




Una guida completa ai benchmark ANN: valutare le prestazioni della ricerca Approximate Nearest Neighbor (ANNS)
Una guida completa ai benchmark ANN: valutare le prestazioni della ricerca Approximate Nearest Neighbor (ANNS)
Immagina di costruire un motore di ricerca che deve trovare rapidamente gli elementi più simili da un database contenente miliardi di immagini, documenti di testo o altri dati non strutturati. Come fai a garantire che il tuo algoritmo di ricerca non solo restituisca risultati accurati, ma lo faccia anche alla velocità della luce? È qui che entra in gioco la ricerca Approximate Nearest Neighbor (ANN). La ricerca ANN è fondamentale in molte applicazioni reali, dai sistemi di raccomandazione al recupero di immagini su larga scala.
Con così tante soluzioni di ricerca ANN disponibili sul mercato, come valutiamo l'efficacia dei diversi algoritmi ANN, specialmente su larga scala? Entrano in gioco gli ANN Benchmarks, che sono diventati lo standard di riferimento per testare le prestazioni dei metodi di ricerca ANN su grandi dataset.
In questo blog, esploreremo i benchmark ANN, perché sono importanti e come aiutano sviluppatori e ingegneri degli algoritmi a scegliere le soluzioni di ricerca vettoriale giuste per il compito. Esamineremo anche alcuni dei benchmark più popolari utilizzati oggi e ciò che li rende essenziali nella ricerca vettoriale.
Che cos'è la ricerca ANN e come funziona?
Prima di approfondire i benchmark, è importante comprendere la ricerca Approximate Nearest Neighbor (ANN), o ANNS, e come opera. La ricerca ANN è una tecnica potente nel machine learning (ML) che consente una ricerca efficiente della similarità semantica in grandi dataset spesso presenti in database vettoriali come Zilliz Cloud. Può trovare rapidamente gli elementi più vicini a un dato elemento di query in un dataset. A differenza dei metodi di ricerca esatta, che garantiscono il 100% di accuratezza, ANNS sacrifica una piccola quantità di accuratezza in cambio di miglioramenti significativi in termini di velocità e scalabilità.
Come funziona la ricerca ANN:
Rappresentazione dei dati: Ogni elemento nel dataset è rappresentato come un vettore in uno spazio multidimensionale. I vettori sono solitamente codificati da un modello di embedding come i modelli di embedding testuale di OpenAI, i modelli multilingue di Cohere e i modelli multimodali di OpenAI. Ad esempio, un'immagine potrebbe essere rappresentata come un vettore di caratteristiche, come colore o forma, in uno spazio a 128 dimensioni.
Elaborazione della query: Quando viene effettuata una query, l'algoritmo di ricerca ANN recupera dal dataset i vettori vicini al vettore di query, utilizzando approssimazioni per accelerare il processo.
Classificazione dei risultati: L'algoritmo classifica i vicini più prossimi in base alla loro distanza dalla query nello spazio ad alta dimensionalità, spesso utilizzando metriche come la distanza euclidea o la similarità del coseno. Più i vettori sono vicini, più sono simili e rilevanti.
Efficienza: Il vantaggio principale della ricerca ANN è la sua capacità di fornire risultati in una frazione del tempo che richiederebbe una ricerca esatta, rendendola ideale per dataset su larga scala.
I metodi ANNS utilizzano varie strategie per approssimare rapidamente i vicini più prossimi:
Metodi basati su alberi: Tecniche come KD-Trees e Ball Trees organizzano i dati gerarchicamente per semplificare il processo di ricerca. Sebbene efficaci in dimensioni inferiori, le loro prestazioni peggiorano con l'aumentare della dimensionalità.
Metodi di hashing: Locality-sensitive hashing (LSH) raggruppa punti dati simili negli stessi bucket hash, riducendo il numero di confronti richiesti durante la ricerca.
Metodi basati su grafi: Algoritmi come i grafi Navigable Small World (NSW) e i grafi Hierarchical Navigable Small World (HNSW) creano reti di punti dati per accelerare le ricerche dei vicini.
Metodi di quantizzazione: Tecniche come Product Quantization (PQ) comprimono i dati in una forma più gestibile, migliorando l'efficienza della ricerca.
Sfruttando questi metodi, gli algoritmi ANNS possono bilanciare accuratezza della ricerca e prestazioni, rendendoli adatti a dataset su larga scala.
Ricerca ANN vs. ricerca KNN
La ricerca esatta dei K-nearest neighbor (KNN) e l'Approximate Nearest Neighbor Search (ANNS) sono due approcci fondamentali utilizzati nella ricerca vettoriale, ciascuno con i propri vantaggi e compromessi.
KNN esatto fornisce risultati precisi valutando la distanza tra il punto di query e ogni punto dati nel dataset, garantendo che i vicini identificati siano i più vicini possibili. Tuttavia, questo metodo può essere computazionalmente intensivo e lento a causa della sua natura brute-force, in particolare quando si gestiscono dataset di grandi dimensioni o spazi ad alta dimensionalità. Questo rende KNN esatto adatto a dataset più piccoli o a scenari in cui la precisione è fondamentale e le risorse computazionali sono meno rilevanti.
Al contrario, ANNS offre una soluzione pratica per gestire dati su larga scala sacrificando un certo grado di accuratezza a favore di prestazioni più rapide. ANNS impiega vari algoritmi e tecniche, come strutture basate su alberi, metodi di hashing e approcci basati su grafi, per approssimare in modo efficiente i vicini più prossimi. Questo approccio riduce significativamente i costi computazionali e scala bene con dataset enormi, rendendolo ideale per applicazioni in tempo reale come motori di ricerca e sistemi di raccomandazione in cui la velocità è cruciale. Sebbene ANNS possa non fornire sempre i vicini esattamente più prossimi, la sua capacità di offrire rapidamente risultati quasi accurati lo rende uno strumento prezioso nelle moderne attività di recupero e analisi dei dati.
Per ulteriori informazioni, consulta la nostra pagina del glossario ANNS.
Cos'è ANN Benchmark?
L'ANN Benchmark è uno strumento di valutazione completo progettato per misurare e confrontare le prestazioni di diversi algoritmi ANNS. Ospitato su ann-benchmarks.com, fornisce test e metriche standardizzati per valutare vari aspetti dei metodi ANNS, tra cui:
Velocità di ricerca: Quanto rapidamente l'algoritmo può trovare i vicini più prossimi.
Accuratezza: Il grado in cui i risultati dell'algoritmo approssimano i veri vicini più prossimi.
Scalabilità: Quanto bene l'algoritmo si comporta all'aumentare delle dimensioni o della dimensionalità del dataset.
Questo benchmark offre una gamma di dataset e criteri di valutazione, consentendo agli sviluppatori di valutare l'efficacia di diversi algoritmi in varie condizioni su un piano di parità.
Metriche chiave nei benchmark ANN:
Recall: La percentuale di veri vicini più prossimi recuperati con successo dall'algoritmo. Un recall elevato indica una migliore accuratezza.
Tempo di ricerca: Il tempo necessario all’algoritmo per restituire un risultato. Tempi di ricerca più rapidi sono cruciali per le applicazioni che richiedono risposte in tempo reale.
Utilizzo della memoria: La quantità di memoria richiesta dall’algoritmo per memorizzare e cercare nel dataset. Un utilizzo efficiente della memoria è importante per la scalabilità.
Scalabilità: La capacità dell’algoritmo di mantenere le prestazioni all’aumentare della dimensione del dataset. La scalabilità è un fattore critico nelle applicazioni reali in cui i dataset possono crescere rapidamente.
Dataset chiave utilizzati in ANN Benchmarks
ANN Benchmark utilizza dataset diversificati per testare gli algoritmi. Questi dataset coprono una gamma di domini, come caratteristiche delle immagini, embedding di testo e dati sintetici. I dataset chiave utilizzati nei benchmark includono:
| Set di dati | Dimensioni | Dimensione train | Dimensione test | Vicini | Distanza | Scarica |
|---|---|---|---|---|---|---|
| DEEP1B | 96 | 9,990,000 | 10,000 | 100 | Angolare | HDF5 (3.6GB) |
| Fashion-MNIST | 784 | 60,000 | 10,000 | 100 | Euclidea | HDF5 (217MB) |
| GIST | 960 | 1,000,000 | 1,000 | 100 | Euclidea | HDF5 (3.6GB) |
| GloVe | 25 | 1,183,514 | 10,000 | 100 | Angolare | HDF5 (121MB) |
| GloVe | 50 | 1,183,514 | 10,000 | 100 | Angolare | HDF5 (235MB) |
| GloVe | 100 | 1,183,514 | 10,000 | 100 | Angolare | HDF5 (463MB) |
| GloVe | 200 | 1,183,514 | 10,000 | 100 | Angolare | HDF5 (918MB) |
| Kosarak | 27,983 | 74,962 | 500 | 100 | Jaccard | HDF5 (33MB) |
| MNIST | 784 | 60,000 | 10,000 | 100 | Euclidea | HDF5 (217MB) |
| MovieLens-10M | 65,134 | 69,363 | 500 | 100 | Jaccard | HDF5 (63MB) |
| NYTimes | 256 | 290,000 | 10,000 | 100 | Angolare | HDF5 (301MB) |
| SIFT | 128 | 1,000,000 | 10,000 | 100 | Euclidea | HDF5 (501MB) |
| Last.fm | 65 | 292,385 | 50,000 | 100 | Angolare | HDF5 (135MB) |
Algoritmi ANN o motori di ricerca vettoriale testati
Gli ANN Benchmarks hanno valutato un'ampia gamma di algoritmi ANN e motori di ricerca vettoriale, tra cui Annoy, Faiss, Knowhere (il motore di ricerca di Milvus) e Glass (il motore di ricerca legacy di Zilliz Cloud). Il numero di algoritmi testati continua a crescere. Di seguito è riportato un elenco di algoritmi e motori di ricerca testati a settembre 2024.
scikit-learn: LSHForest, KDTree, BallTree
NMSLIB (Non-Metric Space Library) : SWGraph, HNSW, BallTree, MPLSH
NGT : ONNG, PANNG, QG
Elasticsearch : HNSW
DiskANN : Vamana, Vamana-PQ
scipy: cKDTree
Nota: Zilliz Cloud ha lanciato un nuovo motore di ricerca chiamato Cardinal, che offre prestazioni tre volte superiori rispetto al motore legacy Glass e una capacità di ricerca (QPS) fino a dieci volte superiore a quella di Milvus. Tuttavia, a causa di vincoli di tempo e altri fattori, le prestazioni di Cardinal non sono incluse nei risultati del benchmark ANN. Nella sezione seguente, puoi esplorarne le prestazioni utilizzando VectorDBBench.
Risultati del benchmark
Il grafico seguente mostra i risultati dei test di recall/query al secondo di vari algoritmi basati sul dataset GIST1M (1 milione di vettori con 960 dimensioni). Riporta il tasso di recall sull'asse x rispetto ai QPS sull'asse y, illustrando le prestazioni di ciascun algoritmo a diversi livelli di accuratezza del recupero.
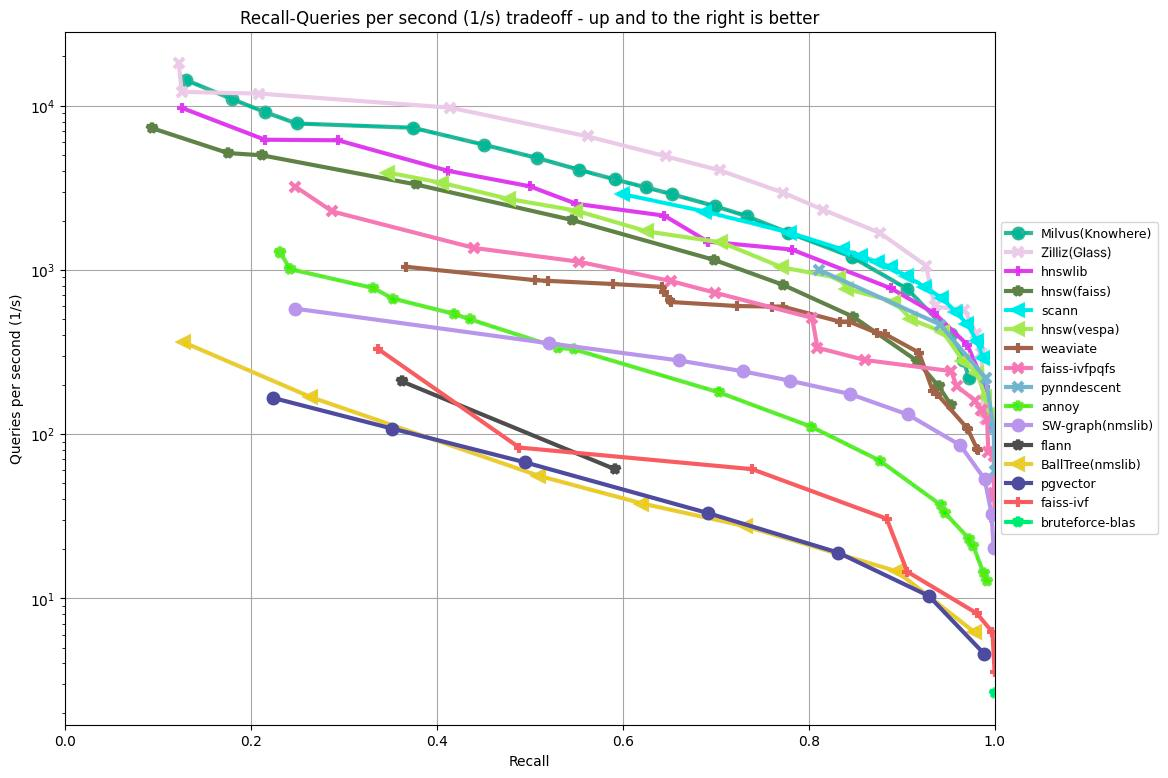 Figura 1: Risultati del benchmark ANN sul dataset GIST1M
Figura 1: Risultati del benchmark ANN sul dataset GIST1M
Figura 1: Risultati del benchmark ANN sul dataset GIST1M
Secondo i risultati mostrati nel grafico sopra, Knowhere (il motore di ricerca di Milvus), Glass (il motore di ricerca legacy di Zilliz Cloud) e le librerie HNSW hanno ottenuto i tre migliori risultati nell'elaborazione di 1.000.000 di vettori con 960 dimensioni.
Per ulteriori risultati di benchmarking, consulta il sito web di ANN-Benchmark.
VectorDBBench: uno strumento di benchmarking open-source per database vettoriali
La ricerca vettoriale, o ricerca di similarità vettoriale, è un concetto più ampio che si riferisce al processo di individuazione di vettori simili all’interno di un dataset. ANNS rappresenta un insieme di algoritmi che alimentano la ricerca vettoriale. I database vettoriali sono soluzioni appositamente progettate per ricerche efficienti di similarità vettoriale.
Sebbene ANN-Benchmark sia incredibilmente utile per selezionare e confrontare diversi algoritmi di ricerca vettoriale, non fornisce una panoramica completa dei database vettoriali. Dobbiamo anche considerare fattori come il consumo di risorse, la capacità di caricamento dei dati e la stabilità del sistema. Inoltre, ANN Benchmark non include molti scenari comuni, come le ricerche vettoriali filtrate.
Per affrontare tali sfide, gli sviluppatori di Zilliz hanno proposto VectorDBBench, uno strumento di benchmarking open-source progettato per database vettoriali open-source come Milvus e Weaviate e servizi completamente gestiti come Zilliz Cloud e Pinecone. Poiché molti servizi di ricerca vettoriale completamente gestiti non espongono i propri parametri per la regolazione da parte dell’utente, VectorDBBench mostra separatamente QPS e tassi di recall.
I grafici seguenti mostrano i risultati dei test per QPS e il tasso di recall di vari database vettoriali mainstream durante l’elaborazione di 1.000.000 di vettori con 768 dimensioni.
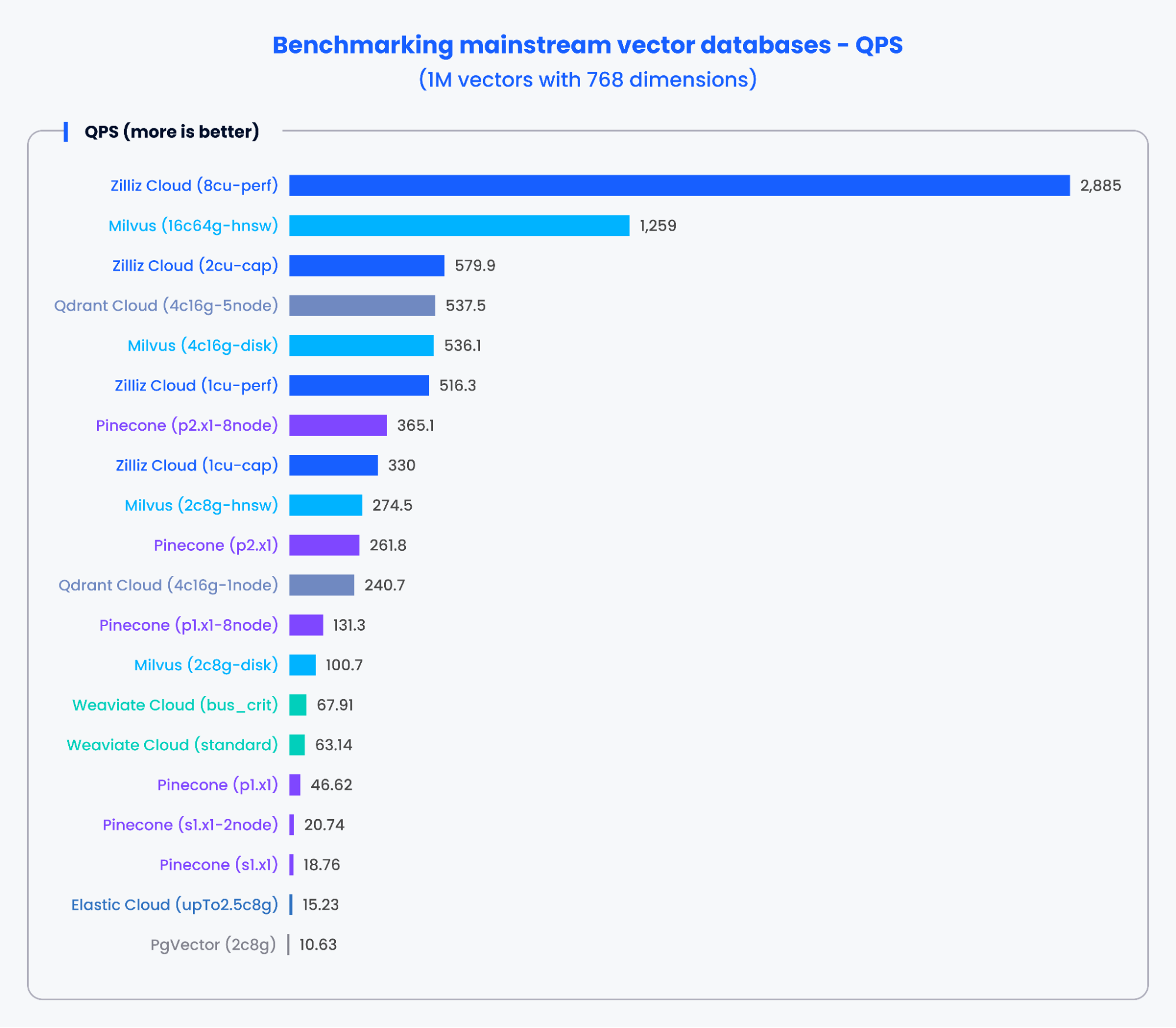 Figura 2: Risultati del benchmark per QPS
Figura 2: Risultati del benchmark per QPS
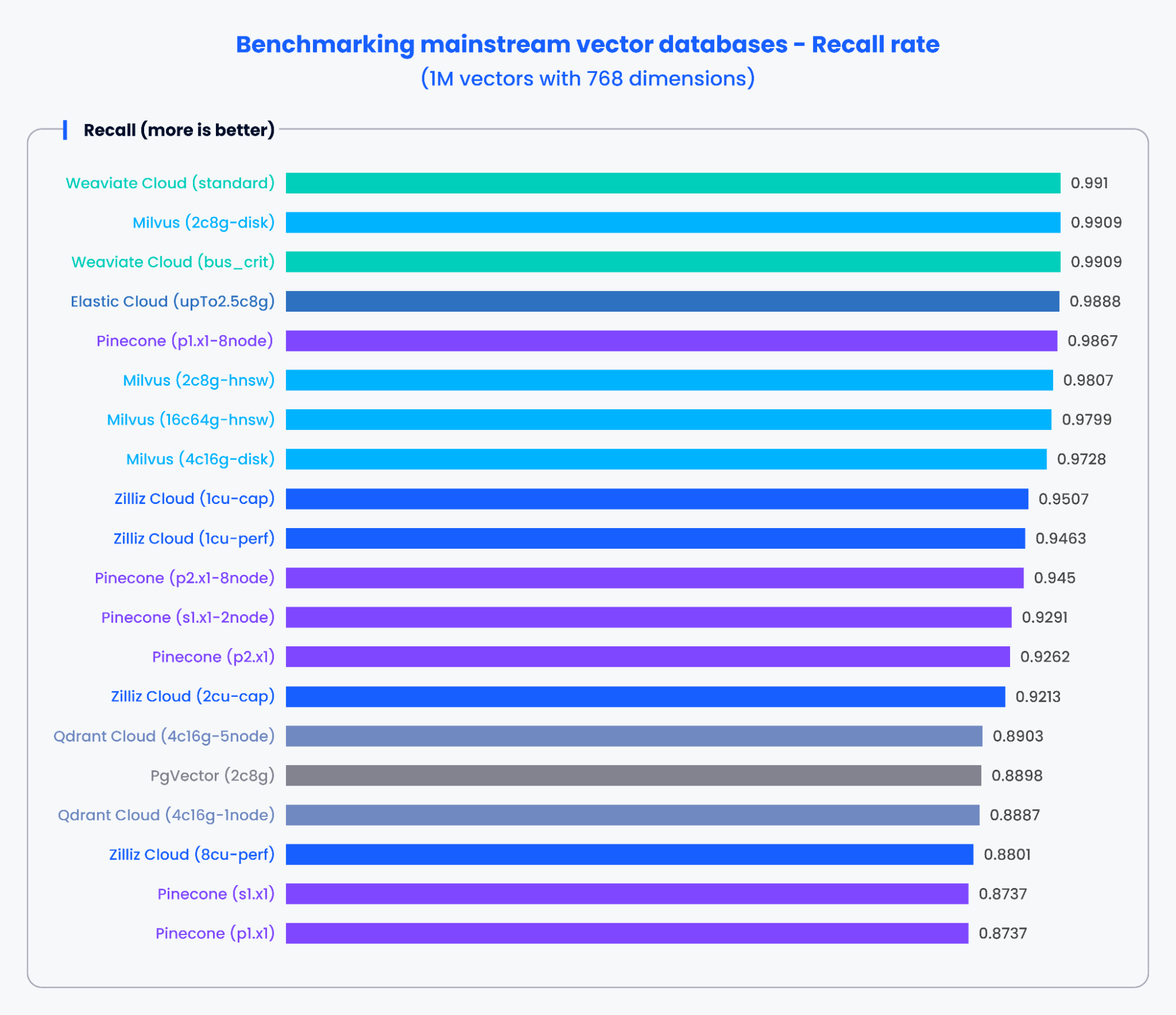 Figura 3: Risultati del benchmark per il tasso di recall
Figura 3: Risultati del benchmark per il tasso di recall
In base ai risultati nei grafici sopra, database vettoriali appositamente progettati come Milvus e Zilliz hanno dimostrato prestazioni eccellenti sia in termini di QPS sia di tassi di recall. Questi risultati indicano che i database vettoriali appositamente progettati possono elaborare rapidamente enormi quantità di dati e recuperare risultati più precisi. Al contrario, gli add-on di ricerca vettoriale basati su database tradizionali hanno mostrato prestazioni inferiori.
Scarica VectorDBBench dal suo repository GitHub per riprodurre i nostri risultati di benchmark o ottenere risultati prestazionali sui tuoi dataset.
Classifica di VectorDBBench
VectorDBBench offre anche una pagina della classifica dedicata, progettata per semplificare la presentazione dei risultati dei test e fornire un rapporto approfondito di analisi delle prestazioni. Questa classifica ci consente di selezionare metriche chiave come Queries Per Second (QPS), metriche di Query Price ($) e latenza per una valutazione completa delle prestazioni.
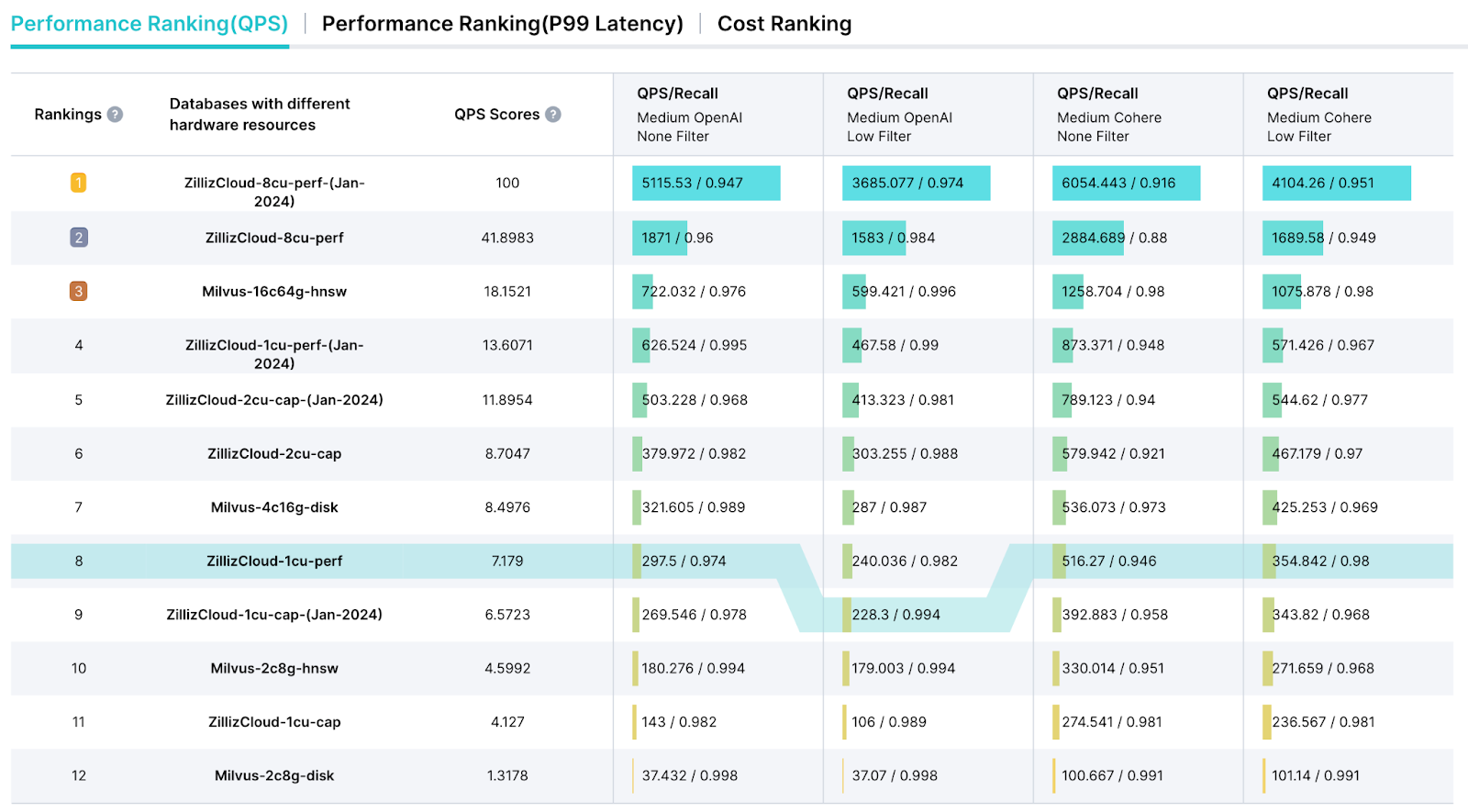 uno screenshot della classifica di vectordbbench
uno screenshot della classifica di vectordbbench
Figura 4: Uno screenshot della classifica di VectorDBBench
ANN Benchmarks vs. VectorDBBench
ANN Benchmarks valuta gli algoritmi di indicizzazione vettoriale, aiutando nella selezione e nel confronto di diverse librerie di ricerca vettoriale. Tuttavia, non è adatto a valutare database vettoriali complessi e maturi e trascura situazioni come la ricerca vettoriale filtrata.
Gli ingegneri di Zilliz hanno creato VectorDB Bench per adattarlo a una valutazione completa dei database vettoriali. Considera fattori essenziali come il consumo di risorse, la capacità di caricamento dei dati e la stabilità del sistema. Separando il client di test e il database vettoriale e garantendo un deployment indipendente, VectorDB Bench consente test che rispecchiano da vicino gli ambienti di produzione reali.
Fattori che influenzano la valutazione delle prestazioni
Diversi fattori incidono sulle prestazioni di un database vettoriale o di un algoritmo ANN, tra cui il dataset, le condizioni di rete e la configurazione del database.
Rete
Le condizioni di rete sono fondamentali. La latenza può rallentare le risposte alle query, mentre la larghezza di banda limitata influisce sulle velocità di trasferimento dei dati. Anche la stabilità della rete è importante, poiché le fluttuazioni possono causare prestazioni incoerenti.
Dataset
La dimensione del dataset influisce sull’uso di memoria e disco: dataset più grandi richiedono più risorse. La dimensionalità vettoriale influisce sulla complessità delle operazioni e sui tempi delle query. Anche la distribuzione dei dati e la struttura di indicizzazione (ad es., gerarchica, piatta) incidono sull’efficienza e sull’accuratezza della ricerca.
Configurazione del database
I parametri dell’indice (ad es., numero di alberi) e le impostazioni di ricerca (ad es., vicini più prossimi) influiscono direttamente sull’efficienza e sulla velocità del recupero. Il caching può migliorare i tempi di risposta per i dati a cui si accede frequentemente.
Fattori ambientali
Il sistema operativo e i processi in background possono influenzare la disponibilità delle risorse e la reattività del sistema, incidendo sulle prestazioni complessive.
Considerare questi fattori ti aiuta a comprendere e ottimizzare le prestazioni del tuo database vettoriale.
Ulteriori risorse
- Che cos'è la ricerca ANN e come funziona?
- Cos'è ANN Benchmark?
- VectorDBBench: uno strumento di benchmarking open-source per database vettoriali
- ANN Benchmarks vs. VectorDBBench
- Fattori che influenzano la valutazione delle prestazioni
- Ulteriori risorse
Contenuto
Inizia gratis, scala facilmente
Prova il database vettoriale completamente gestito progettato per le tue applicazioni GenAI.
Prova Zilliz Cloud gratuitamente