




Milvusインスタンスでベクターインデックスを選ぶ方法:ビジュアルガイド
この投稿では、大量のデータと考慮すべき複数の制約があるシナリオでも、効率的に類似性検索を実行するために使用できる、いくつかのベクトル・インデックス戦略を探ります。
シリーズ全体を読む
- 楽々AIワークフロー:Hugging FaceとPyMilvusの初心者ガイド
- MilvusとHaystack 2.0によるRAGパイプラインの構築
- Milvusインスタンスでベクターインデックスを選ぶ方法:ビジュアルガイド
- MilvusとOpenAIによるセマンティック検索
- GCP KubernetesでMilvusを効率的にデプロイする:オープンソースデータベース管理ガイド
- 北極雪片とMilvus上のトランスフォーマーでRAGを作る
- MilvusでJSONデータをベクトル化し、類似性検索を行う
- Gemini 1.5、BGE-M3、Milvus Lite、LangChainによるマルチモーダルRAGの構築
類似性検索は、データサイエンスやAIアプリケーションの最も一般的な実世界での使用例の一つとして浮上してきた。推薦システム、情報検索、文書クラスタリングなどのタスクは、そのコアアルゴリズムとして類似性検索に依存している。
健全な類似検索システムは、正確な結果を迅速かつ効率的に提供しなければならない。しかし、データ量が増大するにつれて、これらの要件をすべて満たすことはますます困難になる。したがって、類似検索タスクのスケーラビリティを向上させるアプローチや技術が必要となる。
この投稿では、大量のデータと考慮すべき複数の制約があるシナリオでも、効率的に類似性検索を実行するために使用できる、いくつかのベクトル・インデックス作成戦略を探ります。
ベクターインデックスとは?
自然言語処理(NLP)の重要な実世界アプリケーションである類似検索は、テキストを入力データとして扱う場合に特に重要です。機械学習モデルは生のテキストを直接処理することができないため、これらのテキストはベクトル埋め込みに変換される必要があります。
