




楽々AIワークフロー:Hugging FaceとPyMilvusの初心者ガイド
この包括的なガイドでは、PyMilvusとHugging Faceデータセットを活用して機械学習プロジェクトを強化する方法を学びます。
シリーズ全体を読む
- 楽々AIワークフロー:Hugging FaceとPyMilvusの初心者ガイド
- MilvusとHaystack 2.0によるRAGパイプラインの構築
- Milvusインスタンスでベクターインデックスを選ぶ方法:ビジュアルガイド
- MilvusとOpenAIによるセマンティック検索
- GCP KubernetesでMilvusを効率的にデプロイする:オープンソースデータベース管理ガイド
- 北極雪片とMilvus上のトランスフォーマーでRAGを作る
- MilvusでJSONデータをベクトル化し、類似性検索を行う
- Gemini 1.5、BGE-M3、Milvus Lite、LangChainによるマルチモーダルRAGの構築
#はじめに
人工知能と機械学習に関して、高品質なデータセットと効率的なデータ管理システムへのアクセスは、効率的でスケーラブルなアプリケーションを構築するために不可欠である。Hugging Face リポジトリには、自然言語処理から複雑なデータ分析まで、多くのドメインに適したデータセットが含まれている。膨大なキュレーションされたデータセットリポジトリへのアクセスを求める多くの開発者の目的地となっている。
この膨大な量のデータには、効率的なデータ管理メカニズムが必要です。そこでPyMilvusの登場です。PyMilvusは、高次元ベクトルデータの管理とクエリを専門とするMilvusの堅牢な基盤の上に構築されています。PyMilvusは、データサイエンティストやAI開発者が推奨システム、コンテンツベースの検索、類似性マッチングなどの幅広い用途にベクトルデータベースの力を活用できるようにするPythonインターフェースを提供する。
この包括的なガイドでは、PyMilvusとHugging Faceデータセットを活用して機械学習プロジェクトを強化する方法を学びます。
Hugging Face データセットとは?
Hugging Face DatasetsはHugging Face Hubの一部であり、モデル、データセット、その他のAIリソースを共有し、協力するためのプラットフォームです。これらのデータセットは、テキスト、音声、画像、ビデオデータを含む様々なドメインから提供された高品質のデータセットの多様なコレクションで構成されています。これらのデータセットは、AIモデルのトレーニングと評価のための基礎的なリソースとして機能します。
Hugging Faceデータセットの真の力は、その汎用性にあります。単一のアプリケーションやユースケースに限定されません。言語翻訳、感情分析、画像分類、質問応答など、Hugging Faceデータセットがあなたをカバーします。
クイック・データセット・ライブラリ
Hugging Face Datasets Hub**に掲載されているデータセットにアクセスするには、Datasetsというライブラリが必要です。これを使うには、まず以下のコマンドを使ってPython環境にインストールする必要があります:
bash
pip install datasets
ライブラリをインポートし、Hugging Face Hubから必要なデータセットをロードする。
パイソン
from datasets import load_dataset
# ハグする顔のデータセットからデータセットをロードする hub
データセット = load_dataset('squad')
print(dataset)
上のコードでは、Stanford Question Answering Dataset (SQuAD) を読み込んでいます。以下は、データセットの構造を示すスクリーンショットである:
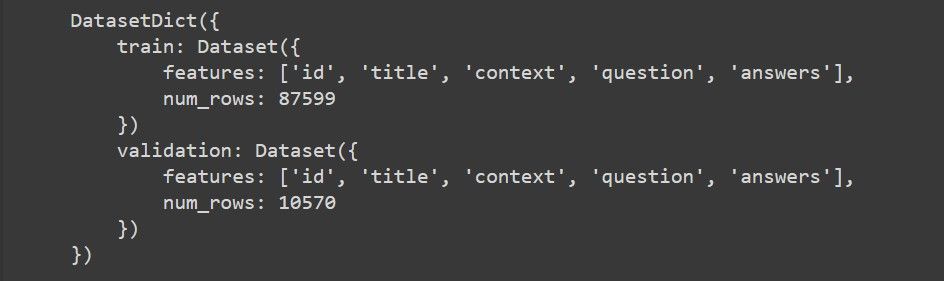
この構造から、我々のデータセットには2つの分割があることがわかる:trainとvalidationである。train分割には、87,599のデータポイントがあり、それぞれid、title、contextなどの特徴を含んでいる。同様に、検証分割には、同じ特徴を持つ10,570以上のデータポイントがあります。これらの特徴は、このガイドの後半で非常に役立ちます。
ハグする顔データセットをPyMilvusで統合する利点
