




Buenas prácticas en la implantación de aplicaciones de generación mejorada por recuperación (RAG)
Retrieval-Augmented Generation (RAG) es un método que ha demostrado ser muy eficaz para mejorar las respuestas de los LLM y abordar las alucinaciones de los LLM. En pocas palabras, la GAR proporciona a los LLM un contexto que puede ayudarles a generar respuestas más precisas y contextualizadas. Los contextos pueden proceder de cualquier parte: de sus documentos internos, bases de datos vectoriales, archivos CSV, archivos JSON, etc.
RAG es un enfoque novedoso que consta de muchos componentes que trabajan juntos. Estos componentes incluyen el procesamiento de consultas, context chunking, la recuperación de contextos, context reranking, y el propio LLM para generar la respuesta. Cada componente influye en la calidad de la respuesta final generada a partir de una aplicación RAG. El problema es que resulta difícil encontrar la mejor combinación de métodos en cada componente que conduzca al rendimiento RAG más óptimo.
En este artículo, discutiremos varias técnicas comúnmente utilizadas en todos los componentes de la GAR, evaluaremos el mejor enfoque para cada componente y luego encontraremos la mejor combinación que conduzca a la respuesta generada por la GAR más óptima, según este documento. Así que, sin más preámbulos, empecemos con una introducción a los componentes GAR.
Componentes RAG
Como ya se ha mencionado, la GAR es un potente método para aliviar los problemas de alucinación de los LLM, que suelen producirse cuando realizamos consultas que van más allá de sus datos de entrenamiento o cuando requieren conocimientos especializados. Por ejemplo, si hacemos a un LLM una pregunta sobre nuestros datos internos, es probable que obtengamos una respuesta inexacta. RAG resuelve este problema proporcionando a nuestro LLM un contexto que puede ayudarnos a responder a nuestra consulta.
RAG consiste en una cadena de componentes que forman un flujo de trabajo. Los componentes típicos de RAG incluyen:
Clasificación de la consulta: para determinar si nuestra consulta necesita la recuperación de contextos o puede ser procesada directamente por el LLM.
Recuperación de contextos**: para obtener los k candidatos principales en los contextos más relevantes para nuestra consulta.
Reordenación de contextos**: para ordenar los k mejores candidatos obtenidos del componente de recuperación, empezando por el más similar.
Reagrupamiento de contextos: organiza los contextos más relevantes en un formato más estructurado para generar mejores respuestas.
Resumen de contextos: extracción de la información clave de los contextos relevantes para mejorar la generación de respuestas.
Generación de respuestas:** para generar una respuesta basada en la consulta y los contextos relevantes.
Figura - Componentes RAG..png](https://assets.zilliz.com/Figure_RAG_Components_d88965cf8b.png)
Figura: Componentes RAG._ Fuente
Aunque estos componentes RAG son útiles durante el proceso de generación de la respuesta (es decir, cuando ya hemos almacenado todos los contextos y están listos para ser recuperados), hay que tener en cuenta otros factores antes de implementar un método RAG.
Necesitamos transformar nuestros documentos de contexto en incrustaciones vectoriales para que nuestros documentos de contexto sean útiles en un enfoque RAG. Por lo tanto, es crucial elegir el modelo de incrustación más apropiado y la estrategia para representar nuestros documentos de entrada como incrustaciones.
Una incrustación contiene una representación semánticamente rica de nuestro documento de entrada. Sin embargo, si el documento utilizado como contexto es demasiado largo, puede confundir al LLM a la hora de generar una respuesta adecuada. Un enfoque común para resolver este problema es aplicar un método de chunking, en el que dividimos nuestro documento de entrada en varios trozos y luego transformamos cada trozo en una incrustación. Es crucial elegir el mejor método de fragmentación y el mejor tamaño, ya que los trozos demasiado cortos probablemente no contengan suficiente información.
Figure- RAG workflow.png](https://assets.zilliz.com/Figure_RAG_workflow_5bfbcccddf.png)
Figura: Flujo de trabajo GAR_
Debemos considerar el almacenamiento apropiado para estas incrustaciones una vez que transformemos cada trozo en una incrustación. Si no se trabaja con muchas incrustaciones, se pueden almacenar directamente en la memoria local del dispositivo. Sin embargo, en la práctica se suelen manejar cientos o incluso millones de incrustaciones. En este caso, necesitas una base de datos vectorial como Milvus o su servicio gestionado, Zilliz Cloud, para almacenarlos, y elegir la base de datos vectorial adecuada es crucial para el éxito de nuestra aplicación RAG.
