




🚀 Milvus v2.4.3のメタデータフィルタリングの新機能
Milvus v2.4.3は完全な文字列メタデータマッチングを導入しました!これにより、接頭辞、接尾辞、接尾辞、あるいは文字ワイルドカード検索を使用して文字列をマッチングできるようになりました。
# 接頭辞の例、"The "で始まる文字列にマッチします。
expression='title like "The%"'.
# インフィクスの例: 文中のどこかに "the "を含む文字列にマッチします。
expression='「%the%」のようなタイトル'
# Postfixの例: "Rye "で終わる文字列にマッチします。
expression='「%Rye」のようなタイトル'
# 1文字のワイルドカードの例.
expression='title like "Flip_ed"'.
以前のブログでは、接頭辞文字列マッチングについてのみ説明しました。しかし、Milvus v2.4.3以降では、配列値を使った完全一致や、配列内の要素が一致するかどうかのチェック(contains_any())など、あらゆるバリエーションが可能になっています。🗂️🔍
これらのアップデートにより、メタデータのフィルタリングがより多機能で強力なものになりました!
例で説明しましょう。このブログでは、KaggleからダウンロードしたIMDB映画データを使うことにする。
# 一般的なライブラリをインポートする。
インポート sys, os, time, pprint
import pandas as pd
# CSVデータを読み込む。
df = pd.read_csv("data/original_data.csv")
# デモ用にデータをショートカットする。
df = df.tail(200)
表示(df.head())

各映画には'text'フィールドがあり、説明とレビューが表示されます。📝
各映画には、公開年、レーティング、ジャンル、俳優、キーワードのリストなどのメタデータが含まれています。🎬⭐️📅
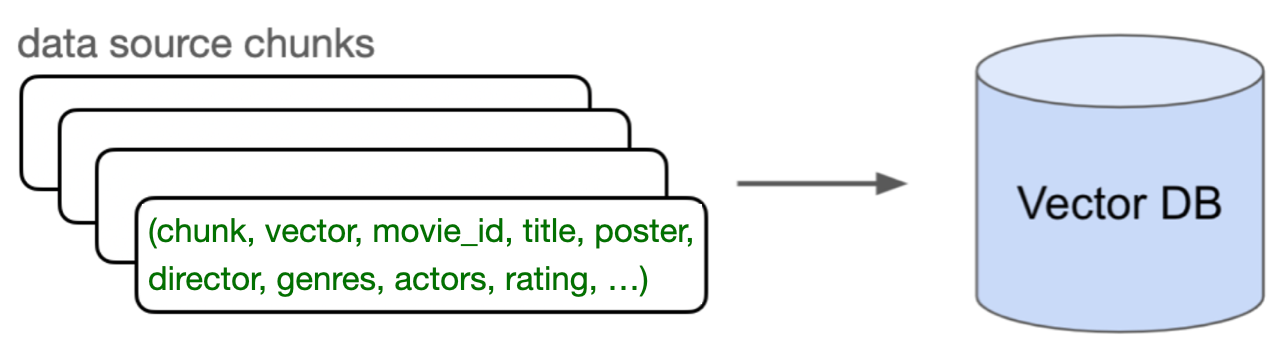
各 "行 "は、映画レビューのテキストチャンク、そのベクトル表現、movie_id、映画タイトル、ポスターリンク、ジャンル、俳優などのメタデータを表す。
通常のRAGパターンに従う: 📝🫃。
1.Milvusに接続する:まず、Milvusのローカル展開であるMilvus Liteに接続する。これはベクターを保存・管理するためのデータベースである。🖥️🔗
2.映画のテキストをベクトルに変換します:各映画のテキストフィールド(説明とレビューを含む)を取り出し、ベクターに変換します。これにはHuggingFaceモデル** BAAI/bge-large-en-v1.5 を使います。🧠➡️📏
3.ベクターとメタデータをMilvusに挿入します:このベクトルを、元のテキスト(「チャンク」と呼びます)とそのメタデータ(年、レーティング、ジャンルなど)とともにMilvusに挿入します。 📥📊
4.**ユーザーのクエリを処理する:ユーザーのクエリを同じ埋め込みモデルを使ってベクトルに変換する。次に、近似最近傍探索を実行し、クエリ・ベクトルに最も近いデータ・ベクトルを見つける。🔍🎬
完全なコードは私のGitHubにあります。
まず、Milvusに接続します。Pymilvusをpip-installする必要があります。(ローカルのファイル名だけを指定することで、ローカルのベクターデータベースであるMilvus Liteを使用します。dockerやK8sがデプロイされていたり、完全に管理されているZilliz Cloudなど、他のMilvusがある場合は、URIとTokenを指定して接続することができます。残りのコードは同じように動作します)。
# !python -m pip install -U pymilvus
import pymilvus
# クライアントをMilvus Liteサーバに接続する。
from pymilvus import MilvusClient
クライアント = MilvusClient("milvus_demo.db")
次に、映画のレビューを含むテキストカラムをチャンクしてベクトルに埋め込む。多くのリソースがその方法を例示しているので、ここで改めてコードを示すことはしない。 以下では、チャンクされたテキスト、ベクター表現、メタデータを組み立て、データをMilvusに挿入する方法を示す。
# 一つのループでchunk_listとdict_listを作成する。
dict_list = [].
for id, title, chunk, vector, poster_url, director, \
genres, actors, keywords, film_year, rating in zip(
df.id, df.Name, chunks, converted_values, df.PosterLink、
df.監督, df.ジャンル, df.俳優, df.キーワード、
df.MovieYear、df.RatingValue):
# 埋め込みベクトル、元のテキストチャンク、メタデータを組み立てる。
chunk_dict = { {'movie_index': id
'movie_index': id、
'title': タイトル、
'chunk': chunk.page_content、
'poster_url': poster_url、
'director': 監督、
'genres': ジャンル、
'actors': 俳優、
'keywords': キーワード
'film_year': フィルム年、
'rating': レーティング
'vector': vector、
}
dict_list.append(chunk_dict)
# データをMilvusコレクションに挿入する。
print("エンティティの挿入を開始")
start_time = time.time()
client.insert(
コレクション名
data=dict_list、
progress_bar=True)
end_time = time.time()
print(f "Milvus insert time for {len(dict_list)} vectors:", end="")
print(f"{np.round(end_time - start_time, 2)}秒")

データがMilvusに入ったので、検索する準備ができた!
文字列メタデータフィルタによる検索
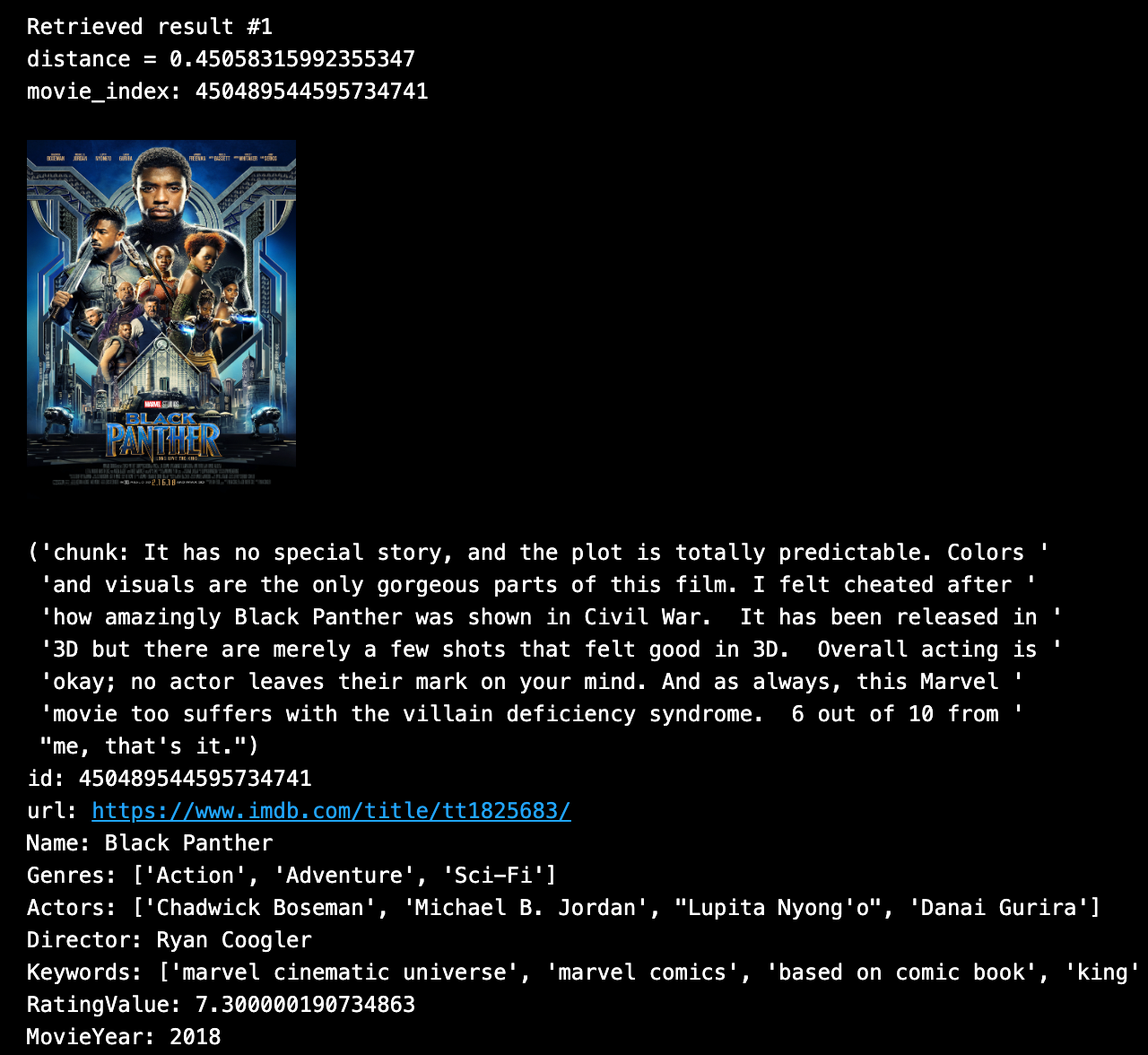
例えば、ロボットが登場するディストピア的な未来が描かれ、評価の高いSF映画を検索したいとします。 サンプルデータはこの検索に使えるメタデータを持っています。
以下は、ファジーな文字列マッチを使ったメタデータのフィルタリングの例です。以下では、vanilla Milvus search APIのみをラップして、検索後にメタデータを表示しやすくしています。
SAMPLE_QUESTION = "ロボットが出てくるディストピアSF"
TOP_K = 1
# メタデータのフィルター
expression='rating >= 7'
# インフィックス文字列マッチ。
expression=expression + ' && title like "%Panther%"'.
formatted_results、context、context_metadata = \
mc_run_search(SAMPLE_QUESTION, expression, TOP_K)
リソースと参考文献
https://github.com/milvus-io/pymilvus/blob/2.4/examples/fuzzy_match.py
https://milvus.io/docs/boolean.md#Usage
https://milvus.io/docs/single-vector-search.md#Filtered-search

読み続けて

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Announcing VDBBench 1.0: Open-Source VectorDB Benchmarking with Your Real-World Production Workloads
Discover VDBBench 1.0, an open-source tool for benchmarking vector databases with real-world production data, streaming ingestion, and concurrent workloads.

Optimizing Embedding Model Selection with TDA Clustering: A Strategic Guide for Vector Databases
Discover how Topological Data Analysis (TDA) reveals hidden embedding model weaknesses and helps optimize vector database performance.