




OpenAI o1:開発者が知っておくべきこと
2024年9月、OpenAIは独自の大規模言語モデル(LLM)の最新シリーズ「o1シリーズ」を発表した。o1シリーズがOpenAIの以前の最も強力なモデルであるGPT-4oと異なる主な特徴は、ユーザーに最終的な答えを生成する前に、問題を通して考える能力です。つまり、o1モデルは、問題をより小さな構成要素に分解し、一般的に思考連鎖推論と呼ばれるプロセスで段階的に解決するように訓練されている。
この記事では、開発者の視点からo1シリーズについて話し、これらのモデルが洗練されたユースケースのためにどのように実装できるかを探ります。その前に、o1モデルとは何か、GPT-4oと比較してどのように動作するか、OpenAIがこのシリーズで導入した新機能について簡単に説明します。
o1 モデルの簡単な紹介
OpenAIはo1シリーズにo1-preview、o1、o1-miniの3つのバリエーションを導入しました。GPT-4のような他のOpenAIのモデルと比較して、3つのバリエーションはすべて、高度な推論機能というユニークな特徴を共有しています。
o1モデルは、答えを生成する前に問題の分析に多くの時間を費やすように設計されています。このアプローチは、人間が複雑な問題を分析し、解決する方法を模倣しています。どのような問題に対しても、これらのモデルは問題を分解し、思考プロセスを段階的に明確にし、最初の推論が不十分な場合は代替策を探ります。
これらのモデルは完全にクローズドソースであるため、そのトレーニングプロセスに関する明確な詳細はまだ明らかになっていない。しかし、o1モデルのトレーニングで使用される可能性が高いアプローチは2つある。思考の連鎖(CoT)プロンプティングと強化学習(RL)である。
CoTプロンプティングのコンセプトは単純だ。与えられた問題に対する直接的な答えをモデルに与える代わりに、CoTプロンプトには、以下に示すように、問題を解くための詳細な文脈上の手順が含まれる:
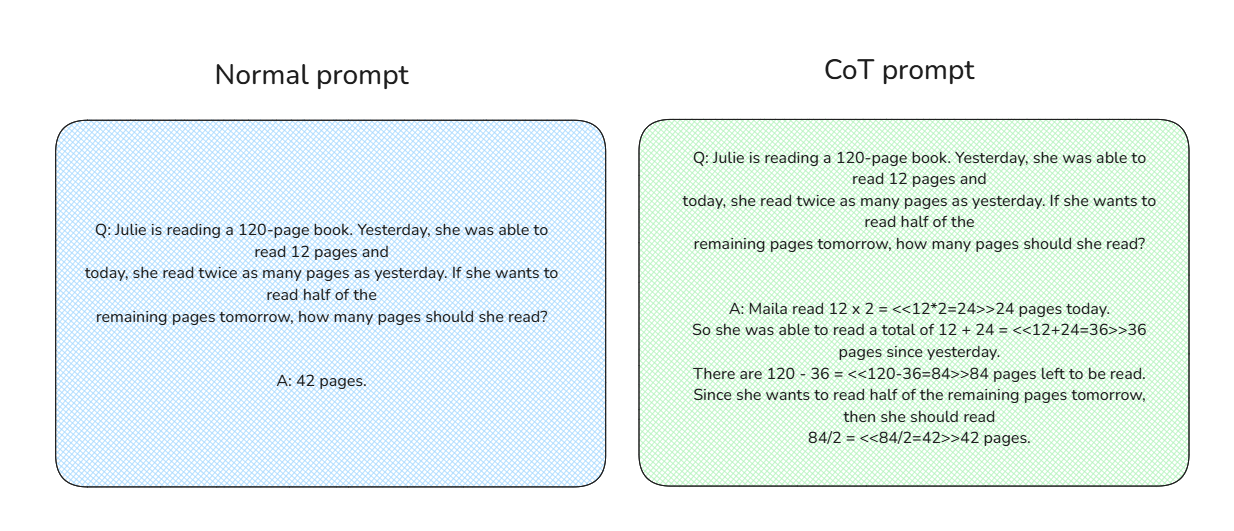
通常のプロンプトとCoTプロンプトの比較_。
膨大な量のCoTプロンプトデータを微調整中のRLと組み合わせることで、モデルは推論プロセスを反復的に改良する。モデルは論理の欠陥を識別し、問題解決により賢明なアプローチを採用することを学習する。そしてモデルは、正確な推論ステップと正しい答えを生成することで、報酬を得る。その結果、o1シリーズのモデルは、答えを出す前に批判的に考え、効果的に推論できるようになります。
この推論機能を実装するために、OpenAIはo1モデルに「推論トークン」と呼ばれる追加トークンを導入しました。入力と出力のトークンのみを使用する他のLLMとは異なり、o1モデルは思考プロセスを促進するために推論トークンを使用します。
これらの推論トークンにより、モデルはプロンプトを分析し、出力トークンを生成する前に複数のアプローチを検討することができる。回答が確定すると、推論トークンはコンテキストから破棄される。以下は、ユーザーとモデルの相互作用の複数のラウンドにおける入力、出力、および推論トークンのダイナミクスの視覚化です:
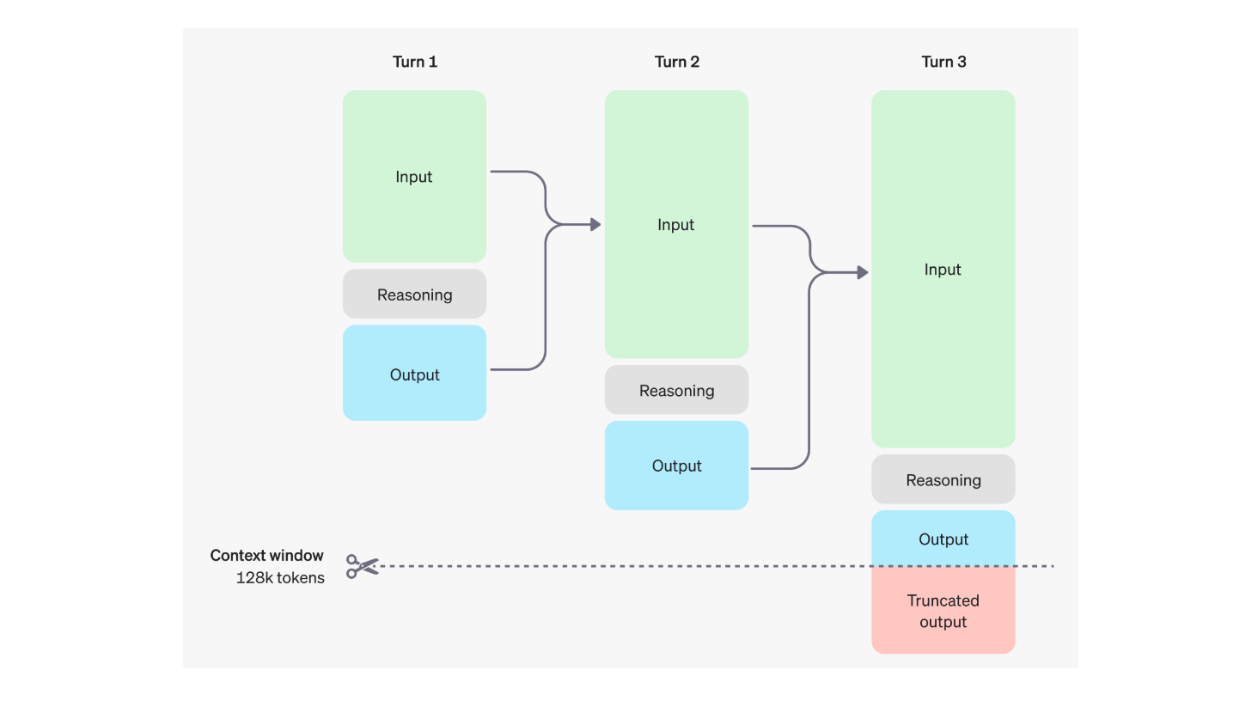
ユーザーとモデルの相互作用の複数のラウンド中の入力、出力、推論トークンのダイナミクス Source._.
o1 の特徴(そして開発者にとって重要な理由)
本質的に、o1モデルはGPT-4oの素晴らしさの全てをベースにしていますが、思考の連鎖(CoT)と強化学習(RL)アプローチを組み合わせることで、その限界をさらに押し広げています。その結果、o1モデルは、コーディング、数学、一般科学など、複雑な推論を必要とする様々なドメインにおいてGPT-4oを凌駕します。
以下のビジュアライゼーションに示されているように、o1-previewとo1モデルの両方が、高度な推論を必要とするベンチマークにおいてGPT-4oを上回っています。特に、3つの主要な科学的推論ベンチマークでは、GPT-4oの方が大幅に優れています:AIME 2024、Codeforces、GPQA Diamondです。
