




Anatomy of A Cloud Native Vector Database Management System
I am honored that our latest paper, "Manu: A Cloud Native Vector Database Management System" has been accepted by VLDB'22, a top international conference in database research. In this article, I will discuss the key design philosophy and principles behind Manu (project name for Milvus 2.0), a cloud native database that is purpose built for vector data management. You can refer to our previous papers and our GitHub repository for more information.
Background
When we designed Milvus 1.0, our main goal was simply to support vector management and to optimize vector retrieval performance. But as we got to interact with more users over the years, we discovered some common business requirements for vector databases that were difficult to address under the initial framework.
These needs can be grouped into the following categories: ever-changing requirements, a more flexible consistency policy, component-level elasticity, and a simpler, more efficient transaction processing model.
Ever-changing requirements
Business requirements are still not fully defined when it comes to vector data processing.
In the earliest days, K-nearest neighbor search was the most needed. But then, more and more requirements surface, including range search, support for various custom distance metrics, hybrid search, multimodal query, and other increasingly diverse query semantics.
This requires the architecture of a vector database to be flexible enough to support new requirements quickly and agilely.
A more flexible consistency policy
Take content recommendation as an example, this scenario has high requirements for timeliness. New content needs to be recommended to users within a few minutes or even seconds, so the system cannot take a day or more to update its recommendation. In these scenarios, it is difficult to guarantee business results by providing only eventual consistency, whereas there will be a large system overhead if we insist on strong consistency.
To address this problem, we propose the following solution: according to the business requirements, users can specify the maximum delay that can be tolerated before the inserted data can be queried. The system in turn adjusts certain data processing mechanisms to guarantee the final result for the business.
Component-level elasticity
Resource requirements and load intensity vary greatly for each component of a vector database in different applications. For example, vector retrieval and query components require large computational and memory resources to ensure their performance, while data archiving and metadata management only need a few resources to function.
In terms of applications, the most critical requirement for recommendation systems is the ability to make large-scale concurrent queries, and so in these systems, only the query component takes a higher load. Analytics applications, on the other hand, often need to import a large amount of offline data, so the load pressure falls on data insertion and index building, two inter-related components.
In order to improve the utilization of resources, it is necessary that each functional module have independent and elastic scalability, so that the system's resource allocation can be more closely matched to the actual needs of an application.
A simpler, more efficient transaction processing model
Strictly speaking, the transaction model is a space for optimization that can be exploited in the system design rather than a business requirement.
As machine learning evolves in its descriptive power, businesses tend to fuse data from multiple dimensions of a single entity to represent it as a single, unified vector. For example, in user profiling, information such as personal profiles, preferences, and social relationships are fused together. As a result, vector databases can be maintained with only a single table without having to implement JOIN-like operations that are common in traditional databases. In this way, the system only needs to support row-level ACID on a single table and can do without complex transactions that involve multiple tables, leaving a large room for component decoupling and performance optimization in the system.
Objectives
As the second major release of Milvus, Manu is positioned as a cloud-native, distributed vector database system.
When we set out to design Manu, we considered the various business requirements mentioned above and combined them with the common requirements for a distributed system. The results are five broad objectives for Manu: long-term evolvability, tunable consistency, good elasticity, high availability, and high performance.
Long-term evolvability
In order to control the complexity of the system to a manageable level while functionalities evolve, we need to decouple the system well to ensure that individual components can evolve, be added, or be replaced independently, with minimal interference to other components.
Tunable consistency
The system needs to support delta consistency so that users can specify the query visibility delay for newly inserted data. Delta consistency requires that all queries can return all relevant data at least up to the delta time unit, which can be specified by the user application based on business requirements.
Good elasticity
In order to improve the efficiency of resource utilization, the system needs to achieve fine-grained elasticity at the component level, as well as a resource allocation policy that takes into account various hardware dependencies of the components.
High availability and performance
High availability is the basic requirement of all cloud databases, which requires that in case a few service nodes or components fail, other services are not affected, and that the system is capable of effective fault recovery.
High performance is a cliché for vector databases. In the design process, we need to strictly control the overhead generated at the system framework level to ensure good performance.
