




Comprender el aprendizaje por refuerzo profundo (DRL): Una guía completa
Respuesta breve: El aprendizaje por refuerzo profundo (DRL) es un campo de la IA en el que un agente aprende a tomar decisiones interactuando con un entorno y mejorando con el tiempo en función de la retroalimentación o las "recompensas". El DRL combina el aprendizaje por refuerzo (RL), un método de aprendizaje mediante ensayo y error, con el aprendizaje profundo, que permite al agente manejar datos complejos como imágenes o lecturas de sensores. El DRL puede usar redes neuronales profundas para enseñar a los agentes a navegar por tareas complicadas con entradas de alta dimensionalidad. Se utiliza ampliamente en aplicaciones como la robótica y los juegos, donde los métodos de aprendizaje tradicionales tienen dificultades debido a la complejidad y variabilidad del entorno.
Comprender el aprendizaje por refuerzo profundo (DRL): Una guía completa
En 2016, cuando AlphaGo derrotó al campeón mundial Lee Sedol en Go—un juego con más movimientos posibles que átomos en el universo—marcó un momento decisivo en la tecnología empresarial. ¿El secreto detrás de esta victoria? Aprendizaje por refuerzo profundo: un método que entrena a las computadoras para mejorar mediante la práctica, igual que un tenista que perfecciona su saque después de años en la cancha. Donde los programas informáticos tradicionales tienen dificultades con los cambios inesperados, esta tecnología destaca en situaciones que cambian constantemente: desde dirigir robots en almacenes concurridos hasta tomar decisiones rápidas en el trading bursátil. Este nuevo enfoque del aprendizaje automático abre puertas para las empresas, abordando problemas que antes eran demasiado complejos para que el software convencional los resolviera.
Esta guía ofrece una exploración en profundidad del aprendizaje por refuerzo profundo, destacando conceptos clave, sus diversas aplicaciones, sus ventajas y los desafíos que pueden surgir en su implementación.
¿Qué es el aprendizaje por refuerzo profundo?
El aprendizaje por refuerzo profundo (DRL) combina dos técnicas eficaces de IA, el aprendizaje por refuerzo (RL) y el aprendizaje profundo, lo que permite a los agentes de IA aprender acciones óptimas mediante ensayo y error en entornos complejos. En el RL, un agente interactúa con su entorno y ajusta su comportamiento en función de las recompensas y las estrategias de aprendizaje para maximizar las recompensas a largo plazo. El aprendizaje profundo añade la capacidad de manejar representaciones de estado detalladas utilizando redes neuronales.
Por ejemplo, un robot que navega por un laberinto se mueve inicialmente al azar, pero con el tiempo aprende a llegar al objetivo de manera eficiente mediante la retroalimentación. El DRL ayuda a los agentes a adaptarse a entornos dinámicos y resolver problemas complejos sin instrucciones detalladas. Es útil en videojuegos, coches autónomos y recomendaciones personales. Al combinar el aprendizaje por refuerzo y el aprendizaje profundo, los agentes de DRL pueden manejar eficazmente tareas complicadas del mundo real.
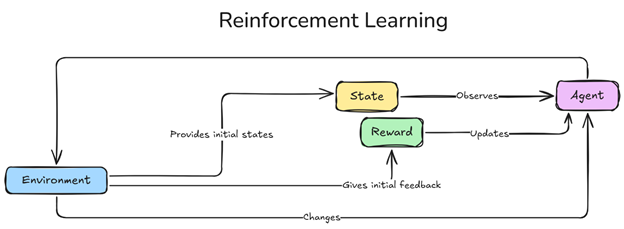 Figura 1 Marco de aprendizaje por refuerzo.png
Figura 1 Marco de aprendizaje por refuerzo.png
Cómo funciona el aprendizaje por refuerzo profundo
Para comprender cómo funciona el DRL, es importante conocer sus componentes clave:
Agente
Entorno
Estado
Acciones y recompensas
Política
Agente
El agente es el encargado de tomar decisiones, con la tarea de navegar por el entorno y elegir acciones para maximizar las recompensas acumuladas con el tiempo. Mediante interacciones repetidas (episodios de aprendizaje), el agente perfecciona su estrategia basándose en la retroalimentación, ajustando su comportamiento para lograr el éxito a largo plazo. Al igual que un jugador en un juego, las acciones del agente están guiadas por una política: un conjunto de reglas aprendidas con el tiempo para mejorar el rendimiento y alcanzar resultados óptimos.
