




テキストを変換する:NLPにおけるセンテンス・トランスフォーマーの台頭
Transformersモデルのアーキテクチャ、実装、制限について知る必要があるすべてを探る。
シリーズ全体を読む
自然言語処理(NLP)は、センチメント分析のような単純なタスクからチャットボットのような複雑なタスクまで、その応用範囲の広さから、AIの中でも人気のある分野だ。NLPを必要とするユースケースに遭遇するとき、私たちは通常、テキストを入力とし、ディープラーニング・モデルに特定のタスクを実行させます。
しかし、ディープラーニング・モデルはテキストを直接処理することはできない。テキストをエンベッディングと呼ばれる高次元ベクトルに変換する必要がある。このエンベッディングこそが、ディープラーニング・モデルが理解できるものなのだ。この記事では、テキストをエンベッディングに変換するさまざまな手法の進化を探り、センテントランスフォーマーがテキストエンベッディング技術にどのような革命をもたらしたかを議論する。
Word2VecとGlove:初期の方法
高度なディープラーニングモデルが登場する以前は、テキストを埋め込みに変換するために2つの一般的な手法が使われていた:Word2VecとGloVeである。Word2Vecは、隠れ層が1つしかない基本的なフィードフォワード・ニューラルネットワークで、各単語の埋め込みを学習するように訓練されている。対照的に、GloVeはテキストコーパス中の単語間の共起を捉えるように設計されたアルゴリズムである。
これら2つの手法は学習アプローチが異なるものの、単語を埋め込みに変換するという共通の目標を持っている。これらの埋め込みは単なるランダムなベクトルではなく、対応する単語に関連する意味情報を含んでいる。つまり、類似した単語の埋め込みは、ベクトル空間において互いに近接する傾向がある。
 ベクトル空間における埋め込み | Ruben Winastwan .png
ベクトル空間における埋め込み | Ruben Winastwan .png
例えば、"dog "という単語の埋め込みは、ベクトル空間において、"puppy "と近い位置にありますが、"crime "という単語の埋め込みは、意味合いが異なるため、離れている可能性があります。
しかし、Word2VecとGloVeの両方を使用することは、少なくとも2つの重要な課題がある。
第一に、Word2VecとGloVeは単語埋め込みモデルである。文レベルでの埋め込みを得るためには、特別なテクニックが必要である。一般的なアプローチは、素朴な方法を用いたり、重み付けにTF-IDF法を用いたりして、単語の埋め込みを平均化することである。残念ながら、これらの方法では最適な結果が得られないことが多い。
次に、2つの文を考えてみよう:「I walk my dog in the park」と「I park my car in the garage」である。単語 "park*"は2つの異なる文脈で使われているにもかかわらず、どちらの文でも同じ埋め込みを持つ。
この制限は、Word2VecとGloVeの両方が、文中の各単語の文脈的意味を捉えるのに苦労しており、様々なタスクで不正確さをもたらしていることを示している。
そこでTransformersの出番となる。
トランスフォーマーの概要
TransformersはAI領域における最も重要なブレークスルーのひとつであり、テキストの分類からテキスト生成まで、多様なタスクを処理できる柔軟なアーキテクチャを備えている。BERT、XLM-Roberta、GPTなどの主要なNLPモデルはすべて、アーキテクチャのバックボーンとしてTransformersを統合している。では、一体何がTransformersをこれほど強力にしているのでしょうか?
