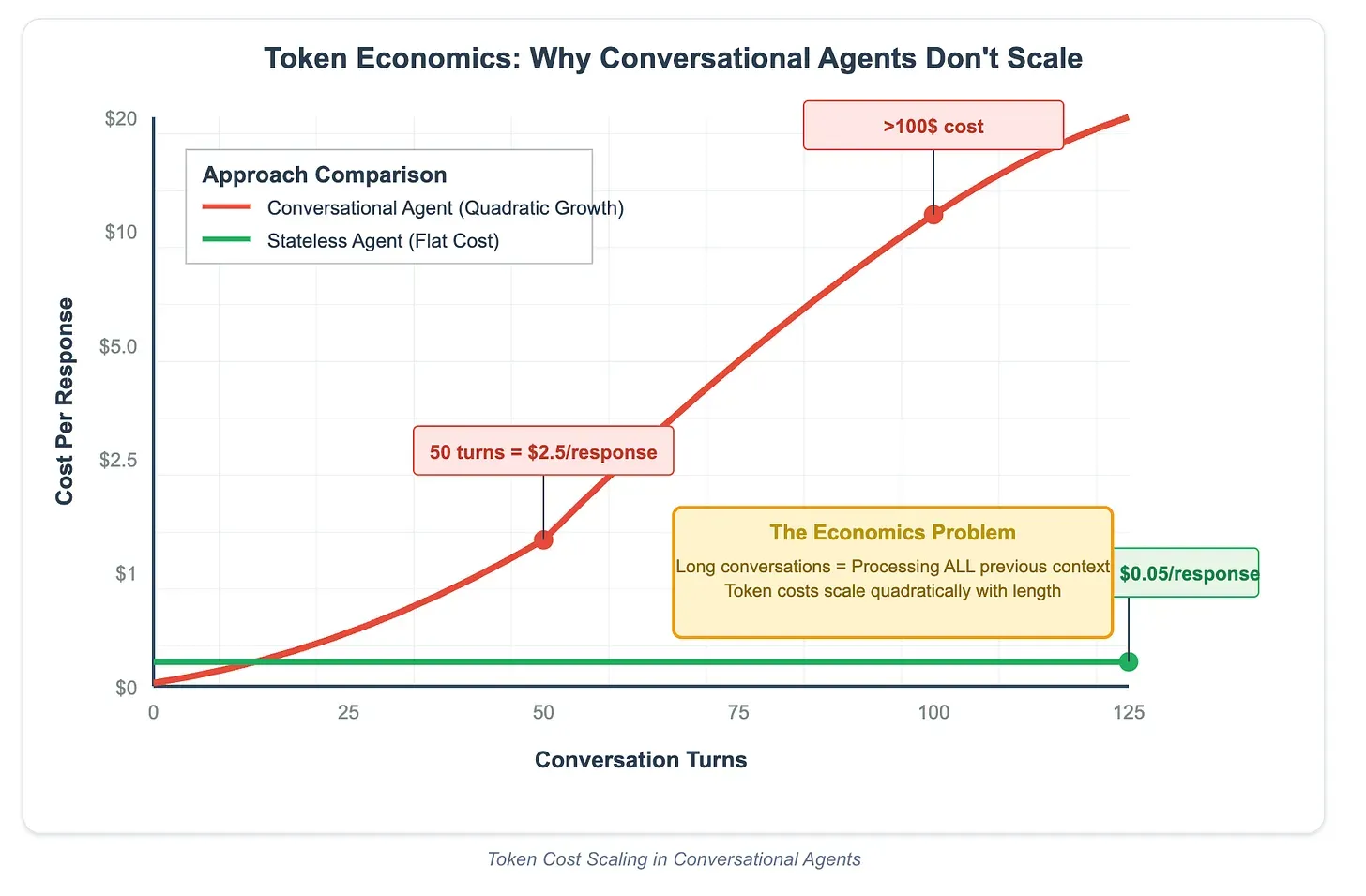
This seemingly small technical adjustment can deliver outsized benefits: reducing costs by an order of magnitude while also improving response times. For production deployments, it’s one of the most impactful low-level optimizations developers can apply.
