




Building an End-to-End GenAI App with Ruby and Milvus
The introduction of specialized GenAI frameworks like LangChain has enabled us to build sophisticated AI applications quickly and easily by leveraging powerful large language models (LLMs) such as ChatGPT and LLaMA. LangChain, for example, allows us to create a powerful Retrieval Augmented Generation (RAG) application in just a few lines of code without requiring deep theoretical AI knowledge.
This trend means that nowadays, data scientists and machine learning engineers are no longer the only ones capable of building GenAI applications. Full-stack engineers or software developers can now build GenAI apps using LangChain.
However, these GenAI frameworks are typically written in Python, and we know that some full-stack engineers and software developers rarely use Python in their projects. Therefore, there is a need for extensions of these GenAI frameworks in other programming languages so that these full-stack engineers can leverage powerful LLMs to build GenAI applications in their software projects.
In a recent talk, Andrei Bondarev, a Solution Architect at Source Labs LLC, introduced a Ruby extension of LangChain called LangChain.rb to make it easier for full-stack engineers to build GenAI applications in their software projects.
But before we discuss how to build a GenAI application with Ruby, let's briefly explore the inner workings of Retrieval Augmented Generation (RAG), a popular use case of GenAI.
How RAG Works
It's no secret that data is the gold mine of any GenAI app. It serves as the source of information used by GenAI to generate factual and accurate responses. Of all the data available right now, 80% can be classified as unstructured data.
Unstructured data refers to data that doesn't conform to a predefined data format. This type of data includes images, text, sound, and videos. For machines to make sense of these unstructured data types, we need to transform them into a numerical format called vector embeddings.
Fundamental Concepts of Vector Embeddings
An embedding consists of an n-dimensional vector, where n refers to the dimensionality of the embedding. The dimensionality depends on the deep learning model that transforms the data into an embedding. An embedding carries the semantic meaning of the data it represents.
We can use deep learning models to transform various data modalities into embeddings. For example, if we have text data, we can use OpenAI or Sentence Transformer models to transform this text data into an embedding. If we have image data, we can use specialized pre-trained models capable of extracting image features, such as Vision Transformer, as an embedding model.
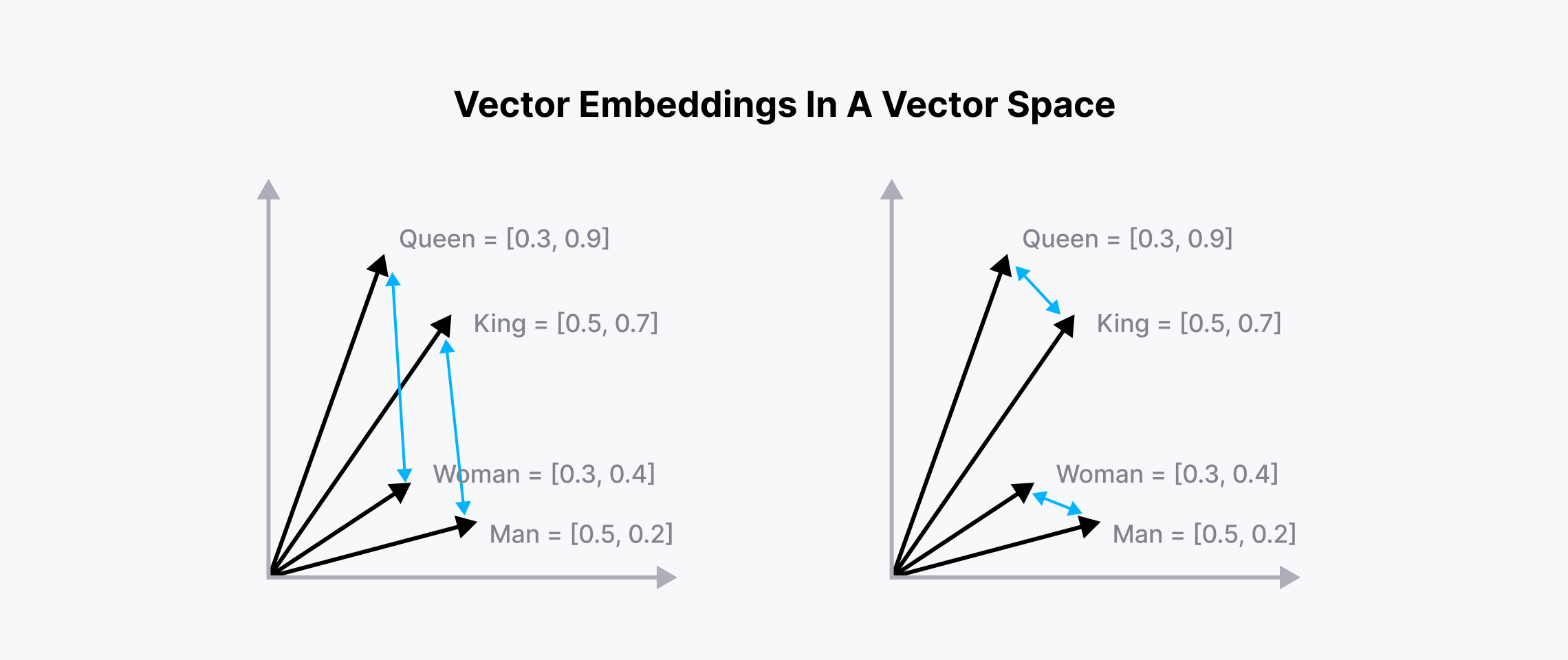
Since an embedding carries the semantic meaning of the data it represents, we can calculate the similarity of that embedding with other embeddings in the so-called vector space. Embeddings with similar semantic meanings will be placed near each other in the vector space, as you can see in the visualization below:
 Vector embeddings in a vector space.png
Vector embeddings in a vector space.png
Embedding of related words in vector space
