




What Is a NoSQL Database? A Guide to Modern Data Storage

What Is a NoSQL Database? A Guide to Modern Data Storage
What is a NoSQL Database?
A NoSQL database (not only SQL) provides flexible, schema-less data storage designed to handle unstructured or semi-structured data such as JSON, documents, or graphs. Unlike traditional relational databases (SQL), which use structured tables and predefined schemas, NoSQL databases are built for scalability, performance, and agility in modern applications. They support diverse data models, including key-value, document, column-family, and graph formats. Commonly used in scenarios like real-time analytics, content management, and IoT, NoSQL databases can handle large volumes of data across distributed systems. Popular examples include MongoDB, Cassandra, Redis, and DynamoDB.
The Rise of NoSQL Databases
NoSQL databases became important because they solved problems that traditional SQL databases couldn’t handle. Traditional databases use fixed structures, like tables with rows and columns, which work fine for organized data. But today, many applications deal with unstructured or semi-structured data, such as social media posts and sensor data from IoT devices. This data doesn’t fit neatly into tables, making traditional databases less effective.
One major issue traditional databases face is scalability. When data grows rapidly, it’s harder and more expensive to scale them. NoSQL databases solve this problem by being designed for horizontal scaling, which means they can easily spread data across many servers. This makes them perfect for applications that need to handle massive amounts of data without slowing down.
Types of NoSQL Databases
NoSQL databases come in several types, each designed to solve specific data management challenges. Let’s explore the four main types of NoSQL databases and see how they work with real-world examples.
1. Document-Based Databases
Document-based databases store data as documents, typically in formats like JSON, BSON, or XML. Each document is self-contained and can have a unique structure, which makes these databases flexible for handling unstructured or semi-structured data.
How It Works: Each document has fields and values, which can include text, numbers, arrays, or even nested documents.
Example: MongoDB, Couchbase.
Use Cases:
E-commerce systems: Storing product catalogs, where each document represents a product with fields like name, price, and description.
Content Management Systems: Managing articles, blogs, or multimedia content with varying attributes.
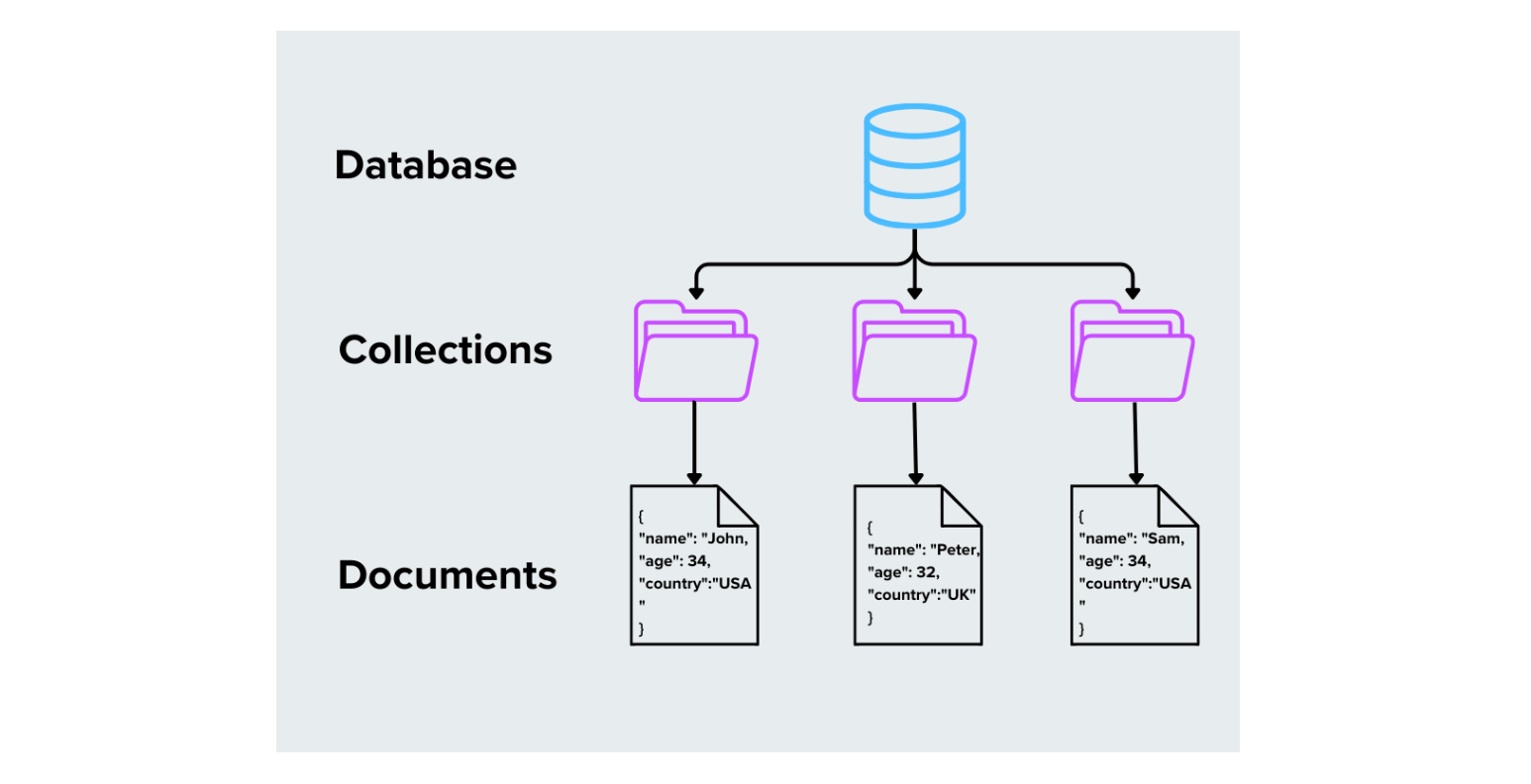 Figure- Document-based Databases
Figure- Document-based Databases
Figure: Document-based Databases
2. Key-Value Stores
Key-value databases use a unique key to retrieve values, which can be anything from simple text to complex data structures. This design is highly efficient for fast data access.
How It Works: Think of it like a dictionary—each key maps directly to a value.
Examples are Redis, Amazon DynamoDB, and Firebase.
Use Cases:
Caching: Storing temporary data for quick access, like user sessions or recently viewed products.
Real-Time Applications: Managing gaming leaderboards or chat messages, where speed is critical.
 Figure- Key-value Stores Databases
Figure- Key-value Stores Databases
Figure: Key-value Stores Databases
3. Column-Family Stores
Column-family stores organize data into rows and columns, but unlike traditional databases, columns can be grouped into families. This structure makes them ideal for reading and writing large datasets.
How It Works: Instead of having a fixed schema, rows in a column-family store can have different sets of columns grouped into families based on relevance.
Example: Apache Cassandra, HBase.
Use Cases:
Time-Series Data: Storing logs or metrics from servers and applications where new entries are continuously added.
Big Data Applications: Powering systems like recommendation engines or analytics platforms that process massive amounts of structured data.
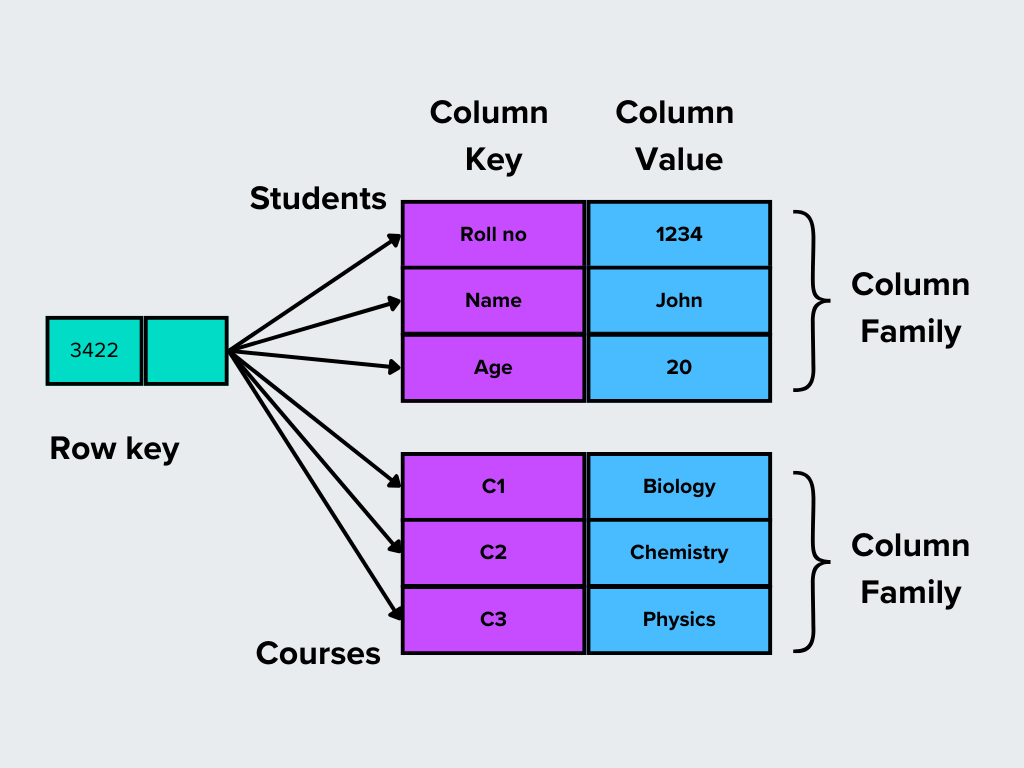 Figure- Column-family databases.png
Figure- Column-family databases.png
Figure: Column-family databases
4. Graph Databases
Graph databases use nodes to represent entities and edges to represent the connections between them. This makes them suitable for applications where understanding and analyzing relationships is key.
How It Works: Data is stored as nodes (entities), edges (relationships), and properties (details about nodes and edges).
Example: Neo4j, Amazon Neptune.
Use Cases:
Social Networks: Representing users as nodes and their connections (friends, followers) as edges.
Recommendation Systems: Identifying related products or content based on user behavior and preferences.
Fraud Detection: Analyzing patterns in financial transactions to uncover suspicious relationships.
 Figure- Graph-databases.png
Figure- Graph-databases.png
Figure: Graph-databases
The following table provides quick insights into the types of NoSQL databases along with their working, examples, and use cases.
| Type | How It Works | Examples | Key Use Cases |
|---|---|---|---|
| Document-Based | Stores data as flexible documents. | MongoDB, Firebase, Couchbase | E-commerce, content management. |
| Key-Value Stores | Maps keys to values for quick access. | Redis, DynamoDB | Caching real-time data like gaming or sessions. |
| Column-Family | Groups columns into families. | Cassandra, HBase | Time-series data, big data analytics. |
| Graph Databases | Focuses on data relationships. | Neo4j, Neptune | Social networks, recommendation systems, fraud. |
Table: Types of NoSQL databases
Advantages of NoSQL Databases
NoSQL databases provide several advantages for modern applications dealing with massive, diverse, and dynamic data. For example:
1. Scalability
One of the biggest strengths of NoSQL databases is their ability to scale horizontally. This means you can add more servers to distribute the data and workload rather than relying on a single server with more power (vertical scaling). Horizontal scaling is cost-effective and ensures the system can handle growing amounts of data and traffic. Applications like social media, e-commerce, or IoT generate massive data that needs to be stored and processed without slowing down. NoSQL databases are designed to spread this load across multiple machines seamlessly.
- Example: An online retailer can handle peak shopping seasons by adding more servers to their NoSQL database cluster instead of upgrading to a single server.
2. Flexibility in Data Modeling
NoSQL databases store data in a way that matches your application’s needs. Unlike relational databases that use rigid tables and predefined columns, NoSQL databases let you work with data in various formats, such as documents, key-value pairs, graphs, or columns.
This flexibility is perfect for applications where data structures change frequently or need to support diverse types of data.
- Example: A content management system can store articles, videos, and user profiles in the same database without forcing them into a fixed format.
3. Schema-Less Design for Dynamic Applications
Traditional databases require a predefined schema, meaning you have to decide how your data will be structured before storing it. NoSQL databases, on the other hand, are schema-less, which means you can store data without defining a structure beforehand. This makes it easy to adapt to changes in your application. This is useful for startups or rapidly evolving applications where requirements change frequently.
- Example: A mobile app adding new features like payment integrations or chat functionality can easily store new types of data without needing to redesign the database.
4. Performance Benefits
NoSQL databases are optimized for specific types of workloads, such as high-speed reads and writes, handling unstructured data, and real-time processing. Unlike relational databases that can slow down under heavy loads, NoSQL databases are built to perform consistently. Applications requiring fast response times, such as gaming, financial trading, or real-time analytics, can rely on NoSQL databases for their speed and efficiency.
- Example: A gaming platform can use a key-value store like Redis to handle millions of concurrent players’ session data with minimal latency.
5. Support for Large-Scale, Distributed Systems
NoSQL databases are designed for distributed systems, where data is stored across multiple servers in different locations. This makes them highly reliable and ensures data availability even if one server fails. Distributed systems also improve performance by reducing latency through localized data access.
Large-scale applications like global e-commerce platforms or content delivery networks need to ensure that data is always accessible, no matter where the user is located.
- Example: An international video streaming service can use a distributed NoSQL database to ensure fast and reliable access to content for users across different regions.
Challenges and Limitations of NoSQL Databases
While NoSQL databases offer many advantages, they are not without their challenges and limitations:
1. Lack of Standardization
NoSQL databases do not follow a universal standard like SQL does for relational databases. Each NoSQL system has its own query language, APIs, and design principles. The lack of standardization can make it harder to switch between NoSQL systems or integrate them with other tools and platforms.
2. Data Consistency Issues in Distributed Systems
Many NoSQL databases prioritize availability and partition tolerance (based on the CAP theorem) over consistency. This means they may allow temporary inconsistencies in data across distributed servers. Applications that require strict consistency, such as financial systems or critical transactional platforms, may face difficulties with NoSQL databases.
3. Learning Curve
Developers used to working with relational databases may find the NoSQL paradigm unfamiliar. Concepts like schema-less design, eventual consistency, or specific data models can require a shift in thinking. This learning curve can slow development and increase the risk of design errors in NoSQL-based systems.
4. Use-Case Limitations
NoSQL databases are not always suitable for applications that require complex, multi-step transactions or strong ACID (Atomicity, Consistency, Isolation, Durability) compliance. Relational databases are better suited for tasks like maintaining inventory levels or processing financial transactions, where strong guarantees about data integrity are critical.
Hybrid Approaches and Multi-Model Databases
In the evolving world of data management, organizations often need the reliability and structure of SQL databases alongside the flexibility and scalability of NoSQL. Hybrid approaches and multi-model databases provide a solution by combining the best features, allowing developers to work with diverse data and workloads without needing multiple database systems.
A multi-model database is a single database system that supports multiple types of data models. For example, it can store relational data in tables while handling documents, key-value pairs, or graphs—all within the same system. Multi-model databases eliminate the need to maintain separate databases for different data types, reducing complexity and operational overhead.
Examples:
ArangoDB: Supports document, graph, and key-value models.
Couchbase: Combines document and key-value storage with SQL-like querying.
Oracle Database: Provides support for relational, JSON, and spatial data.
Vector Database: The Backbone of Modern AI Applications
While NoSQL databases handle unstructured data like documents and graphs, vector databases take one step further to manage data through high-dimensional vectors. These vectors are mathematical representations of complex unstructured data, such as text, images, or audio, used extensively in AI and machine learning. Vector databases are purpose-built to store, index, and query these embeddings, enabling tasks like similarity searches, image recognition, and natural language processing (NLP). Unlike traditional databases, which rely on exact matches, vector databases focus on finding "similar" data, making them critical for AI-powered applications like recommendation engines, chatbots, and retrieval augmented generation (RAG).
Milvus and Zilliz Cloud ****(managed Milvus) are primary examples of modern vector databases. Milvus is an open-source vector database that can handle billion-scale vector data and offers a variety of enterprise-ready features, such as scalability, multi-tenancy, hybrid search (full-text search, sparse & dense vector searches, vector search with metadata filtering, etc), and seamless integration with AI ecosystem. Zilliz Cloud provides a fully managed service of Milvus so that developers can eliminate the complexity of maintenance and deployment and focus on their app development and business. Zilliz Cloud also provides 10x times faster performance in many situations.
SQL vs. NoSQL vs Vector Databases
The table below highlights the key distinctions between SQL, NoSQL, and vector databases:
| Feature | SQL Databases | NoSQL Databases | Vector Databases |
|---|---|---|---|
| Data Model | Relational (tables with rows and columns). | Non-relational (document, key-value, graph, etc.). | Vector-based (high-dimensional vector embeddings). |
| Schema | Rigid, predefined schema. | Flexible, dynamic schema. | Schema-less focuses on vector embeddings. |
| Query Language | Structured Query Language (SQL). | Varies by system (NoSQL query languages, APIs etc.). | Vector search methods (e.g., ANN, cosine similarity). |
| Data Type Focus | Structured data. | Semi-structured and unstructured data. | Unstructured data is represented as vectors. |
| Scalability | Vertical scaling (limited horizontal scaling). | Horizontal scaling (adding more servers). | Highly scalable with both vertical and horizontal distribution. (note: not all vector databases can offer both) |
| Use Case Examples | Transactional systems, analytics. | Big data, real-time web apps, distributed systems. | AI/ML applications, similarity searches, and RAG. |
| Performance | Optimized for complex queries and joins. | Optimized for speed and scalability. | Optimized for high-dimensional vector similarity search. |
| Typical Applications | Banking, ERP, CRM systems. | Social networks, IoT, content management. | Image retrieval, recommendation engines, NLP, RAG. |
| Storage Format | Rows and columns. | Varies (JSON, BSON, etc.). | High-dimensional vectors. |
Table: SQL vs. NoSQL vs Vector Database
When to Use SQL, NoSQL, or Vector Databases?
Choosing between SQL, NoSQL, and vector databases depends on your application’s specific needs, including data structure, scalability, and the nature of the workload. The points below outline when each type is most suitable.
When to Use SQL?
Applications requiring consistent data and complex relationships.
Systems with a fixed schema and predictable data needs.
Examples: Banking, ERP systems, and traditional business apps.
When to Use NoSQL?
Applications dealing with large-scale, dynamic, or unstructured data.
Scenarios needing high-speed operations and scalability.
Examples: Social media, IoT, real-time analytics, and big data processing.
When to Use Vector Database?
Applications requiring similarity search for high-dimensional data like images, documents, or audio.
AI/ML workflows involving vector embeddings for tasks like NLP, recommendations, or RAG.
Advanced search systems, such as image recognition or semantic search, for unstructured data.
Conclusion
NoSQL databases have transformed data storage and management by offering flexibility, scalability, and speed for unstructured and semi-structured data. They excel in handling large-scale workloads for applications like IoT, real-time analytics, and big data. On the other hand, vector databases, such as Milvus, are designed for specialized needs like managing high-dimensional vector data for AI and machine learning tasks. Organizations can leverage the right solutions to build robust, future-ready systems tailored to their specific needs by understanding the distinct roles of SQL, NoSQL, and vector databases.
FAQs on NoSQL Database
1. What is a NoSQL database?
A NoSQL database is a non-relational database that handles unstructured, semi-structured, or structured data. Unlike SQL databases, it provides flexibility in data modeling and scalability for modern applications.
2. How do NoSQL databases differ from traditional SQL databases?
NoSQL databases do not rely on fixed schemas or structured tables. They are designed for distributed systems and better for handling large-scale, dynamic, and diverse data.
3. What is Milvus, and how is it different from NoSQL databases?
Milvus is a specialized vector database designed to manage high-dimensional data, such as vectors used in AI and machine learning. Unlike general-purpose NoSQL databases, Milvus focuses specifically on tasks like similarity searches, semantic search, and managing vector embeddings for AI-driven applications.
4. What are the advantages of NoSQL databases?
Key advantages include scalability, flexibility in data modeling, a schema-less design, high performance for specific workloads, and support for distributed systems.
5. When should I use a NoSQL database?
Use NoSQL when dealing with large-scale, unstructured data or applications requiring scalability, such as AI systems, IoT platforms, real-time analytics, or big data processing.
Related Resources
- What is a NoSQL Database?
- The Rise of NoSQL Databases
- Types of NoSQL Databases
- Advantages of NoSQL Databases
- Challenges and Limitations of NoSQL Databases
- Hybrid Approaches and Multi-Model Databases
- Vector Database: The Backbone of Modern AI Applications
- SQL vs. NoSQL vs Vector Databases
- When to Use SQL, NoSQL, or Vector Databases?
- Conclusion
- FAQs on NoSQL Database
- Related Resources
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for Free