Manu architecture
Manu adopts a four-layer architecture that enables the decoupling of read from write, stateless from stateful, and storage from computing.
As shown in the figure below, from top to bottom, Manu has four layers, i.e., access layer, coordinator layer, worker layer, and storage layer. Manu also uses a log system as its backbone, which connects the decoupled components.
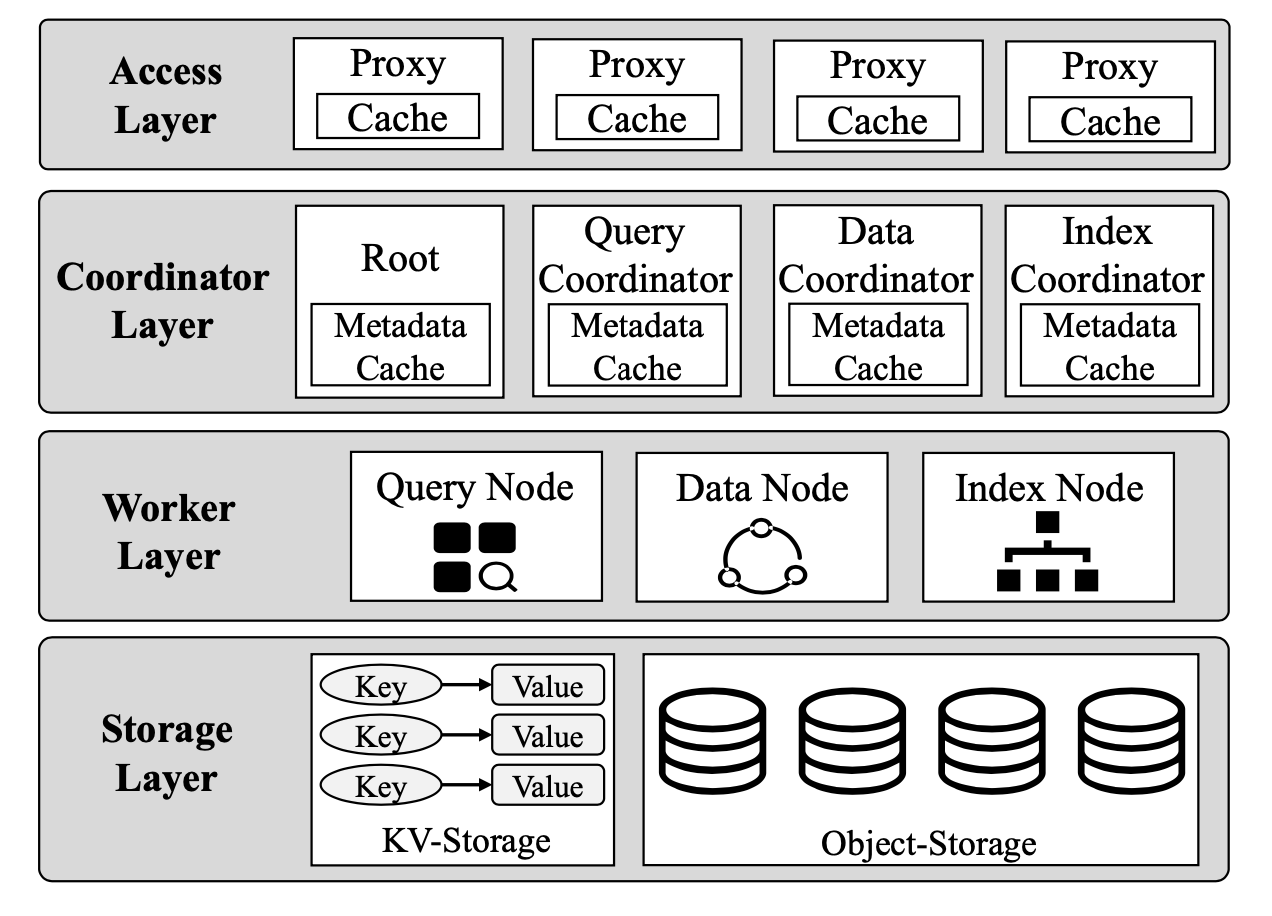 Manu architecture.