Hugging FaceデータセットとPyMilvusの統合は、データの管理、照会、AIや機械学習アプリケーションでの活用方法に革命をもたらします。Hugging Faceデータセットからのベクトル化されたデータを扱うためにPyMilvusを活用する利点は以下の通りです:
- 効率的なデータ管理**:Milvusは最適化されたデータ保存と検索のメカニズムを提供し、Hugging Faceデータセットとのシームレスな統合を可能にし、手作業によるデータ管理作業の必要性を排除します。これにより、面倒なデータ処理プロセスに煩わされることなく、モデル開発と実験に焦点を移すことができます。
- スケーラビリティとパフォーマンス**:Milvusは水平方向に拡張できるように設計されており、ベクトル化された大量のデータを容易に扱うことができます。このスケーラビリティは、数百万から数十億のデータポイントを含む可能性のある大規模なハギングフェイスデータセットを扱う際に特に有益です。
- 高速で正確な検索**:ベクトル化されたデータを扱うためにMilvusを使用するもう一つの重要な利点は、高速で正確な類似検索操作を実行できることです。Milvusは高度なインデックス作成技術と類似検索アルゴリズムを活用し、大規模なデータセットからでも関連情報を迅速に検索します。これにより、データサイエンティストはHugging Faceデータセット内の類似データポイントを効率的に検索し、取り出すことができます。
- AIワークフローとのシームレスな統合**:PyMilvusは、TensorFlow、PyTorch、scikit-learnなどの一般的なAIおよび機械学習フレームワークと統合するシームレスなPythonインターフェースを提供します。これにより、既存のワークフローにベクトルデータベースをシームレスに組み込むことができ、大規模な再設定や再開発を行うことなく、Hugging Faceデータセットからベクトル化されたデータを扱うためにMilvusのパワーを活用することができます。
Hugging Faceの大規模な質問回答データセットから類似した質問を検索することを想像してみてください。ベクトルデータベースは、従来のキーワードベースの検索よりも大幅に速く、意味的類似性に基づいた関連する質問の高速検索を可能にするでしょう。
環境のセットアップ
Hugging FaceのデータセットをPyMilvusと統合する前に、環境をセットアップする必要があります。これは必要なライブラリのインストールと、シームレスな統合のためのPyMilvusの設定を含みます。
まず、Python IDEを起動します。次に、仮想環境を作成し、以下のコマンドを使用してPIPを使用して必要なライブラリをインストールします:
bash
pip install transformers datasets pymilvus torch
各ライブラリを何に使うかの内訳は以下の通りだ:
- transformers**:transformers**:このライブラリは事前に学習された変換モデルをロードし、埋め込みを生成するためのトークン化を行うために使用します。
- データセット**:Hugging Faceデータセットハブからデータセットを読み込み、質問応答などのタスクに使用します。
- pymilvus**:このライブラリを使用して、Milvusサーバに接続し、コレクションを作成し、埋め込みを挿入し、類似検索を実行します。
- トーチtorch**:このライブラリは、テンソル操作や、事前に学習された変換モデルを使った埋め込みデータの生成など、ディープラーニングモデルの操作に使用します。
ライブラリをインストールした後、[Milvus](https://milvus.io/)をインストールする必要があります。これはPyMilvusが構築されている実際のベクトルデータベースです。Milvusはローカルか[managed Milvus](https://cloud.zilliz.com/signup)を介してクラウド上で動作させる必要があります。Milvusをインストールするには、この[quickstart guide](https://zilliz.com/learn/milvus-vector-database-quickstart)に従ってください。
Milvusはデフォルトで**19530**ポートで動作します。他のポートでMilvusを実行している場合、接続時にポート番号が必要となりますので、ご注意ください。以下はDockerの19530番ポートでMilvusを実行しているスクリーンショットです。
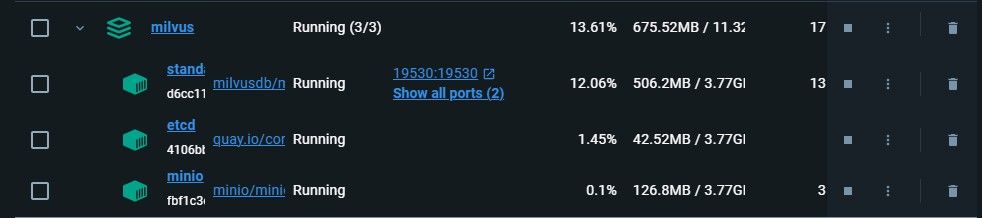
