




Databricks & Spark Connectors
Leverage Databricks' powerful data processing alongside Milvus & Zilliz Cloud's vector index and search with no custom code required
Use this integration for Free
Combining the data processing the vector search capabilities of Milvus & Zilliz Cloud
Databricks is a unified analytics platform simplifying data processing and machine learning tasks. It is built on Apache Spark, an open-source distributed computing system. It provides a collaborative environment for data engineers, data scientists, and analysts to collaborate on big data projects. Databricks abstract away the complexities of managing Spark clusters, allowing users to focus on data analysis and machine learning tasks. It offers interactive notebooks, automated cluster management, and built-in support for various data sources and machine-learning libraries. Overall, Databricks enhances the usability and scalability of Spark, making it easier for organizations to derive insights from large datasets.
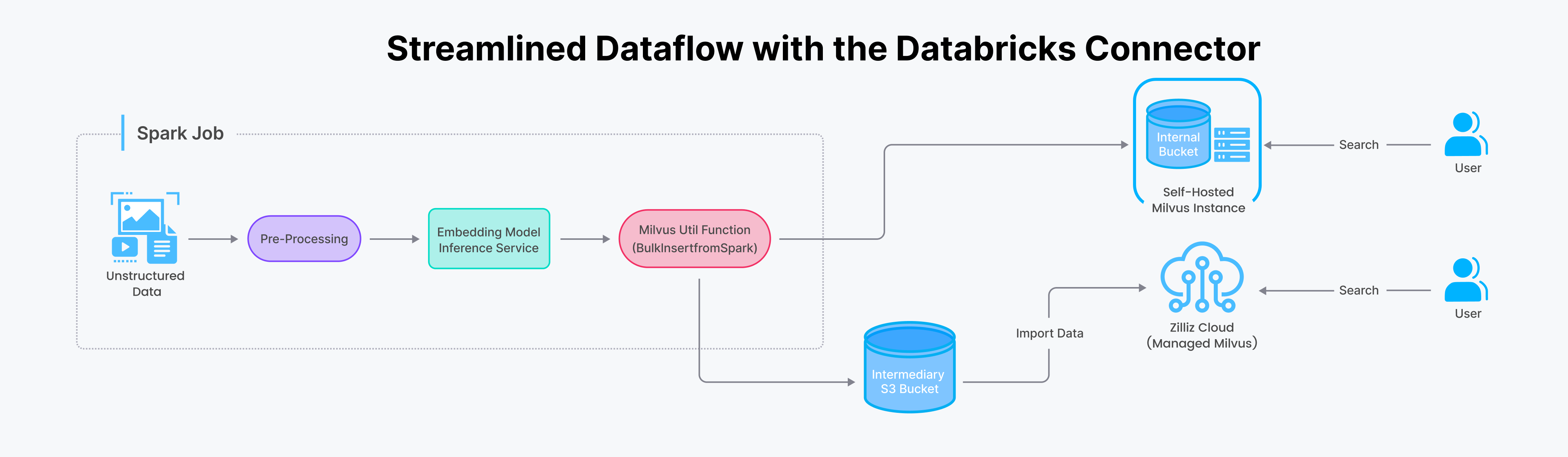
The Spark Milvus Connector creates synergies between Apache Spark and Milvus, allowing users to harness Spark's processing abilities alongside Milvus's vector data storage and query functionalities. This integration unlocks a range of valuable applications, such as seamless data transfer and integration between Milvus and different storage systems or databases, streamlined data processing and analysis within Milvus, and efficient vector processing operations leveraging the Spark MLlib and other AI libraries.
This same connector can be used between Zilliz Cloud and Databricks, simplifying the transition of data from offline processing to online, important for AI-driven search.
Key highlights of the integration include:
- Enable vector-generating Spark jobs to load data directly into Milvus with a simple utility function call, eliminating the need for custom glue code or additional Spark jobs
- Directly insert Spark DataFrame records into Milvus using the Spark-Milvus connector streamlines integration, eliminating the need for connection-establishing code and API calls.
How it works
Let's dive into the process of transferring data from Spark to Milvus. Traditionally, this task required complex backend glue code. However, with the Spark-Milvus connector, it's streamlined into a single function call within your Spark application.
 Streamlined Dataflow with the Databricks Connector.png
Streamlined Dataflow with the Databricks Connector.png
With the Spark/Databricks Connector, you can import data to Zilliz Cloud (or Milvus) in two ways: streaming for real-time updates and batch for large datasets. Check out our example notebooks for a step-by-step guide on how to use it effectively.
Learn How to use the Sparks and Databricks Connectors
Check out these resources to help you get started using Zilliz Cloud, the Spark and Databricks Connectors
Spark Milvus Connector
Databricks Connector