




Data Mastery Made Easy: Exploring the Magic of Vector Databases in Jupyter Notebooks
Anthropic recently released a 100k token version of Claude. Google recently released PaLM 2. And of course, we are all well aware of GPT and ChatGPT from OpenAI at this point. Large language models (LLMs) have driven the speed up in AI adoption, driving demand for vector databases along with them.
Why? Because vector databases can help solve one of the biggest problems LLMs face - a lack of domain knowledge and up-to-date data. Outside of LLMs, vector databases also show their usefulness in powering similarity search applications. In addition, they are necessary for working on product recommendations, reverse image search, and semantic text search.
How can you get started with a vector database in your Jupyter Notebook? This tutorial covers:
- What is a Vector Database?
- How to Use a Vector Database in Your Jupyter Notebook
- What is Milvus (Lite)?
- Summary of a Vector Database in Your Jupyter Notebook
This equally applies to CoLab notebooks. Here are two for you: a CoLab notebook for reverse image search, and a CoLab notebook for semantic text search.
What is a Vector Database?
Before we jump into the tutorial, let’s get a basic understanding of vector databases. A vector database is built to store, index, and query vector data. They are primarily used for working with unstructured data such as images, text, or video. First, you run your data through an existing neural network to get the vector embeddings, usually extracted from the second to last layer.
Those vector embeddings then get stored in a vector database. Once your vector embeddings are stored, you can query the vector database for the top k most similar data entries via vector embeddings as shown in the CoLab notebooks above. Some of the tools that vector databases abstract out for you include:
- Vector indexes you’d have to include otherwise.
- Vector search algorithms such as HNSW.
- A way to communicate with a persistent storage layer.
What is Milvus (Lite)?
Milvus is a vector database with a distributed system native backend. It is purpose-built to handle indexing, storing, and querying vector data at a billion scales. Milvus uses multiple layers and types of worker nodes for an easily scalable design. In addition to using multiple single-purpose nodes, Milvus also uses segmented data for more efficient indexing. Milvus uses 512MB data segments that don’t get changed after they are filled and queries them in parallel to offer the lowest latency across the industry.
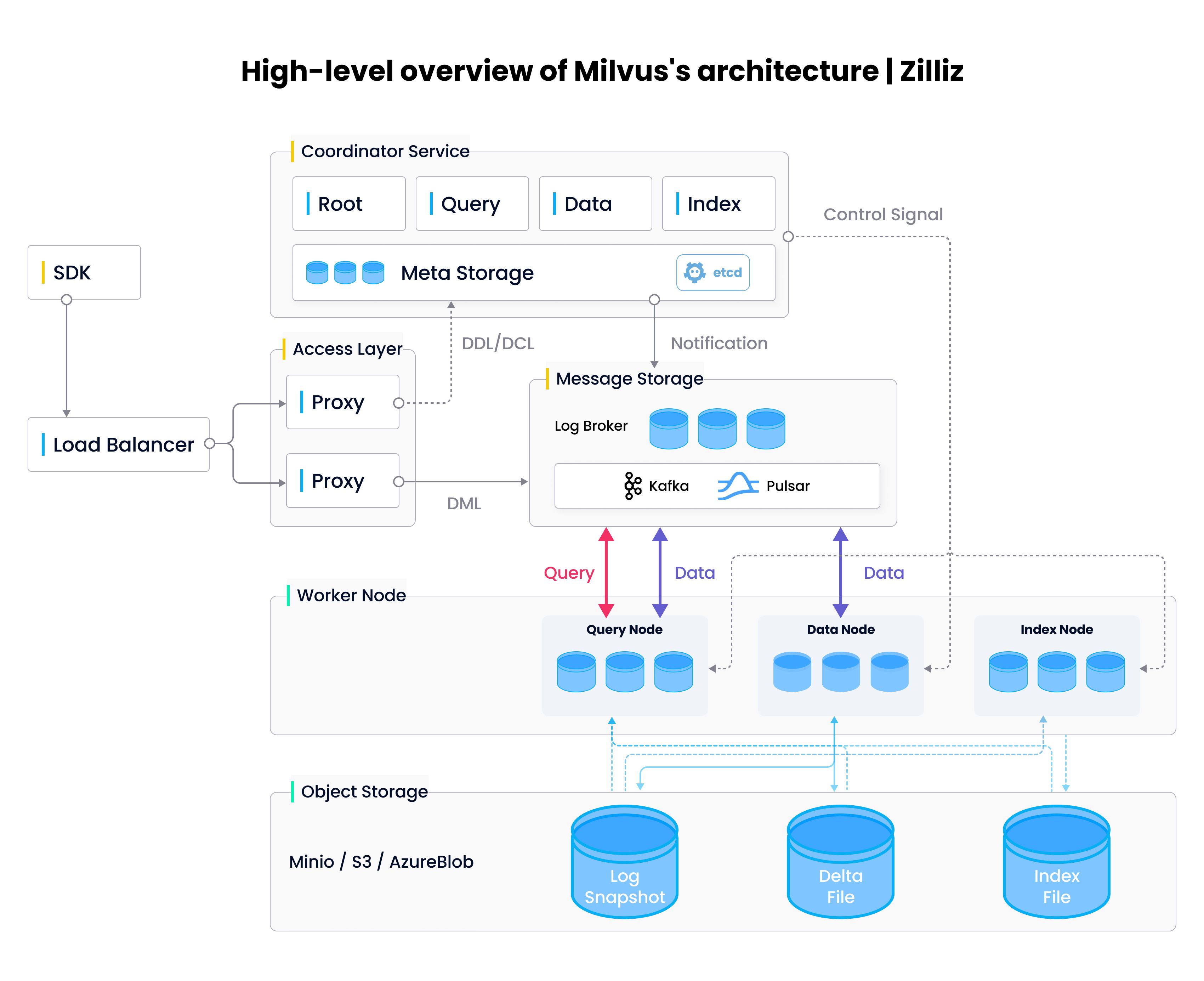 High Level architecture of Milvus Vector Database
High Level architecture of Milvus Vector Database
Typically, you would use Docker Compose, Helm, or the Milvus Operator to launch a Milvus instance. However, Milvus Lite lets you launch a Milvus instance directly from your Jupyter Notebook or Python script. It works in the same way as Milvus and saves all your data locally.