La última consideración es el propio LLM. Si procede, podemos ajustar el LLM para satisfacer nuestras necesidades específicas con mayor precisión. Sin embargo, el ajuste fino es costoso e innecesario en la mayoría de los casos, especialmente si estamos utilizando un LLM de alto rendimiento con muchos parámetros.
En las siguientes secciones analizaremos los mejores enfoques para cada componente del GAR. A continuación, exploraremos combinaciones de estos mejores enfoques y sugeriremos varias estrategias para desplegar la GAR que equilibren el rendimiento y la eficiencia.
Clasificación de consultas
Como se mencionó en la sección anterior, la RAG es útil para garantizar que el LLM genere respuestas precisas y contextualizadas, especialmente cuando se requiere conocimiento especializado de nuestros datos internos. Sin embargo, RAG también aumenta el tiempo de ejecución del proceso de generación de respuestas. Lo que ocurre es que no todas las consultas requieren el proceso de recuperación, y muchas de ellas pueden ser procesadas directamente por el LLM. Por lo tanto, saltarse el proceso de recuperación de contexto sería más beneficioso si una consulta no lo necesita.
Podemos implementar un modelo de [clasificación] de consultas (https://zilliz.com/glossary/classification) para determinar si una consulta necesita recuperación de contexto antes del proceso de generación de respuestas. Un modelo de clasificación de este tipo suele consistir en un modelo supervisado, como BERT, cuyo objetivo principal es predecir si una consulta necesita o no recuperación. Sin embargo, al igual que otros modelos supervisados, debemos entrenarlo antes de utilizarlo para la inferencia. Para entrenar el modelo, es necesario generar un conjunto de datos con ejemplos de consultas y sus correspondientes etiquetas binarias, incluyendo si la consulta necesita ser recuperada o no.
Figura- Ejemplo de conjunto de datos de clasificación de consultas..png](https://assets.zilliz.com/Figure_Query_classification_dataset_example_157161163d.png)
Figura: Query classification dataset example._ Source
En el artículo, se utiliza un modelo multilingüe basado en BERT para la clasificación de consultas. Los datos de entrenamiento incluyen 15 tipos de consultas en total, como traducción, resumen, reescritura, aprendizaje en contexto, etc. Hay dos etiquetas distintas: "suficiente" si la consulta se basa por completo en la información proporcionada por el usuario y no necesita recuperación, e "insuficiente" si la información de la consulta es incompleta, necesita información especializada y requiere un proceso de recuperación. Con este planteamiento, el modelo alcanzó el 95% tanto en precisión como en puntuación F1.
Este paso de clasificación de consultas puede mejorar significativamente la eficacia del proceso de GAR al evitar recuperaciones innecesarias de consultas que pueden ser gestionadas directamente por el LLM. Actúa como filtro, garantizando que sólo las consultas que requieren un contexto adicional se envíen a través del proceso de recuperación, que requiere más tiempo.
Figura - Resultado del clasificador de consultas..png](https://assets.zilliz.com/Figure_Query_classifier_result_3aaa0173d7.png)
Figura: Query classifier result._ Fuente
Técnica de fragmentación
Chunking se refiere al proceso de dividir documentos de entrada largos en segmentos más pequeños. Este proceso es muy útil para proporcionar al LLM un contexto más granular. Existen varios métodos de fragmentación, incluidos los enfoques a nivel de token y a nivel de frase. La fragmentación por frases suele ofrecer un buen equilibrio entre simplicidad y preservación semántica del contexto. Al elegir un método de fragmentación, hay que tener cuidado con el tamaño de los trozos, ya que los trozos demasiado cortos pueden no proporcionar un contexto útil para el LLM.
