




ベクトル検索とRAG - 精度とコンテキストのバランス
#はじめに
大規模言語モデル(LLM)は、特に機械学習や自然言語処理において大きな進歩を遂げ、機械が複雑なタスクを簡単に処理できるようになった。しかし、LLM技術が成長するにつれ、LLMはユニークな問題に直面している:AIの幻覚である。これは、AIが誤った情報や虚偽の情報を生成することで、これらのシステムがどれほど信頼できるものなのか疑問を抱かせるものである。Zillizのデベロッパー・アドボケイトであり、AI/MLの豊富な経験を持つChristy Bergmanは最近、Unstructured Data Meetupで、こうした幻覚の影響とAIシステムの展開に与える影響について語った。
クリスティはプレゼンテーションの中で、AIの幻覚の原因とその影響について述べた。彼女はまた、Retrieval Augmented Generation (RAG)と呼ばれる主なコンセプトについても言及した。これは、ユーザーの質問に関連する最新の情報を提供することで、言語モデルの信頼性を高めるために用いられる手法である。この技術は、モデルが最近のニュースや研究のような最新のデータにアクセスできるようにし、より良い回答を与え、ミスを減らすのに役立つ。
AI の幻覚を理解する
AI幻覚とは、人工知能システム、特に大規模な言語モデルに基づくシステムが、事実と異なる、誤解を招く、あるいは完全に捏造された出力を生成する現象を指す。
この問題はいくつかの理由で起こりうる:
1.1:コンテキストの欠如: AIモデルは、特に複雑または微妙なクエリを扱うときに、正確な応答を生成するのに十分なコンテキストを持っていない可能性があります。
2.学習データの問題: AIモデルの学習に使用されるデータには、エラー、バイアス、または古い情報が含まれている可能性があり、モデルが不注意に複製する可能性があります。
