




Timeplus ProtonでKafkaのストリーミングデータを処理する
2024年4月、Timeplusの共同設立者であるJove Zhong氏がSeattle Unstructured Data Meetupに登壇し、"Processing Streaming Data in Kafka with Timeplus Proton."について講演を行った。データストリーミングとリアルタイム処理のエキスパートであるJove氏は、TimeplusがどのようにKafkaと統合してリアルタイムデータを処理するかについて包括的な概要を提供し、また魅力的で勉強になるライブデモも行ってくれた。この洞察に満ちたセッションの重要なポイントと洞察に飛び込んでみよう。
Jove ZhongのYouTubeリプレイへのリンク:YouTubeで講演を見る
タイムプラスとそのリアルタイム機能
ジョーブ・ジョンはソフトウェア・エンジニアリングの巨匠だ。もし信じられないなら、彼の実績をチェックしてほしい。Timeplusの共同設立者兼製品責任者、Splunkの元エンジニアリング・ディレクター、17の特許保持者、4つのAWS認定。そして、2010年からは "ワールドクラスのパパ "でもある。ジョーブは、父親業とビジネス・リーダーシップの間に魅力的な類似点を描き、子供を育てることと会社を経営することは、想像以上に共通点が多いことを示している。
それでは、"Timeplus Protonを使ったKafkaでのストリーミング・データの処理 "についてのジョーヴェの講演に入りましょう。
カリフォルニア州サンタクララに本社を置くTimeplus社は、革新的なストリーミングSQLデータベースとリアルタイム分析プラットフォームで、リアルタイム・データ処理に革命を起こしている。一流のベンチャーキャピタルや技術者に支えられ、オープンソース版と商用版の両方を提供するTimeplusは、ライブデータストリームの効率的な管理と処理を可能にする。ダイナミック・ダッシュボードやSQLベースの処理など、その際立った機能により、リアルタイムのデータ操作にアクセスしやすく、ユーザーフレンドリーなものとなっている。
Timeplus ProtonはTimeplusのコアエンジンであり、ksqlDBやApache Flinkのようなプラットフォームの強力な代替となる。軽量で、C++で書かれ、パフォーマンスのために最適化されている。ストリーミングETL、ウィンドウ機能、高カーディナリティ集約などの機能により、開発者はストリーミングデータ処理の課題に効率的に取り組むことができる。このプラットフォームは、Apache Kafka、Confluent Cloud、Redpandaを含む多様なデータソースをサポートし、リアルタイムの洞察とアラートを可能にします。
FinTech、AI、機械学習、観測性のいずれにおいても、Timeplusは、データチームがストリーミングデータと履歴データを迅速かつ直感的に処理できるよう、エンドツーエンドの機能を提供します。Timeplusは、あらゆる規模や業種の組織向けに設計された、シンプルで強力、かつコスト効率の高いソリューションです。
ライブデモビットコイン価格のリアルタイム監視