Figura - División de un documento largo en trozos más pequeños.png](https://assets.zilliz.com/Figure_Splitting_a_long_document_into_smaller_chunks_0929fcee85.png)
Figura: Dividir un documento largo en trozos más pequeños_
Para encontrar el tamaño óptimo de los trozos, se realizó una evaluación con el documento Lyft 2021. Se eligieron las primeras 60 páginas del documento como corpus y se dividieron en varios tamaños. A continuación, se utilizó un LLM para generar 170 consultas basadas en estas 60 páginas. Se utilizó el modelo text-embedding-ada-002 para las incrustaciones, mientras que el modelo Zephyr 7B se utilizó como LLM para generar respuestas basadas en las consultas elegidas.
Para evaluar el rendimiento del modelo en diferentes tamaños de trozos, se utilizó GPT-3.5 Turbo. Se emplearon dos métricas para evaluar la calidad de la respuesta: fidelidad y relevancia. La fidelidad mide si la respuesta es alucinada o coincide con los contextos recuperados, mientras que la relevancia mide si los contextos recuperados y las respuestas coinciden con las consultas.
Figura - Comparación de distintos tamaños de trozos. .png](https://assets.zilliz.com/Figure_Comparison_of_different_chunk_sizes_4156be62c9.png)
Figura: Comparación de los diferentes tamaños de los trozos. Fuente
Los resultados muestran que se prefiere un tamaño máximo de trozo de 512 tokens para la generación de respuestas altamente relevantes desde el LLM. Los trozos más pequeños, como 256 tokens, también funcionan bien y pueden mejorar el tiempo de ejecución global de la aplicación RAG. Para combinar las ventajas de los distintos tamaños de trozos, se pueden utilizar técnicas avanzadas de fragmentación, como small2big y ventanas deslizantes.
Small2big es un enfoque de chunking que organiza las relaciones entre bloques de trozos. Los trozos de pequeño tamaño se utilizan para emparejar consultas, y los trozos más grandes, que contienen la información de los más pequeños, se utilizan como contexto final para el LLM. Una ventana deslizante es un método de chunking que proporciona solapamientos de tokens entre trozos para preservar la información de contexto.
Comparación de distintas técnicas de fragmentación..png](https://assets.zilliz.com/Figure_Comparison_of_different_chunking_techniques_2ac7bcdb48.png)
Figura: Comparación de diferentes técnicas de chunking._ Fuente
Los experimentos muestran que con un tamaño de trozo menor de 175 tokens, un tamaño de trozo mayor de 512 tokens y un solapamiento de trozos de 20 tokens, ambas técnicas de chunking mejoran las puntuaciones de fidelidad y relevancia de las respuestas LLM.
A continuación, es crucial encontrar el mejor modelo de incrustación para representar cada trozo como una incrustación vectorial. Para ello se realizó una prueba en namespace-Pt/msmarco. Los resultados muestran que los modelos LLM Embedder y bge-large-en son los más eficaces. Sin embargo, dado que LLM Embedder es tres veces más pequeño que bge-large-en, se eligió como incrustación por defecto para el experimento.
Figura- Resultados de los distintos modelos de incrustación en el espacio de nombres-Pt:msmarco. .png](https://assets.zilliz.com/Figure_Results_for_different_embedding_models_on_namespace_Pt_msmarco_5e4b6f5e16.png)
Figura: Resultados de distintos modelos de incrustación en el espacio de nombres-Pt:msmarco._ Fuente
Bases de datos vectoriales
Las bases de datos vectoriales desempeñan un papel crucial en las aplicaciones GAR, sobre todo a la hora de almacenar y recuperar contextos relevantes. En las aplicaciones RAG del mundo real, tratamos con una enorme cantidad de documentos, lo que da lugar a un gran número de incrustaciones de contexto que deben almacenarse. En estos casos, el almacenamiento de estas incrustaciones en la memoria local es insuficiente, y el cálculo de la recuperación de contextos relevantes entre grandes colecciones de incrustaciones llevaría un tiempo considerable.
Las bases de datos vectoriales están pensadas para resolver estos problemas. Con una base de datos vectorial podemos almacenar millones o incluso miles de millones de incrustaciones vectoriales y recuperar contextos en una fracción de segundo. A la hora de elegir la mejor base de datos vectorial para su caso de uso, debemos tener en cuenta varios factores, como la compatibilidad con el tipo de índice, la compatibilidad con vectores a escala de miles de millones, la compatibilidad con búsqueda híbrida y las capacidades nativas de la nube.
