




SuperGLUE: комплексный бенчмарк для расширенной оценки НЛП
SuperGLUE: комплексный бенчмарк для расширенной оценки НЛП
TL; DR
SuperGLUE (Super General Language Understanding Evaluation) - это эталон, предназначенный для оценки производительности моделей понимания естественного языка (NLU). Основываясь на своем предшественнике GLUE, он включает более сложные задачи для оценки способности модели обрабатывать сложные лингвистические рассуждения, такие как ответы на вопросы, разрешение кореференции и умозаключения. SuperGLUE включает в себя разнообразные наборы данных и метрики, а также тестирование таких навыков, как понимание контекста, поиск знаний и многозадачное обучение. Разработанный с целью расширить границы NLU, он отражает задачи, приближенные к человеческому мышлению. Достижение высоких результатов в SuperGLUE свидетельствует о надежности и эффективности модели в решении реальных языковых задач.
Введение
Обработка естественного языка (NLP) изменила способы взаимодействия машин с людьми, от чат-ботов до рекомендательных систем. Такие модели, как ELMo, BERT и GPT , переопределили порог понимания языка, улучшив моделирование и понимание человеческого языка. Эти преобразования проложили путь к эталону GLUE , систематическому средству оценки, которое позволяет оценить компетентность языковых моделей в различных задачах.
Однако по мере того, как модели НЛП становятся все умнее, становится ясно, что мы столкнулись с более сложной задачей. Именно здесь на помощь приходит ****SuperGLUE, который ставит перед собой более сложные цели и предлагает новый набор задач, основанных на рассуждениях, понимании смысла и тонкой контекстной интерпретации. SuperGLUE проверяет способность любой модели решать сложные, реальные языковые проблемы, тем самым подвергая модели НЛП гораздо более суровому испытанию.
В этой статье мы рассмотрим уникальные характеристики SuperGLUE, задачи, которые в него входят, и то, как он стимулирует разработку еще более сложных и надежных моделей НЛП.
Что такое SuperGLUE?
SuperGLUE, сокращение от Super General Language Understanding Evaluation, - это эталон, созданный для проверки того, насколько хорошо модели НЛП справляются с широким спектром сложных задач понимания языка. По сути, это обновленная версия GLUE, призванная поднять планку. Если GLUE ориентирован на более простые задачи, то SuperGLUE включает в себя более сложные задачи, требующие более глубоких рассуждений, понимания смысла и контекста. Например, если в задании GLUE можно оценить, являются ли два предложения семантически похожими, то в задании SuperGLUE, таком как Winograd Schema Challenge (WSC), требуется разрешить двусмысленность местоимений, используя здравый смысл.
SuperGLUE сохраняет две наиболее сложные задачи из GLUE (RTE и WNLI) и вводит шесть совершенно новых задач, призванных вывести модели за рамки простого сопоставления шаблонов и углубить семантические и прагматические знания.
Каковы цели SuperGLUE?
Тестирование продвинутого мышления: SuperGLUE выходит за рамки базовой обработки языка - он призван проверить, могут ли модели рассуждать, делать умозаключения и использовать знания на уровне здравого смысла в сложных сценариях.
Поощрение прогресса в области НЛП: Вводя более сложные задачи, SuperGLUE мотивирует исследователей к разработке более продвинутых и способных методов машинного обучения.
Создание всестороннего эталона: В отличие от GLUE, который фокусируется на более простых задачах, SuperGLUE предоставляет более реалистичный и всеобъемлющий способ проверить, как модели работают со сложными, реальными исходными данными.
Установка более высокой планки для НЛП: SuperGLUE был создан с прицелом на будущее - он достаточно сложен, чтобы даже лучшие современные модели имели возможность совершенствоваться, что делает его ценным инструментом для отслеживания прогресса в НЛП.
