




DeepSeek-OCR Explained: Optical Compression for Scalable Long-Context and RAG Systems
Large language models (LLMs) still struggle when processing long contexts. Handling long text consumes a lot of computing power, increases latency, and often reduces output quality. Despite many optimization efforts, the results have remained unsatisfactory.
To tackle this problem, DeepSeek introduced DeepSeek-OCR, an open-source model that compresses long contexts using optical 2D mapping. Instead of feeding raw text into the model, it converts pages of text into images and treats those images as visual tokens. One image can contain as much information as thousands of text tokens, allowing the model to handle long documents with far fewer resources.
The idea is both clever and straightforward. By using visual representations, DeepSeek-OCR maintains high accuracy while reducing computation. This could be a turning point—not only for handling long contexts for LLMs but also for RAG systems, which have long struggled with high costs and limited context windows.
In the sections ahead, I’ll explain how DeepSeek-OCR works and explore how this “optical compression” approach might shape the next generation of LLMs and RAG systems.
The Traditional Way LLMs Handle Text — and Its Core Limitations
To understand why DeepSeek-OCR is such a big deal, it helps to first understand how large language models (LLMs) traditionally handle text and its limitations. LLMs don’t read words or sentences the way humans do—they process tokens, which are small units of text, such as words, subwords, or even characters. When a model receives input, it converts the text into a long sequence of these tokens. The self-attention mechanism then compares every token with every other token to understand context and meaning. This method works well for short passages but quickly becomes inefficient as the sequence grows longer.
Quadratic Compute Costs
That inefficiency is rooted in the math: the computational cost of self-attention increases quadratically (O(n²)) with the number of tokens. If an input grows from 1,000 to 10,000 tokens, the number of attention operations increases by a factor of 100. Even top-tier GPUs can hit memory limits or inference timeouts when faced with such workloads.
Flattened Attention: Losing Focus in Long Contexts
The problem doesn’t stop there. As sequences stretch, the model’s attention weights tend to flatten—spreading too evenly across the text or focusing only on the beginning and end. This loss of focus hurts accuracy and relevance, no matter how much compute you throw at it.
Inefficiency in Multimodal and Structured Text
Text tokens also fall short in multimodal or structured document tasks such as PDFs, slides, or spreadsheets. Once text is tokenized, the layout, tables, and visual structure are lost, even though they carry crucial meaning. Multilingual text adds another layer of complexity: each language requires its own tokenizer with unique segmentation rules. And after all that, even the most aggressive text-based compression rarely goes beyond a modest 1–2× reduction in token count—far from enough for real long-context applications.
DeepSeek-OCR: Powering Long-Context Processing with Contexts Optical Compression
As discussed earlier, the traditional token-based approach faces three hard limits: high computational cost, loss of focus, and loss of document structure when handling multimodal text. DeepSeek-OCR overcomes these challenges by turning text into visual tokens—compressing far more information into fewer elements while preserving meaning and structure.
So how does it work? The key lies in a new paradigm called Contexts Optical Compression. Instead of feeding long streams of text tokens into the model, DeepSeek-OCR first converts the text into images and then encodes those images into compact visual tokens. This process directly addresses the two biggest pain points in LLMs: the high computational cost of long contexts and the loss of document structure during tokenization.
Here’s how it works in three steps:
Render text into structured document images. The original text—along with charts, tables, and equations—is rendered into images that preserve visual layout and semantic cues.
Compress images into visual tokens. A visual encoder transforms each image into a compact representation, reducing the token count by 7–20×, and up to 60× on benchmarks such as OmniDocBench.
Reconstruct text from visual tokens. A language decoder converts these visual tokens back into text with more than 97% recognition accuracy, retaining both meaning and formatting.
