




Milvus、vLLM、Llama 3.1によるRAGの構築
カリフォルニア大学バークレー校は、2024年7月に、LLM推論とサービングのための高速で使いやすいライブラリであるvLLMを、インキュベーション段階のプロジェクトとしてLF AI & Data Foundation に寄贈しました。vLLMがLF AI & Dataファミリーに加わることを歓迎します!🎉
大規模言語モデル(LLMs)とベクトルデータベースは通常、AI幻覚に対処するための一般的なAIアプリケーションアーキテクチャであるRAG(Retrieval Augmented Generation)を構築するために対になっています。このブログでは、Milvus、vLLM、Llama 3.1を使ってRAGを構築し、実行する方法を紹介します。具体的には、Milvusにテキスト情報をvector embeddingsとして埋め込んで保存し、このvector storeを知識ベースとして使用して、ユーザの質問に関連するテキストの塊を効率的に検索する方法を紹介します。最後に、vLLMを活用してMetaのLlama 3.1-8Bモデルを提供し、検索されたテキストによって拡張された回答を生成します。さあ、飛び込もう!
Milvus、vLLM、MetaのLlama 3.1の紹介
Milvusベクターデータベース
Milvus**は、Generative AI(GenAI)ワークロード用のベクトルを保存、インデックス付け、検索するためのオープンソースの目的別分散ベクトルデータベースです。ハイブリッド検索](https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) メタデータフィルタリング [リランキング]を実行し、何兆ものベクトルを効率的に処理する能力により、MilvusはAIおよび機械学習ワークロードに最適な選択肢となっています。Milvusは、ローカル、クラスタ、またはフルマネージドのZilliz Cloudでホストすることができます。
vLLM
vLLM**は、UC Berkeley SkyLabで開始されたオープンソースプロジェクトで、LLMサーバーのパフォーマンスを最適化することに重点を置いています。PagedAttentionによる効率的なメモリ管理、継続的なバッチ処理、最適化されたCUDAカーネルを使用しています。従来の方法と比較して、vLLMは、GPUメモリ使用量を半分に削減しながら、サービング性能を最大24倍向上させます。
論文「Efficient Memory Management for Large Language Model Serving with PagedAttention」によると、KVキャッシュはGPUメモリの約30%を使用しており、潜在的なメモリ問題につながっています。KVキャッシュは連続したメモリに保存されますが、サイズが変わるとメモリの断片化を引き起こし、計算効率が悪くなります。

画像1.既存システムにおけるKVキャッシュのメモリ管理 (2023 Paged Attention_ paper)
KVキャッシュに仮想メモリを使用することで、vLLMは必要に応じて物理GPUメモリのみを割り当て、メモリの断片化を排除し、事前割り当てを回避します。テストでは、vLLMはHuggingFace Transformers (HF)とText Generation Inference (TGI)を上回り、NVIDIA A10GとA100 GPU上でHFより最大24倍、TGIより最大3.5倍高いスループットを達成しました。
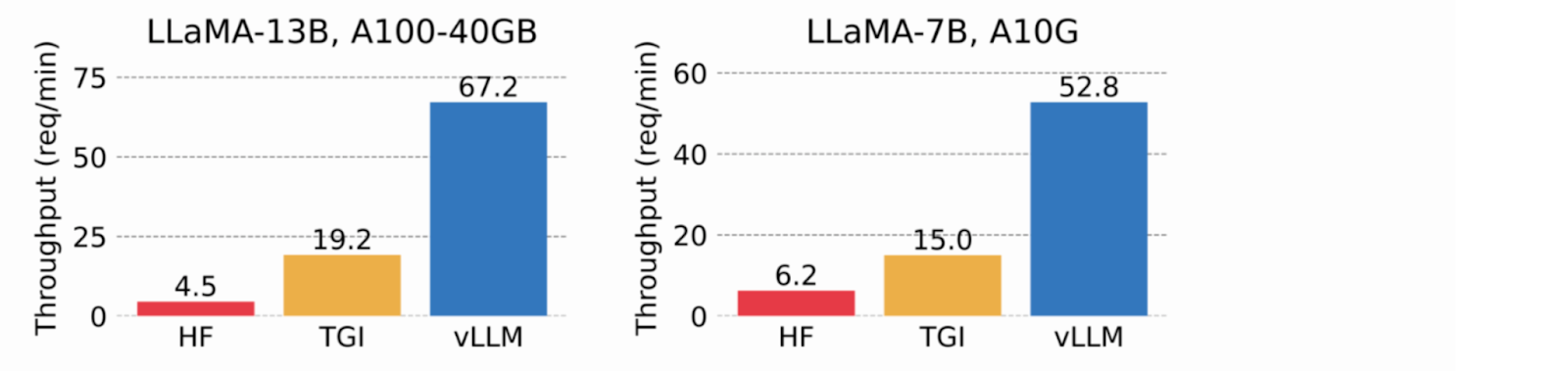
画像2.vLLMは、HFより8.5倍~15倍、TGIより3.3倍~3.5倍高いスループットを達成する(2023_ vLLM blog) 。
メタのラマ3.1
2024年7月23日、Meta's Llama 3.1が発表された。405Bモデルはいくつかの公開ベンチマークで最先端の性能を発揮し、128,000の入力トークンのコンテキストウィンドウを持ち、様々な商用利用が許可されている。4,050億パラメータモデルと並行して、Meta社はLlama3 70B(700億パラメータ)と8B(80億パラメータ)の更新版をリリースした。モデルの重みは[Metaのウェブサイトから]ダウンロードできる(https://info.deeplearning.ai/e3t/Ctc/LX+113/cJhC404/VWbMJv2vnLfjW3Rh6L96gqS5YW7MhRLh5j9tjNN8BHR5W3qgyTW6N1vHY6lZ3l8N8htfRfqP8DzW72mhHB6vwYd2W77hFt886l4_PV22X226RPmZbW67mSH08gVp9MW2jcZvf24w97BW207Jmf8gPH0yW20YPQv261xxjW8nc6VW3jj-nNW6XdRhg5HhZk_W1QS0yL9dJZb0W818zFK1w62kdW8y-_4m1gfjfNW2jswrd3xbv-yW5mrvdk3n-KqyW45sLMF21qDrwW5TR3vr2MYxZ9W2hWhq23q-nQdW4blHqh3JlZWfW937hlZ58-KJCW82Pgv9384MbYW7yp56M6pvzd6f77wnH004).
重要な洞察は、生成されたデータを微調整することでパフォーマンスを向上させることができるが、質の低い例はパフォーマンスを低下させる可能性があるということだった。Llamaチームは、モデル自体、補助モデル、およびその他のツールを使用して、これらの悪い例を特定し、除去するために広範な作業を行った。
MilvusによるRAG検索の構築と実行
データセットの準備
このデモのデータセットとして、公式のMilvus documentationをダウンロードし、ローカルに保存したものを使用した。
from langchain.document_loaders import DirectoryLoader
# 既にローカルディレクトリに保存されているHTMLファイルをロードする。
path = "../../RAG/rtdocs_new/"
global_pattern = '*.html'
loader = DirectoryLoader(path=path, glob=global_pattern)
docs = loader.load()
# ドキュメントの数とプレビューを表示
print(f "loaded {len(docs)} documents")
print(docs[0].page_content)
pprint.pprint(docs[0].metadata)
 loaded 22 docs
loaded 22 docs
埋め込みモデルのダウンロード
次に、HuggingFaceからフリーでオープンソースのembedding modelをダウンロードします。
インポートトーチ
from sentence_transformers import SentenceTransformer
# デバイスに依存しないコードのためにトーチの設定を初期化する。
N_GPU = torch.cuda.device_count()
DEVICE = torch.device('cuda:N_GPU' if torch.cuda.is_available() else 'cpu')
# huggingface model hubからモデルをダウンロードする。
モデル名 = "BAAI/bge-large-en-v1.5"
エンコーダ = SentenceTransformer(model_name, device=DEVICE)
# モデルパラメータを取得し、後のために保存します。
EMBEDDING_DIM = encoder.get_sentence_embedding_dimension()
MAX_SEQ_LENGTH_IN_TOKENS = encoder.get_max_seq_length()
# モデルのパラメータを調べる
print(f "model_name: {model_name}")
print(f "EMBEDDING_DIM: {EMBEDDING_DIM}")
print(f "MAX_SEQ_LENGTH: {MAX_SEQ_LENGTH}")

カスタムデータをベクターとしてチャンクし、エンコードする。
固定長512文字で、10%重複するようにする。
from langchain.text_splitter import RecursiveCharacterTextSplitter
チャンクサイズ = 512
chunk_overlap = np.round(CHUNK_SIZE * 0.10, 0)
print(f "chunk_size: {CHUNK_SIZE}, chunk_overlap: {chunk_overlap}")
# スプリッターを定義する。
child_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE、
chunk_overlap=chunk_overlap)
# ドキュメントをチャンクする。
chunks = child_splitter.split_documents(docs)
print(f"{len(docs)}個のドキュメントを{len(chunks)}個の子ドキュメントに分割します。")
# エンコーダーの入力はdoc.page_contentの文字列です。
list_of_strings = [doc.page_content for doc in chunks if hasattr(doc, 'page_content')].
# HuggingFace エンコーダを使った埋め込み推論。
embeddings = torch.tensor(encoder.encode(list_of_strings))
# エンベッディングを正規化する。
embeddings = np.array(embeddings / np.linalg.norm(embeddings))
# Milvus は `numpy.float32` の `numpy.ndarray` のリストを期待する。
converted_values = list(map(np.float32, embeddings))
# Milvus挿入用のdict_listを作成する。
dict_list = [].
for chunk, vector in zip(chunks, converted_values):
# 埋め込みベクトル、元のテキストチャンク、メタデータを組み立てる.
chunk_dict = { 'chunk': chunk.page__page。
'chunk': chunk.page_content、
'source': chunk.metadata.get('source', "")、
'vector': vector、
}
dict_list.append(chunk_dict)

ベクターをMilvusに保存する
エンコードされたベクトル埋め込みをMilvusベクトルデータベースに取り込む。
# クライアントをMilvus Liteサーバに接続する。
from pymilvus import MilvusClient
mc = MilvusClient("milvus_demo.db")
# 柔軟なスキーマとAUTOINDEXでコレクションを作成する。
COLLECTION_NAME = "MilvusDocs"
mc.create_collection(COLLECTION_NAME、
EMBEDDING_DIM、
consistency_level="Eventually"、
auto_id=True、
上書き=True)
# データをMilvusコレクションに挿入します。
print("エンティティの挿入を開始します")
start_time = time.time()
mc.insert(
コレクション名
data=dict_list、
progress_bar=True)
end_time = time.time()
print(f "Milvus insert time for {len(dict_list)} vectors:", end="")
print(f"{round(end_time - start_time, 2)}秒")

ベクトル検索を実行する
質問をし、Milvusの知識ベースから最近傍のチャンクを検索する。
SAMPLE_QUESTION = "HNSWのパラメータは何を意味しますか?"
# 同じエンコーダを使って質問を埋め込む。
query_embeddings = torch.tensor(encoder.encode(SAMPLE_QUESTION)))。
# エンベッディングを単位長に正規化する。
query_embeddings = F.normalize(query_embeddings, p=2, dim=1) # 埋め込みを単位長に正規化。
# 埋め込みデータをnp.float32のリストに変換。
query_embeddings = list(map(np.float32, query_embeddings))
# フィルタリングできるメタデータフィールドを定義する。
OUTPUT_FIELDS = list(dict_list[0].keys())
OUTPUT_FIELDS.remove('vector')
# 何個のTOP-K結果を取得したいかを定義する。
TOP_K = 2
# クエリとベクトルデータベースを使用してセマンティックベクトル検索を実行する。
results = mc.search(
コレクション名、
data=query_embeddings、
output_fields=OUTPUT_FIELDS、
limit=TOP_K、
consistency_level="Eventually")
検索結果は以下のようになる。
vLLMとLlama 3.1-8BによるRAG生成の構築と実行
HuggingFace から vLLM とモデルをインストールする。
vLLMはデフォルトでHuggingFaceから大きな言語モデルをダウンロードします。一般的に、HuggingFaceの新しいモデルを使いたい場合は、いつでもpip install--updateか-Uを実行してください。また、vLLMでMetaのLlama 3.1モデルの推論を実行するにはGPUが必要です。
vLLMがサポートしているモデルの全リストは、こちらのドキュメントページを参照してください。
# (推奨) 新しい conda 環境を作成します。
conda create -n myenv python=3.11 -y
conda activate myenv
# CUDA 12.1でvLLMをインストールする。
pip install -U vllm transformers torch
インポート vllm, torch
from vllm import LLM, SamplingParams
# GPU メモリキャッシュをクリアします。
torch.cuda.empty_cache()
# GPU をチェックします。
nvidia-smi
vLLM のインストール方法については、installation ページを参照してください。
HuggingFace トークンの取得
Meta Llama 3.1のようなHuggingFace上のいくつかのモデルは、ユーザーがウェイトをダウンロードできるようにする前にライセンスを受け入れることを要求します。したがって、HuggingFaceアカウントを作成し、モデルのライセンスを承認し、トークンを生成しなければなりません。
HuggingFaceのこのLlama3.1のページにアクセスすると、条件に同意するようメッセージが表示されます。モデルウェイトをダウンロードする前に、"Accept License"をクリックし、メタ条件に同意してください。承認には通常1日もかかりません。
**承認を受けた後、新しいHuggingFaceトークンを生成する必要があります。古いトークンは新しい権限では使えません。
vLLMをインストールする前に、新しいトークンでHuggingFaceにログインしてください。 以下では、トークンの保存にColab secretsを使用しています。
# 新しいトークンを使ってHuggingFaceにログインする。
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get('HF_TOKEN')
login(token = hf_token, add_to_git_credential=True)
RAGジェネレーションの実行
デモではLlama-3.1-8B`モデルを実行する。以下の例は、A100 GPUを搭載したGoogle Colab Pro(月額10ドル)で実行した。vLLMの実行方法の詳細については、Quickstart documentationをご覧ください。
# 1.モデルの選択
MODELTORUN = "メタ・ラマ/メタ・ラマ-3.1-8B-インストラクト"
# 2.GPUメモリキャッシュをクリアします!
torch.cuda.empty_cache()
# 3.vLLM モデルインスタンスをインスタンス化します。
llm = LLM(model=MODELTORUN、
enforce_eager=True、
dtype=torch.bfloat16、
gpu_memory_utilization=0.5、
max_model_len=1000、
seed=415、
max_num_batched_tokens=3000)

Milvusから取得したコンテキストとソースを使用してプロンプトを書く。
# 全てのコンテキストをスペースで区切る。
contexts_combined = '.join(contexts)
# LangChainのランス・マーティンは、最適なコンテキストを最後に置くように言っている。
contexts_combined = ' '.join(reversed(contexts))
# ユニークなソースをカンマで区切る。
source_combined = '.join(reversed(list(dict.fromkeys(sources))))
SYSTEM_PROMPT = f"""最初に、提供されたコンテキストがユーザーの質問に関連しているかどうかをチェックします。
をチェックする。 次に、提供されたコンテキストが強く関連している場合にのみ、コンテキストを使用して質問に答えます。 そうでなければ、Contextが強く関連していない場合、Contextを使わずに質問に答えてください。
明確、簡潔、適切であること。 2文以内で明確に答える。
根拠となる情報源{source_combined}ソース
コンテキストコンテキスト: {contexts_combined}
ユーザーの質問{サンプル質問}
"""
プロンプト = [SYSTEM_PROMPT]
ここで、取得したチャンクとプロンプトに詰め込まれた元の質問を使って答えを生成します。
# サンプリングパラメータ
sampling_params = SamplingParams(temperature=0.2, top_p=0.95)
# vLLM モデルを起動する。
出力 = llm.generate(prompts, sampling_params)
# 出力を表示する。
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
# !rはrepr()を呼び出し、引用符で囲まれた文字列を表示します。
print()
print(f "Question: {SAMPLE_QUESTION!r}")
pprint.pprint(f "Generated text: {generated_text!r}")

上記の答えは私には完璧に見える!
このデモに興味を持たれた方は、ご自由にお試しいただき、感想をお聞かせください。また、Discord上のMilvusコミュニティに参加して、GenAI開発者全員と直接会話することも大歓迎です。
参考文献
ページングされたアテンションに関する2023年のvLLM論文](https://arxiv.org/pdf/2309.06180)
Ray Summitでの2023 vLLMプレゼンテーション
vLLMサーバーの運用に役立つブログ:vLLM のデプロイ:ステップ・バイ・ステップ・ガイド
ラマ3モデルの群れ|研究 - AI at Meta](https://ai.meta.com/research/publications/the-llama-3-herd-of-models/)

読み続けて

Migrating Self-Managed Milvus to Zilliz Cloud for >99% Latency Reduction
Step-by-step guide to migrating 50M vectors from self-managed Milvus to Zilliz Cloud using milvus-backup. Achieve >99% query latency reduction with zero data loss.

DeepSeek Always Busy? Deploy It Locally with Milvus in Just 10 Minutes—No More Waiting!
Learn how to set up DeepSeek-R1 on your local machine using Ollama, AnythingLLM, and Milvus in just 10 minutes. Bypass busy servers and enhance AI responses with custom data.

Proactive Monitoring for Vector Database: Zilliz Cloud Integrates with Datadog
we're excited to announce Zilliz Cloud's integration with Datadog, enabling comprehensive monitoring and observability for your vectorDB deployments.