Entorno
El entorno es el espacio estructurado dentro del cual opera el agente, definiendo los posibles estados, acciones y recompensas. Reacciona a cada acción del agente, proporcionando retroalimentación que influye en las decisiones futuras del agente y da forma a su proceso de aprendizaje.
Estado
El estado representa una instantánea del entorno en un momento determinado, que contiene información importante para la toma de decisiones del agente. Por ejemplo, un estado podría incluir la posición de un agente y los obstáculos en un laberinto, o la velocidad de un vehículo y su proximidad a otros coches. Cada estado ayuda al agente a evaluar su situación y seleccionar la acción más ventajosa.
Acciones y recompensas
Las acciones representan las elecciones de un agente en cada estado, dirigiendo su trayectoria a través del entorno. Las acciones pueden ser:
Acciones discretas: Opciones limitadas, como moverse hacia arriba, hacia abajo, a la izquierda o a la derecha, en entornos de cuadrícula facilitan que los agentes exploren y desarrollen políticas.
Acciones continuas: Estas incluyen un rango de valores, como ajustar la velocidad o el ángulo, que requieren modelos avanzados para manejar la mayor complejidad.
El agente tiene como objetivo realizar acciones óptimas a lo largo del tiempo y maximizar las recompensas.
Las recompensas proporcionan retroalimentación para guiar el aprendizaje del agente. Las recompensas positivas señalan acciones exitosas, mientras que las recompensas negativas penalizan los errores. Las recompensas pueden incluir:
Recompensas inmediatas: Estas se otorgan directamente después de una acción, como ganar puntos por capturar una pieza del oponente en ajedrez.
Recompensas diferidas: Se obtienen después de completar una secuencia de acciones, como navegar por un laberinto.
Es importante diseñar la estructura de recompensas, conocida como moldeado de recompensas. Por ejemplo, las recompensas intermedias a lo largo de una ruta compleja pueden acelerar el aprendizaje, motivando al agente a dar pasos específicos hacia el objetivo final.
 Figura- Arquitectura de aprendizaje por refuerzo.png
Figura- Arquitectura de aprendizaje por refuerzo.png
Figura: Arquitectura de aprendizaje por refuerzo
El proceso de aprendizaje
El proceso de aprendizaje o entrenamiento del aprendizaje por refuerzo profundo es un ciclo iterativo de interacción, retroalimentación y mejora que implica:
Exploración
Explotación
Redes neuronales profundas
Retropropagación
Exploración
Inicialmente, el agente no conoce el entorno. Comienza explorando al azar, probando diferentes acciones y observando las consecuencias. Esta fase de exploración es importante para recopilar información del entorno y descubrir acciones gratificantes.
Explotación
A medida que el agente explora y acumula experiencia, comienza a identificar acciones que conducen a recompensas positivas. Luego explota este conocimiento, eligiendo esas acciones con mayor frecuencia para maximizar sus recompensas.
Redes neuronales profundas
El agente utiliza redes neuronales profundas para aproximar la política y la función de valor del agente.
Red de políticas: Esta red toma el estado actual como entrada y genera la probabilidad de realizar diferentes acciones.
Red de valor: Esta red estima el valor a largo plazo de estar en un estado particular, ayudando al agente a tomar decisiones que conduzcan a mayores recompensas acumulativas. Estas redes neuronales permiten al agente aprender patrones y relaciones complejos del entorno, ayudándolo a tomar decisiones más inteligentes.