トランスフォーマー・アーキテクチャ|ルーベン・ウィナストワン.png](https://assets.zilliz.com/Transformer_Architecture_Ruben_Winastwan_cb4415ba41.png)
一言で言えば、トランスフォーマーのアーキテクチャは、複数のエンコーダーとデコーダーのブロックで構成されている。各ブロックには、各単語(またはトークン)の文脈を文全体との関連で学習することを可能にする、特殊なアテンション・レイヤーが含まれている。その結果、"I walk my dog in the park"と "I park my car in the garage"という文の中の "park"という単語は、異なる形で埋め込まれることになる。
Transformersのエンコーダコンポーネントは、主に感情分析、質問応答、名前付きエンティティ認識などの分類タスクに使用される。Transformerエンコーダーを活用した最先端のモデルには、BERT、DistilBERT、XLM-Robertaがある。一方、デコーダコンポーネントはシーケンス生成に頻繁に使用される。Transformerデコーダを活用したモデルの代表例は、ChatGPTの基盤となっているGPTファミリーである。
センテンス・トランスフォーマーの概要
Sentence Transformersは、Transformerのエンコーダ部分を利用して、文の埋め込みを生成します。本質的には、BERT、Roberta、XLM-RobertaのようなエンコーダベースのTransformerモデルの微調整バージョンと考えることができます。
文のトランスフォーマーの内部構造を説明するために、例としてBERTベースモデルを考えてみましょう。BERT ベースモデルは、下図に示すように、合計 12 個の Transformer-encoder ブロックで構成されます:
12xエンコーダー・ブロック|ルーベン・ウィナストワン.png](https://assets.zilliz.com/12x_Encoder_Block_Ruben_Winastwan_955f7f97ee.png)
BERT-baseモデルはシーケンス全体を入力とする。最初のステップでは、入力シーケンスの先頭と末尾に2つの特別なトークン、すなわち[CLS]と[SEP]を追加する。たとえば、"I love food" という入力シーケンスは、"[CLS] I love food [SEP]" に変換される。
次に、入力シーケンスはトークンの集まりに変換され、各トークンは単語、サブワード、あるいは文字を表す。BERT のコンテキストでは、各トークンはサブワードを表す。 トークン化された入力は埋め込み層を通過し、各トークンについて768次元ベクトルを出力する。
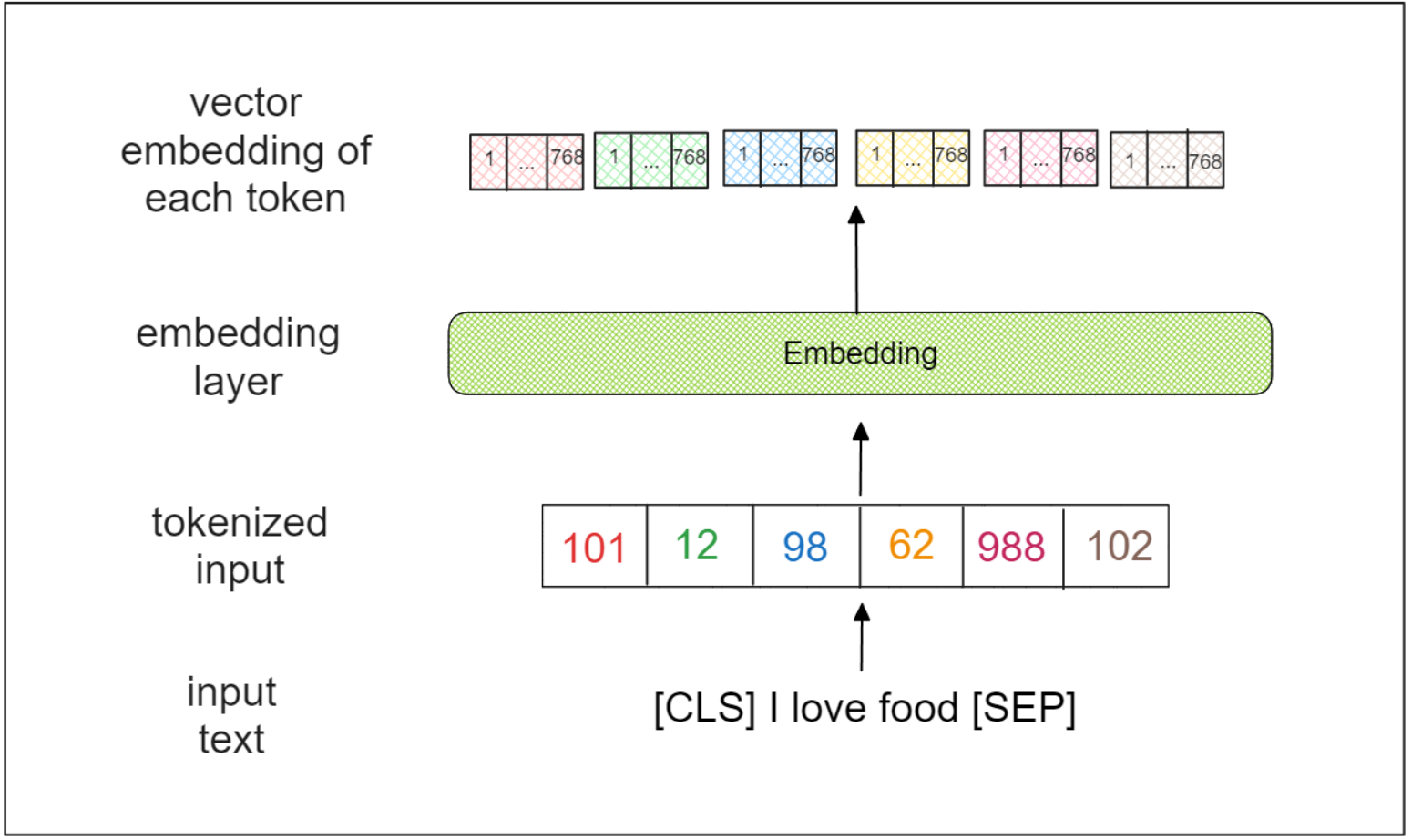 各トークンのベクトル埋め込み | Ruben Winastwan.png
