




Da Vector Database a Vector Lakebase
Oggi lanciamo la preview pubblica di Zilliz Vector Lakebase — il prossimo capitolo di Zilliz Cloud. Vector Lakebase è il passo successivo oltre i database vettoriali. È una piattaforma dati incentrata sulla semantica in cui storage aperto e calcolo elastico convergono per i carichi di lavoro AI.
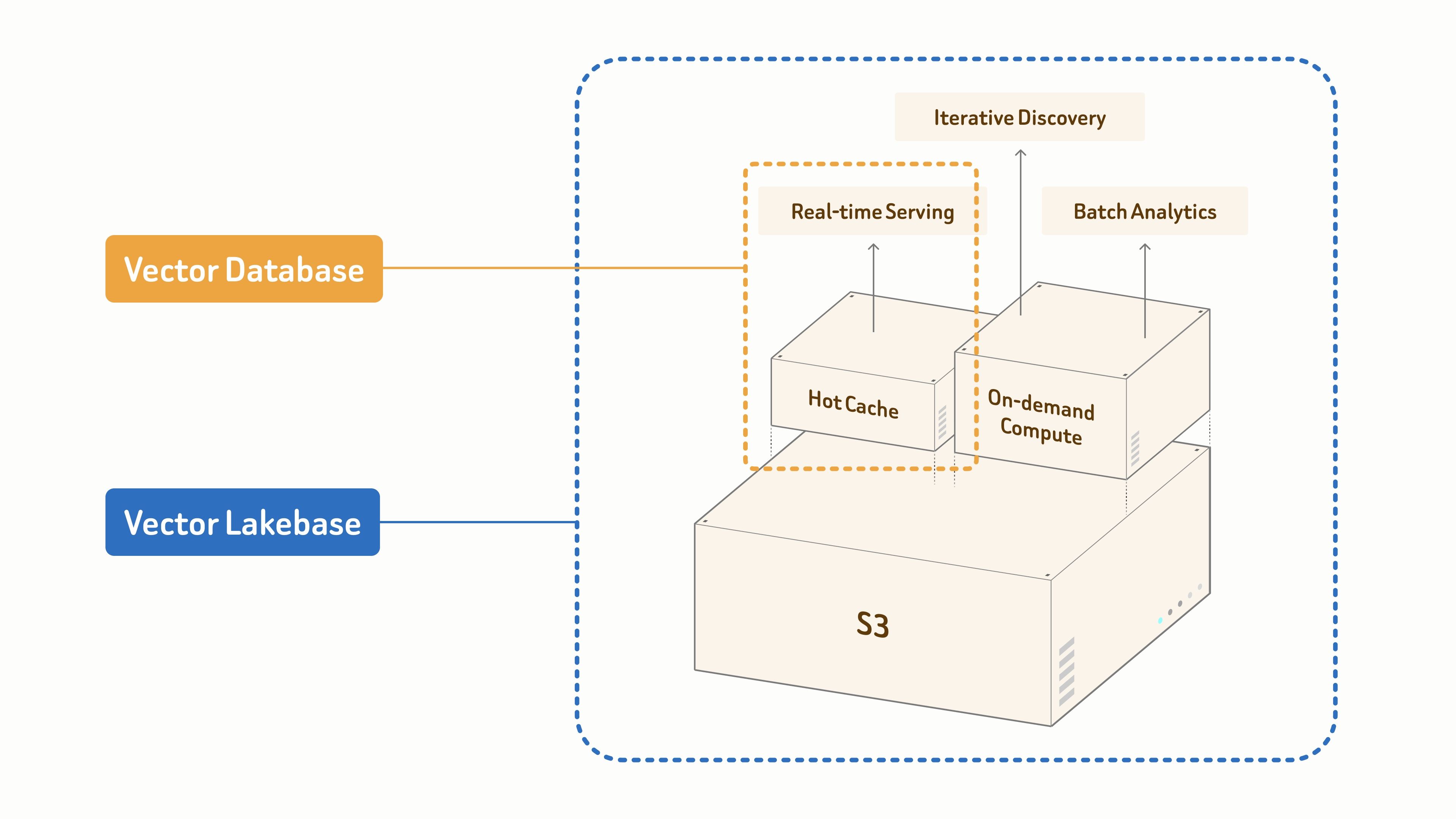
- I database vettoriali sono progettati appositamente per il serving in tempo reale.
- Vector Lakebase si basa su una fondazione dati unificata basata su S3 per alimentare AI e agenti attraverso tre modalità di carico di lavoro:
- recupero in tempo reale per il serving in produzione sensibile alla latenza,
- scoperta iterativa per l’esplorazione interattiva e multi-step,
- analisi batch per il mining offline e l’ottimizzazione dei dataset.
Scalando dai gigabyte ai petabyte.
Perché la fondazione dati unificata e le tre modalità di carico di lavoro sono davvero importanti?
In breve: perché i sistemi AI non sono più solo un problema di recupero a singola query. Operano come un ciclo continuo di serving, apprendimento e miglioramento.
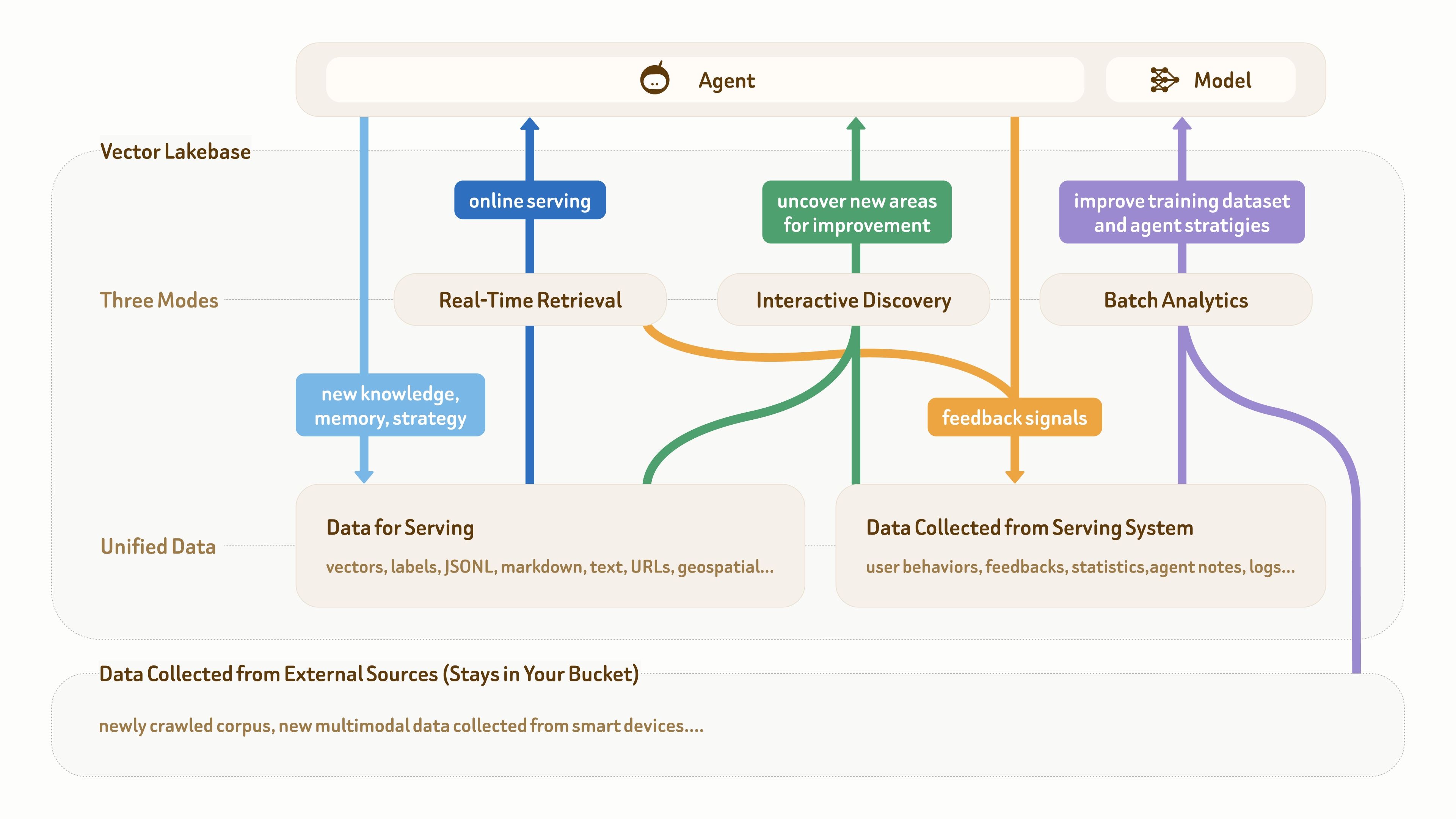
Come mostra questa figura, la fondazione dati per le applicazioni AI e agentiche di solito ha tre parti: dati multimodali grezzi nella parte inferiore, dati semantici per il serving online (come testo, vettori ed etichette) e dati di feedback raccolti dai sistemi di produzione (come comportamento degli utenti, log, note degli agenti e statistiche).
Molte applicazioni agentiche mature hanno già questo tipo di fondazione dati. Il vero punto critico è che questi diversi tipi di dati sono spesso dispersi tra più pipeline e sistemi, senza un piano dati unificato e strutturato a supporto del ciclo di workflow:
serving online (blu scuro) → accumulo di conoscenza e feedback (azzurro e arancione) → scoperta di insight (verde) → miglioramento di dataset e strategia (viola) → migliore serving online.
Come mostra anche l’immagine, un database vettoriale da solo non è più sufficiente, perché supporta principalmente il recupero in tempo reale e le scritture di dati orientate al serving (i due percorsi blu). In questo ciclo, le altre due modalità di accesso — scoperta interattiva e analisi batch — sono altrettanto importanti.
Ad esempio, gli sviluppatori AI (manualmente o tramite sistemi agentici) devono spesso esplorare i dati di feedback e il corpus sottostante per capire perché la qualità del serving sia scarsa. Possono anche eseguire deduplicazione semantica e clustering su larga scala su dati appena raccolti dal web, quindi effettuare mining dei cluster marginali per scoprire nuovi candidati di dati di training.
Questi carichi di lavoro sono molto diversi dall’elaborazione tradizionale dei big data. Il calcolo principale è semantico anziché numerico. I dati consistono principalmente in vettori, testo, etichette e metadati semantici, mentre le operazioni principali includono ricerca vettoriale, ricerca full-text, reranking, clustering semantico e attività correlate di recupero semantico.
Per questo motivo, la scoperta interattiva e le analisi batch sono naturalmente allineate con i database vettoriali sia a livello di dati sia di calcolo. In molti casi, il serving online e l’elaborazione offline condividono persino la stessa fondazione dati sottostante.
Ad esempio, i team possono raggruppare in cluster e analizzare offline attività utente ad alto valore, verificando contemporaneamente se la conoscenza o le strategie di supporto nel sistema di serving mostrano problemi di scarsità o qualità.
Nel complesso, qualsiasi architettura dati frammentata o isole infrastrutturali isolate rallentano questo ciclo — il che può essere fatale nella corsa in rapida evoluzione alle capacità AI. Vector Lakebase accelera questo ciclo attraverso un approccio semplice ma efficiente: fornire un piano dati semantico zero-copy a cui tutte e tre le modalità di carico di lavoro possono accedere in modo efficiente — recupero in tempo reale, scoperta interattiva e analisi batch.
Le funzionalità chiave di Vector Lakebase
Zilliz Vector Lakebase supporta questo ciclo di workflow attraverso cinque capacità fondamentali:
- Soluzioni di serving a livelli
Livelli di serving flessibili ottimizzati per diversi carichi di lavoro in tempo reale — offrendo prestazioni ultra-elevate, efficienza bilanciata e scalabilità conveniente su dataset enormi. - Ricerca on-demand
Progettata per carichi di lavoro su larga scala in cui la latenza è meno critica e il calcolo rimane inattivo per la maggior parte del tempo — inclusi ricerca infrequente, esplorazione dei dati e analytics batch. - Ricerca su Data Lake esterno
Aggiungi funzionalità di indicizzazione all'avanguardia e ricerca su larga scala direttamente ai dati del tuo lake esistente. - Ricerca a spettro completo Da vettori e testo a JSON e dati geospaziali—combinati con retrieval ibrido, filtraggio e reranking per query multimodali espressive.
- Storage unificato Lake-Native
Storage unificato sia per il serving sia per l’analytics, basato su Vortex — un formato aperto di nuova generazione che offre letture casuali più rapide ed economiche rispetto a Lance e Parquet, oltre a flessibilità di formato per colonna e capacità più ampie di modellazione dei dati.
Soluzioni di serving in tempo reale a livelli
Le soluzioni di serving a livelli di Zilliz Cloud offrono tre livelli di serving: Performance-Optimized, Capacity-Optimized e Tiered-Storage. Ogni livello è costruito con algoritmi di indicizzazione dedicati e strategie di posizionamento dei dati lungo la gerarchia di storage, offrendo un’ampia gamma di compromessi tra prestazioni e costi.
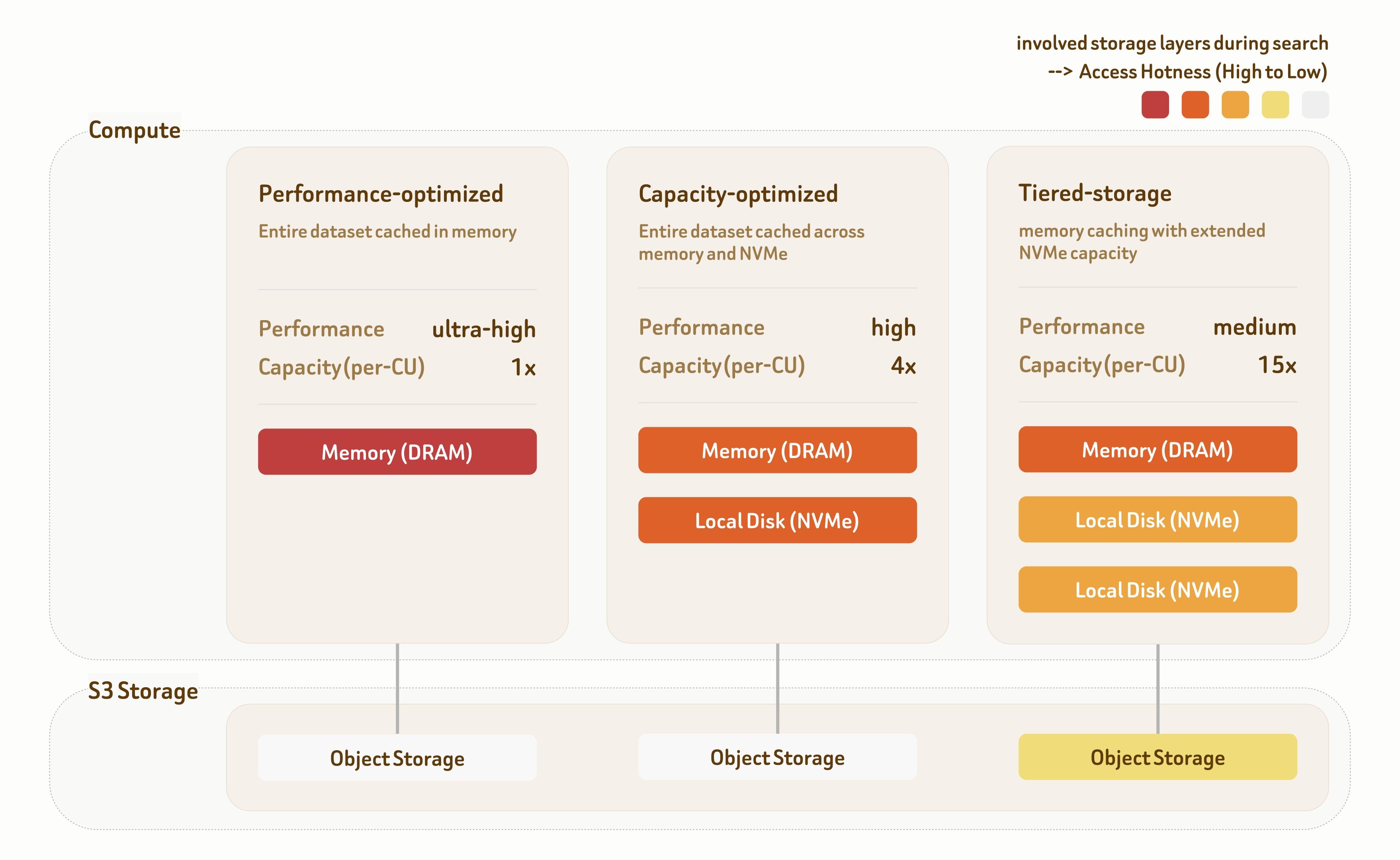
Il livello Performance-Optimized è destinato a scenari con prestazioni ultra-elevate. Tutti i dati sono serviti direttamente dalla memoria, offrendo oltre 1000 QPS con latenza di pochi millisecondi. Il throughput scala ulteriormente in modo lineare con il deployment multi-replica.
Il livello Capacity-Optimized combina memoria e storage NVMe locale per bilanciare prestazioni e capacità. Offre 100~500 QPS con latenza inferiore a 100 ms, risultando adatto alla maggior parte dei carichi di lavoro di retrieval.
Il livello Tiered-Storage comprende memoria, NVMe locale e object storage. Grazie a strategie di prefetching e caching altamente ottimizzate, oltre il 95% degli accessi ai dati colpisce ancora la memoria o il disco locale, fornendo 10~50 QPS con latenza intorno a 100 ms a un costo infrastrutturale significativamente inferiore.
Tutti e tre i livelli offrono un recall del 95%–98% per impostazione predefinita, con tuning flessibile tra indicizzazione e ricerca—supportando un recall dal 90% al 99%+ in base ai requisiti del carico di lavoro.
Queste architetture di serving sono collaudate in alcuni dei carichi di lavoro AI e internet su larga scala più esigenti al mondo, tra cui:
- piattaforme AI multi-tenant su scala internet,
- livelli di servizio differenziati sia per utenti enterprise premium sia per ampi pool di utenti gratuiti,
- knowledge base per agenti ad alte prestazioni,
- sistemi di raccomandazione a throughput ultra-elevato,
- motori di ricerca AI su scala web,
- schedulazione dinamica hot/cold dei dati a livello di secondi tra livelli di storage,
- pipeline di data mining per guida autonoma su scala 100B+ con vincoli di costo estremi.
Per il serving online, Zilliz Cloud fornisce anche funzionalità Global Cluster per alta disponibilità e disaster recovery cross-region, supportate da uno SLA di uptime del 99,99%.
Ricerca on-demand
La scoperta interattiva e l’analytics batch spesso operano su volumi di dati da uno a tre ordini di grandezza superiori rispetto al serving online, specialmente quando includono dati di feedback, note generate da agenti, log e corpora raccolti tramite crawling. Questi dataset possono facilmente raggiungere la scala dei TB o persino dei PB. Tuttavia, utilizzare centinaia o persino migliaia di nodi di database vettoriali per servirli è spesso difficile da giustificare da una prospettiva costi–benefici.

Ancora più importante, questi carichi di lavoro sono solitamente guidati da task. A differenza del livello di serving online delle applicazioni agentiche, non richiedono un’infrastruttura attiva 24/7. Le risorse di calcolo vengono utilizzate intensamente solo durante i task di elaborazione attivi, mentre rimangono inattive per la maggior parte del tempo, spesso con oltre il 97% di tempo di inattività.
Le soluzioni di serving serverless possono sembrare interessanti, ma spesso diventano molto più costose per questi workload.
A livello di compute, sia i sistemi serverless sia On-Demand Search seguono un modello pay-as-you-go. Nonostante le differenze nei modelli di pricing dettagliati, il costo di compute sottostante è spesso simile. Tuttavia, nell'architettura serverless, l'overhead di pooling, l'indicizzazione e i costi dei dati persistenti sono incorporati in markup aggiuntivi di scrittura e storage, anziché riflettere direttamente il costo reale delle risorse sottostanti.
Al contrario, Zilliz On-Demand Search addebita direttamente object storage e compute on-demand — in modo simile ad AWS Lambda, dove il pricing si basa principalmente sulla dimensione delle risorse allocate e sul tempo di esecuzione, mentre il costo dello storage rimane vicino al costo S3 sottostante. Questo evita overhead infrastrutturali nascosti e modelli di pricing black-box.
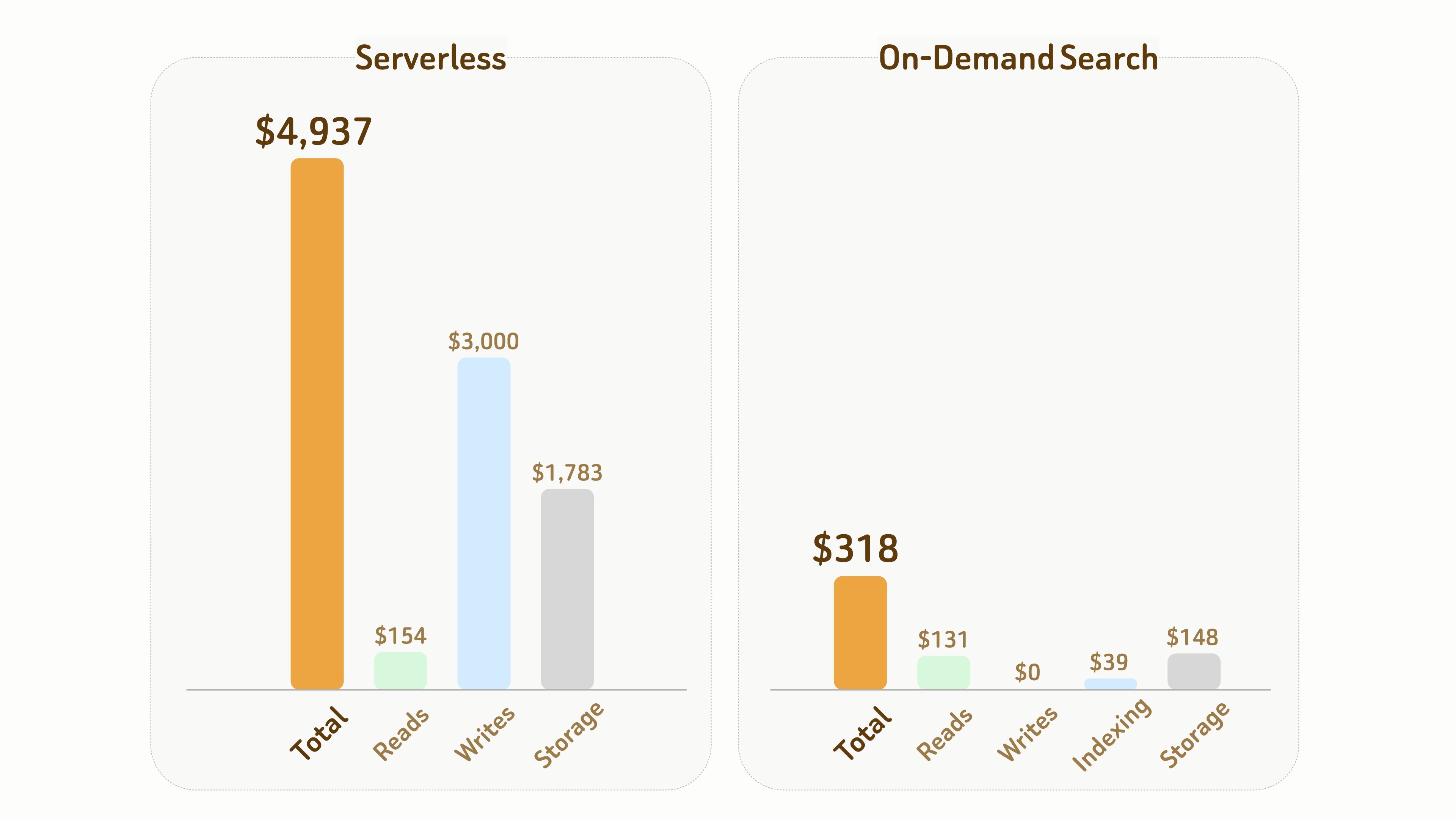
Il seguente confronto illustra la differenza di costo tra Serverless e On-Demand Search.
Configurazione:
- 1B vettori con 768 dimensioni, che richiedono circa 6 TB di storage inclusi dati e file di indice,
- durata di 1 mese con 10 ore di tempo di compute attivo accumulato.
Nel complesso, in questo esperimento, il costo totale di On-Demand Search è solo circa 1/15 ($318 vs $4,937) di quello di Serverless.
Ricerca su Data Lake esterno
Zilliz Vector Lakebase fornisce storage e compute di query completamente gestiti, consentendo agli utenti di archiviare e gestire i propri dati direttamente in Zilliz Cloud. Tuttavia, alcuni clienti dispongono già di infrastrutture data lake mature e pipeline di governance consolidate.
Per le applicazioni AI, una delle sfide principali è abilitare il recupero efficiente e l'esplorazione semantica direttamente sui dati lake esistenti. I sistemi big data tradizionali come Spark e Ray non sono ottimizzati per questi workload, perché sono fondamentalmente progettati attorno alla scansione completa dei dati e alla computazione map-reduce piuttosto che a query accelerate da indici e recupero semantico.
Per risolvere questo problema, Zilliz fornisce una modalità External Collection. Crea una mappatura logica zero-copy dal data plane di Zilliz alle tabelle lake di proprietà del cliente, abilitando al contempo indici ad alte prestazioni e ricerca full-spectrum su tale mappatura.
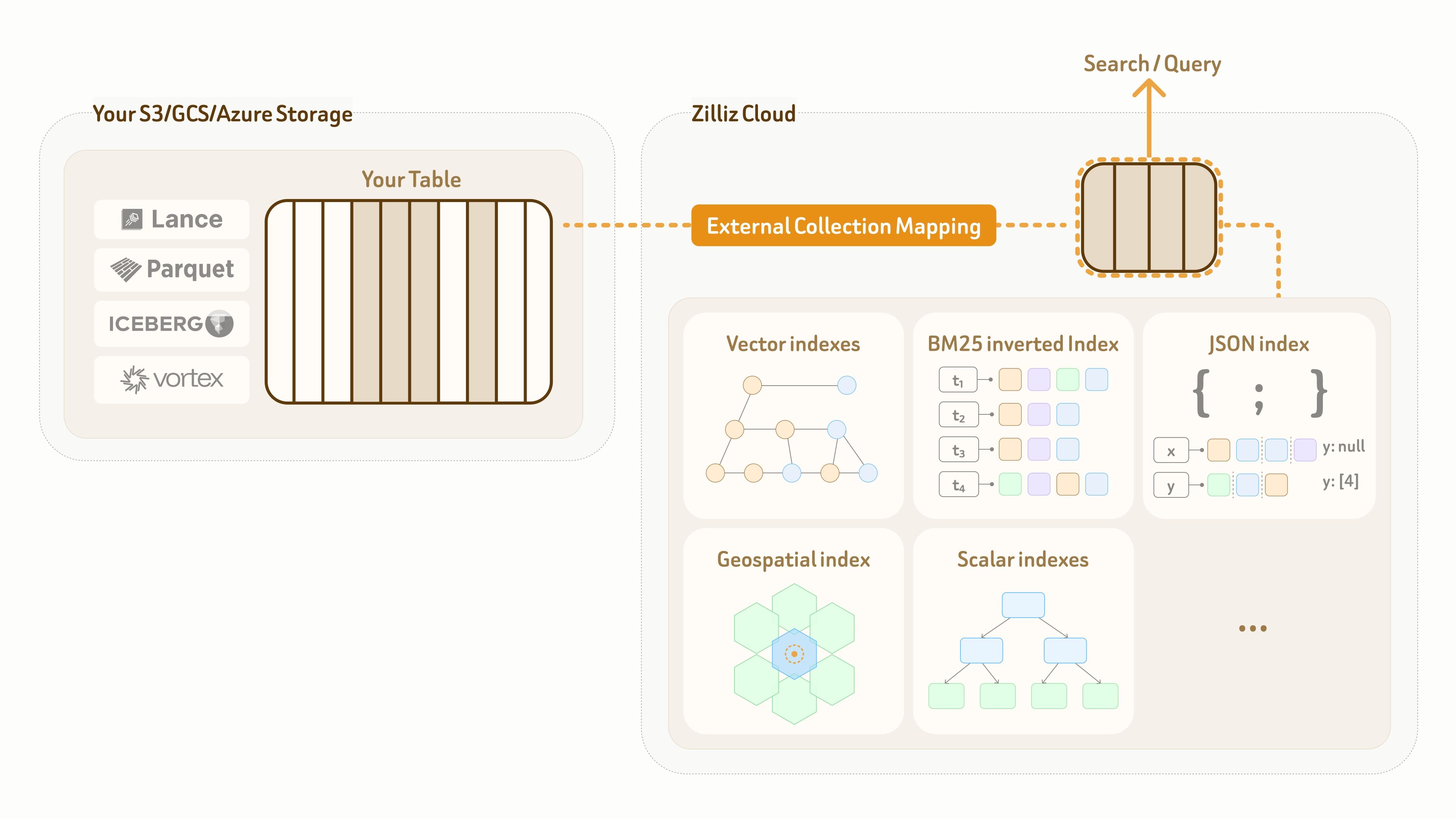
Attualmente, External Collection supporta due formati di tabelle data lake — Lance e Iceberg, oltre a due formati dati aperti — Parquet e Vortex.
Per gli aggiornamenti del data lake, Zilliz External Collection fornisce funzionalità di sincronizzazione incrementale. In base al pattern di aggiornamento del data lake e ai requisiti di visibilità delle query, gli utenti possono sincronizzare i dati in qualsiasi momento con una chiamata di refresh.
Ricerca full-spectrum
Le applicazioni AI hanno sempre più bisogno di recuperare e analizzare dati provenienti da fonti e modalità diverse — sia per combinare informazioni complementari sia per estrarre più prospettive dallo stesso contenuto grezzo, al fine di migliorare la qualità del recupero e dell'analisi.
Zilliz Vector Lakebase supporta la modellazione wide-table con tipi di dati ricchi, inclusi vettori densi e sparsi, testo, JSON, dati geospaziali e tipi primitivi, insieme a strutture complesse come Struct e Array — abilitando una modellazione semantica annidata efficiente direttamente all'interno di un layout tabellare unificato.

Questo abilita una modellazione unificata del contesto mappando ogni entità a livello applicativo direttamente a una singola riga. Ad esempio, invece di suddividere un documento in centinaia di righe per chunk di testo, immagini e tabelle, Zilliz Vector Lakebase può modellare l'intero documento come una singola riga. Ciò migliora il recupero e l'analisi multi-modali evitando al contempo l'overhead prestazionale e operativo di JOIN e aggregazioni.
Oltre alla modellazione dei dati, Vector Lakebase offre anche funzionalità di indicizzazione e ricerca all'avanguardia su tutti i tipi di dati supportati. Le funzionalità dettagliate sono elencate di seguito:
| Vector Search | Algoritmi di indicizzazione avanzati che superano HNSW, IVF e RaBitQ, con 10 livelli di ottimizzazione richiamo-latenza. |
|---|---|
| Full-Text Search | Ricerca full-text con BM25, frase, prefisso, corrispondenza fuzzy e un'ampia gamma di analizzatori. |
| Grep | Supporto regex integrato che copre la maggior parte dei pattern di corrispondenza in stile grep. |
| Hybrid Search | Ricerca vettoriale ibrida densa e sparsa per un richiamo e una pertinenza migliori. |
| Query on JSON | Shredding e indicizzazione JSON integrati per filtraggio e query veloci su campi JSON annidati. |
| Geospatial Search | Ricerca geospaziale veloce con filtraggio per raggio, nearest-neighbor e area. |
| Multi-Vector Search | Ricerca su più embedding generati da una o più modalità, con reranking unificato. |
| Vector Search with Filtering | Ricerca vettoriale con filtraggio degli attributi, ottimizzata da selettività del filtro bassa ad alta. |
| Range Search | Restituisce tutti i vettori entro una soglia di distanza specificata dal vettore di query. |
| Iterative Search | Ricerca iterativa con perfezionamento passo dopo passo della query basato sui risultati intermedi. |
| Multi-Path Retrieval | Recupero multi-percorso con più strategie, in cui ogni percorso può utilizzare uno qualsiasi dei metodi di ricerca sopra indicati. |
oltre a funzionalità di reranking utilizzate insieme al recupero multi-percorso.
| Cohere Reranker | Un modello di reranking cross-encoder che assegna punteggi alle coppie query–documento con alta precisione semantica per riordinare i risultati del recupero in base alla massima pertinenza. |
|---|---|
| Voyage AI Reranker | Un modello di reranking leggero e ad alta produttività, ottimizzato per un calcolo della pertinenza rapido ed economicamente efficiente in pipeline di recupero su larga scala. |
| Boost Reranker | Applica filtri condizionali ai risultati corrispondenti e ne regola i punteggi con un peso specificato per promuovere o declassare i ranking. |
| Decay Reranker | Regola i punteggi dei risultati applicando una funzione di decadimento basata su fattori come distanza o tempo, riducendo gradualmente la pertinenza man mano che i valori si discostano da un target. |
| RRF Reranker | Fonde più elenchi di risultati combinando le posizioni di ranking di ciascun elemento tra gli elenchi in un unico ranking. |
| Weighted Reranker | Combina i punteggi di più elenchi di risultati utilizzando pesi configurabili per produrre un ranking unificato. |
Storage Lake-Native Unificato
Zilliz Cloud è costruito su un'architettura storage–compute completamente disaccoppiata, con tutto persistito su cloud object storage.
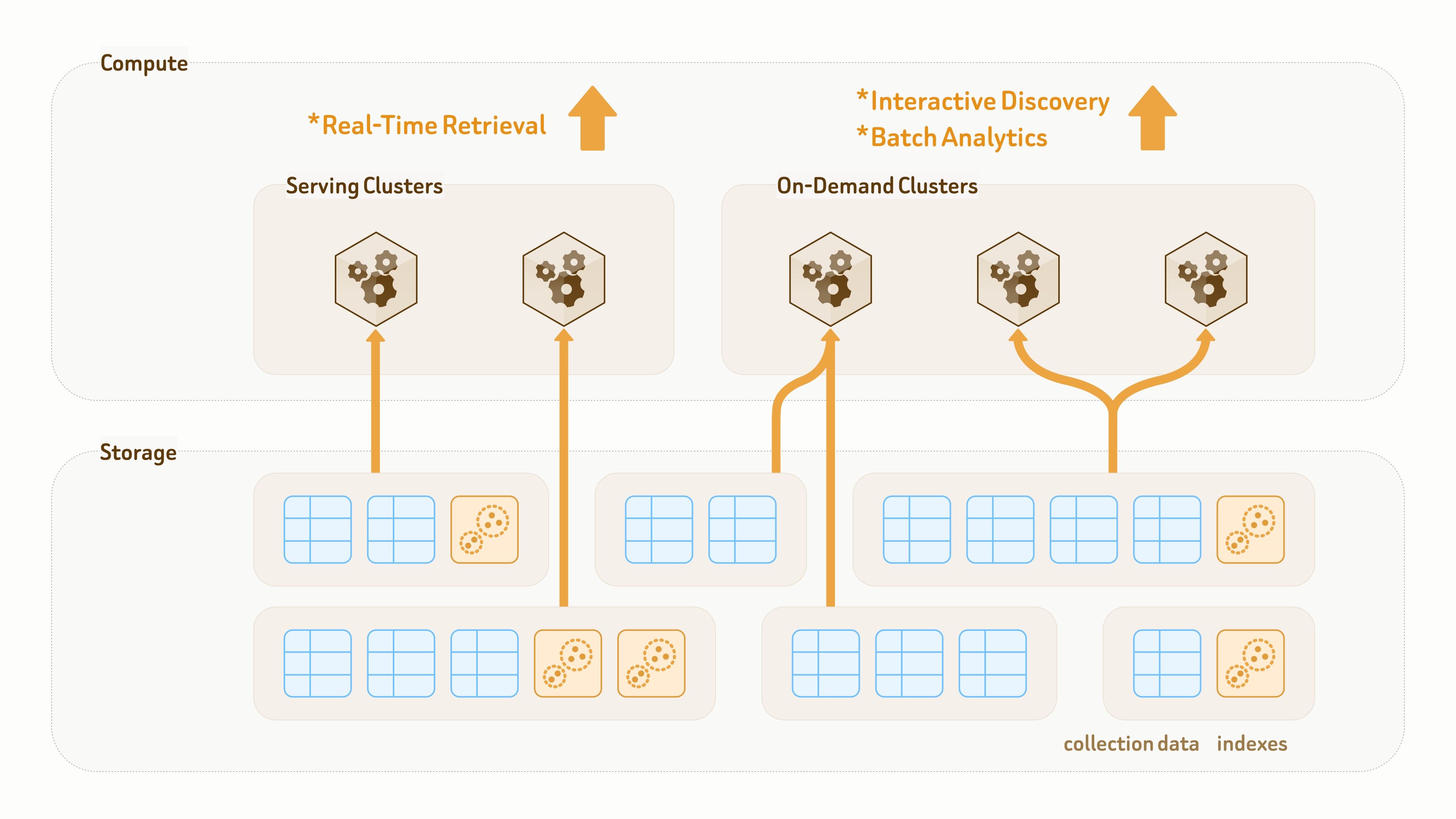
A differenza dei data lake tradizionali progettati principalmente per lo storage, il livello dati di Zilliz Vector Lakebase è progettato sia per la persistenza sia per l'esecuzione delle query. Collezioni e indici sono disaccoppiati dai cluster di calcolo, consentendo agli stessi dati e indici di essere montati tramite accesso zero-copy da cluster diversi per diversi carichi di lavoro di query e analytics.
Per applicazioni AI e agent con modelli di dati in continua evoluzione — come l'aggiunta frequente di nuove etichette e funzionalità o il cambio di modelli di embedding — Zilliz fornisce un meccanismo fluido e ad alta velocità per l'evoluzione dello schema e il backfill dei dati.
I nuovi campi vengono sottoposti a backfill e allineati da risorse di calcolo della piattaforma in pool, quindi esposti ai cluster di query tramite aggiornamenti dei metadati. Un backfill di 100M righe può generalmente essere completato in pochi minuti a una cifra.
Poiché la maggior parte del lavoro è gestita da risorse di calcolo lato piattaforma, i cluster utente esistenti rimangono inalterati e possono continuare a servire traffico di lettura e scrittura durante tutto il processo.
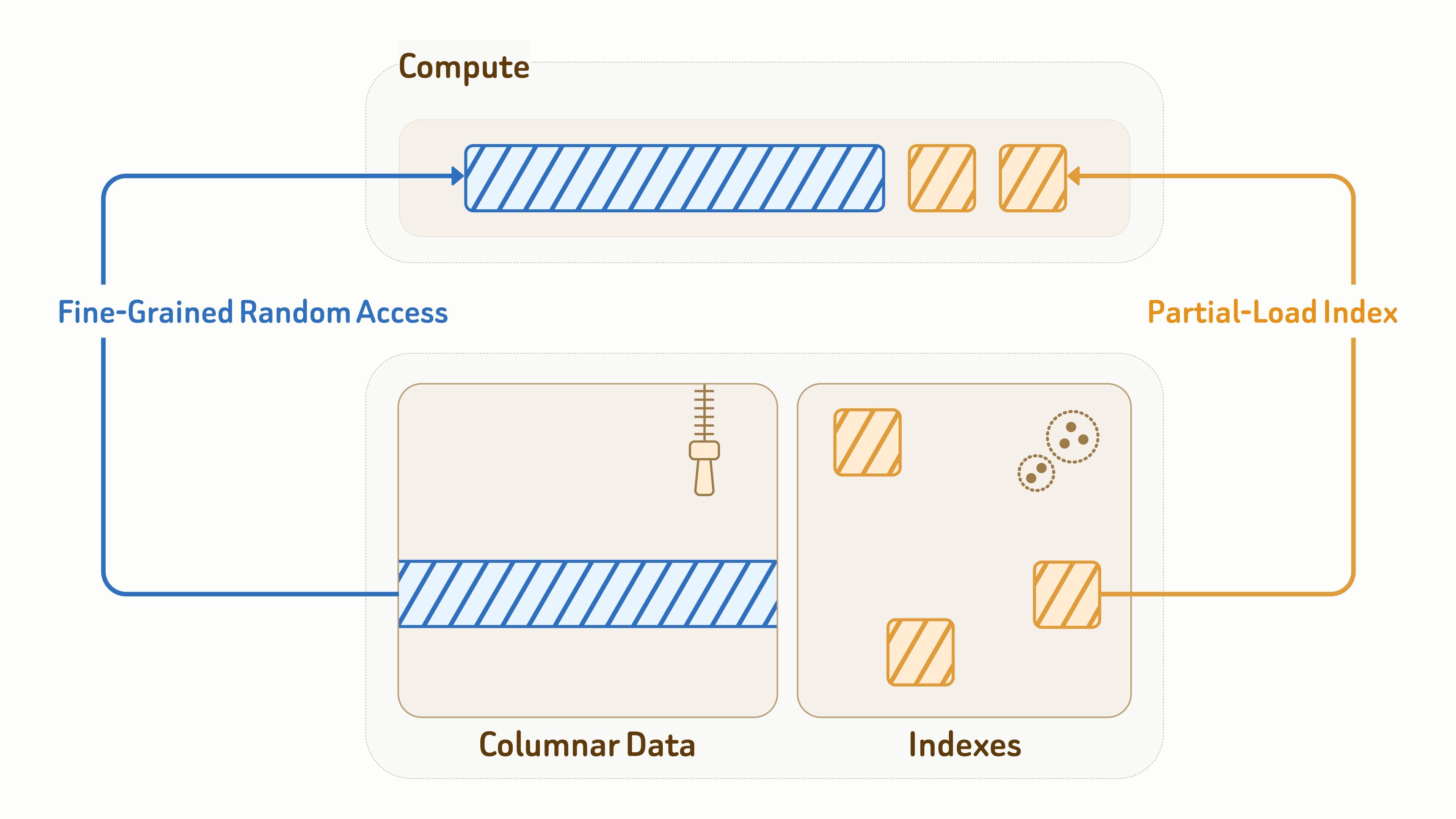
Poiché il livello dati serve anche direttamente i carichi di lavoro di query, un I/O efficiente è fondamentale sia per la latenza sia per la produttività.
Per i dati delle collection, Zilliz utilizza il formato aperto Vortex per il layout di archiviazione colonnare, combinando una codifica efficiente con accesso casuale granulare ai frammenti di dati — significativamente più veloce di Lance e Parquet per le letture casuali.
Per gli indici, Zilliz fornisce progettazioni di algoritmi di indicizzazione consapevoli dell’object storage, con layout e pattern di accesso profondamente ottimizzati per un I/O efficiente, inclusi indici vettoriali, indici invertiti BM25 e indici JSON.
Durante l’esecuzione delle query, i nodi di calcolo caricano solo parzialmente le pagine dell’indice e le entità di dati interessate dalla query. In combinazione con caching e data pruning, ciò riduce significativamente la read amplification di oltre il 90%.
Casi d’uso principali di Vector Lakebase
Gli scenari applicativi tipici per Vector Lakebase includono, a titolo esemplificativo ma non esaustivo:
Carichi di lavoro di serving in tempo reale:
- Memoria degli agenti e recupero di strategie critici per la latenza.
- Basi di conoscenza di domini verticali per settori specializzati come legale, sanità, finanza e altri.
- Motori di ricerca AI su scala web.
- Sistemi di raccomandazione a throughput ultra-elevato.
- Scheduling dinamico di dati hot/cold a livello di secondi tra tier di storage.
- Tier di servizio differenziati sia per utenti enterprise premium sia per pool di utenti gratuiti su larga scala.
Carichi di lavoro di scoperta iterativa:
- Analisi della qualità dei servizi AI e individuazione di problemi su dati di feedback, note generate da agenti, log e altri dati multi-sorgente.
- Esplorazione efficiente di dataset su larga scala.
- Deep research iterativa multi-step.
Carichi di lavoro di analytics batch:
- Deduplicazione e clustering di corpus su scala ultra-ampia.
- Aggiunta di funzionalità di ricerca full-spectrum a Spark e Ray per filtering, retrieval e pipeline di query a due fasi coarse-to-rerank efficienti.
- Preparazione di dataset per training e fine-tuning.
Casi ibridi:
- Indicizzazione e retrieval accelerati su tabelle di data lake esistenti come Lance e Iceberg.
- Modelli di dati in continua evoluzione con frequenti backfill su larga scala.
- Modellazione di wide-table semantiche multi-modali, unificando vettori, metadati, riepiloghi generati da LLM e campi strutturati in tabelle entity-centric con versioning coerente e gestione della lineage.
Prova Zilliz Vector Lakebase
Per ulteriori informazioni su Vector Lakebase e sugli ultimi aggiornamenti, visita il sito web di Zilliz o esplora la documentazione di Zilliz Cloud. Se l’architettura o i casi d’uso descritti in questo articolo sono rilevanti per il tuo lavoro, contatta il team Zilliz per una discussione tecnica più approfondita.

Continua a leggere

Top 10 Context Engineering Techniques You Should Know for Production RAG
A practical guide to context engineering for production LLM systems, covering RAG, context processing, memory, agents, and multimodal context.

VidTok: Rethinking Video Processing with Compact Tokenization
VidTok tokenizes videos to reduce redundancy while preserving spatial and temporal details for efficient processing.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.