3.過度な汎化: AIモデルは学習データから過度な汎化を行う可能性があり、新しい入力に直面したときに正しくない外挿につながる。
4.設計の限界: 一部のAIアーキテクチャは、その出力の真実性を検証するように設計されておらず、代わりに学習データに基づいて統計的に可能性の高い応答を生成することに焦点を当てています。
クリスティは非構造化データ・ミートアップでこの素晴らしい例を挙げた。彼女はAIシステム "Gemini "にニューヨーク生まれの政治家を3人挙げるよう求めたところ、ヒラリー・クリントンが含まれていた。
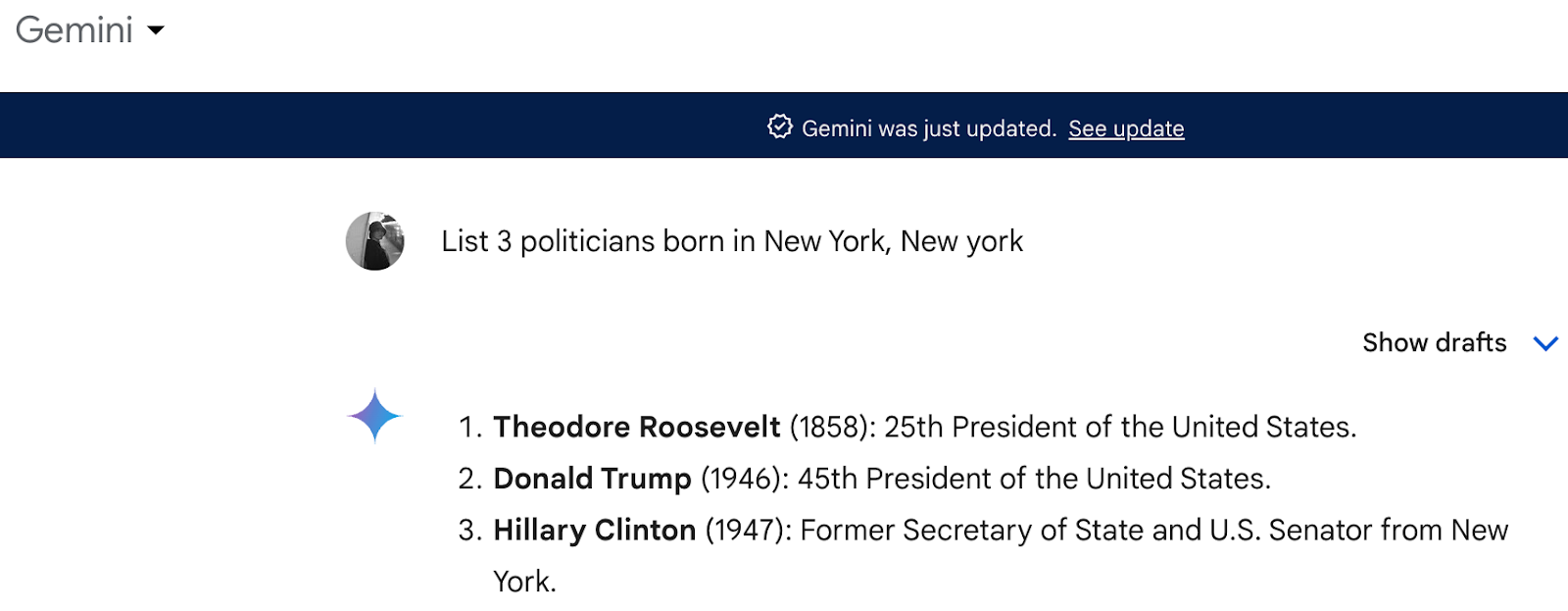

この例は、単純でわかりやすい質問であっても、AIがいかに間違いを犯すかを示している。
クリスティが言及したように、"LLMはRedditのような型にはまった情報源で訓練されることがあり、それが異常な結果をもたらすことがあることに注意"。
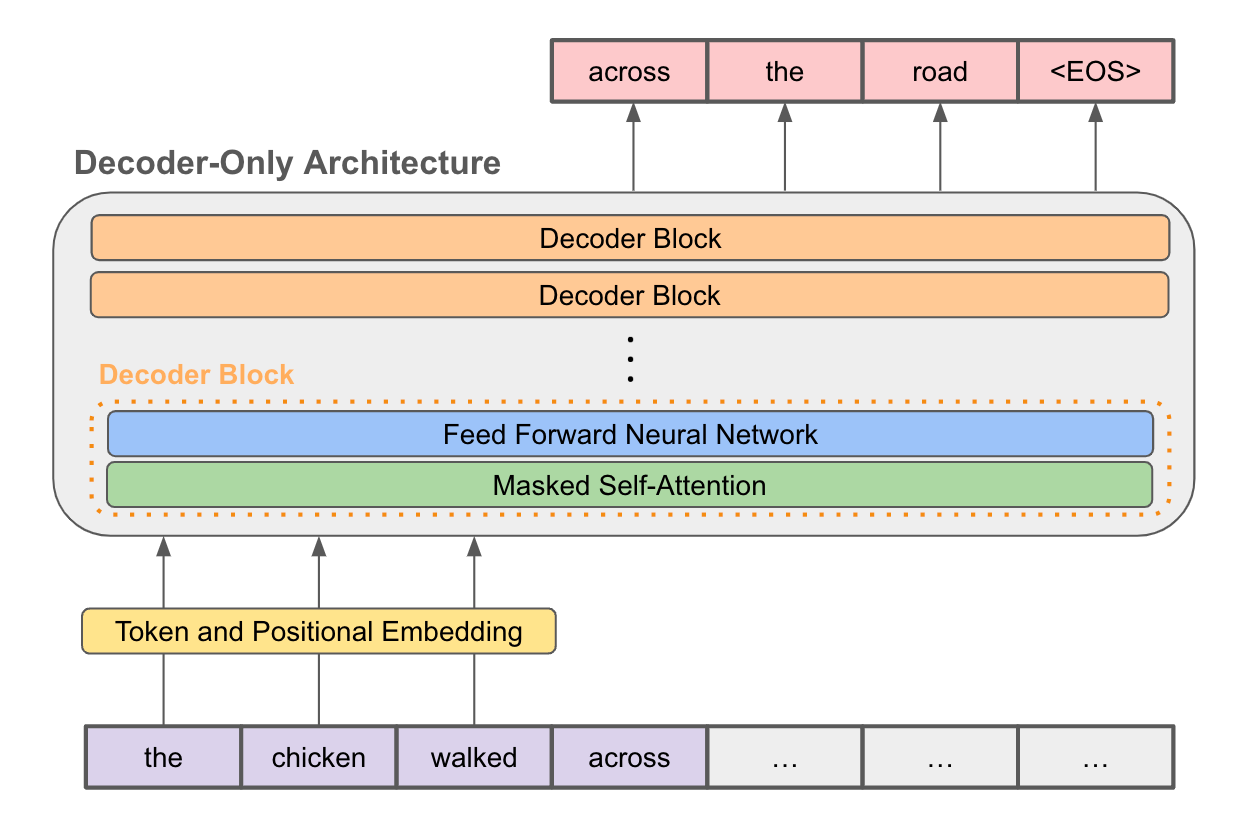
RAGはどのように幻覚を軽減するか
Retrieval Augmented Generation (RAG)は、AIモデルの精度と信頼性を高めることを目的とした自然言語処理における先進的なアプローチであり、特に幻覚を軽減することを目的としている。
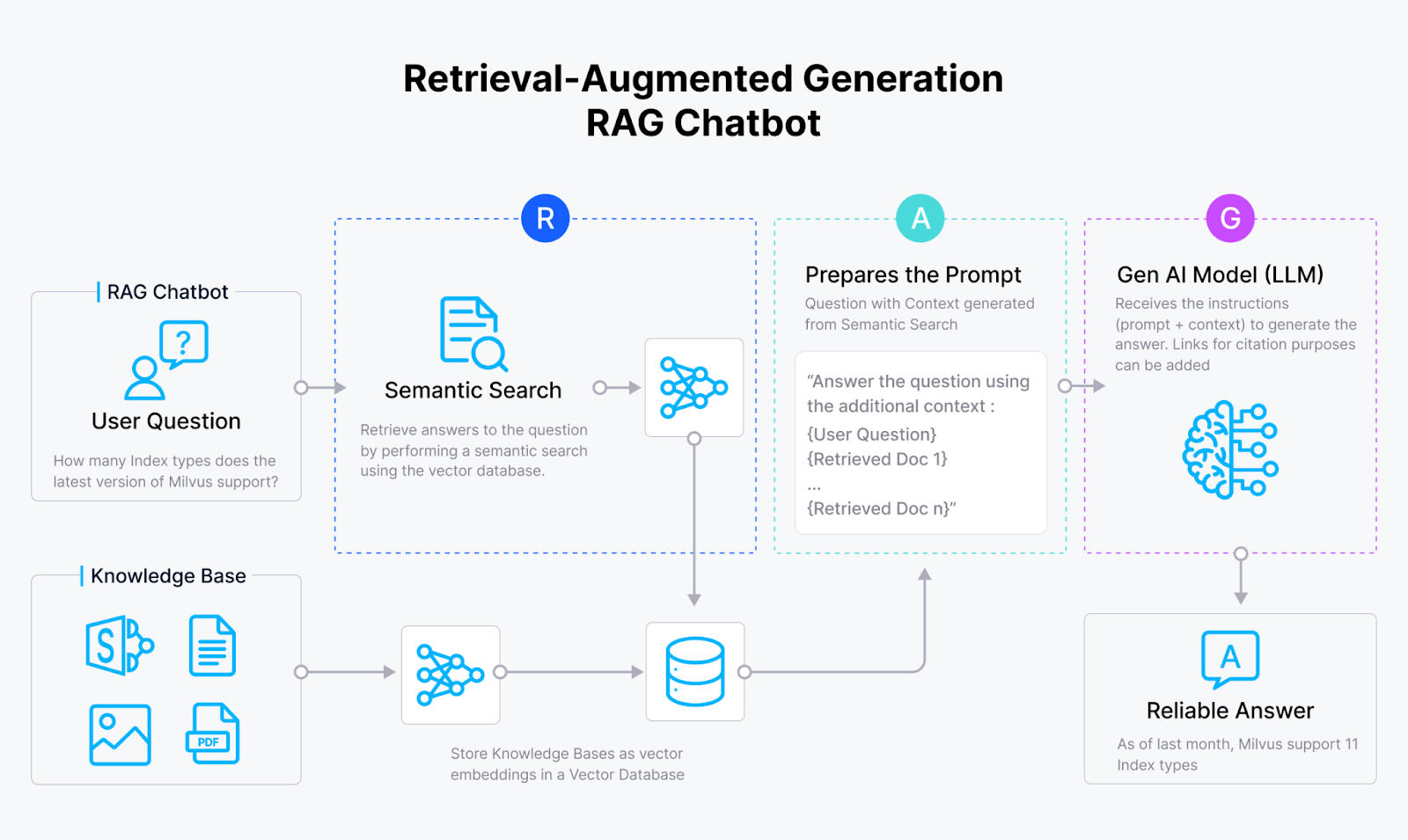
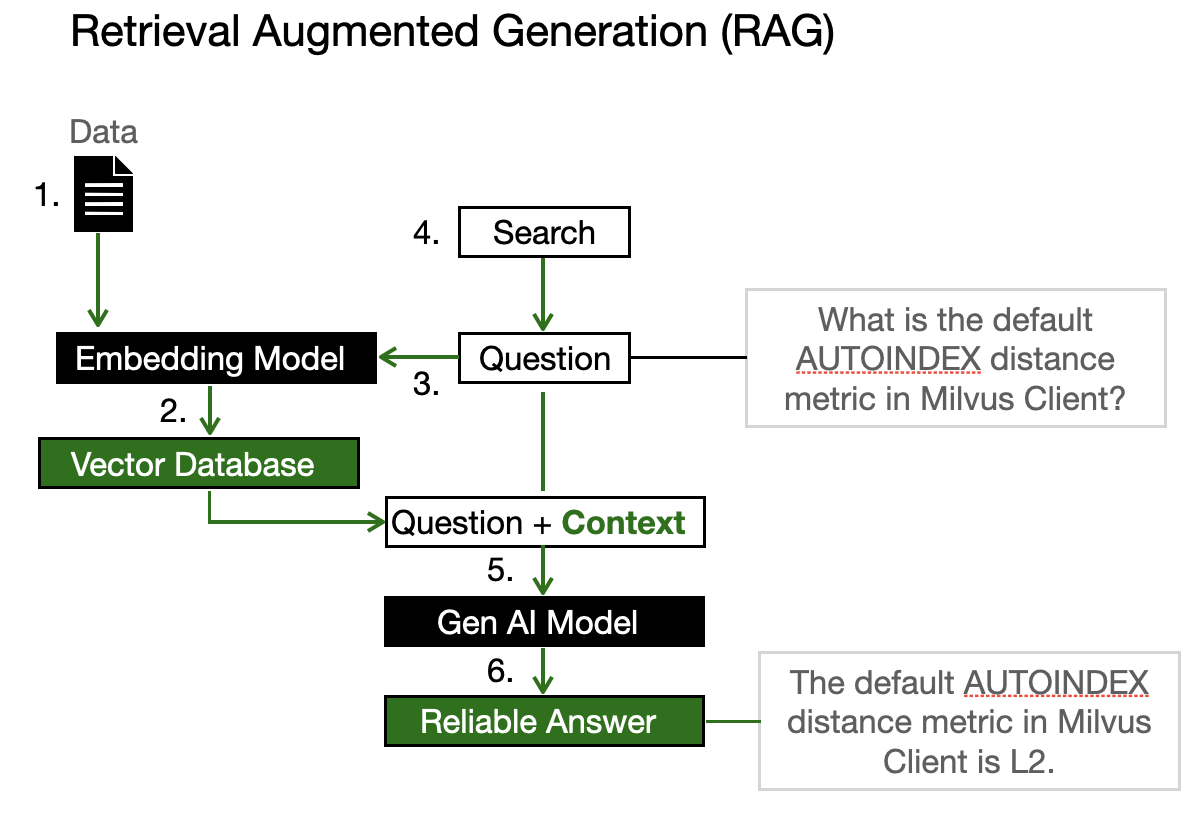
クリスティは、RAGは自分のデータをジェネレーティブAIのプロセスに統合する新しい手法だと説明した。その仕組みを簡単に説明しよう:
まず、データを埋め込みモデルに入力します。このモデルは情報をベクトルと呼ばれる数値の束に変え、ベクトル・データベースに格納する。
