




Observability: Отслеживание за пределами мониторинга
Observability: Отслеживание за пределами мониторинга
Что такое наблюдаемость?
Наблюдаемость означает понимание того, что происходит внутри системы, на основе данных, которые она производит. Считайте, что это возможность "заглянуть внутрь" программной системы и понять ее состояние и поведение. Это помогает ответить на такие вопросы, как "Все ли работает так, как ожидалось?" или "Почему что-то идет не так?". Вместо того чтобы гадать, в чем причина проблем, наблюдаемость позволяет получить четкие сведения с помощью таких данных, как журналы, метрики и трассировки.
Почему наблюдаемость важна?
Современные программные системы становятся все более сложными. С развитием таких технологий, как микросервисы, облачные вычисления и контейнеризация, системы теперь состоят из множества взаимосвязанных частей, которые могут быть разбросаны по разным местам. Это затрудняет их мониторинг и устранение неполадок.
Традиционные инструменты мониторинга часто не справляются с этой задачей - они могут сказать вам, что что-то не так, но не сказать почему. Observability восполняет этот пробел, обеспечивая видимость внутреннего состояния систем для быстрого выявления проблем.
Основные принципы Observability
Observability имеет три основных компонента, которые работают вместе, чтобы дать четкое представление о том, что происходит внутри системы. Давайте разберем их:
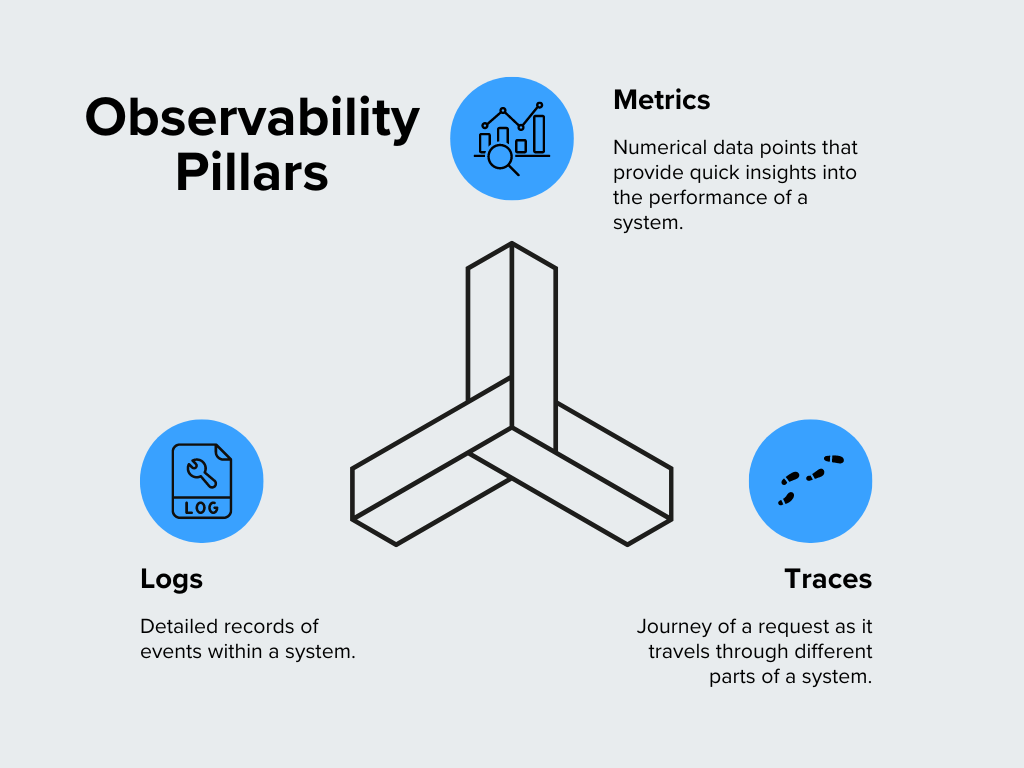 Рисунок- Столпы наблюдаемости.png
Рисунок- Столпы наблюдаемости.png
Рисунок: Столпы наблюдаемости
Метрики
Метрики - это числовые данные, позволяющие быстро получить представление о производительности системы. Это жизненно важные признаки вашей системы, которые показывают, как она функционирует. К общим метрикам относятся использование процессора, потребление памяти, частота запросов и время отклика. Например, если вы заметили необычный всплеск использования ЦП, это может указывать на проблему, требующую внимания. Метрики отлично подходят для выявления тенденций и наблюдения за тем, как система ведет себя с течением времени.
Журналы
Журналы - это подробные записи событий в системе. Думайте о них как о дневнике, в котором фиксируется то, что происходит внутри вашего программного обеспечения. Каждый раз, когда возникает ошибка, пользователь входит в систему или обрабатывается транзакция, это обычно записывается в журнал. Журналы обеспечивают контекст для диагностики проблем и понимания поведения системы. Например, когда что-то идет не так, журналы могут помочь определить, что происходило до и после возникновения проблемы.
Следы
** Трассировка позволяет проследить путь запроса через различные части системы.** В сложной системе с несколькими службами, работающими вместе, трассировка показывает путь, пройденный одним запросом, и время, которое он проводит в каждой службе. Трассировка позволяет выявить узкие места или задержки в процессе. Если вы обнаружите, что запрос выполняется дольше, чем ожидалось, трассировка поможет вам определить, где происходит замедление.
Как работает наблюдаемость?
Наблюдаемость состоит из нескольких важных шагов. Вот как это работает:
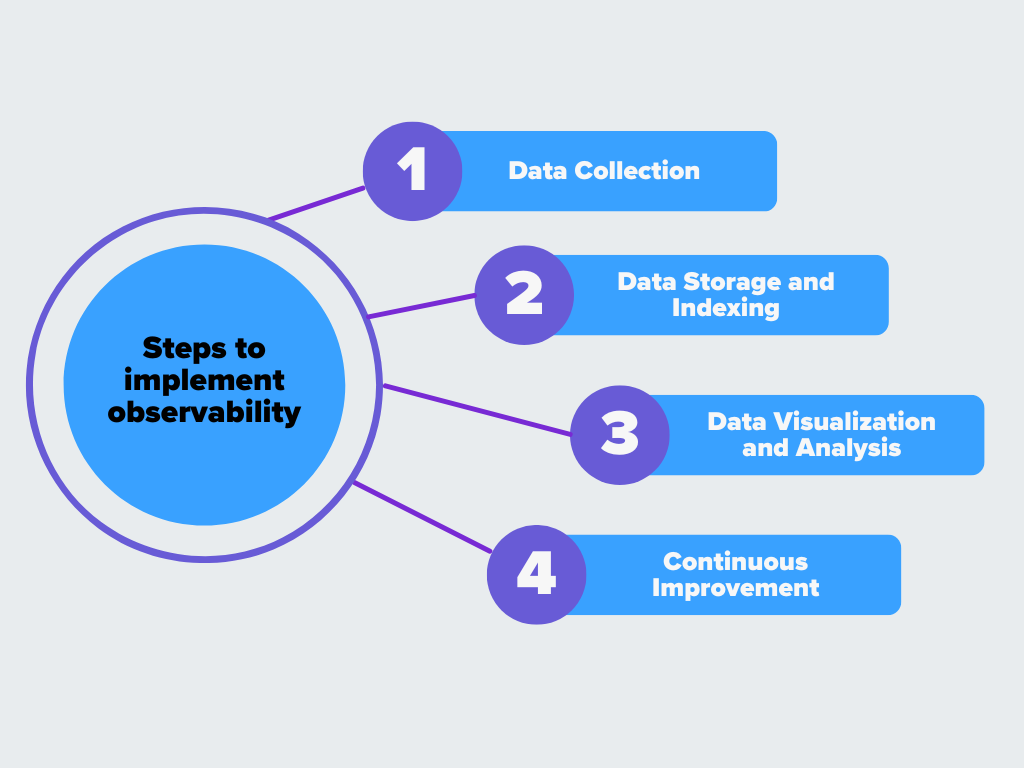 Рисунок - Шаги реализации наблюдаемости.png
Рисунок - Шаги реализации наблюдаемости.png
Рисунок: Шаги по реализации наблюдаемости
Сбор данных
Первый шаг - сбор данных из всех частей системы. Это включает в себя сбор метрик (таких как
использование процессора), логи (подробные записи событий) и трассы (путь запросов через службы). Цель - собрать все, что может дать представление о производительности, проблемах или общем поведении системы. Эти данные поступают из различных источников, таких как серверы, приложения, базы данных и взаимодействие с пользователями.
Хранение и индексирование данных
После того как данные собраны, их необходимо эффективно хранить. Правильное хранение означает, что вы сможете быстро найти и использовать данные в случае необходимости. Индексирование данных помогает быстрее находить и извлекать конкретные фрагменты информации. Например, при возникновении проблемы инженеры должны иметь возможность легко и без задержек найти журналы или метрики, связанные с этим инцидентом. Правильные методы хранения данных имеют решающее значение для обеспечения их упорядоченности и доступности.
Визуализация и анализ данных
Сбор данных - это одно, а их осмысление - совсем другое. Здесь важную роль играют инструменты визуализации и информационные панели. Они превращают необработанные данные в удобные для восприятия графики, диаграммы и оповещения. Визуализация помогает командам быстро увидеть тенденции, закономерности или любое необычное поведение системы. Приборные панели позволяют легко заметить проблемы с производительностью и углубиться в детали, если что-то кажется не так. Системы оповещения также могут уведомлять команды в режиме реального времени, когда показатели пересекают определенные пороги или возникают ошибки.
Непрерывное совершенствование
Данные, полученные в результате наблюдения, нужны не только для устранения проблем, но и для улучшения системы. Регулярно анализируя собранные данные, команды могут выявить области, которые нуждаются в улучшении или оптимизации. Непрерывный цикл обратной связи включает в себя усовершенствования, чтобы система работала более эффективно. Данные о наблюдаемости могут служить основой для принятия решений о масштабировании ресурсов, что улучшает пользовательский опыт и предотвращает будущие проблемы.
Примеры использования Observability
Наблюдаемость оказывает сильное влияние на реальные приложения. Вот несколько практических примеров использования, которые показывают, как наблюдаемость меняет ситуацию:
Мониторинг производительности в распределенных системах
Проблемы с производительностью может быть сложно выявить в распределенной системе с множеством сервисов, работающих вместе. Observability помогает, предоставляя метрики, журналы и трассировки, которые дают четкое представление о взаимодействии различных сервисов. Например, если один микросервис замедляет работу всего приложения, инструменты наблюдаемости могут быстро определить, какой сервис вызывает задержку.
Отладка и устранение неисправностей
Когда система ломается, команды выясняют, что пошло не так. Observability значительно облегчает этот процесс, предоставляя подробные журналы и следы событий. Например, если сервер падает или запрос не выполняется, журналы могут показать, что именно происходило непосредственно перед сбоем. Трассировка помогает командам увидеть, как проблема распространяется по различным сервисам.
Надежность и доступность
Наблюдаемость играет большую роль в достижении целей уровня обслуживания (SLO) и соглашений об уровне обслуживания (SLA). Это обязательства по надежности и доступности системы. Отслеживая состояние системы с помощью метрик и оповещений, команды могут достичь этих целей. Например, если время отклика начинает замедляться, наблюдаемость помогает командам принять меры до того, как пострадают пользователи, поддерживая надежность сервиса.
Планирование и масштабирование мощностей
По мере роста систем им требуется больше ресурсов, таких как серверы или память. Наблюдаемость помогает в планировании мощностей, отслеживая метрики, которые показывают, как используется система. Например, мониторинг использования процессора или загрузки базы данных с течением времени может помочь предсказать, когда потребуется увеличение мощности. При планировании и масштабировании мощностей система работает хорошо и без сюрпризов.
Проактивное обнаружение проблем
Одно из лучших применений наблюдаемости - выявление проблем до того, как они станут серьезными. Мониторинг и оповещение в режиме реального времени позволяют командам обнаружить необычные закономерности или всплески, например, увеличение количества ошибок или времени отклика. Проактивный подход позволяет предотвратить простои и обеспечить бесперебойную работу пользователей. Например, если инструменты наблюдаемости обнаружат утечку памяти на ранней стадии, команды смогут устранить ее до того, как произойдет сбой в системе.
Мониторинг пользовательского опыта
Наблюдаемость - это не только бэкенд; она также может отслеживать взаимодействие и поведение пользователей. Мониторинг таких показателей, как время загрузки страниц, время отклика кнопок и сообщений об ошибках, помогает командам быстро выявлять и устранять проблемы, с которыми сталкиваются пользователи. Например, если новая функция привела к замедлению загрузки страниц, данные наблюдаемости сразу же покажут это.
Оптимизация затрат в облачных средах
В облачных средах часто используется система оплаты по факту использования, то есть вы платите за ресурсы, которые используете. Наблюдаемость может помочь командам оптимизировать расходы, отслеживая, какие части системы используют больше всего ресурсов. Например, если определенный микросервис потребляет большое количество пропускной способности, инструменты наблюдаемости могут точно определить это, что позволит команде оптимизировать или рефакторизовать сервис для снижения затрат.
Инструменты и технологии для наблюдаемости
Prometheus - это инструмент мониторинга с открытым исходным кодом, который собирает и хранит метрики в виде временных рядов данных. Он широко используется для мониторинга производительности систем и приложений благодаря гибким возможностям запросов.
Grafana - инструмент визуализации, часто используемый в паре с Prometheus. Он создает интерактивные панели, которые помогают визуализировать метрики Prometheus, легко интерпретировать данные, отслеживать тенденции и настраивать оповещения о поведении системы.
Jaeger - это инструмент распределенной трассировки, который помогает отслеживать запросы по мере их прохождения через микросервисы. Он также помогает отслеживать задержки и выявлять узкие места в сложных распределенных системах.
AWS CloudWatch - это инструмент мониторинга и наблюдения Amazon, который отслеживает метрики, собирает журналы и предоставляет оповещения для облачных ресурсов AWS. Он хорошо интегрируется с другими службами AWS для мониторинга и управления вашей инфраструктурой.
Google Cloud Monitoring обеспечивает видимость приложений и служб, работающих в облаке Google. Он предлагает метрики, информационные панели и оповещения для мониторинга состояния и производительности облачных ресурсов.
Azure Monitor - это инструмент, обеспечивающий полную видимость облачных ресурсов и приложений Azure. Он собирает метрики, журналы и трассировки, чтобы помочь командам анализировать производительность и быстро устранять проблемы.
Современные инструменты наблюдаемости используют искусственный интеллект и машинное обучение для обнаружения аномалий и прогнозирования будущих проблем. Эти передовые инструменты могут автоматически выявлять закономерности и предупреждать команды о необычном поведении.
Проблемы наблюдаемости
Масштабируемость и объем данных
Сбор, хранение и обработка большого количества метрик, журналов и трасс может стать сложной задачей в растущей системе. Эффективное управление данными и масштабируемые решения для хранения данных являются ключевыми для решения этой проблемы.
Перегрузка данных
Слишком большой объем данных может перегрузить команды и затруднить поиск полезных сведений. Чтобы избежать шума, важно фильтровать и фокусироваться на действенных данных, которые непосредственно помогают диагностировать и решать проблемы, а не отслеживать каждую мелкую деталь.
Интеграция между службами
Современные системы часто используют множество инструментов и компонентов. Для обеспечения бесперебойной наблюдаемости различных сервисов необходима правильная интеграция. Без нее критически важная информация может быть упущена, а время на переходы между инструментами может быть потрачено впустую.
Лучшие практики наблюдаемости
Чтобы максимально использовать преимущества наблюдаемости, обязательно следуйте лучшим практикам, таким как:
Построение с учетом наблюдаемости
С самого начала проектируйте системы так, чтобы их можно было легко наблюдать. Встраивайте в архитектуру метрики, журналы и трассировки, чтобы облегчить отслеживание и понимание поведения системы. Такой проактивный подход упрощает устранение неисправностей и настройку производительности в будущем.
Единый взгляд на все системы
Консолидируйте все данные о наблюдаемости на одной платформе или приборной панели. Единое представление помогает командам быстро выявлять проблемы и получать целостное представление о взаимодействии различных служб, сокращая время на сбор информации из нескольких источников.
Стратегии оповещения и уведомления
Настройте четкие, осмысленные и действенные оповещения. Чтобы избежать усталости от оповещений, выбирайте только критические события, связанные с конкретными необходимыми действиями. Цель - эффективно информировать команду, а не перегружать ее шумом.
Наблюдаемость против мониторинга
Несмотря на то что их часто упоминают вместе, наблюдаемость и мониторинг - это не одно и то же. В таблице ниже приведены основные различия между ними:
| Обзор | Наблюдаемость | Мониторинг | |
|---|---|---|---|
| Назначение | Обеспечивает более глубокое понимание внутреннего состояния системы. | Отслеживает определенные показатели для обнаружения проблем или аномалий. | |
| Собираемые данные | Сбор метрик, журналов и трасс для детального анализа. | Собирает предопределенные метрики, такие как использование ЦП, память и ошибки. | |
| Подход | Исследовательский; помогает понять, "почему" возникла проблема. | Реактивный; уведомляет о возникновении известной проблемы. | |
| Сфера применения | Фокусируется на общем поведении системы и производительности. | Фокусируется на отдельных метриках для оценки состояния системы. | |
| Решение проблем | Помогает быстро выявить неизвестные проблемы и основные причины. | Предупреждает об известных проблемах, но для более глубокого анализа может не хватать контекста. | |
| Анализ в реальном времени | Поддерживает анализ данных в реальном времени для отслеживания поведения системы в реальном времени. | Полагается на заранее установленные проверки и пороговые значения, часто с отложенным контекстом. | |
| Гибкость данных | Позволяет гибко и глубоко исследовать данные, выходящие за рамки заранее определенных показателей. | Мониторинг конкретных, предварительно выбранных показателей без более широкого контекста. |
Различия между наблюдаемостью и мониторингом
Наблюдаемость в Milvus и Zilliz Cloud: Отслеживание производительности векторной базы данных
Milvus - это векторная база данных с открытым исходным кодом, разработанная для эффективной работы с миллиардными объемами неструктурированных данных. Она идеально подходит для семантического поиска, поиска по сходству и GenAI приложений. Наблюдаемость играет важную роль в управлении и оптимизации производительности Milvus. Используя практику наблюдаемости, вы можете обеспечить бесперебойную и эффективную работу вашей векторной базы данных, будь то рекомендации в реальном времени или задачи retrieval-augmented generation (RAG) .
В Milvus с открытым исходным кодом интегрирован Prometheus для мониторинга производительности и Grafana для визуализации всех метрик. Milvus легко интегрируется с Prometheus через:
Prometheus Endpoint: Собирает данные из различных экспортеров.
Prometheus Operator: Упрощает управление настройками мониторинга Prometheus.
Kube-Prometheus: Упрощает полный мониторинг кластера Kubernetes для обеспечения надежной работы.
С помощью Prometheus вы можете отслеживать такие важные показатели производительности Milvus, как время отклика на запросы и использование ресурсов (CPU, GPU и памяти), что позволяет заблаговременно решать проблемы и оптимизировать систему. Кроме того, интеграция Prometheus с Grafana еще больше расширяет возможности мониторинга, предоставляя подробные информационные панели для глубокого анализа и эффективного обслуживания развертываний Milvus, предназначенных для приложений GenAI и поиск сходства.
Для получения исчерпывающих рекомендаций по настройке Prometheus для Milvus и визуализации метрик с помощью Grafana воспользуйтесь ресурсами ниже:
How to Spot Search Performance Bottleneck in Vector Databases using Prometheus and Grafana
Визуализация метрик Milvus с помощью Grafana | Документация Milvus
Zilliz Cloud - это управляемая версия Milvus с более расширенными возможностями и в 10 раз более высокой производительностью. Она предоставляет еще более четкие и простые функции мониторинга и наблюдаемости. Zilliz Cloud недавно представила надежные функции мониторинга и наблюдаемости, чтобы помочь пользователям отслеживать производительность векторной базы данных. Приборная панель Metrics предоставляет обзор состояния кластера, включая использование ресурсов (CPU, память, хранилище), производительность (QPS, VPS, задержки) и метрики данных (сбор и количество объектов), которые можно настраивать для более глубокого анализа. Приборная панель представляет метрики в интуитивно понятном виде для быстрого понимания.
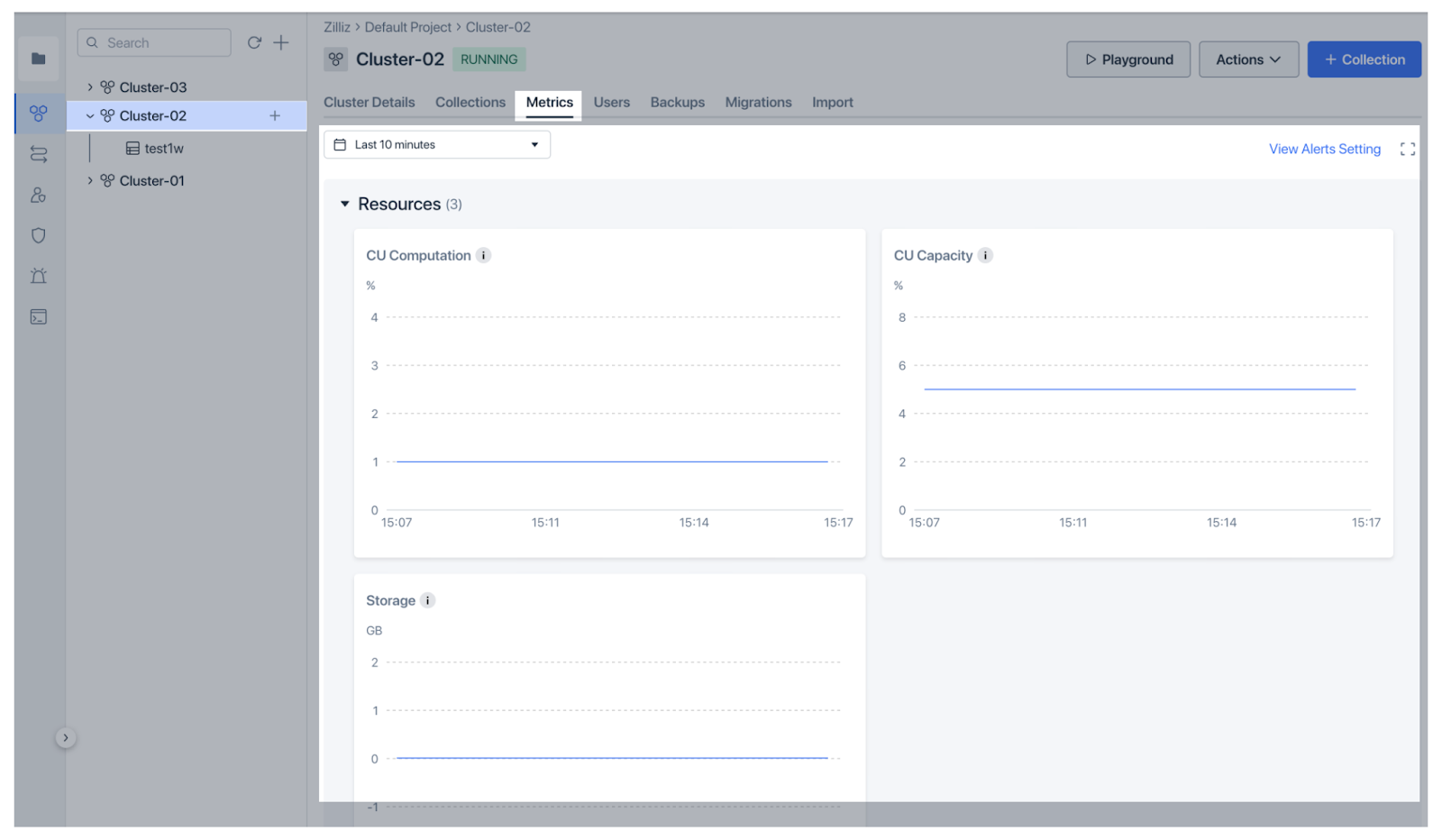 Рисунок: Метрики облачного мониторинга Zilliz
Рисунок: Метрики облачного мониторинга Zilliz
Рисунок: Метрики мониторинга облака Zilliz
Чтобы выявить проблемы на ранней стадии, Zilliz Cloud предлагает Оповещения организации для вопросов биллинга и Оповещения проекта для операционных факторов, таких как использование CU и задержка, с гибкими пороговыми значениями и настройками серьезности.
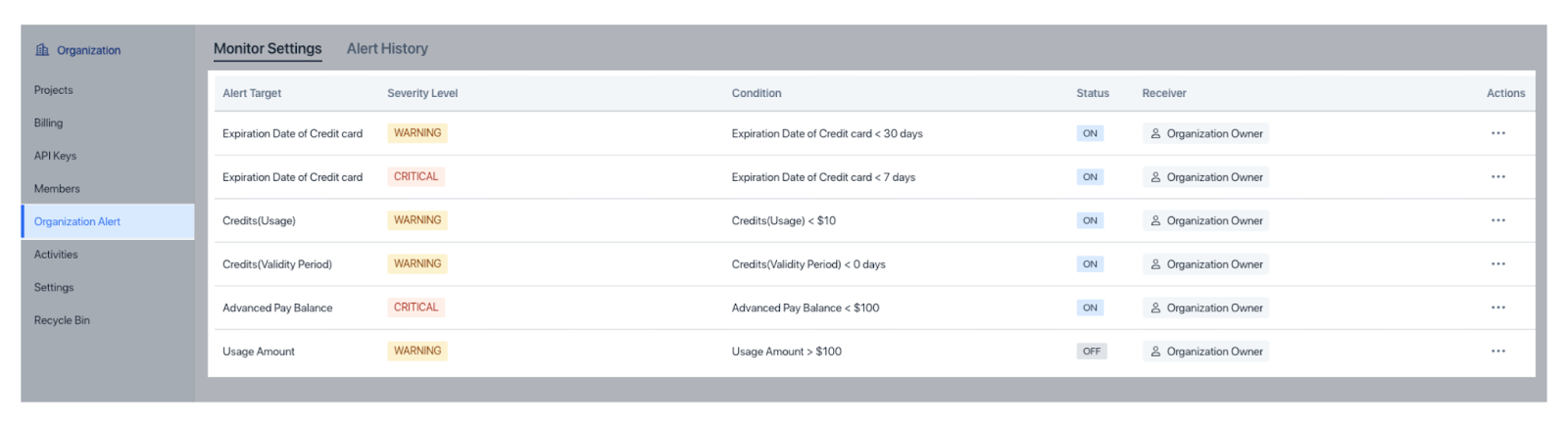 Рисунок: Оповещения организаций в Zilliz Cloud
Рисунок: Оповещения организаций в Zilliz Cloud
Рисунок: Оповещения организации в Zilliz Cloud
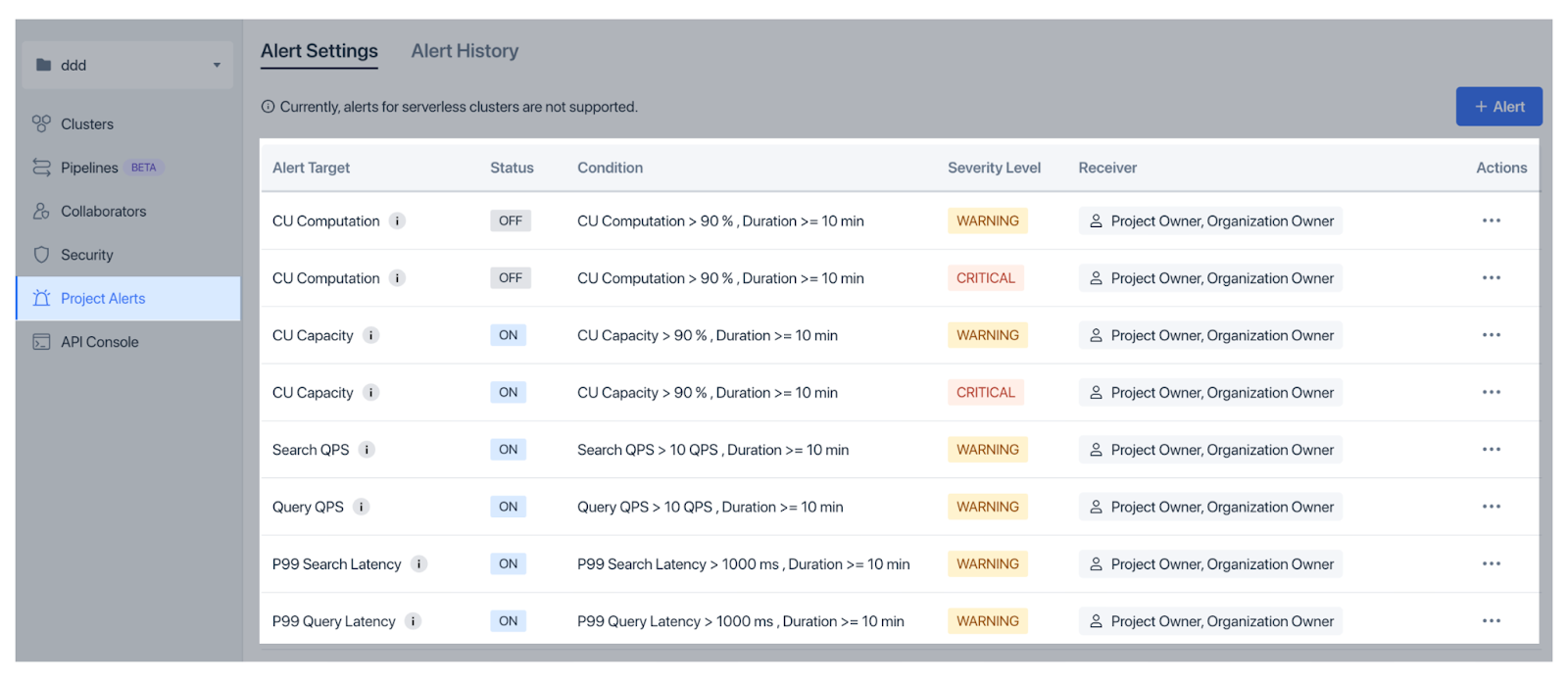 Рисунок: Оповещения о проектах в Zilliz Cloud
Рисунок: Оповещения о проектах в Zilliz Cloud
Рисунок: Оповещения о проектах в Zilliz Cloud
Ключевые особенности
Мониторинг в режиме реального времени для мгновенного получения информации о производительности кластера.
Настраиваемые информационные панели с учетом ваших ключевых показателей.
Гибкие оповещения для раннего обнаружения потенциальных проблем.
Многочисленные каналы уведомлений (электронная почта, Slack, PagerDuty).
Исторические данные для анализа тенденций производительности и долгосрочного планирования.
Заключение
Наблюдаемость - это подход к пониманию и поддержанию работоспособности современных сложных систем. Используя метрики, журналы и трассировки, команды могут обеспечить надежную работу, быстро устранять проблемы и улучшать пользовательский опыт. По мере роста и развития систем внедрение лучших практик наблюдаемости важно для опережения проблем и эффективного масштабирования. Независимо от того, работают ли распределенные микросервисы или создаются приложения, управляемые искусственным интеллектом, с помощью таких инструментов, как Milvus, наблюдаемость обеспечивает видимость, необходимую для обеспечения бесперебойной и надежной работы.
Часто задаваемые вопросы о наблюдаемости
Что такое наблюдаемость и почему она важна? ** Наблюдаемость - это практика понимания внутреннего состояния системы путем сбора и анализа данных, таких как метрики, журналы и трассировки. Она важна для диагностики проблем, мониторинга производительности и поддержания надежности системы, особенно в сложных современных системах, таких как микросервисы и облачные нативные приложения.
