




Exploring the Langchain Community API: Seamless Vector Database Integration with Milvus and Zilliz
This article will explore the LangChain Community API and how it simplifies the process of integrating Milvus and Zilliz for efficient vector database interaction.
Introduction
To unlock the full potential of Large language models, developers need ways to manage and retrieve related information efficiently. This is where vector databases come in. Vector databases excel at handling similar data points, making them ideal for applications powered by LLMs.
The LangChain Community API extends core LangChain functionality by providing additional tools and integrations, including support for vector databases. This integration allows developers to seamlessly leverage powerful vector databases like Milvus and Zilliz within their LangChain applications. This article will explore the LangChain Community API and how it simplifies the process of integrating Milvus and Zilliz for efficient vector db interaction.
Overview of Vector Databases and their Importance
Vector databases are specialized databases designed to store and retrieve high-dimensional vectors efficiently. These vectors can represent various types of data, such as text embeddings, images, audio, or any other data that can be converted into a numerical vector representation.
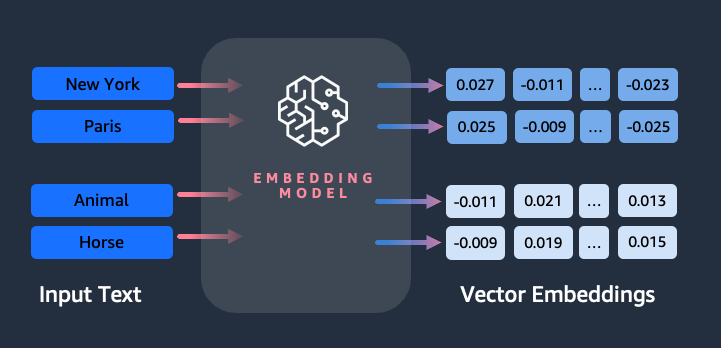
In LangChain and natural language processing (NLP) applications, vector databases are particularly useful for storing and retrieving text embeddings. Text embeddings are numerical representations of text that capture the semantic meaning and context of the text, allowing for efficient similarity comparisons and retrieval. Take a look at the embedding representation below:
{kind=link}
The above high-level diagram shows how an embedding model takes words and converts them into respective vector representations. This allows us to measure the semantic similarity between data points by calculating the distance between their corresponding vectors. Words with similar meanings will have embeddings that reside close to each other in the vector space.
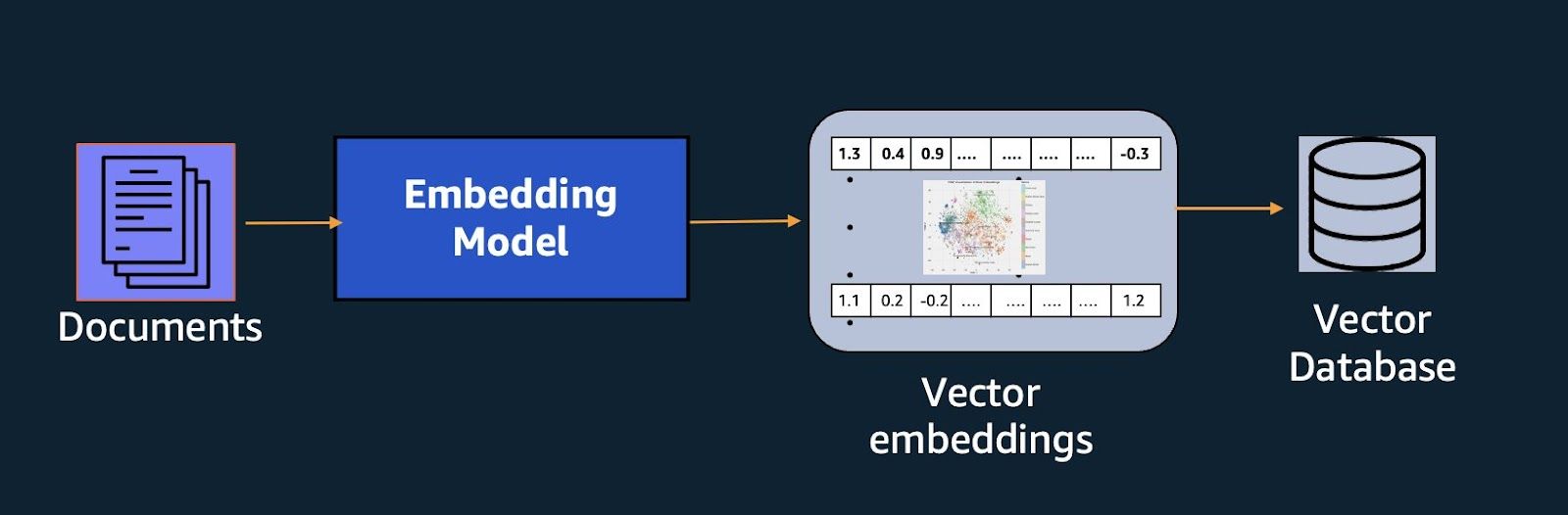
Vector databases like Milvus and Zilliz Cloud, in particular, excel at storing and retrieving related information using vector embeddings as shown below:
{kind=link}
The above diagram shows documents being represented as vector embeddings and the embeddings being stored in a vector db. We can then use the vector db to retrieve the relevant documents for a user query.
By leveraging vector databases, LangChain applications can quickly and accurately retrieve relevant information from large text corpora based on semantic similarity, enabling powerful capabilities such as question-answering, information retrieval, and knowledge extraction.
Why use Milvus and Zilliz
Milvus vector database provides a highly scalable and performant solution for storing and querying large volumes of vector data, making it an ideal choice for applications that require efficient vector similarity search capabilities.
Key features of Milvus include:
Scalability: Milvus can handle billions of vectors and supports horizontal scaling through distributed deployment.
High Performance: Milvus utilizes advanced indexing techniques and parallelization to deliver high-speed vector similarity searches.
Flexible Data Models: Milvus supports various data models, including flat, hierarchical, and hybrid, allowing for efficient storage and retrieval of structured and unstructured data.
Multiple Index Types: Milvus offers several index types, such as HNSW, FLAT, IVF_FLAT, IVF_PQ, and more, enabling users to choose the best index type based on their specific use case and performance requirements.
On the other hand, Zilliz is the cloud-managed version of Milvus. It includes Milvus as its core vector db and adds additional layers of functionality, such as data ingestion, ETL (Extract, Transform, Load) pipelines, and data visualization tools.
Key features of Zilliz include:
Managed Milvus Deployment: Zilliz offers a fully managed Milvus deployment, ensuring optimal performance, scalability, and ease of use.
Data Ingestion Pipelines: Zilliz provides tools and APIs for ingesting and preprocessing data from various sources, streamlining the data preparation process for vector databases.
ETL Workflows: Zilliz supports building complex ETL workflows for transforming and enriching data before storing it in Milvus.
Data Visualization: Zilliz includes data visualization tools that allow users to explore and analyze their vector data, enabling better understanding and interpretation.
Cloud-Native Architecture: Zilliz is designed as a cloud-native platform, ensuring seamless integration with modern cloud computing environments and enabling easy scaling and deployment.
If you want to use the vector db locally on your computer Milvus covers that. On the other hand, if you want a fully managed cloud version of Milvus, opt for Zilliz.
Integrating Milvus and Zilliz with LangChain Community API
The Langchain Community API includes dedicated vector store connectors for both Milvus and Zilliz. This enables seamless vector search and database support within LangChain applications. These integrations allow us to leverage the power of vector databases for efficient retrieval and similarity search capabilities within their LangChain applications.
Setting up Your Environment
To use Milvus or Zilliz in your code, you have to install PyMilvus, which is a Python SDK for interacting with Milvus and Zilliz in a Python environment. Run the following command to install PyMilvus using PiP:
pip install pymilvus
Then install LangChain, LangChain OpenAI, python-dotenv, and Langchain Community API using the following command:
pip install langchain langchain-community langchain-openai python-dotenv
Langchain Community API will provide us with Milvus and Zilliz vector store connectors, Langchain will provide us with a text splitter class, and finally, LangChain OpenAI will allow us to embed our text using the OpenAI embedding model.
Let us import and load dotenv as we will require it throughout the article to load environmental variables:
from dotenv import load_dotenv
load_dotenv()
When the installation of the libraries is finished, ensure a Milvus instance is running before proceeding with the integration step. If you don't have Milvus set up, refer to the Milvus project setup guide.
Integrating Milvus with LangChain Community API
Let us integrate Milvus with LangChain and store embeddings. Begin by importing the required classes from the libraries we installed.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Milvus
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
After importing the classes, we need to declare a variable that will store the OpenAI API key as we will need to authenticate ourselves before accessing the embedding model. To obtain an API Key, follow this article. Then store the API key in an environmental variable which you will then retrieve using this code. It is not mandatory to use the OpenAI embedding model, you can opt for other models.
import os
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
Now we need to load the data we need to store in the Milvus vector database and split it into smaller chunks. This will allow for efficient indexing. After splitting the data initialize the OpenAI embedding model.
loader = TextLoader("/content/vector-databases.txt")
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
Since we now have our data and the embedding model ready, it is time we use the Lanchain-Community API vector store connector to connect to the Milvus database instance and store our data and its embeddings.
milvus_db_integration = Milvus.from_documents(
docs,
embeddings,
connection_args={"host": "localhost", "port": "19530"},
)
The code above will connect to your Milvus localhost instance and store the split documents together with their embeddings.
To ensure the connection was successful, let us pass a query and conduct a similarity search on the vector store.
query = "What are vector stores?"
docs = milvus_db_integration.similarity_search(query)
docs[0].page_content
The output of the above code is as shown below:

We can see that the first related document retrieved is similar to the query about the vector stores, hence the Integration was successful.
Integrating Zilliz with LangChain Community API
In the example in the previous section, the integration used a Milvus instance locally hosted on your computer. This section will cover integrating Zilliz, a fully managed Milvus version hosted on the cloud with the LangChain Community API.
For this integration, you will need Zilliz connection credentials. You can acquire yours by signing up for a Zilliz account. After signing up, you will receive $100 worth of free credits valid for thirty days. Continue to create a cluster and obtain the connection credentials.

You are now ready to start the integration process. The integration process is very similar to that of integrating Milvus with a few changes.
Start by importing the required modules.
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Zilliz
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import CharacterTextSplitter
Then set the required Zilliz and OpenAI environmental variables. Don't forget to add the Zilliz login credentials to your .env file.
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ZILLIZ_CLOUD_URI = os.getenv("ZILLIZ_CLOUD_URI")
ZILLIZ_CLOUD_API_KEY = os.getenv("ZILLIZ_CLOUD_API_KEY")
Proceed to initialize the OpenAI embeddings, load your document, and split the content into chunks as we did with Milvus.
embeddings = OpenAIEmbeddings()
loader = TextLoader('/content/vectot-databases.txt')
documents = loader.load()
# Split the documents into chunks
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
Now connect to your cluster and pass your chunks, embeddings, and connection credentials to integrate Zilliz with Langchain Community API.
vectorstore = Zilliz.from_documents(
documents=docs,
embedding=embeddings,
connection_args={
"uri": ZILLIZ_CLOUD_URI,
"token": ZILLIZ_CLOUD_API_KEY,
"secure": True,
},
auto_id=True,
drop_old=True,
)
Let us pass a query and conduct a similarity search on the vector store to ensure the connection was successful.
query = "What are vector stores?"
docs = vectorstore.similarity_search(query)
docs[0].page_content
When the similarity search is complete, the following results are printed.
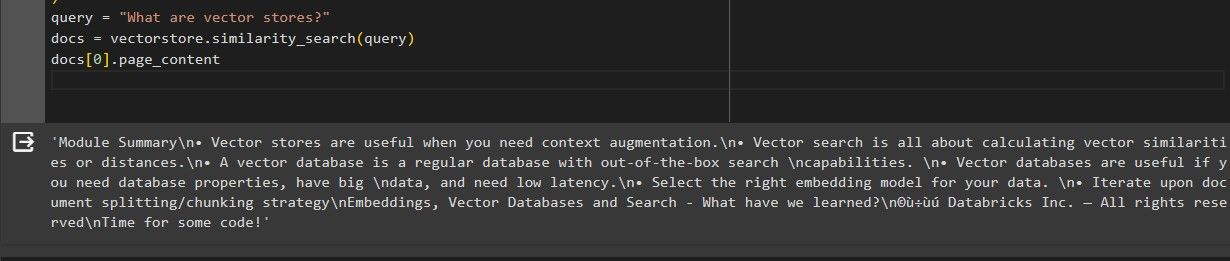
We can see that the first related document retrieved is similar to the query about the vector stores, hence the Integration was successful.
You can also access the stored information on your Zilliz account under the Data Preview section.
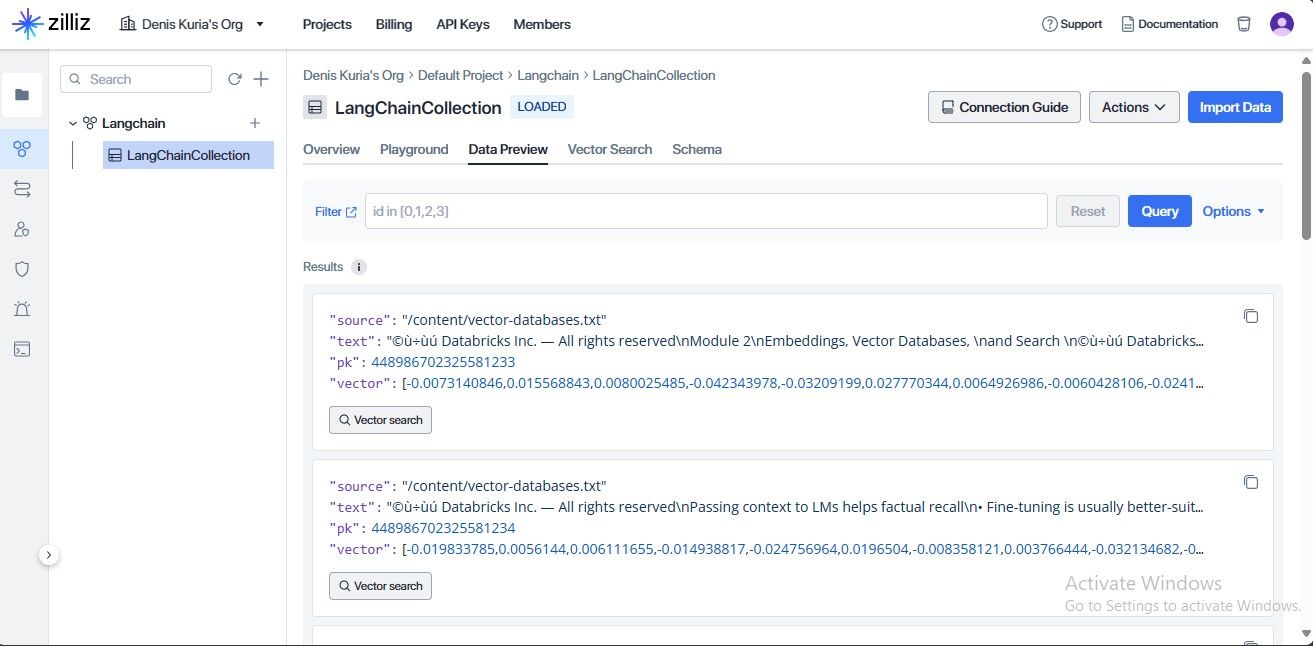
We can see the Integration was successful and the data and its embeddings were stored.
Practical Examples and Use Cases
The integration of Milvus and Zilliz with the LangChain Community API opens up a wide range of practical use cases and applications. Here are a few examples:
Question Answering Systems: By combining LangChain's question-answering capabilities with the efficient vector retrieval provided by Milvus or Zilliz, developers can build powerful question-answering systems that can quickly find relevant information from large text corpora.
Document Similarity and Clustering: LangChain applications can leverage vector databases to perform efficient document similarity comparisons and clustering, enabling tasks such as deduplication, topic modeling, and document organization.
Knowledge Base Construction: Vector databases can be used to build rich knowledge bases by storing and retrieving text embeddings representing various concepts, entities, and relationships, enabling advanced knowledge extraction and reasoning capabilities within LangChain applications.
Personalized Content Recommendation: By combining text embeddings with user preference vectors stored in a vector database, LangChain applications can provide personalized content recommendations based on semantic similarity.
Conversational AI: Vector databases can enhance the capabilities of conversational AI systems built with LangChain by enabling efficient retrieval of relevant context and information from large knowledge bases.
Let us implement a simple retrieval augmented generation (RAG) system covering the knowledge base construction and question-answering use cases.
Developing the RAG System
We will use the Zilliz vector store to implement similarity search as the Zilliz cloud is faster in retrieval compared to a locally hosted Milvus instance.
Importing the Required Modules
Start by importing the required modules. Notice we also import PyPDF from the LangChain Community API document retriever module as our system will handle both text and PDF files.
pip install pypdf
import os
from langchain_openai import OpenAI
from langchain_community.vectorstores import Zilliz
from langchain_community.document_loaders import TextLoader, PyPDFLoader
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain.prompts import PromptTemplate
We also import the Prompt Template class for guiding the LLM in generating responses. The RunnablePassthrough class is for building the RAG pipeline and the StrOutputParser class is for parsing the output from the LLM into a usable format.
Setting Up Environment Variables
Then define the environment variables needed to access OpenAI and Zilliz cloud services.
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
ZILLIZ_CLOUD_URI = os.getenv("ZILLIZ_CLOUD_URI")
ZILLIZ_CLOUD_API_KEY = os.getenv("ZILLIZ_CLOUD_API_KEY")
It's important to note that you should not expose these API keys in your code for security reasons.
Initializing OpenAI LLM and Embeddings
The LLM is the AI model that will be used to generate responses, and the embedding model is used to convert text data into numerical representations suitable for storage and retrieval by the Zilliz vector database.
llm = OpenAI(temperature=0.1)
embeddings = OpenAIEmbeddings()
The temperature parameter controls the randomness of the LLM's generated text (lower values result in more conservative outputs).
Loading and Splitting the Documents
Load a PDF or text file file that you would like to chat with.
file_path = '/content/vector-databases.pdf,' # Change this to your file path
if file_path.endswith('.txt'):
loader = TextLoader(file_path)
elif file_path.endswith('.pdf'):
loader = PyPDFLoader(file_path)
else:
raise ValueError("Unsupported file type. Please provide a .txt or .pdf file.")
documents = loader.load()
Then split the contents of the loaded document using the RecursiveCharacterTextSplitter, which splits the documents based on character count with a specified overlap to avoid missing information at chunk boundaries.
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
These are the chunks we will use for generating embeddings.
Defining the Prompt Template and Creating the Prompt Object
Start by defining a prompt template that instructs the LLM on how to behave. You can modify the template to your liking.
PROMPT_TEMPLATE = """
Human: You are a helpful assistant, and provide answers to questions using provided context. Use the following pieces of information to provide a concise answer to the question enclosed in <question> tags. If you don't know the answer, just say that you don't know, don't try to make up an answer.
<context> {context} </context>
<question> {question} </question>
Assistant:"""
Then, create a prompt template instance.
prompt = PromptTemplate(
template=PROMPT_TEMPLATE,
input_variables=["context", "question"]
)
The code creates a PromptTemplate object using the defined template string (PROMPT_TEMPLATE) and specifies the input variables (context and question) that will be used to fill in the placeholders within the template.
Initializing the Zilliz Vector Store
Initialize the Zilliz vector store which will store the embeddings and enable efficient retrieval based on semantic similarity. This acts as our knowledge base.
vectorstore = Zilliz.from_documents(
documents=docs,
embedding=embeddings,
connection_args={
"uri": ZILLIZ_CLOUD_URI,
"token": ZILLIZ_CLOUD_API_KEY,
"secure": True,
},
auto_id=True,
drop_old=True,
)
The code drops any existing data in the vector store before populating it with the new documents.
Creating a Retriever and Formatting the Retrieved Documents
Create a retriever object from the Zilliz vector store. The retriever will be used to search for relevant documents based on a given query.
retriever = vectorstore.as_retriever()
Then, define a helper function format_docs that takes a list of retrieved documents and joins their page content (assuming they have a page_content attribute).
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
The function doubles newlines for better readability.
Building and Invoking the RAG Chain
Build the core Retrieval-Augmented Generation (RAG) chain. RAG systems combine document retrieval with LLM generation for improved response quality.
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
Here's how the chain works:
"context": retriever | format_docs: Retrieves relevant documents from the Zilliz store using the retriever and formats the retrieved documents."question": RunnablePassthrough(): This part allows the user-provided question to be passed through the chain without modification.| prompt: Applies the defined prompt template (prompt) to the context and question.| llm: Sends the prompted text to the OpenAI LLM for generating the response.| StrOutputParser(): Parses the LLM output into a string format.
Finally, invoke the RAG chain to chat with your document.
question = "what are vecore stores?"
response = rag_chain.invoke(question)
print(response)
Here are the results obtained from invoking the RAG chain.

From the results, we can see the response obtained is a direct answer to our question. This is because we built our system to be a question-answering system with a Zilliz vector store knowledgebase.
Conclusion
Integrating Milvus and Zilliz with LangChain via the Community API empowers developers to leverage efficient LangChain similarity search for information retrieval in their NLP applications. This paves the way for innovative use cases like question-answering knowledge-base construction and many more.
Go ahead and try to implement more practical use cases for similarity search!
Further Resources
You can obtain the full source code in this notebook.
LangChain Integration, Build Retrieval-Augmented Generation applications with Zilliz Cloud
https://python.langchain.com/docs/integrations/vectorstores/milvus/
https://api.python.langchain.com/en/latest/community_api_reference.html#
https://python.langchain.com/docs/integrations/vectorstores/zilliz/
https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
- Introduction
- Overview of Vector Databases and their Importance
- Why use Milvus and Zilliz
- Integrating Milvus and Zilliz with LangChain Community API
- Practical Examples and Use Cases
- Developing the RAG System
- Conclusion
- Further Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Introduction to LangChain
Discover the capabilities of LangChain, enhancing user interactions and driving innovation in AI-powered applications.

LangChain Memory: Enhancing AI Conversational Capabilities
This article explores the memory capabilities of modern LLMs, using LangChain modules to establish memory buffers and build conversational AI applications.

Langchain Tools: Revolutionizing AI Development with Advanced Toolsets
LangChain tools and Milvus redefine the boundaries of what’s achievable with AI.