




LLMによる大規模構造化文書データ抽出の課題
大規模言語モデル(LLMs)を適用する際の中心的な課題のひとつは、データ処理の段階にあり、特に多様なデータ形式を扱う場合にある。データは通常、構造化、半構造化、非構造化の3種類に分類することができます。LLMは主にテキストを扱うので、データがすでに関係表に整理されていない限り、 非構造化 データに適用されることが多い。
最近のウェビナーで、ZillizのPrincipal Developer AdvocateであるTim Spann氏は、Unstractを紹介した。Unstractは、非構造化データの抽出を合理化し、構造化されたフォーマットに変換するために設計されたオープンソースのプラットフォームである。このツールは、構造化プロセスを自動化することで、データ管理を簡素化することを目的としている。
このブログでは、Unstractの共同設立者兼CEOであるShuveb Hussainが概説する、構造化文書データ抽出の主な課題について掘り下げていきます。また、Milvus](https://zilliz.com/what-is-milvus)のようなベクトルデータベースとの統合を含め、Unstractがどのように様々なシナリオに取り組み、以前は扱いにくかったデータに構造を持たせているのかを探ります。現在の限界
データの構造化は、特に機械学習モデルがますます大量のデータを要求するようになるにつれて、長い間複雑で時間のかかるものとなってきた。歴史的に、この抽出作業の大部分は手作業で行われてきた。例えばスキャンした手書き文書の場合、自動化ではモデルの多様なニーズを完全に満たすことができなかったからだ。
大規模言語モデル(LLM)は、文書から情報を分析・抽出する能力を向上させたが、顕著な限界がある。ドキュメントは、表、フォーム、チャート、スキャンなど、さまざまな形式で表示されることが多く、抽出を成功させるには、データの品質と一貫性が重要な役割を果たします。さらに、多くのアプリケーションでは膨大な量のドキュメントを処理する必要があり、すべてのドキュメントが統一された構造に準拠しているわけではありません。LLMは、人手を介することなく、非常に可変的または複雑なレイアウトを処理するのに苦労する可能性があるため、抽出プロセスにおいてさらなるカスタマイズが必要になる場合があります。
図1:データ構造化の課題](https://assets.zilliz.com/Figure_1_Data_Structuring_Challenges_246e82ea4c.png)
図1は、構造化文書データ抽出における現在の開発の状況を示すチャレンジ・バブル・チャートです。この図では、3つの主要分野が強調されています:
現在の技術で解決に成功している小さなユースケース。
市場のかなりの部分**は、大規模言語モデル(LLM)によって積極的に対処されている。
未解決のビジネスケースの**膨大な可能性。これらのケースは、様々な技術の進歩次第では、将来的に解決される可能性がある。
この可視化は、AIエージェントアプリケーション開発のような、現在達成可能なものと近い将来ブレークスルーとなる可能性のギャップを強調している。
ドキュメント抽出
LLMを使って文書からテキストを抽出しようとしたことのある人なら誰でも、わずか数行のコードで必要な情報をすべて得ることがいかに困難であるかを知っている。Co-pilotsのようなツールはこのプロセスを支援することはできますが、完全に自動化されたソリューションを提供するには至らないことがよくあります。抽出されたデータが必ずしも望ましい構造を持っているとは限らず、情報を正しいフォーマットに整理するために、人間の介入ステップが必要になることがよくあります。
そこで、アンアブストラクトは、非構造化ドキュメントを構造化データに変換する完全自動化ソリューションを提供します。アンアブストラクトは、LLMベースの技術を使って情報を抽出します。
図2:ドキュメント抽出](https://assets.zilliz.com/Figure_2_Document_Extraction_fa7f607c71.png)
Unstractクラウド
Unstractはコード不要のLLMプラットフォームで、インテリジェント・ドキュメント・プロセッシング(IDP)のカテゴリーに属します。プロセスを主に2つのステップに分けることで、文書抽出を効率化します:
プロンプトエンジニアリング**](https://zilliz.com/glossary/prompt-as-code-(prompt-engineering)):UnstractのPrompt Studioでは、特定のドキュメントタイプに対応した汎用的なプロンプトを開発することができ、このプロンプトを再利用して、同じタイプの他のドキュメントから構造化データを抽出することができます。
デプロイメント段階**:プロンプトが作成されると、ETLパイプライン、APIエンドポイント、またはさらなる検査のための手動レビューキューの一部など、さまざまな方法でデプロイすることができます。
Unstractは、正確なデータ抽出を実現するために2つのアプローチを提供しています:
精度の向上(LLMチャレンジ)***:この方法では、1つのLLMで文書を処理し、2つ目のLLMを使って1つ目のLLMの出力に挑戦します。2つのモデルがコンセンサスに達しない場合、抽出される特定のフィールドはNULLに設定され、誤ったデータが入力されるリスクを回避する。これにより、幻覚のリスクが大幅に軽減されます。異なるベンダーの2つのモデルが同じ間違った出力を生成する可能性は低いからです。
コスト削減
シングルパス抽出**:個々のフィールドに対して複数のプロンプトを送信する代わりに、このアプローチではすべてのプロンプトを1つのリクエストに統合する。LLMは、1回のパスですべての必要なフィールドを含むJSON出力を返し、トークンの使用量と待ち時間を削減します。
要約抽出**: このメソッドは、ユーザーのプロンプトに基づいてLLMを使用して入力ドキュメントの要約を作成します。この要約を使用して必要なフィールドを抽出し、トークンの使用量を最適化し、待ち時間をさらに短縮します。
図3:非抽出ストラテジー](https://assets.zilliz.com/Figure_3_Unstract_Extraction_Strategies_cac93f2f3b.png)
図4と図5は、シングルパス抽出プロジェクトの例を示しており、複数のプロンプトが組み合わされて1つのJSON出力が得られることがわかります。
図4: Unstract Prompt Studio (ドキュメントパーサー)](https://assets.zilliz.com/Figure_4_Unstract_Prompt_Studio_Document_Parser_15958b7943.png)
図5:Unstract Prompt Studio(結合出力)](https://assets.zilliz.com/Figure_5_Unstract_Prompt_Studio_Combined_Output_1df689d361.png)
さらに、ユーザーは抽出プロセスをカスタマイズするために様々なオプションを設定することができます。Milvus](https://milvus.io/)やZilliz Cloudのようなベクトルデータベースを選択してvector embeddingsを保存・取得したり、コストや待ち時間のような出力を比較するために2番目のLLMモデルを選択したり、コストよりも精度を優先する場合はchallenge LLMオプションを選択したりすることができます。
図6: Unstract Prompt Studio: 設定](https://assets.zilliz.com/unnamed_Figure_6_Unstract_Prompt_Studio_Settings_91b393f294.png)
設定が定義され、テキスト抽出の結果が満足のいくものであれば、ワークフローをツールとしてエクスポートし(図7)、デプロイするワークフローを選択し(図8)、APIエンドポイントを取得することができます(図9)。
図 7:ワークフローをツールとしてエクスポート](https://assets.zilliz.com/Figure_7_Export_the_Workflow_as_a_Tool_b01b772398.png)
図 8:ワークフローをツールとしてエクスポート](https://assets.zilliz.com/Figure_8_Export_the_Workflow_as_a_Tool_e155d3a43d.png)
図9:APIエンドポイントのデプロイ](https://assets.zilliz.com/Figure_9_Deploy_API_Endpoint_ca5847e171.png)
抽象的でない検索戦略
設定]で、ユーザーは2つの検索戦略から選択することができます:
シンプル**:このストラテジーでは、1つのクエリーを使用して関連する情報の塊を検索し、キーワードマッチングとベクトル検索を組み合わせて精度を確保します。
サブクエスチョンこのアプローチでは、複雑なクエリをより単純なサブクエスチョンに分解する。各サブクエッションは関連情報を取得し、それを集約して元の複雑なクエリに対する包括的なレスポンスを提供する。
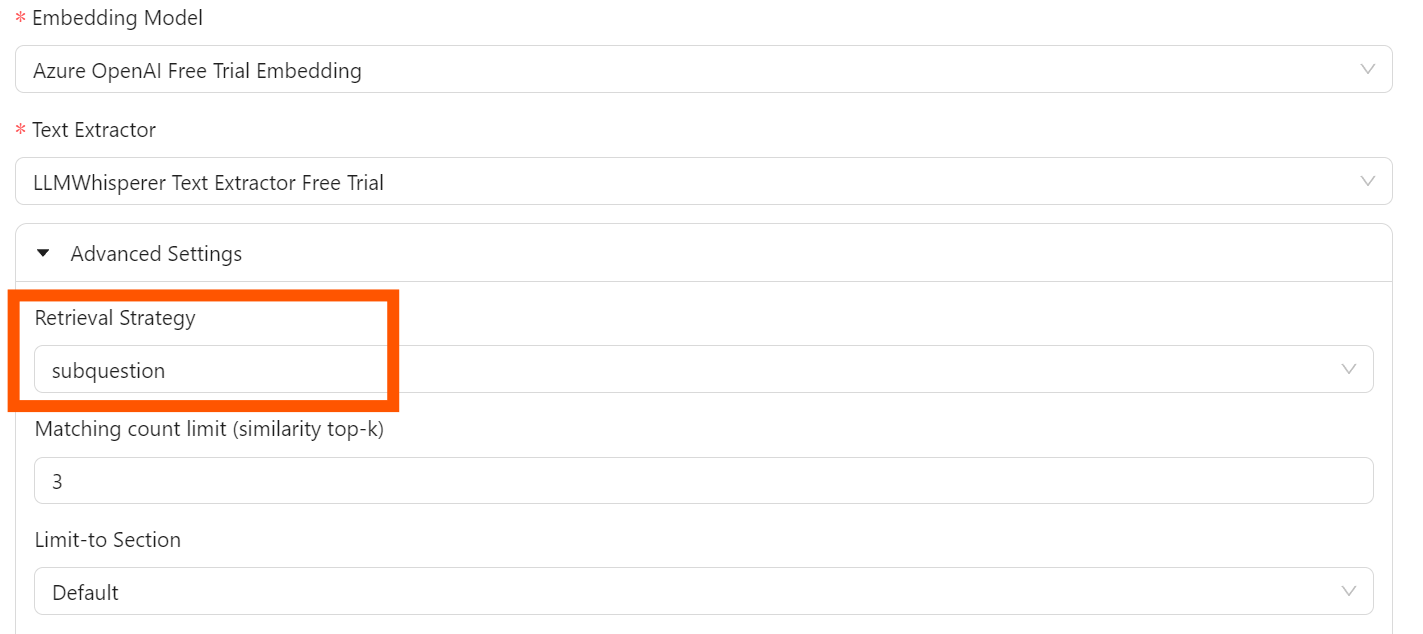
単純な検索アプローチはスピードとコスト効率を提供するが、より洗練されたモデルが提供できるようなニュアンスに富んだ理解は得られないかもしれない。
サブクエスチョン・リトリーバは、様々なコンテキストやドメインからの情報を統合する必要がある複雑な質問に対応するために、特に有用である。各サブクエスチョンの特定の情報要件に焦点を当てることで、このアプローチは、詳細なクエリを効果的に処理するモデルの能力を向上させる。
結論
大規模言語モデルの進歩とUnstractのような革新的なツールのおかげで、構造化文書データ抽出の分野は急速に変化している。Unstractは、Zilliz Cloudのようなベクトルデータベースと組み合わせて、非構造化データを構造化フォーマットに変換する効果的な方法を提供し、精度とコスト削減の両方に重点を置いている。さまざまな検索戦略により、ユーザーが複雑な質問をユーザーフレンドリーな方法で処理できるようにします。
ウェビナーでShuveb Hussainが強調したように、インテリジェントな文書処理におけるさらなる改善の可能性は非常に大きい。効率的なデータ抽出の必要性が高まる中、Unstractのようなプラットフォームがその道をリードする準備が整っています。これらの技術をより良いものにすることで、組織が非構造化データを有用な洞察に変える手助けをします。
完全に自動化された文書処理へのこのシフトは、単なる技術的な問題ではなく、さまざまな業界にわたってデータの管理方法を変えるということです。これらの進歩を採用することで、組織はますますデータ主導の世界における成長の新たな機会を発見することができる。
 Benito Martin
Benito MartinFreelance Technical Writer
読み続けて

Introducing Zilliz CLI and Agent Skills for Zilliz Cloud
Manage your vector database from your terminal or AI coding agent. Zilliz CLI and Agent Skills work with Claude Code, Cursor, Codex, and Copilot.

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Why DeepSeek V3 is Taking the AI World by Storm: A Developer’s Perspective
Explore how DeepSeek V3 achieves GPT-4 level performance at fraction of the cost. Learn about MLA, MoE, and MTP innovations driving this open-source breakthrough.