最初のコンテナはMilvusのスタンドアロンサービスで、残りはその2つの依存関係です。
Milvusをインストールして起動したら、PyMilvusとHugging Faceデータセットを統合する準備ができました。
## PyMilvusとHugging Faceデータセットの統合
それでは、**PyMilvus**と**Hugging Face datasets**の統合方法をステップバイステップで見ていきましょう。コードの再利用性を促進するために、コードを関数に分割します。
### ライブラリのインポートと必要なパラメータの宣言<a id="importing-libraries-and-declaring-necessary-parameters"></a>
コードに必要なライブラリをインポートすることから始めます:
python
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
from datasets import load_dataset_builder, load_dataset, Dataset
from transformers import AutoTokenizer, AutoModel
from torch import clamp, sum
importはMilvusへの接続の確立、コレクションスキーマの定義、データセットのロード、テキストのトークン化、トランスフォーマモデルのロード、テンソル操作の実行に役立つ。
次に、コードで使用する様々なパラメータを定義する:
python
パラメーター
DATASET = 'squad' # 使用するハグ顔のデータセット
MODEL = 'bert-base-uncased' # エンベッド用の変換モデル
TOKENIZATION_BATCH_SIZE = 1000 # トークン化処理のバッチサイズ
INFERENCE_BATCH_SIZE = 64 # 埋め込み生成のバッチサイズ
INSERT_RATIO = 0.001 # Milvusにデータを埋め込んで挿入する割合
COLLECTION_NAME = 'huggingface_db' # Milvusコレクションの名前
DIMENSION = 768 # 埋め込みデータの次元
LIMIT = 5 # 検索結果を返す数
MILVUS_HOST = "localhost"
milvus_port = "19530"
完全なデータセットを使用したい場合は `INSERT_RATIO` を `1.0` に設定する。また、Milvusを他のポートで動作させている場合は、`MILVUS PORT`パラメータにそのポートを渡してください。
### Milvusコレクションの作成
パラメータ定義の次のステップはMilvusコレクションの作成である。これは、検索や挿入などの操作を行うコレクションである。
パイソン
def create_collection():
# Milvusデータベースに接続する
connections.connect(host=MILVUS_HOST, port=MILVUS_PORT)
# コレクションが既に存在する場合は削除する
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
# コレクションのスキーマを定義する
fields = [
FieldSchema(name='id', dtype=DataType.INT64, is_primary=True, auto_id=True)、
FieldSchema(name='original_question',dtype=DataType.VARCHAR,max_length=1000)、
FieldSchema(name='answer',dtype=DataType.VARCHAR,max_length=1000)、
FieldSchema(name='original_question_embedding', dtype=DataType.FLOAT_VECTOR、
dim=DIMENSION)
]
schema = CollectionSchema(fields=fields)
コレクション = コレクション(name=COLLECTION_NAME, schema=schema)
#効率的な類似検索のためにIVF_FLATインデックスを作成する。
インデックスパラメータ
'metric_type':'L2'、
'index_type': "IVF_FLAT"、
'params':{"nlist":1536}
}