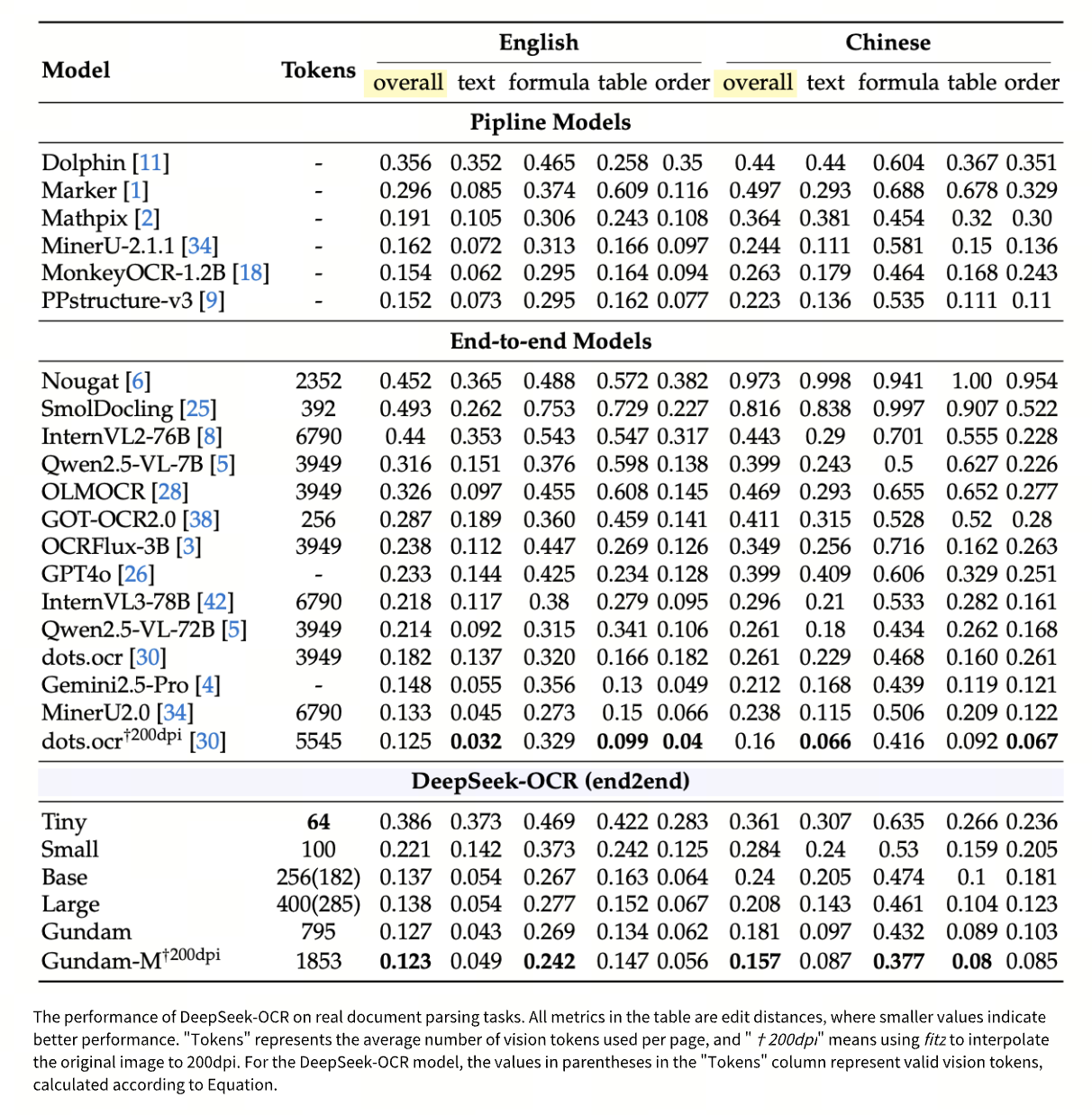
This approach works because document images can hold equivalent semantic information with dramatically fewer tokens. At the same time, they inherently preserve layout, symbols, and other non-text elements that ordinary tokenization discards. In effect, DeepSeek-OCR sidesteps the core limitations of text-based LLMs—maintaining structure, semantics, and efficiency all at once.
Under the hood, Contexts Optical Compression is powered by two core components: a DeepEncoder, which performs high-ratio compression of document images, and an MoE (Mixture-of-Experts) Decoder, which reconstructs the original content from the visual tokens. Together, they allow DeepSeek-OCR to process long-context information with both high accuracy and remarkable efficiency.