Entre estos criterios, Milvus destaca como la mejor base de datos vectorial de código abierto en comparación con sus competidores como Weaviate, Chroma, Faiss, Qdrant, etc.
Comparación de varias bases de datos vectoriales..png](https://assets.zilliz.com/Comparison_of_Various_Vector_Databases_6137ea412f.png)
Comparación de varias bases de datos vectoriales. Fuente.
En términos de soporte de tipo de índice, Milvus ofrece varios métodos de indexación para adaptarse a diversas necesidades, como el índice plano ingenuo (FLAT) u otros tipos de indexación diseñados para acelerar el proceso de recuperación, como el índice de archivo invertido (IVF-FLAT) y Hierarchical Navigable Small World (HNSW). Para comprimir la memoria necesaria para almacenar los contextos, también se puede implementar la cuantización del producto (PQ) durante el proceso de indexación de las incrustaciones.
Milvus también admite un enfoque de búsqueda híbrida. Este enfoque nos permite combinar dos métodos diferentes durante el proceso de recuperación del contexto. Por ejemplo, podemos combinar la incrustación densa con la incrustación dispersa para recuperar contextos relevantes, mejorando la relevancia del contexto recuperado con respecto a la consulta. Esto, a su vez, también mejora la respuesta generada por el LLM. Además, si se desea, se puede combinar la incrustación densa con el filtrado de metadatos.
Si desea utilizar Milvus en la nube, ya sea en GCP o en AWS, para almacenar miles de millones de incrustaciones, puede optar por su servicio gestionado: Zilliz Cloud.
Con Zilliz Cloud, puede crear unidades de clúster (CU) optimizadas tanto en capacidad como en rendimiento para almacenar incrustaciones a gran escala. Por ejemplo, puede crear 256 CU de rendimiento optimizado que sirvan 1.300 millones de vectores de 128 dimensiones o 128 CU de capacidad optimizada que sirvan 3.000 millones de vectores de 128 dimensiones.
Diagrama de clúster lógico y autoescalado implementado en Zilliz Cloud Serverless..png](https://assets.zilliz.com/Diagram_of_logical_cluster_and_auto_scaling_implemented_in_Zilliz_Cloud_Serverless_1727047350.png)
Diagrama de clúster lógico y autoescalado implementado en Zilliz Cloud Serverless.
Si desea crear una aplicación RAG con Milvus pero también quiere ahorrar en costes operativos, puede optar por Zilliz Cloud Serverless. Este servicio proporciona una función de autoescalado dentro de Milvus, con costes que aumentan sólo a medida que crece su negocio. La opción sin servidor también es perfecta para ahorrar costes porque solo paga cuando utiliza el servicio, no cuando está inactivo.
Zilliz Cloud ha lanzado múltiples actualizaciones interesantes recientemente, incluyendo un nuevo servicio de migración, múltiples réplicas, nueva integración con conectores Fivetran, capacidad de auto-escalado, y muchas más características de preparación para la producción. Vea más detalles a continuación:
Zilliz Cloud Update: Migration Services, Fivetran Connectors, Multi-replicas, and More](https://zilliz.com/blog/zilliz-sep-24-launch)
Monitorización y capacidad de observación mejoradas en Zilliz Cloud](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
Desbloquee la búsqueda potenciada por IA con Fivetran y Milvus](https://zilliz.com/blog/unlock-ai-powered-search-with-fivetran-and-milvus)
Las 5 razones principales para migrar de Milvus de código abierto a Zilliz Cloud](https://zilliz.com/blog/top-5-reasons-to-migrate-milvus-to-zilliz-cloud)
Técnicas de recuperación
El objetivo principal del componente de recuperación es obtener los k contextos más relevantes para una consulta determinada. Sin embargo, un reto importante en este componente que podría afectar a la calidad general de nuestra GAR procede de la propia consulta. A menudo, las consultas originales están mal redactadas o expresadas, y carecen de la información semántica necesaria para que las aplicaciones de la GAR obtengan los contextos pertinentes.
Algunas de las técnicas que se suelen aplicar para resolver este problema son:
Reescritura de consultas**: Pide al LLM que reescriba la consulta original para mejorar su claridad y su información semántica.
Descomposición de la consulta:** Descompone la consulta original en subconsultas y realiza la recuperación basándose en estas subconsultas.
