




トランスフォーマー4レック最新の推薦システムにNLPの力をもたらす
#はじめに
デジタルコマースとオンラインコンテンツ消費が急増し続ける中、効果的でパーソナライズされたレコメンデーションエンジンに対する需要はかつてないほど高まっている。買い物客もストリーミング視聴者も、商品、映画、音楽のいずれを検索する場合でも、自分に合った推薦を期待している。しかし、協調フィルタリングやコンテンツベースのフィルタリングに依存する従来の推薦システムは、静的な過去のデータを使用しており、変化するユーザーの嗜好に適応するのに苦労することが多い。こうした限界に対処するため、進化するユーザー行動を捉えるダイナミックAIモデルを活用したレコメンデーション・システムが不可欠となり、人気を集めている。
先日Zillizが主催したUnstructured Data Meetupでは、NordstromのデータサイエンティストであるKunal Sonalkarが、ユーザーの進化するニーズによりよく応えるために、逐次およびセッションベースのレコメンデーションを可能にするTransformers4Recの使用に関する洞察を共有した。このブログポストでは、Kunalのプレゼンテーションの主な要点と、レコメンデーションシステムの将来についての私たちの見解を紹介します。詳しくはYouTubeでのクナールの講演全文をご覧ください。
#Transformers4Recとは?Transformers4Recは、PyTorchで逐次レコメンドシステムやセッションベースのレコメンドシステムを作成するために設計された強力で柔軟なライブラリです。自然言語処理(NLP)で最も人気のあるフレームワークの一つであるTransformersと統合することで、Transformers4RecはNLPと推薦システムの橋渡しをします。
次の図は、レコメンダーシステムにおけるtransformers4Recライブラリの使用例を示しています。ライブラリの入力データは、ユーザーがセッション中にブラウズしたり、カートに追加したりするアイテムなど、ユーザーインタラクションのシーケンスです。Transformers4Recはこれらのインタラクションを処理し、ユーザーが次に何を欲しがるかをインテリジェントに予測します。例えば、ある顧客がオンライン書店を閲覧しているとします。まず、SF小説をいくつか見て、カートに入れ、その後、関連する作家のページをいくつか見る。Transformers4Recはこの一連の行動を分析し、顧客が別の人気SFタイトルや関連するファンタジー小説に興味を持つかもしれないと予測します。
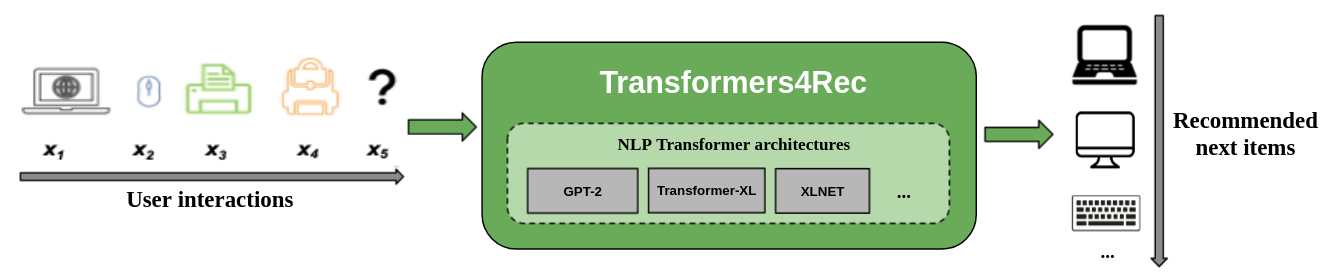 図- Transformers4Recがレコメンダーシステムでどのように機能するか.png
図- Transformers4Recがレコメンダーシステムでどのように機能するか.png
図Transformers4Recがレコメンダーシステムでどのように機能するか_。