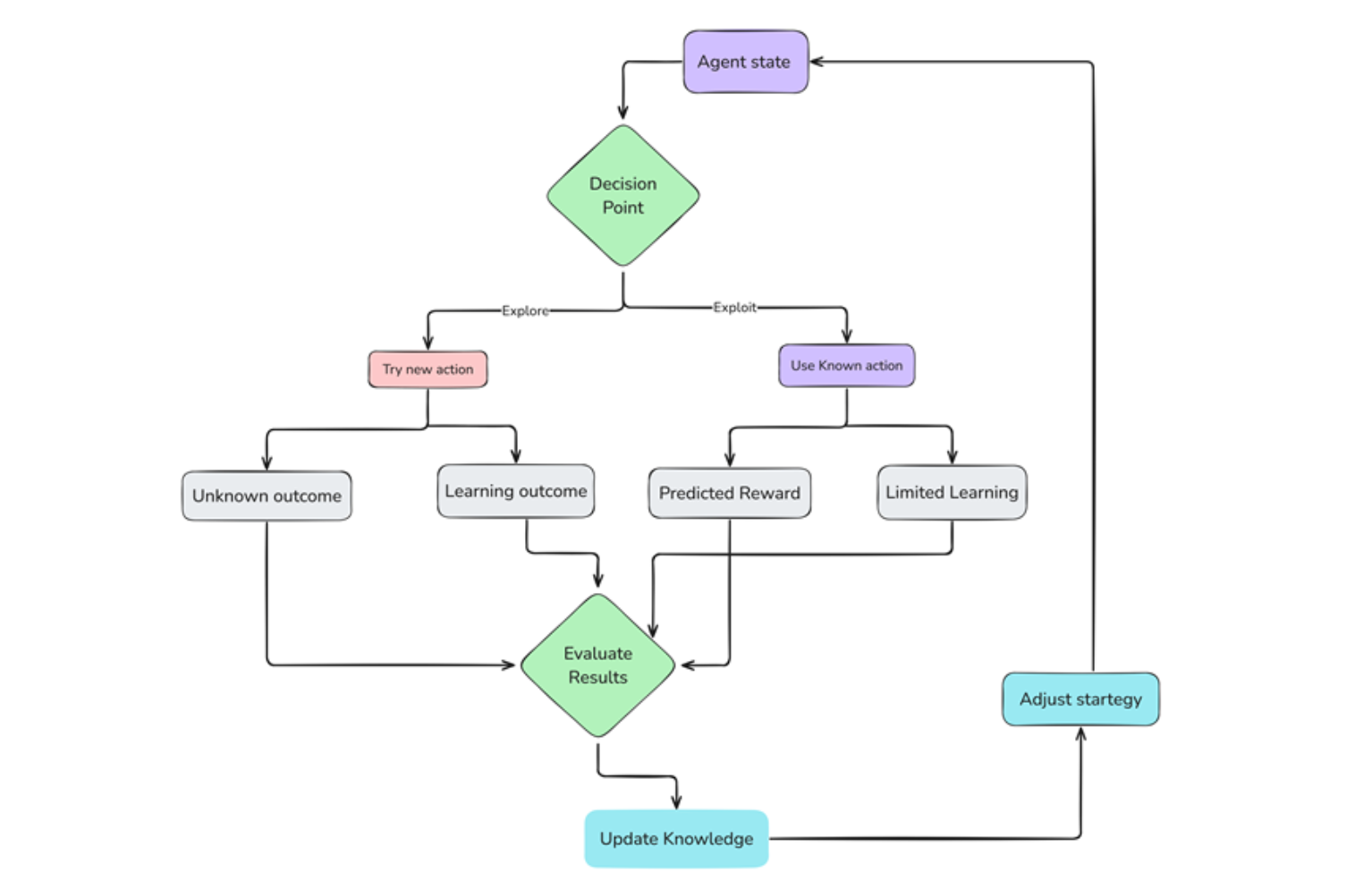 Proceso de exploración vs explotación .png
Proceso de exploración vs explotación .png
Figura 3 Proceso de exploración vs explotación
Retropropagación
La retropropagación, abreviatura de "propagación hacia atrás de errores", es un algoritmo clave en el entrenamiento de redes neuronales. Ajusta los pesos en una red neuronal para minimizar el error en las predicciones.
