




SuperGLUE: A Comprehensive Benchmark for Advanced NLP Evaluation
SuperGLUE: A Comprehensive Benchmark for Advanced NLP Evaluation
TL; DR
SuperGLUE (Super General Language Understanding Evaluation) is a benchmark designed to evaluate the performance of natural language understanding (NLU) models. Building on its predecessor, GLUE, it introduces more challenging tasks to assess a model’s ability to handle complex linguistic reasoning, such as question answering, coreference resolution, and inference. SuperGLUE includes a diverse set of datasets and metrics, as well as testing skills like contextual understanding, knowledge retrieval, and multi-task learning. Developed to push the boundaries of NLU, it reflects tasks closer to human reasoning. Achieving high scores on SuperGLUE indicates a model’s robustness and effectiveness in tackling real-world language challenges.
Introduction
Natural Language Processing (NLP) has transformed how machines interact with humans, from chatbots to recommendation systems. Models such as ELMo, BERT, and GPT have redefined the threshold of language understanding, improving human language modeling and understanding. These transformations paved the way for the GLUE benchmark, a systematic means of evaluation that assesses the competency of language models over various tasks.
However, as the NLP models get smarter, it becomes clear that we’ve faced a tougher challenge. This is where ****SuperGLUE comes in–with greater, more demanding aims, it lays out a new array of tasks based on reasoning, commonsense understanding, and nuanced contextual interpretation. SuperGLUE tests the ability of any model to solve tough, real-world language problems, hence putting a much harsher test on the NLP models.
In this article, we’ll explore the unique characteristics of SuperGLUE, the tasks it includes, and how it’s driving the development of even more sophisticated and reliable NLP models.
What is SuperGLUE?
SuperGLUE, short for Super General Language Understanding Evaluation, is a benchmark created to test how well NLP models handle a wide range of complex language understanding tasks. It’s essentially an upgraded version of GLUE, designed to raise the bar. While GLUE focuses on simpler tasks, SuperGLUE includes more sophisticated challenges that demand deeper reasoning, commonsense knowledge, and understanding of context. For example, while a GLUE task might evaluate whether two sentences are semantically similar, a SuperGLUE task like the Winograd Schema Challenge (WSC) requires resolving ambiguous pronouns using commonsense reasoning.
SuperGLUE retains two of the most challenging tasks from GLUE (RTE and WNLI) and introduces six entirely new tasks designed to push models beyond simple pattern matching and go into semantic and pragmatic knowledge.
What are the Goals of SuperGLUE?
Testing Advanced Reasoning: SuperGLUE goes beyond basic language processing—it’s designed to see if models can reason, make inferences, and use commonsense knowledge in complex scenarios.
Encouraging NLP Progress: By introducing harder tasks, SuperGLUE motivates researchers to develop more advanced and capable machine learning techniques.
Creating a Well-Rounded Benchmark: Unlike GLUE, which focuses on simpler challenges, SuperGLUE provides a more realistic and comprehensive way to test how models perform with complex, real-world inputs.
Setting a Higher Bar for NLP: SuperGLUE was built with the future in mind—it’s challenging enough that even today’s best models have plenty of room to improve, making it a valuable tool for tracking progress in NLP.
How SuperGLUE Works
SuperGLUE evaluates NLP models by challenging their linguistic skills. These tasks require models to do more than just classify sentences or predict individual words—they must tackle real-world complexities. This includes coreference resolution (figuring out which words or phrases refer to the same thing), reasoning (drawing logical conclusions from the text), and understanding the relationships between entities in context. Each task measures how well models handle human language's nuanced and sophisticated demands.
A Detailed Overview of Tasks
SuperGLUE is a superset of many tasks, which we will cover in this section. Before that, we will see different evaluation metrics required to score the model on its performance.
Evaluation Metrics
SuperGLUE employs several evaluation metrics depending on the task:
Exact Match (EM): Used for tasks to evaluate whether the predicted answer exactly matches the expected answer.
