




自然言語処理とベクトルデータベース:高度処理のための相乗効果を生み出す
写真の検索、商品の推薦、顔認識など、ベクトル・データベースの威力は、私たちを取り巻く世界の複雑さを理解する能力にある。
シリーズ全体を読む
生徒とその成績の記録を取りたいとします。おそらく、表1に示すような形式で、学生の姓名、登録番号、特定の科目の成績を取り込むでしょう。これは伝統的なデータベースの例です。
| 件数 | 氏名 | 姓 | 登録番号 | 科目成績 |
|---|
| 3. | ミサ|Mtakatifu|J23/026|A-|2.
*表1.構造化フォームデータベース
さて、表1の架空の生徒と同じように画像を保存したいとします。あなたならどうしますか?実際の画像を保存しますか?保存された画像を検索するには、どのようにクエリを実行するのでしょうか?この記事では、画像、音声、テキストなどの非構造化データを高次元ベクトルとして保存し、ベクトルの類似性に基づいて高速かつ正確に検索・取得できるようにするために使用される、別のタイプのデータベースであるベクトルデータベースについて説明することで、これらの疑問を深く探ります。そして、このようなタイプのデータベースが、自然言語処理 (NLP)、コンピュータビジョン(CV)、推薦システム(RecSys)など、類似検索やマッチングデータが必要とされる分野で、どのように実世界に応用されているかを見ていきます。
ベクターデータベースを理解する
デジタルプラットフォーム上に画像のコレクションがあり、特定の画像に類似した画像、例えば休暇中の家族の画像を見つけたいとする。ベクターデータベースの出番だ。これらのデータベースは画像そのものを保存するのではなく、ベクターと呼ばれる数値表現を保存します。これらのベクトルは、形、色、顔の有無など画像の本質を、機械が理解し比較できる方法で捉えます。
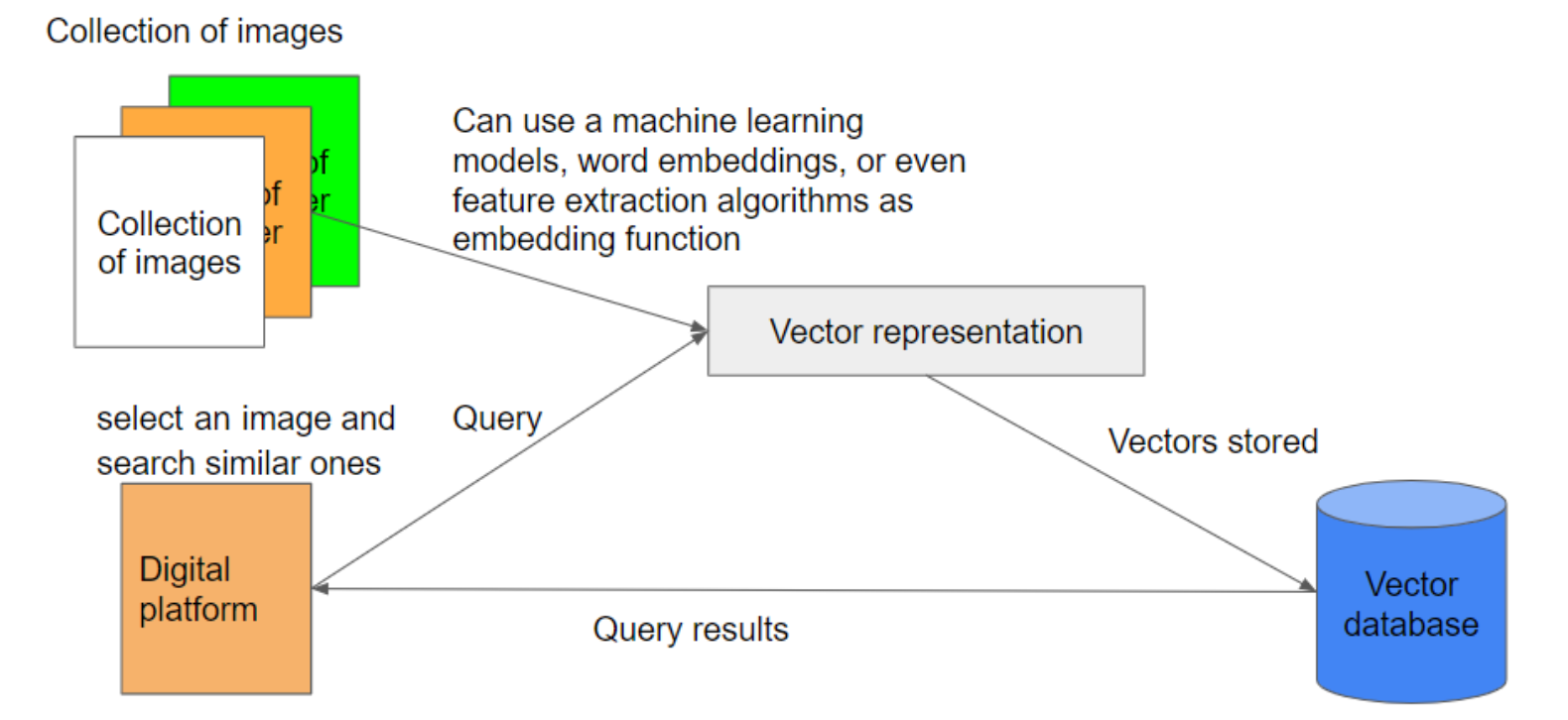
私が画像を選択し、似たような画像を探すようプラットフォームに要求すると、システムはこれらのベクトル表現を使用してベクトルデータベースを検索する。検索アルゴリズムは、クエリ画像のベクトルとデータベース内のベクトルを比較し、類似したベクトルを持つ画像を一致画像として特定する。このプロセスにより、このプラットフォームは、膨大なコレクションの中からでも、私のクエリ画像に視覚的に似ている画像を素早く返すことができる。このベクトル・データベースの概念を図2に示し、従来のデータベースと比較したものを表2に示す。
