




Enhancing ChatGPT's Intelligence and Efficiency: The Power of LangChain and Milvus
This post was originally published in TheSequence and is reposted here with permission.
While ChatGPT has gained significant popularity, with many individuals utilizing its API to develop their chatbots or explore Langchain, it's not without its challenges.
ChatGPT can often create the illusion of intelligence. Users may engage with a chatbot that employs complex jargon, only to later realize the bot generates nonsensical responses or fabricates non-existent 404 links.
Context storage is another hurdle. ChatGPT only retains records from the ongoing session, meaning a bot trained mere days ago can act as if it has no recollection of the session. This "amnesia" highlights the need for a chatbot that can preserve and retrieve data.
Cost and performance are significant considerations when using ChatGPT or even smaller open-source models for inference. In many cases, this can be costly, requiring several A100s and substantial time. Developments must address the performance bottlenecks before pulling large language models (LLMs) into real-time applications.
Enhancing ChatGPT's intelligence is where the combination of LangChain and Milvus comes into play. With the integration of LangChain and Milvus, LLMs can harness vector stores' power to increase intelligence and efficiency. How does all of this work? Let's dive into the power of LangChain and Milvus in LLM applications, then explore how to build and enhance your own AI Generated Content (AIGC) application.
LangChain for LLM-powered application
LangChain is a framework for developing applications powered by language models. The LangChain framework is designed around the following principles:
- Data-aware: connect a language model to other sources of data
- Agentic: allow a language model to interact with its environment
LangChain's robust framework consists of a range of modules, such as Models, Prompts, Memory, Indexes, Chains, Agents, and Callbacks, which are the core abstractions that can view as the building blocks of any LLM-powered application. For each module, LangChain provides standard, extendable interfaces. LanghChain also provides external integrations and even end-to-end implementations for off-the-shelf use.
The LLM wrapper is at the heart of LangChain functionality, offering a host of LLM providers such as OpenAI, Cohere, Hugging Face, etc. It provides a standard interface to all LLMs and includes common tools for working with them.
Vector database for LLMs
LangChain offers an impressive range of Large Language Models (LLMs) to cater to diverse needs. But that's not all. LangChain goes beyond the basics by integrating various vector databases such as Milvus, Faiss, and others to enable the semantic search functionality. Through its VectorStore Wrapper, LangChain standardizes the necessary interfaces to simplify the loading and retrieval of data. For instance, using the Milvus class, LangChain allows the storage of feature vectors representing documents using the from_text method. The similarity_search method then fetches vectors of the query statement to find the nearest-matching documents to the query in the embedding space, thus facilitating semantic search with ease.
Delving deeper into the subject, we realize that vector databases have a significant role in LLM applications, as evident from the chatgpt-retrieval-plugin. But that's not where their utility ends. Vector databases have a plethora of other use cases, making them an indispensable component of LLM applications:
- Vector Databases facilitate context-based storage, a helpful feature in LLM platforms like Auto-GPT and BabyAGI. This capability enhances contextual understanding and retention of memories.
- Vector Databases provide semantic caching for LLM platforms like GPTCache, which optimizes performance and enables cost savings.
- Vector Databases enable document knowledge capabilities, such as OSSChat, which resolve hallucinations.
- And much more.
If you want to learn more about Milvus and Auto-GPT, you can read this article about how Milvus powers Auto-GPT. In the following section, you will learn how LangChain and Milvus can address hallucinations.
Why LangChain + Milvus can resolve hallucinations
In artificial intelligence, there is a saying that the system will frequently generate "hallucinations," which means fabricating facts unrelated to reality. Some even describe ChatGPT as "a confident guy who can write very convincing nonsense," and the hallucination problem undermines the credibility of ChatGPT.
Vector Databases illustrated in the following diagram address the issue of hallucinations. First, store the official documents as text vectors in Milvus, and search for relevant documents in response to the question (the orange line in the diagram). Chatgpt answers the question based on the correct context, resulting in the expected answer (the green line in the diagram).