Manu architecture.
Access layer
Access layer consists of stateless proxies that serve as the user endpoints.
These proxies receive requests from clients, distribute the requests to the corresponding components, and collect the results before returning them to clients. Besides, the proxies cache a copy of the metadata for verifying the legitimacy of the search requests (e.g., whether the collection to search exists).
Coordinator layer
Coordinator layer manages system status, maintains metadata, and coordinates the system components for processing tasks.
There are four types of coordinators, each designed independently for different functionality. In this way, system failures can be isolated and the components can be evolved separately. For reliability concerns, each coordinator can have multiple instances (e.g., one main and two backups).
Root coordinator
Root coordinator handles data definition requests, such as creating/deleting collections, and maintains the meta-information of the collections (e.g., the properties of the collections, the data type of each property).
Data coordinator
Data coordinator deals with the persistence of data. It coordinates the data nodes to transform requests for updating data into binlogs and records the detailed information of the collections (e.g., the list of the segments of each collection, the storage path of each segment).
Index coordinator
Index coordinator manages data indexing. It coordinates index nodes for indexing tasks and records the index information of each collection (e.g., index type, related parameters, storage path, etc.).
Query coordinator
Query coordinator monitors the status of the query nodes, and adjusts the assignment of segments (along with related indexes) to query nodes for load balancing.
Worker layer
The worker layer executes the multiple tasks in the system.
All the worker nodes are stateless - they fetch read-only copies of data to conduct tasks and do not need to coordinate with each other. Therefore, the number of worker nodes can be flexibly adjusted according to the load. Besides, Manu uses different worker nodes for different tasks, so that each node type can be scaled independently according to the actual load and QoS requirements.
Storage layer
Storage layer persistently stores system status information, metadata, collections, and associated indexes.
Manu uses highly available distributed KV (key-value) stores, like etcd, to store system status information and metadata. When metadata is updated, the data will first be written into the KV store and then synchronized with relevant coordinators. Data of large volume, like that of collections and indexes, are managed with object storage services like AWS S3. The high latency that comes with object storage is not a performance bottleneck because the worker nodes take read-only copies of the data from the object store and cache them locally before processing the data, so most data processing is done locally.
Log backbone
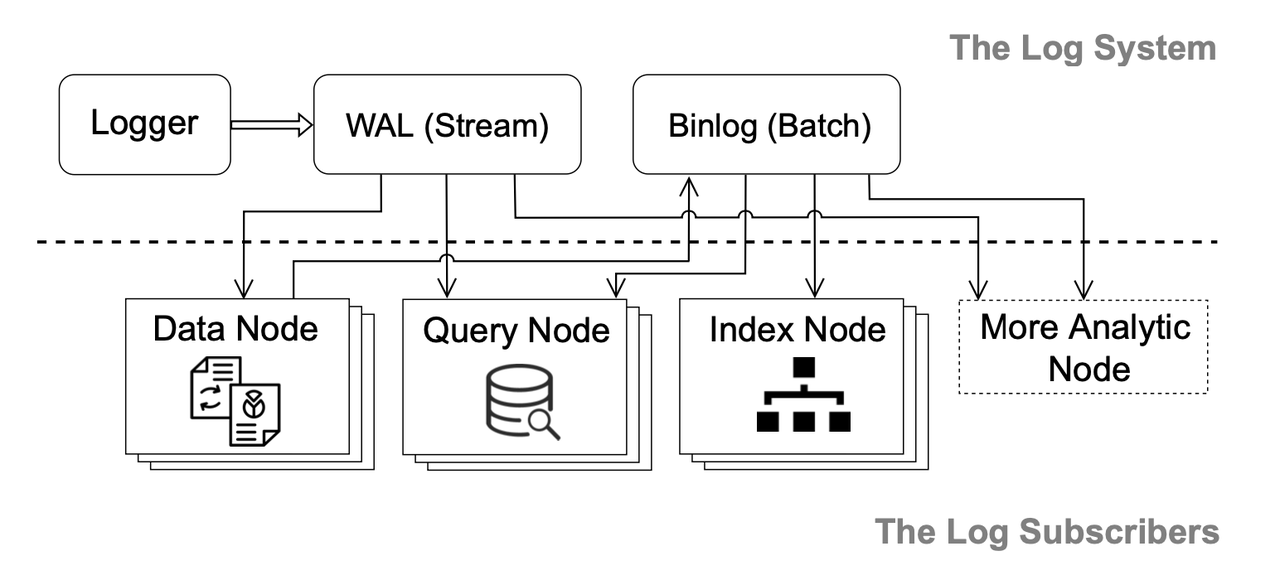 Log backbone.