F1 Score: Measures precision and recall where multiple correct answers are possible.
Accuracy: The proportion of correctly predicted examples used in simpler classification tasks like BoolQ.
Macro-Averaged F1: An average of F1 scores across classes, ensuring balanced evaluation even with class imbalance.
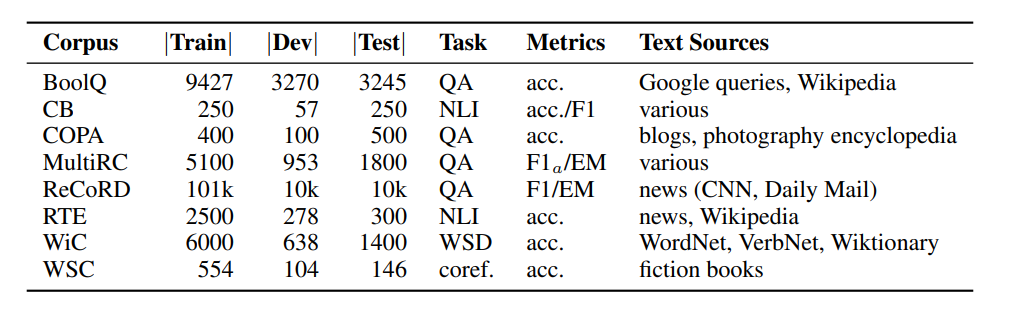 Figure- SuperGLUE Benchmark- Summary table of SuperGLUE tasks, including corpus sizes, metrics, and text sources for each task..png
Figure- SuperGLUE Benchmark- Summary table of SuperGLUE tasks, including corpus sizes, metrics, and text sources for each task..png
Figure: SuperGLUE Benchmark: Summary table of SuperGLUE tasks, including corpus sizes, metrics, and text sources for each task.
Let's explore the detailed overview of SuperGLUE's tasks to understand the depth and variety of its challenges.
- BoolQ (Boolean Questions)
BoolQ is a binary question-answering task where the model determines whether a yes/no question is true based on a given passage. Here are the input, output and metric of the task:
| Input | Output | Metric |
|---|---|---|
| A passage and a yes/no question about the passage. | A boolean value (True for yes, False for no). | Accuracy |
Here’s an example:
Passage: "Barq's is a soft drink that contains caffeine and is bottled by Coca-Cola."
Question: "Does Barq's root beer contain caffeine?"
Output: True
- CB (CommitmentBank)
CB involves evaluating whether an embedded clause within a text is likely true (entailment), false (contradiction), or indeterminate (neutral).
| Input | Output | Metric |
|---|---|---|
| A premise and a hypothesis. | A label (entailment, neutral, or contradiction). | Accuracy and Macro-averaged F1. |
Here’s an example:
Premise: "She said she might attend the meeting."
Hypothesis: "She is certain to attend the meeting."
Output: Contradiction
- COPA (Choice of Plausible Alternatives)
COPA is a causal reasoning task where the model determines the most plausible cause or effect of a given premise from two alternatives.
| Input | Output | Metric |
|---|---|---|
| A premise and two alternatives (cause/effect). | The more plausible alternative (1 or 2). | Accuracy |
Let’s look at an example:
Premise: "The grass is wet."
Alternative 1: "It rained last night."
Alternative 2: "The sun was shining brightly."
Output: 1
- MultiRC (Multi-sentence Reading Comprehension)
MultiRC involves answering questions based on a passage, where each question may have multiple correct answers.
| Input | Output | Metric |
|---|---|---|
| A passage, a question, and a set of possible answers. | A binary label (True or False) for each answer. | F1 and Exact Match. |
Here’s a simple example:
Passage: "Susan invited her friends to a party. One of her friends was sick but later attended."
Question: "Did the sick friend attend the party?"
Answers: "Yes", "No"
Output: Yes
- ReCoRD (Reading Comprehension with Commonsense Reasoning Dataset)
ReCoRD is a Cloze-style reading comprehension task requiring commonsense reasoning to predict masked entities in a passage.
| Input | Output | Metric |
|---|---|---|
| A passage with masked entities and a query. | The correct entity from a list of candidates. | F1 and EM. |
Here’s a simple example:
Passage: "Tesla was founded by
Query: "Who founded Tesla?"
Candidates: "Elon Musk", "Nikola Tesla", "Thomas Edison"
Output: Elon Musk
- RTE (Recognizing Textual Entailment)
RTE determines whether a hypothesis is true, false, or indeterminate based on a given premise.
| Input | Output | Metric |
|---|---|---|
| A premise and a hypothesis. | A label (entailment, neutral, or contradiction). | Accuracy |
Here’s an example:
Premise: "Dana Reeve, the widow of Christopher Reeve, passed away at 44."
Hypothesis: "Dana Reeve was 44 years old when she died."
Output: Entailment
- WiC (Word-in-Context)
WiC tests word sense disambiguation by determining whether a word is used with the same meaning in two different contexts.
| Input | Output | Metric |
|---|---|---|
| Two sentences containing the same target word. | A binary label (True for same sense, False for different sense). | Accuracy |
Let’s look at an example:
Sentence 1: "He nailed the boards to the wall."
Sentence 2: "The chessboard was beautifully crafted."
Target Word: "board"
Output: False
- WSC (Winograd Schema Challenge)
WSC is a coreference resolution task where the model identifies the correct referent of an ambiguous pronoun using commonsense reasoning.
| Input | Output | Metric |
|---|---|---|
| A sentence containing an ambiguous pronoun. | The correct referent. | Accuracy |
Here’s an example:
Sentence: "Mark gave Ted a book, but he didn’t like it."
Pronoun: "he"
Output: Ted
The above tasks in SuperGLUE challenge NLP models beyond mere language understanding, for which any system is supposed to build nuanced reasoning and solve real-world problems. Thus, SuperGLUE evaluates the model based on understanding, reasoning, and effectively applying common sense knowledge. It provides a comprehensive evaluation framework that captures both the precision and recall of models across diverse language understanding challenges.
Implementation Example
Below is an example of loading and interacting with SuperGLUE task ReCoRD using the Hugging Face library:
from datasets import load_dataset
# Load the ReCoRD task from SuperGLUE
dataset = load_dataset("super_glue", "record", trust_remote_code = True
)
# Access the training data
train_data = dataset['train']
# Example data point
example = train_data[0]
print(f"Passage: {example['passage']}")
print(f"Query with masked entity: {example['query']}")
The functionload_dataset loads the ReCoRD task. The input includes a passage and a query with a masked entity that needs to be resolved. The model aims to predict the masked entity correctly, demonstrating its ability to comprehend the passage and apply commonsense reasoning.
 Figure- Output of Implemented Example.png
Figure- Output of Implemented Example.png
Figure: Output of Implemented Example
SuperGLUE vs. GLUE: Key Differences
SuperGLUE improves upon GLUE by introducing significantly more challenging tasks reflective of real-world language understanding.
| Features | GLUE | SuperGLUE |
|---|---|---|
| Task Complexity | Basic linguistic tasks (e.g., sentiment analysis) | Complex tasks requiring reasoning and commonsense |
| Dataset Saturation | Performance nearing the human level | Ample headroom for model improvements |
| Reasoning Requirement | Minimal reasoning required | High-level reasoning and inference are necessary |
| Task Diversity | Mainly sentence classification and similarity tasks | Includes QA, coreference, and reading comprehension |
| Real-World Application | Limited real-world reflection | Tasks designed to emulate real-world language challenges |
Benefits and Challenges of SuperGLUE
SuperGLUE supersedes how NLP models have been evaluated by shifting focus to their ability to solve real-world tasks nuancedly that demand reasoning and advanced context. Let's discuss some concrete benefits that SuperGLUE confers on NLP and the challenges researchers face in using it to its fullest potential.
Benefits
Tests Reasoning and Commonsense: SuperGLUE includes tasks that require models to utilize commonsense knowledge. For example, the Winograd Schema Challenge (WSC) tests pronoun resolution using commonsense, while the COPA task assesses causal reasoning by choosing the most plausible cause or effect in a given scenario. These tasks make them more capable in real-world scenarios.
Addresses GLUE Limitations: By including more complex tasks, SuperGLUE overcomes GLUE's saturation, where models achieved near-human performance on simpler tasks, making it less effective for distinguishing advancements.
Promotes Model Explainability: SuperGLUE's complex tasks encourage the development of models that perform well and provide more interpretable outputs, helping researchers understand how and why models make specific predictions.
Reflects Real-World Problems: SuperGLUE's tasks are designed to reflect the problems models encounter in applications like reading comprehension and dialogue systems. For instance, the ReCoRD task tests commonsense reasoning to infer missing information, while WSC evaluates resolving ambiguous pronouns—key capabilities for virtual assistants and conversational AI.
Provides Insightful Error Analysis: SuperGLUE allows researchers to examine how and where models fail by providing diverse and challenging tasks highlighting specific weaknesses. This detailed error analysis helps identify areas where models struggle, such as reasoning, commonsense understanding, or contextual comprehension, enabling targeted improvements to make the models more robust and reliable.
Challenges
High Computational Costs: Training models on SuperGLUE can be computationally expensive due to the complexity of tasks. Utilizing optimized architectures and cloud-based infrastructure can help manage resource demands effectively.
Complex Fine-Tuning: Each task in SuperGLUE may require different fine-tuning strategies. Multi-task learning approaches and transfer learning can help streamline this process. Multi-task learning trains a model on related tasks to improve generalization, while transfer learning applies knowledge from one task to enhance performance on another, minimizing the need for extensive data and training.
Small Dataset Sizes: Some SuperGLUE tasks come with limited data, which increases the risk of models overfitting during training. This challenge can be addressed by employing techniques like data augmentation to create more diverse training samples and regularization to improve model generalization.
Overemphasis on Leaderboards: While leaderboard rankings showcase model performance, focusing solely on these scores can detract from the practical value of the models. Shifting attention toward real-world applications helps ensure that models are competitive and impactful in practical scenarios.
Difficulty in Comparing Results: Variability in implementations, hardware, and hyperparameters can make it challenging to compare results across research groups fairly. By standardizing evaluation protocols, sharing codebases, and using common benchmarks, we can achieve more consistent and fair comparisons.
Use Cases for SuperGLUE
SuperGLUE is an important benchmark that helps improve NLP by challenging models with tasks based on real-world complexities. Examples of such uses can range from driving better conversational AI and reasoning systems to semantic search.
SuperGLUE has numerous applications in NLP and beyond:
Conversational AI: SuperGLUE enhances the development of virtual assistants by providing benchmarks that test models’ ability to understand nuanced queries with better reasoning and common sense.
Advanced Reasoning Systems: SuperGLUE powers the creation of decision support tools by evaluating and improving models' logical inference capabilities.
Reading Comprehension: SuperGLUE enables NLP models to analyze and summarize lengthy documents accurately by challenging them with tasks that require advanced comprehension and contextual understanding, aiding research and education.
Knowledge Representation and Inference: SuperGLUE assists in building more robust knowledge graphs by testing models' ability to understand relationships and apply commonsense reasoning, supporting search engines and recommendation systems.
Semantic Search and Vector Databases: SuperGLUE improves semantic search accuracy by enabling models to handle complex, large-scale information retrieval tasks effectively.
Tools Supporting SuperGLUE
The advanced tasks and benchmarks of SuperGLUE led to the development of other tools and platforms designed to ease its implementation and evaluation. These tools help researchers and developers make better decisions about accessing data, training models, and analyzing results.
Let’s look at the tools that support and enhance the adoption and interaction with SuperGLUE.
Tools
Hugging Face Datasets: Provides an easy way to load and interact with SuperGLUE tasks, streamlining model development and testing.
TensorFlow Datasets: Offers preformatted versions of SuperGLUE tasks, integrating well with TensorFlow-based models.
AllenNLP: Supplies modules and components for NLP tasks, making it simpler to experiment with SuperGLUE.
Evaluating AI Models with SuperGLUE and Enhancing Them with RAG
Benchmarks like SuperGLUE are essential for assessing the capabilities of large language models (LLMs). They provide a standardized framework to measure a model’s performance across diverse tasks and facilitate direct comparisons between models. By highlighting strengths like reasoning and exposing weaknesses such as struggles with complex reasoning or domain-specific tasks, SuperGLUE helps researchers identify areas for improvement. These insights enable fine-tuning, improving a model’s understanding and content generation capabilities.
However, while SuperGLUE is valuable for improving LLMs, it’s not a cure-all. LLMs have inherent limitations, regardless of how well they perform on benchmarks. They are trained on static, offline datasets and lack access to real-time or domain-specific information. This can lead to hallucinations, where models generate inaccurate or fabricated answers. These shortcomings become even more problematic when addressing proprietary or highly specialized queries.
Introducing RAG: A Solution to Enhance LLM Responses
To address these challenges, Retrieval-Augmented Generation (RAG) offers a powerful solution. RAG enhances large language models (LLMs) by combining their generative capabilities with the ability to retrieve domain-specific information from external knowledge bases stored in a vector database like Milvus or Zilliz Cloud. When a user asks a question, the RAG system searches the database for relevant information and uses this information to generate a more accurate response. Let’s take a look at how the RAG process works.
 Figure- RAG workflow.png
Figure- RAG workflow.png
A RAG system usually consists of three key components: an embedding model, a vector database, and an LLM.
The embedding model converts documents into vector embeddings, which are stored in a vector database like Milvus.
When a user asks a question, the system transforms the query into a vector using the same embedding model.
The vector database then performs a similarity search to retrieve the most relevant information. This retrieved information is combined with the original question to form a "question with context," which is then sent to the LLM.
The LLM processes this enriched input to generate a more accurate and contextually relevant answer.
This approach bridges the gap between static LLMs and real-time, domain-specific needs.
FAQs of SuperGLUE
What makes SuperGLUE more difficult than GLUE? SuperGLUE builds upon GLUE by introducing reasoning and commonsense tasks that extend far beyond tasks found in GLUE.
Which models perform best on SuperGLUE? Transformer-based models excel on SuperGLUE due to their self-attention mechanism, which captures context and long-range dependencies, extensive pretraining on large datasets, scalability, and adaptability through transfer learning.
What are the computational requirements for SuperGLUE? Training models on SuperGLUE requires significant computational resources due to the complexity of the tasks, which demand extensive processing power for fine-tuning, reasoning, and handling large datasets effectively.
Can SuperGLUE be applied to domain-specific tasks? While it focuses on generalization, customization for specific domains is possible with additional fine-tuning with domain-specific data.
How is SuperGLUE relevant to modern AI applications? It sets a standard for evaluating models in real-world applications like semantic search and conversational AI.
Related Resources
- TL; DR
- Introduction
- What is SuperGLUE?
- How SuperGLUE Works
- SuperGLUE vs. GLUE: Key Differences
- Benefits and Challenges of SuperGLUE
- Use Cases for SuperGLUE
- Tools Supporting SuperGLUE
- Evaluating AI Models with SuperGLUE and Enhancing Them with RAG
- FAQs of SuperGLUE
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free