各トークンのベクトル埋め込み | Ruben Winastwan.png
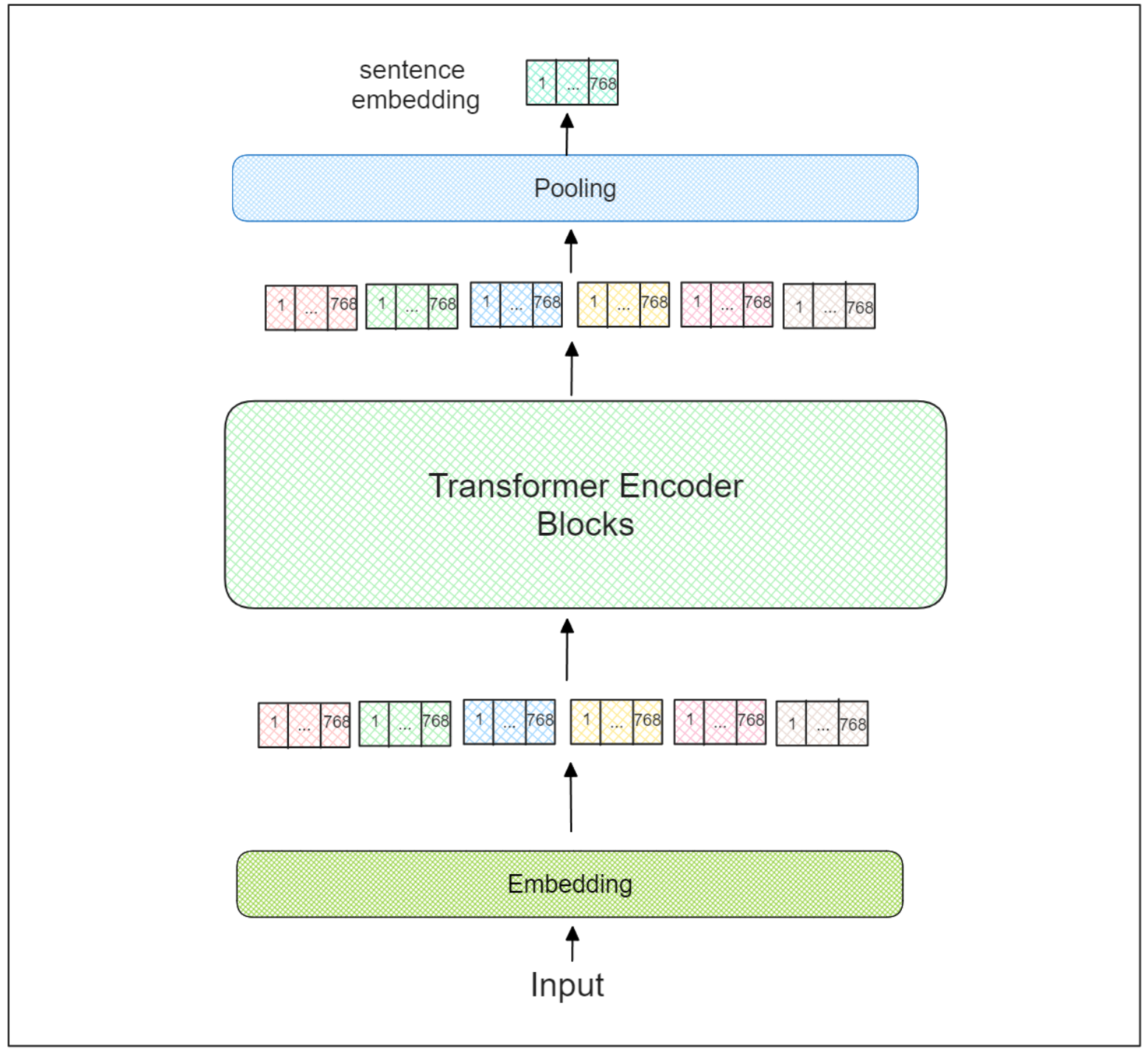
この後、各トークンのベクトル埋め込みは、12個のトランスフォーマー・エンコーダー・ブロックのシーケンスを通過する。各ブロックの中で、注意層は入力シーケンス全体との関係で各トークンの文脈を学習する。
最後のTransformer-encoderブロックで、各トークンの学習されたベクトル埋め込みを得る。しかし、ベクトル埋め込みはトークン・レベルのままである。では、文レベルのベクトル埋め込みはどうすれば得られるのだろうか?
文トランスフォーマーは、最後のトランスフォーマー・エンコーダー・ブロックの上に、追加のプーリング・レイヤーを組み込む。センテントランスフォーマーを利用する際に推奨されるプーリング戦略は3つある:
1.CLS]トークンのベクトル埋め込みのみを直接使用する。 1.すべてのトークンの埋め込み平均値を利用する。 1.全トークンの埋込みの最大時間値を利用する。
 トランスフォア・エンコーディング・ブロック|ルーベン・ウィナストワン.png
トランスフォア・エンコーディング・ブロック|ルーベン・ウィナストワン.png
このプーリング層の結果は、本質的に入力シーケンス全体の埋め込みベクトルを表す。この埋め込みは、次のセクションで説明する様々なタスクに使用することができます。
文変換器の実装
文変換モデルから得られる文レベルの埋め込みは、テキスト類似度、テキスト感情分析、情報検索、文書要約、クラスタリングなど、様々なタスクに利用することができます。
これらのタスクの中で、文の類似性と情報検索は、文Transformersの最も一般的なアプリケーションとして際立っている。そこでこのセクションでは、PyTorchのsentence-transformers`ライブラリを用いて、これら2つのタスクを実装する方法を紹介します。
以下の例では、all-MiniLM-L6-v2という学習済みの文変換モデルを使用します。I love food"という文のベクトル埋め込みを取得したいとします。以下のように、model.encode()`*メソッドを呼び出すことで、簡単にこれを行うことができます:
python pip install sentence-transformers
from sentence_transformers import SentenceTransformer, util model = SentenceTransformer("all-MiniLM-L6-v2")
エンコードする文
sentences = "私は食べ物が大好きです。"
文はmodel.encode()を呼び出すことでエンコードされる
embeddings = model.encode(sentences) print(embeddings) """
出力
