




RAG評価ツール:検索拡張世代アプリケーションの評価方法
RAG)、Retrieval Augmented Generationは、ChatGPTのような大規模言語モデル(LLMs))時代の著名なAIフレームワークである。これは、外部知識を統合することによってこれらのモデルの能力を強化し、より正確で最新の応答を保証する。標準的なRAGシステムには、LLM、Milvusのようなベクトルデータベース、およびコードとしてのプロンプトが含まれ、これらはすべて包括的なラグ評価フレームワークを使用して評価することができる。
より多くの開発者や企業がGenAIアプリケーションを構築するためにRAGを採用するにつれて、その有効性を評価することがますます重要になってきている。以前の投稿](https://zilliz.com/blog/openai-rag-vs-customized-rag-which-one-is-better)では、OpenAIアシスタントとMilvusベクトルデータベースで構築された2つの異なるRAGシステムのパフォーマンスを評価し、RAGシステムの評価に光を当てました。この投稿では、RAGアプリケーションを評価するために使用される方法論について深く掘り下げて議論します。また、いくつかの強力な評価ツールを紹介し、標準的なメトリクスを強調します。
RAGアプリケーションの評価は、単にいくつかの例を比較するだけではありません。重要なのは、これらのアプリケーションを評価するために、説得力があり、定量的で、再現可能なメトリクスを使用することです。この旅では、メトリクスの3つのカテゴリーを紹介します:
グランドトゥルースに基づくメトリクス
グランド・トゥルースなしのメトリクス
LLM応答に基づく指標
グランドトゥルースとは、ユーザーのクエリに対応するデータセット内の確立された回答や知識文書の塊を指す。グランドトゥルースが回答である場合、グランドトゥルースとRAGの回答を直接比較することができ、回答の意味的類似性や回答の正しさなどのメトリクスを使用したエンドツーエンドの測定が容易になります。
以下は、その正しさに基づいて回答を評価する例です。
*アインシュタインは1879年にドイツで生まれました。
*高い正答率高解答の正しさ:アインシュタインは1879年にドイツで生まれた。
*低い答えの正しさ:正答率が低い:1879年、スペインでアインシュタインが生まれた。
グランドトゥルースが知識文書からのチャンクである場合、完全一致(EM)、Rouge-L、F1などの伝統的なメトリクスを使用して、文書チャンクと検索されたコンテキストとの間の相関関係を評価することができる。要するに、我々はRAGアプリケーションの検索効果を評価しているのである。
RAGアプリケーションの評価には、グランドトゥルースを持つデータセットを使用することが重要であることがわかった。しかし、もしあなたがアノテーションされたグランドトゥルースなしで、プライベートなデータセットを使ってRAGアプリケーションを評価したい場合はどうすればいいのだろうか?データセットに必要なグランドトゥルースをどのように生成するのでしょうか?
最も簡単な方法は、ChatGPTのようなLLMに、あなた独自のデータセットに基づいてサンプル問題と解答を生成してもらうことです。RagasやLlamaIndexのようなツールも、あなたの知識文書に合わせたテストデータを生成する方法を提供しています。

Ragas評価ツールによって生成された質問と回答のサンプル (source: https://docs.ragas.io/en/latest/concepts/testset_generation.html)
これらの生成されたテストデータセットは、質問、文脈、対応する回答から構成され、無関係な外部のベースラインデータセットに依存することなく定量的な評価を容易にします。このアプローチにより、ユーザーは独自のデータを使用してRAGシステムを評価することができ、よりカスタマイズされた有意義な評価プロセスが保証されます。
グランドトゥルースなしのメトリクス
各クエリのグランドトゥルースなしでRAGアプリケーションを評価することができる。オープンソースの評価ツールであるTruLens-Evalは、RAG Triadの概念を革新している。これは、クエリ、コンテキスト、レスポンスのトリプレットの要素の関連性を評価することに焦点を当てている。対応するメトリクスは3つある:
コンテキストの関連性**:検索されたコンテキストがどれだけクエリをサポートしているかを測定する。
LLMの応答が検索されたコンテキストとどの程度一致しているかを評価する。
回答の妥当性(Answer Relevance):** クエリに対する最終的な回答の妥当性を測る。
以下は、質問との関連性に基づいて回答を評価する例です。
*質問フランスはどこにあり、首都はどこですか?