La retropropagación ayuda a los agentes a mejorar sus modelos de toma de decisiones mediante el aprendizaje a partir de la retroalimentación. Cuando un agente realiza una acción, recibe retroalimentación sobre qué tan buena o mala fue esa acción (en forma de una recompensa). Luego, la retropropagación ajusta los pesos de la red neuronal, reduciendo el error entre los resultados predichos y las recompensas reales. Al aplicar la retropropagación repetidamente, la red neuronal aprende a aproximar mejor las funciones de valor o de política, lo que conduce a decisiones más precisas. Este proceso permite que el agente mejore gradualmente su comprensión del entorno y tome decisiones cada vez más óptimas con el tiempo, lo cual es esencial para dominar tareas complejas en entornos dinámicos y de alta dimensionalidad.
Algoritmos populares en el aprendizaje por refuerzo profundo
El DRL emplea una variedad de algoritmos, cada uno diseñado para abordar diferentes desafíos en el proceso de aprendizaje. Estos son algunos de los métodos más utilizados:
Q-Learning: Q-Learning es uno de los algoritmos fundamentales del aprendizaje por refuerzo. Estima el valor de los pares estado-acción, denominados valores Q, ayudando al agente a determinar qué acciones son preferibles en estados particulares. El algoritmo actualiza estos valores Q en función de las recompensas inmediatas y las recompensas futuras anticipadas, refinando gradualmente las elecciones del agente para favorecer acciones con mayor valor a largo plazo.
Deep Q-Networks (DQN): DQN mejora Q-learning al utilizar redes neuronales para aproximar los valores Q. Este enfoque hace que las DQN sean eficaces en entornos complejos como la IA para juegos, la navegación robótica y la conducción autónoma.
Policy Gradients: A diferencia de los métodos basados en valor, los algoritmos de gradiente de política optimizan directamente la política de un agente ajustando los pesos de una red neuronal en función de las recompensas recibidas. Este enfoque permite al agente mejorar el rendimiento al aumentar la probabilidad de acciones exitosas, lo cual es especialmente importante en tareas de control que requieren ajustes precisos, como la manipulación de brazos robóticos.
Actor-Critic Methods: Los enfoques híbridos combinan las fortalezas de los métodos basados en políticas, que buscan estimar el valor de cada acción en un estado dado, y los métodos basados en valor, que se centran en aprender directamente la política óptima. En este marco, el actor es responsable de seleccionar acciones, mientras que el crítico evalúa estas acciones y proporciona retroalimentación. Esta retroalimentación permite mejoras continuas en la política.
Comparación del aprendizaje por refuerzo profundo con otros conceptos
El aprendizaje por refuerzo profundo (DRL) suele compararse con otros enfoques de IA. Para aclarar las diferencias y similitudes, desglosemos los aspectos clave:
| Aspecto | Aprendizaje por Refuerzo Profundo (DRL) | Aprendizaje por Refuerzo Regular (RL) | Aprendizaje Supervisado | Aprendizaje No Supervisado | |
| Concepto central y manejo de datos | Combina RL con redes neuronales profundas; procesa datos de alta dimensionalidad y complejos | Se centra en RL con modelos más simples; funciona bien en entornos de baja dimensionalidad | Aprende de datos etiquetados con resultados predefinidos; depende de conjuntos de datos etiquetados | Encuentra patrones en datos no etiquetados; trabaja con conjuntos de datos no etiquetados | |
| Proceso de aprendizaje | Ensayo y error mediante la interacción con el entorno. | Ensayo y error mediante retroalimentación del entorno. | Aprende patrones a partir de pares entrada-salida etiquetados. | Identifica clústeres o estructuras en los datos. | |
| Objetivo | Maximizar las recompensas acumuladas con el tiempo. | Maximizar las recompensas acumuladas con el tiempo. | Predecir salidas basadas en datos de entrada. | Descubrir patrones ocultos o agrupaciones en los datos. | |
| Aplicaciones | Tareas complejas: IA para juegos, robótica, vehículos autónomos. | Sistemas de control básicos y tareas simples de toma de decisiones. | Clasificación, regresión, modelado predictivo. | Clustering, reducción de dimensionalidad, detección de anomalías. |
Beneficios y desafíos del aprendizaje por refuerzo profundo
El aprendizaje por refuerzo profundo tiene muchas posibilidades, pero es importante saber en qué destaca y dónde podría quedarse corto. Veamos algunos de los principales beneficios y desafíos del DRL.