For more details, check out this blog by Paras.
Manus: 7 Lessons from Building Agents
Manus is a fully autonomous, multi-agent AI system designed to handle complex tasks with minimal human guidance — from research to project management. As part of their work, the Manus team has shared practical lessons on context engineering drawn from running their system in production.
#1 Design Around KV-Cache for Cost Efficiency
For production-grade agents, one of the most critical performance metrics is the KV-cache hit rate, which has a direct impact on both cost and response time. Inputs for modern agents are growing longer — with extensive context and detailed tool call records — while outputs remain concise, often resembling function calls. The mismatch leads to disproportionately high prefill costs.
The recommended approach is to keep prompt prefixes stable and avoid cache-disrupting elements like timestamps that change with every request. Use an append-only context strategy instead of rewriting existing content, and enforce deterministic ordering for JSON serialization. Some model frameworks also require explicitly marking cache breakpoints to maximize KV-cache reuse. Following these practices can make a significant difference in production cost efficiency.
#2 Use Tool Masking Instead of Dynamic Loading
As the number of tools increases into the hundreds, including user-defined tools, models become more prone to errors or getting stuck during the tool selection process. The problem compounds because dynamically inserting or removing tools invalidates the KV cache and causes reference errors for undefined tools.
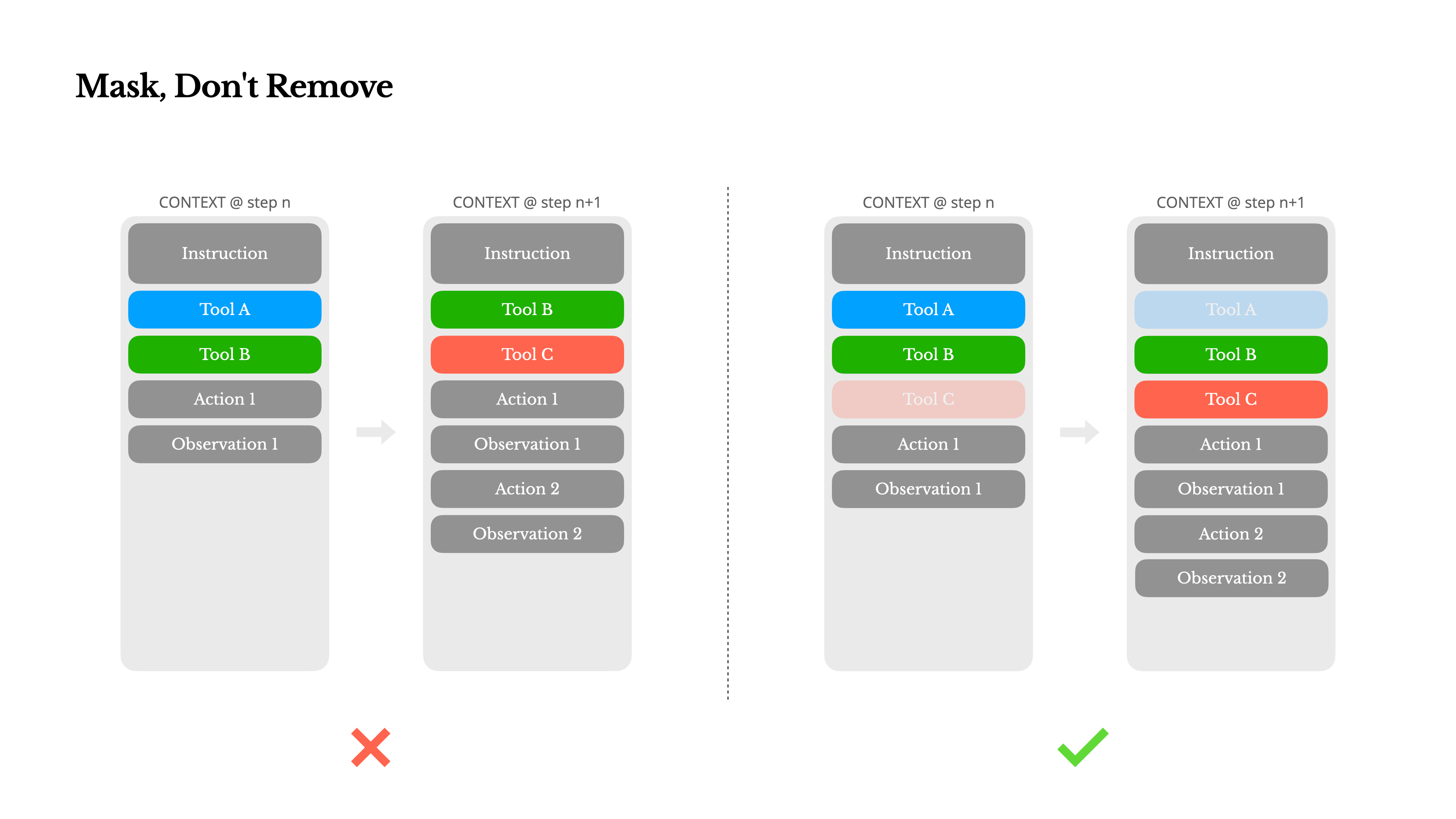
Instead of deleting tools, use masking. Token masking techniques let you dynamically adjust callable tool sets without breaking the cache. Use unified prefixes, such as browser_, for easy grouping and limitation, and leverage the Hermes format or API-supported function-calling prefill to control the selection space.
#3 Use the File System as Context
While a 128K context seems sufficient, it becomes tight when encountering large web pages, PDFs, and other unstructured data. The typical compression approach of discarding information early can cause future steps to lose critical context.
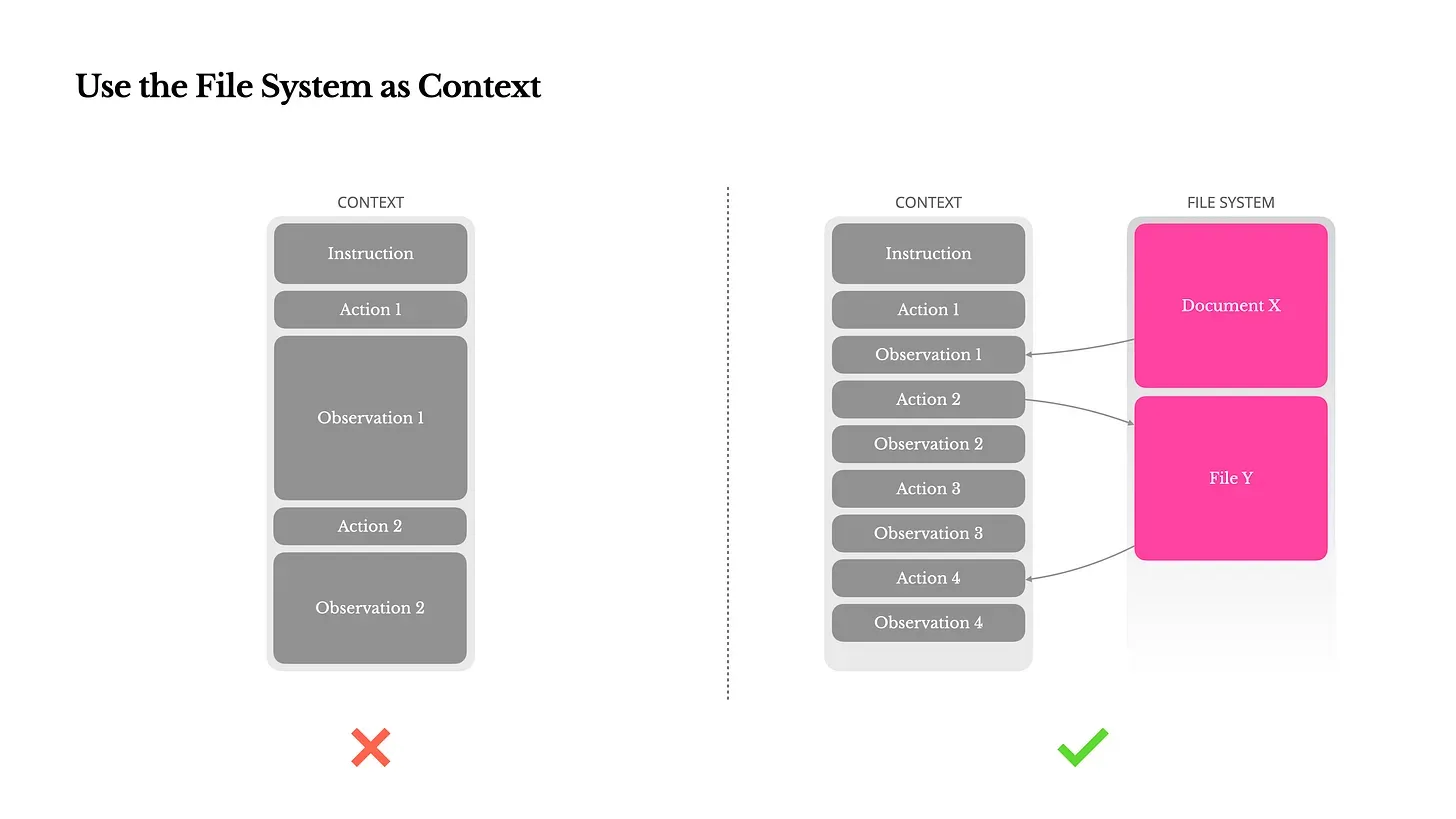
Manus's approach allows agents to use file system read/write operations to externalize data. Delete web page content but retain URLs, clear documents but keep file paths, ensuring information remains recoverable. This implements a "long-term memory" system while laying the groundwork for future, lighter architectures, such as SSM.
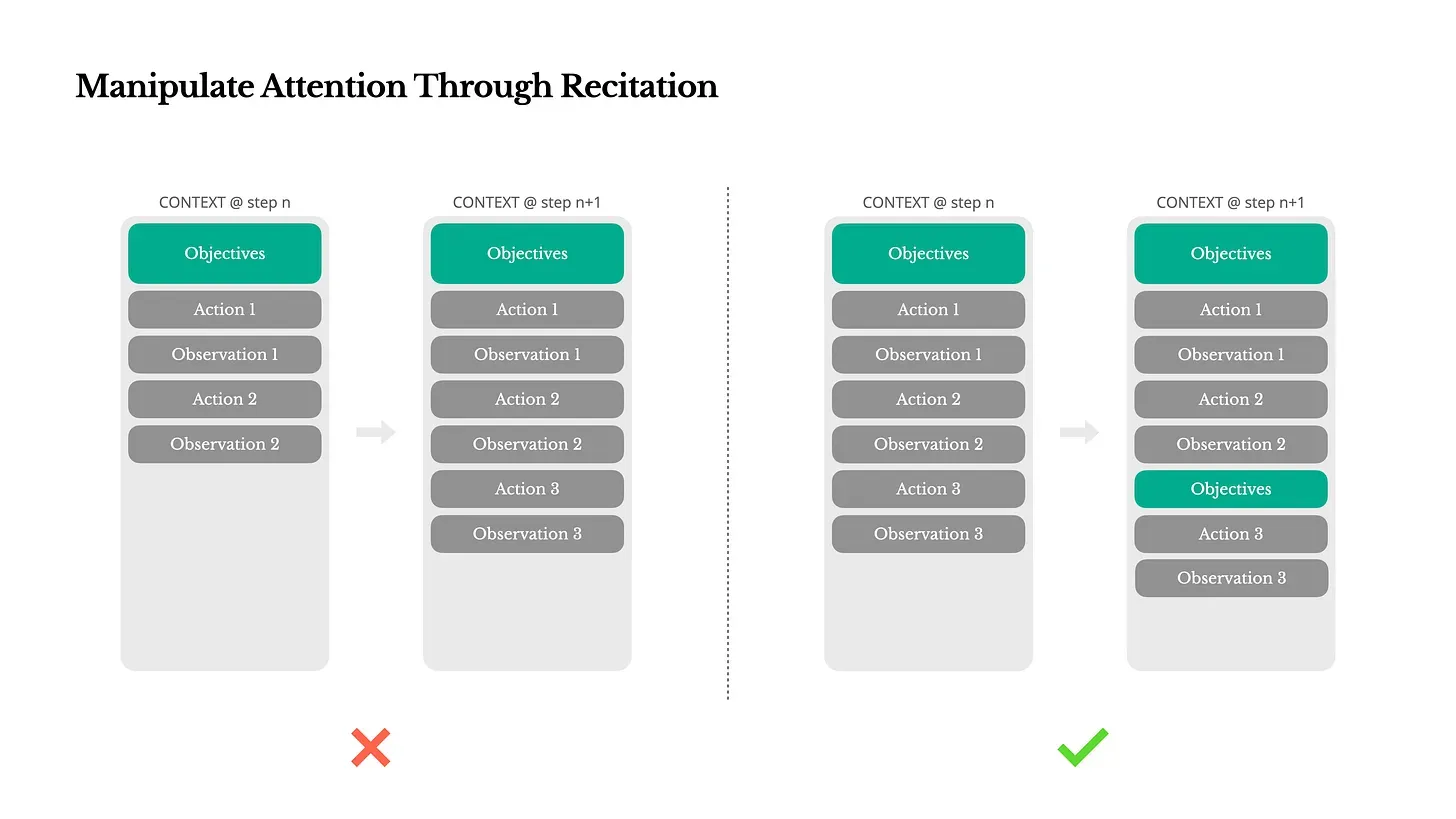
#4 Manipulate Attention Through Recitation