BM25、Sentence Transformers、OpenAI、BG3、SPLADEを含むいくつかのモデルは、生のテキストを埋め込みに変換することができる。
いったんベクトル埋め込みが集まれば、内積、余弦距離、ユークリッド距離、ハミング距離、ジャカード距離など、様々な距離メトリックスを用いて、ある埋め込みと別の埋め込みとの距離を計算することができる。
類似検索の一般的なワークフローは以下の通りです:
1.データベース(通常、専用のベクトル・データベース)に埋込みデータのコレクションを格納する。
2.ユーザからのクエリが与えられたら、そのクエリを埋め込みに変換する。
3.クエリの埋め込みと、データベース内の各埋め込みの間の類似性探索を、距離計算によって行う。
4.距離の最も小さい埋め込みを、ユーザのクエリに最も関連性の高い埋め込みとする。
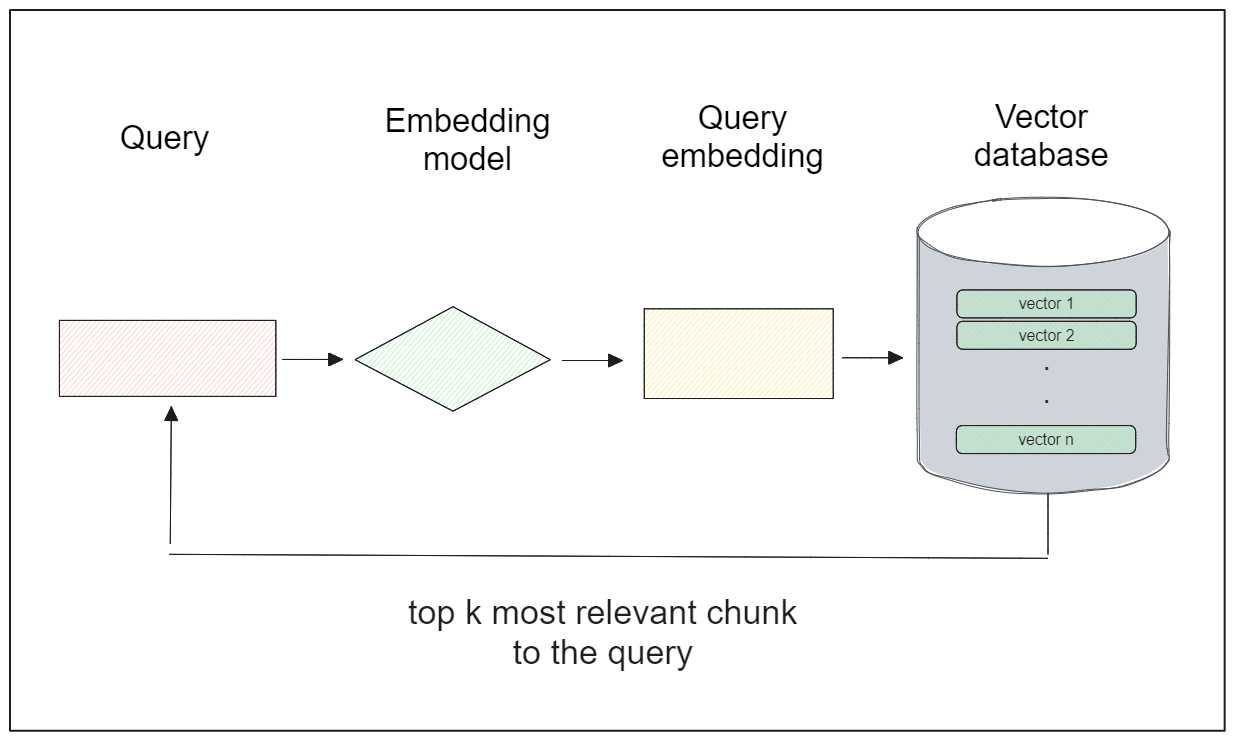
インデックスと呼ばれる特別なデータ構造は、類似の埋め込みを効率的に検索・取得するために、ベクトルデータベース内の各埋め込みの上に構築されます。
私たちの特定のユースケースに合うように、いくつかのインデックス戦略を適用することができます。一般的には、ツリーベース、グラフベース、ハッシュベース、量子化ベースの4つのインデックス戦略がある。
各手法にはそれぞれ長所と短所があり、以下の表はその選択に役立つ便利なインデックス・チートシートです。
| :----------------------------------------------------------------------------------------------------------:| :-----------------------------------------------------------------------:| :----------:| :---------:| :------------:| :------------:| :-------:| | カテゴリ** | インデックス | 精度 | レイテンシ | スループット | インデックス時間 | コスト | | グラフベース|Cagra (GPU)|高い|低い|非常に高い|速い|非常に高い | HNSW | 高い | 低い | 高い | 遅い | 高い | 高い | 高い | DiskANN](https://zilliz.com/learn/DiskANN-and-the-Vamana-Algorithm)|高|高|中|非常に遅い|低|||。 | 量子化ベースまたはクラスター・ベース](https://zilliz.com/learn/scalar-quantization-and-product-quantization) | ScaNN| Mid| Mid| High| Mid| Mid| | | IVF_FLAT|中|中|低|高速|中|低 | IVF+量子化|低|中|中|低|低|低
図1:インデックスのカンニングペーパー|Zilliz
注:この表には、FAISS、ハッシュベースのインデックス(locality-sensitive hashing)、ツリーベースのインデックス(ANNOY)は含まれていません。
以下のセクションでは、Milvusがサポートするインデックスアルゴリズムのうち、これら4つのカテゴリに基づくものについて説明します。
Milvusがサポートする一般的なインデックスタイプ
Milvusはいくつかのインデックスアルゴリズムをサポートしており、特定のユースケースに基づいて選択することができます。まず、最も基本的なFLATインデックスから始めましょう。
FLATインデックス
FLATインデックスは、k-最近傍(kNN)アルゴリズムを利用した単純明快な類似性検索アルゴリズムである。
Qに最も類似した埋め込みを見つけるために、kNNは、指定された距離メトリックを用いて、Qとデータベース内の各埋め込みとの間の距離を計算します。そして、距離が最も小さい埋め込みを、Qに最も類似した埋め込みとして特定する。
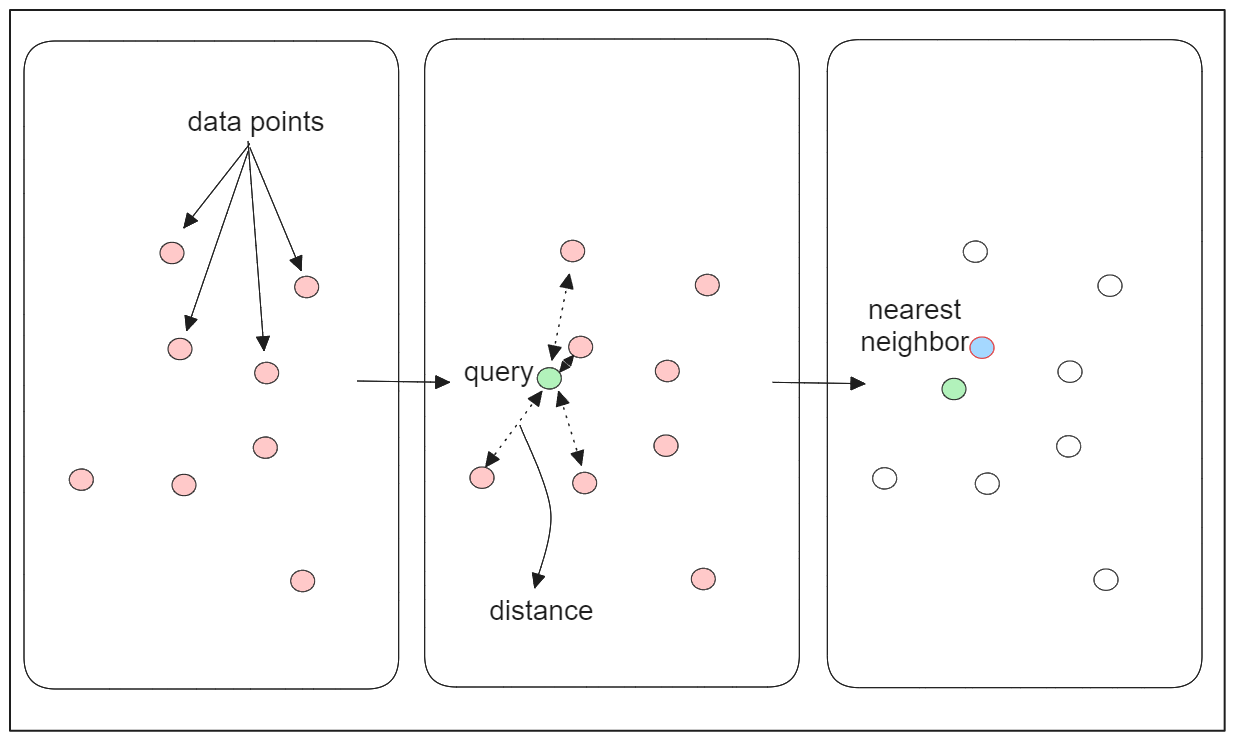
kNNは網羅的な探索によって高い精度の結果を保証する反面、そのスケーラビリティが懸念される。このアルゴリズムによるベクトル探索の複雑さは、データベース内のベクトル埋め込み数に比例して増加します。