あなたが質問をすると、同じ埋め込みモデルがあなたのクエリをベクトルに変換し、このデータベースまたはベクトル空間内で最も近いベクトルの近傍を検索します。最も近いものを見つけると、それをコンテキストとして、あなたの質問とともに大規模な言語モデルを促します。こうすることで、より正確な回答を得ることができる。
さて、RAGがどのようにAIの幻覚に取り組むかを紹介しよう:
**1.常に最新であること: ** RAGのモデルは最新のデータを取り入れることができるため、最新の情報に基づいて対応することができます。
2.正確性と詳細性:* これらのモデルは、特定の関連情報を検索することで、正確な回答を提供するように設計されています。このプロセスにより、誤った内容や捏造された内容が生成される可能性が低くなり、回答が詳細かつ正確に質問に合わせたものとなり、過度に一般的な記述が避けられます。
RAGシステム構築の課題
RAG(Retrieval Augmented Generation)システムの構築には、いくつかの複雑なステップと決断が必要である。主な課題をいくつか紹介しよう:
埋め込みモデルの選択
エンベッディング・モデルを選択する際、いくつかの重要な要素に注目することができます:
- ベクトルの大きさ:ベクトルの大きさ:作業しやすい大きさのベクトルを生成するモデルを選ぶ。
- 検索性能**:CohereやVoyagerのような有名なモデルがどのようなパフォーマンスをしているかを見てください。
- モデルのサイズモデルのサイズを考慮し、計算能力に合うことを確認する。
- 精度:*** あなたの分野や製品にとって重要な細かいディテールをモデルが把握できることを確認します。
- スケーラビリティ:***ニーズが高まるにつれて、モデルがより多くのデータを扱えることを確認する。
オプションとして、以下から選択できます:
オープンソースモデル:これらは自由に利用でき、Hugging Face[ Embding model hub] (https://huggingface.co/spaces/mteb/leaderboard)のようなプラットフォームから比較・選択することができます。
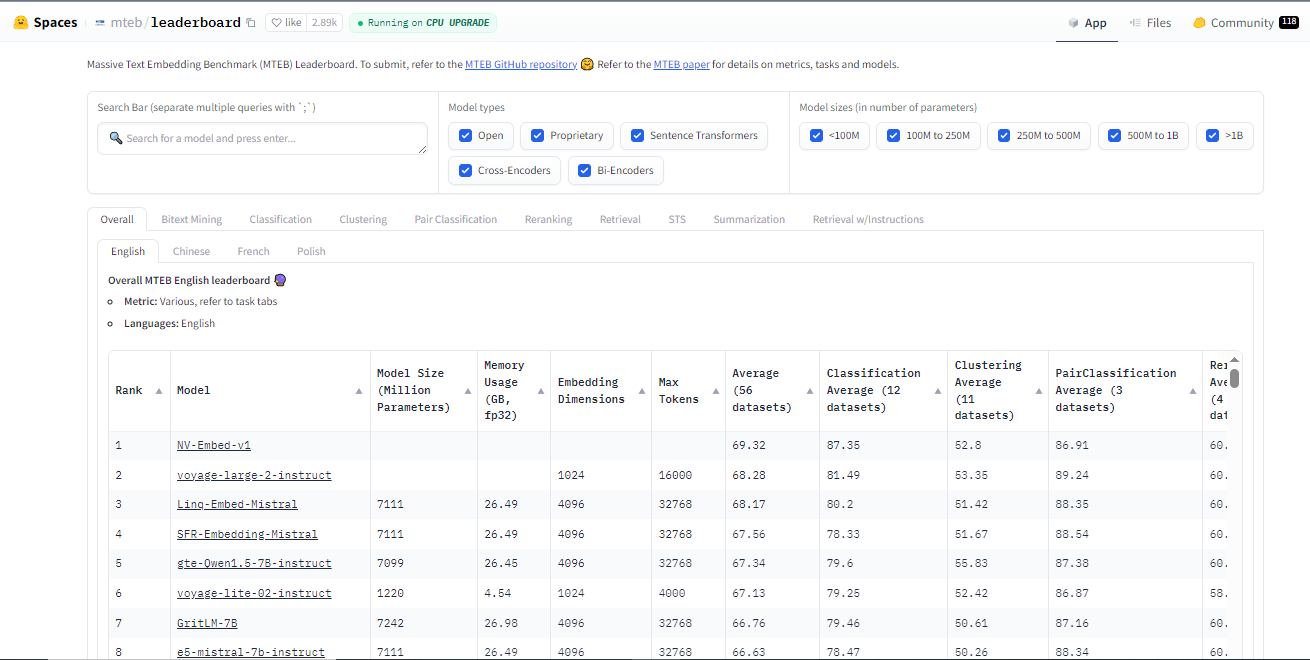
**プロプライエタリー・モデルCohereやOpenAIのような企業は、特定のタスクに対してユニークな機能やより優れたパフォーマンスを持つかもしれないが、コストがかかるモデルを提供している。
インデックスの選択
適切なインデックス構造を選択することは、システムのパフォーマンスにとって重要である。これには以下が含まれます:
1.スケーラビリティ:インデックスは、法外に遅くなることなく、数百万、数十億の文書に拡張できなければならない。
2.メモリー・フットプリント:メモリを効率的に使用することは、特に大規模なデータセットを扱う場合に重要である。
3.検索スピードと精度:文書をいかに早く検索するかということと、いかに正確にクエリと一致させるかということは、しばしばトレードオフの関係にある。
チャンキング
チャンキングとは、より正確な検索を容易にするために、文書をより小さく、意味的に首尾一貫した部分に分解することである。
- チャンクサイズの決定:大きすぎるとチャンクの焦点が定まらず、小さすぎると重要な文脈が失われる可能性がある。
- 一貫性の維持:各チャンクがそれ自体で意味を持ち、一貫性を保つようにする。
- 重複の処理:複数のチャンクに含まれる可能性のある情報をどのように管理するかを決める。
キーワードまたはセマンティック検索
キーワードベースの検索かセマンティック検索かの選択は、クエリを理解し、クエリに応答するシステムの能力に影響を与える可能性がある。