Generación de pseudodocumentos](https://zilliz.com/learn/improve-rag-and-information-retrieval-with-hyde-hypothetical-document-embeddings):** Genera documentos hipotéticos o sintéticos a partir de la consulta original y los utiliza para recuperar documentos similares en la base de datos. La aplicación más conocida de este enfoque es HyDE (Hypothetical Document Embeddings).
Los experimentos demuestran que la combinación de HyDE y la búsqueda híbrida da los mejores resultados en TREC DL19/20 en comparación con la reescritura y la descomposición de consultas. La búsqueda híbrida mencionada en el experimento combina LLM Embedder para obtener incrustaciones densas y BM25 para obtener incrustaciones dispersas.
El flujo de trabajo de HyDe + búsqueda híbrida es el siguiente: en primer lugar, generamos un documento hipotético que responde a la consulta con HyDE. A continuación, este documento hipotético se concatena con la consulta original antes de transformarlo en incrustaciones densas y dispersas mediante LLM Embedder y BM25, respectivamente.
Resultados de distintos métodos de recuperación. .png](https://assets.zilliz.com/Results_for_different_retrieval_methods_b8ef782a59.png)
Results for different retrieval methods._ Fuente
Aunque la combinación de HyDE y la búsqueda híbrida da los mejores resultados, también conlleva mayores costes computacionales. Basándonos en otras pruebas realizadas en varios conjuntos de datos de PNL, tanto la búsqueda híbrida como el uso exclusivo de incrustaciones densas ofrecen un rendimiento comparable al de HyDE + búsqueda híbrida, pero con una latencia casi 10 veces menor. Por lo tanto, sería más recomendable utilizar una búsqueda híbrida.
Dado que utilizamos una búsqueda híbrida, los contextos recuperados se basan en búsqueda vectorial a partir de incrustaciones densas y dispersas. Por lo tanto, también es interesante examinar el impacto del valor de ponderación entre las incrustaciones densas y dispersas en la puntuación global de relevancia según esta ecuación:
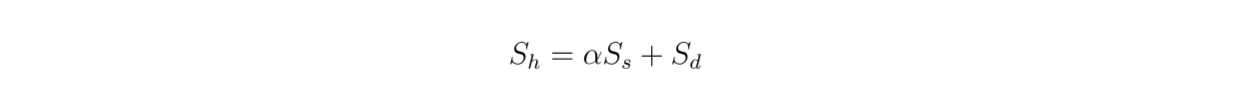 formula.png
formula.png
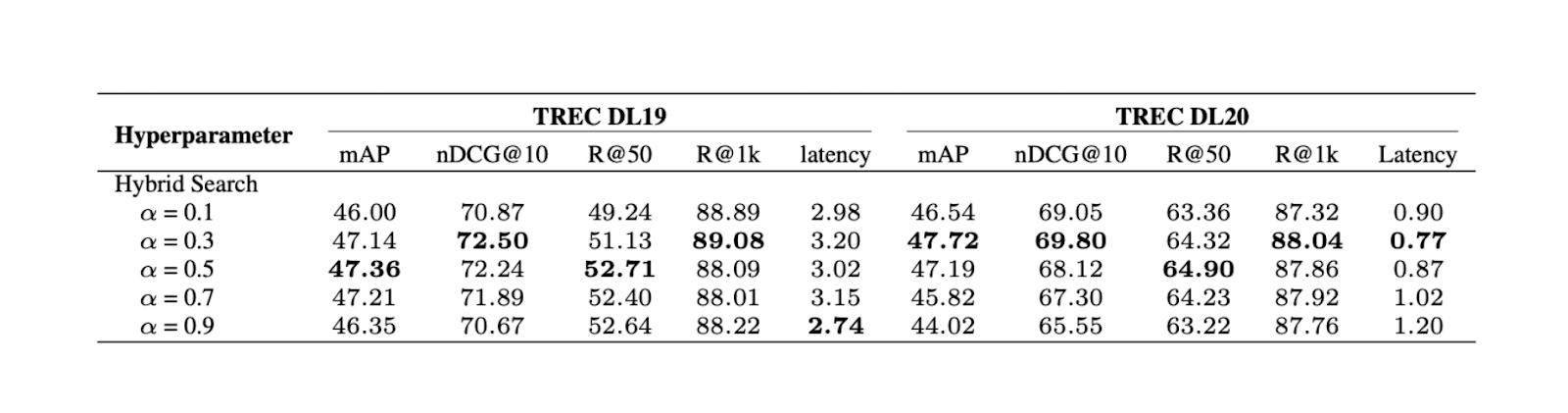 Figura- Resultados de la búsqueda híbrida con diferentes valores alfa..png
Figura- Resultados de la búsqueda híbrida con diferentes valores alfa..png
Figura: Resultados de la búsqueda híbrida con diferentes valores alfa. Fuente._
El experimento muestra que un valor de ponderación de 0,3 arroja la mejor puntuación global de relevancia en TREC DL19/20.