*関連性の低い答えフランスは西ヨーロッパにあります。
*関連性の高い答えフランスは西ヨーロッパにあり、パリが首都である。
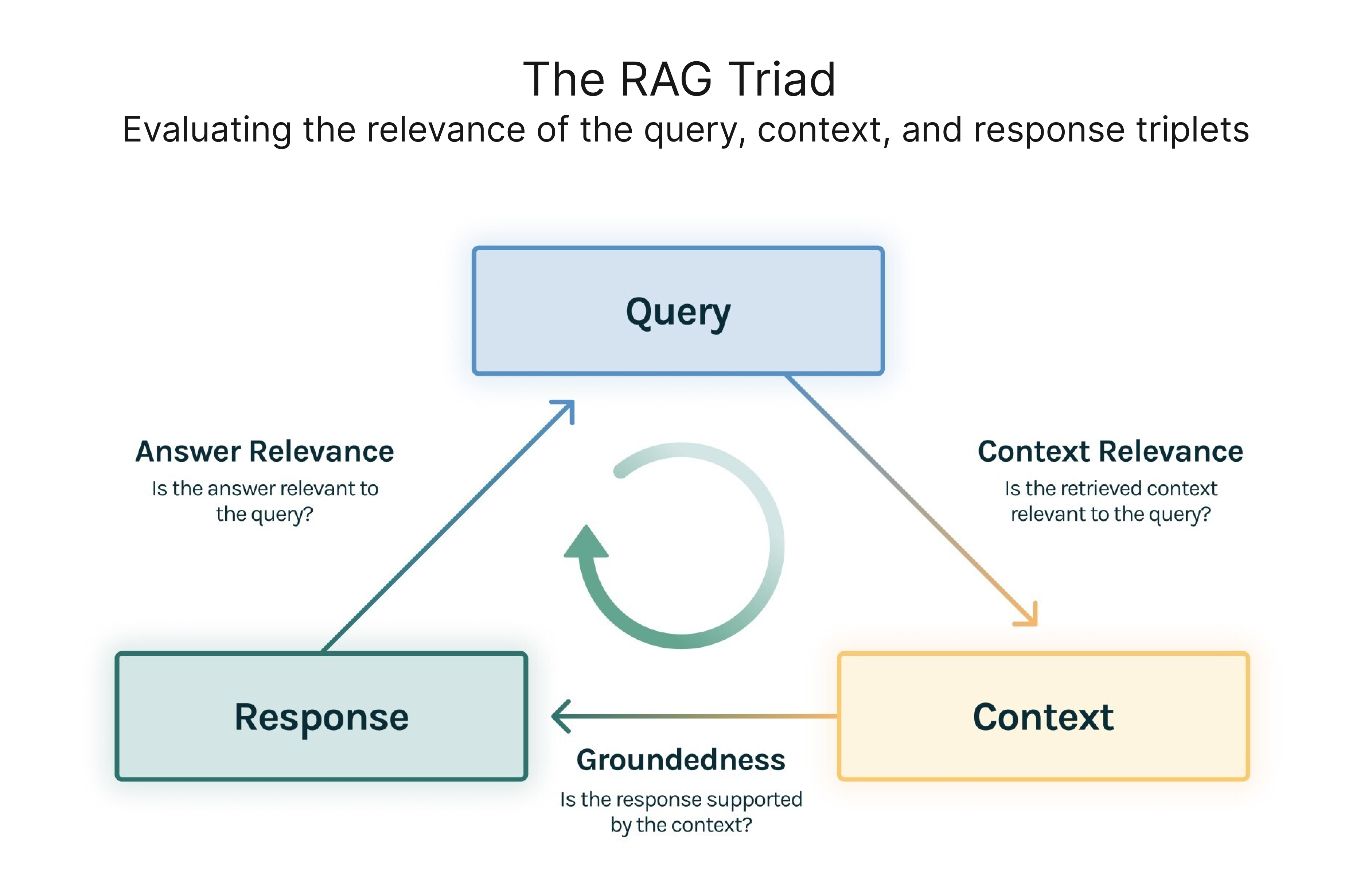
RAG Triad、ソース:https://www.trulens.org/getting_started/core_concepts/rag_triad/
さらに、これらのトライアドのメトリクスは、評価の粒度を高めるために、さらに細分化することができる。例えば、Ragas(RAGシステムのパフォーマンス評価に特化したオープンソースのフレームワーク)は、コンテキストの関連性を、コンテキストの精度、コンテキストの関連性、コンテキストの想起という3つの詳細なメトリクスに分割しています。
このメトリクスのカテゴリーは、親しみやすさ、有害性、簡潔性などの要素を考慮してLLM応答を評価する。例えば、簡潔性、関連性、正しさ、一貫性、有害性、悪意、有用性、論争性、女性嫌悪、犯罪性、無神経さなどのメトリクスを提案している。
以下は、簡潔性に基づいて回答を評価する例です。
*質問2+2は何ですか?
*簡潔性の低い答え2+2は何ですか?初歩的な質問だ。あなたが探している答えは、2と2は4です。
簡潔性の高い答え4
LLMを使ってメトリクスを採点する
前述したメトリクスのほとんどは、スコアを得るためにテキストを入力する必要があります。しかし、GPT-4のようなLLMの登場により、このプロセスはより管理しやすくなりました。
論文「Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena」は、ユーザーの質問に対するAIアシスタントの応答の質を判定するためのGPT-4のプロンプトデザインを提案している。以下に簡単な例を示します:
[システム]
公平な裁判官として、以下に表示されたユーザーの質問に対してAIアシスタントが提供した応答の質を評価してください。あなたの評価は、回答の有用性、関連性、正確性、深さ、創造性、詳細レベルなどの要素を考慮してください。短い説明から評価を始めてください。できるだけ客観的に説明してください。説明の後、以下の書式に厳密に従い、回答を1から10の尺度で評価してください:「評価]]」という形式に従ってください:評価[[5]]".
質問
質問
[アシスタントの回答開始]
回答
[助手の回答終了]
このプロンプトは、GPT-4に回答の質を評価し、1~10のスケールで評価するよう求めるものです。
重要なことは、GPT-4は他の審査員と同様、無謬ではなく、バイアスや潜在的な誤りを持つ可能性があるということです。そのため、プロンプトの設計は非常に重要である。マルチショットやチェーン・オブ・ソート(CoT)のような高度なプロンプトエンジニアリング技術が必要になるかもしれません。幸いなことに、RAGアプリケーションのための多くの評価ツールはすでに適切に設計されたプロンプトを統合しているため、この問題を心配する必要はない。
RAGアプリケーションの評価について説明したところで、RAGアプリケーションを評価するためのツールをいくつか紹介し、それらがどのように機能するか、またどのような使用例がこれらのツールに最も適しているかについて説明する。
ラガス:合理化されたRAG評価
Ragasは、RAGアプリケーションを評価するためのオープンソースの評価ツールです。シンプルなインターフェースで、Ragas は評価プロセスを合理化します。必要な形式のデータセットインスタンスを作成することで、ユーザは迅速に評価を開始し、'ragas_score'、'context_precision'、'faithfulness'、'answer_relevancy'などのメトリクスを得ることができる。
``python from ragas import evaluate from datasets import Dataset
huggingfaceのデータセットをフォーマットで用意する
データセット({
features:['質問', '文脈', '答え', 'ground_truths']、
num_rows: 25
})
データセットデータセット
results = evaluate(dataset)
{'ragas_score': 0.860, 'context_precision':0.817,
'faithfulness': 0.892, 'answer_relevancy':0.874}
Ragasは様々なメトリクスをサポートし、特定のフレームワーク要件を課さないため、様々なRAGアプリケーションを柔軟に評価することができます。Ragasは[LangSmith](https://www.langchain.com/langsmith)を介して評価のリアルタイムモニタリングを可能にし、各評価の理由やAPIキーの消費に関する洞察を提供します。
## RAGシステムを理解する
検索拡張世代(RAG)システムは、大規模言語モデル(LLM)と外部知識検索の長所を組み合わせた人工知能(AI)技術の一種である。RAGシステムは3つの主要コンポーネントから構成される:インデックス、検索、生成である。インデックス・コンポーネントは、検索および取得可能な知識のデータベースを作成する。Retrieveコンポーネントは、インデックス化されたデータベースから関連情報を検索する。生成コンポーネントは、検索された情報に基づいて新しいテキストを作成する。
RAGシステムは、チャットボットや質問応答システムによく使用される。RAGシステムは、AIによる会話や情報処理に堅牢かつダイナミックなアプローチを提供する。外部の知識を活用することで、RAGシステムはより正確で、文脈に沿った、関連性のある、最新の回答を可能にする。そのため、正確でタイムリーな情報が重要な顧客サービスや社内ナレッジチャットボットなど、さまざまな領域で重宝されています。
## RAGの評価指標
RAGシステムのパフォーマンスを評価することは、その信頼性とパフォーマンスにとって極めて重要です。RAGシステムには、以下のような評価指標があります:
* コンテキストの関連性**:ユーザーのクエリに対する検索されたコンテキストの関連性を測定する。
* コンテキスト・リコール**:システムが検索した関連コンテキストの割合を測定します。
* 忠実度**:検索されたコンテキストに基づいて生成されたテキストの精度を測定する。
* 回答の関連性**:生成されたテキストとユーザーのクエリとの関連性を測定する。
* 回答の正しさ**:生成されたテキストの正確さを評価します。
これらのメトリクスは、RAGシステムのパフォーマンスを評価するための包括的なフレームワークを提供します。これらの側面を分析することで、開発者は改善のための領域を特定し、システムが高品質で適切かつ正確な回答を提供できるようにすることができます。
### LlamaIndex: 構築と評価を簡単に
[LlamaIndex](https://zilliz.com/product/integrations/Llamaindex)は、RAG評価ツールを含む、RAGアプリケーションを構築するための堅牢なAIフレームワークです。そのフレームワークの中で構築されたアプリケーションを評価するのに便利です。
python
from llama_index.evaluation import BatchEvalRunner
from llama_index.evaluation import (
FaithfulnessEvaluator、
RelevancyEvaluator、
)
service_context_gpt4 = ...
vector_index = ...
question_list = ...
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4}、
workers=8、
)
eval_results = runner.evaluate_queries(
vector_index.as_query_engine(), queries=question_list
)
TruLens-Eval: 多様なフレームワークの統合評価
TruLens Eval は、LangChain と LlamaIndex でビルドされた RAG アプリケーションを簡単に評価する方法を提供します。以下のコード・スニペットは、LangChain ベースの RAG アプリケーションの評価をセットアップする方法を示しています。
python from trulens_eval import TruChain, Feedback, Tru,Select from trulens_eval.feedback import グラウンデッドネス from trulens_eval.feedback.provider import OpenAI np として numpy をインポート
tru = Tru() rag_chain = ...
プロバイダクラスの初期化
openai = OpenAI()
grounded = Groundedness(groundedness_provider=OpenAI())
グラウンデッドネスフィードバック関数を定義
f_groundedness = ( フィードバック(grounded.groundedness_measure_with_cot_reasons) .on(Select.RecordCalls.first.invoke.rets.context) .on_output() .aggregate(grounded.grounded_statements_aggregator) )
質問と回答の関連性。
f_qa_relevance = Feedback(openai.relevance).on_input_output()
tru_recorder = TruChain(rag_chain、 app_id='Chain1_ChatApplication'、 フィードバック=[f_qa_relevance, f_groundedness])
tru.run_dashboard()
Trulens-Evalは他のフレームワークで構築されたRAGアプリを評価できますが、コードで実装するのは複雑です。詳細は [公式ドキュメント](https://www.trulens.org/getting_started/) を参照してください。
さらに、Trulens-Evalは、評価理由の分析やAPIキーの使用状況を観察するために、ブラウザで視覚的にモニタリングすることもできます。
### Phoenix: LLMを柔軟に評価する
[Phoenix](https://github.com/Arize-ai/phoenix)は、LLMを評価するためのメトリクスの完全なセットを提供します。これには、生成された埋め込みとLLMの応答の品質が含まれます。また、RAGアプリケーションの評価も可能ですが、他の評価ツールよりも少ないメトリクスしか含まれていません。以下のコードスニペットは、LlamaIndexによって構築されたRAGアプリケーションを評価するためにPhoenixを使用する方法を示しています。
python
import phoenix as px
from llama_index import set_global_handler
from phoenix.experimental.evals import llm_classify, OpenAIModel, RAG_RELEVANCY_PROMPT_TEMPLATE, \
rag_relevancy_prompt_rails_map
from phoenix.session.evaluation import get_retrieved_documents
px.launch_app()
set_global_handler("arize_phoenix")
print("phoenix URL", px.active_session().url)
query_engine = ...
question_list = ...
for question in question_list:
response_vector = query_engine.query(question)
retrieved_documents = get_retrieved_documents(px.active_session())
retrieved_documents_relevance = llm_classify(
dataframe=retrieved_documents、
model=OpenAIModel(model_name="gpt-4-1106-preview")、
template=RAG_RELEVANCY_PROMPT_TEMPLATE、
rails=list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values())、
provide_explanation=True、
)
上記のツールとは別に、DeepEval、LangSmith、OpenAI Evalsのような他のプラットフォームもRAGアプリケーションを評価する機能を提供している。これらの方法論は似ていますが、プロンプトの設計と実装の仕様が異なるため、あなたに最適なツールを選ぶようにしてください。
結論として、我々はいくつかの方法論、評価基準、およびRAGアプリケーション評価ツールをレビューした。特に、3つのカテゴリーの評価基準について検討しました:
グランドトゥルースに基づくもの、
グランド・トゥルースを用いないもの
大規模言語モデル(LLM)の応答に基づくもの。
グランド・トゥルース・メトリクスは、RAGの回答を確立された回答と比較する。対照的に、RAG Triadのようなグランドトゥルースのないメトリクスは、クエリ、コンテキスト、レスポンス間の関連性を評価することに重点を置いている。LLMの回答に基づくメトリクスは、親しみやすさ、有害性、簡潔性を考慮する。
私たちはまた、適切に設計されたプロンプトを通して、LLMをメトリクスをスコアリングするために使用することを検討し、Ragas、LlamaIndex、TruLens-Eval、Phoenixを含むRAG評価ツールのセットを紹介した。
急速に変化するAIの世界では、RAGアプリケーションを定期的に評価し、強化することが、その信頼性のために極めて重要である。ここで取り上げた方法論、測定基準、およびツールを使用することで、開発者と企業は RAG システムのパフォーマンスと能力について情報に基づいた決定を下すことができ、AI アプリケーションの進歩を促進することができます。
ゴールドスタンダードデータセットの作成
ゴールドスタンダードデータセットの作成は、RAGシステムの評価において重要なステップである。ゴールドスタンダードデータセットとは、システムの性能を評価するための参考となる例の集合である。データセットは、RAGシステムのドメインに関連する質問、回答、コンテキストのセットを含むべきである。
ゴールドスタンダードデータセットを作成するには、以下の手順に従ってください:
RAGシステムのドメインに関連する質問と回答のセットを特定する。
質問と回答に関連するコンテキストのセットを作成する。
人間の評価者にコンテキストと回答に注釈をつけてもらい、グランドトゥルースデータセットを作成する。
RAGシステムの性能を評価するために、ground truthデータセットを使用する。
このプロセスは、評価が正確で関連性のあるデータに基づいていることを保証し、システムのパフォーマンスを評価するための信頼できるベンチマークを提供します。
RAG 評価のベストプラクティス
RAGシステムを評価するには、いくつかの要素を慎重に考慮する必要がある。以下は、RAG評価のベストプラクティスである:
RAGシステムの性能を評価するためにゴールドスタンダードデータセットを使用する。
システムのパフォーマンスを包括的に理解するために、評価指標を組み合わせて使用する。
異なる評価メトリクス間のトレードオフを考慮し、ユースケースに最も適したものを選択する。
評価指標を定期的に見直し、改善することで、適切かつ効果的な評価指標を維持することができます。
評価プロセスを合理化し、人間の評価者の負担を軽減するために、自動評価ツールを使用する。
これらのベストプラクティスに従うことで、RAGシステムの徹底的かつ効果的な評価を保証し、継続的な改善と最適なパフォーマンスにつなげることができます。
結論
RAGシステムは、チャットボットや質問応答システムを構築するための強力なテクノロジーです。RAGシステムのパフォーマンスを評価することは、その信頼性とパフォーマンスにとって極めて重要です。RAGシステムを理解し、評価指標を使用し、ゴールドスタンダードデータセットを作成し、RAG評価のベストプラクティスに従うことで、RAGシステムが最適に動作し、ユーザーに正確で適切な応答を提供していることを確認できます。
急速に変化するAIの世界では、RAGアプリケーションを定期的に評価し、強化することが、その信頼性のために極めて重要です。ここで取り上げた方法論、測定基準、およびツールを使用することで、開発者と企業はRAGシステムのパフォーマンスと能力について情報に基づいた決定を下すことができ、AIアプリケーションの進歩を促進することができます。

読み続けて

Zilliz Cloud Now Available in Azure North Europe: Bringing AI-Powered Vector Search Closer to European Customers
The addition of the Azure North Europe (Ireland) region further expands our global footprint to better serve our European customers.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.