collection.create_index(field_name="original_question_embedding")、
index_params=index_params)
コレクション.load()
コレクションを返す
この関数は Milvus データベースとの接続を確立します。接続に成功すると、パラメータで指定した名前のコレクションが存在するかどうかをチェックします。存在する場合は、そのコレクションをデータベースにドロップします。次に、ID、元の質問、回答、埋め込み用のフィールドを含むコレクションのスキーマを定義します。最後に、類似検索を最適化するためにコレクションのインデックスを作成し、コレクションをロードします。
データのロードとトークン化
コレクションの準備ができたので、好みのデータセットからデータをロードする。
``python def load_data():
data_dataset = load_dataset(DATASET, split='all')
data_dataset = data_dataset.train_test_split(test_size=INSERT_RATIO、
seed=42)['test']
data_dataset = data_dataset.map(lambda val: {'answer': val['answers'][)
'text'][0]}, remove_columns=['answers'])
return data_dataset
このステップでは、上記の関数が**Hugging Face Hub**からデータセットをロードし、埋め込みと挿入のための**テストセット**に分割する。埋め込み**とは、構造化されていないデータの数値表現である。そして、そのデータをマップして回答テキストを抽出する。
データセットをロードし、必要なデータを抽出したら、次は抽出したデータをトークン化する番だ。トークン化とは、テキストをより小さな部分に分割することで、**トークン**とも呼ばれます。
パイソン
def tokenize_question(batch):
results = tokenizer(batch['question'], add_special_tokens=True、
truncation=True, padding="max_length"、
return_attention_mask=True, return_tensors="pt")
バッチ['input_ids']=結果['input_ids'].
batch['token_type_ids'] = results['token_type_ids'].
batch['attention_mask'] = results['attention_mask'].
バッチを返す
data_dataset = data_dataset.map(tokenize_question、
batch_size=TOKENIZATION_BATCH_SIZE, batched=True)
data_dataset.set_format('torch', columns=['input_ids'、
'token_type_ids', 'attention_mask']、
output_all_columns=True)
return data_dataset
この関数は指定された変換モデルを使用してデータセット内の質問をトークン化します。次に、質問のバッチをトークン化するヘルパー関数を定義し、結果として得られる token ids, token_type_ids, attention_mask をデータセットに追加します。トークン化されたデータセットは PyTorch フォーマットにセットされ、返されます。
データを埋め込む
データをトークン化したら、それを数値で表す必要があります。この処理をエンベッディングと呼びます。エンベッディングは、ベクターデータベースが、挿入されるデータが適合することを期待するフォーマットです。なぜなら、ベクトル・データベースはこのエンベッディングを保存し、操作するように設計されているからです。
パイソン
def embed_data(data_dataset):
model = AutoModel.from_pretrained(MODEL)
def embed(batch):
sentence_embs = model(
input_ids=batch['input_ids']、
token_type_ids=batch['token_type_ids']、
attention_mask=batch['attention_mask'])[0].
input_mask_expanded = batch['attention_mask'].unsqueeze(-1).expand()
sentence_embs.size()).float()
batch['question_embedding'] = sum(sentence_embs * input_mask_expanded, 1) / clamp(input_mask_expanded.sum(1), min=1e-9)
バッチを返す
data_dataset = data_dataset.map(embed, remove_columns=['input_ids'、
'token_type_ids'、
'attention_mask']、
batched=True, batch_size=INFERENCE_BATCH_SIZE)
return data_dataset
この関数はトークン化されたデータセットを受け取り、指定された変換モデルを使用して質問の埋め込みを生成します。そして、トークン化された質問を変換モデルに通し、アテンションマスクで重み付けされたトークンの埋め込みを合計することで、トークン化された質問の埋め込みを計算するヘルパー関数 `embed` を定義します。結果として得られた埋め込み値は `question_embedding` フィールドとしてデータセットに追加される。データセットは `embed` 関数でマップされ、トークン化された列が取り除かれる。
### データをMilvusに挿入する
これはHugging FaceデータセットをMilvusに統合する最後のステップです。データを埋め込みという形で手に入れたら実行します。
python
def insert_data(collection, data_dataset):
def insert_function(batch):
挿入可能 = [
batch['question']、
[x[:995] + '...' if len(x) > 999 else x for x in batch['answer']]、
バッチ['question_embedding'].tolist()
]
コレクション.insert(insertable)
data_dataset.map(insert_function, batched=True, batch_size=64)
collection.flush()
この関数はコレクションとHugging Faceの埋め込みデータセットを入力として受け取り、Milvusコレクションにデータを挿入します。この関数はヘルパー関数 insert_function を定義しており、元の質問、切り捨てられた回答(999文字より長い場合)、質問埋め込みベクトルなど、バッチごとに挿入可能なデータのリストを作成する。
そして、コレクションの insert メソッドが各バッチの挿入可能なデータと共に呼び出されます。最後に、すべてのデータがコレクションに保持されるように flush メソッドが呼び出されます。構造化された方法でステップを実行するメイン関数を作成します。
パイソン
if name == "main":
コレクション = create_collection()
data_dataset = load_data()
data_dataset = tokenize_data(data_dataset)
data_dataset = embed_data(data_dataset)
insert_data(collection, data_dataset)
これでPymilvusとHugging Face Datasetの統合が完了した。
## 実用例
Hugging FaceデータセットとPyMilvusの統合は様々な領域で実用的な使用例があります:
- 自然言語理解**:自然言語理解**:質問応答、テキスト要約、感情分析などのタスクのための言語理解モデルの強化。
- 推薦システム**:ユーザーの好みやアイテムの類似性に基づいてパーソナライズされた推薦のためのコンテンツベースの推薦システムを構築する。
簡単な類似質問推薦システムの作成方法を見てみよう。このシステムは、ユーザーの質問を受け取り、可能な限り最良の答えを検索し、ユーザーが興味を持ちそうな他の質問に対する推薦を与える。このようなシステムは、AIプロバイダーによって使用されている例です。

そのためには、main関数の前に以下のコードを追加する。
パイソン
def recommendation_system(collection, query):
# クエリをトークン化して埋め込む
tokenizer = AutoTokenizer.from_pretrained(MODEL)
query_tokenized = tokenizer(query, add_special_tokens=True, truncation=True、
padding="max_length", return_attention_mask=True、
return_tensors="pt")
# クエリーを埋め込む
model = AutoModel.from_pretrained(MODEL)
query_embedding = model(
input_ids=query_tokenized['input_ids']、
token_type_ids=query_tokenized['token_type_ids']、
attention_mask=query_tokenized['attention_mask']である。
)[0]
query_embedding = sum(query_embedding * query_tokenized['attention_mask'] )[0].
.unsqueeze(-1).expand(query_embedding.size()).float(), 1) / clamp(query_tokenized['attention_mask'].sum(1), min=1e-9)
# 類似の質問を検索する
search_results = collection.search(query_embedding.tolist()、
anns_field='original_question_embedding', param={}、
output_fields=['original_question', 'answer'], limit=LIMIT)
# 答えを得るために最も関連性の高い結果を抽出する
most_relevant_result = search_results[0][0] # 最初のヒットが最も関連性が高いと仮定する
answer_to_query = most_relevant_result.entity.get('answer')
# 推薦文のフォーマット
おすすめ = [].
for hits in search_results:
for hit in hits:
recommendations.append({
'id': hit.id、
'distance': hit.distance、
'original_question': hit.entity.get('original_question')。
})
return answer_to_query, recommendations
この関数はまず、データ埋め込みステップと同じ変換モデルと処理を使って、入力されたクエリをトークン化して埋め込みます。次に、検索ベクトルとしてクエリの埋め込みベクトル、埋め込み用のフィールド名(original_question_embedding)、出力に含めるフィールド(original_questionとanswer)を渡して、コレクションに対してベクトルの類似性検索を行う。
そして、最も関連性の高い結果が検索結果の最初にヒットすると仮定し、この結果の entity 属性から対応する回答を抽出する。最後に、この関数は検索結果を繰り返し、各ヒットのID、距離スコア、元の質問テキストを含む辞書を追加することで、推薦文をフォーマットする。
次に、このコードをメイン関数に追加して実行することで、サンプルのクエリでレコメンデーションシステム関数をテストします。
パイソン
回答で推薦システムをテストする
query = "映画はいつ公開されますか?"
answer, recommendations = recommendation_system(collection, クエリ)
print("クエリ '{}' に対する答え:{}".format(query, answer))
print("類似の質問に対するn個の推薦:")
for rec in recommendations:
print("推奨される質問:{}, 距離:{}".format(rec[)
'original_question'], rec['distance']))
これが推薦システムの出力です:
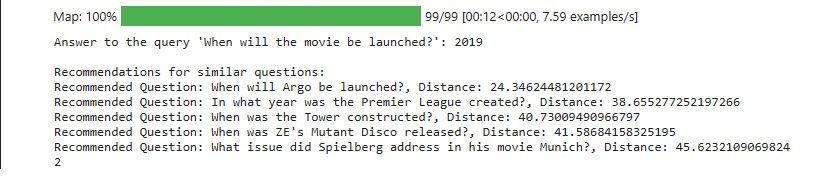
この結果は、様々なイベントや製品のリリース日や発売日に関するおすすめの質問を示しています。これは映画の発売日に関するクエリと一致しています。距離の値は、クエリとそれぞれの推奨される質問の間の類似性の程度を示しています。距離が低いほど類似度が高いことを示しています。
出力の品質は、使用するデータの品質と使用するデータセットのサブセットにも左右されることに注意することが重要です。
## その他のリソース
ベクターデータベースとHugging Face Datasetがどのように機能するかを理解するのに役立つ、その他のリソースです:
- このガイドで使われている完全なコードは [this notebook](https://www.kaggle.com/code/deniskuria/notebooke3b8752737) にあります。
- https://github.com/huggingface/notebooks/blob/main/datasets_doc/en/quickstart.ipynb
- https://milvus.io/docs/integrate_with_hugging-face.md
- https://www.ibm.com/topics/vector-database#:~:text=Vector%20databases%20create%20indexes%20on,nearest%20neighbor%20search%20between%20vectors。
 Denis Kuria
Denis KuriaDenis is a machine learning engineer who enjoys writing guides to help other developers. He has a bachelor's in computer science and loves hiking and exploring the world.
読み続けて

MilvusとHaystack 2.0によるRAGパイプラインの構築
このガイドでは、MilvusとHaystack 2.0の統合による強力なRAGアプリケーションの構築について説明します。

MilvusとOpenAIによるセマンティック検索
このガイドでは、MilvusとOpenAIのEmbedding APIを統合したセマンティック検索機能について、書籍のタイトル検索をユースケース例としてご紹介します。

GCP KubernetesでMilvusを効率的にデプロイする:オープンソースデータベース管理ガイド
Milvus on Kubernetes (K8s)のセルフホスト、特にGoogle Cloud Platform (GCP)環境には多くのメリットがあります。そのメリットとGCP上でのKubernetesクラスタのセットアップ方法については、ブログをお読みください。