As shown in the image above, the embeddings of "queen" and "king" are placed near each other, and so are "woman" and "man". The Euclidean Distance between "queen-king" and "woman-man" would also be approximately the same since they carry similar meanings.
This concept is the basis of a vector search operation, where we calculate the similarity between one embedding and several embeddings.
The Role of Vector Database in Vector Search and RAG Applications
Implementing a vector search is straightforward if we only deal with a small amount of embeddings. However, we commonly deal with thousands, millions, or even billions of embeddings in real-world cases Therefore, we need a solution to efficiently store the embeddings and perform fast vector searches on them.
This is where a vector database like Milvus comes into play. Milvus is an open-source vector database where you can store massive amounts of embeddings and perform vector searches on these embeddings in a split second.
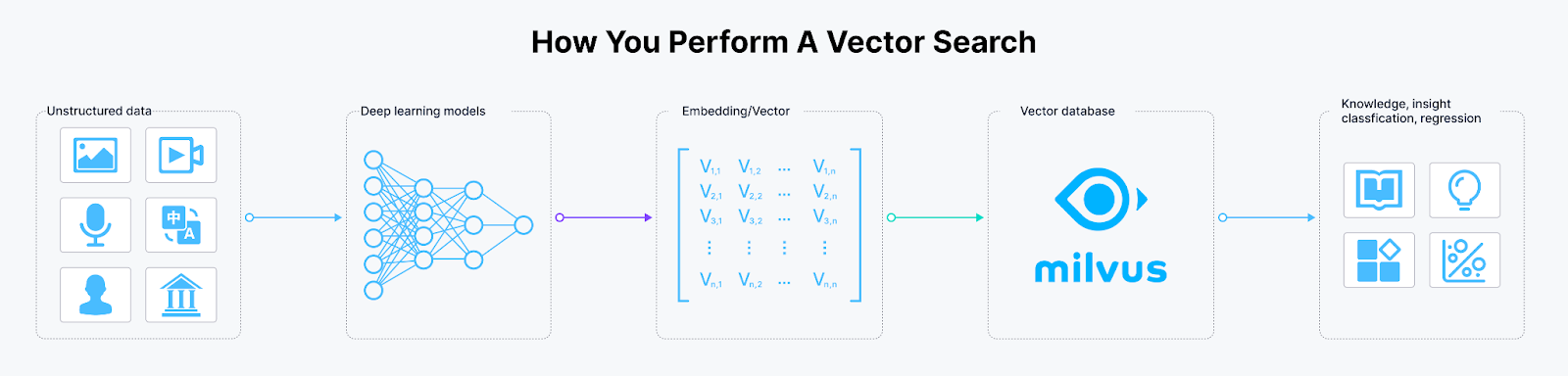 The workflow of transforming unstructured data into embeddings and storing them in Milvus
The workflow of transforming unstructured data into embeddings and storing them in Milvus
The workflow of transforming unstructured data into embeddings and storing them in Milvus
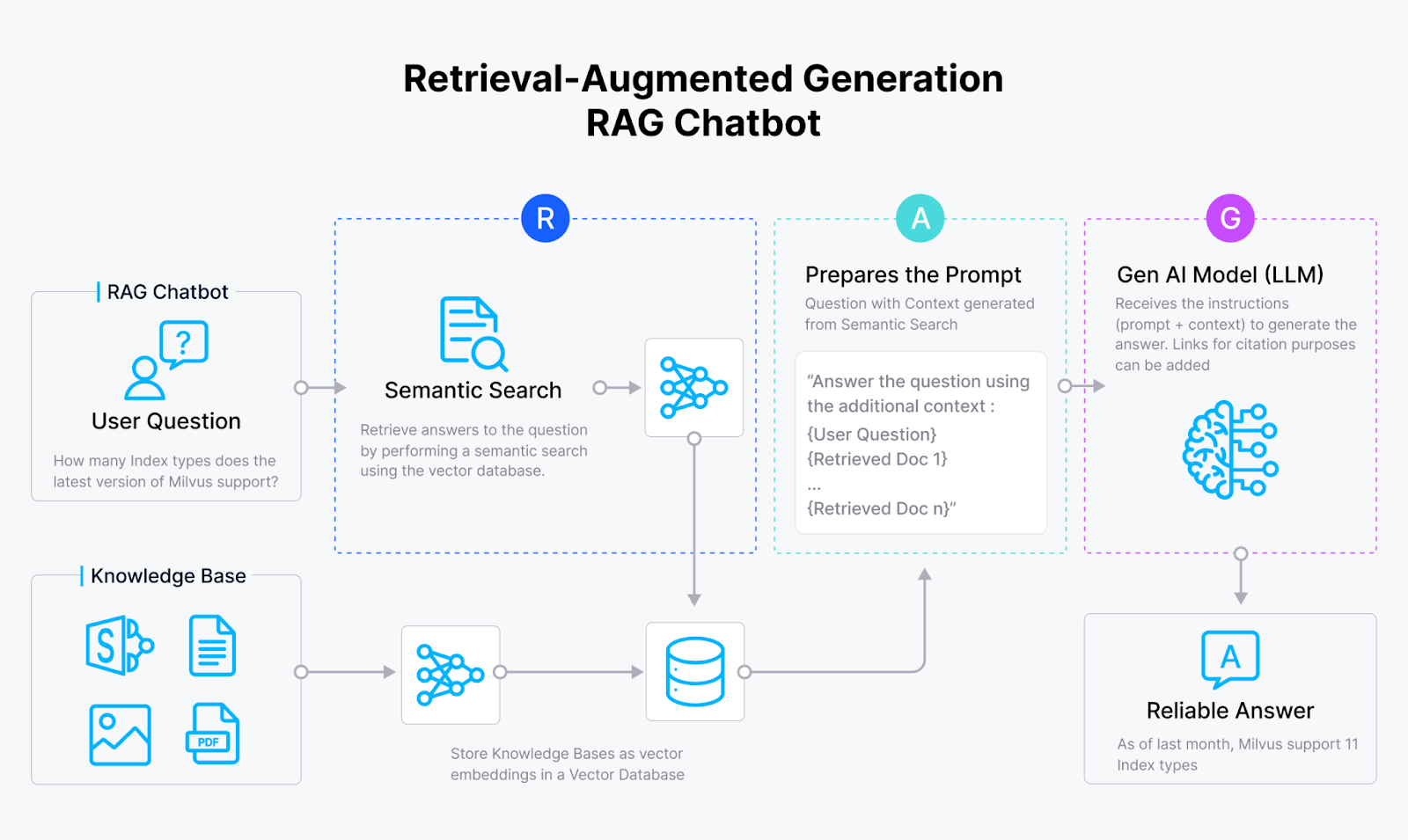
Vector databases also play a crucial role in popular GenAI apps like RAG. As you might already know, the main goal of RAG is to improve the accuracy of responses generated from LLMs like ChatGPT and LLaMA by providing them with context that can be useful in answering the user's query.