Beneficios:
Adaptabilidad: Un beneficio clave del DRL es su adaptabilidad. Los agentes de DRL pueden manejar situaciones nuevas e inesperadas sin requerir programación adicional. Por ejemplo, un vehículo autónomo impulsado por DRL puede responder a cambios repentinos en la carretera, como obstáculos o condiciones meteorológicas adversas, ajustando su comportamiento para navegar de forma segura.
Toma de decisiones óptima: El DRL también permite una toma de decisiones más inteligente y, a menudo, más efectiva. A diferencia de los sistemas tradicionales basados en reglas, los modelos de DRL pueden descubrir estrategias que incluso los diseñadores humanos podrían pasar por alto. En finanzas, por ejemplo, el DRL se ha aplicado con éxito para crear bots de trading que con frecuencia toman decisiones más rentables que los sistemas convencionales.
Potencial de automatización: El DRL permite la automatización de tareas en campos como el transporte de mercancías, la atención médica y la ayuda a clientes. En estas áreas, a menudo complicadas y siempre cambiantes, el DRL ayuda a facilitar las cosas al automatizarlas.
Desafíos:
Eficiencia de muestreo: Uno de los mayores desafíos del DRL es su demanda de enormes cantidades de datos de entrenamiento. Los modelos de DRL normalmente requieren datos extensos para funcionar bien, lo cual puede ser costoso y llevar mucho tiempo recopilar. Técnicas como la repetición de experiencias ayudan al permitir que los modelos aprendan de datos pasados, pero aún se necesitan mejoras en la eficiencia de datos para hacer que el DRL sea más práctico.
Diseño de recompensas: Otro desafío radica en diseñar funciones de recompensa efectivas. Establecer las recompensas adecuadas es crucial porque las recompensas mal diseñadas pueden conducir a comportamientos no deseados y, a veces, problemáticos por parte del agente. Como resultado, el diseño de recompensas en DRL requiere una planificación cuidadosa para garantizar que los agentes actúen de maneras que se alineen con sus objetivos previstos.
Estabilidad y convergencia: Por último, el entrenamiento de DRL puede ser inestable. A veces, los modelos se quedan atascados en estrategias menos que ideales o no logran alcanzar una solución estable. Mejorar la estabilidad del entrenamiento es esencial para hacer que los modelos de DRL sean más fiables, especialmente para aplicaciones de alto riesgo donde la consistencia es clave.
Aplicaciones del aprendizaje por refuerzo profundo en el mundo real
Ahora que hemos explorado el funcionamiento del aprendizaje por refuerzo profundo (DRL), cambiemos nuestro enfoque hacia sus aplicaciones prácticas. El DRL se está utilizando para resolver problemas del mundo real en diversos dominios. Incluyendo:
Juego: El DRL ha permitido la creación de agentes de IA avanzados que sobresalen en juegos como Chess, Go y Dota 2. Para quienes estén interesados en la exploración práctica, Unity ML-Agents proporciona un kit de herramientas accesible para experimentar con el aprendizaje basado en juegos.
Robótica: En robótica, el DRL enseña a las máquinas habilidades como navegar y manipular objetos. El DRL demuestra ser muy eficaz en almacenes, permitiendo que los robots se adapten a nuevos diseños y tareas cambiantes, impulsando la eficiencia de las operaciones.
Vehículos autónomos: En los autos sin conductor, el DRL desempeña un papel crucial en la toma de decisiones en fracciones de segundo para cambiar de carril, evitar obstáculos o ajustar la velocidad. Waymo, por ejemplo, utiliza DRL para ayudar a sus vehículos a tomar decisiones seguras en situaciones de tráfico complejas.