キーワード検索はシンプルで高速に見えますが、たとえ意味的に関連性があったとしても、正確なキーワードを含まないドキュメントを見逃すと、精度に大きく影響します。逆に、セマンティック検索はクエリの意図をより深く理解することができるが、より多くの計算資源と洗練されたモデルを必要とする。
再ランカー
再ランカーとは、最初の検索結果を改良する追加モデルやアルゴリズムのことで、最終的なレスポンスを生成するために選択された文書の関連性と精度を向上させることを目的としている。問題は、再ランカーを使う価値があるのか、そして再ランカーをうまく統合するためには何が必要なのかということである。
- 統合:再ランカーは、大きな待ち時間を発生させることなく、シームレスにシステムに統合されなければならない。
- トレーニングデータ:他のモデルと同様、リランカーが効果を発揮するには、高品質で代表的なトレーニングデータが必要です。
- チューニング:最初の検索とリランキングフェーズの間で適切なバランスを見つけることは難しい。
RAGは死んだのか?
クリスティの講演の中で、最近気になっている疑問がある。それは、ロング・コンテクストのLLMがステップアップしている今、RAGはまだ主役なのかということだ。
最近のロングコンテクストLLMの進歩は、RAG(Retrieval-Augmented Generation)技術の将来について疑問を投げかけている。ClaudeやGemini 1.5 Proのような、最大1,000万トークンを処理できるモデルによって、RAGの動的検索アプローチはもはや必要ないと主張する人もいる。
対決:ロングコンテクストはRAGを捨てられるか?
これは誰もが口を揃えて言う問題だ。それを分解してみよう。