How to Use a Vector Database in Your Jupyter Notebook
You can start with a vector database like Milvus Lite directly in your notebook through a pip install. In the first line of your Jupyter Notebook, run ! pip install pymilvus milvus. Once you have pymilvus and milvus installed, you can start up the vector database and connect to it within an iPython notebook.
The milvus module provides Milvus Lite and the pymilvus module provides a Python interface to connect to Milvus. To start, we import three modules. First, default_server from milvus. Second,connections from pymilvus, and third, utility from pymilvus. We use the start() function from the default_server to start the server. Once the server is started, we connect using connect from connections and passing in the host, localhost or 127.0.0.1, and the port, retrieved from the default server.
from milvus import default_server
from pymilvus import connections, utility
default_server.start()
connections.connect(host="127.0.0.1", port=default_server.listen_port)
Once you’ve connected to Milvus, you can use utility to check on your database. For example, call get_server_version() to ensure you have the latest version, which you can check for on the Milvus Blog. You can also use utility to check for collections, separate tables in Milvus. If you want to start anew, you can check if a collection with the name you want to use is already in use and either drop it with drop_collection, or pick a new name.
utility.get_server_version()
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
Want to go even further and use a vector database in production or for a larger project? Consider Zilliz Cloud or Milvus Standalone.
Summary of How to Use a Vector Database in Your Jupyter Notebook
In this post, we learned that vector databases are helpful whenever you need to do anything that involves a similarity search. They help index, store, and query vector embedding representations of unstructured data like images, videos, or text. Then we look at an example of using a vector database in your Jupyter Notebook via Milvus Lite.
Finally, we peek under the hood of Milvus to see the distributed system backend. We also provide resources to understand how to start using a vector database via examples in CoLab notebooks. For those that want to use a standalone vector database instance, we also provide examples for how to set up Milvus Standalone.

Keep Reading

VDBBench Adds Cost-Aware Benchmarking for Vector Databases
Compare Zilliz Cloud, Pinecone, and turbopuffer with VDBBench cost-aware vector database benchmarks across latency, freshness, multitenancy, and cold starts.

Zilliz Cloud BYOC Now Available Across AWS, GCP, and Azure
Zilliz Cloud BYOC is now generally available on all three major clouds. Deploy fully managed vector search in your own AWS, GCP, or Azure account — your data never leaves your VPC.

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.