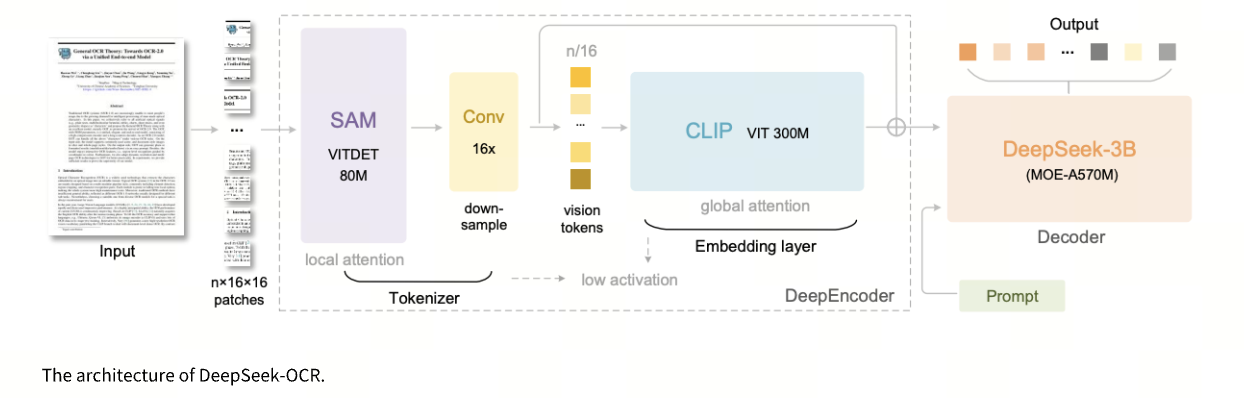
DeepEncoder: Compression Meets Precision
The DeepEncoder is the core of DeepSeek-OCR’s architecture—the component responsible for extracting visual features and compressing them into compact, information-rich visual tokens. It combines precision with efficiency through a three-part architecture:
SAM-base (800M parameters): Uses windowed attention to process high-resolution document images. This design captures fine details such as characters and punctuation while keeping activation memory under control.
16× Convolutional Compressor (2 layers): Reduces the number of image tokens by a factor of 16. For example, a 1024×1024 image that initially generates 4,096 tokens shrinks to just 256—achieving 16× compression with minimal quality loss.
CLIP-large (300M parameters): Applies dense global attention to maintain semantic consistency across the whole document. It preserves relationships such as table row–column alignment and formula structure, even under aggressive compression.
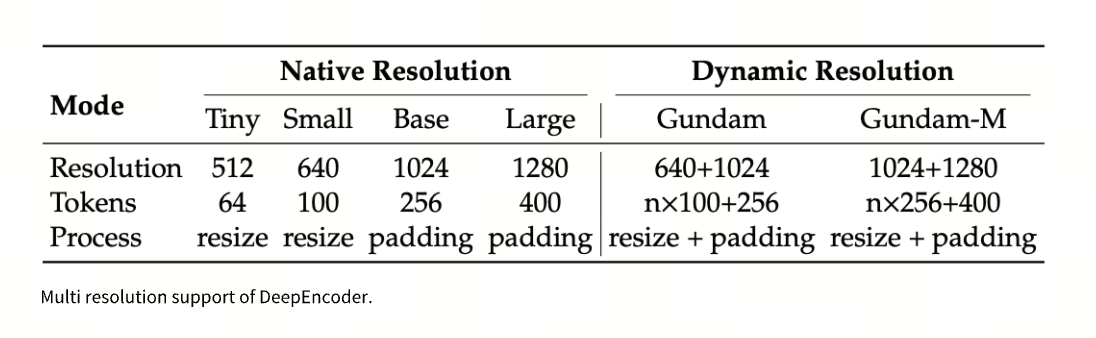
The DeepEncoder supports six resolution modes — Tiny, Small, Base, Large, Gundam, and Gundam-M — generating between 64 and 1,853 visual tokens depending on task requirements. This flexibility enables adaptive context management: low-resolution compression for older or less important content, and high-resolution encoding for recent, critical segments.
MoE Decoder: Efficient and Accurate Reconstruction
Once compression is complete, the MoE (Mixture of Experts) Decoder reconstructs the text efficiently and accurately. DeepSeek-OCR employs the DeepSeek-3B-MoE-A570M model, which achieves large-model accuracy with a fraction of the compute. Only 570M parameters are activated at a time (selecting 6 out of 64 experts plus 2 shared ones), achieving processing accuracy comparable to large-scale models within a 3-billion-parameter framework.
The decoder also supports nonlinear mapping from visual tokens to text tokens, enabling structured and semantically rich outputs. For example, it can convert charts to HTML tables or translate chemical formulas into SMILES strings, ensuring that complex visual data is faithfully represented in text.
