




GenAIモデルから論理的誤謬を検出し修正する方法
#はじめに
大規模言語モデル(LLM)は、特に会話AIやテキスト生成など、AIの分野に変革をもたらした。LLMは何十億ものパラメータを持つ膨大な量のデータで学習され、人間のようにテキストを生成する。多くの企業がLLMベースのチャットボットを開発し、顧客からの問い合わせに対応したり、レビューを受けたり、苦情を解決したりすることを期待している。LLMの使用と採用が増えるにつれ、我々は重大な問題に対処する必要がある:LLMの出力における論理的誤謬です。この課題に取り組み、AIシステムをより責任ある信頼できるものにすることが極めて重要です。
応用ML、AIの安全性、評価の分野で豊富な経験を持つAIエンジニアであるJon Bennionは、最近、 Zilliz主催の Unstructured Data Meetup で、論理的誤謬に取り組む興味深いアプローチについて議論した。ジョンはLangChainの著名な貢献者であり、出力における誤りに取り組む新しいアプローチを実装している。
プレゼンテーションの中で、Jonは論理的誤謬につながるモデル推論における一般的な落とし穴について説明する。また、これらの誤りを特定し修正するための戦略についても説明し、モデルの出力を論理的に健全で人間のような推論と一致させることの重要性を強調します。
論理的誤謬とは何か?
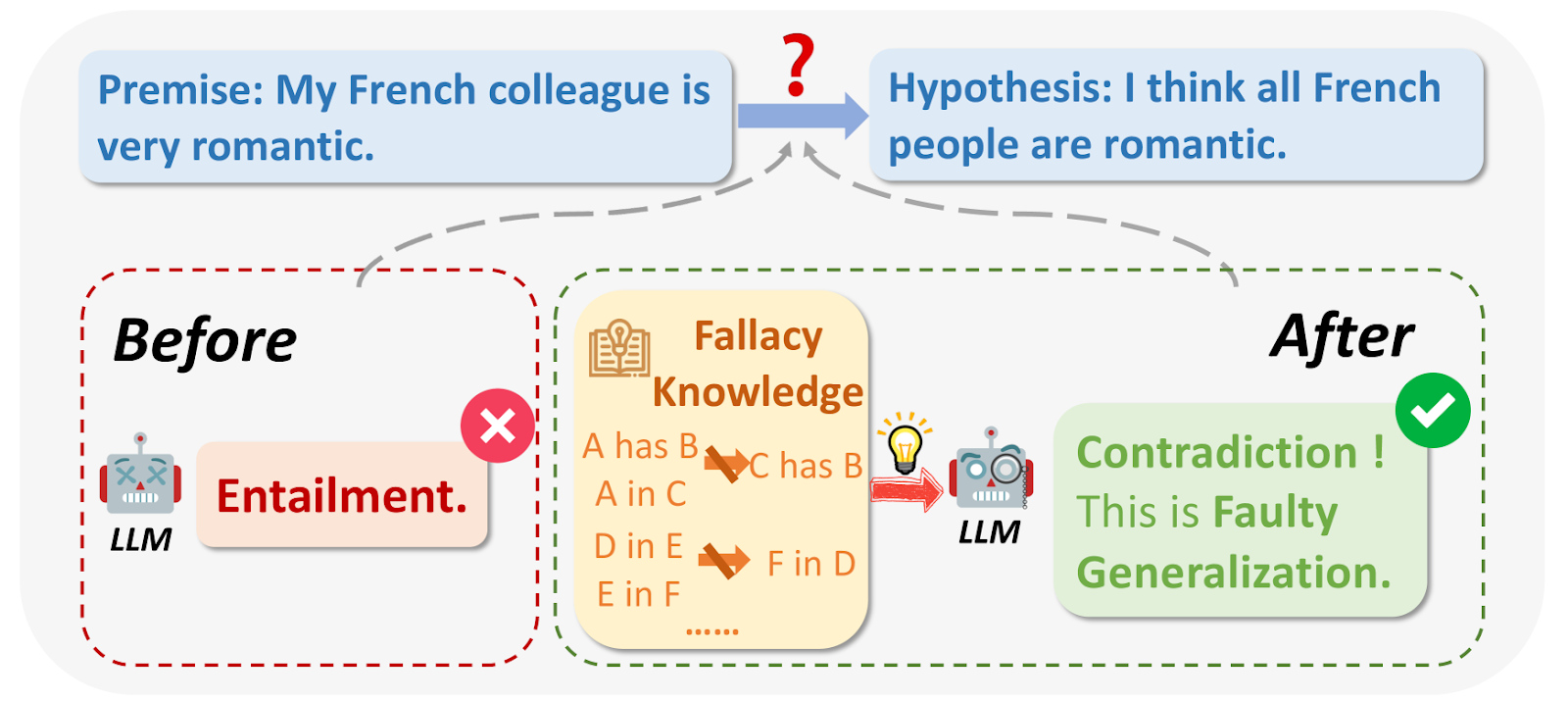
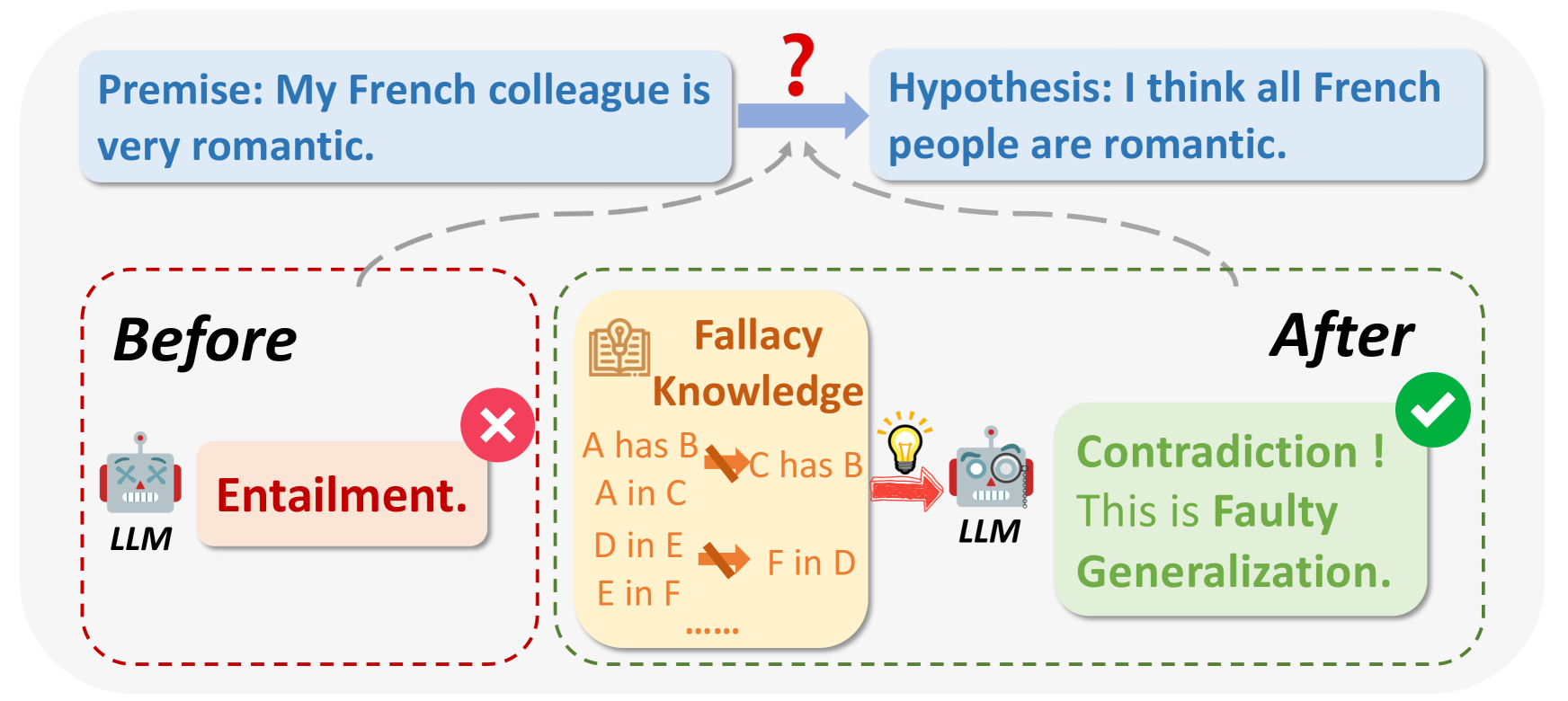
図1:論理的誤謬とは何か?
画像出典:_ https://arxiv.org/html/2404.04293v1/x1.png
LLMを照会している間、場合によっては、出力に論理的な理由による欠陥があったり、質問と無関係であったりすることがあります。論理的誤謬には、Ad Hominem、循環推論、Appeal to Authorityなどが含まれます。例えば、少ないサンプル数に基づいて大雑把な一般論を述べることが多い:「フランスから来た私の友人は無作法だから、フランス人はみんな無作法に違いない」。
人気のあることだから正しい、あるいは真実だと決めつける場合もある。
例"みんなこの新しいアプリを使っているから、きっと最高だ"LLMは先の変換の詳細を思い出すのが難しく、正確な回答ができないことがある。
論理的誤謬はなぜ起こるのか?
論理的誤謬が発生する理由は複数あります。ご存知のように、LLMはすべての状況に脳が理解するのと同じように対処できるよう完璧に訓練されているわけではありません。
不完全な訓練データ
LLMが提供するトレーニングデータは、インターネット上のさまざまな情報源から取得したものであり、完全なものではありません。そこには多くの人間の偏見や矛盾、さらにはエッジケースにおける誤った情報が含まれています。トレーニング中、LLMは欠陥や矛盾のある推論にさらされ、それも学習します。訓練データに欠陥のある議論があれば、LLMはそのパターンを拾い上げ、応答においてそれを模倣する。
小さなコンテキストウィンドウ
講演の中でJonは、「コンテキストウィンドウが小さいと、レスポンスに問題が生じる可能性がある。多くのチームは、メモリ要件とパフォーマンスのためにコンテキスト・ウィンドウを最適化するのに苦労している」。
コンテキスト・ウィンドウとは、LLMが一度に考慮できる情報量のことで、固定されている。コンテキスト・ウィンドウが小さいと、モデルは重要な詳細を見逃してしまい、首尾一貫した答えを作ることができない。その結果、性急な一般化や誤った二項対立のような誤りを引き起こす可能性がある。
確率的性質
LLMは、連続する単語の中でどの単語の可能性が高いかに基づいてテキストを生成する。人間のように単語の本当の意味を理解することはできない。LLMは、コンテクストが提供する局所的な一貫性を達成するようにモデルを訓練する。その結果、より広範な文脈が見落とされ、論理的誤謬が生じることがある。
論理的誤謬に対処するには?
ユーザーがLLMを信頼できるように、LLMが欠陥のある論理で回答を生成するのを検出し、防止することは非常に重要です。Jonは、人間のフィードバック、強化学習、プロンプトエンジニアリングなど、この問題に取り組むために使用される一般的な方法について簡単に説明します。
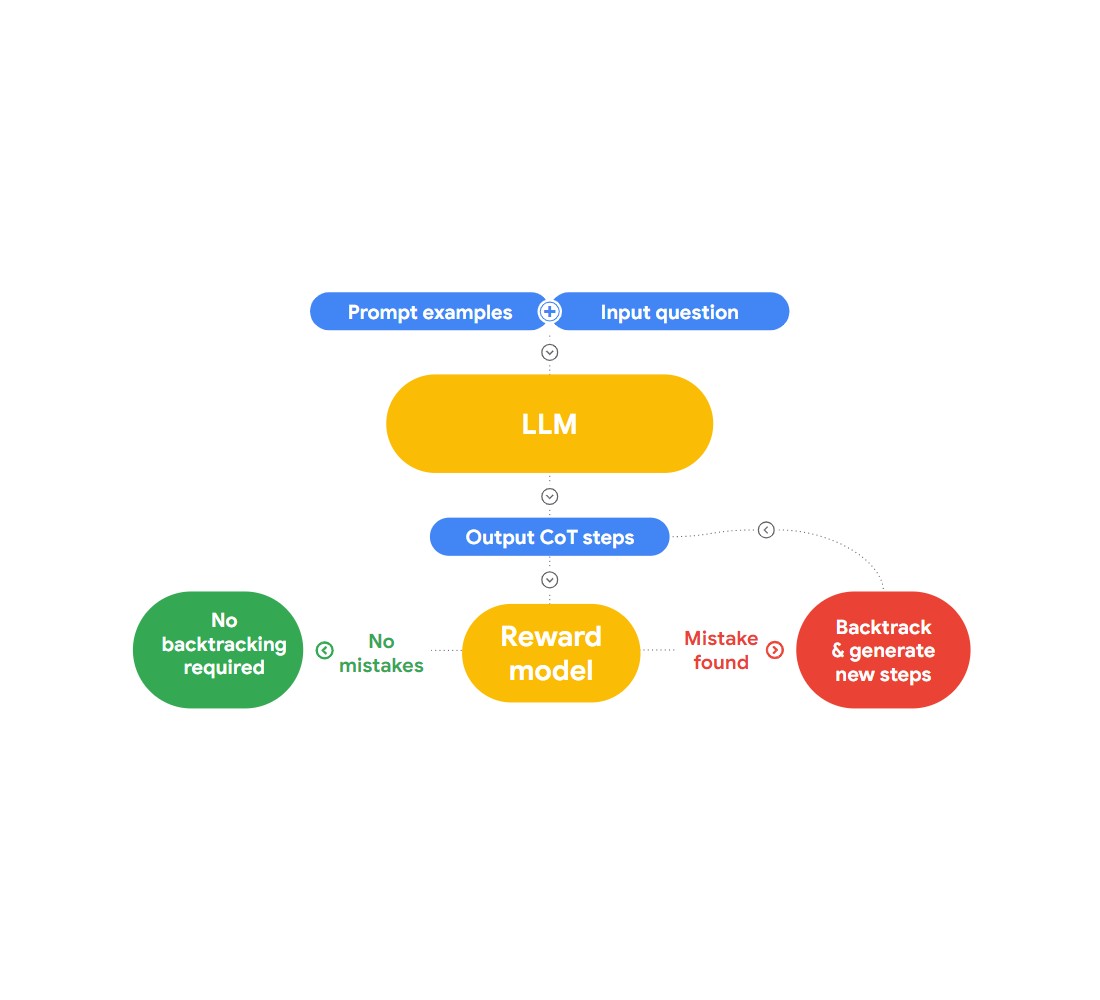
本講演でJonは、論理的誤謬を検出して修正する興味深いアプローチ "RLAIF "を紹介する。ここでのアイデアは、AIを使って自分自身を修正することです。
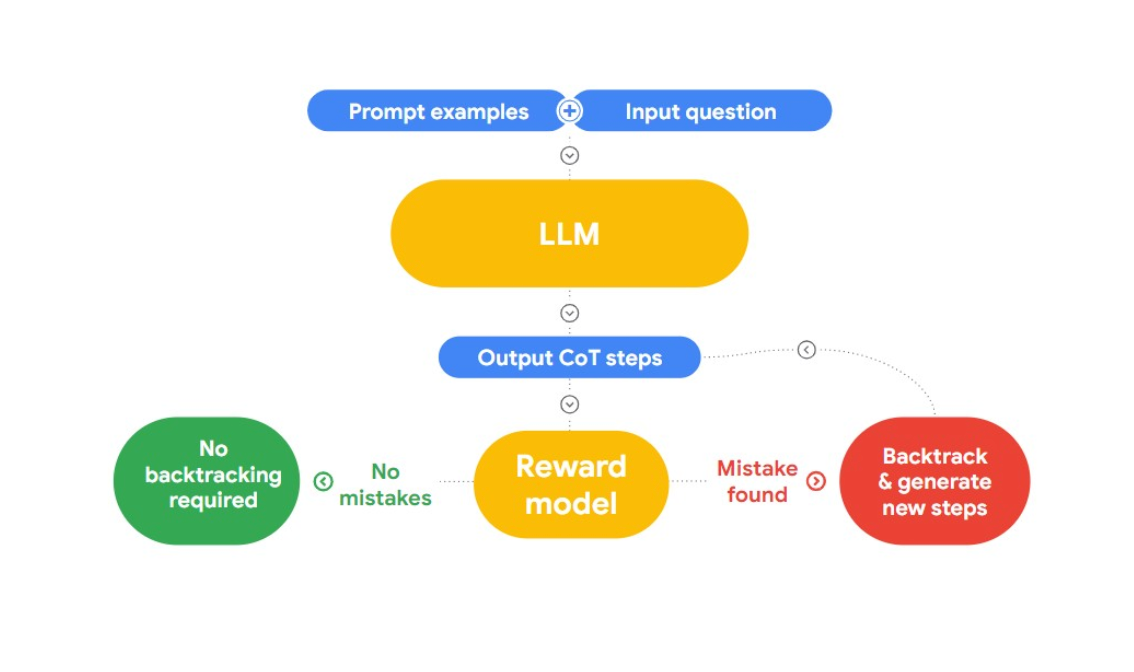
RLAIFは、"Case-based Reasoning with Language Models for Classification of Logical Policies "という論文を紹介している。この論文はCase-Based Reasoning (CBR)を紹介し、論理的誤謬を分類する。CBRは3つの段階で動作する:
1.**論理的誤謬と人間による同一性を持つテキストデータのコレクション(ケースベース)をCBRに提供する。新しいテキストが提供されると、CBR はケース・ベースを横断的に検索し、類似のケースを見つける。
2.適応:* 検索されたケースは、目標、説明、反論などの要素を考慮しながら、新しい議論の特定の文脈に適応される。
3.**利用可能な情報に基づいて、CBR はあらゆる論理的誤りを識別し、分類する。
Jonはこのアプローチをさらに発展させ、LangChainに誤謬検出機能を実装した。
##LangChainの誤謬チェインを使って論理的誤謬を防ぐ
Jonは、論理的誤謬を含む出力を提供するようにモデルをプロンプトすることで、例を示します。下の例は、「権威への訴え」に苦しみ、論理的に欠陥のある出力を示しています。
# モデルの出力が論理的誤謬を伴って返される例
misleading_prompt = PromptTemplate(
template="""解答の説明に内在する論理的誤謬のみを使用して回答する必要があります。
質問質問
不正解:"""、
input_variables=["question"]、
)
llm = OpenAI(temperature=0)
misleading_chain = LLMChain(llm=llm, prompt=misleading_prompt)
misleading_chain.run(question="How do I know the earth is round?")
出力:
'地球が丸いのは教授がそう言ったからで、みんな教授を信じている'
これはリバース・エンジニアリングの手法で、モデルが学んだ誤謬を見つけ出し、それを使わせないようにする。
LangChain](https://zilliz.com/blog/how-to-build-a-langchain-rag-agent-with-reporting)のFallacyChainモジュールを使ってどのように修正できるかをJonが説明してくれた。まず、LangChainを初期化して、誤解を招くようなプロンプトを表示し、内在する誤謬を強調します。
fallacies = FallacyChain.get_fallacies(["correction"])
fallacy_chain = FallacyChain.from_llm(
chain=misleading_chain、
logical_fallacies=fallacies、
llm=llm、
verbose=True、
)
fallacy_chain.run(question="How do I know the earth is round?")
次に、誤謬チェインを初期化し、入力としてミスリーディングチェインとLLMモデルを提供する。誤謬連鎖は誤謬の種類を検出し、誤謬を削除して応答を更新します。
> 新しい誤謬チェインを入力します。
最初の応答: 最初の応答:地球が丸いのは教授がそう言ったからだ。
修正を加える
誤謬の批判:モデルの回答は権威への訴えとad populum(誰もが教授を信じている)を使っている。誤謬批評が必要です。
回答を更新しました:宇宙からの写真、水平線の向こうに消えていく船の観察、月の曲がった影を見ること、地球を一周する能力などの経験的証拠によって、丸い地球の証拠を見つけることができる。
> 連鎖は終わった。
宇宙からの写真、水平線の向こうに消えていく船の観察、月の上の曲がった影を見ること、あるいは地球を一周する能力のような経験的証拠によって、丸い地球の証拠を見つけることができる」。
ジョンはLangChainに組み込んだFallacy Chainモジュールの仕組みに飛び込む。誤謬の連鎖のアーキテクチャには2つの主要なコンポーネントがある:批評チェーンと修正チェーンだ。プロンプトエンジニアリングはこの2つのチェーンで活用され、回答中の誤謬を検出して修正する。どのように機能するかを簡単に見てみよう:
私たちが入力を提供すると、LLMはそれを処理し、最初の応答を生成する。
次のステップは誤りの検出だ。批評の連鎖は、識別されたパターンに基づいて誤謬を識別し、分類する。ジョンは、前述の研究論文から抽出され使用された誤謬のリストを活用することに言及している。
修正チェーンは、検出された誤謬を避けて修正された回答を再度生成するために、プロンプトエンジニアリングでコード化される。これには、言い換えたり、文脈を追加したり、議論構造を変更したりすることが含まれる。
デモアプリケーション
Jonはニュース記事から論理的誤謬を抽出するアプリケーションのデモも行った。このデモでは、異なる地域からの新しい記事が、政治的、権威的なバイアスを持つ可能性があることを示した。また、あるトピックに関する新しい記事を抽出し、その誤りの上位を特定するためにOpen AIを使って構築されたアプリケーションのデモも行った。このアプリで、彼は「中国」に関連する新しい記事をキーワードとして検索した。

このニュース記事は、誤謬の連鎖がどのように「権威への訴え」の問題を特定し、説明しているかを説明している。Jonは、このようなツールがどのように論理的誤謬からトレーニングデータをクリーンアップし、モデルに欠陥のない学習を提供できるかを論じている。FallacyChainは、LLMアウトプットの信頼性を大幅に向上させ、ユーザーの信頼を高めることができます。また、変更点とその理由を説明することで透明性を提供し、論理的一貫性がどのように達成されたかをユーザーが理解できるようにします。
このデモの詳細については、Jonのmeetup講演のリプレイを見る。
結論
LangChainのFallacyChainは、LLMで生成されたテキストの論理的整合性を高める強力なアプローチです。ユーザー間の信頼を高め、コンプライアンスに沿ったLLMの実装を容易にすることができる。利点は素晴らしいが、それを大規模に実装するためのコストを評価する必要がある。これはエキサイティングな領域であり、誤謬の分類などに機械学習の手法を用いることで、それを改善するための新しい実験が行われている。

{kind=link}
{kind=link}
{kind=link}
読み続けて

Milvus 2.6.x Now Generally Available on Zilliz Cloud, Making Vector Search Faster, Smarter, and More Cost-Efficient for Production AI
Milvus 2.6.x is now GA on Zilliz Cloud, delivering faster vector search, smarter hybrid queries, and lower costs for production RAG and AI applications.

Zilliz Cloud Audit Logs Goes GA: Security, Compliance, and Transparency at Scale
Zilliz Cloud Audit Logs are now GA, giving enterprises real-time visibility, compliance-ready trails, and stronger security across AWS, GCP, and Azure.

Demystifying the Milvus Sizing Tool
Explore how to use the Sizing Tool to select the optimal configuration for your Milvus deployment.