Как работает SuperGLUE
SuperGLUE оценивает модели НЛП, бросая вызов их лингвистическим навыкам. Эти задачи требуют от моделей не просто классифицировать предложения или предсказывать отдельные слова - они должны решать сложные задачи реального мира. Сюда входит разрешение кореференции (определение того, какие слова или фразы относятся к одному и тому же предмету), рассуждение (получение логических выводов из текста) и понимание отношений между сущностями в контексте. Каждая задача позволяет оценить, насколько хорошо модели справляются с тонкостями и сложными требованиями человеческого языка.
Подробный обзор задач
SuperGLUE - это супернабор из множества задач, которые мы рассмотрим в этом разделе. Перед этим мы рассмотрим различные метрики оценки, необходимые для определения производительности модели.
Метрики оценки
SuperGLUE использует несколько метрик оценки в зависимости от задачи:
Exact Match (EM): Используется для задач, в которых необходимо оценить, точно ли предсказанный ответ совпадает с ожидаемым.
F1 Score: Измеряет точность и отзыв, когда возможно несколько правильных ответов.
Точность: Доля правильно предсказанных примеров, используемая в более простых задачах классификации, таких как BoolQ.
Macro-Averaged F1: Среднее значение оценок F1 по классам, обеспечивающее сбалансированную оценку даже при дисбалансе классов.
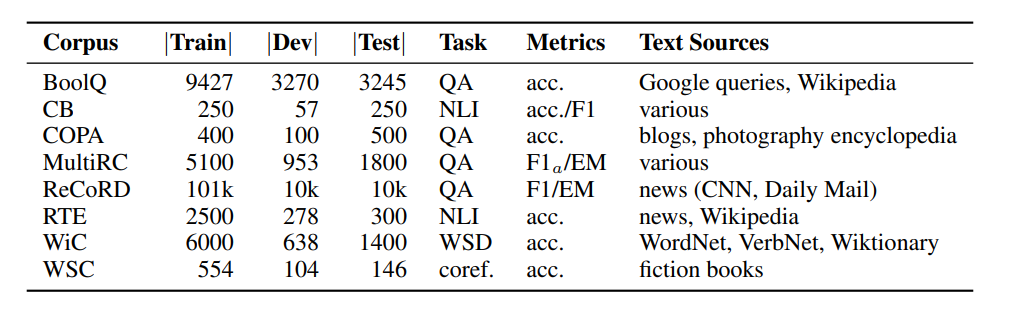 Рисунок- SuperGLUE Benchmark- Сводная таблица задач SuperGLUE, включая размеры корпуса, метрики и источники текстов для каждой задачи..png
Рисунок- SuperGLUE Benchmark- Сводная таблица задач SuperGLUE, включая размеры корпуса, метрики и источники текстов для каждой задачи..png
Рисунок: SuperGLUE Benchmark: Сводная таблица задач SuperGLUE, включая размеры корпусов, метрики и источники текстов для каждой задачи.
Давайте изучим подробный обзор задач SuperGLUE, чтобы понять глубину и разнообразие его проблем.
- BoolQ (булевы вопросы).
BoolQ - это задача с бинарными вопросами-ответами, в которой модель определяет, является ли вопрос "да/нет" истинным на основе заданного отрывка. Здесь приведены входные данные, выходные данные и метрика задачи:
| Input | Output | Metric |
|---|---|---|
| Отрывок и вопрос "да/нет" по этому отрывку. | Булево значение (True - да, False - нет). | Точность |
Вот пример:
Пассаж: "Barq's - это безалкогольный напиток, который содержит кофеин и разливается в бутылки компанией Coca-Cola".
Вопрос: "Содержит ли корневое пиво Barq's кофеин?"
Вывод: True
- CB (CommitmentBank).
CB предполагает оценку того, является ли встроенное в текст положение, скорее всего, истинным (эвентуальным), ложным (противоречивым) или неопределенным (нейтральным).
| Вход | Выход | Метрика | Метрика. | --------------------------- | ------------------------------------------------ | ------------------------------- | | Посылка и гипотеза. | Метка (эвентуальная, нейтральная или противоречивая). | Точность и макросреднее F1. |
Вот пример:
Premise: "Она сказала, что может прийти на встречу".
Гипотеза: "Она обязательно придет на встречу".