 ベクトルデータベースの役割の図解.png
図2.ベクトルデータベースの役割の実例(出典:筆者によるイメージ図)。
ベクトルデータベースの役割の図解.png
図2.ベクトルデータベースの役割の実例(出典:筆者によるイメージ図)。
| メトリック|伝統的データベース|ベクトル・データベース| |---------------|-------------|-------------|- | クエリ技術|スカラーデータ型を扱うのに理想的な、特定の条件に正確に一致するデータエントリを正確に検索するための完全一致に基づく|画像、テキスト、オーディオのような非構造化データを扱うのに効果的な、クエリに最も関連するベクトルを識別するための類似性検索に基づく|。 | データ型|文字列、数値、その他のスカラーデータを行と列に格納|ベクトル(データの数値表現)を操作。|
表2.従来のデータベースとベクトル・データベースの比較
PythonとZillizのベクトルデータベースMilvusを使ったコード例。
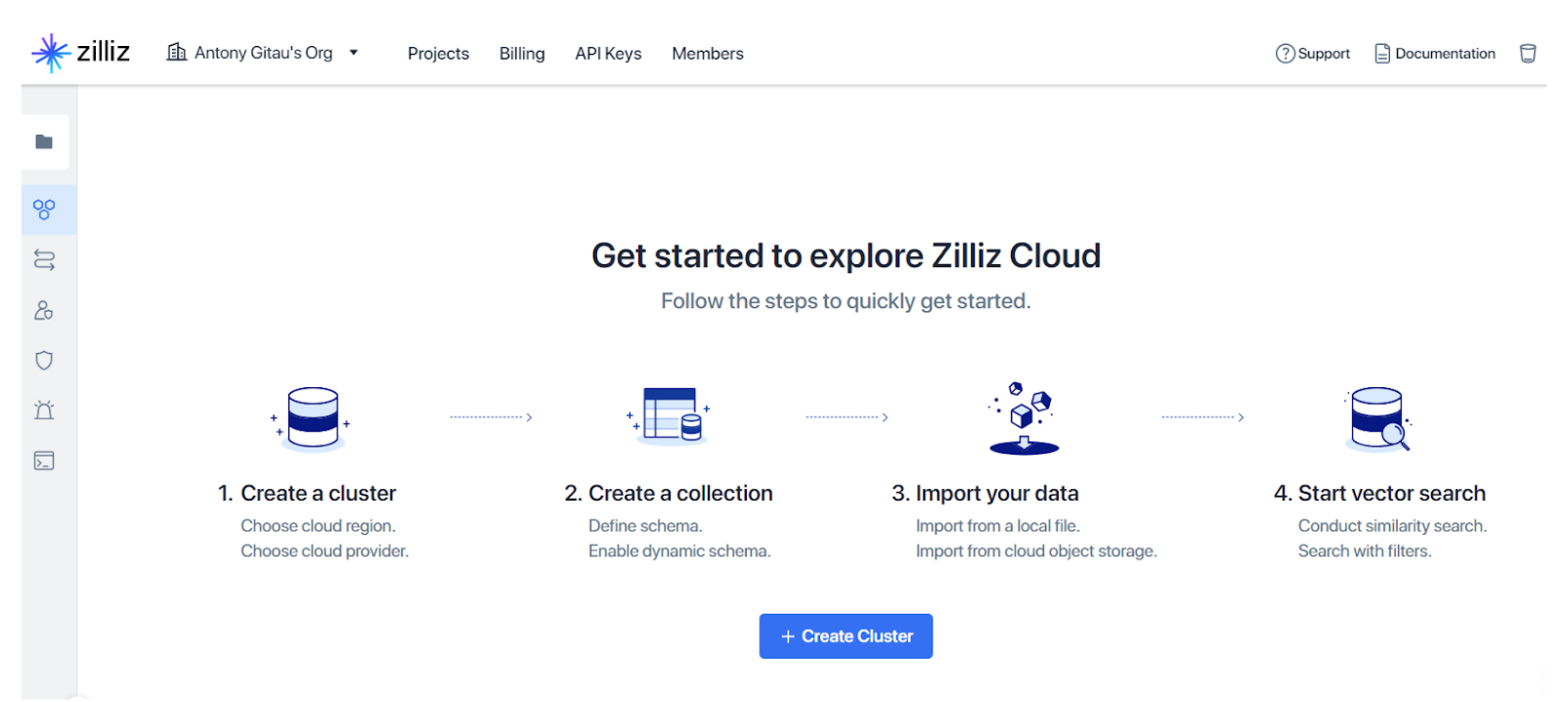
まず、Zilliz Cloudでアカウントを作成し、クラスタを作成する(100ドルの無料クレジットをもらえる!)。サインアップすると、図3のようなページが表示されます。
 Zillizクラウドのスタートページ.png
Zillizクラウドのスタートページ.png
*図3.Zilliz Cloudの利用開始ページ
次に、図4のようにZilliz Cloudから取得したエンドポイントURIとAPIキーをPythonコードにコピーして、Zilliz CloudとPythonコードを接続します。
Python
Zilliz Cloudのセットアップ引数
COLLECTION_NAME = 'image_search' # コレクション名 DIMENSION = 2048 # この例では埋め込みベクトルサイズ URI = 'https://in03-277eeacb6460f14.api.gcp-us-west1.zillizcloud.com' # Zilliz Cloudから取得したエンドポイントURI API_KEY = 'あなたのキー'
推論の引数
バッチサイズ = 128 TOP_K = 3
*図4.ZillizクラウドとPythonコードの接続(出典:筆者による画像)*。
図5のように必要なライブラリをインストールした後、Zilliz Cloudクラスタへの接続を設定し、コレクションにスキーマを作成し(スキーマは図6のようにZillid Cloud上で確認できる)、コレクションにインデックスを作成する。
pip3 install pymilvus==2.2.11 !pip3 install --no-cache-dir --force-reinstall -Iv grpcio==1.49.1 !pip install pymilvus torch gdown torchvision tqdm
*図 5.インストールするライブラリ
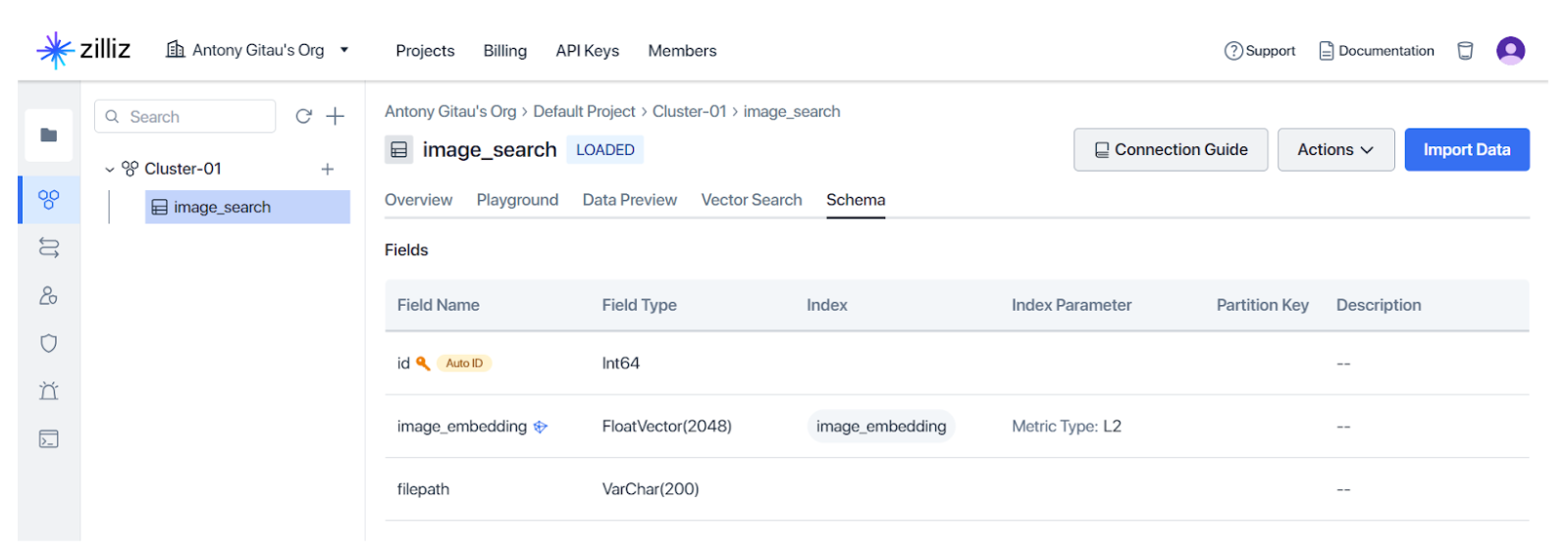
*図6.この例のスキーマ(出典:著者による画像)*。
次に、データを前処理し、ニューラルネットワークモデルを使用します。この場合、[Resnet50モデル](https://pytorch.org/hub/pytorch_vision_resnet/)を使用し、処理されたデータをベクトル埋め込みに埋め込みます。クラスターとコレクションを作成したZillizのクラウドアカウントには、図7に示すように、データと埋め込みが存在していることがわかるだろう。
Zillizクラウド上のデータとエンベッディングの図.png](https://assets.zilliz.com/Illustration_of_data_and_embedding_on_Zilliz_Cloud_04b525d051.png)
*図7.Zilliz Cloud上のデータとエンベッディングのイラスト(出典:筆者による画像)*。
図7から、ベクトル検索機能も見ることができる。1枚目の画像をクリックすると、図8に示すように、その1枚目の画像に最も近いエンベッディングを持つ画像のランクが表示される。
Zillizクラウドのベクトル検索機能をクリックした結果.png](https://assets.zilliz.com/Results_of_clicking_vector_search_function_on_Zilliz_Cloud_c1e87702cd.png)
*図8.Zilliz Cloud上のベクトル検索機能をクリックした結果(出典:筆者による画像)*。
このパートでは、ベクトルデータベースを使ったNLPタスクの実例を紹介した。ZillizのベクトルデータベースであるMilvusを使って、画像の類似検索を行うことが目的であり、画像コレクションを使い、それらの画像を前処理して埋め込みに変換し、Milvusを使ってベクトルの埋め込みを保存し、クエリを実行する。このチュートリアルは、[Zillizを使った画像を使ったベクトル類似検索](https://youtu.be/Q4OBx3S0Ysw)で再現しました。また、[Colab notebook](https://colab.research.google.com/drive/1VZ4ia9lsYighn3et6qqYW9XEKc-oPwL_?usp=sharing)も参考にしてください。
## NLP とベクトルデータベースの接点と実世界での応用例
ベクターデータベースは、類似画像の検索以外にも使用例があります。前節で見たのと同じ原理で、ベクターデータベースは様々な【ユースケース】(https://zilliz.com/vector-database-use-cases)に活用できる。例えば、[大規模言語モデル](https://zilliz.com/glossary/large-language-models-(llms))の知識を、より具体的な、ドメイン指向の情報を保存することで拡張し、より正確で首尾一貫した情報を生成することができる。例えば、Zilliz Cloudのベクトル・データベースは、図9に示すように、より正確な応答を得るために、[近似最近傍](https://zilliz.com/glossary/anns)(ANN)検索アルゴリズムを通してクエリを文脈化するために使用される、ドメインに特化した、最新の、機密データをベクトル埋め込みとして格納することによって、大規模言語モデルの精度と一貫性を強化します。
ラグ.png](https://assets.zilliz.com/rag_3d94a263d8.png)
*図9.出典Zilliz*
その他のユースケースとしては、Google検索、YouTube、Google Playなどの様々なGoogleサービスに実装されている、検索とレコメンデーションの要であるGoogleのベクトル検索技術が挙げられる。このテクノロジーは、コンテンツの発見とユーザーへの推薦方法を強化し、グーグルのプラットフォーム全体で情報検索をより効率的で適切なものにしている。
## 課題と考察、今後の方向性
NLPとベクトルデータベースの領域では、スケーラビリティ、精度とクエリー速度のバランス、データセキュリティの確保などが重要な課題となっている。[Zillizベクトルデータベース](https://zilliz.com/event/choosing-the-right-vector-database)は、スケーラビリティ、機能性、パフォーマンスなど、ベクトルデータベースを選択する際の重要な検討事項を提示している。2021年のGoogle Cloud [ブログ](https://cloud.google.com/blog/topics/developers-practitioners/find-anything-blazingly-fast-googles-vector-search-technology)の投稿では、カスタム埋め込みスペース、検索結果の品質評価、ベクトル検索と従来のエンジンとの統合など、今後10年間の検索技術とベストプラクティスの大きな進歩を予想しており、将来のベクトルデータベースアプリケーションの効率化を約束している。
## 結論
ベクトルデータベースは、非構造化データを効率的に扱い、検索する我々の能力を大きく進歩させるものである。データを機械が理解し比較できる形に変換することで、ベクトルデータベースは従来のデータベース技術では不可能であった幅広いアプリケーションを可能にする。写真の検索であれ、商品の推薦であれ、顔認識の実現であれ、ベクトルデータベースの力は、私たちを取り巻く世界の複雑さを理解する能力にあります。詳しくは、以下のリソースをご覧ください。