クナルは、効果的なレコメンデーションシステムを構築するためには、顧客がどのような商品に興味があるのか、価格に敏感なのかなど、顧客の意図を理解し、それに応じてレコメンデーションを調整することが不可欠であると強調する。
例えば、"靴 "を探している2人の顧客は、過去のやり取りや、予算やブランドの好みなどの嗜好に基づいて、異なるレコメンデーションを受け取るかもしれない。
 shoes.png
shoes.png
トランスフォーマー4レック・アーキテクチャ
前に述べたように、Transformers4Recのアーキテクチャは、構造化された方法でユーザーとの対話データを処理することによって、逐次およびセッションベースの推薦のためのトランスフォーマーモデルを適応させるように設計されています。そのアーキテクチャには、予測を行うために協働する4つの主要なコンポーネントが含まれている:**フィーチャー集約、シーケンスマスキング、シーケンス処理、予測ヘッドである。
図- Transformers4Recアーキテクチャ.png](https://assets.zilliz.com/Figure_Transformers4_Rec_Architecture_2b1b62f15f.png)
図Transformers4Recのアーキテクチャ
特徴集約
特徴集約**コンポーネントは、推薦のための包括的なプロフィールを構築するために、連続変数とカテゴリ変数の両方で、ユーザーインタラクションに関するデータを収集する。例えば、eコマースのレコメンデーションシステムでは、カテゴリカルな特徴にはブランドや商品タイプのような属性が含まれ、連続的な特徴には価格、割引率、最近のインタラクション(例えば、過去24時間における商品のクリック数)が含まれるかもしれません。
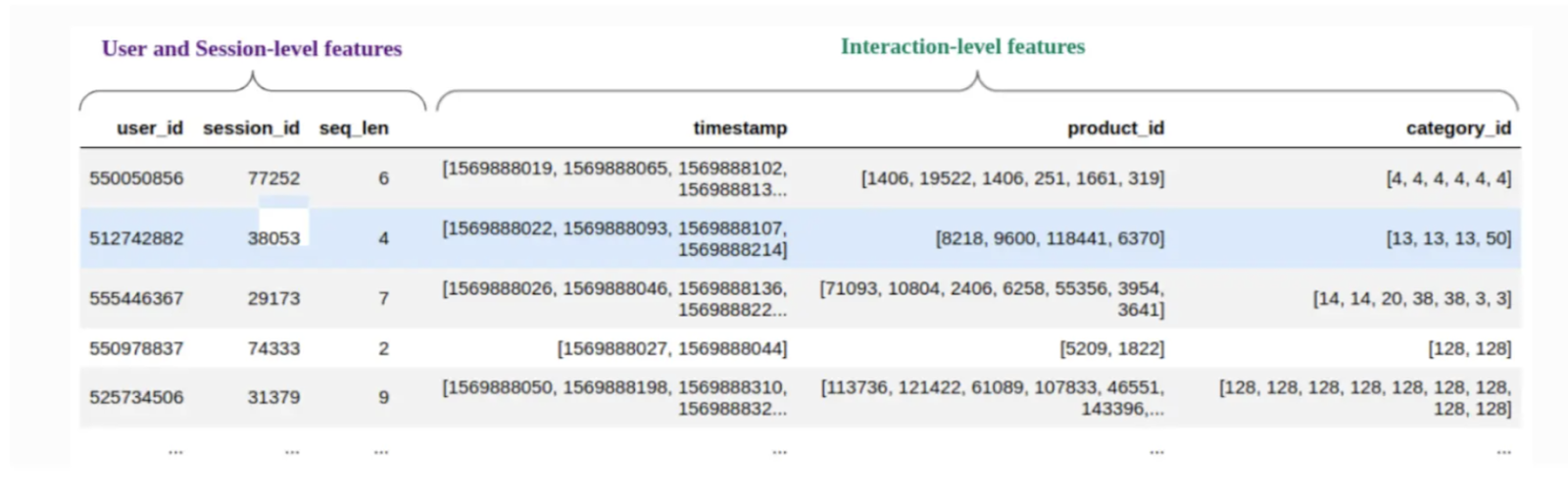 図- Transformers4Rec.pngにおける特徴集約
図- Transformers4Rec.pngにおける特徴集約
図Transformers4Recのフィーチャーアグリゲーション
これらのシーケンスをトランスフォーマーブロックに入力する前に、インタラクションデータはvector embeddingsと呼ばれる標準化されたフォーマット(高次元空間におけるインタラクションデータの数値表現)に前処理される必要があります。入力は、ユーザーIDまたはセッションIDによって整理することができ、一連のインタラクションは、"インタラクション埋め込み "として知られる単一のベクトル表現に集約される。このエンベッディングは、ユーザーアクションのタイプ、関係するアイテム、インタラクションの順序など、ユーザーインタラクションに関するコンテキスト情報を含み、効率的な検索とセマンティック検索のために、ベクトルデータベースに格納することができる。Milvus](https://milvus.io/docs/overview.md)やそのマネージドサービスであるZilliz Cloudのような堅牢なベクトルデータベースは、PyTorchとうまく統合し、このプロセスを効率化することができる。さらに、Transformers4Recには、生データを必要なフォーマットに簡単に変換するNVTabularモジュールが含まれており、データ準備をより管理しやすくしている。