AIME 2024:AIME 2024:米国で最も優秀な高校生を対象とした数学試験に基づくベンチマーク。
GPQA Diamond**:GPQA Diamondの略:化学、生物学、物理学などの科学科目の専門知識を測定する。
コードフォース**:競技プログラミングコンテストの課題を含む。
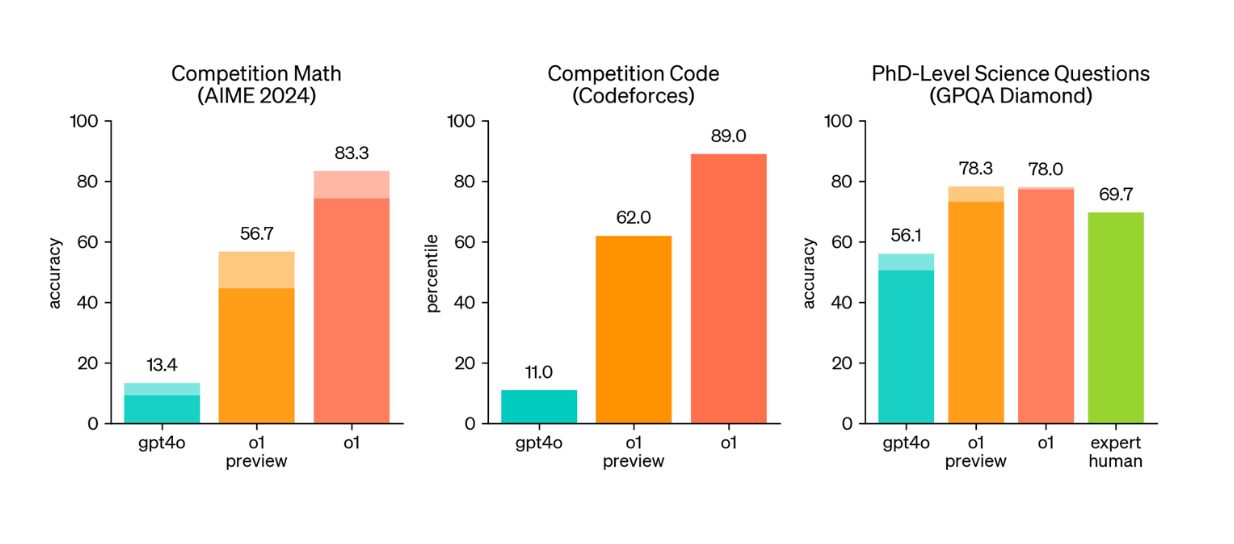
GPT-4o、o1-preview、o1モデルの推論ベンチマークの比較 Source._.
o1-previewモデルはGPT-4oと比較して複雑な推論タスクにおいて優れた性能を示すが、注目すべき欠点もある:
高い推論トークン使用量**:o1-previewは大量の推論トークンを生成し、モデルの128,000トークンのコンテキストウィンドウのかなりの部分を消費する。膨大な入出力トークンを必要とするタスクでは、応答が切り捨てられることがあります。これもGPT-4oに比べて使用コストを増加させます。
レイテンシの問題**:トークンの数が多いため、応答時間が遅くなります。平均して、o1-previewのレイテンシはGPT-4oの約10倍遅く、本番使用には適していません。
これらの制限に対処するため、OpenAIはo1シリーズに2つの追加モデルを導入しました:o1-miniと最新のo1モデルです。
o1-miniはo1-previewに比べて小型のモデルで、特にSTEM関連データに最適化されている。この最適化により、AIME 2024(o1-previewの44.6%に対し70%の精度を達成)やCodeforcesなどの科学的ベンチマークにおいて、o1-previewを上回る性能を発揮します。
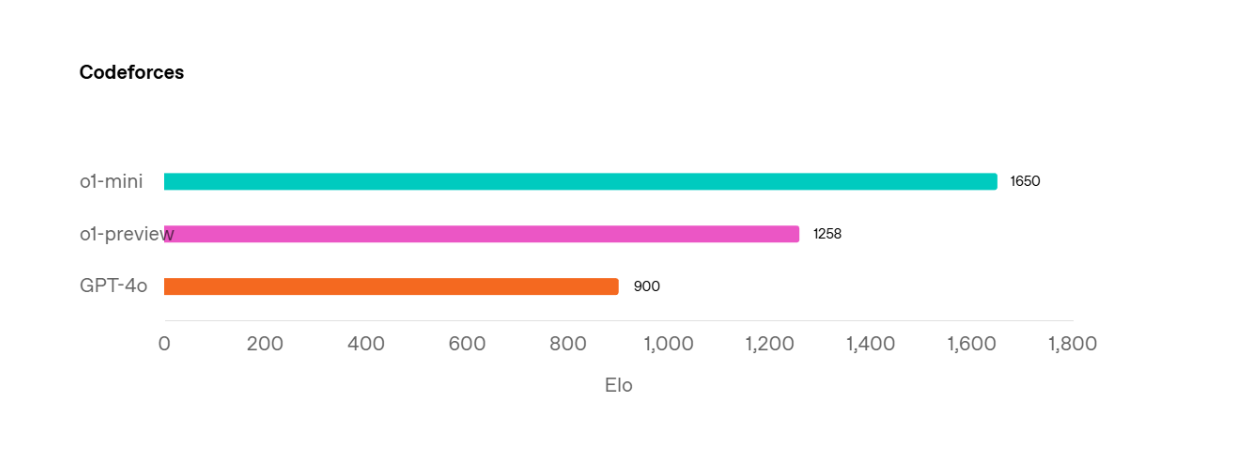
CodeforcesベンチマークにおけるGPT-4o、o1-preview、o1-miniモデルの比較 Source._.