Вывод: Противоречие
- COPA (Выбор правдоподобных альтернатив).
COPA - это задача причинно-следственных рассуждений, в которой модель определяет наиболее правдоподобную причину или следствие данной посылки из двух альтернатив.
| Вход | Выход | Метрика | Метрика. | ---------------------------------------------- | ---------------------------------------- | ---------- | | Предпосылка и две альтернативы (причина/следствие). | Более правдоподобная альтернатива (1 или 2). | Точность |
Давайте рассмотрим пример:
Премьера: "Трава мокрая".
Альтернатива 1: "Прошлой ночью шел дождь".
Альтернатива 2: "Ярко светило солнце".
Вывод: 1
- MultiRC (многосюжетное понимание прочитанного).
MultiRC предполагает ответы на вопросы, основанные на отрывке, где на каждый вопрос может быть несколько правильных ответов.
| Input | Output | Metric | Metric. | ----------------------------------------------------- | ----------------------------------------------- | ------------------- | | Отрывок, вопрос и набор возможных ответов. | Бинарная метка (True или False) для каждого ответа. | F1 и точное совпадение. |
Вот простой пример:
Пассаж: "Сьюзан пригласила своих друзей на вечеринку. Один из ее друзей заболел, но позже пришел".
Вопрос: "Посетил ли больной друг вечеринку?"
Ответы: "Да", "Нет".
Вывод: Да
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset).
ReCoRD - это задание на понимание прочитанного в стиле Клозе, требующее рассуждений на основе здравого смысла для предсказания замаскированных сущностей в отрывке.
| Input | Output | Metric | Metric. | ------------------------------------------- | --------------------------------------------- | ---------- | | Отрывок с замаскированными сущностями и запрос. | Правильная сущность из списка кандидатов. | F1 и EM. |
Вот простой пример:
Пассаж: "Компания Tesla была основана <маской>".
Запрос: "Кто основал компанию Tesla?"
Кандидаты: "Элон Маск", "Никола Тесла", "Томас Эдисон".
Вывод: Элон Маск
- RTE (Recognizing Textual Entailment).
RTE определяет, является ли гипотеза истинной, ложной или неопределенной на основе заданной посылки.
| Input | Output | Metric | Metric. | --------------------------- | ------------------------------------------------ | ---------- | | Посылка и гипотеза. | Метка (следствие, нейтральность или противоречие). | Точность |
Вот пример:
Премьера: "Дана Рив, вдова Кристофера Рива, скончалась в 44 года".
Гипотеза: "Дане Рив было 44 года, когда она умерла".
Вывод: Entailment
- WiC (Word-in-Context).
WiC проверяет расстановку смыслов слов, определяя, используется ли слово с одним и тем же значением в двух разных контекстах.
| Input | Output | Metric | Metric. | ---------------------------------------------- | ---------------------------------------------------------------- | ---------- | | Два предложения, содержащие одно и то же целевое слово. | Бинарная метка (True - одинаковый смысл, False - разный смысл). | Точность |
Рассмотрим пример:
Предложение 1: "Он прибил доски к стене".
Предложение 2: "Шахматная доска была прекрасно сделана".
Целевое слово: "доска"
Вывод: False
- WSC (Winograd Schema Challenge).
WSC - это задача на разрешение кореференции, в которой модель определяет правильный референт неоднозначного местоимения с помощью рассуждений.
| Input | Output | Metric | Metric. | ------------------------------------------- | --------------------- | ---------- | | Предложение, содержащее неопределенное местоимение. | Правильный референт. | Точность |
Вот пример:
Предложение: "Марк подарил Теду книгу, но она ему не понравилась".
Прононс: "он"
Вывод: Тед
Приведенные выше задачи в SuperGLUE ставят перед моделями НЛП задачи, выходящие за рамки простого понимания языка, для которых любая система должна строить тонкие рассуждения и решать проблемы реального мира. Таким образом, SuperGLUE оценивает модель на основе понимания, рассуждения и эффективного применения знаний здравого смысла. Он предоставляет комплексную систему оценки, которая позволяет оценить точность и запоминаемость моделей при решении различных задач понимания языка.
Пример реализации
Ниже приведен пример загрузки и взаимодействия с SuperGLUE-задачей ReCoRD с использованием библиотеки Hugging Face:
from datasets import load_dataset
# Загружаем задачу ReCoRD из SuperGLUE
dataset = load_dataset("super_glue", "record", trust_remote_code = True
)
# Доступ к обучающим данным
train_data = dataset['train']
# Пример точки данных
example = train_data[0]
print(f "Проход: {example['passage']}")
print(f "Запрос с замаскированной сущностью: {example['query']}")
Функция load_dataset загружает задачу ReCoRD. На вход подается отрывок и запрос с маскированной сущностью, которую необходимо разрешить. Модель стремится правильно предсказать маскируемую сущность, демонстрируя свою способность понимать отрывок и применять логические рассуждения.
 Figure- Output of Implemented Example.png
Figure- Output of Implemented Example.png
Рисунок: Выходные данные реализованного примера
SuperGLUE против GLUE: основные различия
SuperGLUE улучшает GLUE, вводя значительно более сложные задания, отражающие реальное понимание языка.
| Особенности | GLUE | SuperGLUE |
|---|---|---|
| Сложность задач | Базовые лингвистические задачи (например, анализ настроения) | Сложные задачи, требующие рассуждений и здравого смысла |
| Насыщенность набора данных | Производительность близка к человеческому уровню | Большой резерв для улучшения модели |
| Требования к рассуждениям | Требуются минимальные рассуждения | Необходимы высокоуровневые рассуждения и умозаключения |
| Разнообразие задач | В основном классификация предложений и задачи сходства | Включает QA, кореференцию и понимание прочитанного |
| Применение в реальном мире | Ограниченное отражение реального мира | Задания, разработанные для имитации реальных языковых проблем |
Преимущества и проблемы SuperGLUE
SuperGLUE заменяет собой способы оценки моделей НЛП, перенося акцент на их способность решать реальные задачи, требующие осмысления и расширенного контекста. Давайте обсудим некоторые конкретные преимущества, которые SuperGLUE дает НЛП, и проблемы, с которыми сталкиваются исследователи при его использовании в полной мере.
Преимущества
Тесты на рассуждения и здравый смысл: SuperGLUE включает задания, требующие от моделей использования здравого смысла. Например, Winograd Schema Challenge (WSC) проверяет разрешение местоимений с помощью здравого смысла, а задача COPA оценивает причинно-следственные рассуждения, выбирая наиболее правдоподобную причину или следствие в заданном сценарии. Эти задания помогают учащимся лучше ориентироваться в реальных сценариях.
Устранение недостатков GLUE:** Включая более сложные задачи, SuperGLUE преодолевает перенасыщенность GLUE, когда модели достигали производительности, близкой к человеческой, при выполнении более простых задач, что делало его менее эффективным для выявления достижений.
Повышает объяснимость моделей: Сложные задачи SuperGLUE стимулируют разработку моделей, которые хорошо работают и дают более интерпретируемые результаты, помогая исследователям понять, как и почему модели делают конкретные предсказания.
Отражает проблемы реального мира: Задачи SuperGLUE разработаны таким образом, чтобы отражать проблемы, с которыми сталкиваются модели в таких приложениях, как понимание прочитанного и диалоговые системы. Например, задача ReCoRD проверяет разумные рассуждения для вывода недостающей информации, а WSC оценивает разрешение двусмысленных местоимений - ключевые возможности для виртуальных помощников и разговорного ИИ.
Предоставляет глубокий анализ ошибок: SuperGLUE позволяет исследователям изучить, как и где модели терпят неудачу, предоставляя разнообразные и сложные задачи, подчеркивающие конкретные слабые места. Такой подробный анализ ошибок помогает выявить области, в которых модели испытывают трудности, такие как рассуждения, понимание смысла или контекстуальное восприятие, что позволяет целенаправленно улучшать модели, делая их более надежными и прочными.
Задачи
Высокие вычислительные затраты: Обучение моделей на SuperGLUE может быть вычислительно дорогостоящим из-за сложности задач. Использование оптимизированных архитектур и облачной инфраструктуры поможет эффективно управлять потребностями в ресурсах.
Сложная тонкая настройка: Для каждой задачи в SuperGLUE могут потребоваться различные стратегии тонкой настройки. Подходы многозадачного обучения и трансферного обучения могут помочь упростить этот процесс. Многозадачное обучение тренирует модель на смежных задачах для улучшения обобщения, а трансферное обучение применяет знания из одной задачи для повышения эффективности другой, сводя к минимуму необходимость в обширных данных и обучении.
Малые размеры наборов данных: Некоторые задачи SuperGLUE поставляются с ограниченным количеством данных, что повышает риск переоценки моделей в процессе обучения. Эту проблему можно решить с помощью таких методов, как увеличение объема данных для создания более разнообразных обучающих выборок и регуляризация для улучшения обобщения модели.
Чрезмерный акцент на таблицах лидеров: Хотя рейтинги в таблицах лидеров демонстрируют производительность моделей, фокусировка только на этих показателях может отвлечь от практической ценности моделей. Переключение внимания на реальные приложения помогает убедиться в том, что модели конкурентоспособны и эффективны в практических сценариях.
Трудности сравнения результатов: Различия в реализациях, аппаратных средствах и гиперпараметрах могут затруднить справедливое сравнение результатов разных исследовательских групп. Стандартизация протоколов оценки, обмен кодовыми базами и использование общих эталонов позволят нам добиться более последовательных и справедливых сравнений.
Примеры использования SuperGLUE
SuperGLUE - это важный бенчмарк, который помогает улучшить NLP, ставя перед моделями задачи, основанные на сложностях реального мира. Примеры такого использования могут быть самыми разнообразными: от улучшения разговорного ИИ и систем рассуждений до семантического поиска.
SuperGLUE имеет множество применений в НЛП и за его пределами:
Разговорный ИИ: SuperGLUE способствует развитию виртуальных помощников, предоставляя эталоны, которые проверяют способность моделей понимать тонкие запросы с помощью более точных рассуждений и здравого смысла.
Advanced Reasoning Systems: SuperGLUE способствует созданию инструментов поддержки принятия решений, оценивая и улучшая возможности моделей по логическим выводам.
Понимание прочитанного: SuperGLUE позволяет моделям NLP точно анализировать и обобщать объемные документы, ставя перед ними задачи, требующие глубокого понимания и контекстуального осмысления, что помогает в научных исследованиях и образовании.
Представление и вывод знаний:** SuperGLUE помогает создавать более надежные графы знаний, проверяя способность моделей понимать взаимосвязи и применять здравые рассуждения, что помогает поисковым системам и рекомендательным системам.
Семантический поиск и векторные базы данных:** SuperGLUE повышает точность семантического поиска, позволяя моделям эффективно справляться со сложными крупномасштабными задачами поиска информации.
Инструменты, поддерживающие SuperGLUE
Расширенные задачи и контрольные показатели SuperGLUE привели к разработке других инструментов и платформ, призванных облегчить его внедрение и оценку. Эти инструменты помогают исследователям и разработчикам принимать лучшие решения по доступу к данным, обучению моделей и анализу результатов.
Давайте рассмотрим инструменты, которые поддерживают и улучшают внедрение и взаимодействие с SuperGLUE.
Инструменты
Hugging Face Datasets: Обеспечивает простой способ загрузки и взаимодействия с задачами SuperGLUE, оптимизируя разработку и тестирование моделей.
TensorFlow Datasets: Предлагает предварительно отформатированные версии задач SuperGLUE, хорошо интегрирующиеся с моделями на основе TensorFlow.
AllenNLP: Поставляет модули и компоненты для задач NLP, упрощая эксперименты с SuperGLUE.