配列マスキング
Transformers4RecのSequence Maskingコンポーネントは、データの漏えいを防ぎ、順序を維持するために、ユーザーインタラクションにマスクを適用します。例えば、ユーザーの次のアイテムを予測するとき、このモジュールは将来のアクションを隠し、モデルが因果的でステップバイステップで学習できるようにします。
Transformers4Recの異なるタイプのシーケンスマスキングは、学習や推論中にモデルが "見る "ものをコントロールし、ユーザーの行動に意味のあるパターンを捉え、次のインタラクションを予測する能力を向上させます。Transformers4Recは、シーケンスマスキングに複数のオプションを提供します:
因果言語モデリング(CLM)**:この技術は、シーケンス内の将来のアイテムをマスクし、以前のアイテムのみに基づいて各アイテムを予測するようにモデルを訓練します。CLMは、相互作用の順序が重要であるシーケンシャルなレコメンデーションに最適です。
マスク言語モデリング(MLM)**:MLMでは、シーケンスの特定の位置がランダムにマスクされ、モデルは周囲の文脈を使って隠されたアイテムを予測するように学習する。この技術は、厳密な順序に依存することなく、モデルが項目の関係を理解するのに役立つ。
ランダム・トークン検出(RTD)**:RTDはシーケンスの中のランダムなアイテムを無関係なものに置き換え、モデルはこの不正確なアイテムを見分けるように学習する。この方法は、本物のパターンをランダムなノイズや異常から区別することをモデルに教える。
パーミュテーション言語モデリング(PLM)**:ここでは、シーケンスの項目がシャッフルされ、モデルは新しい並べ替えられた順序の項目を予測するように学習される。PLMは、モデルがどのような順序でもパターンを認識できるようにすることで、柔軟性を高める。
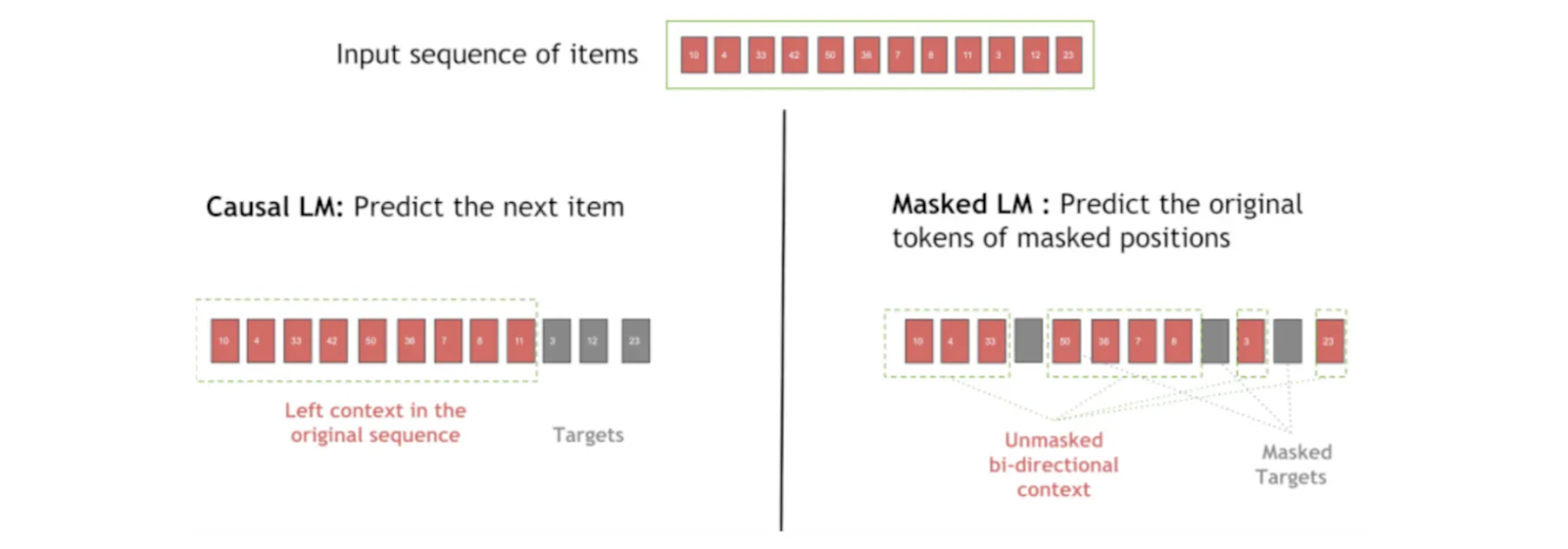 図- シーケンスマスキング中のカジュアルLMとマスキングLMの違い.png
図- シーケンスマスキング中のカジュアルLMとマスキングLMの違い.png
図: シークエンスマスキング時のカジュアルLMとマスクLMの違い_Figure: Casual LM and Masked LM in Sequence Masking_
通常、学習前に20-30%の位置埋め込みがマスキングされる。マスキング確率は推薦システムの頑健性にも影響する。
これらのマスキング技術により、モデルは様々な方法でユーザーとのインタラクションから学習し、正確でコンテキストを考慮した推薦を行う能力を向上させることができる。
シーケンス処理