数百万から数十億の埋め込みをデータベースで扱う場合、この手法によるベクトル探索の実行には時間がかかる。また、この手法にはベクトル圧縮の技術がないため、RAMに収まりきらない数百万の埋め込みを保存しようとしたときに問題になる可能性があります。
反転ファイルFLAT(IVF-FLAT)インデックス
反転ファイルFLAT(IVF-FLAT)インデックスは、ネイティブのkNNの代わりに近似最近傍(ANN)アルゴリズムを実装することで、基本的なFLATインデックスの検索性能を向上させることを目的としています。IVF_FLATは、データベース内の埋め込みデータを、交差しない複数のパーティションに分割することで動作する。各パーティションはセントロイドと呼ばれる中心点を持ち、データベース内の全ての埋め込みベクトルは、最も近いセントロイドに基づく特定のパーティションに関連付けられる。
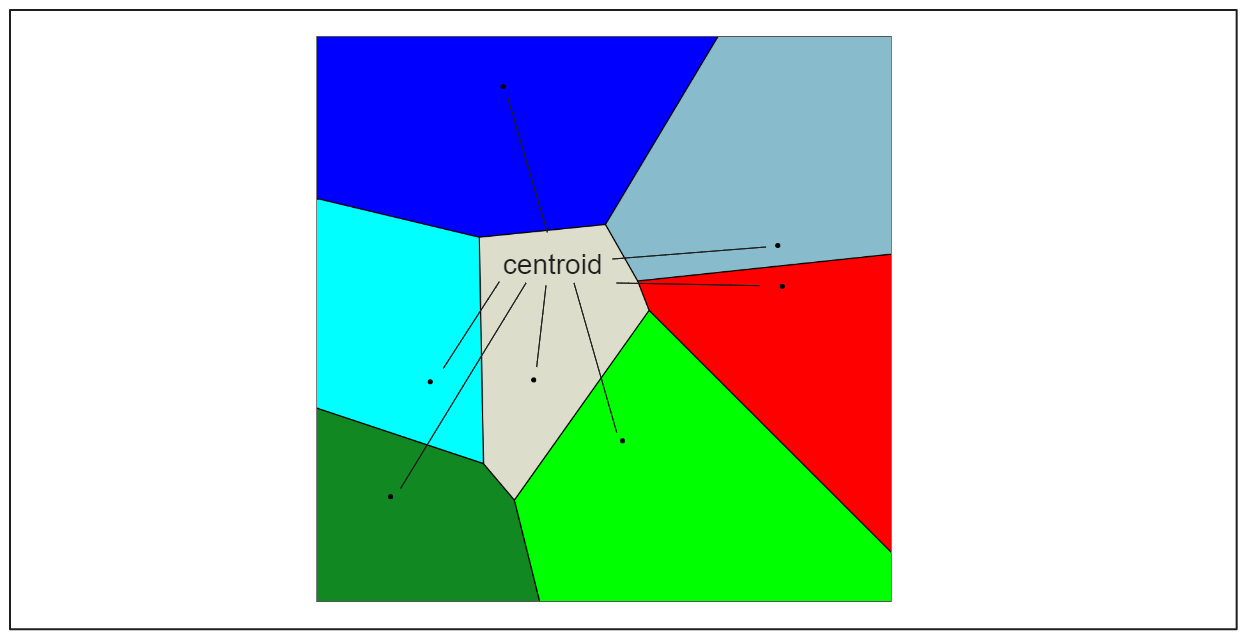
クエリ埋め込みQが与えられると、IVF-FLATはデータベース中の埋め込み全体の集合ではなく、Qと各セントロイドとの距離のみを計算すればよい。そして、最も距離の小さいセントロイドが選択され、そのパーティションに関連する埋め込みが最終的な探索の候補として使われる。

このインデクシング法は、検索処理を高速化しますが、潜在的な欠点を伴います。それは、クエリ埋め込みQに最も近いものとして見つかった候補が、正確な最も近いものとは限らないということです。これは、Qに最も近い埋め込みが、最も近い重心に基づいて選択されたパーティションとは異なるパーティションに存在する場合に起こり得ます(以下の可視化を参照)。
この問題に対処するため、IVF-FLATは2つのハイパーパラメータを提供します:
1.nlist:nlist: k-meansアルゴリズムで作成するパーティションの数を指定する。
2.nprobe`:候補を検索する際に考慮するパーティションの数を指定する。
ここで、nprobeを1ではなく3に設定すると、以下のような結果になる:
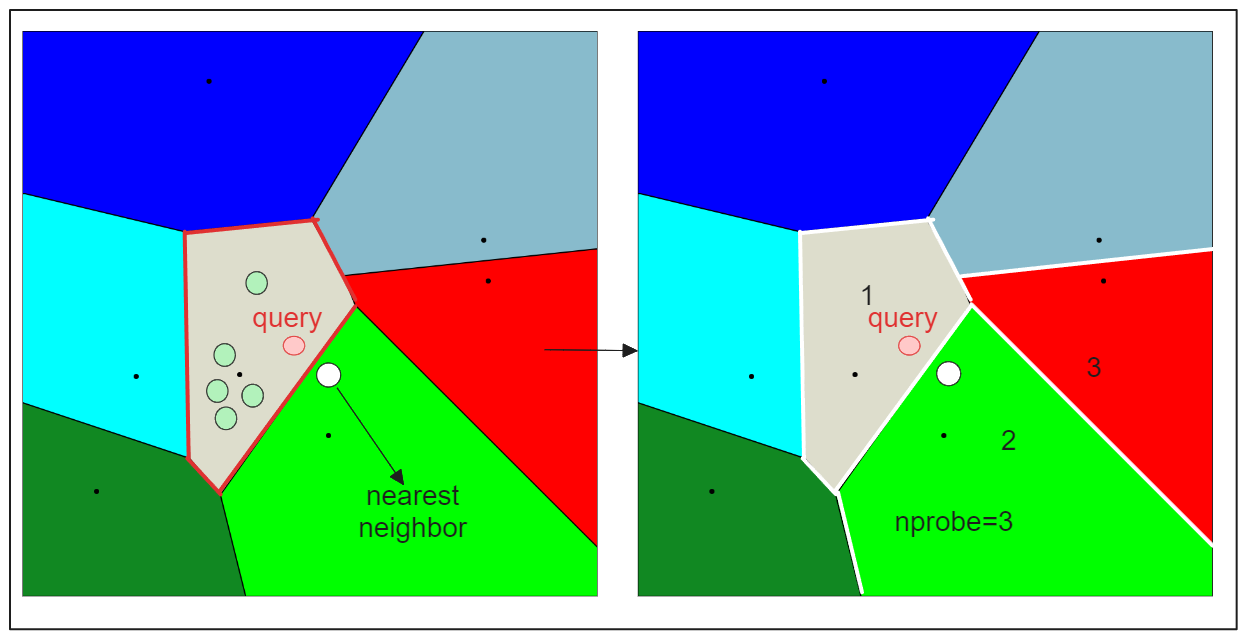