[8.35129712e-03 -1.36965998e-02 5.85979000e-02 7.40111247e-02 -2.90784426e-02 -2.50987854e-04 8.10163021e-02 -5.44814840e-02 3.77929062e-02 7.24284165e-03 2.29576509e-02 -6.07334115e-02 ... ... ... 7.86333159e-02 5.17795160e-02 4.13309932e-02 -1.12455534e-02 2.45422567e-03 -1.25547433e-02 1.07740775e-01 1.18402615e-02 3.46895605e-02 7.11588934e-02 -1.47232888e-02 -1.09383598e-01 ]
これで、埋め込みを複数のことに使えるようになった。例えば、この埋め込みを他のテキストの埋め込みと比較して、最も類似したテキストを見つけることができます。
sentences1 = ["私は食べ物が大好きです"]。
sentences2 = [ 「私はステーキが大好きです 「女性がテレビを見ている "新しい映画はとても素晴らしい"、 ]
両方のリストの埋め込みを計算する
embeddings1 = model.encode(sentences1, convert_to_tensor=True) embeddings2 = model.encode(sentences2, convert_to_tensor=True)
#余弦類似度を計算する cosine_scores = util.cos_sim(embeddings1, embeddings2)
ペアとそのスコアを出力
for i in range(len(sentences2)): print("{}")\{}\Score: {:.4f}".format( sentences1[0], sentences2[i], cosine_scores[0][i]) )) """
出力
食べ物が好き ステーキが好き スコア: 0.6131 食べ物が好き 女性がテレビを見ている スコア: 0.0898 食べ物が大好き 新しい映画はとても素晴らしい スコア: 0.1875
おわかりのように、「ステーキが大好き」というテキストは、他の例と比べて「食べ物が大好き」というテキストとの意味的類似度が最も高い。この結果は理にかなっている。ステーキは食べ物のサブセットであるのに対し、他のテキストは食べ物とのテーマ的関連性がないからである。
センテントランスフォーマーのもう一つの一般的な使用例は、情報検索の領域である。この場合、通常、個々のテキストの埋め込みを、ベクトルデータベースのような専用のデータベースに格納する。そして、特定のテキストに関する情報が必要なときに、その埋め込みをデータベースから取り出す。
例として、データベースに次のようなテキストがあるとします:
コーパス = [ "男が食べ物を食べている、 「女の子が赤ちゃんを抱いている、 「男が馬に乗っている、 「女性がバイオリンを弾いている、 ]
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
あるクエリのシナリオを考えてみよう:「ある男性が食卓に座っています。というクエリがあり、我々のゴールはデータベースから最も確率の高い答えを取り出すことである。これを達成するために、クエリとデータベースの各エントリとの類似度を計算することができます。
query = "男が食卓に座っている。彼は何をしていますか?"
余弦類似度に基づいて、各クエリ文に最も近いコーパスの2文を見つける
top_k = min(2, len(corpus))
query_embedding = model.encode(query, convert_to_tensor=True)
cosine-similarityとtorch.topkを使って最高5つのスコアを見つける
cos_scores = util.cos_sim(query_embedding, corpus_embeddings)[0]. top_results = torch.topk(cos_scores, k=top_k)
print("Query:", query) print("コーパスの最も類似した文トップ2:")
for score, idx in zip(top_results[0], top_results[1]): print(corpus[idx], "(スコア: {:.4f})".format(score)) """ 出力 クエリーある男が食卓に座っている。彼は何をしているのか?
コーパスの類似文トップ2: 男がご飯を食べている。 (スコア: 0.4170) 男が馬に乗っている。(スコア: 0.2206)
私たちの観点からは、私たちのクエリに対する最も適切な応答は "A man is eating food "であり、これは埋め込み類似度が示すものと一致する。
最近の進歩では、RAG(Retrieval-Augmented Generation)フレームワークの中でGPTモデルの精度を向上させるために、センテントトランスフォーマーによって生成された埋め込みを使用することができます。この方法論により、GPTモデルは内部情報をより効果的に検索できるようになり、文脈に関連した応答の生成が容易になる。
## センテンス・トランスフォーマーのトレーニング手順
上の実装セクションで、テキスト埋め込みを生成するために事前学習されたモデルを使用したことにお気づきでしょうか。しかし、事前学習されたモデルによって生成された埋め込みが十分でない場合、どうすればよいのでしょうか?あるいは、事前学習モデルが利用できない外国語のテキストの埋め込みを生成する必要がある場合、どうすればよいでしょうか?
このような場合、自力で文型変換モデルを学習する必要があります。
文型変換モデルの学習プロセスは、通常のシャムニューラルネットワークの学習プロセスとまったく同じです。2つの入力を受け取り、その意味に基づいて2つの入力の類似性を判断することが目的である。非類似のペアの埋め込みはより遠くに押しやられ、類似のペアの埋め込みはより近くに押しやられる。
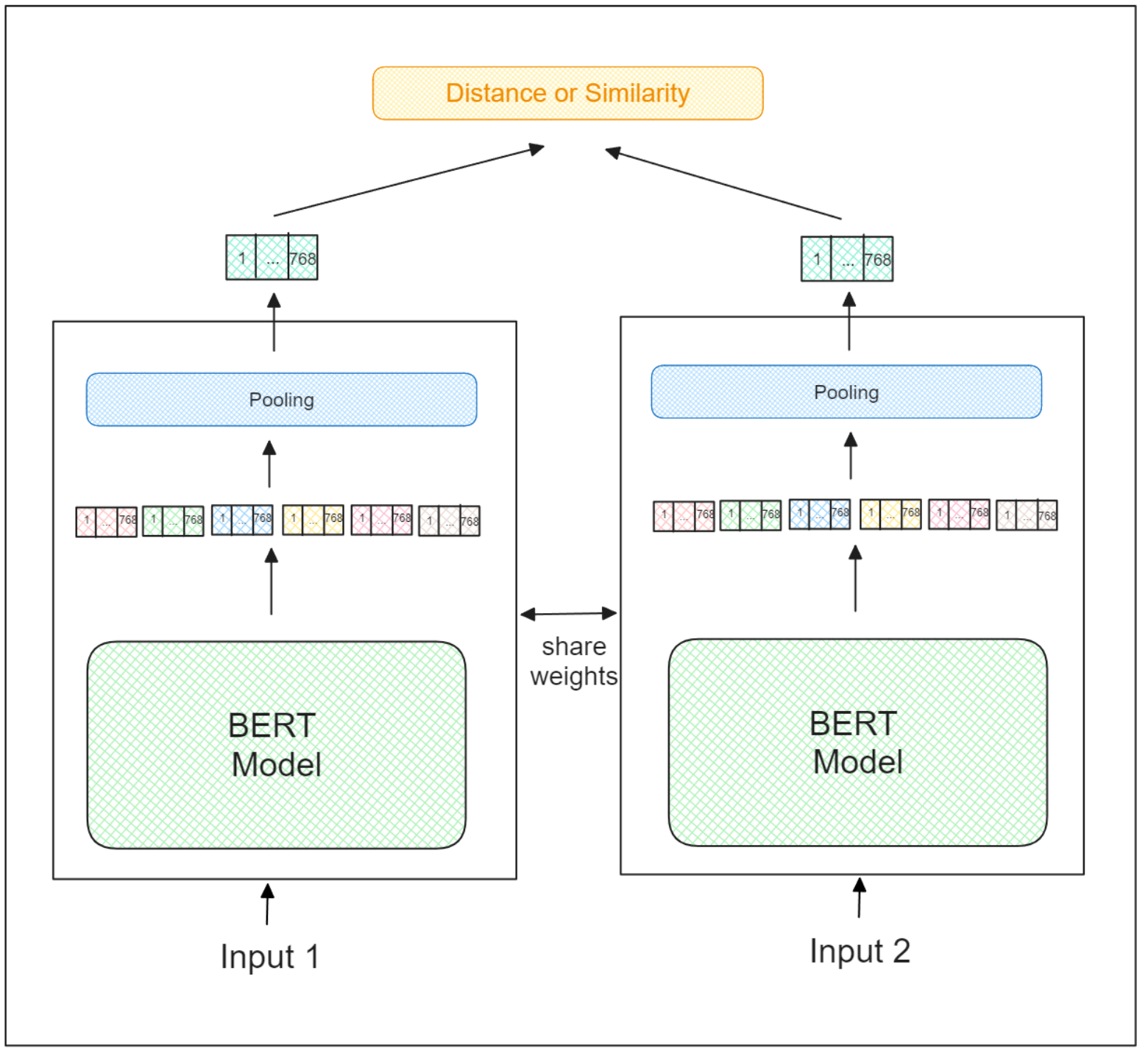
したがって、文変換モデルを学習するには、十分な量の学習データが必要であり、各データは2つの文を入力とし、対応する類似度をラベルとして構成される。
しかし、2つの文の類似度を設定する方法は、万能ではありません。それはあなたの目的とデータの構造に大きく依存するからである。
例えば、同じレポート内の2つの文の類似度を高く設定する場合と、異なるレポート内の2つの文の類似度を高く設定する場合があります。同様に、隣接するセンテンス間の類似度を、隣接しないセンテンス間の類似度よりも高く設定することもできます。また、2つの文が互いに矛盾する場合、類似度は0となり、逆に一致する場合、類似度は1となる。
## 文章変換器の課題と改良
一般的に、文レベルでの正確な埋め込みを生成する文Transformersの能力は、その高度なTransformersアーキテクチャのおかげで、Word2VecやGloVeのような伝統的な手法を凌駕している。
しかし、前節で説明したように、文Transformersモデルの学習プロセスでは、学習データの準備に多大な労力を要します。2つの入力テキスト間の類似度を明示的にラベル付けする必要がある。この課題に対処するため、現在、文Transformersの学習に最適な教師なし手法を特定することを目的とした研究が活発に行われている。
その一例が[TSDAE](https://arxiv.org/abs/2104.06979)であり、ノイズ除去オートエンコーダに基づく教師なし文埋め込み学習手法である。この手法では、入力テキストにノイズを導入する。そして、エンコーダはこのノイズ入力をベクトル埋め込みにマップする。次にデコーダはノイズを除去して元のテキストを再構成しようとする。最後に、エンコーダを文埋め込み手法として使用する。
もう一つのアプローチは[simCSE](https://arxiv.org/abs/2104.08821)であり、同じ入力テキストを2回エンコードする、教師なし文埋め込み学習手法である。Transformersアーキテクチャ内部のドロップアウト機構により、結果として得られるベクトル埋め込みはわずかに異なる位置になる。そこで、同じバッチに含まれる他の入力テキストのベクトル埋め込みとの距離を最大化しつつ、これら2つの埋め込み間の距離を最小化することを目的とする。
とはいえ、教師なし学習で学習されたモデルの性能は、教師あり学習で学習されたモデルよりもはるかに劣っているため、文Transformersモデルを学習するための教師なし学習分野の研究は、まだまだこれからである。
## 結論
この記事では、Transformersモデルについて、そのアーキテクチャ、実装、限界について、知るべきことをすべて学んだ。全体として、文のTransformersモデルは、AI領域における重要なブレークスルーであり、トークンレベルの埋め込みと比較して、より広い適用範囲を提供する文レベルの埋め込みを生成することを可能にする。
文レベルの埋め込みは、テキストのより正確で文脈を考慮した表現を提供する。そのため、意味的類似性、情報検索、意味検索、テキスト分類など、幅広い自然言語処理タスクに有用です。また、RAGシナリオにおけるGPTのようなモデルと文Transformersエンベッディングの統合は、生成された応答の精度と関連性を向上させる有望な結果を示している。
この記事が、センテントランスフォーマーを使い始めるための参考になれば幸いです!