**コストと効率
RAGの質素な性質は、必要なものだけを取得することで、計算コストを節約する。しかし、AI技術の価格が下がれば、ロングコンテクストLLMはより財布に優しくなる。ここは僅差だ。
検索と推論のダイナミクス:*。
ロング・コンテクストのLLMは、思考と情報検索を融合させ、回答によりパーソナライズされたタッチを生み出す。それに比べると、RAGの先行的な情報収集は、少しロボット的だと感じるかもしれない。
スケーラビリティとデータ複雑性:
何兆ものトークンを処理できるRAGの能力はその切り札であり、膨大で変化し続けるデータセットを処理するための王者となる。ロングコンテキストのLLMは、ここでは埃をかぶっている。
競争より協調:*。
なぜ両方を使わないのか?RAGの精度とロングコンテキストモデルの適応性を組み合わせることで、強力な相乗効果が期待できる。
OpenAI RAGとカスタマイズRAGの比較
さて、RAGがどのようなもので、どのような課題があるのかを理解していただけたと思います。さて、いよいよRAGを構築する技術的な側面に飛び込む時です。具体的には、OpenAIのRAGと、Milvusのようなベクターデータベースを使用してカスタマイズしたRAGを構築する場合との比較について説明します。
聴衆からの素晴らしい質問は、"Open AI RAGの代わりにカスタムRAGを行う理由は何か "というものでした。
クリスティが言ったように、最も重要な部分は、"オープンAIを使用していないRAGシステムをより深く理解することができる。
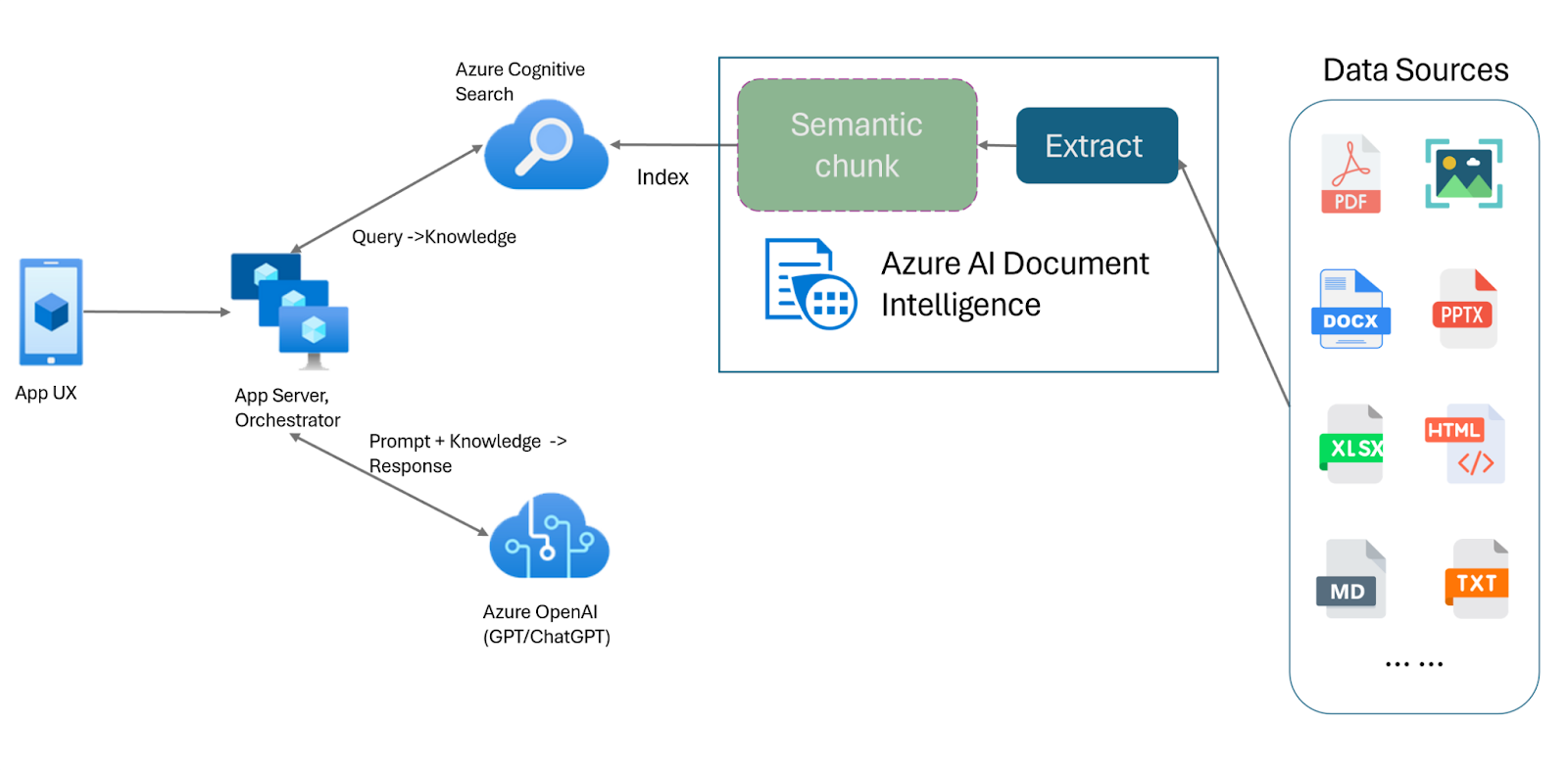
RAG構築におけるOpenAIアシスタントAPIの役割
OpenAIアシスタントAPIは、独自のアプリ内にAIアシスタントを作成できる強力なツールです。アシスタントは指示を持ち、モデル、ツール、ファイルを使用してユーザーの問い合わせに応答することができます。このAPIは、カスタマーサポートやバーチャルパーソナルアシスタントのような、魅力的で長期的な会話を必要とするアプリに最適です。