Trading financiero: El DRL también se usa ampliamente en finanzas para desarrollar bots de trading que responden a los cambios del mercado. Usando enfoques como Deep Q-Learning, los bots de trading impulsados por DRL analizan tendencias históricas y datos en vivo para tomar decisiones informadas de compra, mantenimiento o venta, logrando a menudo mejores resultados que las estrategias de trading manual.
Recomendaciones personalizadas: El DRL impulsa sistemas de recomendación cada vez más avanzados. Para proporcionar recomendaciones a medida, los algoritmos de DRL analizan el comportamiento y las preferencias de los usuarios en servicios de streaming, tiendas en línea y plataformas de redes sociales. Al observar las acciones de los usuarios, el DRL puede recomendar contenido o productos que se ajusten más estrechamente a las preferencias individuales.
Preguntas frecuentes sobre el aprendizaje por refuerzo profundo
- ¿Cómo aprende un agente en el aprendizaje por refuerzo profundo?
En el DRL, un agente aprende realizando acciones en un entorno y recibiendo retroalimentación en forma de recompensas. El agente utiliza la exploración (probar nuevas acciones) para descubrir estrategias eficaces y la explotación (usar acciones conocidas) para maximizar las recompensas. Las redes neuronales profundas ayudan al agente a generalizar a partir de sus experiencias y adaptarse a escenarios complejos.
- ¿Cómo equilibran los modelos de aprendizaje por refuerzo profundo la exploración y la explotación?
Los modelos de DRL equilibran la exploración (probar nuevas acciones para descubrir mejores estrategias) y la explotación (usar acciones conocidas para maximizar las recompensas) mediante algoritmos como epsilon-greedy o Thompson Sampling. Estas técnicas ayudan a mantener un equilibrio, asegurando que el agente descubra nuevas estrategias mientras maximiza las recompensas conocidas.
- ¿Cómo funcionan las funciones de valor en el aprendizaje por refuerzo profundo?
Las funciones de valor estiman la recompensa esperada de estar en un cierto estado (función de valor de estado) o de realizar una acción específica en un estado determinado (función de valor de acción). Ayudan al agente a priorizar estados y acciones que conducen a recompensas más altas, guiando la toma de decisiones.
- ¿Cómo se puede usar el DRL con Milvus para aplicaciones de IA?
Milvus puede almacenar y gestionar las representaciones de estado de alta dimensión generadas por agentes de DRL. Puede servir como un búfer de repetición para experiencias pasadas o ayudar en el almacenamiento de representaciones de estado, mejorando la eficiencia de la optimización de políticas y la estimación de valor.
- ¿Cuáles son las preocupaciones éticas de usar el aprendizaje por refuerzo profundo?
Las preocupaciones éticas incluyen posibles sesgos en los datos de entrenamiento, comportamientos no deseados derivados de funciones de recompensa mal diseñadas y problemas de equidad en aplicaciones sensibles. Para mitigar estos riesgos, es crucial implementar pruebas sólidas, transparencia e IA explicable.
Recursos relacionados
Para una exploración más profunda, considera estos recursos:
Artículo: [1811.12560] Una introducción al aprendizaje por refuerzo profundo
Comprender la regularización de redes neuronales y las técnicas clave de regularización
Hacer que el machine learning sea más accesible para los desarrolladores
Evolución de la búsqueda: de la coincidencia de palabras clave a la búsqueda vectorial y GenAI
Introducción a la búsqueda por similitud vectorial - blog de Zilliz
Modelos de IA de mayor rendimiento para tus aplicaciones GenAI | Zilliz
- ¿Qué es el aprendizaje por refuerzo profundo?
- Cómo funciona el aprendizaje por refuerzo profundo
- Algoritmos populares en el aprendizaje por refuerzo profundo
- Comparación del aprendizaje por refuerzo profundo con otros conceptos
- Beneficios y desafíos del aprendizaje por refuerzo profundo
- Aplicaciones del aprendizaje por refuerzo profundo en el mundo real
- Preguntas frecuentes sobre el aprendizaje por refuerzo profundo
- Recursos relacionados
Contenido
Comienza Gratis, Escala Fácilmente
Prueba la base de datos vectorial completamente gestionada construida para tus aplicaciones GenAI.
Prueba Zilliz Cloud Gratis