ジョーブ氏はまず、ビットコイン価格のライブ・フィードを披露し、Timeplusのリアルタイム機能を実演した。このデモは、単に技術力の高さを示すだけでなく、TimeplusがGoogleのような従来の情報源よりもいかに速くデータを処理し、表示できるかを示すものでもあった。ジョーブ氏がリアルタイムのフィードをグーグルのものと比較し、タイムプラスの優れた性能を強調すると、聴衆は魅了された。
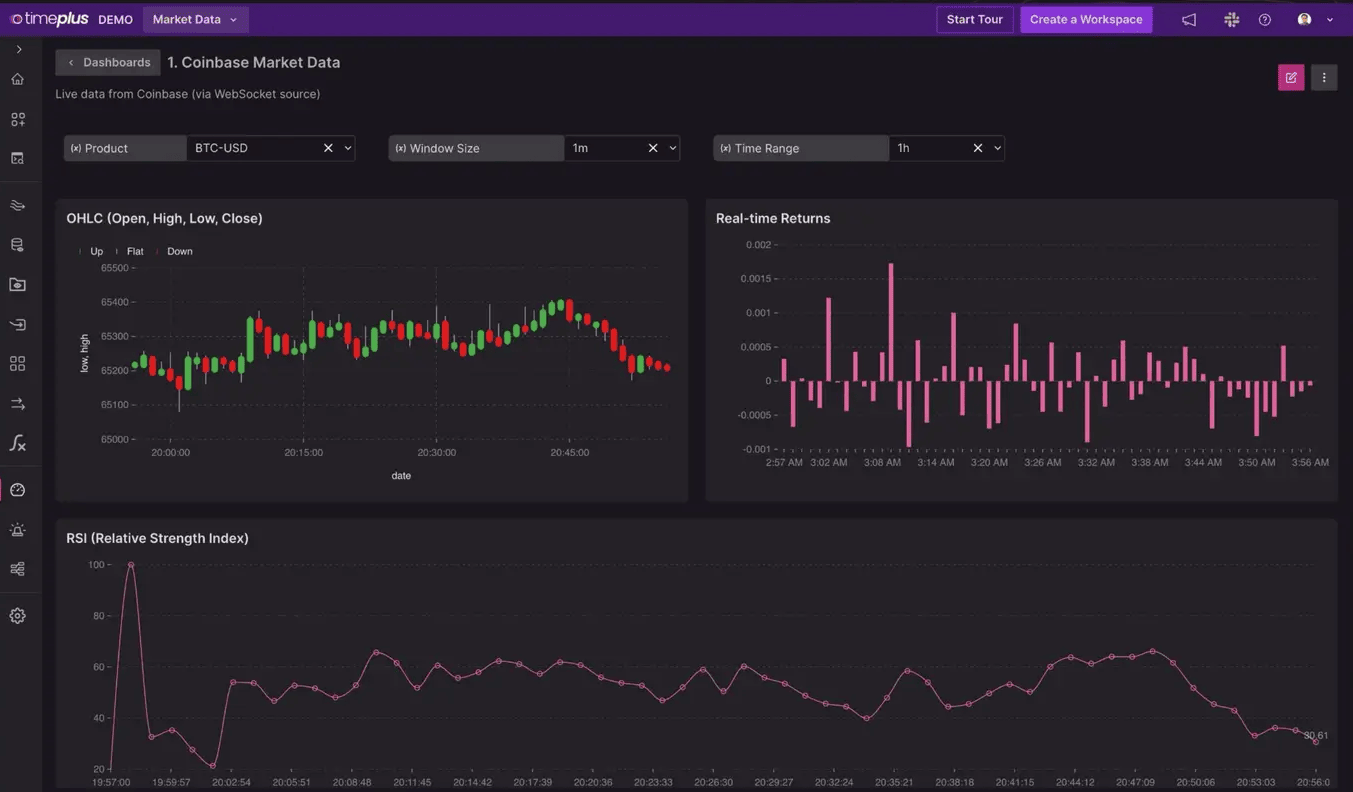
カフカ:リアルタイムデータストリーミングのバックボーン
JoveはKafkaを深く掘り下げ、そのアーキテクチャと機能を説明した。Kafkaは、多様なデータタイプを扱い、分散コンピューティング環境を管理するための強力なオープンソースのイベント・ストリーミング・プラットフォームである。JavaとScalaで書かれたKafkaは、高スループットと低レイテンシーでリアルタイムのデータフィードを処理するように設計されています。Goldman Sachs、Target、Ciscoなどの業界大手を含むFortune 100企業の80%以上に信頼されているKafkaは、その信頼性とパフォーマンスで知られています。
Kafkaのアーキテクチャを理解する
Kafkaは、毎秒数百万のイベントを処理できる分散データストリーミングプラットフォームとして動作しています。以下の図を通してKafkaのアーキテクチャを視覚化することで、Joveはこのプラットフォームが高いスループットと低いレイテンシでリアルタイムのデータフィードを処理する能力を実証し、最新のデータストリーミングのニーズに対応する強力なツールであることを示しました。この図では、プロデューサー、コンシューマー、ブローカーがどのように連携し、データが効率的に処理され配信されるかのアーキテクチャを説明している。また、フォールトトレランスとスケーラビリティを提供するKafkaのレプリケーションとパーティショニング戦略についても説明した。
Kafkaは、高性能なTCPネットワーク・プロトコルを介して通信するサーバーとクライアントで構成される分散システムとして動作する。オンプレミス環境とクラウド環境の両方で、ベアメタルハードウェア、仮想マシン、コンテナ上にデプロイできる。
https://assets.zilliz.com/kafka_101_b566074cec.png
図に示すように、Kafkaのアーキテクチャはいくつかの主要コンポーネントで構成されている:
クライアントとブローカー:** Kafkaはクライアントとブローカーからなる分散システムとして動作する。クライアントとブローカー:** Kafkaはクライアントとブローカーからなる分散システムとして動作する。ブローカーは、これらのメッセージを保存・転送するサーバーである。この図は、クライアントがブローカーにどのように接続するかを示しており、ブローカーはデータをクラスタ内の他のブローカーにルーティングするブートストラップ・サーバーとして機能する。
プロデューサーとコンシューマー:** プロデューサーはKafkaトピックへのデータ送信を担当し、コンシューマーはこれらのトピックからデータを読み取る。この図は、プロデューサーが複数のブローカーにまたがる異なるトピック(トピックA、トピックB、トピックC)にメッセージを送信する方法を示しています。その後、コンシューマーはこれらのトピックからデータを読み込み、データが効率的に処理・配信されるようにする。