Log backbone.
To better decouple the system components (e.g., WAL, binlog, data nodes, index nodes and query nodes), so that they each can be scaled and evolved independently, Manu follows the "log as data" paradigm and uses a log system as its backbone, which connects the decoupled system components. In Manu, logs can persistently be subscribed to by different system components, which therefore are called the subscribers of the logs.
The logs in Manu can be divided into the write-ahead log (WAL) and binlog. The WAL is the incremental part of system log while the binlog is the base part. They complement each other in delay, capacity and cost.
As shown in the figure above, loggers are the entry points of the log system, publishing data onto the WAL. Data nodes subscribe to the WAL and convert the row-based WALs into column-based binlogs. All read-only components such as index nodes and query nodes are independent subscribers to the log service to keep themselves up-to-date.
The log system also serves to pass inter-component messages. In other words, components can broadcast system events via logs. For example, data nodes can inform other components which segments have been written to object storage and index nodes can inform all query coordinators as soon as new indexes have been built. Moreover, different types of messages are organized on different channels. Each component only needs to subscribe to its corresponding channel instead of listening to all the broadcast logs.
Data processing workflow
This section elaborates on the data processing workflow inside Manu and introduces the process of data insertion, index building, and query execution.
Data insertion
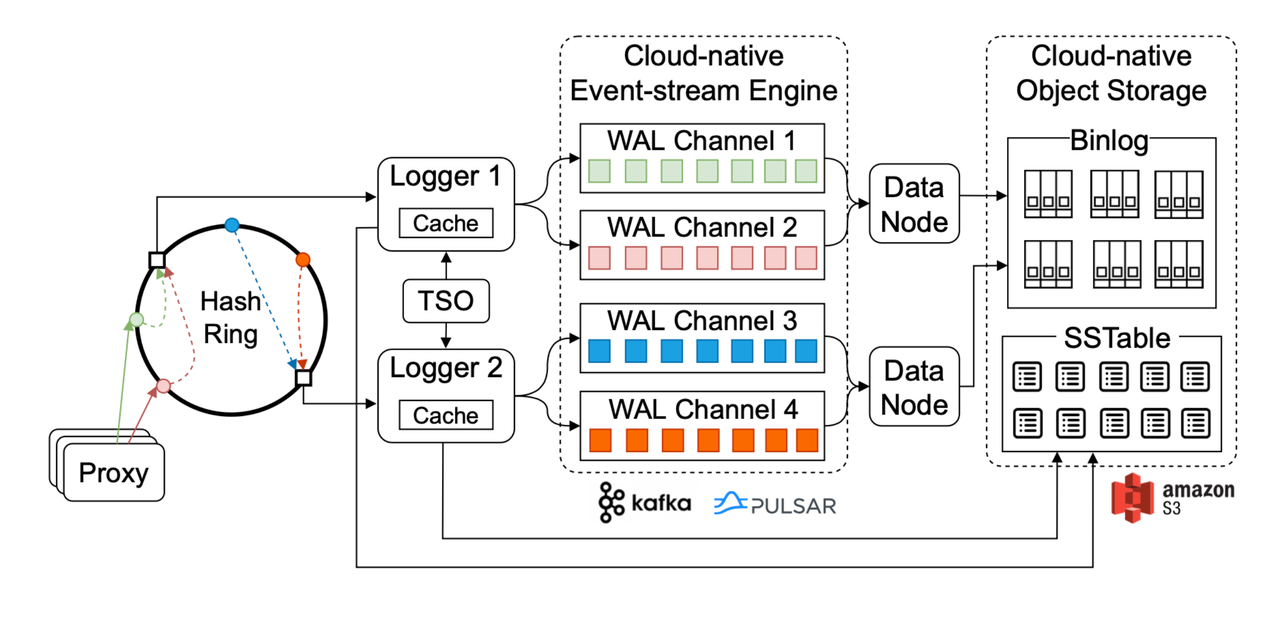 Data insertion workflow.