Técnicas de reordenación y reempaquetado
El objetivo principal de las técnicas de reordenación es reordenar los k contextos más relevantes obtenidos del método de recuperación para garantizar que el contexto más similar aparezca al principio de la lista. Existen dos métodos habituales para reordenar los contextos:
Reordenación DLM**: Este método utiliza un modelo de aprendizaje profundo para la reordenación. El modelo se entrena con un par formado por la consulta original y un contexto como entrada y una etiqueta binaria "verdadero" (si el par es relevante entre sí) o "falso" como salida. A continuación, los contextos se clasifican en función de la probabilidad que devuelve el modelo cuando predice un par de consultas y contexto como "verdadero".
RejerarquizaciónTILDE: Este enfoque utiliza la probabilidad de cada término de la consulta original para reordenarla. Durante el tiempo de inferencia, podemos utilizar el componente de probabilidad de la consulta (TILDE-QL) solo para una reordenación más rápida o la combinación de TILDE-QL con su componente de probabilidad del documento (TILDE-DL) para mejorar el resultado de la reordenación con un mayor coste computacional.
Figura- Resultados de los distintos métodos de reordenación..png](https://assets.zilliz.com/Figure_Results_of_different_reranking_methods_0174dc1792.png)
Figura: Resultados de distintos métodos de reordenación _ Fuente
Los experimentos realizados con el conjunto de datos MS MARCO Passage ranking muestran que el método DLM reranking con el modelo Llama 27B ofrece el mejor rendimiento de reranking. Sin embargo, al tratarse de un modelo grande, su uso conlleva un coste computacional significativo. Por lo tanto, se recomienda más el uso de mono T5 para el reranking DLM, ya que proporciona un equilibrio entre rendimiento y eficiencia computacional.
Después de la fase de reordenación, también tenemos que considerar cómo presentar los contextos reordenados a nuestro LLM: si en orden descendente ("hacia delante") o ascendente ("hacia atrás"). A partir de los experimentos realizados en este artículo, se puede concluir que la mejor calidad de respuesta se genera utilizando la configuración "inversa". La hipótesis es que posicionar el contexto más relevante más cerca de la consulta conduce a resultados óptimos.
Técnicas de resumen
En los casos en los que tenemos contextos largos recuperados de componentes anteriores, es posible que queramos hacerlos más compactos y eliminar la información redundante. Para lograr este objetivo, se suelen aplicar enfoques de resumen.
Existen dos técnicas diferentes de resumen de contextos: extractiva y abstractiva.
El resumen extractivo divide el documento de entrada en segmentos más pequeños y los clasifica en función de su importancia. Por su parte, el método abstractivo genera un nuevo resumen contextual que sólo contiene información relevante.
Comparación entre distintos métodos de resumen..png](https://assets.zilliz.com/Figure_Comparison_between_different_summarization_methods_3e8e54c91c.png)
Figura: Comparación entre diferentes métodos de resumen._ Fuente
Según los experimentos realizados en tres conjuntos de datos diferentes (NQ, TriviaQA y HotpotQA), el resumen abstractivo con Recomp ofrece el mejor rendimiento en comparación con otros métodos abstractivos y extractivos.