In terms of performance, the MoE Decoder is both fast and scalable:
Processes up to 90 billion tokens/day on pure text data
Handles 70 billion tokens/day on multimodal datasets
Achieves 2,500 tokens per second throughput on a single A100-40G GPU
This combination of compression efficiency, structural preservation, and decoding speed dramatically lowers the cost of long-context processing while maintaining near–large-model precision.
What DeepSeek-OCR Has Achieved and Why It Matters
The impact of DeepSeek-OCR extends far beyond boosting OCR accuracy. Through cross-modal compression, it introduces a new foundation for long-context LLMs, multimodal reasoning, and multilingual document understanding. By turning text into a universal visual representation, DeepSeek-OCR unlocks three significant advancements that push the boundaries of large-model efficiency and versatility.
1. End-to-End Processing of Mixed Text-and-Image Documents
Traditional pipelines struggle with documents that contain charts, formulas, or other visual elements. Typically, they rely on a separate OCR step to convert images into text—often losing formatting, breaking structure, or introducing recognition errors—before the text is passed to a tokenizer for further processing.
DeepSeek-OCR eliminates this fragile middle step. It directly converts mixed text-and-graphic content into unified visual tokens, preserving structure and visual integrity in a single, continuous workflow. For example, when analyzing a financial report with embedded line charts, the model’s visual tokens retain the trends themselves. The decoder can then generate structured outputs—such as editable HTML tables or formatted text—rather than flat strings.
2. Greater Universality in Multilingual Processing
Token-based systems require separate tokenizers for each language, each following different segmentation rules—for example, Chinese character composition, English subword units, or Arabic script connections. Managing this complexity makes multilingual model training and maintenance both expensive and error-prone.
DeepSeek-OCR solves this by using images as an intermediate representation, enabling it to process over 100 languages without distinguishing among linguistic families. This lowers the barrier to multilingual document understanding, enabling a single model architecture to handle diverse text systems seamlessly.
3. Lower Costs and Smarter Context Management for Long Documents
Conventional long-context processing solutions—such as sliding windows or sparse attention—optimize efficiency at the level of text tokens, but they still operate within the O(n²) computational bottleneck of attention. In contrast, by transforming text → image → visual tokens, DeepSeek-OCR replaces text-based computation with a lower-complexity visual carrier, reducing the heavy computational load that comes with long text sequences.
This design brings another important advantage: adaptive context management. The model can allocate higher resolution (more visual tokens) to recent, detail-rich content while assigning lower resolution (fewer visual tokens) to older or less important information. This makes DeepSeek-OCR particularly effective for multi-turn dialogue, long-document analysis, and retrieval-augmented generation (RAG) scenarios where both memory and precision are critical.
Looking Forward: How DeepSeek-OCR Points to the Future of RAG
DeepSeek-OCR offers valuable insight into where RAG could go next. Its core principle—compressing information into visual tokens—echoes the logic behind models like Sentence-BERT, which transform text into dense embeddings. Both approaches share the same goal: representing rich, complex information in a compact and computationally efficient form.
Looking ahead, this idea could fundamentally reshape multimodal RAG. When processing documents that include charts, tables, or figures, DeepSeek-OCR can skip the decoding step entirely and feed its compressed visual tokens directly into a multimodal large model for reasoning or generation. Future RAG systems could follow a similar path—evolving from today’s multi-step process (embedding similarity search → text reconstruction → LLM input) into a more streamlined pipeline: embedding retrieval → direct LLM input.