Data insertion workflow.
The figure above illustrates the workflow of data insertion in Manu and the relevant components involved.
After being processed by the proxy, data insertion requests are distributed into several buckets based on hash algorithms. Generally, there are multiple loggers in the Manu system handling the entities in each hash bucket based on consistent hashing. Entities in each hash bucket are written into a write-ahead log (WAL) channel that only maps to this bucket. When a logger receives a data insertion request, it assigns a globally unique log sequence number (LSN) to this request, and writes it into the corresponding WAL channel. The LSN is generated by the central time service oracle (TSO). Each logger needs to receive an LSN from the TSO and save the LSN locally at a regular interval.
To ensure that log pub/sub has a low delay and is fine-grained, entities are stored in a row-based way in the WAL in Manu, and each component that subscribes to the WAL reads data from it in a streaming manner. In most cases, WAL can be implemented via a cloud-based message queue such as Kafka or Pulsar. Data nodes subscribe to the WALs and convert the row-based WALs into column-based binlogs. The column-based nature of binlog makes it easy to compress and access data. An example of this efficiency comes with the index nodes. Index nodes only read the required vector column from the binlog for index building and thus are free from read amplifications.
Index building
There are two index building scenarios in Manu - batch indexing and stream indexing. Batch indexing occurs when the user builds an index for an entire collection (e.g., when all vectors are updated with a new embedding model). In this case, the index coordinator obtains the paths of all segments in the collection from the data coordinator, and instructs index nodes to build an index for each segment. Stream indexing happens when users continuously insert new entities, and indexes are built asynchronously on-the-fly without interrupting search services.
When data node writes a new segment into binlog, the data coordinator notifies the index coordinator to create a task for an index node to build an index on the new segment. In both batch and stream indexing scenarios, after the required index is built for a segment, the index node persists it in object storage and sends the storage path to the index coordinator, notifying the query coordinator so that query nodes can load the index for processing queries.
Query execution
Manu partitions a collection into segments and distributes the segments among query nodes for executing query requests in parallel. The proxies cache a copy of the distribution of segments on query nodes by inquiring the query coordinator, and dispatch search requests to query nodes that hold segments of the searched collection. The query nodes perform vector queries on their local segments, merge the results, and return them to the proxy. The proxy further aggregates the results by each query node and returns the final results to the client.
Query nodes obtain data from three sources - the WAL, the index files, and the binlog. For historical data, query nodes read the corresponding binlogs or index files from object storage. Whereas for incremental data, query nodes directly read from the WAL in a streaming manner. Obtaining incremental data from the binlog will cause latency in data visibility, which is especially true for large search requests. In other words, newly inserted data will only be available for query after a long period of time, which fails to meet the need for high consistency in some scenarios.
As mentioned earlier, Manu adopts a delta consistency model to enable users to tune consistency levels more flexibly. Delta consistency ensures that the updated data (including inserted and deleted data) can be queried and searched up to delta time units after the data update request is received by Manu.
Manu achieves delta consistency by adding LSNs carrying timestamps to all data insertion and query requests. When executing query requests, the query node checks the timestamp of the request (Lr) and the timestamp of the latest data update request processed by the query node (Ls). The query request is executed only when the interval between Lr and Ls is smaller than delta. Otherwise, the query request waits to be executed until the data updates recorded in WAL are processed. However, if there is no data update for a long period of time, the time interval between Ls and the current system time will become so small that queries are blocked. To prevent such an issue, Manu regularly inserts control information into the WAL, forcing the query node to update its timestamp.
Performance evaluation
In the paper, we also integrated Manu into real-world applications and conducted an overall system performance evaluation. The followings are part of the evaluation results.