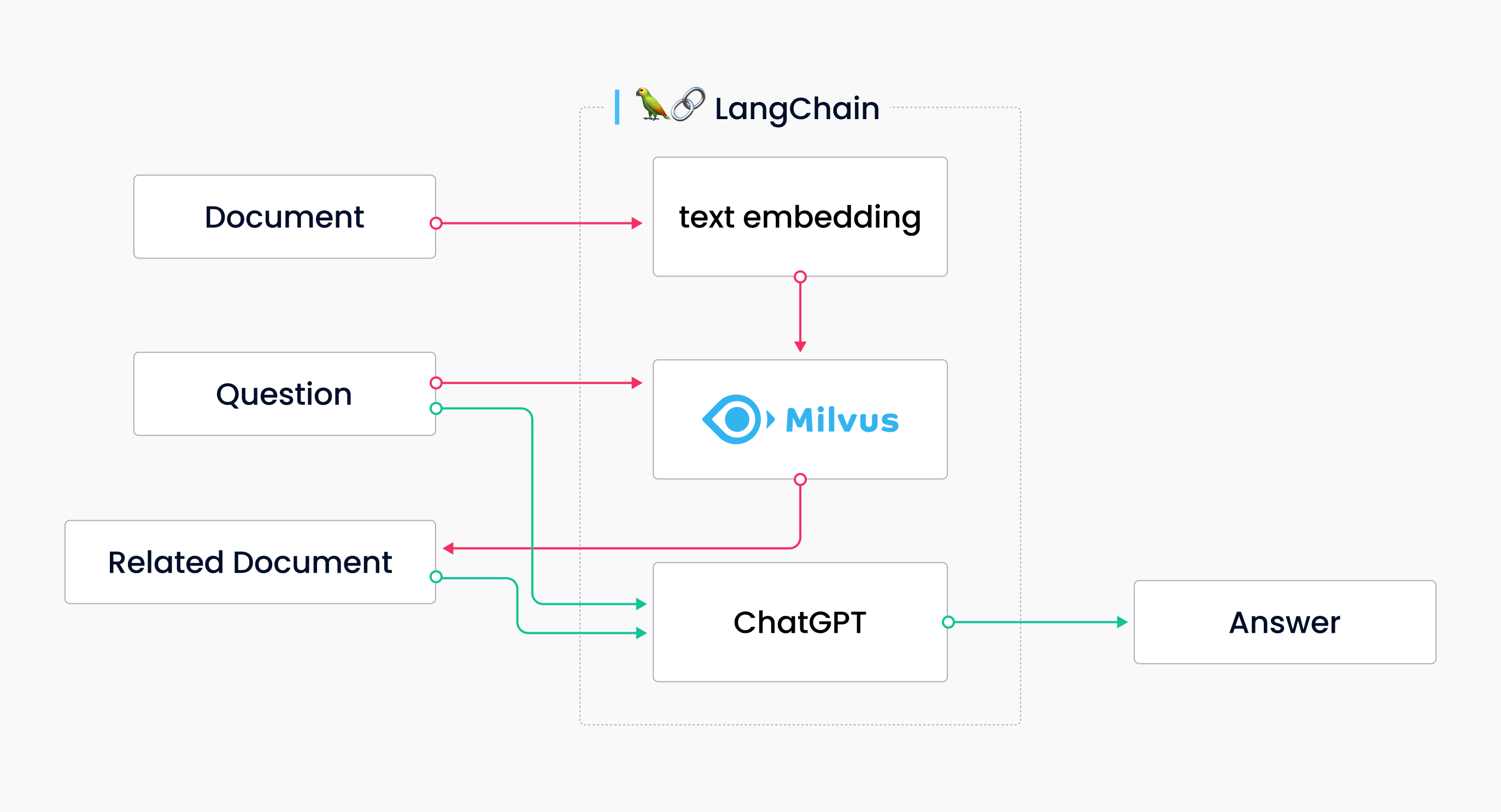 Diagram showing Langchain, Milvus, and ChatGPT
Diagram showing Langchain, Milvus, and ChatGPT
The example above shows that combining Milvus and ChatGPT is very simple. There's no need to label data, train or develop it, or fine-tune it – you need to convert text data into vector data and insert it into Milvus. The Langchain-Milvus-ChatGPT combo creates text storage, and the final answer is derived from referencing the content in the document library.
This ensures the chatbot is fed with the correct knowledge, effectively reducing the likelihood of errors. For example, as a community administrator, when I need to answer community-related questions, I can store all the documents from Milvus's official documentation.
When a user asks, "How to use Milvus to build a chatbot," the chatbot will answer the question based on the official documentation, telling the user that it provides examples of building applications and extracting relevant documents. This type of response is reliable. In short, we don't need to retrain or process everything; we need to feed the necessary contextual knowledge to ChatGPT. When we send a request, the robot can provide context related to the official content.
Are you feeling excited after discovering the power of Milvus and Langchain for ChatGPT? If yes, then get ready to take your application development. Let's team up and create an enhanced chatbot by using the incredible capabilities of LangChain and Milvus combined!
Build your own application with LangChain and Milvus
0. Prerequisites
First, install LangChain using the command pip install langchain. As for Milvus, you have two options at your disposal. Either install and start the open-source Milvus on your local system or go for the cloud option to try out Zilliz – a cloud-native service for Milvus that offers a free trial version. Zilliz is an easy, accessible, and robust service, so we'll dive into how to use Zilliz Cloud for the application, and LangChain makes it easy to use.
1. Load data for knowledge base
First, we need to load data into a standard format. In addition to loading the text, we need to chunk it up into small pieces. This is necessary to ensure we only pass the most minor, most relevant pieces of text to the language model.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Milvus
from langchain.document_loaders import TextLoader
loader = TextLoader('state_of_the_union.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
Next, now that we have small chunks of text, we need to create embeddings for each piece of text and store them in a vector store. Creating embeddings is done so that we can use the embeddings to find only the most relevant pieces of text to send to the language model. This is done with the following lines. Here we use OpenAI’s embeddings and Zilliz Cloud.
embeddings = OpenAIEmbeddings()
vector_db = Milvus.from_documents(
docs,
embeddings,
connection_args={
"uri": "YOUR_ZILLIZ_CLOUD_URI",
"user": "YOUR_ZILLIZ_CLOUD_USERNAME",
"password": "YOUR_ZILLIZ_CLOUD_PASSWORD",
"secure": True
}
)
2. Query data
So now that we have loaded the data, we can use it in a question-answering chain.
Check out the code snippet below, which tackles part 3, "Resolve Hallucinations," of this article. It can help you fully grasp the concept.
This involves searching for documents related to our given query from the knowledge base. To accomplish this, use the similarity_search method to generate the feature vector for the query and then search the vectors in Zilliz Cloud for similar matches, along with their associated document content.
query = "What did the president say about Ketanji Brown Jackson"
docs = vector_db.similarity_search(query)
Then run load_qa_chain to get the final answer. It provides the most generic interface for answering questions. It loads a chain that can do QA for the input documents and uses ALL of the text in the documents.
The code below uses OpenAI as the LLM. When running, the QAChain receives input_documents and question as input. The input_documents is the document related to the query in the database. Then, the LLM organizes the answer based on the content of these documents and the question being asked.
from langchain.chains.question_answering import load_qa_chain
from langchain.llms import OpenAI
llm = OpenAI(temperature=0)
chain = load_qa_chain(llm, chain_type="stuff")
chain.run(input_documents=docs, question=query)
Why Milvus is better for the AIGC application
So if you want to make your Artificial Intelligence-Generated Content (AIGC) applications more reliable, having a vector database representing text is necessary. But why choose the Milvus vector database?
- Semantic search: Milvus stores the extracted semantic feature vectors, enabling intelligent and convenient semantic retrieval, which is difficult for traditional databases. Vector databases make semantic retrieval more intelligent and convenient.
