




Um Guia Abrangente para Benchmarks de ANN: Avaliando o Desempenho da Busca Aproximada por Vizinhos Mais Próximos (ANNS)
Um Guia Abrangente para Benchmarks de ANN: Avaliando o Desempenho da Busca Aproximada por Vizinhos Mais Próximos (ANNS)
Imagine que você está construindo um mecanismo de busca que precisa encontrar rapidamente os itens mais semelhantes em um banco de dados contendo bilhões de imagens, documentos de texto ou outros dados não estruturados. Como garantir que seu algoritmo de busca não apenas retorne resultados precisos, mas também faça isso em altíssima velocidade? É aqui que a busca por Vizinhos Mais Próximos Aproximados (ANN) entra em cena. A busca ANN é crucial em muitas aplicações do mundo real, de sistemas de recomendação à recuperação de imagens em larga escala.
Com tantas soluções de busca ANN disponíveis no mercado, como avaliamos a eficácia de diferentes algoritmos ANN, especialmente em escala? Entram os Benchmarks de ANN, que se tornaram o padrão-ouro para testar o desempenho de métodos de busca ANN em grandes conjuntos de dados.
Neste blog, exploraremos os benchmarks de ANN, por que eles são importantes e como ajudam desenvolvedores e engenheiros de algoritmos a escolher as soluções certas de busca vetorial para o trabalho. Também veremos alguns dos benchmarks mais populares usados hoje e o que os torna essenciais na busca vetorial.
O que é Busca ANN e Como Ela Funciona?
Antes de mergulhar nos benchmarks, é importante entender a Busca Aproximada por Vizinhos Mais Próximos (ANN), ou ANNS, e como ela opera. A Busca ANN é uma técnica poderosa em machine learning (ML) que permite a busca eficiente por similaridade semântica em grandes conjuntos de dados frequentemente encontrados em bancos de dados vetoriais como o Zilliz Cloud. Ela pode encontrar rapidamente os itens mais próximos de um item de consulta em um conjunto de dados. Diferentemente dos métodos de busca exata, que garantem 100% de precisão, a ANNS troca uma pequena quantidade de precisão por melhorias significativas em velocidade e escalabilidade.
Como a Busca ANN Funciona:
Representação dos Dados: Cada item no conjunto de dados é representado como um vetor em um espaço multidimensional. Os vetores geralmente são codificados por um modelo de embeddings, como modelos de embedding de texto da OpenAI, modelos multilíngues da Cohere e modelos multimodais da OpenAI. Por exemplo, uma imagem pode ser representada como um vetor de características, como cor ou forma, em um espaço de 128 dimensões.
Processamento da Consulta: Quando uma consulta é feita, o algoritmo de Busca ANN recupera do conjunto de dados os vetores próximos ao vetor da consulta, usando aproximações para acelerar o processo.
Classificação dos Resultados: O algoritmo classifica os vizinhos mais próximos com base em sua distância em relação à consulta no espaço de alta dimensionalidade, frequentemente usando métricas como distância euclidiana ou similaridade de cosseno. Quanto mais próximos os vetores estiverem localizados, mais semelhantes e relevantes eles são.
Eficiência: A principal vantagem da Busca ANN é sua capacidade de entregar resultados em uma fração do tempo que uma busca exata levaria, tornando-a ideal para conjuntos de dados em larga escala.
Os métodos ANNS usam várias estratégias para aproximar rapidamente os vizinhos mais próximos:
Métodos baseados em árvores: Técnicas como KD-Trees e Ball Trees organizam os dados hierarquicamente para simplificar o processo de busca. Embora sejam eficazes em dimensões mais baixas, seu desempenho se degrada à medida que a dimensionalidade aumenta.
Métodos de hashing: Hashing sensível à localidade (LSH) agrupa pontos de dados semelhantes nos mesmos buckets de hash, reduzindo o número de comparações necessárias durante a busca.
Métodos baseados em grafos: Algoritmos como grafos Navigable Small World (NSW) e grafos Hierarchical Navigable Small World (HNSW) criam redes de pontos de dados para agilizar as consultas de vizinhos.
Métodos de quantização: Técnicas como Product Quantization (PQ) comprimem os dados em uma forma mais gerenciável, aumentando a eficiência da busca.
Ao aproveitar esses métodos, os algoritmos ANNS podem equilibrar precisão e desempenho da busca, tornando-os adequados para conjuntos de dados em larga escala.
Busca ANN vs. Busca KNN
A busca exata de K-vizinhos mais próximos (KNN) e a Busca Aproximada de Vizinhos Mais Próximos (ANNS) são duas abordagens fundamentais usadas na busca vetorial, cada uma com suas próprias vantagens e trade-offs.
O KNN exato fornece resultados precisos ao avaliar a distância entre o ponto de consulta e cada ponto de dados no conjunto de dados, garantindo que os vizinhos identificados sejam os mais próximos possíveis. No entanto, esse método pode ser computacionalmente intensivo e lento devido à sua natureza de força bruta, particularmente ao lidar com grandes conjuntos de dados ou espaços de alta dimensionalidade. Isso torna o KNN exato adequado para conjuntos de dados menores ou cenários em que a precisão é essencial e os recursos computacionais são menos preocupantes.
Em contraste, o ANNS oferece uma solução prática para lidar com dados em larga escala ao sacrificar certo grau de precisão em favor de um desempenho mais rápido. O ANNS emprega vários algoritmos e técnicas, como estruturas baseadas em árvores, métodos de hashing e abordagens baseadas em grafos, para aproximar os vizinhos mais próximos de forma eficiente. Essa abordagem reduz significativamente os custos computacionais e escala bem com conjuntos de dados massivos, tornando-a ideal para aplicações em tempo real, como mecanismos de busca e sistemas de recomendação, em que a velocidade é crucial. Embora o ANNS nem sempre forneça os vizinhos mais próximos exatos, sua capacidade de entregar rapidamente resultados quase precisos o torna uma ferramenta valiosa em tarefas modernas de recuperação e análise de dados.
Para mais informações, consulte nossa página do glossário ANNS.
O que é o ANN Benchmark?
O ANN Benchmark é uma ferramenta de avaliação abrangente projetada para medir e comparar o desempenho de diferentes algoritmos ANNS. Hospedado em ann-benchmarks.com, ele fornece testes e métricas padronizados para avaliar vários aspectos dos métodos ANNS, incluindo:
Velocidade de busca: Quão rapidamente o algoritmo consegue encontrar os vizinhos mais próximos.
Precisão: O grau em que os resultados do algoritmo aproximam os verdadeiros vizinhos mais próximos.
Escalabilidade: Quão bem o algoritmo se comporta à medida que o tamanho do conjunto de dados ou a dimensionalidade aumenta.
Este benchmark oferece uma variedade de conjuntos de dados e critérios de avaliação, permitindo que desenvolvedores avaliem a eficácia de diferentes algoritmos sob diversas condições em um campo de comparação nivelado.
Métricas-chave em benchmarks ANN:
Recall: A porcentagem de verdadeiros vizinhos mais próximos recuperados com sucesso pelo algoritmo. Um recall alto indica melhor precisão.
Tempo de busca: O tempo que o algoritmo leva para retornar um resultado. Tempos de busca mais rápidos são cruciais para aplicações que exigem respostas em tempo real.
Uso de memória: A quantidade de memória que o algoritmo requer para armazenar e pesquisar o conjunto de dados. O uso eficiente da memória é importante para a escalabilidade.
Escalabilidade: A capacidade do algoritmo de manter o desempenho à medida que o tamanho do conjunto de dados aumenta. A escalabilidade é um fator crítico em aplicações do mundo real onde os conjuntos de dados podem crescer rapidamente.
Principais conjuntos de dados usados em ANN Benchmarks
ANN Benchmark usa diversos conjuntos de dados para testar algoritmos. Esses conjuntos de dados abrangem uma variedade de domínios, como características de imagem, embeddings de texto e dados sintéticos. Os principais conjuntos de dados usados nos benchmarks incluem:
| Conjunto de dados | Dimensões | Tamanho de treino | Tamanho de teste | Vizinhos | Distância | Download |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angular | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidiana | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidiana | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angular | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidiana | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angular | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidiana | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angular | HDF5 (135MB) |
Algoritmos ANN ou mecanismos de busca vetorial testados
Os ANN Benchmarks avaliaram uma ampla variedade de algoritmos ANN e mecanismos de busca vetorial, incluindo Annoy, Faiss, Knowhere (mecanismo de busca do Milvus) e Glass (mecanismo de busca legado do Zilliz Cloud). O número de algoritmos testados continua a crescer. Abaixo está uma lista de algoritmos e mecanismos de busca testados até setembro de 2024.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Biblioteca de Espaço Não Métrico) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Nota: A Zilliz Cloud lançou um novo mecanismo de busca chamado Cardinal, que oferece três vezes o desempenho do mecanismo Glass legado e oferece throughput de busca (QPS) até dez vezes maior que o do Milvus. No entanto, devido a restrições de tempo e outros fatores, o desempenho do Cardinal não está incluído nos resultados do benchmark de ANN. Na seção a seguir, você pode explorar seu desempenho usando o VectorDBBench.