Чем отличается наблюдаемость от мониторинга? В то время как мониторинг отслеживает конкретные метрики для обнаружения проблем, наблюдаемость идет глубже, предоставляя понимание "почему", стоящего за этими проблемами. Мониторинг похож на контрольный список, а наблюдаемость - на полное исследование поведения и состояния системы.
Три основных компонента наблюдаемости - это метрика (числовые данные о производительности системы), логи (подробные записи событий) и трассы (пути, пройденные запросами через сервисы). В совокупности они дают полное представление о состоянии и производительности системы.
Почему наблюдаемость важна для распределенных систем? ** Распределенные системы, например построенные на микросервисах или облачных платформах, состоят из множества взаимодействующих компонентов. Наблюдаемость помогает отслеживать и отлаживать проблемы во всех этих компонентах, облегчая отслеживание проблем с производительностью, выявление узких мест и поддержание работоспособности системы.
Дополнительные ресурсы
- Что такое наблюдаемость?
- Почему наблюдаемость важна?
- Основные принципы Observability
- Как работает наблюдаемость?
- Примеры использования Observability
- Инструменты и технологии для наблюдаемости
- Проблемы наблюдаемости
- Лучшие практики наблюдаемости
- Наблюдаемость против мониторинга
- Наблюдаемость в Milvus и Zilliz Cloud: Отслеживание производительности векторной базы данных
- Заключение
- Часто задаваемые вопросы о наблюдаемости
- Дополнительные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно