




De Banco de Dados Vetorial a Lakebase Vetorial
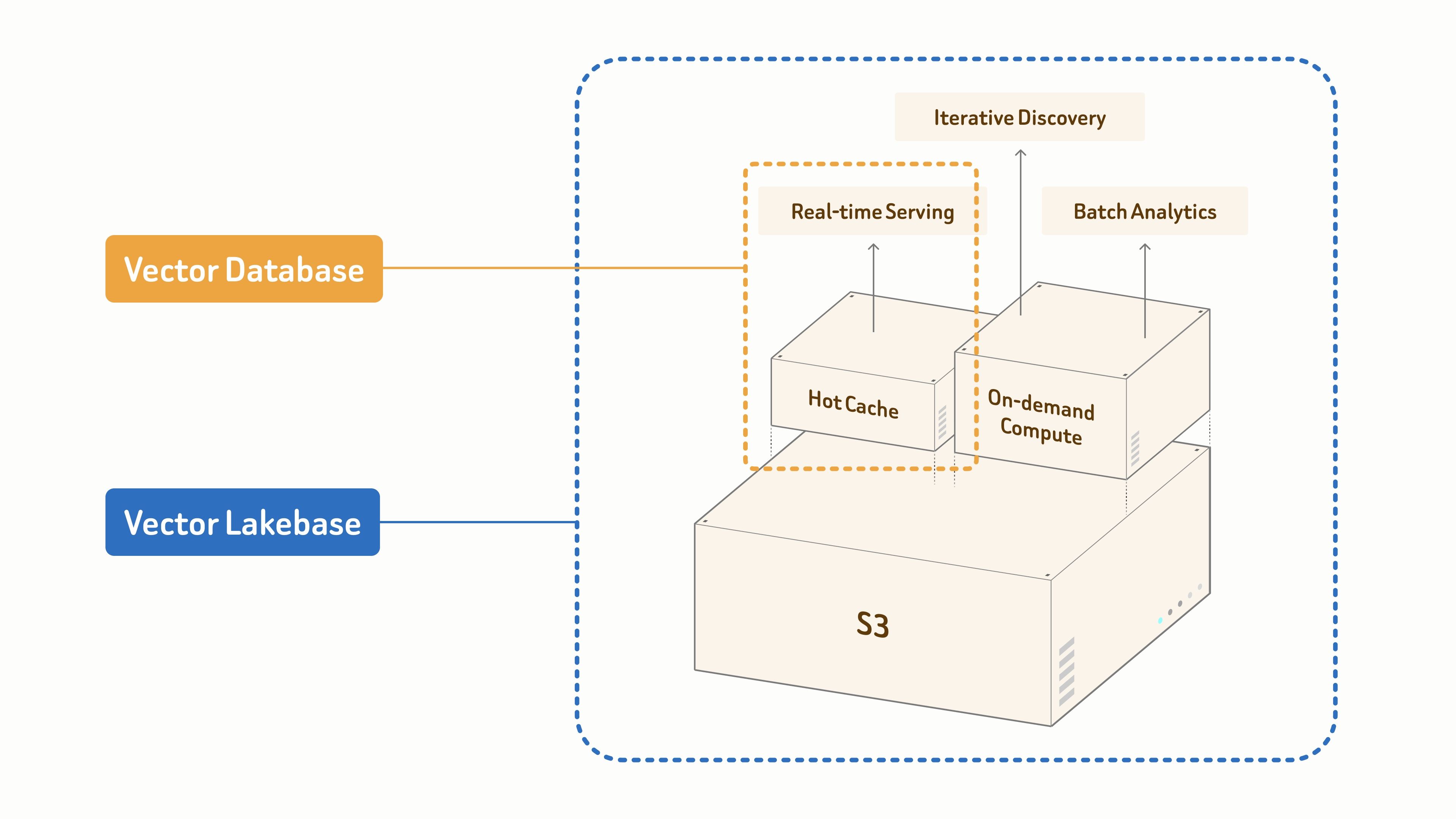
Hoje, estamos lançando a prévia pública do Zilliz Vector Lakebase — o próximo capítulo do Zilliz Cloud. Vector Lakebase é o próximo passo além dos bancos de dados vetoriais. É uma plataforma de dados centrada em semântica, onde armazenamento aberto e computação elástica convergem para cargas de trabalho de IA.
- Bancos de dados vetoriais são projetados especificamente para servir em tempo real.
- Vector Lakebase se baseia em uma fundação de dados unificada baseada em S3 para impulsionar IA e agentes em três modos de carga de trabalho:
- recuperação em tempo real para serving de produção sensível à latência,
- descoberta iterativa para exploração interativa e em várias etapas,
- análises em lote para mineração offline e otimização de datasets.
Tudo escalando de gigabytes a petabytes.
Por que a fundação de dados unificada e os três modos de carga de trabalho realmente importam?
Em resumo: porque os sistemas de IA não são mais apenas um problema de recuperação de consulta única. Eles operam como um ciclo contínuo de servir, aprender e melhorar.
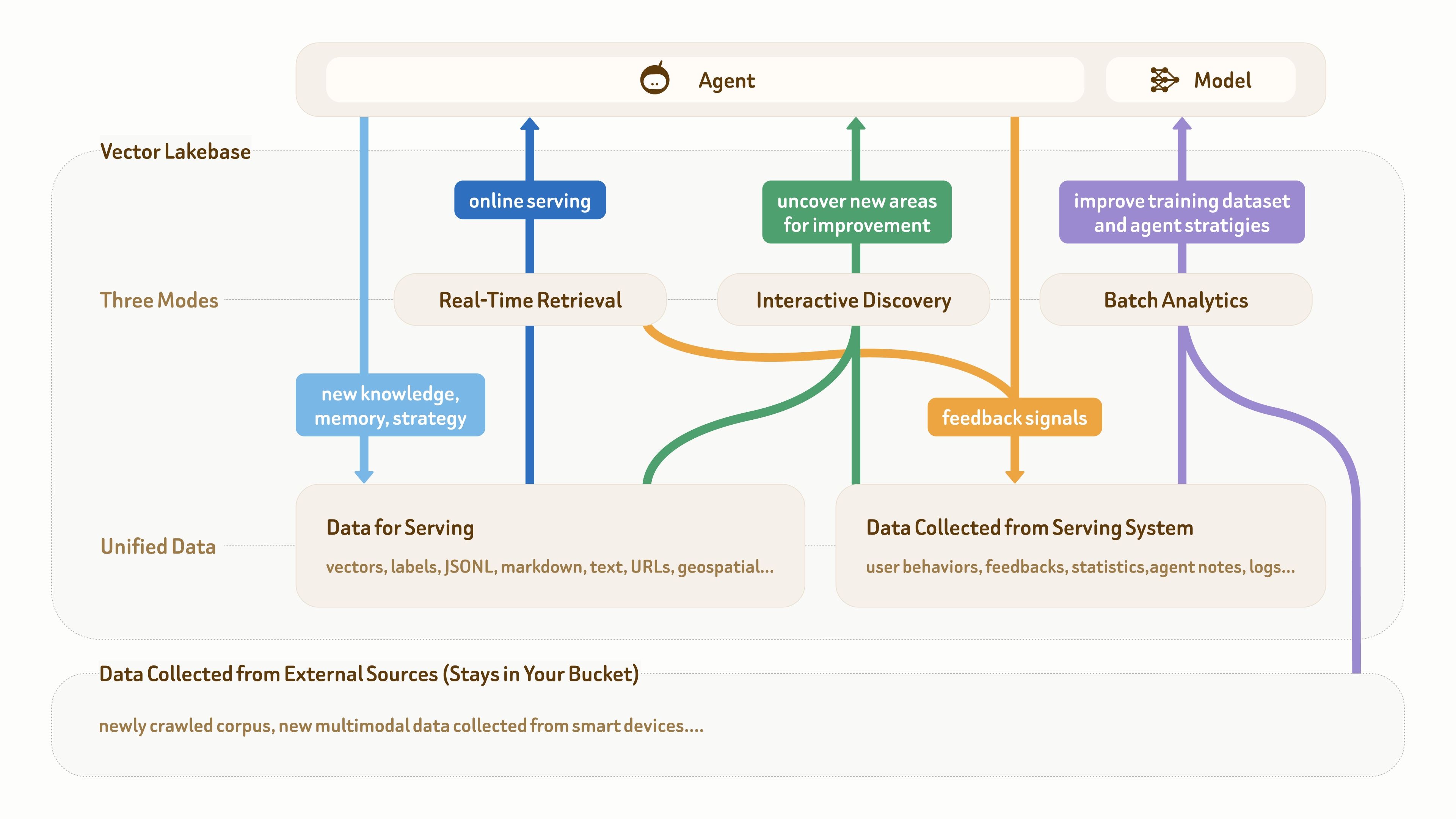
Como esta figura mostra, a fundação de dados para aplicações de IA e agentes geralmente tem três partes: dados multimodais brutos na base, dados semânticos para serving online (como texto, vetores e rótulos) e dados de feedback coletados de sistemas de produção (como comportamento do usuário, logs, anotações de agentes e estatísticas).
Muitas aplicações maduras de agentes já têm esse tipo de fundação de dados. O verdadeiro ponto problemático é que esses diferentes tipos de dados muitas vezes estão espalhados por vários pipelines e sistemas, sem um plano de dados unificado e estruturado para dar suporte ao ciclo do fluxo de trabalho:
serving online (azul-escuro) → acúmulo de conhecimento e feedback (azul-claro e laranja) → descoberta de insights (verde) → melhoria de datasets e estratégias (roxo) → melhor serving online.
Como a imagem também mostra, apenas um banco de dados vetorial já não é suficiente, porque ele oferece suporte principalmente à recuperação em tempo real e a gravações de dados orientadas a serving (os dois caminhos azuis). Nesse ciclo, os outros dois modos de acesso — descoberta interativa e análises em lote — são igualmente importantes.
Por exemplo, desenvolvedores de IA (seja manualmente ou por meio de sistemas agênticos) frequentemente precisam explorar dados de feedback e o corpus subjacente para entender por que a qualidade do serving é baixa. Eles também podem executar deduplicação semântica e clustering semântico em larga escala em dados recém-coletados por crawling e, em seguida, minerar clusters de borda para descobrir novos candidatos a dados de treinamento.
Essas cargas de trabalho são muito diferentes do processamento tradicional de big data. A computação central é semântica, e não numérica. Os dados consistem principalmente em vetores, texto, rótulos e metadados semânticos, enquanto as operações centrais incluem busca vetorial, busca de texto completo, reranking, clustering semântico e tarefas relacionadas de recuperação semântica.
Por isso, a descoberta interativa e as análises em lote se alinham naturalmente aos bancos de dados vetoriais tanto na camada de dados quanto na de computação. Em muitos casos, o serving online e o processamento offline até compartilham a mesma fundação de dados subjacente.
Por exemplo, equipes podem agrupar em clusters e analisar tarefas de usuários de alto valor offline enquanto verificam simultaneamente se o conhecimento ou as estratégias de suporte no sistema de serving apresentam problemas de esparsidade ou qualidade.
No geral, qualquer arquitetura de dados fragmentada ou ilhas de infraestrutura isoladas desaceleram esse ciclo — o que pode ser fatal na corrida em rápida evolução por capacidades de IA. Vector Lakebase acelera esse ciclo por meio de uma abordagem direta, mas eficiente: fornecer um plano de dados semântico de cópia zero que pode ser acessado de forma eficiente por todos os três modos de carga de trabalho — recuperação em tempo real, descoberta interativa e análises em lote.
Os principais recursos do Vector Lakebase
O Zilliz Vector Lakebase oferece suporte a esse ciclo de fluxo de trabalho por meio de cinco capacidades principais:
- Soluções de atendimento em camadas
Camadas de atendimento flexíveis otimizadas para diferentes cargas de trabalho em tempo real — oferecendo desempenho ultra-alto, eficiência equilibrada e escalabilidade econômica em conjuntos de dados massivos. - Busca sob demanda
Projetada para cargas de trabalho em larga escala nas quais a latência é menos crítica e a computação permanece ociosa na maior parte do tempo — incluindo busca infrequente, exploração de dados e análises em lote. - Busca em data lake externo
Adicione recursos de indexação de ponta e busca em larga escala diretamente aos dados do seu lake existente. - Busca de espectro completo De vetores e texto a JSON e geoespacial—combinados com recuperação híbrida, filtragem e reranking para consultas multimodais expressivas.
- Armazenamento unificado nativo de lake
Armazenamento unificado tanto para atendimento quanto para análises, construído sobre o Vortex — um formato aberto de próxima geração que oferece leituras aleatórias mais rápidas e mais baratas do que Lance e Parquet, além de flexibilidade de formato por coluna e recursos mais amplos de modelagem de dados.
Soluções de atendimento em tempo real em camadas
As Soluções de atendimento em camadas do Zilliz Cloud fornecem três camadas de atendimento: Otimizada para desempenho, Otimizada para capacidade e Armazenamento em camadas. Cada camada é construída com algoritmos de indexação dedicados e estratégias de posicionamento de dados em toda a hierarquia de armazenamento, oferecendo uma ampla gama de compensações entre desempenho e custo.
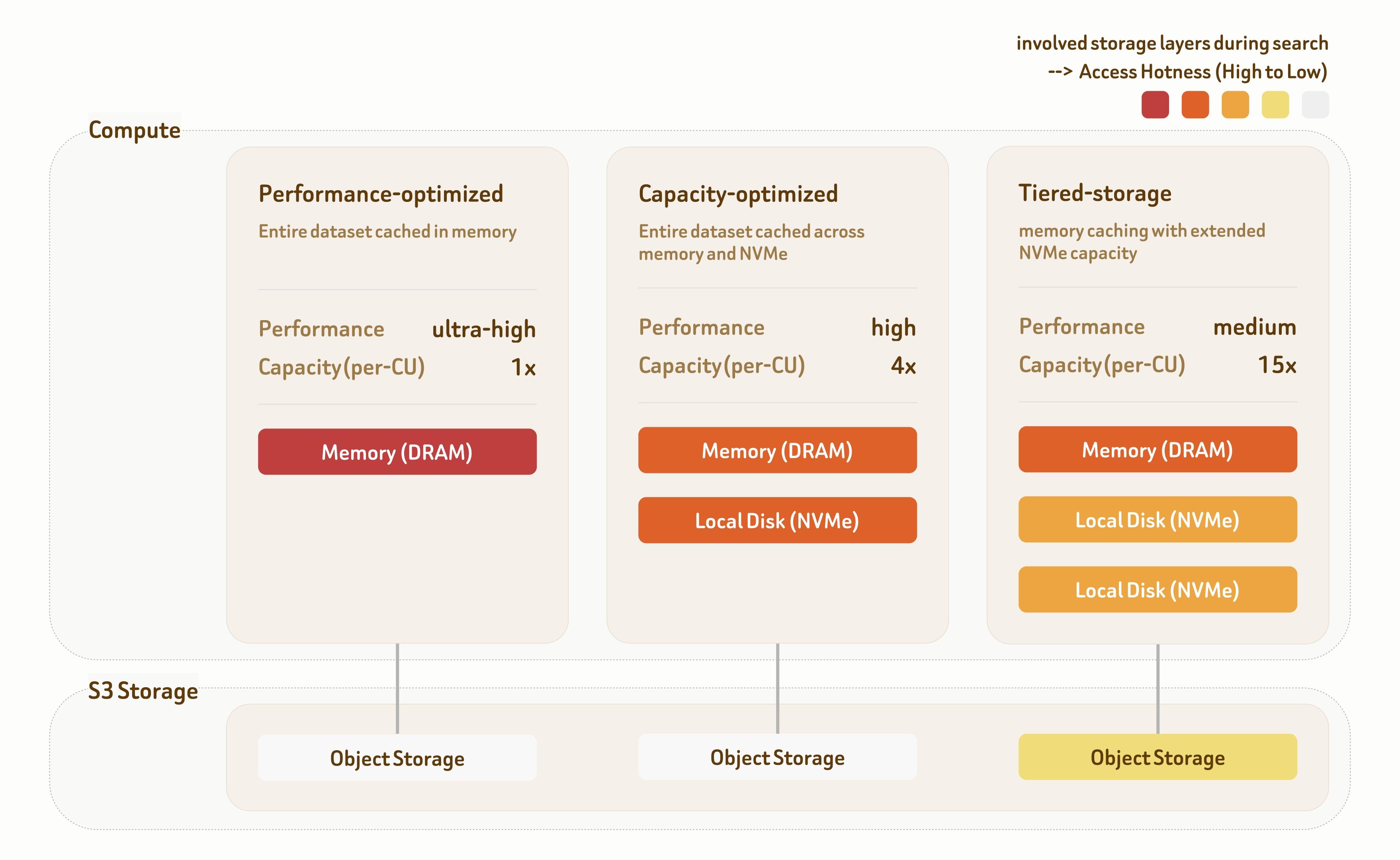
A camada Otimizada para desempenho visa cenários de desempenho ultra-alto. Todos os dados são servidos diretamente da memória, entregando mais de 1000 QPS com latência de milissegundos de um dígito. A taxa de transferência escala ainda mais linearmente com implantação de múltiplas réplicas.
A camada Otimizada para capacidade combina memória e armazenamento NVMe local para equilibrar desempenho e capacidade. Ela entrega 100~500 QPS com latência abaixo de 100 ms, tornando-a adequada para a maioria das cargas de trabalho de recuperação.
A camada Armazenamento em camadas abrange memória, NVMe local e armazenamento de objetos. Com estratégias altamente otimizadas de pré-busca e cache, mais de 95% do acesso aos dados ainda atinge a memória ou o disco local, fornecendo 10~50 QPS com cerca de 100 ms de latência a um custo de infraestrutura significativamente menor.
Todas as três camadas oferecem 95%–98% de recall por padrão, com ajuste flexível entre indexação e busca—suportando recall de 90% a 99%+ com base nos requisitos da carga de trabalho.
Essas arquiteturas de atendimento foram testadas em batalha em algumas das cargas de trabalho de IA e internet em larga escala mais exigentes do mundo, incluindo:
- plataformas de IA multilocatárias em escala de internet,
- camadas de serviço diferenciadas tanto para usuários corporativos premium quanto para grandes pools de usuários gratuitos,
- bases de conhecimento de agentes de alto desempenho,
- sistemas de recomendação de throughput ultra-alto,
- mecanismos de busca de IA em escala web,
- agendamento dinâmico de dados quentes/frios em nível de segundos entre camadas de armazenamento,
- pipelines de mineração de dados de direção autônoma em escala de mais de 100B sob restrições extremas de custo.
Para atendimento online, o Zilliz Cloud também fornece recursos de Global Cluster para alta disponibilidade e recuperação de desastres entre regiões, respaldados por um SLA de 99,99% de disponibilidade.
Busca sob demanda
A descoberta interativa e a análise em lote geralmente operam sobre volumes de dados uma a três ordens de magnitude maiores do que o atendimento online, especialmente ao incluir dados de feedback, notas geradas por agentes, logs e corpora rastreados. Esses conjuntos de dados podem facilmente atingir escala de TB ou até PB. Mas usar centenas ou até milhares de nós de banco de dados vetorial para atendê-los muitas vezes é difícil de justificar sob uma perspectiva de custo-benefício.

Mais importante, essas cargas de trabalho geralmente são orientadas por tarefas. Diferentemente da camada de atendimento online de aplicações de agentes, elas não exigem infraestrutura ativa 24/7. Os recursos de computação são muito usados apenas durante tarefas de processamento ativas, permanecendo ociosos na maior parte do tempo, muitas vezes com mais de 97% de tempo ocioso.
Soluções de serving serverless podem parecer atraentes, mas frequentemente se tornam muito mais caras para essas cargas de trabalho.
Na camada de computação, tanto os sistemas serverless quanto o On-Demand Search seguem um modelo de pagamento conforme o uso. Apesar das diferenças nos modelos detalhados de precificação, o custo de computação subjacente muitas vezes é semelhante. No entanto, em uma arquitetura serverless, a sobrecarga de pooling, a indexação e os custos de dados persistentes são incorporados a markups adicionais de escrita e armazenamento, em vez de refletirem diretamente o custo real dos recursos subjacentes.
Em contraste, o Zilliz On-Demand Search cobra diretamente pelo armazenamento de objetos e pela computação sob demanda — semelhante ao AWS Lambda, em que a precificação se baseia principalmente no tamanho dos recursos alocados e no tempo de execução, enquanto o custo de armazenamento permanece próximo ao custo subjacente do S3. Isso evita sobrecarga de infraestrutura oculta e modelos de precificação de caixa-preta.
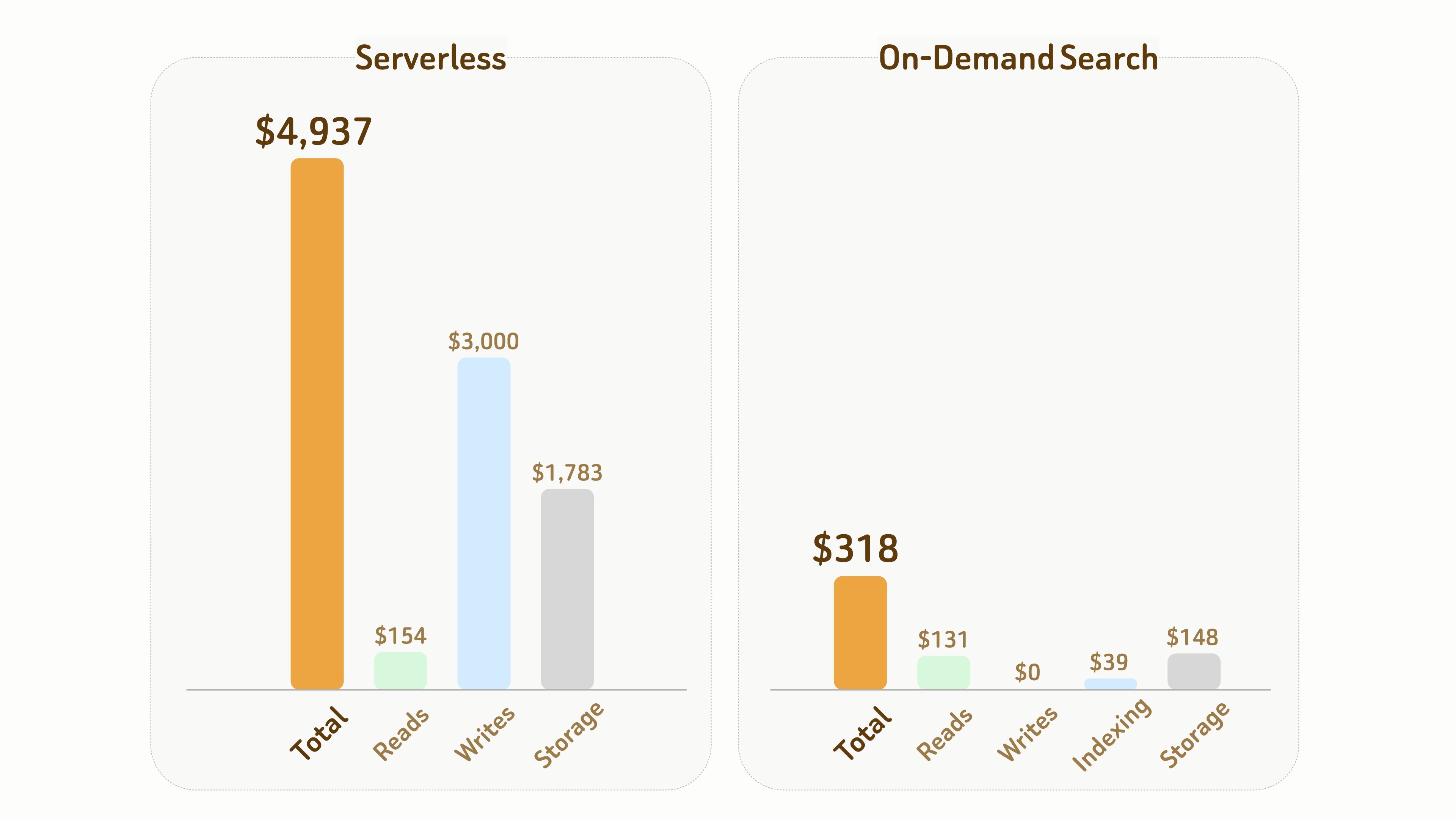
A comparação a seguir ilustra a diferença de custo entre Serverless e On-Demand Search.
Configuração:
- 1B de vetores com 768 dimensões, exigindo aproximadamente 6 TB de armazenamento incluindo arquivos de dados e índice,
- Duração de 1 mês com 10 horas de tempo acumulado de computação ativa.
No geral, neste experimento, o custo total do On-Demand Search é apenas cerca de 1/15 ($318 vs $4,937) do custo do Serverless.
External Data Lake Search
O Zilliz Vector Lakebase oferece armazenamento e computação de consulta totalmente gerenciados, permitindo que os usuários armazenem e operem seus dados diretamente no Zilliz Cloud. No entanto, alguns clientes já têm infraestrutura de data lake e pipelines de governança maduros em funcionamento.
Para aplicações de IA, um dos principais desafios é possibilitar recuperação eficiente e exploração semântica diretamente sobre os dados existentes no lake. Sistemas tradicionais de big data, como Spark e Ray, não são otimizados para essas cargas de trabalho, porque são fundamentalmente projetados em torno de varredura completa dos dados e computação map-reduce, em vez de consulta acelerada por índice e recuperação semântica.
Para resolver isso, a Zilliz oferece um modo External Collection. Ele cria um mapeamento lógico zero-copy do plano de dados da Zilliz para tabelas de lake pertencentes ao cliente, ao mesmo tempo em que possibilita índices de alto desempenho e busca de espectro completo sobre esse mapeamento.
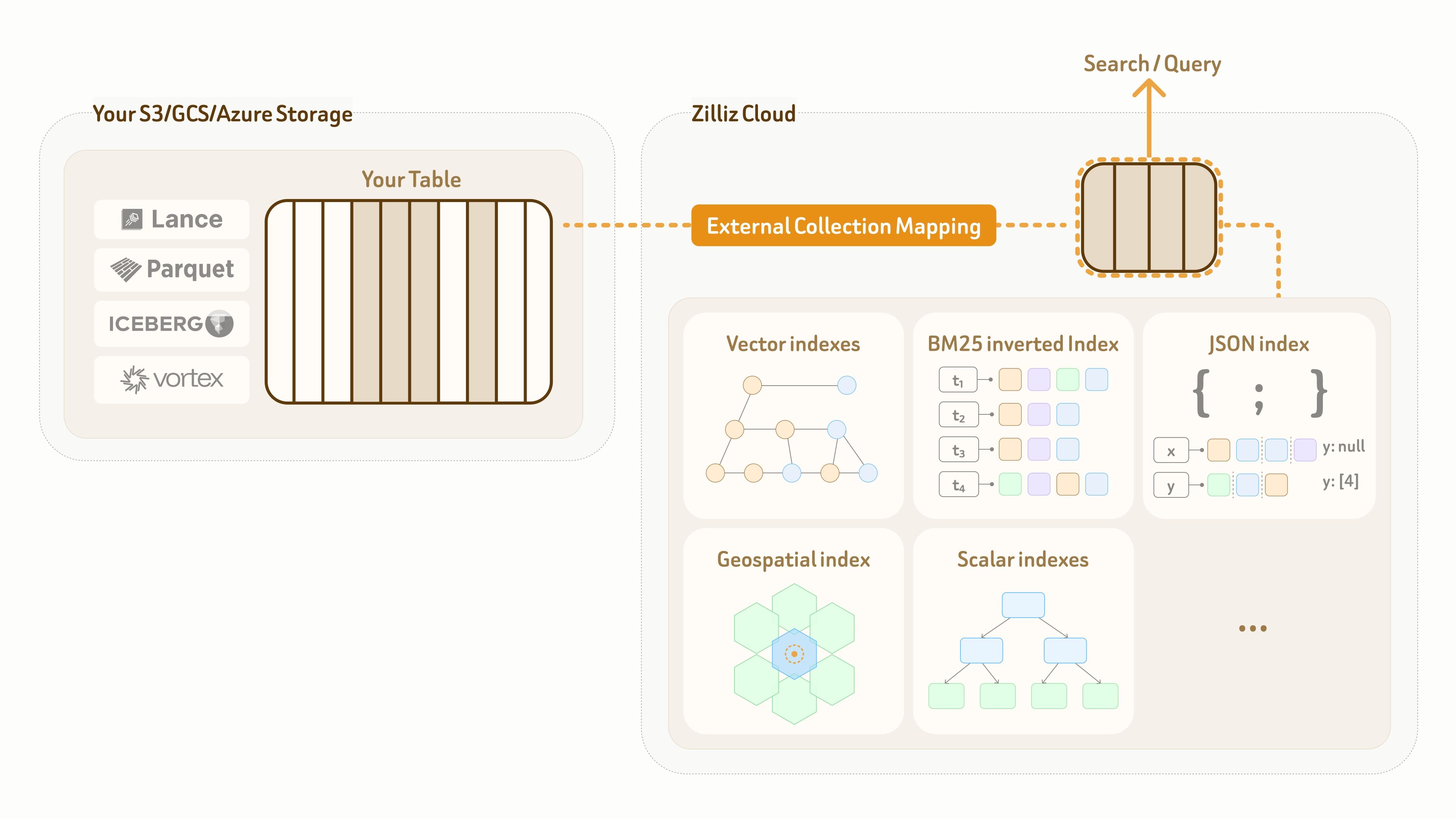
Atualmente, o External Collection suporta dois formatos de tabela de data lake — Lance e Iceberg, bem como dois formatos de dados abertos — Parquet e Vortex.
Para atualizações de data lake, o Zilliz External Collection oferece recursos de sincronização incremental. Com base no padrão de atualização do data lake e nos requisitos de visibilidade de consulta, os usuários podem sincronizar dados a qualquer momento com uma chamada de refresh.
Full-Spectrum Search
Aplicações de IA precisam cada vez mais recuperar e analisar dados em diferentes fontes e modalidades — tanto para combinar informações complementares quanto para extrair múltiplas perspectivas do mesmo conteúdo bruto para melhor qualidade de recuperação e análise.
O Zilliz Vector Lakebase suporta modelagem de tabelas largas com tipos de dados ricos, incluindo vetores densos e esparsos, texto, JSON, dados geoespaciais e tipos primitivos, juntamente com estruturas complexas como Struct e Array — permitindo modelagem semântica aninhada eficiente diretamente dentro de um layout de tabela unificado.

Isso possibilita modelagem de contexto unificada ao mapear cada entidade no nível da aplicação diretamente para uma única linha. Por exemplo, em vez de dividir um documento em centenas de linhas para trechos de texto, imagens e tabelas, o Zilliz Vector Lakebase pode modelar o documento inteiro como uma única linha. Isso melhora a recuperação e a análise multimodais, ao mesmo tempo em que evita a sobrecarga operacional e de desempenho de JOINs e agregações.
Além da modelagem de dados, o Vector Lakebase também oferece recursos de indexação e busca de última geração em todos os tipos de dados compatíveis. Os recursos detalhados estão listados abaixo:
| Vector Search | Algoritmos avançados de indexação que superam HNSW, IVF e RaBitQ, com 10 níveis de ajuste de recall-latência. |
|---|---|
| Full-Text Search | Busca de texto completo com BM25, frase, prefixo, correspondência fuzzy e uma ampla variedade de analisadores. |
| Grep | Suporte integrado a regex cobrindo a maioria dos padrões de correspondência no estilo grep. |
| Hybrid Search | Busca vetorial híbrida densa e esparsa para melhor recall e relevância. |
| Query on JSON | Fragmentação e indexação JSON integradas para filtragem e consulta rápidas em campos JSON aninhados. |
| Geospatial Search | Busca geoespacial rápida com filtragem por raio, vizinho mais próximo e área. |
| Multi-Vector Search | Busca em múltiplos embeddings gerados a partir de uma ou mais modalidades, com reranking unificado. |
| Vector Search with Filtering | Busca vetorial com filtragem de atributos, otimizada para seletividade de filtro de baixa a alta. |
| Range Search | Retorna todos os vetores dentro de um limite de distância especificado em relação ao vetor de consulta. |
| Iterative Search | Busca iterativa com refinamento da consulta passo a passo com base em resultados intermediários. |
| Multi-Path Retrieval | Recuperação multi-path com múltiplas estratégias, em que cada caminho pode usar qualquer um dos métodos de busca acima. |
bem como recursos de reranking usados em conjunto com a recuperação multi-path.
| Cohere Reranker | Um modelo de reranking cross-encoder que pontua pares consulta–documento com alta precisão semântica para reordenar resultados de recuperação visando máxima relevância. |
|---|---|
| Voyage AI Reranker | Um modelo de reranking leve e de alto throughput, otimizado para pontuação de relevância rápida e econômica em pipelines de recuperação em larga escala. |
| Boost Reranker | Aplica filtros condicionais aos resultados correspondentes e ajusta suas pontuações com um peso especificado para promover ou rebaixar posições no ranking. |
| Decay Reranker | Ajusta as pontuações dos resultados aplicando uma função de decaimento com base em fatores como distância ou tempo, reduzindo gradualmente a relevância à medida que os valores se desviam de um alvo. |
| RRF Reranker | Combina múltiplas listas de resultados ao agregar as posições de ranking de cada item nas listas em um único ranking. |
| Weighted Reranker | Combina pontuações de múltiplas listas de resultados usando pesos configuráveis para produzir um ranking unificado. |
Armazenamento unificado nativo de Lake
O Zilliz Cloud é construído sobre uma arquitetura de armazenamento–computação totalmente desacoplada, com tudo persistido em armazenamento de objetos na nuvem.
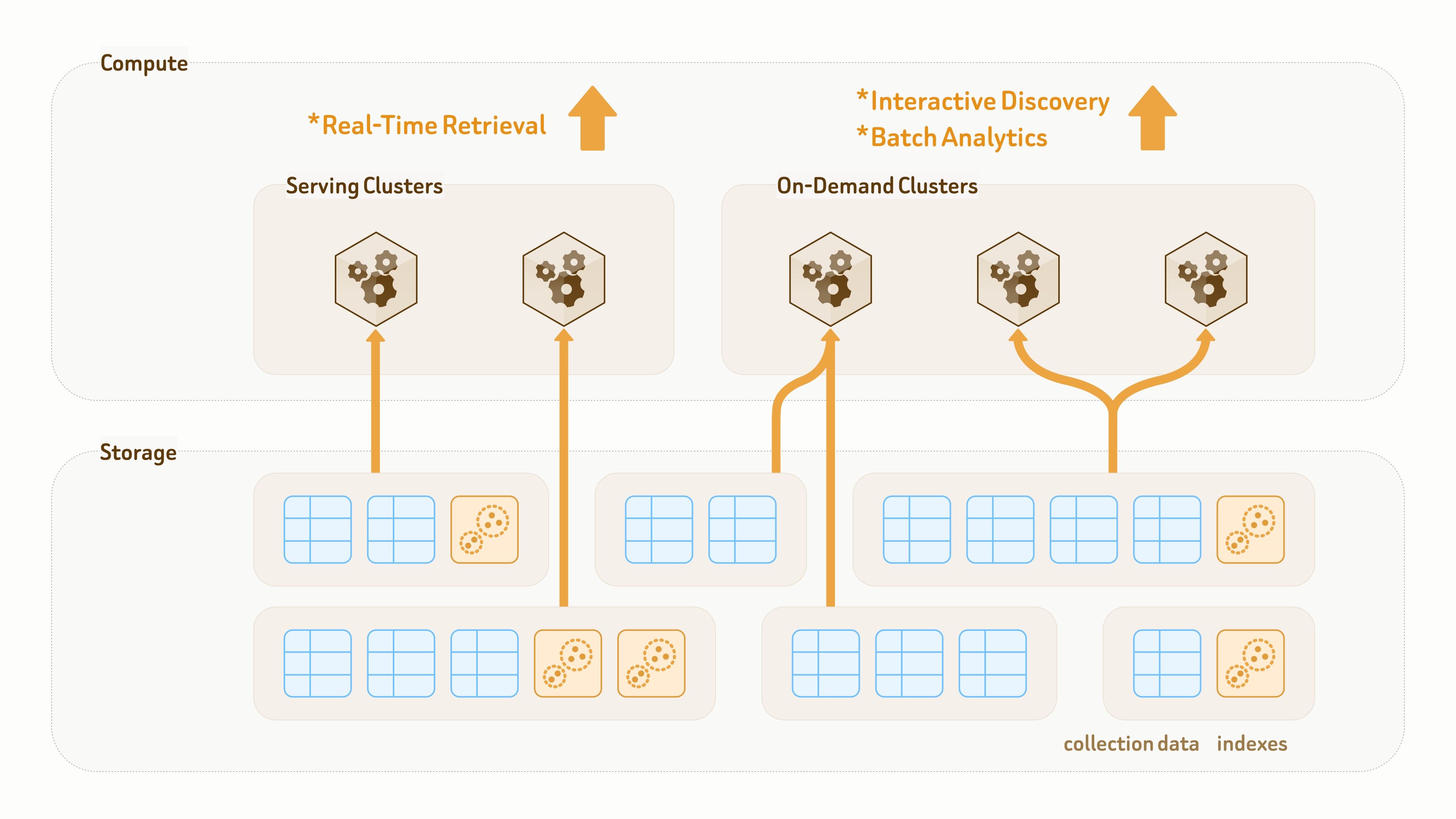
Diferentemente dos data lakes tradicionais, projetados principalmente para armazenamento, a camada de dados do Zilliz Vector Lakebase é projetada tanto para persistência quanto para execução de consultas. Coleções e índices são desacoplados dos clusters de computação, permitindo que os mesmos dados e índices sejam montados por meio de acesso zero-copy por diferentes clusters para diferentes cargas de trabalho de consulta e analytics.
Para aplicações de IA e agentes com modelos de dados em evolução contínua — como a adição frequente de novos rótulos e recursos ou a troca de modelos de embedding — a Zilliz oferece um mecanismo contínuo e de alta velocidade para evolução de schema e backfill de dados.
Novos campos recebem backfill e são alinhados por recursos de computação agrupados da plataforma, depois expostos aos clusters de consulta por meio de atualizações de metadados. Um backfill de 100 milhões de linhas geralmente pode ser concluído em minutos de um dígito.
Como a maior parte do trabalho é tratada por recursos de computação do lado da plataforma, os clusters de usuários existentes permanecem inalterados e podem continuar atendendo tráfego de leitura e gravação durante todo o processo.
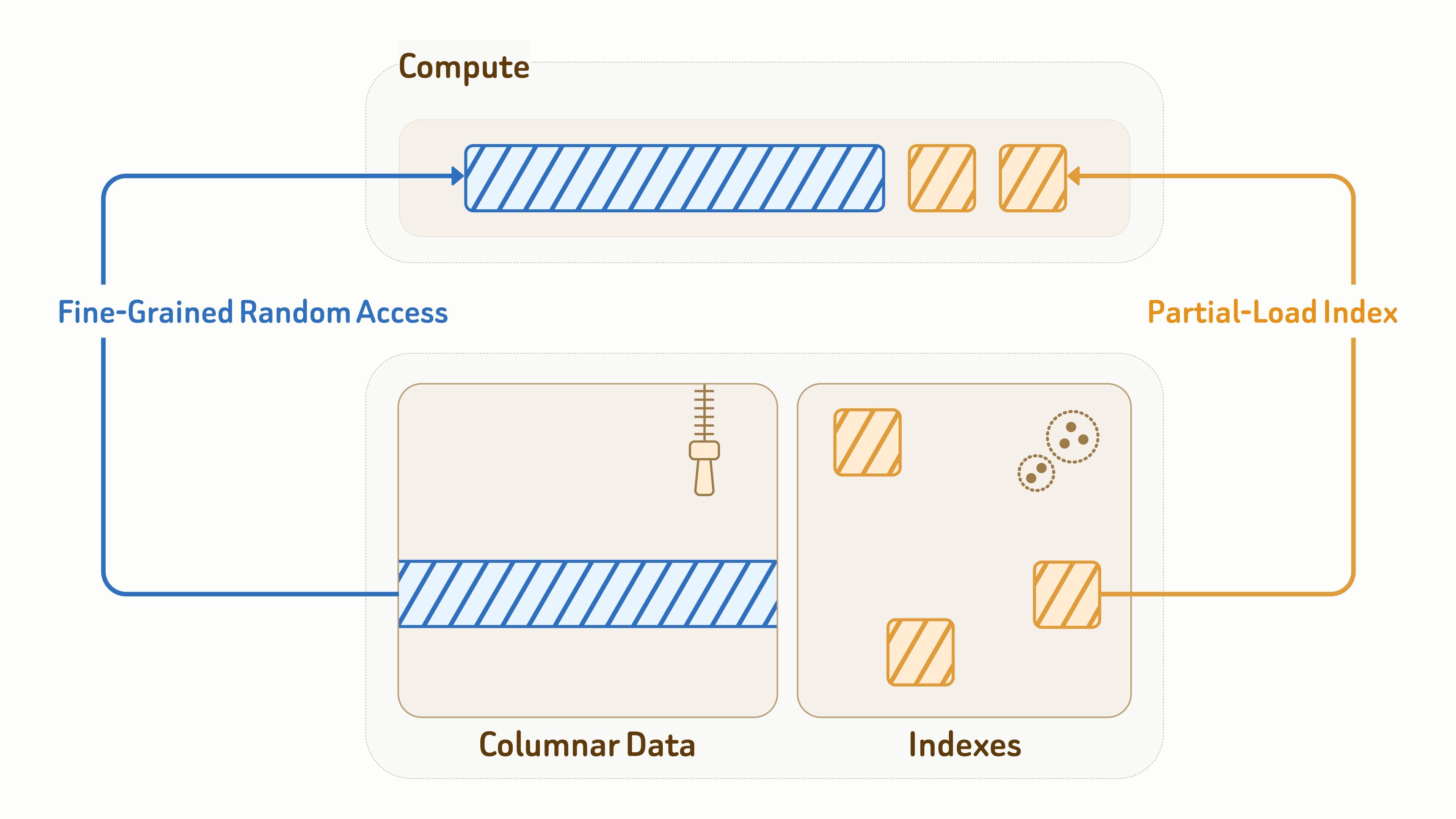
Como a camada de dados também atende diretamente cargas de trabalho de consulta, I/O eficiente é fundamental tanto para latência quanto para throughput.
Para dados de coleção, a Zilliz usa o formato aberto Vortex para layout de armazenamento colunar, combinando codificação eficiente com acesso aleatório granular a fragmentos de dados — significativamente mais rápido que Lance e Parquet para leituras aleatórias.
Para índices, a Zilliz fornece designs de algoritmos de indexação conscientes de armazenamento de objetos, com layouts e padrões de acesso profundamente otimizados para E/S eficiente, incluindo índices vetoriais, índices invertidos BM25 e índices JSON.
Durante a execução de consultas, os nós de computação carregam apenas parcialmente as páginas de índice e as entidades de dados acessadas pela consulta. Combinado com cache e poda de dados, isso reduz significativamente a amplificação de leitura em mais de 90%.
Principais Casos de Uso do Vector Lakebase
Cenários típicos de aplicação para o Vector Lakebase incluem, mas não se limitam a:
Cargas de Trabalho de Serving em Tempo Real:
- Memória de agentes e recuperação de estratégias críticas para latência.
- Bases de conhecimento de domínios verticais para os setores jurídico, de saúde, financeiro e outros setores especializados.
- Mecanismos de busca de IA em escala web.
- Sistemas de recomendação de vazão ultra-alta.
- Agendamento dinâmico de dados quentes/frios em nível de segundos entre camadas de armazenamento.
- Camadas de serviço diferenciadas tanto para usuários corporativos premium quanto para pools de usuários gratuitos em larga escala.
Cargas de Trabalho de Descoberta Iterativa:
- Análise de qualidade de serviços de IA e descoberta de problemas em dados de feedback, notas geradas por agentes, logs e outros dados de múltiplas fontes.
- Exploração eficiente de conjuntos de dados em larga escala.
- Pesquisa profunda iterativa em várias etapas.
Cargas de Trabalho de Análise em Lote:
- Deduplicação e agrupamento de corpus em escala ultra-grande.
- Adição de recursos de busca de espectro completo ao Spark e Ray para filtragem, recuperação e pipelines de consulta em dois estágios, de grosseiro para rerank.
- Preparação de conjuntos de dados para treinamento e ajuste fino.
Casos Híbridos:
- Indexação e recuperação aceleradas em tabelas de data lake existentes, como Lance e Iceberg.
- Modelos de dados em evolução contínua com backfills frequentes em larga escala.
- Modelagem de tabelas largas semânticas multimodais, unificando vetores, metadados, resumos gerados por LLM e campos estruturados em tabelas centradas em entidades, com versionamento consistente e gerenciamento de linhagem.
Experimente o Zilliz Vector Lakebase
Para mais informações sobre o Vector Lakebase e as atualizações mais recentes, visite o site da Zilliz ou explore a documentação do Zilliz Cloud. Se a arquitetura ou os casos de uso deste artigo forem relevantes para o seu trabalho, entre em contato com a equipe da Zilliz para uma discussão técnica mais aprofundada.

Continue lendo

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

Announcing the General Availability of Zilliz Cloud BYOC on Google Cloud Platform
Zilliz Cloud BYOC on GCP offers enterprise vector search with full data sovereignty and seamless integration.