




Getting Started with LlamaIndex
Large language models (LLMs) made a huge splash in the AI scene in 2022 with the release of GPT. Since then, many people have been vying to make the next big thing via LLM applications. Others are making the tools to make LLM applications easier, better, faster, and more robust. LlamaIndex is one of the best tools for accelerating and expanding the use cases for LLMs.
We've already covered one way to make your LLMs better through agents using Auto-GPT. Now let's take a look at how to use LlamaIndex. In this post, we'll cover the following:
- What is LlamaIndex?
- The Indexes in LlamaIndex
- List Index
- Vector Store Index
- Tree Index
- Keyword Index
- The Basics of How to Use LlamaIndex
- Querying the LlamaIndex Vector Store Index
- Saving and Loading Your Index
- What Can You Make with LlamaIndex?
- LlamaIndex vs. Langchain
- A Summary of Our LlamaIndex Overview
What is LlamaIndex?
In our post about the ChatGPT + Vector Database + Prompt as Code (CVP) stack, we point out that one of the many challenges in using LLMs is the lack of domain-specific knowledge. Therefore, we introduce the CVP stack to inject domain knowledge into LLM applications. Like the CVP stack, LlamaIndex helps address LLMs' lack of domain-specific knowledge by injecting data.
LlamaIndex is a user-friendly, flexible data framework connecting private, customized data sources to your large language models (LLMs). Opening up the black box a bit, we can think of LlamaIndex as a managed interaction between you and an LLM. LlamaIndex takes some input data you provide and builds an index around it. Then it uses that index to help answer any questions related to the input data. LlamaIndex can build many types of indexes depending on the task at hand. You can use it to build a vector index, a tree index, a list index, or a keyword index.
“ You can think of LlamaIndex as a black box around your data and LLM. Jerry Liu Co-founder and CEO of LlamaIndex
The Indexes in LlamaIndex
Let's take a closer look at the indices you can build with LlamaIndex, how they work, and what sorts of use cases would best fit each. At their core, all of the index types in LlamaIndex are made up of “nodes”. Nodes are objects that represent a chunk of text from a document.
List Index
 List index
List index
As the name suggests, a list index is an index that is represented like a list. First, the input data gets chunked into nodes. Then, the nodes are lined up sequentially. The nodes are also queried sequentially if no additional parameters are specified at query time. In addition to basic sequential querying, we can query the nodes using keywords or embeddings.
List indexing offers you a way to sequentially query along your input. LlamaIndex provides an interface to automatically use the entirety of your input data even if it exceeds the LLM's token limit. How does that work? Under the hood, LlamaIndex is querying with the text from each node, and refining the answers based on additional data as it goes down the list.
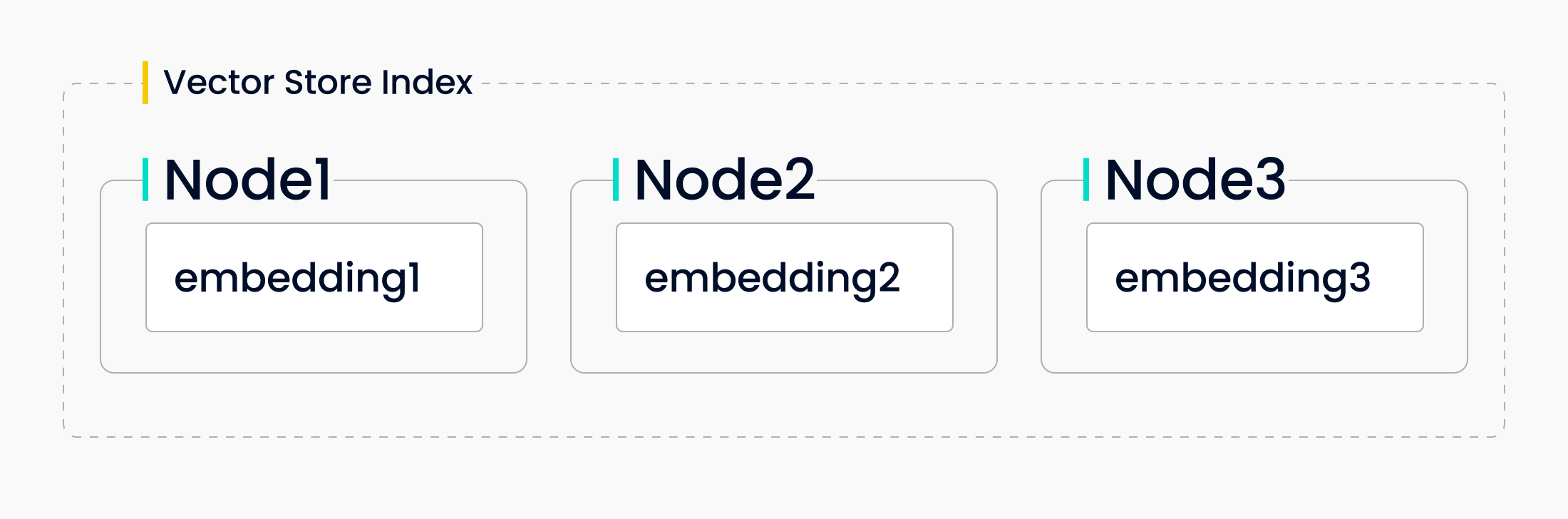
Vector Store Index
 Vector Store Index
Vector Store Index
The next index that LlamaIndex offers is a vector store index. This type of index stores the nodes as vector embeddings. LlamaIndex offers a way to store these vector embeddings locally or with a purpose-built vector database like . When queried, LlamaIndex finds the top_k most similar nodes and returns that to the response synthesizer.
Using a vector store index lets you introduce similarity into your LLM application. This is the best index for when your workflow compares texts for semantic similarity via vector search. For example, if you want to ask questions about a specific type of open-source software, you would use a vector store index.
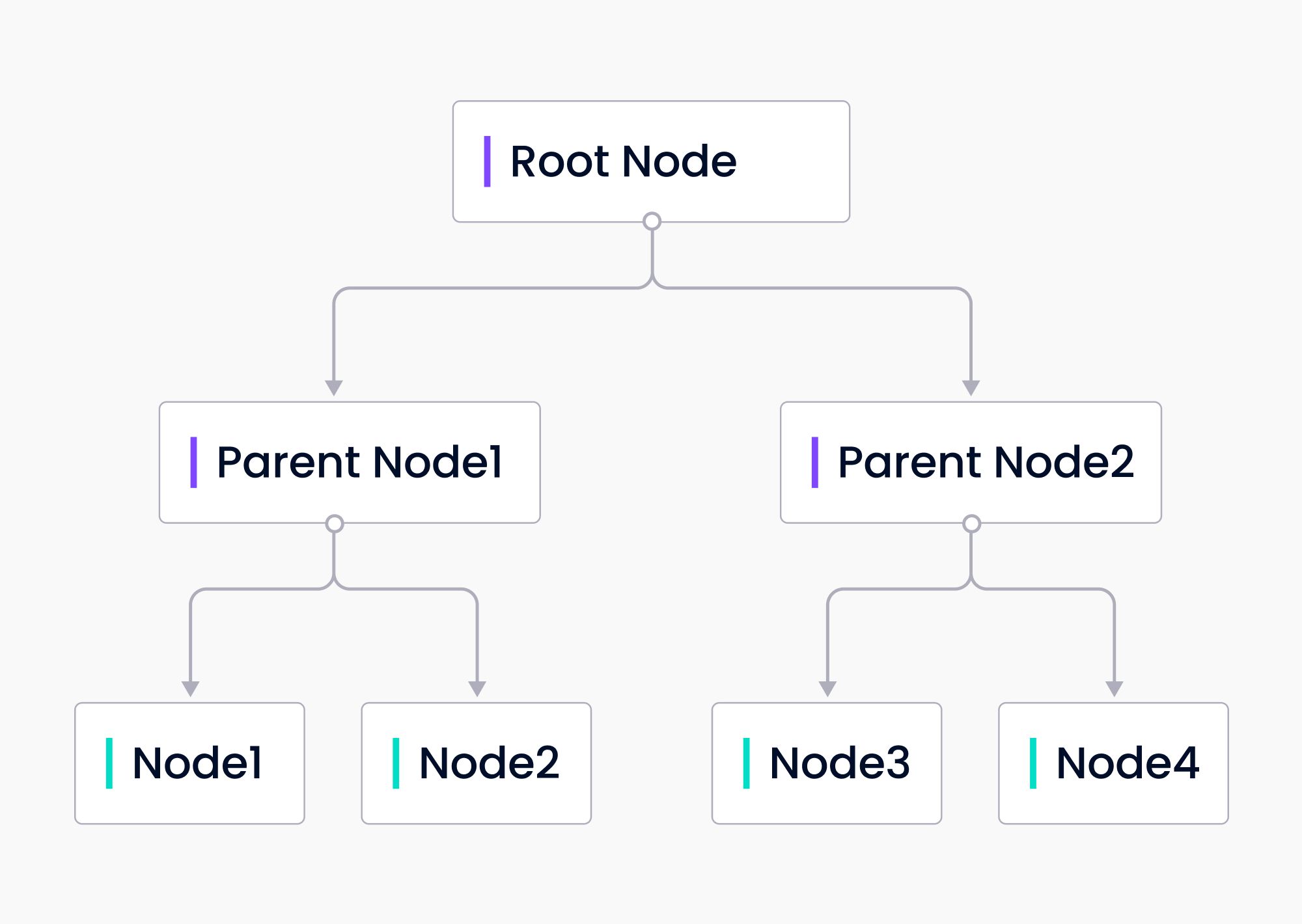
Tree Index
 Tree Index
Tree Index
A tree index builds a tree out of your input data. The tree index is built bottom-up from the leaf nodes, the original input data chunks. Each parent node is a summary of the leaf nodes. LlamaIndex uses GPT to summarize the nodes to build the tree. Then when building a response to a query, the tree index can traverse down through the root node to the leaf nodes or build directly from chosen leaf nodes.
The tree index offers a more efficient way to query long chunks of text. It can also be used to extract information from different parts of the text. Unlike the list index, a tree index does not need to be queried sequentially.
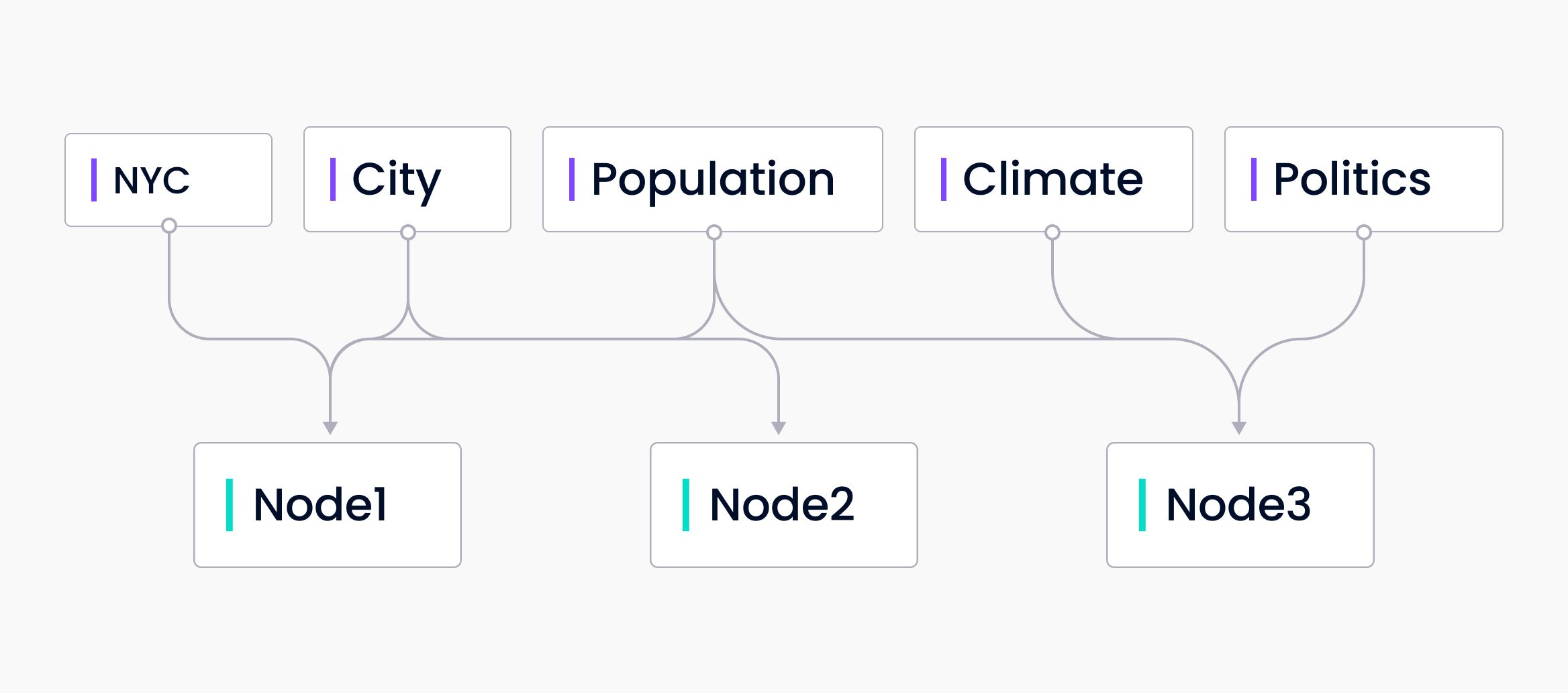
Keyword Index
 Keyword index
Keyword index
Finally we come to the keyword index. The keyword index is a map of keywords to nodes that contain those keywords. This is a many-to-many mapping. Each keyword may point to multiple nodes and each node may have multiple keywords that map to it. During query time, keywords are extracted from the query and only the mapped nodes are queried.
The keyword index provides a more efficient way to query large amounts of data for certain keywords. This is most useful when you know what the user is querying for. For example, if you’re querying through health care related documents and you only care about documents related to COVID 19.
Creating and Managing Vector Store Indexes
Creating and managing vector store indexes is a crucial step in building a RAG system with LlamaIndex. A vector store index class is a combination of a base vector store index class and a vector store, and can be used to build indexes on top of existing vector stores. The base vector store index is a fundamental component of vector store index classes, and is used to store node objects in the index store and document store.
To create a vector store index, you can use the VectorStoreIndex class, which accepts a list of node objects and builds an index from them. Node objects are lightweight abstractions over text strings that keep track of metadata and relationships, and can be created and defined manually or using the ingestion pipeline.
Once a vector store index is created, it can be used to store and retrieve data efficiently. LlamaIndex supports dozens of vector stores, and the vector store to use can be specified by passing a StorageContext with the vector_store argument. The load_documents function can be used to load a set of documents and build an index from them, and the insert_batch_size parameter can be modified to use persistent vector stores.
In addition to creating and managing vector store indexes, LlamaIndex also provides a range of features for customizing and optimizing the indexing process. The use_async parameter can be used to enable asynchronous calls, and the store_nodes_override parameter can be used to always store node objects in the index store and document store, even if the vector store keeps text.
By using LlamaIndex to create and manage vector store indexes, you can build fast and accurate RAG systems that can handle large amounts of data. Whether you’re working with text, images, or other types of data, LlamaIndex provides a powerful and flexible framework for building and managing vector store indexes.
How to Use LlamaIndex
Now that we understand what the “index” in LlamaIndex refers to, let's take a look at how to use the vector store index. This section covers the basics of how to load a text file into LlamaIndex, query the file, and save your index. If you want to quickly grab this code, it is available at this Google Colab Notebook. You can grab the data provided or clone the LlamaIndex repo and navigate to the examples/paul_graham_essay to use the example code provided.
Before you can use LlamaIndex, you’ll need to access an LLM. By default, LlamaIndex uses GPT. You can get an OpenAI API key from their website. In the example code, I load my OpenAI API key from a .env file. However, you may directly input your key for your example locally if you’d like. Remove your key from the code before uploading it anywhere though!
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
To get started with the basics, we only need to import two libraries from LlamaIndex. GPTVectorStoreIndex and SimplyDirectoryReader. This example uses the data and folder structure from the Paul Graham Essay example provided in the LlamaIndex repo. If you did not clone the repo, create a folder called data in your working directory for the code below to work.
The first step is to load the data. We call the load_data() function from SimpleDirectoryReader on the name of the directory containing the data. In this case, data. You can pass in an absolute or relative file path here.
Next, we need the index. We can create the index by calling from_documents from GPTVectorStoreIndex on the documents we just loaded.
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
Querying the LlamaIndex Vector Store Index
As mentioned above, a vector store index is great when you need to do similarity searches. In this example, we give LlamaIndex a query that requires an understanding of the meaning behind the text. We ask “What did the author do growing up?”. This requires LlamaIndex to interpret the text and what “growing up” means.
query_engine = index.as_query_engine()
response=query_engine.query("What did the author do growing up?")
print(response)
You should see a response:
The author grew up writing short stories, programming on an IBM 1401, and nagging his father to buy a TRS-80 microcomputer. …
Saving and Loading Your Index
When working on examples, saving your index isn’t important. For practical purposes, you want to save your index most of the time. Saving your index saves on GPT tokens and lowers your LLM cost. Saving your index is remarkably easy. Call .storage_context.persist() on your index.
index.storage_context.persist()
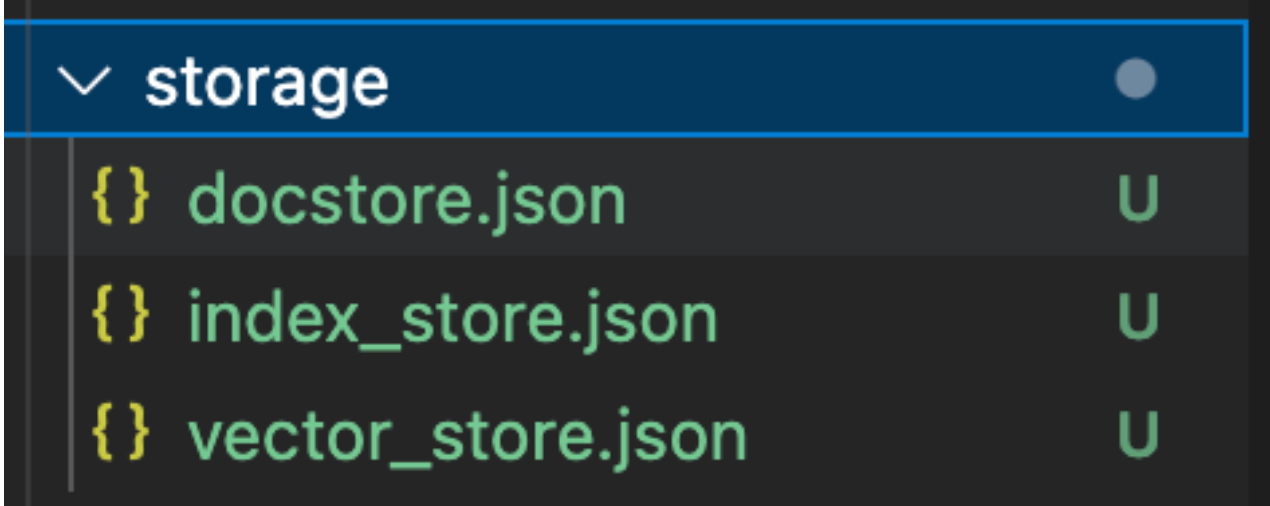 storage
storage
This creates a folder called storage that contains three files: docstore.json, index_store.json, and vector_store.json. These files contain the documents, the index metadata, and the vector embeddings respectively. If you need a more scalable version, you probably want a vector database as your vector index store.
The point of saving your index is so you can load it later. To load an index, we need two more imports from llama_index. We need StorageContext and load_index_from_storage. To rebuild the storage context, we pass the persistent storage directory to the StorageContext class. Once we’ve loaded the storage context, we call the load_index_from_storage function on it to reload the index.
from llama_index import StorageContext, load_index_from_storage
# rebuild storage context
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# load index
index = load_index_from_storage(storage_context)
What Can You Make with LlamaIndex?
The section above only begins to show the capabilities of LlamaIndex. You can use it to build many different types of projects. Examples of projects you can make using LlamaIndex include Q/A applications, full-stack web apps, text analytics projects, and more.
You can find a LlamaIndex app showcase here.
LlamaIndex vs. LangChain
LangChain is a framework centered around LLMs that offers a wide range of applications, such as chatbots, Generative Question-Answering (GQA), summarization, and more. The fundamental concept behind this framework is the ability to chain together various components, and enable the creation of sophisticated functionalities and use cases based on LLMs. These chains may consist of multiple components from several modules, including LLMs, memory, agents, and prompt templates.
While there may be some overlap, LllamaIndex doesn’t utilize agents/chatbots/prompt management/etc., rather, it focuses on going deep into indexing and efficient information retrieval for LLM's. LlamaIndex can be used as a retrieval/tool in LangChain and provides tool abstractions so you can use a LlamaIndex query engine along with a LangChain agent. It also allows you to use any data loader within the LlamaIndex core repo or in LlamaHub as an “on-demand” data query Tool within a LangChain agent.
LLamaIndex Summary
In this post, we learned about what an “index” in LlamaIndex is, went over a basic tutorial on how to use LlamaIndex, and learned about some of its use cases. We also covered the indexes in LlamaIndex: a list index, a vector store index, a tree index, and a keyword index. This makes it ideal for connecting vector databases like Zilliz with unstructured data or even structured or semi-structured data sources for conducting rapid queries at scale.
In our basic tutorial, we showed how to create an index from some input data, query a vector store index, and save and load an index. Finally, we looked at some examples of projects you can create with LlamaIndex which include chatbots, web apps, and more.
 Yujian Tang
Yujian TangYujian Tang is a Developer Advocate at Zilliz. He has a background as a software engineer working on AutoML at Amazon. Yujian studied Computer Science, Statistics, and Neuroscience with research papers published to conferences including IEEE Big Data. He enjoys drinking bubble tea, spending time with family, and being near water.
- What is LlamaIndex?
- The Indexes in LlamaIndex
- Creating and Managing Vector Store Indexes
- How to Use LlamaIndex
- Querying the LlamaIndex Vector Store Index
- What Can You Make with LlamaIndex?
- LlamaIndex vs. LangChain
- LLamaIndex Summary
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free