In a RAG application, once the user's query is received, it is transformed into an embedding using an embedding model. Next, a vector search is performed, where the query embedding is compared with context embeddings stored inside the vector database like Milvus. The most similar context data is then fetched and passed alongside the query to the LLM. The LLM can then use the information from the context to generate a contextualized response to answer the user's query.
 RAG
RAG workflow
RAG
RAG workflow
LangChain as a Popular GenAI Framework
LangChain is a framework that makes it easy to build and develop GenAI apps using state-of-the-art LLM models. It easily integrates with popular LLM providers like OpenAI, Anthropic, and Google, as well as vector database providers like Zilliz.
LangChain also offers flexible abstractions for developing LLM-powered AI applications, making it straightforward for data scientists and software developers to build sophisticated systems like RAG with just a few lines of code.
For example, let's say we want to summarize the content of this blog post using GPT-4. We can finish this task with the following code:
import os
from langchain.chains.summarize import load_summarize_chain
from langchain_community.document_loaders import WebBaseLoader
from langchain_openai import ChatOpenAI
os.environ["LANGCHAIN_TRACING_V2"] = "True"
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
docs = loader.load()
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-1106")
chain = load_summarize_chain(llm, chain_type="stuff")
result = chain.invoke(docs)
"""
Output: The article discusses the concept of LLM-powered autonomous agents, with a focus on the components of planning, memory, and tool use. It includes case studies and proof-of-concept examples, as well as challenges and references to related research. The author emphasizes the potential of LLMs in creating powerful problem-solving agents, while also highlighting limitations such as finite context length and reliability of natural language interfaces.
"""
As you can see, with roughly only 10 lines of code, we can leverage the GPT-4 model to accurately summarize a long blog post.
With LangChain, you can also perform more complex tasks. For example, you can split a long text from a PDF document into chunks, transform each chunk into an embedding using an embedding model of your choice, store the embedding of those chunks inside a vector database, and perform RAG afterward.
import getpass
import os
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores.milvus import Milvus
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
from langchain.embeddings import SentenceTransformerEmbeddings
from langchain_openai import ChatOpenAI
# Set the API key
os.environ["OPENAI_API_KEY"] = getpass.getpass("Enter your OpenAI API key: ")
llm = ChatOpenAI(model="gpt-4")
# Text to be processed
texts = "This is a very long text.....:"
# Split text into chunks
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) # Example chunk size and overlap
chunk_texts = text_splitter.split_text(texts)
# Instantiate embedding model
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# Store embeddings of chunks inside Milvus DB
vector_db = Milvus.from_texts(texts=chunk_texts, embedding=embeddings, collection_name="rag_milvus")
retriever = vector_db.as_retriever()
# Define function to format documents
def format_docs(docs):
return "\\n\\n".join(doc.page_content for doc in docs)
# Perform RAG (Retrieval Augmented Generation)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| llm
| StrOutputParser()
)
# Example question
question = "What is the main idea of the text?"
# Execute RAG chain and print the result
for chunk in rag_chain.stream(question):
print(chunk, end="", flush=True)
Aside from the demos provided above, LangChain offers a wide range of functionalities. For instance, it integrates LLMs and APIs from external sources such as weather apps, calculators, or Google Search. This approach allows LLMs to utilize information from these sources to generate more accurate and contextual responses. We’ll see the detailed implementation of this approach in the upcoming sections.
You can also explore all of LangChain's functionalities on their documentation page.
GenAI App Development with Ruby and Milvus
Python has become the de-facto programming language for AI research and development frameworks, including LangChain. Meanwhile, Ruby remains popular for rapid software and web application development.
However, as you've seen in the previous section, the introduction of LangChain opens up possibilities for software developers to integrate the power of LLMs into their web apps without knowing the detailed theories of LLMs and AI in general.
This capability has created a growing demand to extend these GenAI development frameworks to other languages that are more familiar to full-stack developers, such as Ruby. To fulfill this demand, Andrei Bondarev introduced LangChain.rb, which is the Ruby extension of the original LangChain framework.
LangChain.rb enables Ruby full-stack developers to build LLM-powered web apps without the hassle of incorporating multiple programming languages in their projects. With it, you can easily integrate popular vector databases, LLMs, and external resources into your LLM web apps.
LangChain.rb has the same general functionalities as the original LangChain, such as:
Prompt management: create, load, and save prompt templates for LLMs of your choice
Context length validation: validate the context length of the inputs according to the context length of LLMs and embedding models of your choice
Data chunking: split data into chunks with predefined rules before ingesting them into vector databases of your choice
Conversation Memory: persisting a chat with an LLM to a memory
In the following sections, we'll demonstrate the development of simple LLM-powered apps with the help of LangChain.rb.
General RAG Apps with LangChain.rb
In this first example, we will build a simple and quick RAG application using LangChain.rb. Before you can use LangChain.rb for your Ruby project, make sure to install the gem by executing the following command:
gem install langchainrb
In this project, we will use Milvus as the vector database and models from OpenAI as both the LLM and embedding models. To spin up Milvus, we need to install Milvus in Docker and start the container with the following command:
# Download the installation script
curl -sfL https://raw.githubusercontent.com/milvus-io/milvus/master/scripts/standalone_embed.sh -o standalone_embed.sh
# Start the Docker container
bash standalone_embed.sh start
Now that we started the Docker container, let’s instantiate Milvus and the models we’ll use for our RAG application.
require 'langchain'
milvus = Langchain::Vectorsearch::Milvus.new(
url: ENV["MILVUS_URL"],
index_name: "Documents",
llm: Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
)
The first thing we need to do is create a schema inside the Milvus vector database and the corresponding indexing method. Next, we need to load that schema before we can perform a vector search with it.
# Create default schema
milvus.create_default_schema
# Create default index
milvus.create_default_index
# Load default schema
milvus.load_default_schema
Now we’re able to ingest some data into our schema. Let’s say we have a PDF in our local directory containing information on employee benefits. If we want to store all of the texts in this PDF inside of the Milvus database, we can do so by executing the following commands:
pdf = Langchain.root.join("path/to/my.pdf")
# Add PDF inside of Milvus
milvus.add_data(path: pdf)
Once you execute the above commands, LangChain will do all the preprocessing stuff under the hood. It will parse the text inside the PDF file, split it into several chunks, transform each chunk into embeddings, and then store the embeddings inside the Milvus vector database.