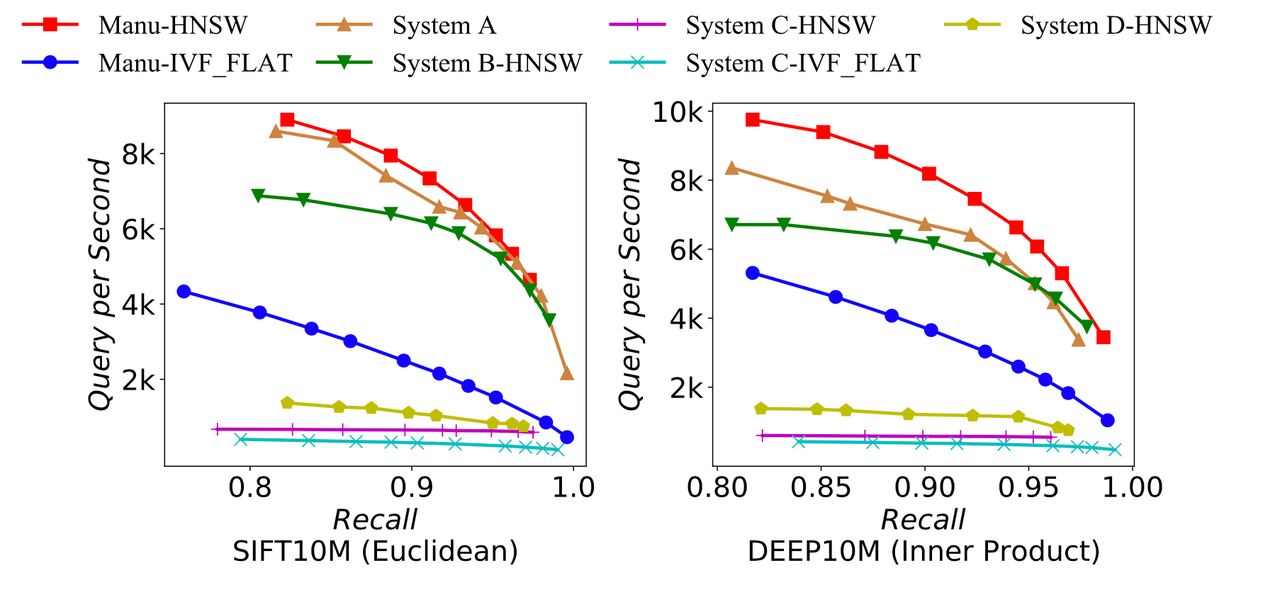 Query performance of Manu and other vector search systems.
Query performance of Manu and other vector search systems.
The figure above compares Manu with other four anonymous open-source vector search systems in terms of query performance. We can see that Manu evidently outperforms other vector search systems when conducting queries on SIFT and DEEP datasets.