OpenAI RAGとカスタマイズRAGの比較
1つはOpenAIのAPIを使ったもの、もう1つはMilvusと呼ばれるベクターデータベースを使ってカスタマイズしたものです。この比較は、それぞれのアプローチの違いと利点を理解するのに役立つだろう。
OpenAI RAGとCustomized RAGの主な違いは以下の通りです。
| --------------------------- | ----------------------------------------------------------------------------------- | ---------------------------------------------------------------------------- | | 基準|OpenAI RAG|カスタマイズRAG | アプリケーションの適性|カスタマーサポート、バーチャルパーソナルアシスタント、長期的な会話に最適|学術研究の支援、複雑なクエリ、事実に基づくデータに最適 | パフォーマンスとスケーラビリティ|速いレスポンスタイムと高い効率性|データベース検索のため、レスポンスタイムが遅くなることがある。 | 実装の複雑さ|セットアップと使用が容易|AIモデルの統合とデータベース管理の専門知識が必要 | コスト|使用量に応じた価格|コストには計算リソースとデータベースのメンテナンスが含まれる。
Milvusのようなベクターデータベースを使用したカスタマイズされたRAGアプローチは、より柔軟でコントロールしやすいが、より多くの専門知識とリソースを必要とする。
コードが実際に動いているところを見たいですか?このnotebookで実例をご覧ください!