After storing our data inside the Milvus vector database, we can start asking questions related to our PDF document. Let’s say that we want to ask, “What’s the company’s vacation policy? How much can I take off?” then we can ask our LLMs in a RAG system by simply executing this one line of code:
response = milvus.ask(question: "What’s the company’s vacation policy? How much can I take off?")
puts response
"""
Response:
=> The company's vacation policy allows employees to take any reasonable amount of time off with pay,
as long as they consult with their manager in advance and get their work done.
"""
And that’s it! In addition to building a general RAG application, we can also build an agentic RAG application with LangChain.rb, which we’ll discuss in the next section.
Utilizing Agents to Interact with Third-Party Tools
The main limitation of many LLMs is their knowledge cutoff date. GPT-4, for example, has a cutoff date of April 2023. This means that if we want to ask about general or factual events after April 2023, we won't get an accurate response from the LLM.
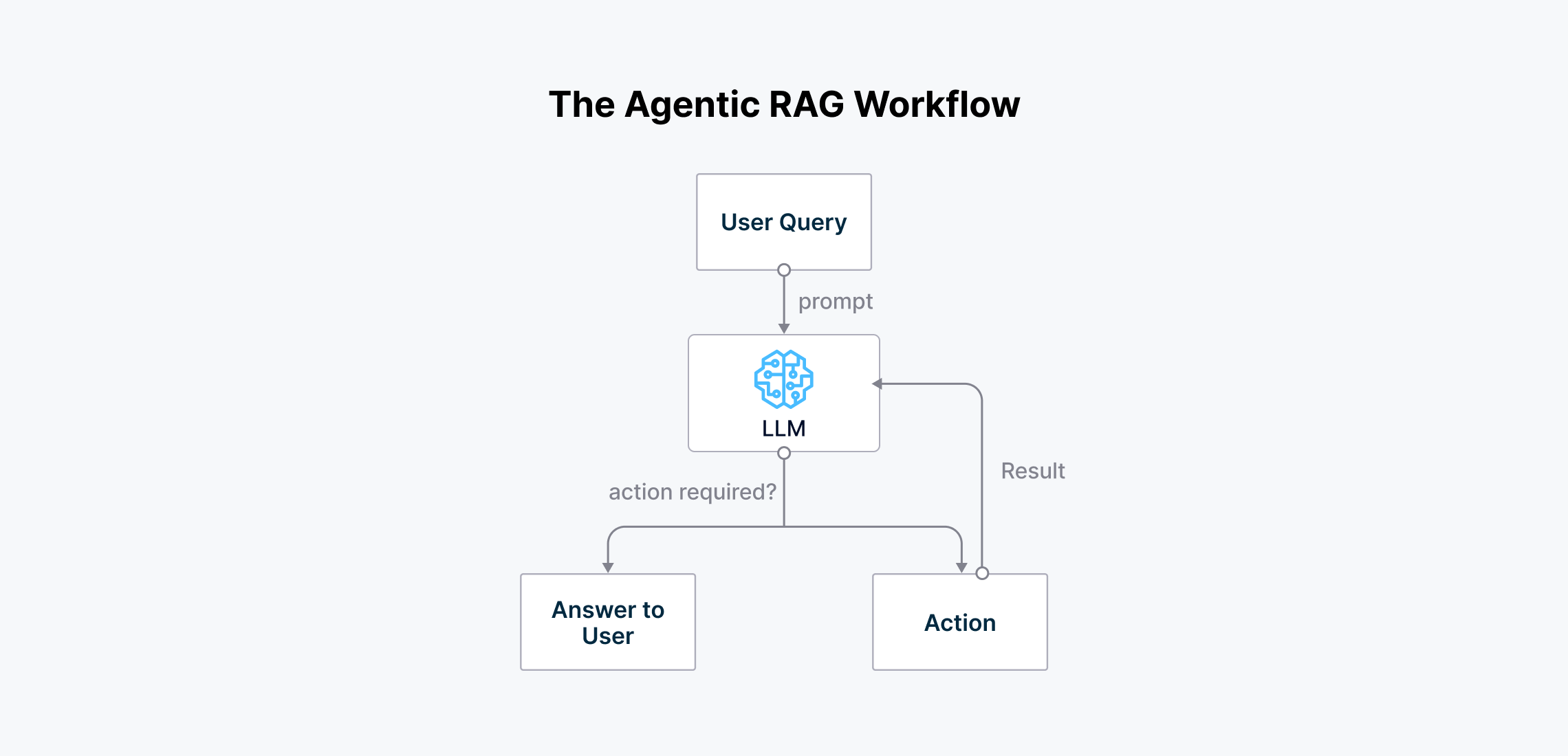
To solve this problem, LangChain.rb enables us to build an agentic RAG application. This type of RAG application adds another intelligence layer, containing an "agent" that acts as a decision-maker. The agent analyzes the user query and then decides on the most effective third-party tools that can provide the most suitable context to answer the query.
Let's say we want to ask our LLM about the current weather in New York. With a general RAG system, the LLM can't know the real-time weather in New York. It will most likely start to hallucinate and give us some random weather predictions.
 The agentic RAG workflow (1).png
The agentic RAG workflow (1).png
Workflow of an agentic RAG
Agentic RAG solves this problem by enabling us to use tools or APIs, such as the OpenWeather API, in the system to get the real-time weather in New York. The agent will first process the user query and then decide on the tools that can provide relevant context to answer the query before synthesizing the context into an accurate answer.
The following demo will use third-party tools inside our RAG system, such as a calculator, the OpenWeather app, and Google Search.
weather = Langchain::Tool::Weather.new(api_key: ENV["OPEN_WEATHER_API_KEY"])
google_search = Langchain::Tool::GoogleSearch.new(api_key: ENV["SERPAPI_API_KEY"])
calculator = Langchain::Tool::Calculator.new
Next, we need to add these three tools inside our RAG system with the following command:
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
agent = Langchain::Agent::ReActAgent.new(
llm: openai,
tools: [weather, google_search, calculator]
)
Now, we can start asking questions to our LLM. Let’s say we want to ask the following question: “Find current weather in Boston, MA, and Washington, D.C., and take an average.”
