




Milvus、Qwen、vLLMによるRAGアプリケーションの構築
#はじめに
2023年8月、アリババグループは、多言語の流暢さ、高度な推論能力、高効率を兼ね備えた、Qwenと呼ばれる最先端のオープンソースモデルファミリーをリリースした。Qwenは、自然言語理解、視覚・音声機能、数学的問題解決、コード生成など、多様なアプリケーションに最適化されたスケーラブルなトランスフォーマーベースのアーキテクチャを導入している。この一連のデコーダのみの大規模言語モデル(LLMs)は、RAG(Retrieval Augmented Generation)システムを構築するための強力な可能性を解き放ち、現在の競争の激しいオープンソースエコシステムに革新的な機能を導入します。
LLMはCPUや専用の推論エンドポイントで実行することができるが、vLLMのようなツールは、効率的な大規模モデル展開のための特別なソリューションを提供する。vLLMは、変換器ベースのモデルの推論プロセス、特にQwenのような大規模モデルの推論プロセスを最適化するために設計されたオープンソースライブラリです。vLLM は、最先端のメモリ最適化技術と並列化技術を活用することで、大規模モデルのパフォーマンスを向上させ、実稼働環境においてより利用しやすくスケーラブルなものにします。QwenとvLLMを統合することで、複雑なモデルのシームレスかつ効率的な展開が可能になり、さまざまな業界のリアルタイムアプリケーションにおけるLLMの活用が促進されます。