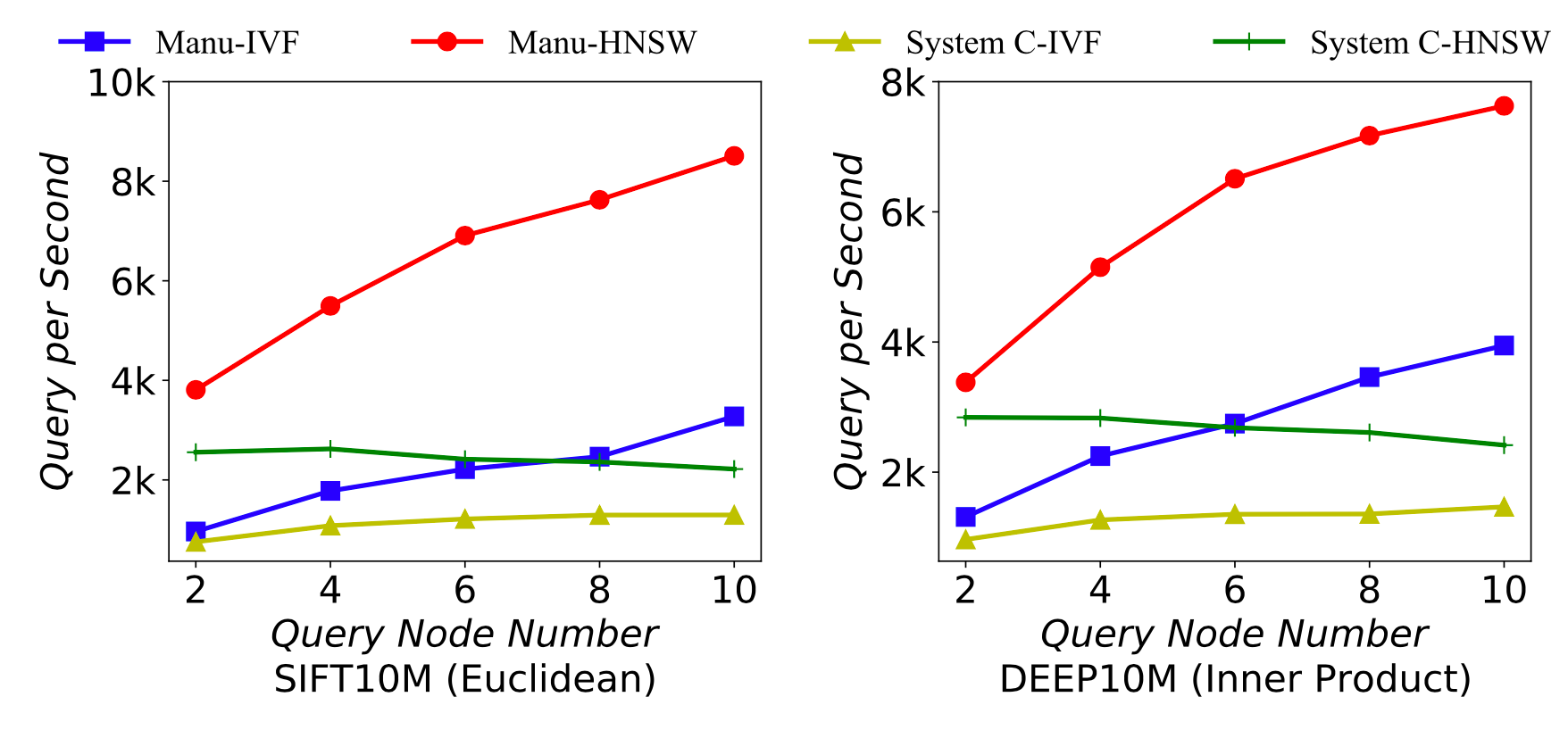 Query performance of Manu under different numbers of nodes.
Query performance of Manu under different numbers of nodes.
The figure above shows the query performance of Manu when the number of query node varies. We can see that when querying different datasets with different similarity metrics, the query performance of Manu presents an approximately linear relationship to the number of query nodes.
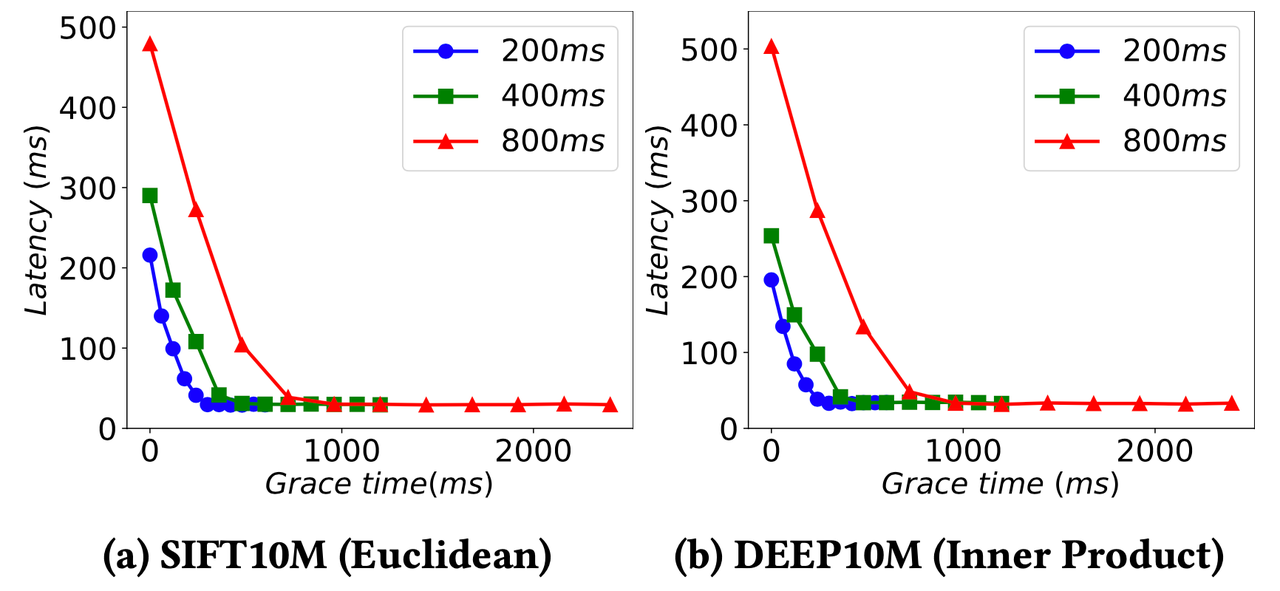 Query performance of Manu under different consistency levels.
Query performance of Manu under different consistency levels.
The figures above demonstrate the query performance of Manu under different consistency levels. The horizontal coordinates represent the values of delta as in delta consistency. Each figure reflects the frequency of control information sent to WAL that forces query nodes to sync time. We can see from the figure that the query latency of Manu drastically decreases as the value of delta increases. Therefore, Manu users need to choose the appropriate delta value according to their need for performance and consistency.
Conclusion
In this paper, based on real-world requirements for vector database, we have introduced the designs of Manu and the workflows of its main functionalities. In short, the two main features of Manu are as follows:
Manu uses the log backbone to connect the system components, which enables the independent scaling and evolution of each component and facilitates resource allocation and failure isolation.
With the log system and the LSN, Manu adopts a delta consistency model to enable flexible trade-off among consistency, cost and performance.
To sum up, the main contribution of our VLDB paper lies in the introduction of the real-world demand for vector database and the design of the basic architecture of a cloud-native vector database. At present, the architecture is still far from perfect and some of our future directions include:
How to retrieve vectors extracted from multimodal content;
How to better leverage cloud storage services, including local disks, cloud drives and other storage services, to make data retrieval more efficient;
How to maximize indexing and search performance with the help of new computing, storage or communication hardware like FPGA、GPU、RDMA、NVM 、RDMA.
Endnote
A year ago, I attended ACM SIGMOD 2021 in Xi'an with Charles Xie, CEO of Zilliz. The idea of writing this paper came to me while we were on the way back to Shanghai for the GA release of Milvus 2.0 (Manu). Both Charles and I perceived that cloud-native databases were becoming the new hot topic in academia. It was such a coincidence that Manu is exactly a cloud-native and purpose-built database system for massive vectors. As a result, we came to write this paper about Manu and the cloud-native database management system.
We hope our paper can shed some light and attract more scholars and colleagues in the industry to join us in exploring and researching into cloud-native vector database management systems.
We also want to express our gratitude to Assistant Professor Bo Tang, Research Assistant Professor Xiao Yan, and Long Xiang for their contribution. This paper is jointly written by the Zilliz team and the Database Group from the Southern University of Science and Technology.
Keep Reading

Democratizing AI: Making Vector Search Powerful and Affordable
Zilliz democratizes AI vector search with Milvus 2.6 and Zilliz Cloud for powerful, affordable scalability, cutting costs in infrastructure, operations, and development.

AI Agents Are Quietly Transforming E-Commerce — Here’s How
Discover how AI agents transform e-commerce with autonomous decision-making, enhanced product discovery, and vector search capabilities for today's retailers.

Vector Databases vs. Graph Databases
Use a vector database for AI-powered similarity search; use a graph database for complex relationship-based queries and network analysis.