- Scalability: Support for cluster and cloud scaling makes it possible to store and retrieve billions of entities easily. Scalability is essential for applications where speed and efficiency are paramount.
- Hybrid search: Milvus supports mixed vector and scalar data search, which can meet different search scenarios and requirements.
- Rich APIs: Milvus provides multi-language APIs, including Python, Java, Go, Restful, and more; Milvus is easy to integrate and use in various applications.
- Integrate LLMs: Integrations with several LLMs, including OpenAI Plugin, Langchain, and LLamaIndex, allow users to personalize their applications even further.
- Multiple Setup: We designed Milvus to support many use cases, from your local laptop to cloud products such as Milvus-lite, docker containers, distributed deployments, and cloud usage. This makes Milvus easily adaptable to different application sizes, supporting everything from small projects to enterprise-level data retrieval.
Next step for your application
In the realm of AI, constantly new advances and game-changing technologies can elevate your application to the next level. Here, we'll go over two ways to improve your application: implementing GPTCache and tuning embedding models and prompts. This can improve performance and search quality, set your application apart, and provide a better user experience.
Improve your AIGC application performance - GPTCache
If you want to optimize the performance and save costs for your AIGC application, check out GPTCache. This innovative project is designed to create a semantic cache for storing LLM responses.
So, how does this help? By caching responses to LLMs, and vector database can retrieve similar questions to get the cached response, your application can quickly and accurately answer users. With GPTCache, accessing cached answers becomes a breeze—no more redundant response generations, ultimately saving time and computational resources. GPTCache goes a step further by improving the overall user experience. Providing quicker and more accurate answers will satisfy your answer, and your application will be more successful.
Improve your search quality - tune your embedding models and prompts
In addition to utilizing GPTCache, fine-tuning your embedding models and prompts can improve the quality of your search results. Embedding models are a crucial component of AI applications, as they are the building blocks that translate text into numerical vectors, which deep learning can process. By tuning your embedding models, you can improve the accuracy and relevance of your semantic search results. This involves adjusting the models to prioritize specific keywords and phrases and tweaking their weighting and scoring mechanisms better to reflect the needs and preferences of your target audience. With a well-trained embedding model, your AIGC application can accurately interpret and categorize user input, leading to more accurate search results.
Apart from that, the prompts used in the applications play an essential role in improving the quality of search results. Prompts are the phrases that your AI uses to prompt users for input, such as "How can I help you today?" or "What's on your mind?". By testing and modifying these prompts, you can improve the quality and relevance of your search results. For example, if your application is geared towards a specific industry or demographic, you may tailor your prompts to reflect the language and terminology used by that group. This helps guide the users towards more relevant search queries, leading to a more satisfactory experience by matching their needs more accurately. By refining prompts to fulfill user requirements, you can help them achieve more successful searches, thus leading to a more satisfied user base.
In the end
In summary, LangChain and Milvus are the perfect recipes for developers creating LLM-powered applications from scratch. LangChain offers a standard and user-friendly interface for LLMs, while Milvus delivers remarkable storage and retrieval capabilities. LangChain and Milvus can enhance the intelligence and efficiency of ChatGPT, which helps you go beyond the obstacles of hallucinations. Even better, with GPTCache, prompt, and model tuning technologies, we can improve our AI applications in ways never thought possible.
As we continue to push the boundaries of AI, let us collaborate and create a brighter future for AIGC to explore the limitless potential of artificial intelligence.

Keep Reading

Vector Databases vs. Time Series Databases
Use a vector database for similarity search and semantic relationships; use a time series database for tracking value changes over time.

Legal Document Analysis: Harnessing Zilliz Cloud's Semantic Search and RAG for Legal Insights
Enhance legal document analysis with Zilliz Cloud’s Semantic Search and RAG. Improve accuracy, efficiency, and scalability for contracts, case law, and compliance.

DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
Explore DeepSeek-VL2, the open-source MoE vision-language model. Discover its architecture, efficient training pipeline, and top-tier performance.