RAG 評価方法
RAGパイプラインを評価するには、両方の部分を別々に、そして一緒に見る必要がある。また、性能が向上しているかどうかもチェックする必要がある。そのためには、評価指標とデータセットの2つが必要です。
クリスティがスピーチでこの部分に取り組んだとき、彼女が言及した主な焦点は、"あなたの答えは根拠があり、質問に忠実に答えているか "だった。
Christyが言及したツールの一つはTrueraであり、大規模言語モデル(LLM)アプリケーションの評価と最適化を支援するプラットフォームである。 Truera](https://assets.zilliz.com/truera_455156ce88.png)
Trueraを使えば、以下のことが可能です:
- LLMアプリの評価
- フィードバック機能とアプリのトラッキングを使用して、LLMアプリの選択を最適化します。
- RAGトライアドやその他のすぐに使えるフィードバック機能を活用することで、幻覚を最小限に抑える。
- プロダクションLLMアプリを大規模に監視・追跡し、応答性の高いダッシュボードを構築し、実用的なアラートを設定する。
ChristyはRAGAsについても話した。これはRAGパイプラインを評価するために作られたフレームワークだ。パイプラインの各コンポーネントを個別に評価するために必要な技術的要件をすべて提供している。
RAGAsは以下の情報を必要とする:
- 質問ユーザーの質問
- 答え生成された答え
- コンテキスト:外部の知識ソースから取得した情報
- 根拠となる真実:質問に対する正しい答え(1つのメトリックにのみ必要)
RAGAsはパイプラインを評価するために、以下のようないくつかのメトリクスを提供する:
- コンテキスト精度:検索された情報の関連性
- コンテキスト・リコール:すべての関連情報が検索されたか
- 忠実さ:生成された答えの正確さ
- 答えの関連性: 生成された答えが質問にどれだけ関連しているか
他のLLMをジャッジとしてLLMを評価する
大規模な言語モデル(LLM)を評価することは困難です。ひとつの解決策は、LLM同士で評価し合うことです。このプロセスでは、テストケースを生成し、モデルのパフォーマンスを測定します。
その方法は次のとおりだ:
- テストの自動生成:LLM は、さまざまな入力、コンテキスト、難易度レベルを含む、さまざまなテストケースを作成します。
- 評価指標:評価対象のLLMはテストケースを解き、その性能は正確さ、流暢さ、一貫性などのメトリクスを使って測定されます。
- 比較とランキング:結果はベースラインや他のLLMと比較され、各モデルの長所と短所が示されます。
クリスティが言及した興味深い点は、「GPTが審査員である場合、GPT自体の順位が高くなる」というもので、これはLLMを評価する際に考慮しなければならない別の側面を示している。
このトピックをより深く掘り下げるために、この記事をチェックすることをお勧めします。
結論
以上である!我々は、AI幻覚とRAGがどのようにこの問題を解決するのに役立つかについて説明した。クリスティは、RAGを構築するためには、埋め込みモデル、インデックス、セマンティック検索アプローチを慎重に選択する必要があることを説明した。AIの幻覚の問題に対処し、最新情報の動的検索を活用することで、RAGは、より信頼性が高く、コンテキストを意識したAIシステムを構築するための強力なツールを提供します。
RAGシステム構築の道のりには、モデルの組み込み、索引付け、膨大なデータセットの取り扱いに関する思慮深い決断が含まれる。挑戦的ではあるが、パフォーマンスと精度という点では大きな見返りがある。
技術的なニュアンスに興味がある人も、実用的なアプリケーションに触発された人も、今こそRAGに飛び込む絶好の機会です。Milvusのようなベクトルデータベースを実験し、高度な検索技術と統合し、RAGがデータ検索とAIインタラクションをどのように変えることができるかを目の当たりにしてください。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
読み続けて

Introducing Zilliz Cloud Global Cluster: Region-Level Resilience for Mission-Critical AI
Zilliz Cloud Global Cluster delivers multi-region resilience, automatic failover, and fast global AI search with built-in security and compliance.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

Milvus WebUI: A Visual Management Tool for Your Vector Database
Explore Milvus WebUI to monitor, manage, and optimize your vector database with real-time insights, performance tracking, and system health monitoring.