response = agent.run(question: "Find current weather in Boston, MA and Washington, D.C. and take an average")
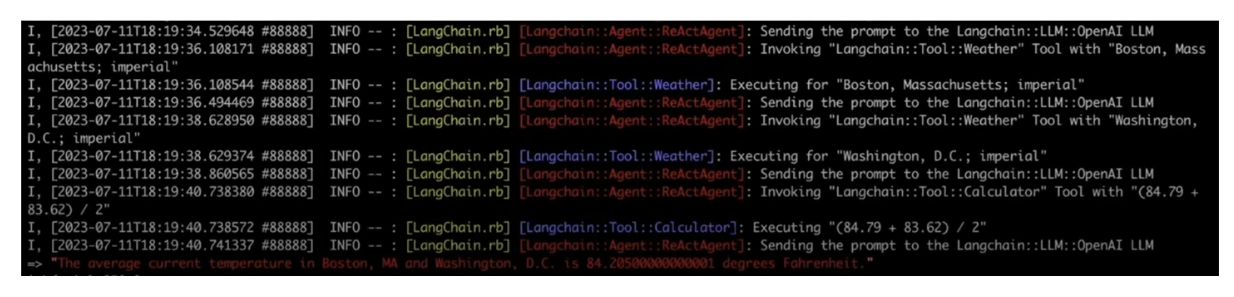 Output of RAG with tools integration
Output of RAG with tools integration
Output of RAG with tools integration
As you can see in the screenshot above, our agentic RAG system was able to answer the query accurately. Let's break down the workflow of this RAG system:
The query was first sent to the OpenAI LLM.
The agent recognized the need to utilize the OpenWeather API to get the current weather in Boston and Washington D.C.
After retrieving the weather data, the agent saw that the query required averaging the weather from the two cities.
The agent then invoked a calculator tool to compute the weather average.
Finally, the LLM synthesized the results into one coherent answer and returned it to the user.
This example demonstrates the power of the agentic RAG approach. By incorporating external tools and APIs, the system overcome the limitations of the LLM's knowledge cutoff date and provided an accurate, up-to-date response to the user's query.
Utilizing Agents to Interact with Internal Database
We can also use agentic RAG to interact with our internal databases. This is very useful because we can ask for insights about our data using human-like language instead of relying on traditional SQL queries.
Let's say we have an online shop and user data stored in a database. Normally, we would need to write SQL queries to extract insights from that data. With agentic RAG, all we need to do is ask the LLM about the insight we want, and the answer will be returned immediately.
For example, let's say we want to know how many user records are stored in the database. We can simply ask: "How many users are there?" and execute the following commands:
require 'langchain'
# Instantiate the database connection
database = Langchain::Tool::Database.new(connection_string: "postgres://localhost:5432/my_database")
# Create OpenAI LLM instance
openai = Langchain::LLM::OpenAI.new(api_key: ENV["OPENAI_API_KEY"])
# Create SQLAgent with the LLM and database connection
agent = Langchain::Agent::SQLAgent.new(
llm: openai,
db: database
)
# Ask a question to the agent
response = agent.run("How many users are there?")
Below is the example output of the command:
 Output of RAG with SQL integration
Output of RAG with SQL integration
Output of RAG with SQL integration
As you can see, our agentic RAG system was able to answer a specific question related to our database data accurately. The workflow of the agent is similar to the previous example:
The query was sent to the OpenAI LLM.
The agent analyzed the query and determined that a database lookup is required to count the number of users.
The LLM generated an appropriate SQL query based on the database table schema.
The SQL query was executed against the database and returned the result.
The database output was sent back to the LLM.
The LLM synthesized the database result into a coherent, human-readable answer and provided it as the final response.
Conclusion
The introduction of LangChain makes LLMs accessible to professionals who may not have deep knowledge of AI and data science theories. We can build a powerful RAG application using LangChain with just a few lines of code.
This accessibility is why Andrei Bondarev introduced LangChain.rb, a LangChain extension for Ruby. This framework enables full-stack developers to incorporate the powerful performance of LLMs into their web applications without needing extensive AI expertise. Additionally, LangChain.rb eliminates the hassle of full-stack developers switching to another programming language when they want to leverage LLMs in their web applications.
Keep Reading

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Zilliz Cloud Delivers Better Performance and Lower Costs with Arm Neoverse-based AWS Graviton
Zilliz Cloud adopts Arm-based AWS Graviton3 CPUs to cut costs, speed up AI vector search, and power billion-scale RAG and semantic search workloads.

How to Build RAG with Milvus, QwQ-32B and Ollama
Hands-on tutorial on how to create a streamlined, powerful RAG pipeline that balances efficiency, accuracy, and scalability using the QwQ-32B and Milvus.