




Build Real-time GenAI Applications with Zilliz Cloud and Confluent Cloud for Apache Flink®
Today, we are thrilled to partner with Confluent to unlock semantic search for real-time updates powered by Apache Kafka®, Apache Flink®, and the Milvus vector database. With the advancement of AI, embedding models and vector retrieval have become widely adopted to implement search and recommendation in many applications, including enterprise search, e-commerce, and increasingly popular Retrieval Augmented Generation (RAG). For any search & recommender system, the recency of information is critical to end-user experience.
Confluent has just announced general availability of the industry’s only cloud-native, serverless Apache Flink® service — now available directly alongside cloud-native Apache Kafka® on Confluent’s fully managed data streaming platform. The new Flink offering is now ready for use on AWS, Google Cloud and Azure. Directly integrated with Milvus and Zilliz Cloud (fully-managed Milvus), Confluent provides a simple solution for accessing and processing data streams from across the entire business to build a real-time, contextual, and trustworthy knowledge base to fuel AI applications.
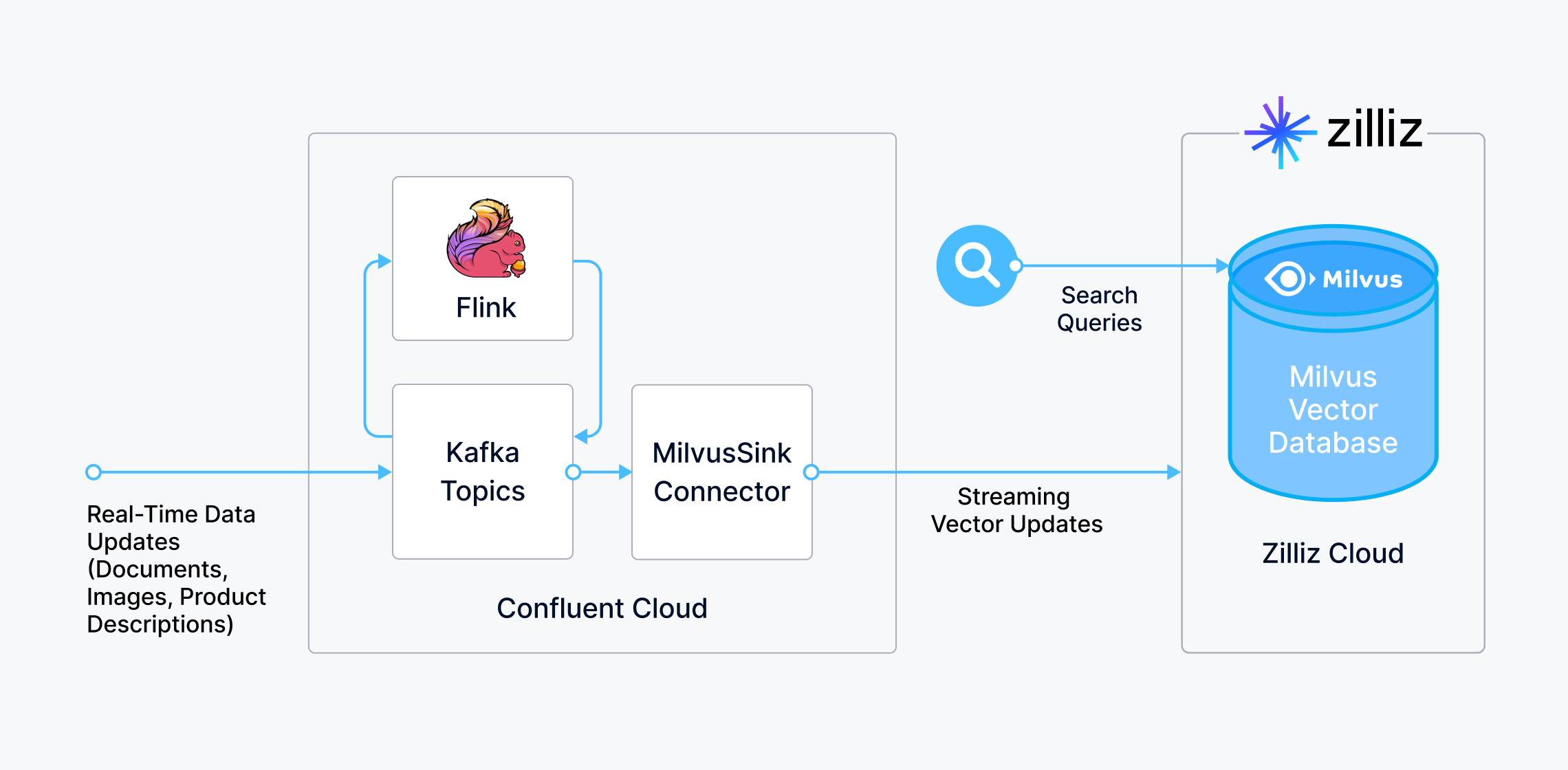 How Zilliz Cloud works with Confluent Cloud
How Zilliz Cloud works with Confluent Cloud
Real-time GenAI Applications Require Real-Time Data Processing
Successfully deploying GenAI applications such as Retrieval Augmented Generation (RAG) requires building data pipelines that provide relevant, real-time data streams sourced from every corner of the business. However, preparing pipelines of this sort is no easy task—especially when accounting for an ever-increasing amount of diverse data sources spanning across both legacy and modern data environments.
Ensuring applications have access to real-time pipelines with processed, prepared data will often require allocation of valuable engineering resources to manage open source tooling in-house rather than focusing on business-impacting innovation. Alternatively, securely processing data streams in multiple downstream systems (or across multiple distributed systems) is complex and inhibits data (re)usability, requiring redundant and expensive processing.
Without a reliable, cost-effective means of processing and preparing real-time data streams required by downstrown tools, the benefits of GenAI will stay out of reach for most.
Easily Build High-Quality, Reusable Data Streams With the Industry’s Only Cloud-native, Serverless Flink Service
Apache Flink is a unified stream and batch processing framework that has been a top-five Apache project for many years. Flink has a strong, diverse contributor community backed by companies like Alibaba and Apple. It powers stream processing platforms at many companies, including digital natives like Uber, Netflix, and LinkedIn, as well as successful enterprises like ING, Goldman Sachs, and Comcast.
Fully integrated with Apache Kafka on Confluent Cloud, Confluent’s new Flink service allows businesses to:
● Effortlessly filter, join, and enrich your Confluent data streams with Flink, the de facto standard for stream processing
● Enable high-performance and efficient stream processing at any scale, without the complexities of infrastructure management
● Experience Kafka and Flink as a unified platform, with fully integrated monitoring, security, and governance
By leveraging Kafka and Flink as a unified platform, teams can connect to data sources across any environment, clean and enrich data streams on the fly, and deliver them in real-time to the Milvus vector database for efficient semantic search or recommendation. Thanks to the scalable architecture of Milvus, the data becomes instantly searchable without sacrificing the latency of ongoing search queries. This ensures the GenAI apps have the most up-to-date view of the business data.
Confluent’s fully managed Flink service is now generally available across all three major cloud service providers, providing customers with a true multi cloud solution and the flexibility to seamlessly deploy stream processing workloads everywhere their data and applications reside. Backed by a 99.99% uptime SLA, Confluent ensures reliable stream processing with support and services from the leading Kafka and Flink experts.
Together, Zilliz and Confluent enable simpler development of GenAI applications
Our Confluent integration enables your teams to tap into a continuously enriched vector database with business data updates being streamed and indexed in real-time, so you can quickly build and scale the AI applications with the best user experience.
Getting Started
Check out the open-sourced Kafka-Milvus Connector and use it with your Flink and Kafka instances on Confluent Cloud and fully-managed Milvus on Zilliz Cloud to make real-time data updates instantly available for vector search.
Not yet a Confluent customer? Start your free trial of Confluent Cloud today. New signups receive $400 to spend during their first 30 days—no credit card required.

Keep Reading

Introducing Functions and Model Inference on Zilliz Cloud: Automatic Embedding and Reranking with Hosted Models
Zilliz Cloud Functions auto-generate embeddings via OpenAI, Voyage AI, Cohere, or Zilliz Hosted Models. Built-in reranking — just insert text and search.

Zilliz Cloud Update: Tiered Storage, Business Critical Plan, Cross-Region Backup, and Pricing Changes
This release offers a rebuilt tiered storage with lower costs, a new Business Critical plan for enhanced security, and pricing updates, among other features.

The Real Bottlenecks in Autonomous Driving — And How AI Infrastructure Can Solve Them
Autonomous driving faces a data bottleneck. Learn how AI-native vector databases like Zilliz solve scale, cost, and insight challenges across AV pipelines.