nprobe`の値を大きくすることで、より多くのパーティションを検索に含めることができ、クエリに最も近い埋め込みが別のパーティションにあったとしても、それを見逃さないようにすることができます。しかし、より多くの候補を評価する必要があるため、検索時間が長くなります。
量子化付き転置ファイルインデックス (IVF-SQ8 および IVF-PQ)
前述の IVF-FLAT インデクシング・アルゴリズムは、ベクトル検索処理を高速化します。しかし、メモリリソースが限られている場合、FLAT戦略を使用することは、埋め込み値の圧縮を行わないため、最適でない可能性があります。
メモリ制約に対処するために、IVFと組み合わせて、各ベクトル次元の値を低精度の整数値にマッピングするステップを追加することができる。このマッピング戦略は一般に量子化と呼ばれ、スカラー量子化と積量子化の2つのアプローチがあります。
**反転ファイル・インデックスとスカラー量子化(IVF-SQ8)
スカラー量子化では、各ベクトル次元を表す浮動小数点数を整数にマッピングします。
スカラー量子化では、まず、ステップサイズを計算するために、ベクトルの各次元の最大値と 最小値を決定し、データベースに保存します。このステップ・サイズは、各次元の浮動小数点数を整数表現にスケーリングするために非常に重要です。例えば、32 ビットの浮動小数点数を 8 ビットの整数に変換するには、通常、範囲を 256 のバケットに分割します。ステップ・サイズは次のように計算できる:
 ステップ・サイズ式.png
ステップ・サイズ式.png
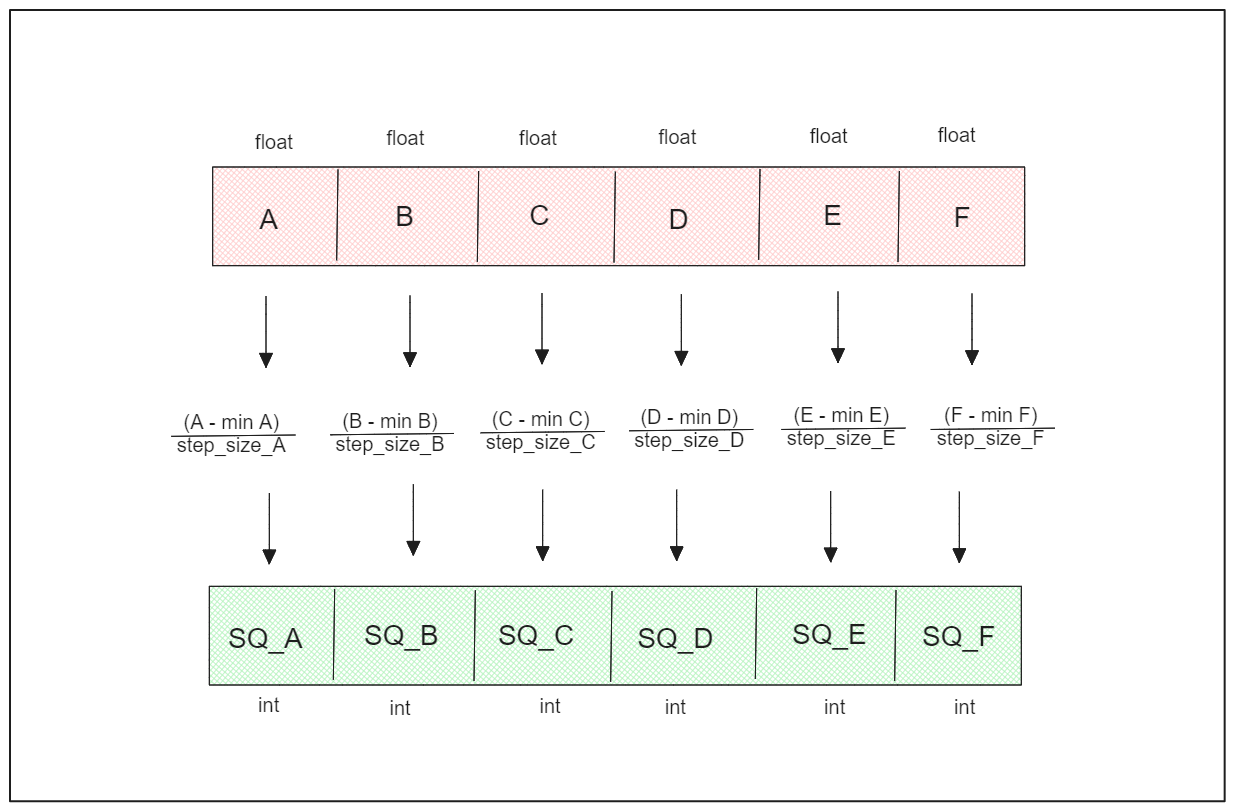
n番目のベクトル次元の量子化バージョンは、その最小値からn番目の次元の値を引き、その結果をステップサイズで割ることによって得られる。
転置ファイル・インデックスと積の量子化(IVF-PQ)*.
積量子化は、各次元の分布を考慮することで、スカラー量子化の限界に対処します。
積量子化は、ベクトル埋め込みをサブベクトルに分割し、各サブベクトル内でクラスタリングを実行してセントロイドを作成し、各サブベクトルを最も近いセントロイドのIDで符号化します。この方法は、IVF-FLATと同様に、部分ベクトル内で交差しないパーティションを作成する。