El resumen de las mejores técnicas de GAR
Ahora que conocemos el mejor enfoque de cada componente de la GAR para conjuntos de datos de referencia específicos, podemos seguir probando todos los enfoques mencionados en las secciones anteriores en más conjuntos de datos. Los resultados muestran que cada componente contribuye al rendimiento global de nuestra aplicación GAR. A continuación se muestra un resumen de los resultados de cada enfoque en cada componente basado en cinco conjuntos de datos diferentes:
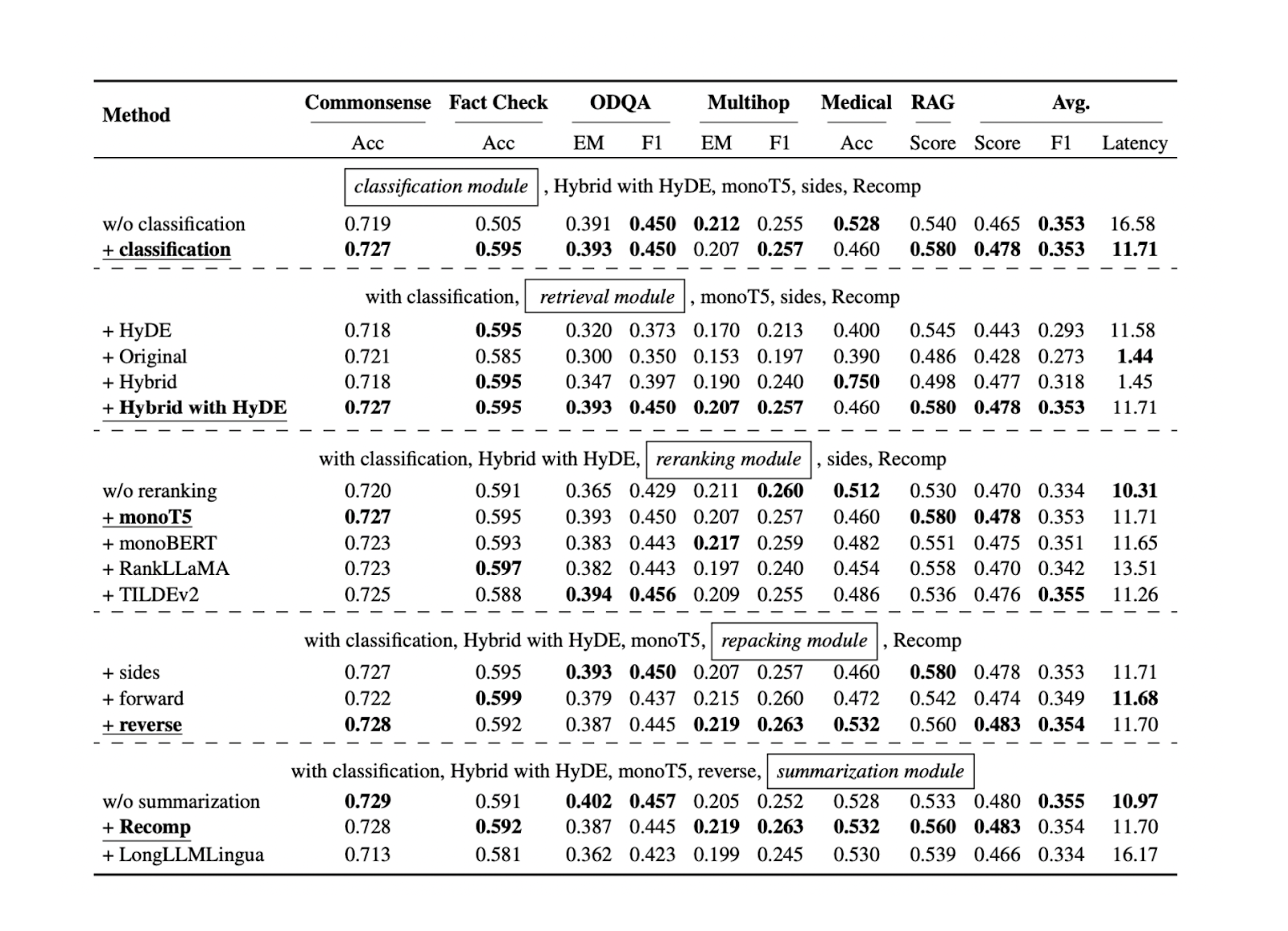 Figura- Resultados de la búsqueda de prácticas óptimas de GAR..png
Figura- Resultados de la búsqueda de prácticas óptimas de GAR..png
Figura: Resultados de la búsqueda de prácticas óptimas de GAR._ Fuente
El componente de clasificación de consultas demuestra que ayuda a mejorar la precisión de las respuestas y a reducir la latencia general del tiempo de ejecución. Este paso inicial ayuda a determinar si una consulta requiere recuperación de contexto o puede ser procesada directamente por el LLM, optimizando así la eficiencia del sistema.