さらに、o1-previewよりも小さいことで、o1-miniのレイテンシが速くなります。このモデルの推論時間は、o1-previewのそれよりも約3-5倍速い。しかし、o1-miniの性能は、非STEMベンチマークではo1-previewよりもまだ悪いことに注意することが重要です。
パフォーマンスと機能をさらに強化するために、OpenAIはo1モデルの最新バージョンを導入しました。上のビジュアライゼーションに示されているように、このモデルはすべての科学的ベンチマークでo1-previewを上回っています。
複雑な推論タスクでより強力な性能を発揮するだけでなく、最新のo1モデルにはいくつかの重要な改良点があります:
より大きなコンテキスト・ウィンドウ:より大きなコンテキスト・ウィンドウ:最大200,000の入力トークンと最大100,000の出力トークンをサポート。
効率的な推論トークンの使用**:どのようなリクエストに対しても、o1-previewより平均して約60%少ない推論トークンを使用します。これにより、最新の o1 モデルのレイテンシは o1 preview より優れています。
視覚機能**:入力として画像を受け入れ、視覚データに対する推論を可能にする。この機能はo1-previewまたはo1-miniモデルでは利用できないことに注意してください。
OpenAIツールとの統合強化**:構造化出力、関数呼び出し、開発者定義のスタイルやトーンの機能を含みます。さらに、ユーザーは
reasoning_effortパラメータを使用して推論の労力(低、中、高)を調整し、スピード、コスト、品質のバランスをとることができます。
o1 モデルの実際の使用例
o1シリーズを使うことで解決できる実際のユースケースはたくさんある。このセクションでは、複雑な問題の推論、テキストからの情報抽出と推論、RAG(Retrieval Augmented Generation)、画像理解、関数呼び出しなど、いくつかの例を紹介します。
しかし、この記事を書いている時点では、最新のo1モデルの利用可能な環境はまだ限られています。特定のユーザー層でしか利用できないからです。したがって、可能な限りo1-miniモデルを使用したユースケースのコード・スニペットを示します。
例に進む前に、まずOpenAIのAPIキーを設定する必要があります。APIキーの設定方法については こちらを参照してください。次に、APIキーを以下のように環境の一部として配置します:
インポート getpass
インポート os
if not os.environ.get("OPENAI_API_KEY"):
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAIのAPIキーを入力してください: ")
これでOpenAIのモデルを使う準備ができました。
複雑な問題推論
o1モデルの最も簡単なアプリケーションは、数学とコーディングの複雑な問題を解くことです。例えば、数学の問題の解き方をOpenAIに教えてもらうとしよう:
from openai import OpenAI
クライアント = OpenAI()
プロンプト = """
ジュリーは120ページの本を読んでいる。昨日、彼女は12ページを読むことができた。
今日は昨日の倍のページを読んだ。もし彼女が半分を読みたければ
明日残りの半分を読むとしたら、何ページ読むべきか?
"""
response = client.chat.completions.create()
model="o1-mini"、
messages=[
{
"role":"ユーザー"、
"コンテンツ": プロンプト
}
]
)
print(response.choices[0].message.content)
"""
出力する
ジュリーが明日読むべきページ数を決定するために、問題をステップごとに分解してみよう:
1.本の総ページ数: **本の総ページ数: **
この本には**120ページ**あります。
2.**昨日読んだページ数:***。
ジュリーは昨日**12ページ**を読みました。
3.**今日読んだページ
今日、彼女は昨日の**倍**のページを読んだ。
( 2 x 12 = 24 ) ページ。
4.**日間で読まれた総ページ数:***。
( 12 text{ (yesterday)} + 24 text{ (today)} = 36 ) ページ。
5.**残りのページ
( 120 text{ (total)} - 36 text{ (read)} = 84 ) ページが残っています。
6.**明日読むページ:***ページ
彼女は残りページの**半分**を読みたがっている:
( frac{84}{2} = 42 ) ページ。
**答え:***である。
ジュリーは明日**42ページ**を読むべきです。
"""
おわかりのように、最終的な答えを提供するだけでなく、モデルは段階的な思考プロセスを生成する。
創造的な自動化
OpenAIの他のLLMと同様に、o1モデルは、PDFの内容を要約したり、記事からYouTubeスクリプトを生成したり、ドキュメントから特定の情報を抽出して推論するなど、創造的な自動化に使用することができます。
以下の例では、特定の出力スキーマを持つテキストから特定の情報を抽出するためにo1-miniモデルを使用します。テキストに含まれる情報を抽出するだけでなく、簡単な数学的演算を実行することによって情報を推論するようモデルに依頼します。
インポートリクエスト
def fetch_html(url):
