




NLPエッセンシャルズAIにおけるトランスフォーマーを理解する
この記事では、自然言語処理(NLP)の分野と、画期的なアーキテクチャであるトランスフォーマーを紹介する。
シリーズ全体を読む
ChatGPT](https://zilliz.com/learn/ChatGPT-Vector-Database-Prompt-as-code) (Chat Generative Pretrained Transformer)を使ったことがあるでしょう。ChatGPTのようなチャットボットが、どうやって自然言語をうまく処理しているのか不思議に思ったことはありませんか?この記事では、自然言語処理(NLP)の分野と、2017年に「Attention is all you need」論文によって初めて発表された画期的なアーキテクチャであるトランスフォーマーを紹介します。
NLP入門
自然言語処理(NLP)は、人間の言語を解釈するAIの一分野であり、翻訳、音声認識、感情分析などのタスクを支援する。医療、法律、金融など様々な分野で活用されているNLPは、検索機能、ソーシャルメディア分析、デジタルアシスタントを強化し、テキスト、ビデオ、オーディオなどの膨大な量の非構造化データの取り扱いを効率化します。
以下の図1に示すように、自然言語モデルは2000年代から大きく進化してきた。初期のモデルは、単語をベクトル埋め込みに変換することはできたが、シーケンス内のコンテキストに苦労した。例えば、「川を渡って銀行に着いた」では、「銀行」という単語は金融機関を意味することもあれば、川岸を意味することもある。革新的なアテンション・メカニズムにより、トランスフォーマーはベクトルを文脈化することでこの問題を克服し、言語のより正確な表現につなげている。
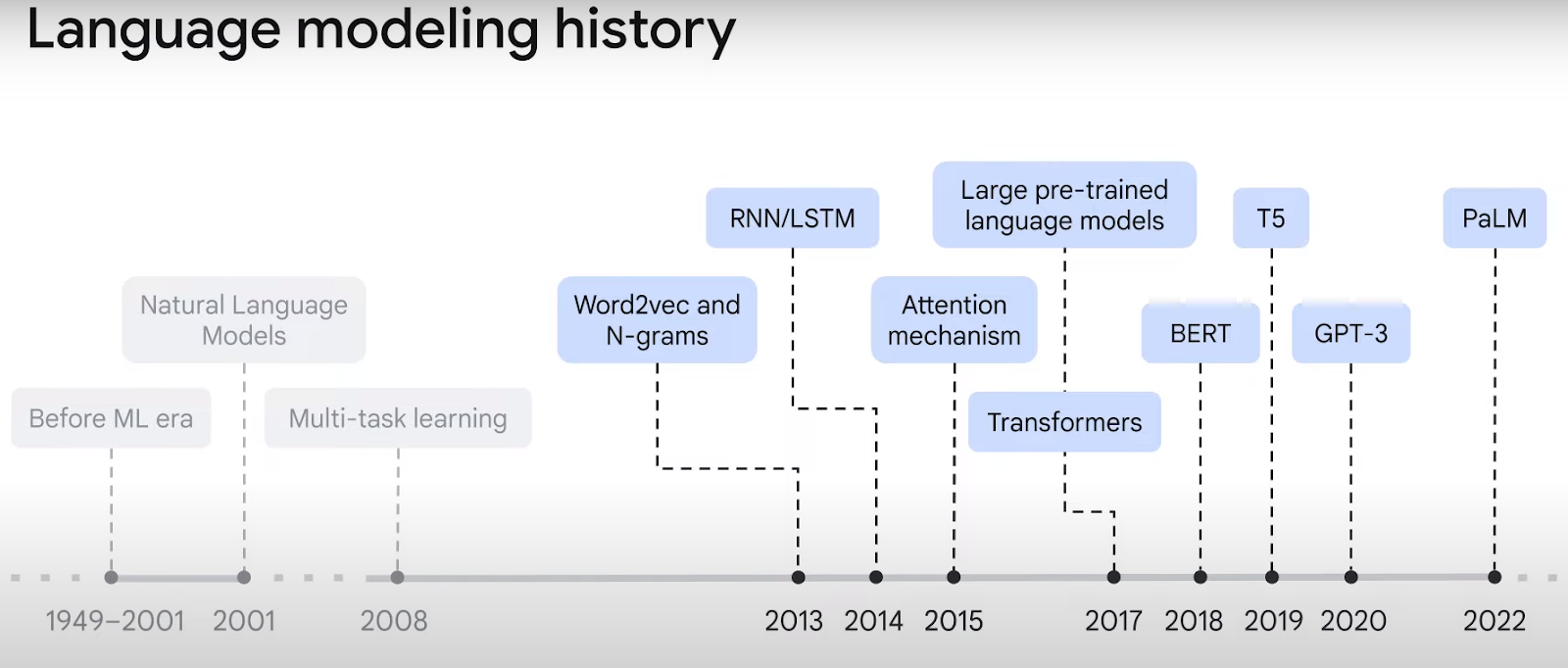
図1.出典チュートリアルビデオ by Google
トランスモデルの理解
図2に示すように、トランスフォーマーは、入力シーケンスを出力に変換するために、再帰や畳み込みの代わりに注意メカニズムを使用するエンコーダー・デコーダーモデルである。
![]()
図2.トランスフォーマーモデルの基本アーキテクチャ構造(画像:著者による)
Attention is all you need」論文の著者は、表1に示す3つの基準に基づいて、畳み込み(CNN)層とリカレント(RNN)層に対してトランスフォーマー層を評価した。彼らは、トランスフォーマー層がCNNやRNN層よりも優れていることを示した。
![]()
表1.トランスフォーマー対RNN対CNN
変圧器の主な構成要素
埋め込みと位置エンコード層
入力トークンとターゲットトークンのシーケンスはベクトルに変換されなければならない。しかし、アテンション層はこれらのベクトル集合を順番なしで見る。例えば、"How are you"、"How you are"、"you how are "は区別できないベクトルである。変換器の位置エンコード部は、埋め込みベクトルに位置をエンコードする。
エンコーダーとデコーダー
エンコーダは、入力シーケンスの埋め込みトークンを取り込む。エンコーダは、入力シーケンスの埋め込みトークンを取り込み、モデルがシーケンス内の異なるトークンの重要性を評価できるように、自己注意を通す。デコーダはエンコーダからの表現と開始シーケンス単語を受け取り、図3に示すように、適切な出力を出力する。
![]()
図3.トランスフォーマーにおける情報の流れ(画像:著者による)
自己注意をより深く
フランス語の文「Je m'appelle Juma」を英語の「My name is Juma」に翻訳したいとします。エンコーダーは、図4に示すように、位置エンコーディングが施されたフランス語文を入力として受け取る。自己アテンションはこの入力をクエリー、キー、バリュー(QKV)ベクトルに分割する。QKVベクトルが得られたら、図4に示すプロセスで、以下の式1を使用して、クエリが与えられたときに最も関連性の高い値にアテンションすることができる。
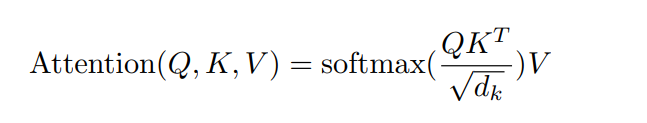
式1.クエリーの集合に対する注意関数を同時に計算する。
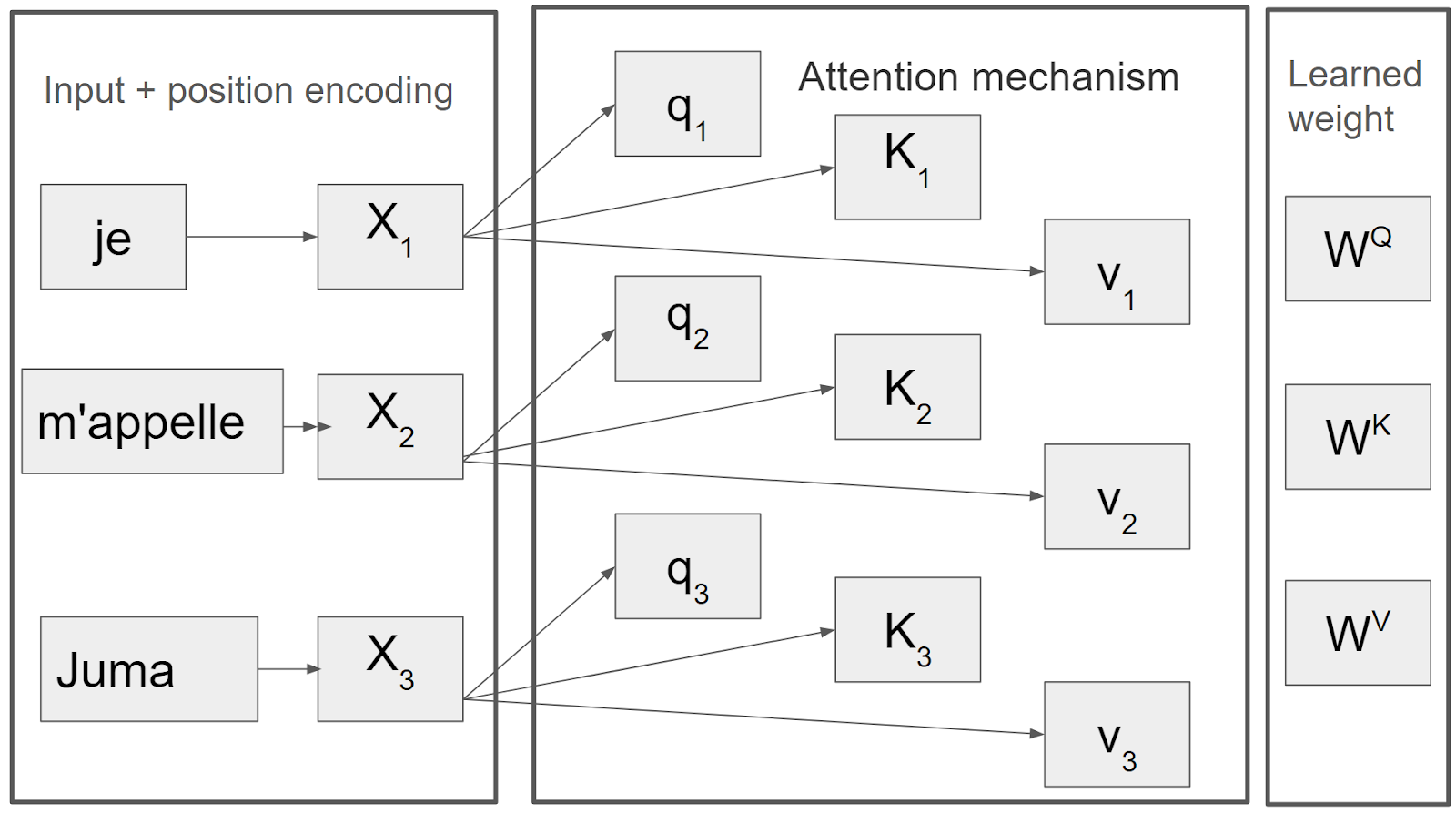
図4.アテンション・メカニズムは自己アテンション・ブロックのバックボーンであり、入力シーケンスを変換器の学習した重みから計算されたクエリーキーと値ベクトルに分解する(Image by Author)
デコーダはエンコーダから文脈に富んだベクトルを受け取り、シーケンス開始トークンを使って翻訳処理を開始する。図5に示すように、まず "Je "から "My "への翻訳を予測し、翻訳が完了するまで後続の単語を自己回帰的に生成する。
![]()
図5.変換器を使った翻訳タスクの説明図(画像:著者)
トランスフォーマーの主な用途と例
トランスフォーマーにはさまざまなモデルがある。エンコーダーとデコーダーの両方に基づくものもあれば、デコーダーまたはエンコーダーのみに基づくものもあります。
Generative pre-trained transformers (GPT)は、変換デコーダを積み重ねてテキストシーケンスを生成し、チャットボットやデジタルアシスタントを実現する。
変換器からの双方向エンコーダ表現(BERT)モデルは、単語理解のために過去と未来のトークンからより深いコンテキストを学習するように訓練されたエンコーダのみのアーキテクチャであり、現在では検索エンジンに応用されている。
視覚トランスフォーマー](https://arxiv.org/abs/2010.11929)は、画像をグリッドではなくパッチのシーケンスとして処理するためにトランスフォーマーアーキテクチャを再利用したもので、現在ではマルチモーダルなタスクに応用されている。
結論
NLPの分野は、画期的なアーキテクチャであるトランスフォーマ・モデルの出現によって、大きな変革を遂げた。我々は、RNNやCNNのような伝統的な手法に対する優位性を強調しながら、注目メカニズムの仕組みを掘り下げ、実用的な例を通してトランスフォーマーがどのように動作するかを示した。さらに、トランスフォーマーのモデルバリエーションが実世界のアプリケーションに適応する様子も観察した。トランスフォーマーとその能力についての理解を深めるために、リソース・セクションで提供されているリソースは、実装の詳細を提供する上で役に立つかもしれません。Zillizには、あなたの学習を向上させる可能性のある、より多くの学習リソースが含まれています。
リソース
NLP基礎学習シリーズ】(https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing)
NLP上級ガイド](https://zilliz.com/learn/introduction-to-natural-language-processing-tokens-ngrams-bag-of-words-models)
論文「Attention is all you need」](https://arxiv.org/abs/1706.03762)
AIにおけるトランスフォーマーとは](https://aws.amazon.com/what-is/transformers-in-artificial-intelligence/#:~:text=Each%20transformer%20block%20has%20two,the%20input%20when%20making%20predictions.)
トランスフォーマーモデルとは](https://blogs.nvidia.com/blog/what-is-a-transformer-model/)
GitHubでのアンケート](https://github.com/NiuTrans/ABigSurvey)
トランスフォーマーによるニューラル機械翻訳](https://www.tensorflow.org/text/tutorials/transformer)
注釈付きトランスフォーマー](https://nlp.seas.harvard.edu/2018/04/03/attention.html#model-architecture)