El componente de recuperación es crucial para garantizar que obtenemos candidatos de contexto relevantes con respecto a la consulta. Para este componente, se recomienda una base de datos vectorial más escalable y con mayor rendimiento como Milvus o su servicio gestionado, Zilliz Cloud. Además, se recomienda la búsqueda híbrida o la búsqueda de incrustación densa. Estos métodos logran un equilibrio entre la comparación exhaustiva de contextos y la eficiencia computacional.
El componente de reordenación garantiza que obtengamos los contextos más relevantes reordenando los k contextos más importantes recuperados del componente de recuperación. El modelo monoT5 se recomienda para la reordenación por su equilibrio entre rendimiento y coste computacional. Este paso refina la selección de contextos, dando prioridad a los más relevantes para la consulta.
Para reordenar el contexto se recomienda el método inverso. Este enfoque posiciona el contexto más relevante más cerca de la consulta, lo que puede dar lugar a respuestas más precisas y coherentes del LLM.
Por último, el método abstractivo con Recomp ha mostrado el mejor rendimiento para el resumen de contextos. Esta técnica ayuda a condensar contextos largos conservando la información clave, lo que facilita al LLM el procesamiento y la generación de respuestas relevantes.
Ajuste del LLM
En la mayoría de los casos, el ajuste fino del LLM no es necesario, especialmente si utilizas un LLM de alto rendimiento con muchos parámetros. Sin embargo, si tienes limitaciones de hardware y sólo puedes utilizar LLMs más pequeños, puede que necesites ajustarlos para hacerlos más robustos a la hora de generar respuestas relacionadas con tu caso de uso. Antes de ajustar un LLM, debe tener en cuenta los datos que utilizará como datos de entrenamiento.
Durante la preparación de los datos, puedes recopilar datos de entrenamiento en prompt y contexto como un par de entradas, con un ejemplo de texto generado como salida. Los experimentos demuestran que aumentar los datos con una mezcla de contextos relevantes y seleccionados al azar durante el entrenamiento dará como resultado el mejor rendimiento. La intuición detrás de esto es que mezclar contextos relevantes y aleatorios durante el ajuste fino puede mejorar la robustez de nuestro LLM.
Conclusión
En este artículo hemos explorado varios componentes de la GAR, desde la clasificación de consultas hasta el resumen de contextos. Hemos discutido y destacado los enfoques con un rendimiento óptimo en cada componente.
Estos componentes optimizados trabajan conjuntamente para mejorar el rendimiento global del sistema RAG. Mejoran la calidad y la relevancia de las respuestas generadas al tiempo que mantienen la eficiencia computacional. Aplicando estas mejores prácticas en cada componente, podemos crear un sistema GAR más robusto y eficaz, capaz de gestionar una amplia gama de consultas y tareas.
Más información
Generative AI Resource Hub | Zilliz](https://zilliz.com/learn/generative-ai)
Modelos de IA de alto rendimiento para tus aplicaciones de GenAI | Zilliz](https://zilliz.com/ai-models)
Construir aplicaciones de IA con Milvus: tutoriales y cuadernos](https://zilliz.com/learn/milvus-notebooks)
Cómo crear un RAG multilingüe con Milvus, LangChain y OpenAI](https://zilliz.com/blog/building-multilingual-rag-milvus-langchain-openai)
Construir un GAR multimodal con Gemini, BGE-M3, Milvus y LangChain](https://zilliz.com/learn/build-multimodal-rag-gemini-bge-m3-milvus-langchain)
¿Qué es GraphRAG? Mejora de RAG con grafos de conocimiento ](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
Cómo evaluar aplicaciones RAG](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
Sigue leyendo

Vector Lakebase: End the AI Data Silo
Learn how Vector Lakebase unifies vector search, data lakes, and AI data operations so teams can serve RAG and agents without copy-and-sync pipelines.

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

Expanding Our Global Reach: Zilliz Cloud Launches in Azure Central India
Zilliz Cloud expands to Azure Central India. This new region helps customers meet compliance, reduce latency, and optimize cloud costs when building AI applications.