Resultados do Benchmark
O gráfico abaixo demonstra os resultados do teste de recall/consultas por segundo de vários algoritmos com base no conjunto de dados GIST1M (1M de vetores com 960 dimensões). Ele plota a taxa de recall no eixo x em relação ao QPS no eixo y, ilustrando o desempenho de cada algoritmo em diferentes níveis de precisão de recuperação.
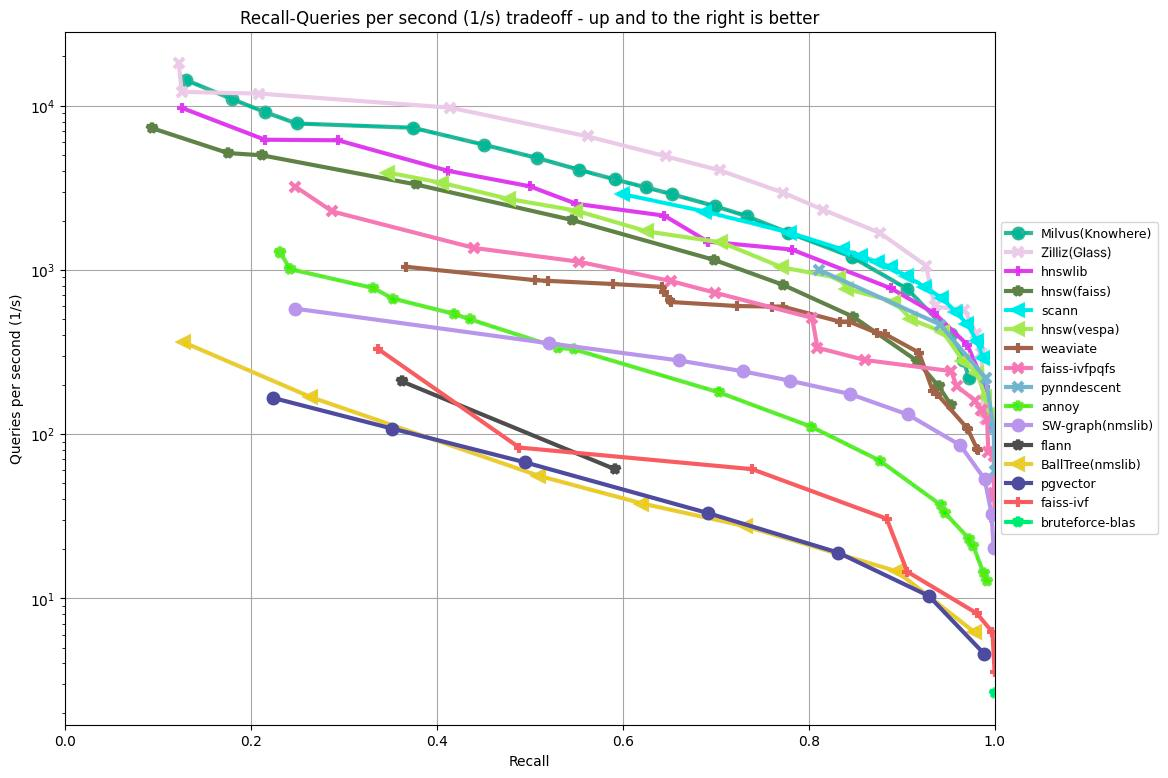 Figura 1: resultados do Benchmark ANN no conjunto de dados GIST1M
Figura 1: resultados do Benchmark ANN no conjunto de dados GIST1M
Figura 1: resultados do Benchmark ANN no conjunto de dados GIST1M
De acordo com os resultados mostrados no gráfico acima, Knowhere (mecanismo de busca do Milvus), Glass (mecanismo de busca legado da Zilliz Cloud) e bibliotecas HNSW alcançaram os três melhores resultados ao processar 1.000.000 de vetores com 960 dimensões.
Para mais resultados de benchmark, consulte o site do ANN-Benchmark.
VectorDBBench: uma ferramenta de benchmarking de código aberto para bancos de dados vetoriais
Busca vetorial, ou busca por similaridade vetorial, é um conceito mais amplo que se refere ao processo de encontrar vetores semelhantes dentro de um conjunto de dados. ANNS representa um conjunto de algoritmos que impulsionam a busca vetorial. Bancos de dados vetoriais são soluções criadas especificamente para buscas eficientes por similaridade vetorial.
Embora o ANN-Benchmark seja incrivelmente útil para selecionar e comparar diferentes algoritmos de busca vetorial, ele não fornece uma visão geral abrangente dos bancos de dados vetoriais. Também devemos considerar fatores como consumo de recursos, capacidade de carregamento de dados e estabilidade do sistema. Além disso, o ANN Benchmark deixa de fora muitos cenários comuns, comobuscas vetoriais filtradas.
Para enfrentar esses desafios, os desenvolvedores da Zilliz propuseram o VectorDBBench, uma ferramenta de benchmarking de código aberto projetada para bancos de dados vetoriais de código aberto como Milvus e Weaviate e serviços totalmente gerenciados como Zilliz Cloud e Pinecone. Como muitos serviços de busca vetorial totalmente gerenciados não expõem seus parâmetros para ajuste pelo usuário, o VectorDBBench exibe QPS e taxas de recall separadamente.
Os gráficos abaixo demonstram os resultados dos testes para QPS e a taxa de recall de vários bancos de dados vetoriais convencionais ao processar 1.000.000 de vetores com 768 dimensões.
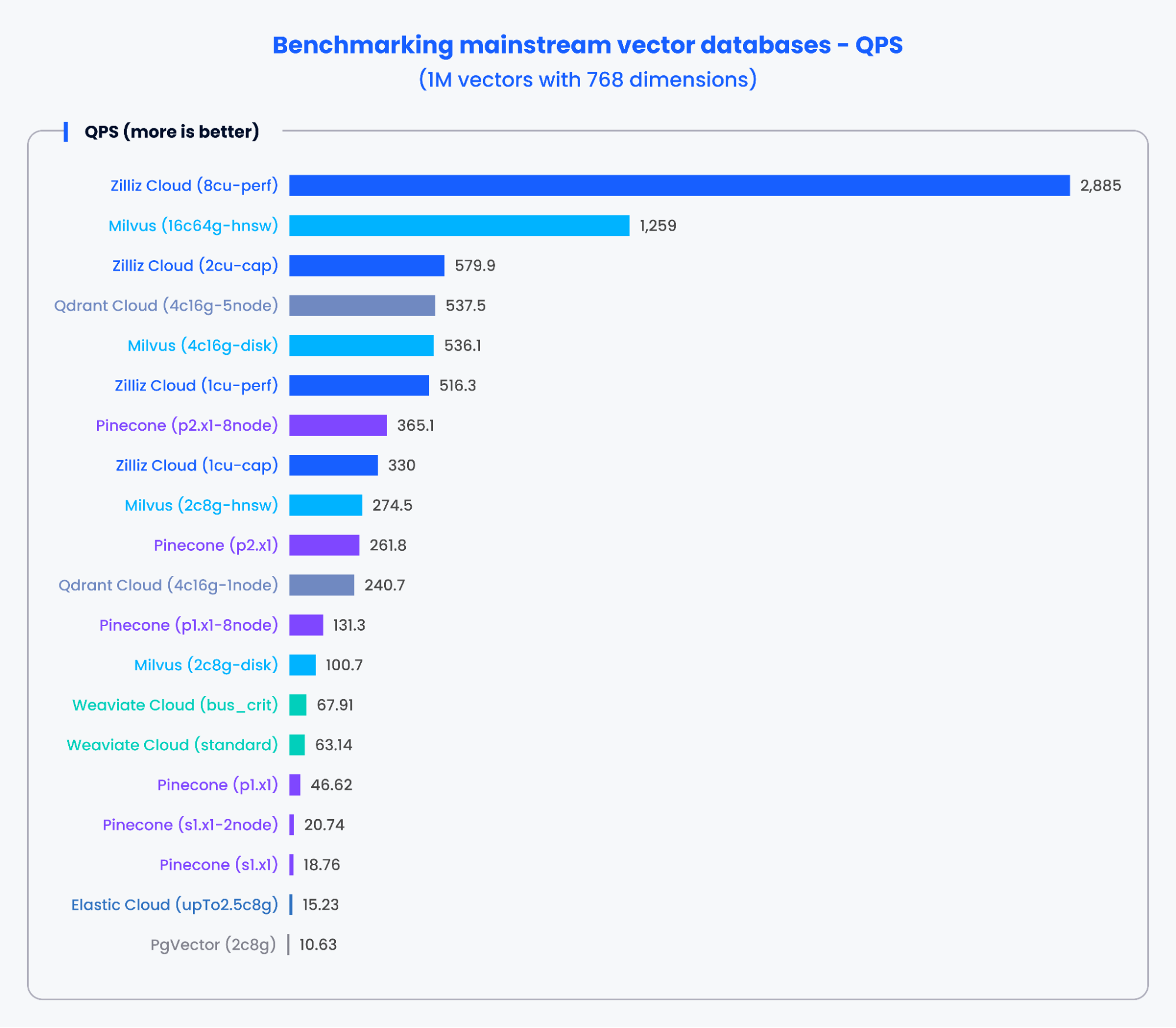 Figura 2: Resultados de benchmark para QPS
Figura 2: Resultados de benchmark para QPS
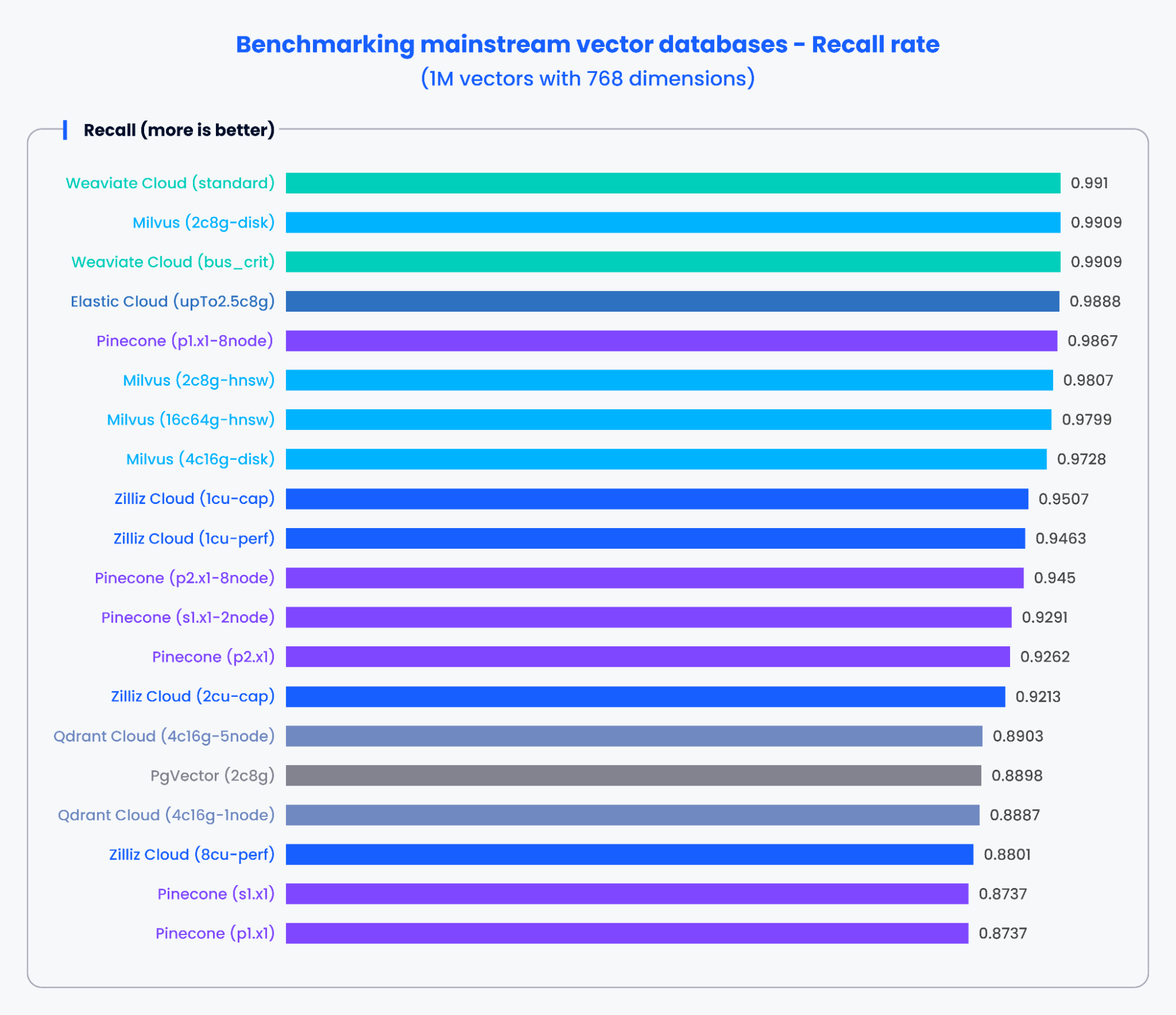 Figura 3: Resultados de benchmark para taxa de recall
Figura 3: Resultados de benchmark para taxa de recall
Com base nos resultados nos gráficos acima, bancos de dados vetoriais criados especificamente, como Milvus e Zilliz, demonstraram desempenho excepcional tanto em QPS quanto em taxas de recall. Esses resultados indicam que bancos de dados vetoriais criados especificamente podem processar rapidamente grandes volumes de dados e recuperar resultados mais precisos. Em contraste, complementos de busca vetorial baseados em bancos de dados tradicionais apresentaram desempenho inferior.
Baixe o VectorDBBench de seu repositório GitHub para reproduzir nossos resultados de benchmark ou obter resultados de desempenho em seus próprios conjuntos de dados.
Leaderboard do VectorDBBench
O VectorDBBench também oferece uma página de leaderboard dedicada, projetada para simplificar a apresentação dos resultados de teste e fornecer um relatório detalhado de análise de desempenho. Este leaderboard nos permite selecionar métricas-chave como Queries Per Second (QPS), métricas de Query Price ($) e latência para uma avaliação abrangente de desempenho.
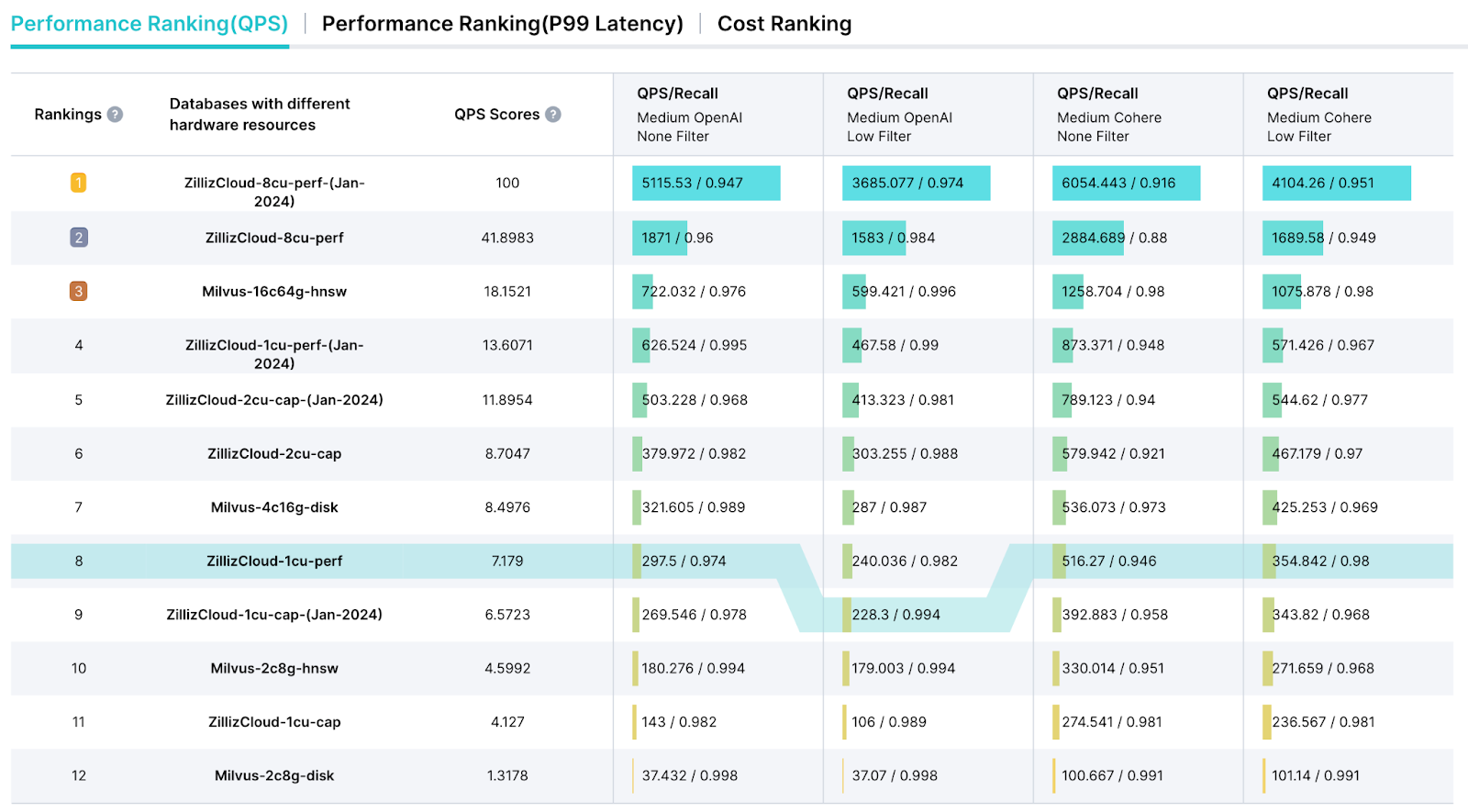 uma captura de tela do leaderboard do vectordbbench
uma captura de tela do leaderboard do vectordbbench
Figura 4: Uma captura de tela do Leaderboard do VectorDBBench
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks avaliam algoritmos de índice vetorial, auxiliando na seleção e comparação de diferentes bibliotecas de busca vetorial. No entanto, eles são inadequados para avaliar bancos de dados vetoriais complexos e maduros e ignoram situações como busca vetorial filtrada.
Os engenheiros da Zilliz criaram o VectorDB Bench para ser adaptado a uma avaliação abrangente de bancos de dados vetoriais. Ele considera fatores essenciais como consumo de recursos, capacidade de carregamento de dados e estabilidade do sistema. Ao segregar o cliente de teste e o banco de dados vetorial e garantir implantação independente, o VectorDB Bench permite testes que refletem de perto ambientes de produção do mundo real.
Fatores que Influenciam a Avaliação de Desempenho
Vários fatores impactam o desempenho de um banco de dados vetorial ou de um algoritmo ANN, incluindo o conjunto de dados, as condições de rede e a configuração do banco de dados.
Rede
As condições de rede são críticas. Latência pode tornar as respostas às consultas mais lentas, enquanto largura de banda limitada afeta as taxas de transferência de dados. Estabilidade da rede também é importante, pois flutuações podem causar desempenho inconsistente.
Conjuntos de Dados
Tamanho do conjunto de dados influencia o uso de memória e disco—conjuntos de dados maiores exigem mais recursos. Dimensionalidade vetorial afeta a complexidade das operações e os tempos de consulta. A distribuição dos dados e a estrutura de indexação (por exemplo, hierárquica, plana) também impactam a eficiência e a precisão da busca.
Configuração do Banco de Dados
Parâmetros de índice (por exemplo, número de árvores) e configurações de busca (por exemplo, vizinhos mais próximos) afetam diretamente a eficiência e a velocidade da recuperação. Cache pode melhorar os tempos de resposta para dados acessados com frequência.
Fatores Ambientais
O sistema operacional e os processos em segundo plano podem influenciar a disponibilidade de recursos e a capacidade de resposta do sistema, afetando o desempenho geral.
Considerar esses fatores ajuda você a entender e otimizar o desempenho do seu banco de dados vetorial.
Recursos Adicionais
- O que é Busca ANN e Como Ela Funciona?
- O que é o ANN Benchmark?
- VectorDBBench: uma ferramenta de benchmarking de código aberto para bancos de dados vetoriais
- ANN Benchmarks vs. VectorDBBench
- Fatores que Influenciam a Avaliação de Desempenho
- Recursos Adicionais
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis