




Zilliz Cloudのよりスマートなオートスケーリング:あらゆるワークロードに常に最適化
AIワークロードは、滑らかで予測可能な曲線を描くわけではありません。ある瞬間には、ベクトルデータベースがクエリを余裕をもって処理していても、次の瞬間には、バイラルキャンペーン、新しいデータ取り込み、または日常的な午前9時のログイン急増によって、使用量が危険域に押し上げられます。チームは、過剰プロビジョニングで予算を無駄にするか、過小プロビジョニングでボトルネックのリスクを負うかの選択を迫られます。
最新のアップグレードにより、Zilliz Cloud はよりスマートなオートスケーリングを導入します—完全自動化され、より合理化された、弾力的なリソース管理システムです。パフォーマンスを維持するために即座にスケールアップし、無駄を削減するために自動的にスケールダウンすることで、推測を排除し、どのようなワークロード下でもデータベースを適切なサイズに保ちます。
オートスケーリングの新機能とその仕組み
Zilliz Cloud は以前から自動スケールアップをサポートしており、突然のトラフィックスパイク時にもパフォーマンスを確保してきました。今回のリリースにより、スケールダウンも自動化され、コスト最適化のループが完結します。しきい値を調整したり、いつ調整すべきかを推測したりする代わりに、最小および最大の CU 範囲を設定するだけで、Zilliz Cloud がリアルタイムで容量を継続的に最適化します。つまり、次のことが可能になります。
コスト削減 – 需要が低下すると、リソースが自動的に縮小します。
一貫したパフォーマンス – 需要が急増すると、リソースが即座に拡張します。
運用の簡素化 – 手動のしきい値管理や継続的な再設定が不要になります。
内部では、オートスケーリングは、実際のワークロードパターンの全範囲をカバーする2つの補完的なモードによって支えられています。
Dynamic Scaling – これはシステムのリアクティブなインテリジェンスです。リアルタイムの CU (Compute Unit) 使用率を継続的に監視することで、Zilliz Cloud は、大量の取り込みや複雑なクエリ負荷などの予測不能なスパイク時にリソースを自動的にスケールアップし、需要が収まるとスケールダウンします。その結果、恒久的な過剰プロビジョニングによる無駄を避けながら、一貫したパフォーマンスを実現します。
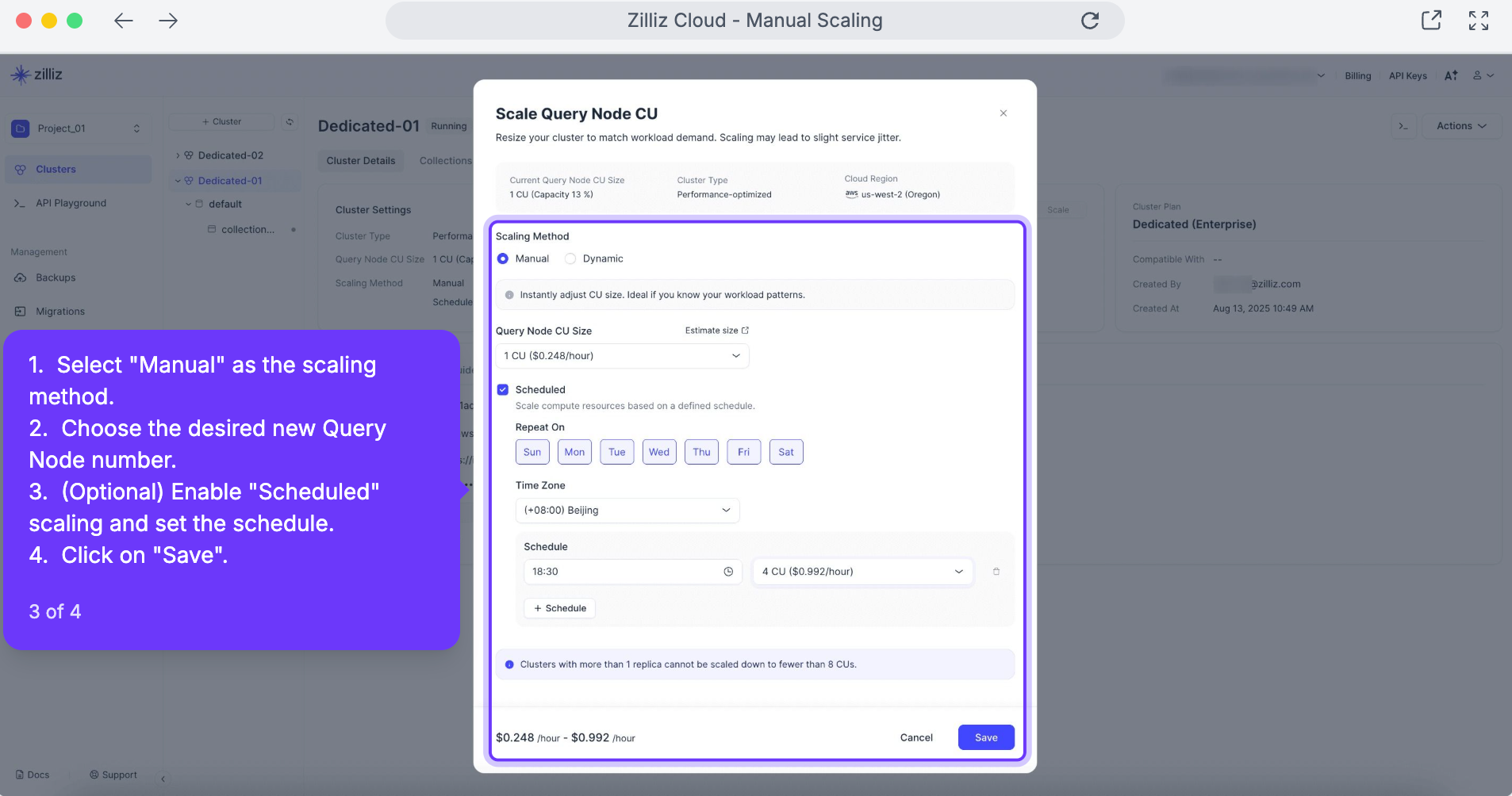
Scheduled Scaling – これはプロアクティブな対応策です。多くのワークロードは、朝のログイン急増やピーク営業時間など、予測可能なパターンに従います。スケジュールされたスケーリングにより、時間枠に基づいて CUs と Replicas の両方の調整を事前に定義できます。これにより、予想されるトラフィックに対してシステムを十分に準備しつつ、オフピーク時の不要なコストを回避できます。
注: いつでも手動でスケールすることもできます。
これらの機能を組み合わせることで、ベクトルデータベースは常に適切なタイミングで適切なリソースを確保でき、無駄な支出やパフォーマンスリスクを回避できます。
オートスケーリングの実用的なユースケース
この機能を具体的に理解するために、オートスケーリングが測定可能なビジネス価値をもたらす3つの一般的なユースケースを見てみましょう。
1. フラッシュセールの熱狂
ある e コマースプラットフォームが正午に2時間限定のフラッシュセールを開始します。トラフィックが殺到し、ベクトル駆動の「類似商品」API やレコメンデーション API に大きな負荷がかかります。スケーリングしなければ、収益がかかっているまさにその瞬間にシステムが不安定になる可能性があります。
解決策: Scheduled Replica Scaling により、イベント開始直前の午前11時50分にレプリカを4倍に増やし、午後2時5分にベースラインへ戻すことができます。これにより、ピーク時間帯にスムーズなパフォーマンスを確保しながら、必要なときにのみ容量分の料金を支払うことが保証されます。
2. 朝のログイン急増
ある企業の AI ナレッジベースでは、平日の午前9時に数百人の従業員がログインします。この急増によりクエリ容量が圧迫され、RAG チャットボットの応答が遅くなり、業務日の始まりに不満を生み出します。
解決策: Scheduled Scaling により、クエリノードのレプリカを午前8時50分に自動的に拡張し、混雑が収まった後に再び縮小できます。これは、ラッシュアワー前に高速道路の車線を増やすようなもので、トラフィックが解消された後にリソースを無駄にすることなく、応答時間を高速に保ちます。
3. 深夜のカタログ更新
データパイプラインが夜間に大規模な予定外の再インデックス作業を開始します。このプロセスはメモリを消費し、ライブトラフィックと競合するため、検索が遅くなり、タイムアウトのリスクさえ生じます。
解決策: Dynamic CU Scaling により、Zilliz Cloud は容量が増加するとリアルタイムで対応し、ワークロードを吸収するために CU を自動的にスケーリングします。インデックス作成が完了すると、リソースは再びスケールダウンします。ライブクエリは高速なまま維持され、取り込みはスムーズに完了し、手動での介入は不要です。
次は何か?
このリリースは大きな前進ですが、同時に、リソースを完全に自律管理するベクトルデータベースという、より大きな構想の基盤でもあります。
現在、私たちは Zilliz Cloud において、よりきめ細かなスケーリング戦略を積極的に探求しています。ワークロードが異なれば、求められるトレードオフも異なります。コスト効率を優先するものもあれば、常にパフォーマンスの余裕を必要とするものもあります。私たちは、望ましい戦略を定義できるスケーリング「プロファイル」を構想しています。バックグラウンドジョブ向けの保守的なもの、一般的なワークロード向けのバランス型、あるいは重要なローンチ向けの積極的なものです。これにより、運用上の推測を減らしながら、チームにきめ細かな制御を提供できます。
私たちの長期的な目標は、自律的かつ適応可能なリソース管理フレームワークを開発し、手動作業ゼロで、ベクトルデータベースが常に需要に応じた容量に合わせられるという安心感を提供することです。
Zilliz Cloud で Autoscaling を始める
Autoscaling は Zilliz Cloud で利用可能になっており、今すぐ使い始めることができます。ご自身で試す方法は次のとおりです。
Zilliz Cloud コンソールにログインします。 プロジェクトに移動し、管理したいクラスターを選択します。
CU 範囲を設定します。 ワークロードに対する最小および最大の Compute Units (CUs) を定義します。Autoscaling は、この範囲内でリソースを自動的に拡張および縮小します。
スケーリングモードを選択します。
- 予測不能なワークロード(例: データ取り込み、突然のクエリ急増)には Dynamic Scaling を使用します。
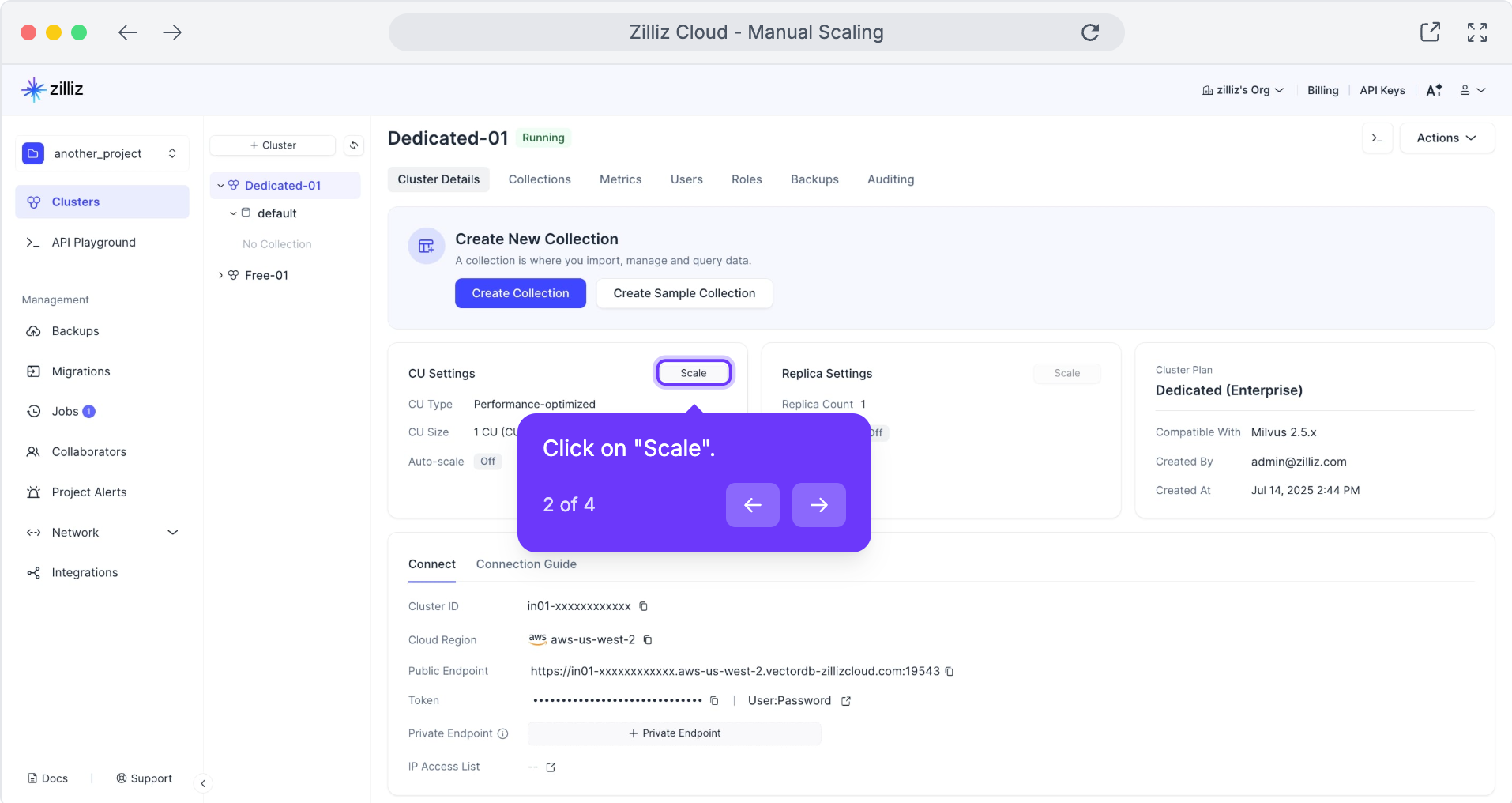
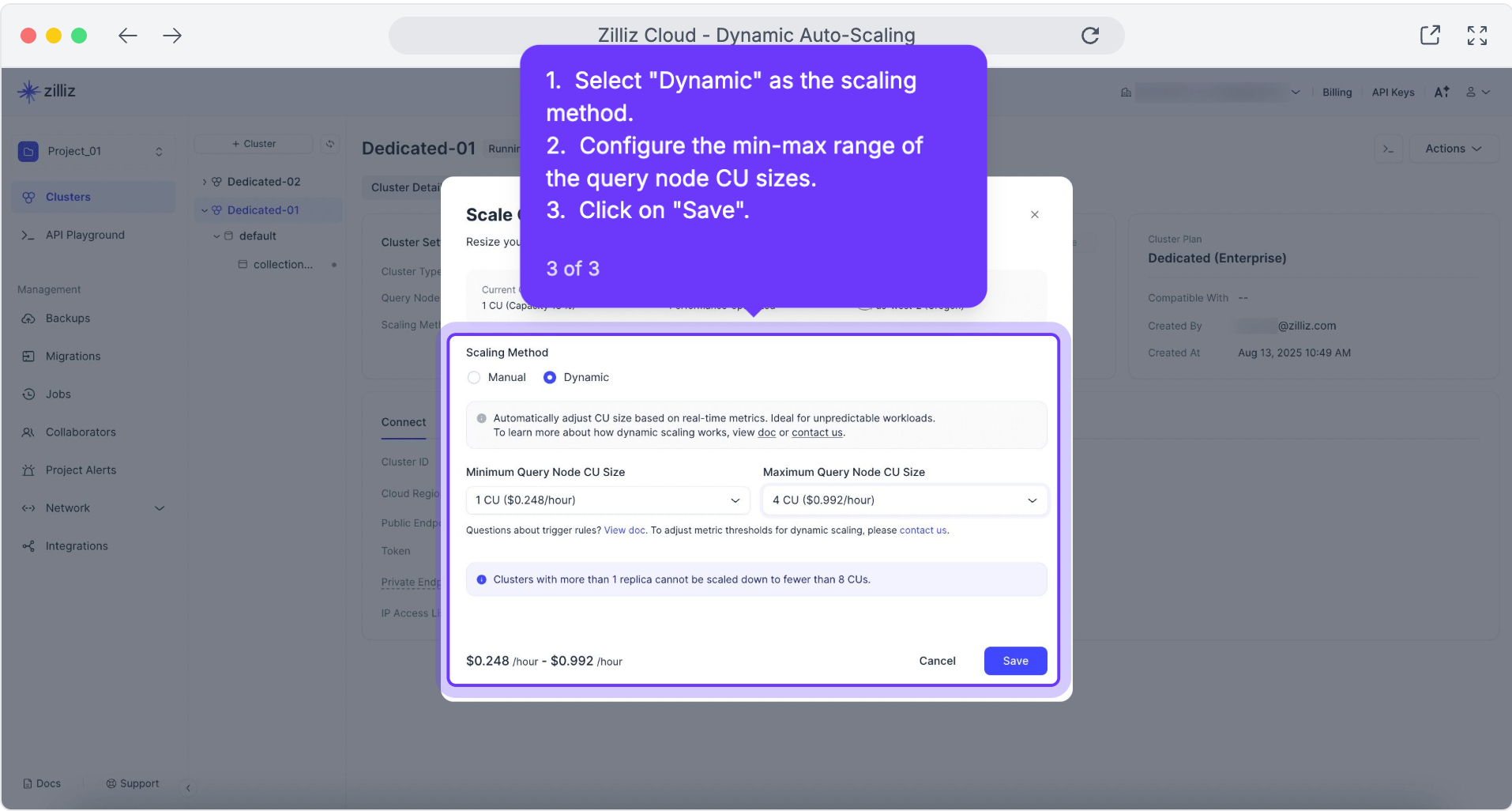
予測可能なサイクル(例: 朝のログイン急増、フラッシュセール)には Scheduled Scaling を使用します。
すぐに調整したい場合は、いつでも 手動でスケーリング することもできます。
- 実際の動作を確認します。 クラスターがリアルタイムでどのようにスケールアップおよびスケールダウンするかを監視し、ワークロードについて理解が深まるにつれて微調整します。
わずか数クリックで、データベースは継続的なチューニングなしに適正なサイズを維持します。ピーク時にはより高速なパフォーマンスを、閑散時にはより低いコストを実現し、その過程で運用上の負担も軽減されます。
ヒント: まずは広めの CU 範囲から始めて Autoscaling の挙動を観察し、ワークロードへの理解が深まったら制限を微調整してください。
👉 詳細については、autoscaling documentation をご確認ください。
👉 ご質問がありますか?私たちの support team がお手伝いします。
Autoscaling だけではない: Zilliz Cloud のエンタープライズ対応機能
Autoscaling は、Zilliz Cloud を最も包括的で本番環境対応のベクトルデータベースサービスにしている要素の一つにすぎません。最近のリリースでは、SSO GA、audit logs、Milvus 2.6 private preview、そして大規模に AI を構築するチームのニーズを満たすために設計された、増え続けるエンタープライズグレードの機能群も導入しました。(詳細は launch blog をご覧ください。)
Milvus 上に構築された Zilliz Cloud は、以下を備えたフルマネージド体験を提供します。
柔軟なスケーリングとコスト効率 – ワンクリックデプロイ、サーバーレス自動スケーリング、従量課金制。
高度な AI 検索 – メタデータフィルタリング、動的スキーマ、マルチテナンシーに対応した、ベクトル検索、全文検索、ハイブリッド(スパース + デンス)検索。
自然言語クエリ – 複雑な API なしで直感的なクエリを実現する MCP サーバーサポート。
エンタープライズグレードの信頼性とセキュリティ – 99.95% SLA、SOC 2 Type II および ISO 27001 認証、GDPR 準拠、HIPAA 対応準備、RBAC、BYOC、そして新たに監査ログ。
グローバルな可用性 – AWS、GCP、Azure 全体でのデプロイにより、世界中で 100ms 未満のレイテンシを実現。
シームレスな移行 – Pinecone、Qdrant、Elasticsearch、PostgreSQL、OpenSearch、またはオンプレミスの Milvus から移行するための組み込みツール。
これらの機能により、Zilliz Cloud は単なるベクトルデータベースサービスではなく、エンタープライズ AI アプリケーション向けの本番対応基盤となります。

読み続けて

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Introducing Business Critical Plan: Enterprise-Grade Security and Compliance for Mission-Critical AI Applications
Discover Zilliz Cloud’s Business Critical Plan—offering advanced security, compliance, and uptime for mission-critical AI and vector database workloads.

Bringing AI to Legal Tech: The Role of Vector Databases in Enhancing LLM Guardrails
Discover how vector databases enhance AI reliability in legal tech, ensuring accurate, compliant, and trustworthy AI-powered legal solutions.