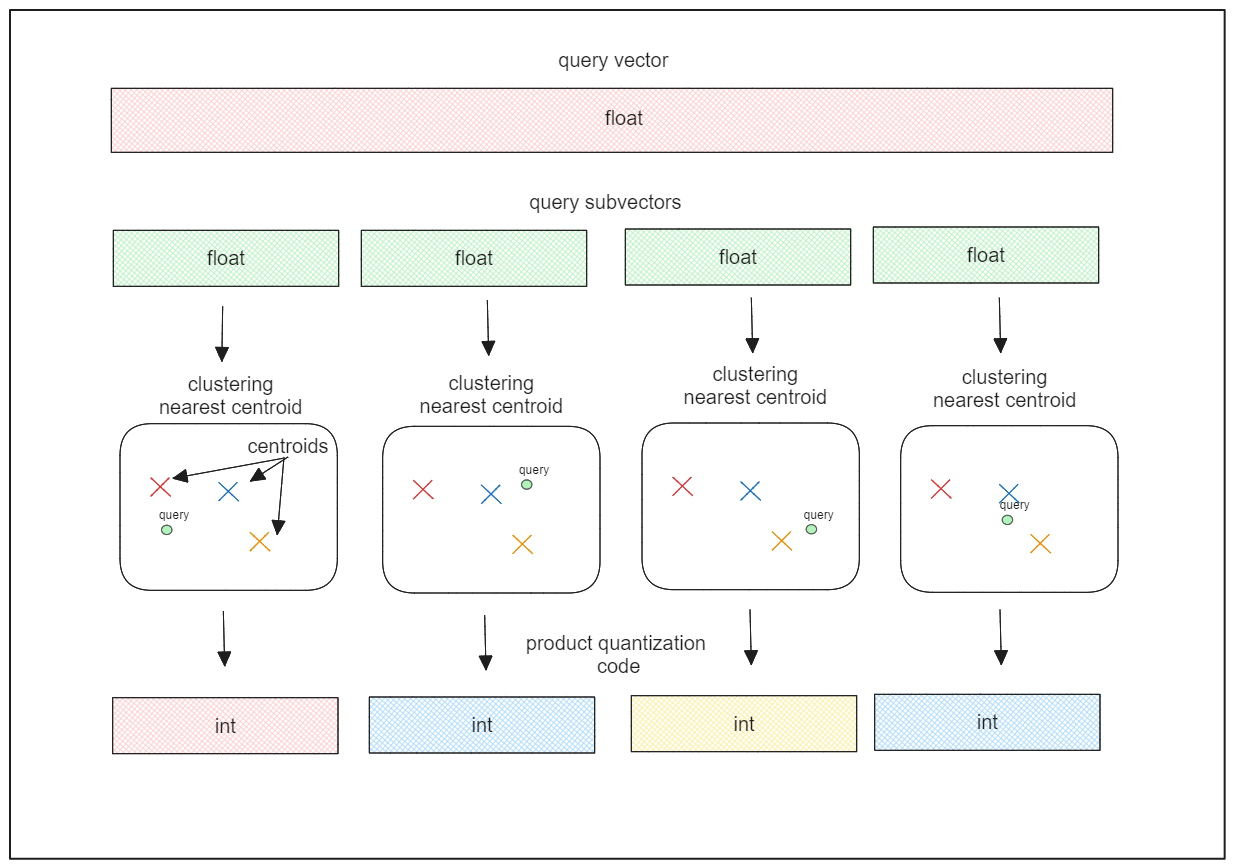
セントロイドのIDはPQコードとして知られ、8ビットの整数を表し、ベクトル埋め込みをメモリ効率よく符号化します。
積量子化はスカラー量子化と比較してより強力なメモリ圧縮を提供し、類似検索アプリケーションで大量のメモリ制約を処理するのに非常に有用な手法となっている。
階層的ナビゲーシブルスモールワールド(HNSW)
HNSWは、スキップリストとNavigable Small World (NSW)グラフという2つの重要な概念を組み合わせたグラフベースのインデックス作成アルゴリズムである。
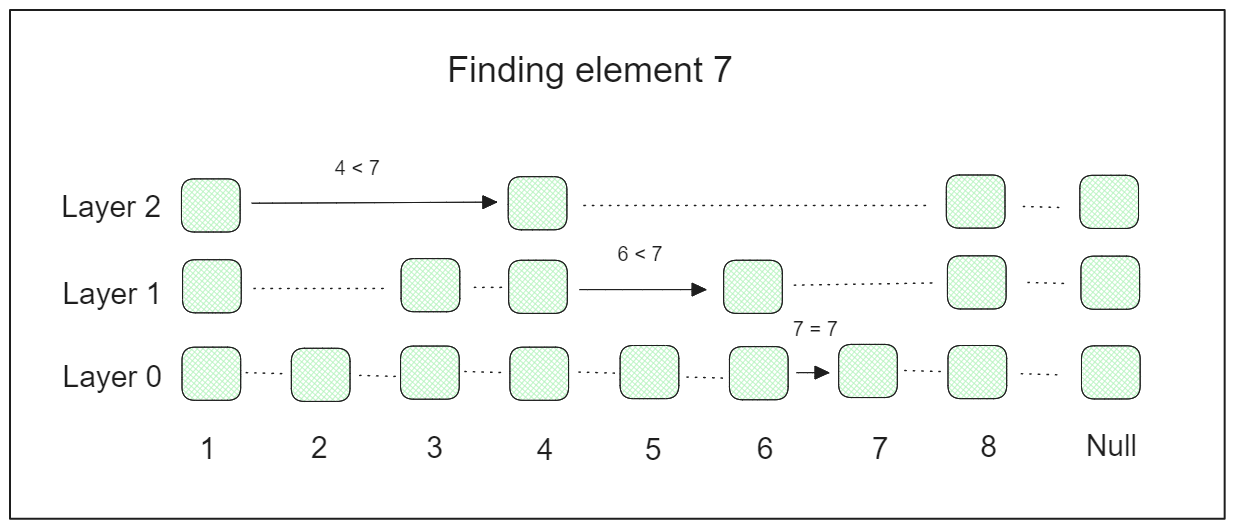
スキップリストは、多層のリンクリストからなる確率的データ構造である。最下層にはすべての要素を含む元のリンクリストが含まれる。高階層に行くにつれて、リンクリストは徐々に要素をスキップしていき、その結果、高階層に行くごとに要素が少なくなっていく。
探索プロセスでは、最上位層から始めて、目的の要素を見つけるまで徐々に下位層へと降りていく。このため、スキップリストは検索プロセスを大幅に高速化することができる。
例えば、元の連結リストに3つのレイヤーと8つの要素を持つスキップリストがあるとしよう。要素7を見つけたい場合、検索プロセスは次のようになります:
一方、NSWグラフは、データ点をランダムにシャッフルして1つずつ挿入し、各点があらかじめ定義された数の辺(M)に接続されることで構築される。これにより、任意の2点が比較的短い経路で接続される「スモールワールド」現象を示すグラフ構造が形成される。
例として、5つのデータポイントがあり、M=2に設定したとしよう。HSWグラフを構築するステップ・バイ・ステップのプロセスを以下に示す:
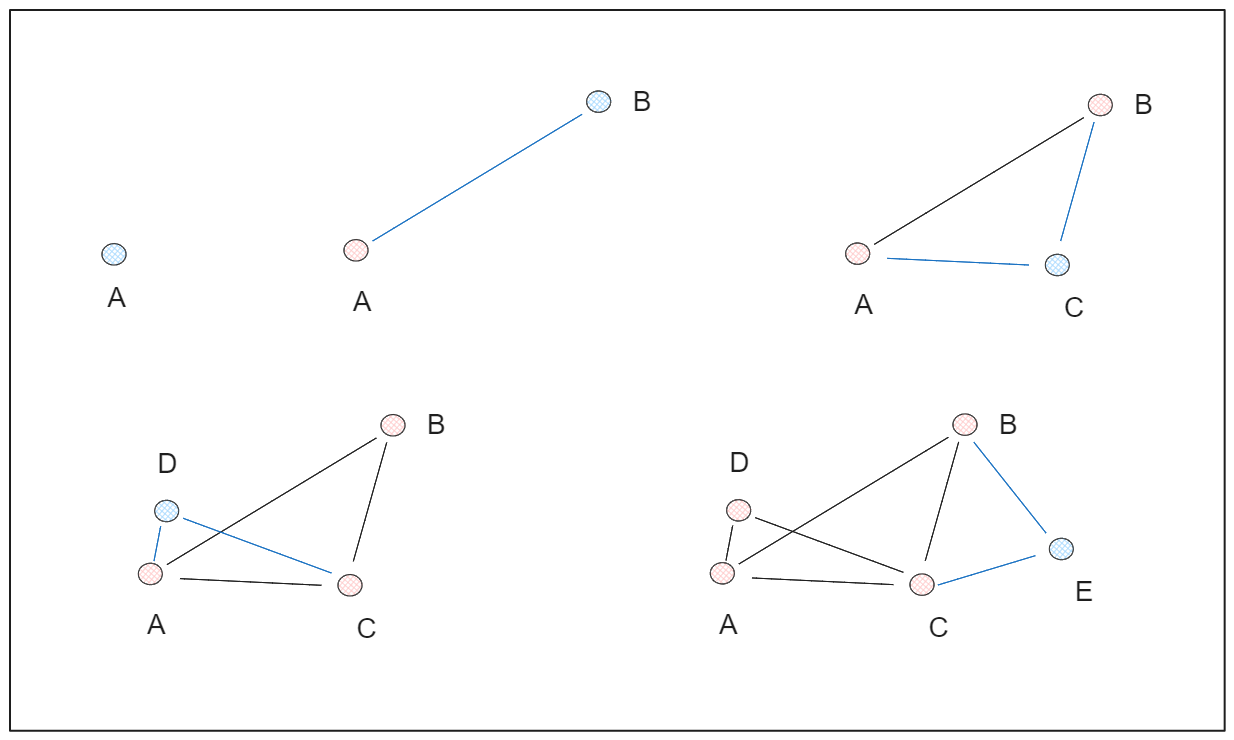
HNSWの "Hierarchical "という用語は、スキップリストとNSWグラフの概念を組み合わせたものである。HNSWは多層グラフで構成され、下位層はデータ点の完全な集合を含み、上位層は点のごく一部しか含まない。
HNSWは各データ点(グラフアルゴリズムで言うところの「ノード」)に0からlまでのランダムな整数値を割り当てることから始まる。あるデータ・ポイントがl=2で、グラフのレイヤーの総数が5だとすると、そのデータ・ポイントは2番目のレイヤーまでしか存在しないはずで、レイヤー3以上では利用できないはずである。
検索プロセスにおいて、HNSWはエントリーポイントを選択することから始め、これは最上位層に存在するデータポイントでなければならない。次にクエリーポイントに最も近い近傍を検索し、最も近いデータポイントが見つかるまで、より低いレイヤーで再帰的に検索を続ける。
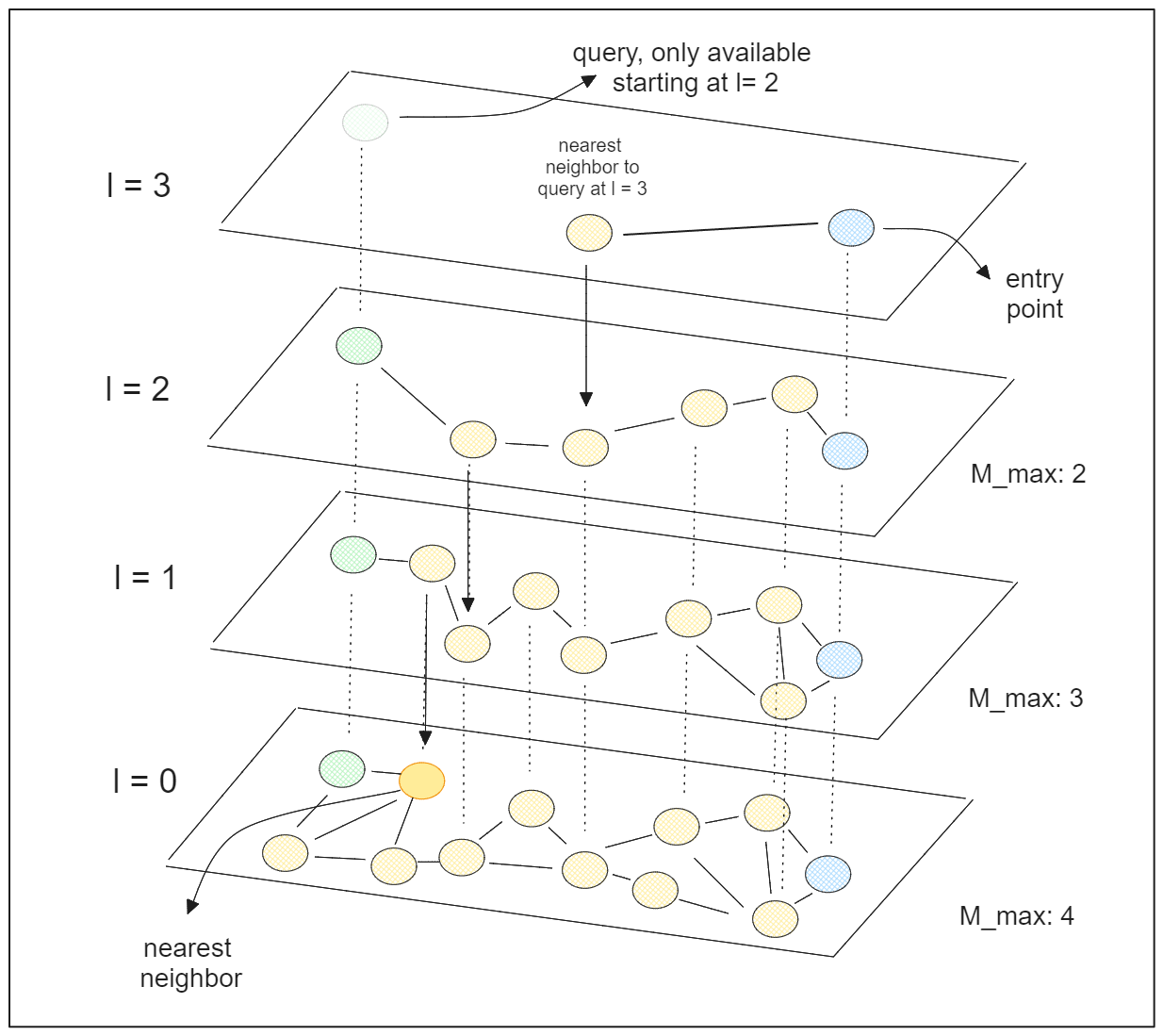
HNSWには2つの重要なハイパーパラメータがあり、これを調整することで検索精度を向上させることができる:
1.efConstruction`:各層で最近傍を見つけるために考慮する近傍の数。値を大きくすると、より綿密な探索が行われ精度が向上するが、計算時間が長くなる。
2.efSearch`:各レイヤーでエントリーポイントとして考慮する最近傍の数。
スキップリストとNSWグラフの概念を活用することで、HNSWは有望でない多くのデータ点をスキップすることにより、類似性検索プロセスを大幅に高速化することができる。
どのインデックスタイプを使うか?
Milvusがサポートする様々なインデックスタイプがわかりました。Milvusがサポートする様々なインデックスタイプを理解することは非常に重要ですが、どのインデックスタイプを使用するかは、特定のユースケースと類似検索の目的によって決まります。
結果の精度の重要性、クエリー速度、メモリ制約、データサイズなどの考慮事項が、適切なインデックスタイプを選択する上で重要な役割を果たします。ユースケースに適したインデックスタイプを決定するために、以下のフローチャートを参照してください:

100%の精度を保証する精密な検索には、FLATインデックスが理想的な選択です。しかし、スピードが優先され、正確さがそれほど重要でない場合は、他のインデックス・アルゴリズムを選択することができます。
メモリリソースが懸念される場合は、IVF-SQ8 や IVF-PQ のような量子化インデクシングアルゴリズムの使用をご検討ください。そうでない場合は、IVF-FLAT や HNSW などのオプションが適しています。小さいデータセット(2GB未満)であればIVF-FLATで十分かもしれませんが、大きいデータセット(2GB以上)であればHNSWを使用することで、検索速度を向上させつつ、高い再現率を維持することができます。
データセットが非常に大きい場合は、IVFと量子化法を組み合わせることが、メモリオーバーを防ぐために望ましいアプローチであることに変わりはない。
結論
ベクトル埋め込みを格納するために適切なインデックスタイプを選択することは、望ましい検索結果を得るために非常に重要です。各インデックスタイプにはそれぞれ長所と注意点があり、ユースケースの具体的な要件に応じて選択する必要があります。
この記事で取り上げたインデックス作成方法に関するさらなる洞察については、弊社が提供する追加リソースをご覧ください。
ベクターインデックスの基礎知識](https://zilliz.com/learn/vector-index)
スカラー量子化と積量子化](https://zilliz.com/learn/scalar-quantization-and-product-quantization)
階層的航行可能小世界(HNSW)](https://zilliz.com/learn/hierarchical-navigable-small-worlds-HNSW)

読み続けて

楽々AIワークフロー:Hugging FaceとPyMilvusの初心者ガイド
この包括的なガイドでは、PyMilvusとHugging Faceデータセットを活用して機械学習プロジェクトを強化する方法を学びます。

MilvusとHaystack 2.0によるRAGパイプラインの構築
このガイドでは、MilvusとHaystack 2.0の統合による強力なRAGアプリケーションの構築について説明します。

MilvusとOpenAIによるセマンティック検索
このガイドでは、MilvusとOpenAIのEmbedding APIを統合したセマンティック検索機能について、書籍のタイトル検索をユースケース例としてご紹介します。