Manus continuously updates todo.md , reciting incomplete goals at the end of context. This technique avoids "lost-in-the-middle" problems and improves the model's ability to maintain goal consistency during long processes. Natural language "self-reminding" has proven to be one of the most effective methods for capturing and maintaining attention.
#5 Preserve Failure Traces for Learning
Language models inevitably experience hallucinations, environment crashes, and call failures. Most systems habitually clear failure traces, retry, or reset, but this prevents learning from occurring. The correct approach preserves failure records, including stack traces and observation results, helping models adjust their beliefs and avoid repeating identical mistakes. Error recovery ability represents the accurate measure of agent intelligence.
#6 Avoid Few-Shot Traps
Few-shot prompting is a well-known technique for improving LLM outputs, but Manus cautions that in agent systems, it can introduce subtle problems. Because models naturally imitate context patterns, loading too many repetitive few-shot examples can lock them into rigid behaviors. For example, when Manus used batch prompting to review resumes, the model began repeating the same actions mechanically instead of adapting to the specifics of each case.
The remedy is to introduce variation and diversity into the examples. Slightly adjust action–observation templates by changing formats, ordering, or wording. Adding structured “noise” prevents agents from becoming brittle and helps them stay adaptive. This maintains flexibility while still giving the model useful guidance.
#7 Prioritize Context Engineering Over Fine-Tuning
In its early work with models like BERT, Manus relied heavily on fine-tuning — a process that often took weeks of iteration and quickly became inefficient and costly. Based on that experience, the team shifted its focus away from end-to-end training and toward context engineering as the primary lever for improving performance.
The impact was significant: product update cycles shrank from weeks to hours. Model upgrades could be integrated seamlessly without retraining or readaptation. Manus describes the difference as building products like ships that can change course rather than posts nailed to the seabed, unable to move with changing conditions. Context engineering gave them flexibility without sacrificing capability.
For more details, check out this Manus blog.
How Vector Databases Support Context Engineering
One of the toughest challenges for AI agents is running out of context. When agents must process massive external knowledge bases, long conversation histories, or multimodal data, the ability to store, retrieve, and reuse information dynamically becomes essential for reliability.
Vector databases provide a practical solution. Milvus, for example, is an open-source, high-performance system built to handle billion-scale multimodal data — text, images, video, and more. By representing this information as vectors, Milvus allows agents to instantly pull the most relevant knowledge snippets and past interactions into their reasoning process. Integrated with frameworks like LangChain or LlamaIndex, Milvus powers retrieval-augmented generation (RAG) systems that expand an agent’s knowledge base and improve inference accuracy. Its managed service, Zilliz Cloud, offers even more advanced features and higher performance, such as natural language querying, enterprise-grade reliability & security, and global availability across AWS, GCP, and Azure.
Developer experience is just as important. Milvus offers a well-documented Python SDK that makes it easy to store and query vectors in only a few lines of code. This lowers the technical barrier and enables teams to quickly establish a closed loop for context management, embedding robust memory capabilities directly into their agents.
from pymilvus import MilvusClient
# Create local Milvus instance
client = MilvusClient("demo.db")
# Create vector collection
client.create_collection(collection_name="knowledge_base", dimension=768)
# Batch insert vectorized data into knowledge base
client.insert(collection_name="knowledge_base", data=embedding_vectors)
# Retrieve most relevant context information
query_vector = embedding_fn.encode_queries(["What is Context Engineering?"])
results = client.search(
collection_name="knowledge_base",
data=query_vector,
limit=3,
output_fields=["text", "source"]
)
For more information, check out the following resources:
Milvus + Loon: Purpose-Built Infrastructure for AI Agents
Vector databases are central to context engineering, but they’re only one part of the stack. Agents also need a way to process messy, multimodal data upstream and then retrieve it at high speed during runtime. That’s why we designed Milvus and Loon to work together — one handling retrieval, the other preparing data at scale.
Milvus: Milvus is the most widely adopted open-source vector database, optimized for billion-scale workloads across text, images, audio, and video. It’s built from the ground up for vector search, delivering sub-10ms retrieval even at massive scale. For agents, this directly translates into responsiveness: whether they feel instant and reliable, or slow and error-prone, depends on retrieval speed.
Loon (Coming Soon): Loon is our upcoming cloud-native multimodal data lake service designed for multimodal preprocessing. Real-world datasets are messy — duplicated, inconsistent, and scattered across formats. Loon uses distributed frameworks like Ray and Daft to clean, deduplicate, and cluster that data before streaming it into Milvus. The result: agents don’t waste cycles on noise; they consume structured, high-quality context from day one.
Cloud-Native Elasticity: Both systems scale storage and compute independently, letting teams balance real-time serving with offline analytics as workloads grow from gigabytes to petabytes. No overprovisioning, no bottlenecks — just the elasticity modern AI pipelines demand.
Future-Proof Foundation: Today’s priority is semantic search and RAG pipelines; tomorrow’s will be multimodal reasoning and agent-driven workflows. With Milvus and Loon, the same stack supports both. You gain flexibility to evolve without ripping out infrastructure — lowering cost, risk, and complexity.
Context Is the Real Frontier for AI Agents
As the debate over single-agent versus multi-agent design shows, the real bottleneck for today’s AI agents isn’t solely creativity — it’s context. Whether it’s LangChain’s four-pillar framework, Lossfunk’s production-focused playbook, or Manus’s hard-earned lessons from building fully autonomous systems, the industry is converging on the same insight: agents succeed or fail based on how well they engineer context.
The strategies differ — some emphasize writing and filtering, others advocate full-file context or cache-aware design — but the goal is the same, particularly for product-ready agents: keep agents both capable and cost-efficient. And while no single technique solves everything, together they form a growing body of practices that developers can adapt to their own systems.
At Zilliz, we see vector databases like Milvus as a cornerstone of this toolkit. By giving agents scalable and more accurate memory beyond the context window, developers can make context engineering practical, flexible, and production-ready. The future of AI agents won’t be defined by bigger models alone, but by smarter ways of engineering context — and that’s where the real breakthroughs will happen.

Keep Reading

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Introducing DeepSearcher: A Local Open Source Deep Research
In contrast to OpenAI’s Deep Research, this example ran locally, using only open-source models and tools like Milvus and LangChain.