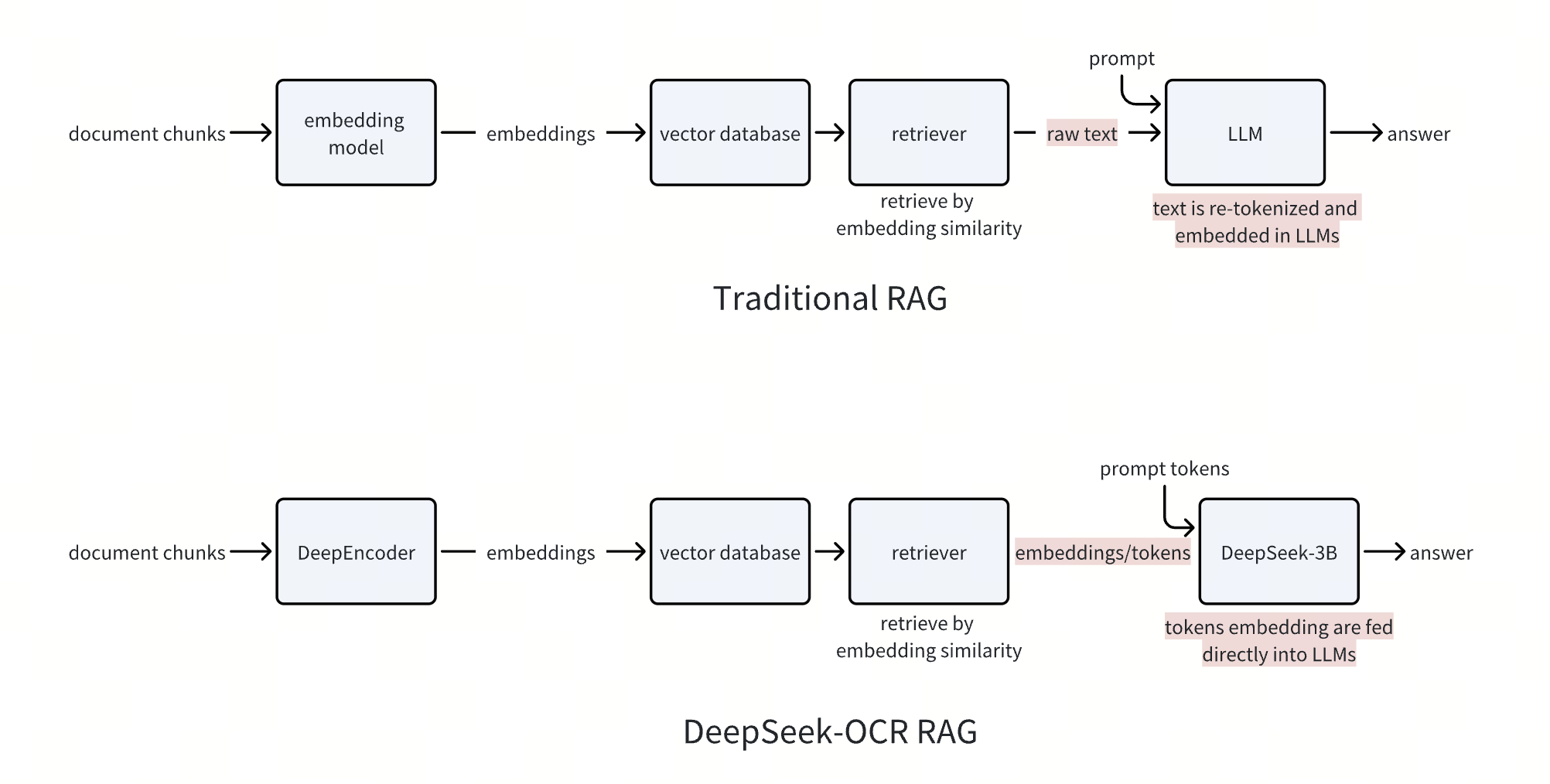
This paradigm shift addresses several of RAG’s long-standing inefficiencies. Current systems repeatedly tokenize text and regenerate embeddings for every query—wasting compute and introducing information loss. These costs compound with longer documents, where attention mechanisms scale quadratically with token count. By contrast, if embeddings or visual tokens can be retrieved and supplied directly to the LLM, tokenization loss is eliminated, and compute overhead drops dramatically.
This also enables a more efficient offline–online workflow. Embeddings can be generated once, stored in a vector database such as Milvus, and reused indefinitely. At query time, only the Top-K embeddings—often fewer than 20—need to be fetched to provide precise contextual grounding for the model.

Keep Reading

The Great AI Agent Protocol Race: Function Calling vs. MCP vs. A2A
Compare Function Calling, MCP, and A2A protocols for AI agents. Learn which standard best fits your development needs and future-proof your applications.

Similarity Metrics for Vector Search
Exploring five similarity metrics for vector search: L2 or Euclidean distance, cosine distance, inner product, and hamming distance.

What is the K-Nearest Neighbors (KNN) Algorithm in Machine Learning?
KNN is a supervised machine learning technique and algorithm for classification and regression. This post is the ultimate guide to KNN.