トピックとパーティション:** Kafkaトピックはパーティションに分割され、データの並列処理を可能にする。各パーティションは複数のブローカーで複製され、フォールトトレランスを確保する。この図は、3つのパーティションを持つトピックが異なるコンシューマーによって消費されている様子を示しており、Kafkaがどのように負荷を分散し、高可用性を維持しているかを示している。
スケーラビリティとフォールトトレランス:** Kafkaクラスタは非常にスケーラブルで、複数のデータセンターやクラウド地域にまたがることができます。アーキテクチャは弾力的な拡張と縮小をサポートし、データを失うことなく継続的な運用を保証します。ブローカーに障害が発生しても、他のブローカーにデータを迂回させることで復旧できます。
ストリーミングLLMとベクトル・データベース
講演の大部分は、データストリーミングが大規模言語モデル(LLM)やベクトルデータベースとどのように統合されるかを探ることに費やされた。Jove氏は、これらの統合がAIアプリケーションを強化し、データ処理をより効率的かつ正確にする可能性を強調した。ストリーミングデータとAIモデルの融合は、様々なアプリケーションの応答性とインテリジェンスを大幅に向上させることができる。
最近、Zilliz CloudとConfluent Cloud for Apache Flink®は、このコンセプトをさらに実証するパートナーシップを発表しました。これを活用することで、KafkaとFlinkを使用してリアルタイムGenAIアプリを構築することができます。企業は、Milvusのようなベクトルデータベースにフィードするリアルタイムデータパイプラインを作成することができます。このセットアップにより、リアルタイム意味検索やRAG(Retrieval Augmented Generation)のような高度なAIアプリケーションの開発が可能になる。リアルタイムのデータ処理により、LLMは最新の情報にアクセスすることができ、企業検索から電子商取引におけるパーソナライズされたレコメンデーションまで、幅広いアプリケーションにおいて正確でタイムリーな応答を保証する。
実用的なアプリケーションAI搭載チャットボット
ジョーヴェが取り上げた実用的なアプリケーションのひとつは、AIを搭載したチャットボットにおけるリアルタイムデータの利用だ。リアルタイムのデータストリームを活用することで、チャットボットはフライト状況の最新情報などを提供することができる。例えば、チャットボットはフライトの遅延を即座にユーザーに知らせ、代替便を提案することができ、リアルタイム・データ処理の実用的な利点を示すことができる。

Jove氏は、フライト状況ボットとチャットしているところを想像した例を挙げた:
User:"ニューヨークへのフライト状況は?"
ユーザー:** "ニューヨークへのフライト状況は?" チャットボット: "フライトは2時間遅れています。"
ユーザー: "もっと早く着く別のフライトはありますか?"
Chatbot: "はい、代替便が1席残っています。1500ドルかかりますが、時間通りに到着します。"
ユーザー: "いいですね、予約してください。"
このシナリオでは、チャットボットはKafkaのリアルタイムデータストリームを利用して、最新のフライト情報を提供します。遅延についてユーザーに知らせるだけでなく、利用可能なフライト、座席、価格をリアルタイムでチェックします。チャットボットはこの情報をユーザーに提示し、迅速で十分な情報に基づいた意思決定を可能にします。この例では、Kafkaのリアルタイムデータ処理機能が、AIを搭載したチャットボットの機能と応答性を強化し、即時かつ正確な情報を求めるユーザーにとって価値あるツールになることを紹介しています。
タイムプラスとベクターデータベースの統合
Joveのデモは、Timeplusとベクトルデータベースi-e Milvusの印象的な統合で続き、Hacker Newsからのデータがどのように処理され、リアルタイムで照会されるかを紹介した。このプロセスは下図に示されている。ワークフローは、Hacker News APIからデータを取得することから始まり、Bytewaxを使ってHTMLをテキストに変換します。その後、テキストはHugging Faceで埋め込まれ、TimeplusのSQL機能を使ってストリーミングされる。データはMilvus sink connectorを介してKafkaに接続され、Milvus vectorデータベースでリアルタイムのクエリと処理が可能になる。
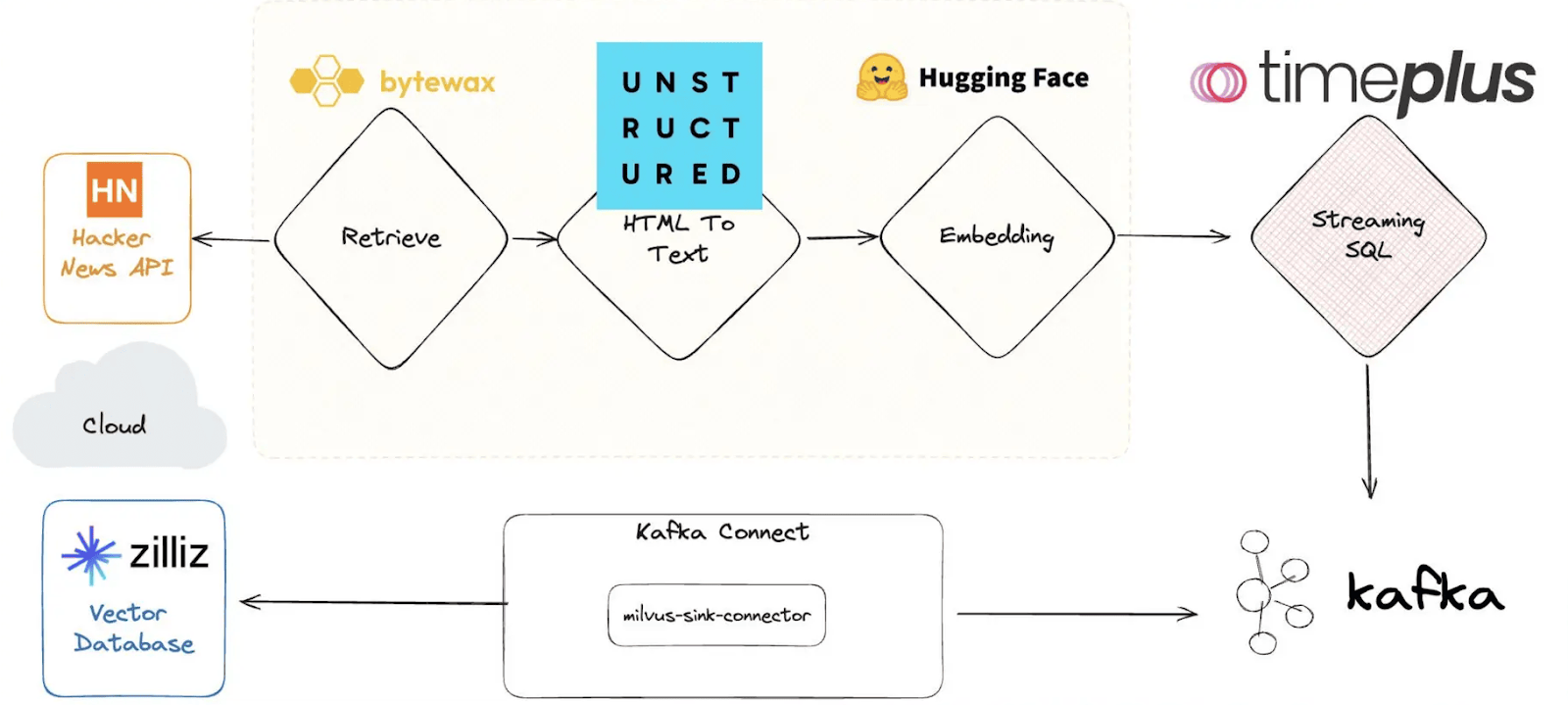
彼は、この統合の威力を説明するために、具体的な例を挙げて説明してくれた。
Hacker News のデータを扱っているとしましょう。Hacker Newsから最新のデータを取り込んでみましょう。Timeplusを使えば、このデータをリアルタイムでストリーミングできます。Joveがコマンドを入力すると、数秒以内にHacker News投稿のストリームが表示されます。ここで、「dogfooding」に言及した投稿をすべて見つけたいとしよう。この非構造化データに対して複雑なクエリーを実行することができる。彼がクエリを入力すると、システムはほとんど瞬時に関連する投稿のリストを返す。
しかし、我々はそれだけで終わらない。これらの投稿のセンチメント分析を見てみよう。別のコマンドでデータが処理され、センチメント分析が表示され、どの投稿が肯定的、否定的、または中立的であるかが示される。
これがTimeplusとベクトルデータベースを統合するパワーです。膨大な量の非構造化データを扱い、複雑なクエリーを実行し、貴重な洞察をリアルタイムで抽出することができます。"
Timeplusに加えて、MilvusはConfluent Kafka Connectorを使用してKafkaとの統合も提供しており、MilvusまたはZilliz Cloudへのリアルタイムベクターデータストリーミングを可能にしている。このセットアップにより、リアルタイムのセマンティック検索や類似検索が可能になり、ストリーミングデータから即座に洞察を得る能力が強化されます。
次の表は、この記事で取り上げたいくつかの重要な製品の説明とユースケースの一覧です。
| 製品概要 | ||
| Timeplus|強力なストリーミングSQL機能を備えたリアルタイム分析プラットフォーム。 | リアルタイムデータ処理と分析。 | |
| Timeplus Proton|C++で書かれたTimeplusのコアエンジンは軽量で、パフォーマンスのために最適化されています。 | ストリーミングETL、ウィンドウ機能、高カーディナリティ集約。 | |
| Kafka|高スループット、低レイテンシーのデータフィードを処理する分散イベントストリーミングプラットフォーム。 | データパイプライン、ストリーミング分析、データ統合。 | |
| Confluent Kafka Connector|KafkaとMilvusおよびZilliz Cloudを統合し、リアルタイム・ベクター・データ・ストリーミングを可能にするツール。 | ベクターデータベースへのリアルタイムデータストリーミング。 | |
| Apache Flink|Confluentクラウド上のKafkaと統合された、統一されたストリームおよびバッチ処理フレームワーク。 | 高性能ストリーム処理。 |
結論
Seattle Unstructured Data MeetupでのJove Zhongの講演は、リアルタイムデータ処理のマスタークラスだった。実用的なデモから高度なコンセプトへの深い掘り下げまで、JoveはTimeplusとKafkaがデータ分析の未来をどのように形成しているかについて包括的な概要を提供した。講演は、ストリーミングSQLとリアルタイム処理の将来への展望で締めくくられた。Jove氏は、よりスマートで応答性の高いAIシステムを構築する上で、これらの技術の重要性が高まっていることを強調した。リアルタイムでデータを処理し、即座に決断を下す能力は、金融からヘルスケアまで、多くの業界で極めて重要になってきている。
これらの技術についてさらに詳しく知りたい方は、講演の完全なリプレイとプレゼンテーション・スライドをご覧ください。

読み続けて

Why Teams Are Migrating from Weaviate to Zilliz Cloud — and How to Do It Seamlessly
Explore how Milvus scales for large datasets and complex queries with advanced features, and discover how to migrate from Weaviate to Zilliz Cloud.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.