シーケンス処理(Sequence Processing) コンポーネントは、ユーザーのインタラクションシーケンスにおけるマスキングされたアイテムや位置を予測するために、入力特徴をトランスフォーマーモデルに与えます。Transformers4Recは、XLNet、GPT-2、LSTMを含む、シーケンス処理のための様々なアーキテクチャをサポートしており、ユーザは推薦システムに最も適したモデルを選択することができます。
下のコードスニペットに示されているように、インタラクションベクトルの埋め込みはトランスフォーマーブロックに渡されます。ユーザーは、層の数やシーケンスの長さなどのパラメータを指定することで、トランスフォーマーのアーキテクチャを構成することができます。PyTorchのシーケンシャルブロックは、集約された入力を渡し、マスキングを適用し、希望するモデル構成を有効にすることで作成することができます。
Pytorchでのシーケンス処理.png](https://assets.zilliz.com/Fig_Sequence_processing_in_Pytorch_e03f5bec60.png)
図) _Pytorchによるシーケンス処理
予測ヘッド
Prediction HeadはTransformers4Recフレームワークの最後のモジュールで、トランスフォーマモデルからの出力が実用的な推奨を生成するために使われる。
図- 実行可能な推奨を生成するために変換モデルからの出力が使われる。.png](https://assets.zilliz.com/Figure_Outputs_from_the_transformer_model_are_used_to_generate_actionable_recommendations_225f6c279c.png)
図:トランスフォーマーモデルからの出力は、実行可能な推奨事項を生成するために使用される。
このモジュールは、以下のような、ビジネスニーズに合わせた様々なユースケースをサポートします:
次のアイテム予測**:このオプションは、タイムリーで適切な推奨を提供するのに役立ち、彼らの前のアクションに基づいて、ユーザーが対話する可能性が高い次の項目を予測します。
バイナリ分類**:ここで、モデルはユーザーが特定のアイテムをクリックする確率を計算します。これはクリックスルー率(CTR)予測に有用で、どのアイテムが最もユーザーを引きつける可能性が高いかを判断し、レイアウトやコンテンツの最適化に役立ちます。
回帰**:回帰タスクは、ユーザーがアイテムに費やす可能性のある時間、予想されるインタラクション数、あるいは推定購入金額などの連続値の予測を可能にします。
下図は、エンドツーエンドのプロダクションパイプラインを示しています。4つのコンポーネント(フィーチャーアグリゲーション、シーケンスマスキング、シーケンス処理、予測ヘッド)がすべて連携し、正確でコンテキストを考慮したレコメンデーションを提供します。
図- Transformers4Rec.pngを使用して構築された推薦システムのエンドツーエンドパイプライン
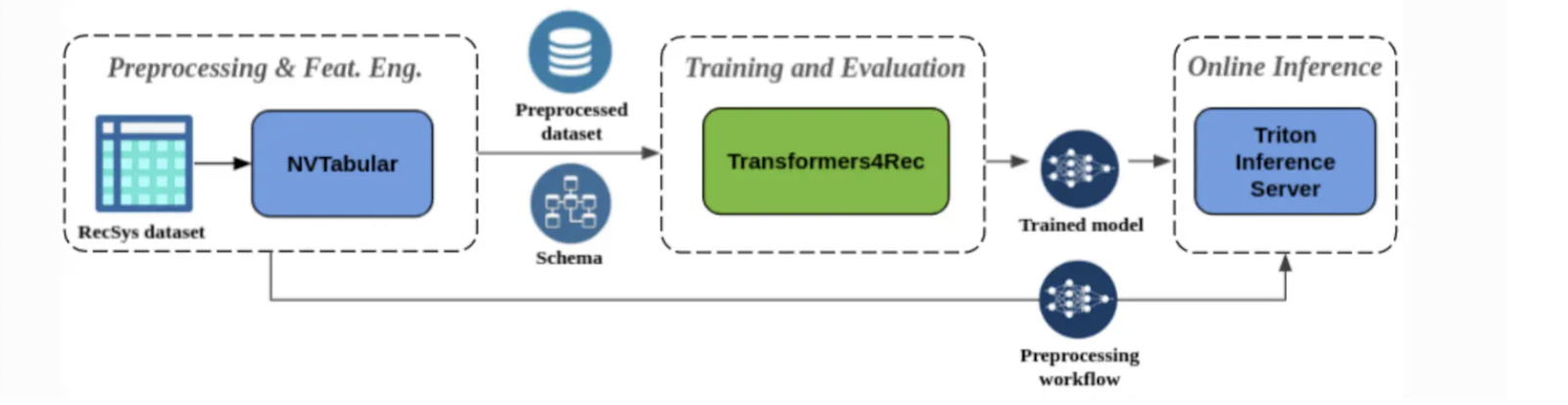{kind=link}
図: Transformers4Recを用いて構築された推薦システムのエンドツーエンドパイプライン_。