レスポンス = requests.get(url)
if response.status_code == 200:
return response.text
else:
なし
url = "<https://en.wikipedia.org/wiki/List_of_NBA_career_scoring_leaders>"
html_content = fetch_html(url)
json_format = """
{
企業:[
{
"player_name":"Tim Duncan",、
"total_points":"1750",
"合計_得点_フリースローなし":"1050",
}
]
}
"""
o1_response = client.chat.completions.create()
model="o1-mini"、
メッセージ=[
{
"role":"ユーザー"、
"コンテンツ": f""
テキストから情報を抽出する。
- 以下のhtmlを読んで、NBAの歴史の中でフリースローなしで最も多くの得点を獲得した選手を返しなさい:{html_content}。
- 結果を高いものから低いものの順に返し、トップ5を表示する。以下のフォーマットのJSONとしてのみ返してください:{json_format}"
"""
}
]
)
print(o1_response.choices[0].message.content)
"""
出力する
json
{
"players":[
{
"player_name":"LeBron James"、
"総得点":"41599",
"フリースローなしの総得点":"33048"
},
{
"player_name":「Kareem Abdul-Jabbar"、
"総得点":"38387",
"合計_得点_フリースローなし":"31675"
},
{
"player_name":"Karl Malone"、
"total_points":"36928",
"合計_得点_フリースローなし":"27141"
},
{
"player_name":「ウィルト・チェンバレン
"総得点":"31419",
"フリースローなしの総得点":"25362"
},
{
"player_name":「コービー・ブライアント
"総得点":"33643",
"フリースローなしの総得点":"25265"
}
]
}
"""
ご覧のように、o1モデルは定義した出力スキーマに従って情報を抽出するだけでなく、数学的演算を実行し、他の抽出情報とともに適切な結果を出力スキーマに含めることができる。
AI検索エンジン
また、o1モデルをRetrieval Augmented Generation (RAG)の設定で使用することもできる。ここでは、類似検索によって得られた提供されたコンテキストに基づいて、クエリに対する応答を生成するために使用する。
RAGアプリケーションの通常のワークフローは以下の通りである:ユーザクエリが与えられると、クエリは、OpenAIのtext-embedding-3-largeのような、選択した埋め込みモデルを用いて埋め込みに変換される。次に、クエリの埋め込みは、類似性検索によって、ベクトルデータベースに格納されたコンテキストの埋め込みコレクションと比較される。そして、最も関連性の高い上位k個のコンテキストが取得され、プロンプトに追加され、LLMにクエリへの回答に役立つコンテキストを提供する。
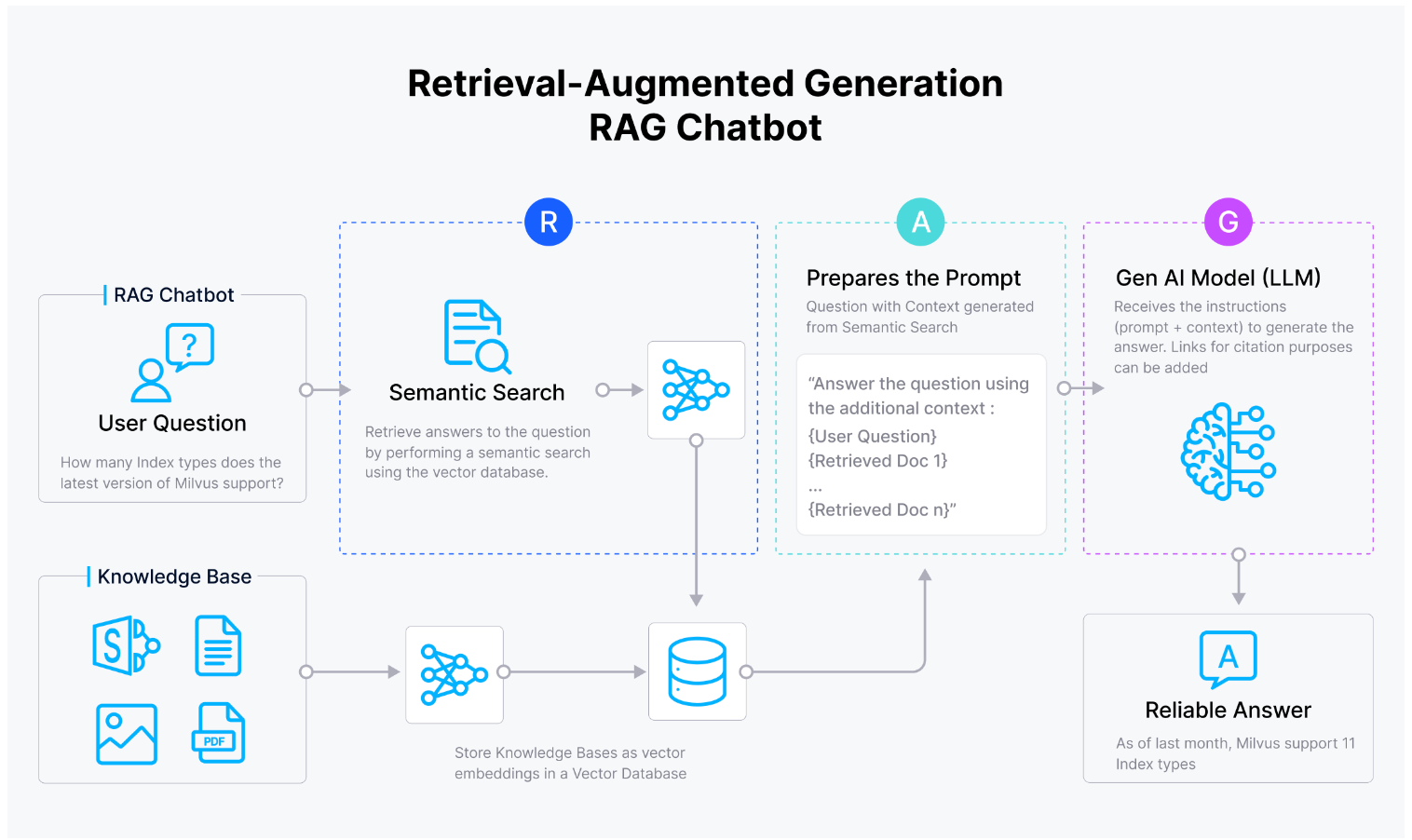
RAGワークフロー
お分かりのように、RAGのユースケースでo1モデルを使用するには、通常、大量のコンテキストを保存し、効率的で高速な類似検索を実行するために、Milvusのようなベクトルデータベースと組み合わせます。
以下の例では、o1-miniモデルとMilvusを組み合わせたシンプルなRAGアプリケーションを作成する。
まず、HTMLからテキストソースを読み込み、RAGアプリケーションの可能なコンテキストとして使用する。次に、元のテキストを約2000文字のチャンクに分割する。チャンキング処理の後、すべてのチャンクをMilvusベクトルデータベースに格納することができる。インデックスタイプを "FLAT "に設定するのは、与えられたクエリに最適なコンテキストを見つけるために網羅的な検索を行いたいからである。
pip install --upgrade --quiet langchain langchain-core langchain-community langchain-text-splitters langchain-milvus langchain-openai bs4
bs4をインポートする
from langchain_community.document_loaders import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_milvus import Milvus
from langchain_openai import OpenAIEmbeddings
# WebソースからドキュメントをロードするためのWebBaseLoaderインスタンスを作成する。
loader = WebBaseLoader(
web_paths=(
"<https://lilianweng.github.io/posts/2023-06-23-agent/>"、
"<https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/>"、
),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
# ローダーを使ってウェブソースからドキュメントをロードする
ドキュメント = loader.load()
# テキストをチャンクに分割するためのRecursiveCharacterTextSplitterを初期化する
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
# text_splitter を使ってドキュメントをチャンクに分割する
docs = text_splitter.split_documents(documents)
# OpenAIのデフォルト埋め込みモデルを定義する
embeddings = OpenAIEmbeddings()
# チャンクされたデータをMilvusに格納する
vectorstore = Milvus.from_documents(
documents=docs、
embedding=embeddings、
connection_args={
"uri":"./milvus_demo.db"、
},
index_params={"index_type":"FLAT", "metric_type":"L2"},
drop_old=True, # 古いMilvusコレクションがある場合はそれを削除する。
)
これで、モデルとプロンプトを定義できます。プロンプトには、クエリそのものだけでなく、「提供されたコンテキストを使ってクエリに答えてください」といった指示が含まれます。結果として、最も関連性の高い上位1つのコンテキストを取得します。
from langchain_openai import ChatOpenAI
from langchain import hub
# レスポンス生成のためにOpenAIの言語モデルを初期化する。
llm = ChatOpenAI(model_name="o1-mini", temperature=1)
# AI応答を生成するためのプロンプトテンプレートを定義する
prompt = hub.pull("rlm/rag-prompt")
# ベクターストアをレトリバーに変換する
retriever = vectorstore.as_retriever()
query = "AIエージェントの自己反省とは?"
vectorstore.similarity_search(query, k=1)
最後に、LangChainを使ってRAGワークフローを簡単にオーケストレーションし、Milvusデータベースから取得した最も関連性の高いコンテキストを使って、与えられたクエリに対するo1-miniモデルからのレスポンスを取得することができます。
from langchain_core.runnables import RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# 取得したドキュメントを整形する関数を定義します。
def format_docs(docs):
return "nn".join(doc.page_content for doc in docs)
# AI応答生成のためのRAG(Retrieval-Augmented Generation)チェーンを定義する。
rag_chain = (
{"context": retriever | format_docs, "question":RunnablePassthrough()}とする。
| プロンプト
| プロンプト
| StrOutputParser()
)
# rag_chain.get_graph().print_ascii()
# 特定の質問でRAGチェーンを呼び出し、レスポンスを取得する
res = rag_chain.invoke(query)
print(res)
"""
出力する
AIエージェントにおける自己反省とは、過去の経験に基づいて自らの行動や決定を評価し、改良する能力のことである。このプロセスにより、エージェントは間違いを特定し、修正することができ、それによって時間の経過とともにパフォーマンスを向上させることができる。試行錯誤による反復的な改善が必要な、複雑な実世界のタスクを処理するために不可欠です。
"""
画像理解
o1-previewやo1-miniと比較した最新のo1モデルの主な利点の1つは、そのマルチモーダル機能である。このため、o1モデルは、画像の内容を記述したり、画像内のテキストを要約したり、画像から構造化された情報を抽出したりといった画像推論のユースケースに理想的です。
画像へのリンクを渡す方法と、Base64でエンコードされた画像を渡す方法です。以下はそのためのコード例です:
from openai import OpenAI
クライアント = OpenAI()
response = client.chat.completions.create()
model="o1"、
messages=[
{
"role":"ユーザー"、
"content":[
{"type":"text", "text":「この画像には何が写っていますか?}
{
"type":「image_url"、
"image_url":{
"url":"<https://upload.wikimedia.org/wikipedia/commons/thumb/d/dd/Gfp-wisconsin-madison-the-nature-boardwalk.jpg/2560px-Gfp-wisconsin-madison-the-nature-boardwalk.jpg>"、
},
},
],
}
],
max_tokens=300、
)
print(response.choices[0])
関数の呼び出し
o1モデルで探求できるもう一つのエキサイティングなユースケースは、関数呼び出しだ。要するに、関数呼び出しは、LLMが我々のコードや、検索エンジンやAPIなどの外部サービスと対話することを可能にします。LLMの問題解決能力によって、LLMは目の前のタスクを解決するために適切な外部サービスを正確に利用することができます。
例として、ロサンゼルスの現在の天気を知りたいとしよう。外部サービスがなければ、LLMが正しい答えを出すことは不可能で、幻覚を見始める可能性が高い。もし天気APIにアクセスできれば、o1モデルがクエリに答えるための追加リソースとして、この「ツール」を使うことができる。
エージェントモデルを作成するための関数呼び出しのコード実装については、 OpenAI や LangChain が提供しているドキュメントで詳しく知ることができる。
o1 モデルとその代替モデルの比較
このセクションでは、o1モデルの長所と短所を、GPT 4o、o3-mini、Claude 3.5 Sonnet、DeepSeek R1などの代替モデルと比較します。
GPT 4oとの比較
複雑な推論ベンチマークでは、o1モデルの性能はGPT-4oモデルよりもはるかに優れていますが、だからといって、GPT-4oよりもo1モデルを常に選択すべきというわけではありません。
全体的に、o1モデルは、アイデア出しのタスクのような複雑で詳細な思考プロセスを必要とするタスクに優れています。例えば、これから始めようとしているビジネスの戦略立案や、最善・最悪のシナリオを描くためのパートナーとしてo1モデルを使うことができる。教育分野では、開発中の科学コースの各要素の詳細な説明を生成するためにo1モデルを使用することができます。また、コードレビューやコードの最適化の際に、o1モデルをパートナーとして活用することもできる。
しかし、本番環境でAIアシスタントをデプロイする場合は、o1モデルよりもGPT-4oの方が好まれます。というのも、OpenAIのAPI実装は、o1モデルに比べてGPT-4oの方がはるかに成熟しているからです。例えば、GPT-4oもo1モデルも入力として画像を受け付けますが、o1モデルはカスタム命令、ファイルアップロード(画像を除く)、音声機能、ウェブブラウジングなど、いくつかのツールや機能を利用できません。したがって、これらの機能が必要な場合は、GPT-4oを使用する必要があります。
さらに、o1モデルの入手可能性は今のところ限られている。このモデルにアクセスするには、少なくともTier 3ユーザーであるか、ChatGPT PlusまたはProプランに加入する必要があるため、特定のユーザーしかアクセスできません。また、推論のレイテンシーが非常に重要なユースケースである場合、GPT-4oはo1モデルよりも良い代替案を提供します。
o3-miniとの比較
o3-miniモデルはOpenAIの推論LLMの最新モデルです。o1-miniと同様に、o3-miniはSTEMドメインにおいて高度に最適化されていますが、以下のように異なるSTEMベンチマークにおけるパフォーマンスグラフを見ればわかるように、o1-miniよりも優れており、o1モデルに匹敵するパフォーマンスを持っています:
(https://assets.zilliz.com/Performance_comparison_between_o3_mini_and_o1_model_across_different_STEM_benchmarks_e7083fc4f1.png)
異なるSTEMベンチマークにおけるo3-miniとo1モデルのパフォーマンス比較 Source._.
o3-miniは、o1-miniの優れた点(低コストとレイテンシー)をすべて維持し、さらに改良を加えています。したがって、あなたのユースケースがSTEMの領域内にあり、レイテンシーやコストが重要であるならば、o1モデルよりもo3モデルの方が望ましいだろう。しかし、o1モデルは依然としてo3-miniよりも幅広い知識を提供しているため、ユースケースがSTEM領域ではなく、より一般的なものである場合は、o3-miniの方が適しています。
o3-miniとo1モデルの両方が、関数呼び出し、構造化出力、開発者メッセージのような高度なAPI機能と、調整可能な推論努力をサポートしています。しかし、o3-miniは現在テキストのみの入力をサポートしているため、ユースケースの入力が画像である場合は、o1モデルを使用する必要があります。
APIによる利用可能性については、現在のところ、o3-miniとo1モデルの両方がTier 3-5のユーザーのみ利用可能である。ChatGPT Plus、Pro、Teamに加入していれば、両方のモデルを使用することができます。
DeepSeek R1およびClaude 3.5 Sonnetとの比較
o1モデルの他の選択肢には、Claude 3.5 SonnetとDeepSeek R1があります。この2つのうち、DeepSeek R1はトレーニング中に推論を最適化しているため、o1に近い競争相手となりますが、Claude 3.5 Sonnetは推論に最適化されていません。以下のいくつかの推論ベンチマークでわかるように、o1とR1はどちらも3.5 Sonnetをかなりの差で上回っています。一方、o1とR1の性能は同等である。

o1モデルと他の代表モデルの比較 Source._.
したがって、LLMによる推論が必要な場合は、o1かR1を使用することをお勧めします。そうでない場合は、クロード3.5ソネットの方がo1モデルよりも低コストでレイテンシも優れているため、そちらが望ましいでしょう。
ここで、我々のユースケースがLLMの推論能力を必要としているとしよう。R1モデルの主な利点は、オープンソースであること、つまり独自のインフラでホストできることです。これは、我々のユースケースにおいてデータのプライバシーが懸念される場合、非常に有益である。
レイテンシーの面では、R1はMoE(Mixture-of-Expert)アーキテクチャを採用しているため、o1よりも優れている可能性がある。MoEのおかげで、R1のパラメー タのごく一部だけが、任意のリクエストで活性化され、推論プロセスを高速化する。また、R1は学習時にマルチトークン予測アプローチを採用し、推論時に投機的解読に再利用することができる。これは推論プロセスをさらに高速化する。
ただし、DeepSeek R1には合計671Bのパラメータが含まれており、これをホストするにはおよそ1.5TBのGPUメモリ(NVIDIA A100 80GB x16など)が必要であることに注意が必要です。したがって、このモデルを独自にホストするのは非常に高価であり、R1をホストするための複雑なステップを省くためには、o1モデルを使用する方がより好ましいでしょう。o1では、APIリクエストを行うときにのみ支払いが必要です。これは、AWSやGCPのような一般的なクラウド・プロバイダーでR1モデルをホスティングする際に必要な1時間あたりのGPUコストと比較すると、ほとんどのケースで安くなる。
結論
o1モデルは、思考連鎖プロンプトと強化学習を統合することで、GPT-4oを改善し、AIの推論能力の進歩を表しています。複雑な問題を分解し、代替解を探索する能力を持つo1モデルは、STEM関連やコーディングタスクなど、深い分析的思考を必要とするタスクに優れている。また、最新のo1モデルは、より大きなコンテキストウィンドウ、マルチモーダル機能、最適化された推論トークンの使用により、効率を高めています。
しかし、その長所にもかかわらず、o1モデルを採用するかどうかは、まだ特定のユースケースの要件に完全に依存しています。o1モデルは、複雑な推論タスクではGPT-4oを上回るが、コスト、レイテンシ、APIの成熟度の点では、GPT-4oの方がより好ましい。o3-miniと比較すると、o1はより広範な一般的知識を提供し、o3-miniはより低いコストとレイテンシでSTEMアプリケーションに効率的である。DeepSeek R1とClaude 3.5 Sonnetに対して、o1とR1は推論において優れているが、R1のオープンソースの性質とMixture-of-Expertアーキテクチャは、コストのかかるインフラを必要とするものの、レイテンシを改善する。
OpenAI GPT-o1を使ったチュートリアル
LangChain、Milvus、OpenAI GPT-o1、OpenAI text-embedding-3-smallを使ったRAGチャットボット](https://zilliz.com/tutorials/rag/langchain-and-milvus-and-openai-gpt-o1-and-openai-text-embedding-3-small)
LangChain、Milvus、OpenAI GPT-o1、NVIDIA embed-qa-4を使ったRAGチャットボット](https://zilliz.com/tutorials/rag/langchain-and-milvus-and-openai-gpt-o1-and-nvidia-embed-qa-4)
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and Cohere embed-multilingual-v3.0](https://zilliz.com/tutorials/rag/langchain-and-milvus-and-openai-gpt-o1-and-cohere-embed-multilingual-v3.0)
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and Ollama mxbai-embed-large](https://zilliz.com/tutorials/rag/langchain-and-milvus-and-openai-gpt-o1-and-ollama-mxbai-embed-large)
RAG Chatbot with LangChain, Milvus, OpenAI GPT-o1, and HuggingFace all-MiniLM-L12-v1](https://zilliz.com/tutorials/rag/langchain-and-milvus-and-openai-gpt-o1-and-huggingface-all-minilm-l12-v1)
読み続けて

Notion's Vector Search Is Excellent. Their Next Problem Is Harder.
Notion solved vector search scaling in two years. The next bottleneck — offline context engineering, unified data, and the real-time/offline gap — is harder.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Context Engineering Strategies for AI Agents: A Developer’s Guide
Learn practical context engineering strategies for AI agents. Explore frameworks, tools, and techniques to improve reliability, efficiency, and cost.