このブログでは、QwenとvLLM、そして両者をMilvusベクターデータベースと組み合わせることで、どのように堅牢なRAGシステムを構築できるかについて説明します。これら3つの技術は、検索ベースと生成アプローチの長所を組み合わせ、複雑なクエリにリアルタイムで対応できるシステムを構築する。Milvusは、大規模なembeddingsを効率的に管理・照会することでシステムを強化し、Qwenの高度な言語機能は応答の基盤を提供する。vLLMがデプロイを最適化することで、この統合は幅広いAI駆動型アプリケーションに高性能なソリューションを提供します。
Qwen シリーズモデル概要
アリババグループは最初のテクニカルレポートで、Qwenという名前は中国語で「何千ものプロンプト」を意味する「Qianwen」に由来すると説明した。Qwenモデルは、最大3兆トークンの多言語テキストとコードを使用して、教師ありファインチューニング(SFT)やヒューマンフィードバックからの強化学習(RLHF)などの高度なファインチューニング技術を組み込んでトレーニングされました。
図1- Qwenシリーズの系譜](https://assets.zilliz.com/Figure_1_Model_Lineage_of_the_Qwen_Series_878d8add15.png)
図1: Qwenシリーズのモデル系統(Source)_。
ベースとなるQwenモデルには、18億から720億パラメータまでの4つのサイズがある。これらのモデルには、数学やコーディングなどのタスクに特化したバージョンもある。最初のリリース以来、Qwen のモデルは進化を続け、モデルサイズ、パフォーマンス、言語機能、コンテキストの長さが改善されてきました。現在、Qwen のモデルは以下のように分類されています:
最初のリリース:Qwen 1.8B、7B、14B、72B
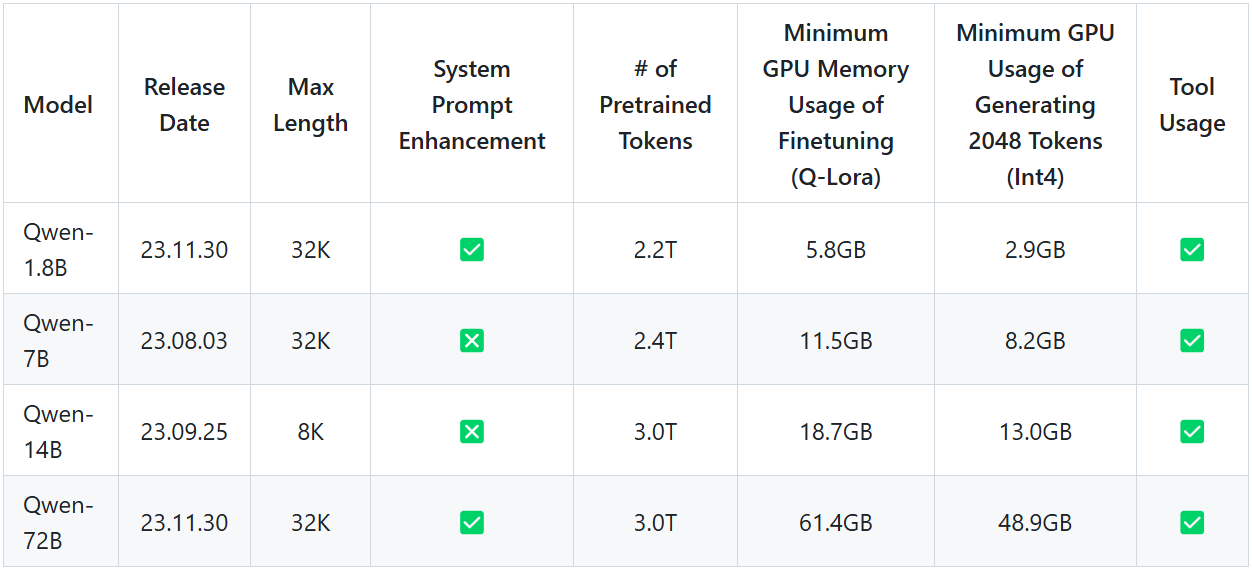 図2- Qwenファーストリリース.png
図2- Qwenファーストリリース.png
図2:Qwen First Releases (Source)_。
Qwenビジョンモデルシリーズ
Qwen Vision Modelは当初2つのバージョンでリリースされた:Qwen-VL と Qwen-VL-Chat です。これらのモデルは、文書読解、数学的推論、視覚的質問応答などの視覚ベースのタスクを処理するように設計されています。その後、Qwen-VLおよびQwen2-VLバージョンにアップグレードされ、最新のバージョンは、様々なビジョンベンチマークにおいて、GoogleのGeminiやOpenAIのGPTのようなモデルを凌ぐ、大幅な性能向上を実現しています:
Qwen-VL**:Qwen-VL-PlusとQwen-VL-Max。
Qwen2-VL**:Qwen2-VL-2B、Qwen2-VL-7B、Qwen2-VL-72B。
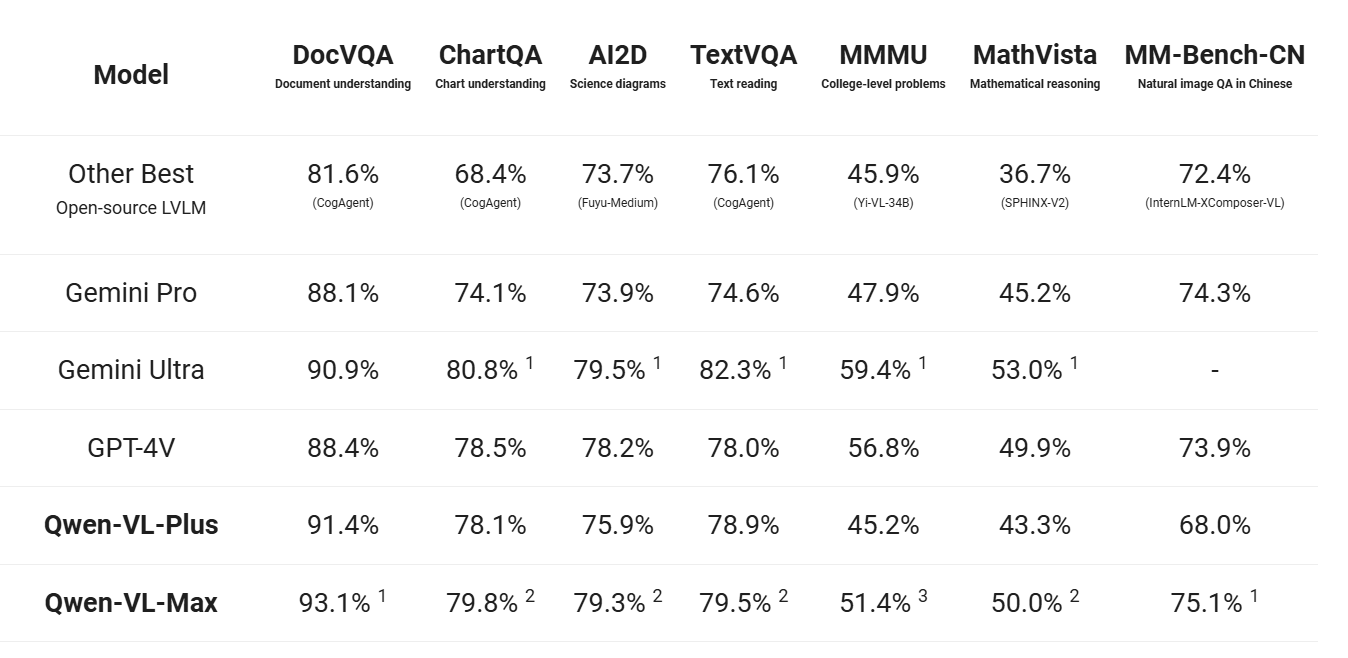 図 3- Qwen-VL ベンチマーク比較.png
図 3- Qwen-VL ベンチマーク比較.png
図3:Qwen-VLベンチマーク比較(Source)_。
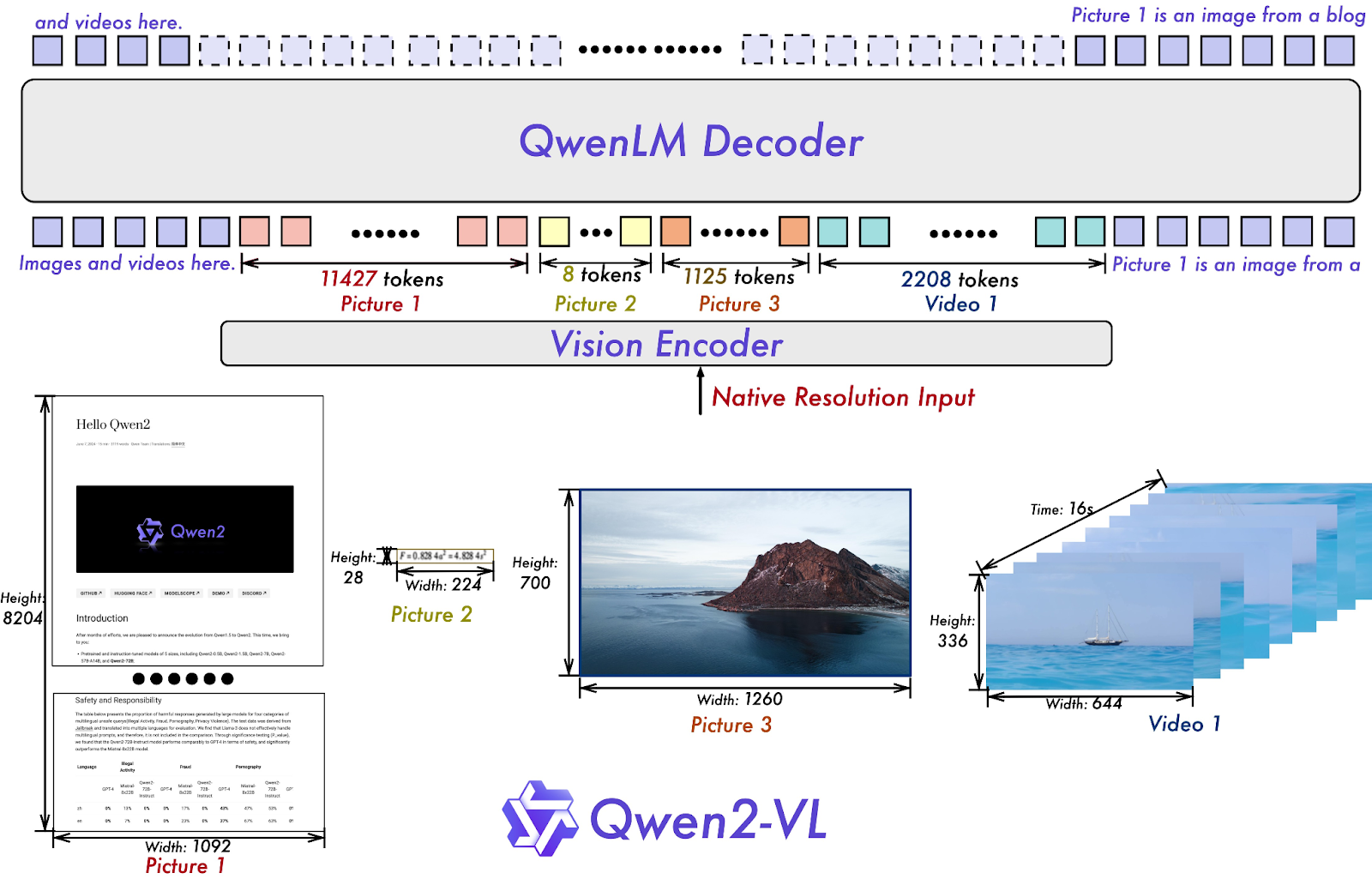 図 4- Qwen2-VL アーキテクチャ.png
図 4- Qwen2-VL アーキテクチャ.png
図 4: Qwen2-VL アーキテクチャ (Source)_ !
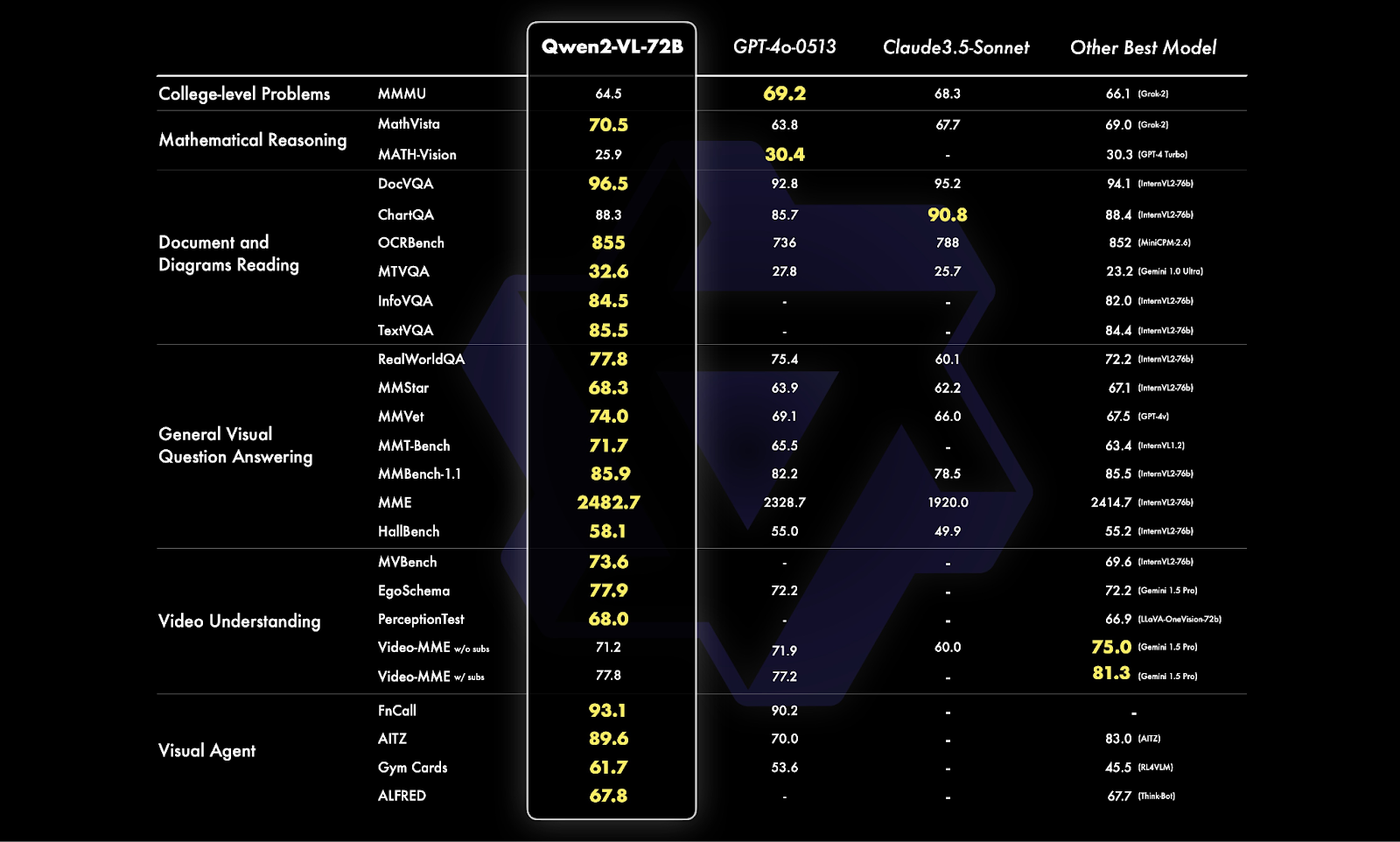 図 5- Qwen2-VL-72B ベンチマーク比較.png
図 5- Qwen2-VL-72B ベンチマーク比較.png
図5:Qwen2-VL-72Bベンチマーク比較(Source)_。
Qwen オーディオシリーズ
ビジョンモデルと同様に、Qwen Audio シリーズも当初は 2 つのバージョンがリリースされた:Qwen-Audio (マルチタスクの音声言語モデル) と Qwen-Audio-Chat (インストラクション付きの 微調整版) です。これらのモデルは、音声入力とテキスト入力の両方を扱い、テキストベースの出力を生成するように設計されていました。Qwen2 シリーズの登場により、両モデルはさらに強化されました:
- Qwen2-Audio-7B** と Qwen2-Audio-7B-Instruct です:Qwen2-Audio-7BとQwen2-Audio-7B-Instruct**は、音声入力とテキスト入力の両方に対応し、テキスト出力を生成することで、音声認識、テープ起こし、音声ベースのAIアシスタントなどのアプリケーションの多言語対応能力を向上させます。
図6- Qwen-Audioアーキテクチャ](https://assets.zilliz.com/Figure_6_Qwen_Audio_Architecture_c6be483d37.png)
図6:Qwen-Audioアーキテクチャ(Source)_。
図7- Qwen2-オーディオアーキテクチャ](https://assets.zilliz.com/Figure_7_Qwen2_Audio_Architecture_20d502d4bb.png)
図7:Qwen2-Audioアーキテクチャ(Source)_。
Qwen 2.5 シリーズ
Qwen 2.5シリーズは、オリジナルのQwenモデルの基礎の上に、2つの重要なアップグレードを施したものです:Qwen 1.5** と Qwen 2 です。これらのシリーズは、Qwen ファミリーの機能をさらに拡張するために設計された特別なモデルを導入し、数学、コーディング、一般的な言語理解など、さまざまな領域にわたって高度な機能拡張を提供します。特筆すべきは、Qwen 1.5 のリリースには **Mixture of Experts (MoE) ** バージョンも含まれており、モデル群に多様性とパフォーマンスの向上が加えられていることです。これらの開発により、Qwen 2.5 シリーズは、広範な適用性を保ちつつ、特殊なタスクに高度に適応できるようになりました。
Qwen 2.5モデルには、0.5B、1.5B、3B、7B、14B、32B、72Bといったさまざまなサイズがあり、さまざまなユースケースに柔軟に対応します:
Qwen 2.5-Math**:このモデルは、複雑な数学問題を解くために特別に設計されています。基本的な算数から高度な微積分まで、さまざまな分野で正確な解答を提供します。このシリーズには、さまざまなサイズのモデルがあります:また、Qwen 2.5-Math-RM-72B は、数学的な課題をより正確に解くために数学的報酬モデルを最適化した特別バージョンです。
Qwen 2.5-Coder:Qwen 2.5-Coder: Qwen 2.5-Coder は、コード生成とデバッグ用に微調整されたモデルで、スクリプト作成、コード補完、コードレビューなどのプログラミング作業の自動化に最適です。このモデルには、0.5B、1.5B、3B、7B、14B、32Bのサイズがあり、幅広いコーディングアプリケーションに取り組む開発者に柔軟性を提供します。
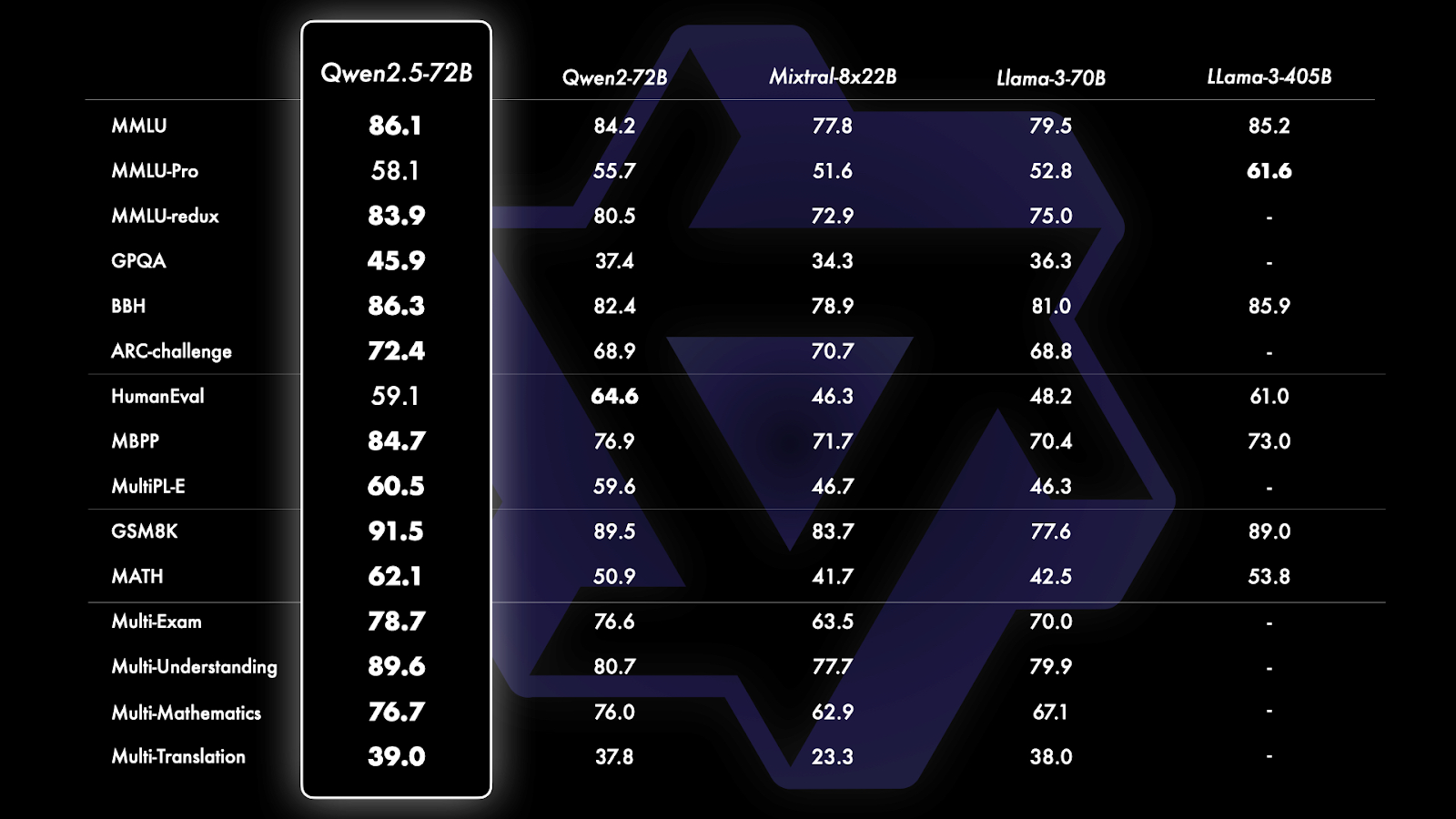 図 8- Qwen 2-5 ベンチマーク比較.png
図 8- Qwen 2-5 ベンチマーク比較.png
図8:Qwen 2-5のベンチマーク比較(Source)_。
図9- Qwen 2-5-コーダーのベンチマーク比較](https://assets.zilliz.com/Figure_9_Qwen_2_5_Coder_Benchmark_Comparison_952b75c92d.png)
図9:Qwen 2-5-コーダーのベンチマーク比較(Source)_。
図10- Qwen 2-5-数学ベンチマーク.png](https://assets.zilliz.com/Figure_10_Qwen_2_5_Math_Benchmark_461b217298.png)
図 10: Qwen 2-5-Math Benchmark (Source)_。
QwQ シリーズ
QwQシリーズは、現在実験的研究モデルであり、高度なAI推論への大胆な飛躍を表しています。このモデルは思慮深い生徒のように行動し、好奇心を体現し、洞察を提供する前に自らの考察を問う。数学、コーディング、推論における複雑な問題の解決に焦点を当て、最初のリリースであるQwQ-32B-Preview,**は、GPQA、AIME、MATH-500などのベンチマークで卓越したパフォーマンスを示しています。
図 11- QwQ ベンチマーク比較](https://assets.zilliz.com/Figure_11_Qw_Q_Benchmark_Comparison_cba4774f40.png)
図11:QwQベンチマーク比較(Source)_。
vLLM: ラージモデル推論の最適化
vLLM(Virtual Large Language Model)は、大規模な言語モデルの推論を最適化するために設計されたオープンソースライブラリであり、変換器ベースのアーキテクチャを大規模に展開する際の重要な課題に対処します。vLLMは、PagedAttention、テンソル並列処理、効率的なキャッシュ戦略などの革新的な手法により、推論時の計算オーバーヘッドとメモリ使用量の大幅な削減を実現しています。これらの最適化により、より大規模で複雑なモデルをより高い効率で展開することが可能になり、最先端のAIシステムの実行に必要なコストと労力を削減することができます。
図12- vLLMシステム概要.png](https://assets.zilliz.com/Figure_12_v_LLM_System_Overview_1e04fa1050.png)
図12: vLLMシステムの概要 (Source)_
主要機能とイノベーション
PagedAttention
vLLMの目玉機能であるPagedAttentionは、オペレーティングシステムのメモリ管理の原則を採用することで、GPUメモリ管理に革命をもたらします。このアプローチにより、推論中にメモリの動的な割り当てとページングが可能になり、スループットが大幅に向上し、レイテンシが短縮されます。GPUリソースを効率的に管理することで、PagedAttentionは大規模なハードウェアリソースを必要とすることなく、より大きなモデルの使用を容易にし、AIアプリケーションのスケーリングに実用的な選択肢となります。
**テンソルの並列処理とキャッシング
PagedAttentionに加え、vLLMは複数のGPUにワークロードを効果的に分散させる高度なテンソル並列処理を採用しています。また、冗長な計算を最小化する効率的なキャッシングメカニズムを組み込み、推論中のモデルパフォーマンスをさらに向上させます。これらの技術により、vLLMはトランスフォーマーモデルの高速でコスト効率の高い推論を実現します。
アプリケーション
vLLM は、多様なドメインにおける大規模な言語モデルのリアルタイム展開をサ ポートします:
自然言語処理 (NLP)](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing):** テキスト要約、感情分析、名前付きエンティティ認識などのタスク。
会話AI:** リアルタイムのチャットボットシステムやバーチャルアシスタント。
検索拡張生成(RAG): 高度な質問応答や知識検索タスクのための検索システムと大規模モデルの統合。
Milvus, vLLM, QwenによるRAGアプリケーション
このチュートリアルでは、ベクトルデータベースとしてMilvusを、言語モデルとしてQwenを、最適化された推論のためにvLLMを、フレームワークとしてLangChainを使用して、RAGパイプラインを実装する方法を示します。このチュートリアルの全コードは以下のnotebookにあります。
ステップ1:環境の設定
vLLMを効率的に使うには、GPUが必要です。以下のノートブックはA100 GPUを使ってGoogle Colabで実行した。また、エンベッディングの生成にはOpenAIのAPI Keyが必要です。
ステップ2:データのロード
ナレッジベースのソースとして、Qwenモデルに関するいくつかのブログをロードし、LangChainのRecursiveCharacterTextSplitterメソッドでチャンクに分割します。
# ドキュメントを読み込む
loader = WebBaseLoader(
web_paths=(
"https://qwenlm.github.io/blog/qwq-32b-preview/"、
"https://qwenlm.github.io/blog/qwen2.5/"、
"https://qwenlm.github.io/blog/qwen2.5-coder-family/"、
)
)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
docs = text_splitter.split_documents(documents)
ステップ3:Milvus Retrieverの作成
次に、Milvusリトリーバをテキストコンテンツとメタデータで設定し、効率的な検索を行います。
# Milvusレトリバーを設定する
embeddings = OpenAIEmbeddings()
vectorstore = Milvus.from_documents(
documents=docs、
embedding=embeddings、
connection_args={
"uri":"./milvus_demo.db"、
},
text_field="page_content"、
metadata_field="metadata"、
drop_old=True、
)
retriever = vectorstore.as_retriever(
search_type="similarity"、
search_kwargs={"k":4})
ステップ4:LLMエンジンの初期化
vLLMエンジンは、特定のモデル(この場合は "Qwen/Qwen2.5-1.5B")をロードするために効率的に初期化する必要があります。最適化された GPU メモリ使用率(80%)、効率的な計算のための bfloat16 などの構成により、メモリ不足を確実にし、最大 500 トークンを生成するための迅速でリソースを意識したオペレーションを実現します。
# vLLMの初期化
llm = VLLM(
model="Qwen/Qwen2.5-1.5B",
max_new_tokens=500、
enforce_eager=True、
dtype="bfloat16"、
gpu_memory_utilization=0.8)
ステップ5:RAGパイプラインの実装
次に、コンテキストと質問を取り込むために、Qwenモデル、Milvusレトリバー、プロンプトテンプレートでRAGパイプラインを構築します。さらに、レスポンスだけでなく、ソースコンテキストも視覚化するために、レスポンスの表示機能を追加します。
# QAチェーンを設定する
テンプレート = ""
あなたは質問応答タスクのアシスタントです。
質問に答えるために、検索されたコンテキストの以下の部分を使用してください。
質問に答えます。
答えがわからない場合は、わからないと言ってください。
英語での回答をお願いします。
質問質問
文脈{文脈}
答え
"""
prompt = PromptTemplate.from_template(template)
qa_chain = RetrievalQA.from_chain_type(
llm、
retriever=retriever、
chain_type_kwargs={"prompt": prompt }、
return_source_documents=True
)
# レスポンスの詳細を印刷する
def display_response_details(response):
print("Query:", response["query"])
print("Result:", response["result"])
# 最初のソースドキュメントからメタデータを抽出する
source_doc = response["source_documents"][0].metadata
print("Source:", source_doc["source"])
print("Description:", source_doc["description"])
print("Title:", source_doc["title"])
# 質問を設定する
question = "QwQモデルについて教えてください"
# クエリを初期化する
レスポンス = qa_chain.invoke({"query": question, "context": retriever})
出力する:
クエリーQwQモデルについて教えてください。
結果 QwQモデル(Qwen with Questions)は、深く考え、質問し、理解することができることを示している。それはまるで、答えを出す前に常に疑問に思い、注意深く考える学生のようだ。新しいことを学ぶのと同じように、Qwenは自分が何も知らないことを知り、より深く学ぶために質問をし続ける。また、限界もあり、もっと学ぶ必要がある。皆と同じように、常に成長し、向上しているのだ。
出典:https://qwenlm.github.io/blog/qwq-32b-preview/
説明github 抱きつき顔 モデルスコープ デモ discord
注:QwQ: /kwju:/ の発音。
考えること、疑問を持つこと、理解することとはどういうことか?これらはQwQ(Qwen with Questions)が渉猟する深い水域である。QwQは知恵を学ぶ永遠の学生のように、数学であれ、コードであれ、私たちの世界に関する知識であれ、あらゆる問題に純粋な驚きと疑問をもって取り組みます。QwQは古代の哲学的精神を体現している。何も知らないことを知り、それこそが好奇心の原動力なのだ。
タイトルQwQ:未知の境界を深く考える|クウェン
他のモデルに関する2つ目の質問も加えることができる。どちらの場合も回答は詳細かつ正確であり、MilvusとQwen、そして1秒未満で回答を提供したvLLMの両方が高いパフォーマンスを示していることがわかる。
# 質問を設定する
question = "Qwen2.5 オープンソースモデルについて教えてください:Qwen2.5、Qwen2.5-Coder、Qwen2.5-Math について教えてください。"
# クエリを初期化する
レスポンス = qa_chain.invoke({"query": question, "context": retriever})
出力します:
クエリーQwen2.5 オープンソースモデルについて教えてください:Qwen2.5、Qwen2.5-Coder、Qwen2.5-Math について教えてください。
結果 Qwen2.5モデル、すなわちQwen2.5、Qwen2.5-Coder、Qwen2.5-Mathは、以前のモデルと比較して、さまざまな面で大幅な改良が加えられています。以下はその主な要点である:
1.**学業成績
- Qwen2.5 は、複数の一般的なコード生成ベンチマーク(EvalPlus、LiveCodeBench、 BigCodeBench)において、オープンソースモデルの中で最高のパフォーマンスを達成しました。
- また、Qwen2.5 は指示評価タスクでも高得点を獲得し、人間のような指示追従能力との強い整合性を示しました。
- Qwen2.5は、GPT-4oと競合する性能を発揮し、前世代のGPT-4oよりも優れていることを示しました。
2.**実用例
- Qwen2.5 は、様々なプログラミング言語への対応に優れており、その適応性と汎用性を示 しています。
- Qwen2.5モデルは、より複雑な推論タスクを処理するために、そのスキルを拡張する大幅な機能強化が行われました。
3.**モデルトレーニング
- Qwen2.5 は、Qwen2.5-Coder、Qwen2.5-Math とともに、18 兆トークンをカバーする大規模デー タセットでトレーニングされています。これにはコード関連データも含まれ、小規模なコーディングモデルでも、より大規模で包括的なモデルに匹敵する性能を発揮することができます。
4.**モデルサポート
- すべての Qwen2.5 モデルは、幅広いプログラミング言語をサポートし、ユーザーにアクセシビリティと適用性を提供します。
5.**一般的な機能
- Qwen2.5モデルは、コード修復やコード記述などの推論や生成タスクにおいて、強化されたパフォーマン スを発揮します。
6.**専門モデル:** Qwen2.5-Coder は、コーディングに特化しています。
- Qwen2.5-Coder はコーディングタスクに特化し、コーディング生成、修復、推論機能において、より 優れたパフォーマンスを提供します。
- Qwen2.5-Math は、基盤モデルである Qwen2-Math を改良し、中国語のサポートを拡張し、Chain-of-Thought (CoT)、Program-of-Thought (PoT)、Tool-Integrated Reasoning (TIR)などの高度な推論手法を組み込んでいます。
7.**モデルのライセンス:***。
- すべてのオープンソースモデルは Apache 2.0 の下でライセンスされており、異なる開発環境間での互換性と使いやすさを保証しています。
これらの機能強化は総体的に、より広範な機能と改善された性能を持つ、強力で多目的なインテリジェント・プログラミング・アシスタントの開発に貢献します。
ソース:https://qwenlm.github.io/blog/qwen2.5/
説明github抱きつき顔モデルスコープデモDiscord
はじめに Qwen2のリリースから3ヶ月の間に、多くの開発者がQwen2の言語モデルで新しいモデルを構築し、貴重なフィードバックを提供してくれました。この間、私たちはより賢く、より知識の豊富な言語モデルの作成に注力してきました。本日、Qwen ファミリーの最新版をご紹介できることを嬉しく思います:Qwen2.5です。史上最大のオープンソースリリースとなるかもしれません!
タイトルQwen2.5: ファウンデーション・モデルの宴!| Qwen
結論
今回の探索で紹介した技術革新、特にvLLMにおけるPagedAttentionの統合とMilvusの効率的なベクトル管理は、大規模な言語モデルを実用的かつ利用しやすくするためのインフラの重要性を浮き彫りにしている。これらの技術は、メモリ最適化、推論速度、スケーラブルな知識検索など、モデル展開における重要な課題に対処している。これらの技術的ボトルネックを解決することで、開発者や組織は、以前は複雑でリソース集約的であった洗練されたRAG(Retrieval-Augmented Generation) システムを実装できるようになり、ヘルスケア、教育、ソフトウェア開発、科学研究などの業界にわたるAI駆動型アプリケーションに新たなフロンティアを開くことができる。
関連リソース
LangChain、Milvus、StrapiでRAGを構築する】(https://zilliz.com/blog/build-rag-with-langchain-milvus-and-strapi)
MilvusとDatabricks DBRXでRAGを構築する ](https://zilliz.com/blog/build-rag-with-milvus-and-databricks-dbrx)
この無料計算機でRAGパイプラインの構築コストを素早く見積もる](https://zilliz.com/rag-cost-estimator/)
MilvusとFriendli AIで高度なRAGとマルチモーダルクエリーを構築する ](https://zilliz.com/blog/leverage-milvus-and-friendli-ai-for-advanced-rag-and-multi-modal-query)
ZillizとVectorizeでRAGアプリケーションを10倍速く提供する ](https://zilliz.com/blog/deliver-rag-apps-10x-faster-with-zilliz-and-vectorize)
高度なRAGテクニック:テキストとビジュアルの橋渡し ](https://zilliz.com/blog/advanced-rag-techniques-bridging-text-and-visuals-for-accurate-responses)
Ollama、Llama3、Milvusを使った関数呼び出しの使い方](https://zilliz.com/blog/function-calling-ollama-llama-3-milvus)

読み続けて

Build Multimodal Search for 3D Assets with Tripo and Zilliz Cloud
Generate 3D assets with Tripo, then search them by text, image, and metadata with multimodal embeddings and Zilliz Cloud.

Introducing Loon: A New Storage Engine for Vector Data That Never Stops Changing
Loon is a new storage engine for Milvus 3.0 and Zilliz Vector Lakebase, built to manage evolving vector datasets with ColumnGroups, row ID alignment, and Manifests.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).