Transformers4Rec の評価と課題
Transformers4Recを使って推薦システムを構築するには、効果的な評価と、スケーラビリティやメンテナンスの課題を克服するための戦略的な計画の両方が必要である。
システムの評価
推薦システムの有効性は、ユーザーのニーズをどれだけ正確に満たしているかに大きく依存します。Transformers4Recの場合、一般的な評価指標には、システムのトップ'N'レコメンデーションがどれだけユーザーの好みに合致しているかを測定する、精度とリコールが含まれます。さらに、平均平均精度(MAP)や正規化割引累積利益(NDCG)のようなランキングメトリックスも推奨アイテムの関連性と順序を評価するために使用されます。
課題
Transformers4Recによる推薦システムのスケーリングには、特にGPUリソースを使って大規模に展開する場合、大きな計算コストがかかります。また、このようなシステムの構築と維持には、データの収集と保存からモデルの展開とリアルタイムの推論に至るまで、広範囲なインフラストラクチャが必要です。
適切なインフラストラクチャーを選択することは、関連する推薦を素早く検索できるシステムを構築する上で極めて重要である。例えば、Milvusのようなベクトルデータベースを使用することで、高速な類似検索とベクトル埋め込みデータの効率的な保存が可能になり、推薦パイプラインにうまく統合されます。
もう一つの重要な課題は、新しい、あるいは頻繁に変更される商品カタログを扱うことである。Transformers4Recは、限られた過去のデータであっても、これらの新しいアイテムに対して正確な推薦を提供する必要がある。これには、新しいコンテキストに基づいて推奨を更新するために、モデルとデータインフラの両方に適応性が必要である。
要約
このブログでは、Transformers4RecがどのようにNLPにヒントを得たテクニックを使って、ダイナミックでパーソナライズされたレコメンデーションシステムを作るかについて説明した。Feature Aggregation、Sequence Masking、Sequence Processing、Prediction Headなどのコンポーネントにより、フレームワークは複雑なユーザーパターンを捉え、リアルタイムで適切なレコメンデーションを提供する。精度、リコール、MAP、NDCGなどの主要メトリクスは、システムの有効性を評価するのに役立ち、レコメンデーションがユーザーのニーズを満たすことを保証します。
また、Transformers4Recのスケーリングの課題、特にインフラコストとストレージの必要性についても議論した。Milvusベクトルデータベースのようなツールは、効率的なベクトルの保存と検索をサポートする。Transformers4Recは現代の推薦システムにとって柔軟で強力なソリューションである。
参考文献
Transformers4Rec GitHub リポジトリ](https://github.com/NVIDIA-Merlin/Transformers4Rec)
マンバ:トランスフォーマー代替の可能性 ](https://zilliz.com/learn/mamba-architecture-potential-transformer-replacement)
Understanding Transformer Models Architecture and Core Concept](https://zilliz.com/learn/decoding-transformer-models-a-study-of-their-architecture-and-underlying-principles)
MilvusとNVIDIA MerlinによるRecSysの効率的なベクトル探索](https://zilliz.com/blog/efficient-vector-similarity-search-recommender-workflows-using-milvus-nvidia-merlin)
広告レコメンデーションの変革: MilvusによるSmartNewsの旅](https://zilliz.com/blog/transforming-ad-recommendations-smartnews-journey-with-milvus)
Milvusの新しい範囲検索で高度なレコメンデーションエンジンのロックを解除](https://zilliz.com/blog/unlock-advanced-recommendation-engines-with-milvus-new-range-search)
MilvusとPythonで映画レコメンドエンジンを作る】(https://zilliz.com/blog/create-a-movie-recommendation-engine-with-milvus-and-python)
読み続けて

A Few Notes from Databricks Data + AI Summit 2026: Why the Data Layer Matters Again
James Luan shares notes from Databricks Data + AI Summit 2026 on why production AI is pushing the data layer back to the center of infrastructure.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Selecting the Right ETL Tools for Unstructured Data to Prepare for AI
Learn the right ETL tools for unstructured data to power AI. Explore key challenges, tool comparisons, and integrations with Milvus for vector search.