Оценка моделей ИИ с помощью SuperGLUE и их улучшение с помощью RAG
Бенчмарки, подобные SuperGLUE, необходимы для оценки возможностей больших языковых моделей (LLMs). Они обеспечивают стандартизированную структуру для измерения производительности модели в различных задачах и облегчают прямое сравнение между моделями. Выделяя сильные стороны, такие как рассуждения, и раскрывая слабые стороны, такие как трудности со сложными рассуждениями или специфическими задачами домена, SuperGLUE помогает исследователям определить области для улучшения. Эти знания позволяют проводить тонкую настройку, улучшая понимание модели и ее способность генерировать контент.
Однако, несмотря на то, что SuperGLUE полезен для улучшения LLM, он не является панацеей. LLM имеют присущие им ограничения, независимо от того, насколько хорошо они работают в бенчмарках. Они обучаются на статичных, автономных наборах данных и не имеют доступа к информации в реальном времени или специфической для конкретной области. Это может привести к галлюцинациям, когда модели генерируют неточные или сфабрикованные ответы. Эти недостатки становятся еще более проблематичными при работе с собственными или узкоспециализированными запросами.
Представляем RAG: решение для улучшения ответов на LLM
Чтобы решить эти проблемы, Retrieval-Augmented Generation (RAG) предлагает мощное решение. RAG улучшает большие языковые модели (LLM), объединяя их генеративные возможности со способностью извлекать специфическую информацию из внешних баз знаний, хранящихся в векторных базах данных, таких как Milvus или Zilliz Cloud. Когда пользователь задает вопрос, система RAG ищет в базе данных соответствующую информацию и использует ее для генерации более точного ответа. Давайте рассмотрим, как работает процесс RAG.
 Рисунок - Рабочий процесс RAG.png
Рисунок - Рабочий процесс RAG.png
Система RAG обычно состоит из трех ключевых компонентов: модель встраивания, база данных векторов и LLM.
Модель встраивания преобразует документы в векторные вкрапления, которые хранятся в векторной базе данных типа Milvus.
Когда пользователь задает вопрос, система преобразует запрос в вектор, используя ту же модель встраивания.
Затем в базе данных векторов выполняется поиск по сходству для извлечения наиболее релевантной информации. Эта полученная информация объединяется с исходным вопросом, образуя "вопрос с контекстом", который затем отправляется в LLM.
LLM обрабатывает этот обогащенный входной сигнал, чтобы сгенерировать более точный и контекстуально релевантный ответ.
Этот подход позволяет преодолеть разрыв между статичными LLM и специфическими потребностями домена в режиме реального времени.
Часто задаваемые вопросы о SuperGLUE
**Что делает SuperGLUE сложнее GLUE? ** SuperGLUE развивает GLUE, вводя задачи на рассуждение и логику, которые выходят далеко за рамки задач, встречающихся в GLUE.
**Какие модели лучше всего справляются с SuperGLUE? ** Модели на основе трансформаторов превосходят SuperGLUE благодаря механизму самовнимания, который улавливает контекст и дальние зависимости, обширному предварительному обучению на больших наборах данных, масштабируемости и адаптивности за счет трансферного обучения.
Каковы вычислительные требования для SuperGLUE? Обучение моделей на SuperGLUE требует значительных вычислительных ресурсов из-за сложности задач, которые требуют большой вычислительной мощности для тонкой настройки, рассуждений и эффективной работы с большими наборами данных.
**Может ли SuperGLUE применяться для решения специфических задач? ** Несмотря на то, что SuperGLUE ориентирован на обобщение, его адаптация к конкретным областям возможна при дополнительной тонкой настройке с использованием данных, специфичных для конкретной области.
Как SuperGLUE применим в современных приложениях ИИ? Он устанавливает стандарт для оценки моделей в реальных приложениях, таких как семантический поиск и разговорный ИИ.
Связанные ресурсы
- TL; DR
- Введение
- Что такое SuperGLUE?
- Как работает SuperGLUE
- SuperGLUE против GLUE: основные различия
- Преимущества и проблемы SuperGLUE
- Примеры использования SuperGLUE
- Инструменты, поддерживающие SuperGLUE
- Оценка моделей ИИ с помощью SuperGLUE и их улучшение с помощью RAG
- Часто задаваемые вопросы о SuperGLUE
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно