




Токенизация: Понимание текста путем его разделения на части

Токенизация: Понимание текста путем его разделения на части
TL; DR
Токенизация - это процесс разбиения текста на более мелкие единицы, называемые лексемами, такие как слова, фразы или подслова, чтобы подготовить его для моделей машинного обучения. Например, предложение "Tokenization in Milvus is powerful" может быть разбито на лексемы типа ["Tokenization", "in", "Milvus", "is", "powerful"]. Эти лексемы преобразуются в числовые вкрапления, которые передают их значение для таких задач, как семантический поиск. В векторной базе данных Milvus токенизация интегрирована со встроенными анализаторами, которые эффективно обрабатывают текст для индексирования и поиска. Эта функция упрощает рабочие процессы, позволяя разработчикам напрямую работать с необработанным текстом и создавать продвинутые поисковые приложения с высокой точностью и масштабируемостью. 
Введение
В основе многих систем искусственного интеллекта (AI) и обработки естественного языка (NLP) лежит процесс, который превращает необработанный текст в "структурированные данные" - токенизация. Но что именно представляет собой токенизация и почему для машин так важно разбивать текст на более мелкие фрагменты?
Токенизация - это процесс разбиения текста на более мелкие единицы, позволяющий машинам более эффективно анализировать и понимать язык. Этот важный шаг позволяет компьютерам обрабатывать человеческий язык для решения различных задач НЛП, таких как анализ настроения, перевод языка и генерация текста.
 токенизация
токенизация
Что такое токенизация?
Токенизация разделяет тексты, такие как слова или символы, на более мелкие единицы, называемые токенами. Это один из основополагающих шагов в НЛП, позволяющий машинам более эффективно обрабатывать и понимать человеческий язык.
Зачем нужна токенизация?
Токенизация похожа на изучение нового языка: вы начинаете с разбивки предложений на более мелкие единицы, чтобы понять их смысл и структуру. Точно так же компьютеры делят блок текста на более мелкие, управляемые единицы, чтобы обработать его. Токенизация учит компьютер определять эти фундаментальные компоненты, такие как слова или подслова, что позволяет ему понимать и анализировать текст.
Технически токенизация преобразует неструктурированный текст в структурированный формат, который может обрабатывать компьютер. Например, когда вы вводите предложение в модель NLP, токенизатор разбивает его на лексемы, которым затем присваиваются числовые значения. Эти значения позволяют компьютерам выполнять математические операции, выявлять взаимосвязи и извлекать смысл из данных. Без токенизации текст оставался бы для машины непонятной строкой символов, что делало бы невозможным его дальнейший анализ.
Ключевые понятия в токенизации
Здесь мы рассмотрим ключевые понятия, которые необходимо знать о токенизации.
Токен
Токен - это базовая единица текста, считающаяся значимой для анализа. Токены могут быть символами, словами или подсловами, служащими первичным входом для последующих задач обработки текста.
Tokenizer
Токенайзеры - это фундаментальные инструменты, позволяющие компьютерам разбирать и интерпретировать человеческий язык, разбивая текст на лексемы. Они применяют специальные правила, такие как разбиение на пробелы или использование методов на уровне подслов, чтобы определить степень детализации представления текста.
Анализатор
Анализатор выходит за рамки простой токенизации и обеспечивает глубокую обработку и понимание текста. После токенизации к лексемам применяются фильтры для их дальнейшей обработки, например понижение регистра, стебли, лемматизация или удаление стоп-слов.
Словарный запас
Словарный запас - это набор уникальных лексем (слов, подслов или символов), которые может обрабатывать модель. Он формируется из лексем, полученных в процессе токенизации. Словарь служит моделью для понимания текста. Его дизайн и размер влияют на способность модели работать с языком, особенно с редкими или невиданными словами.
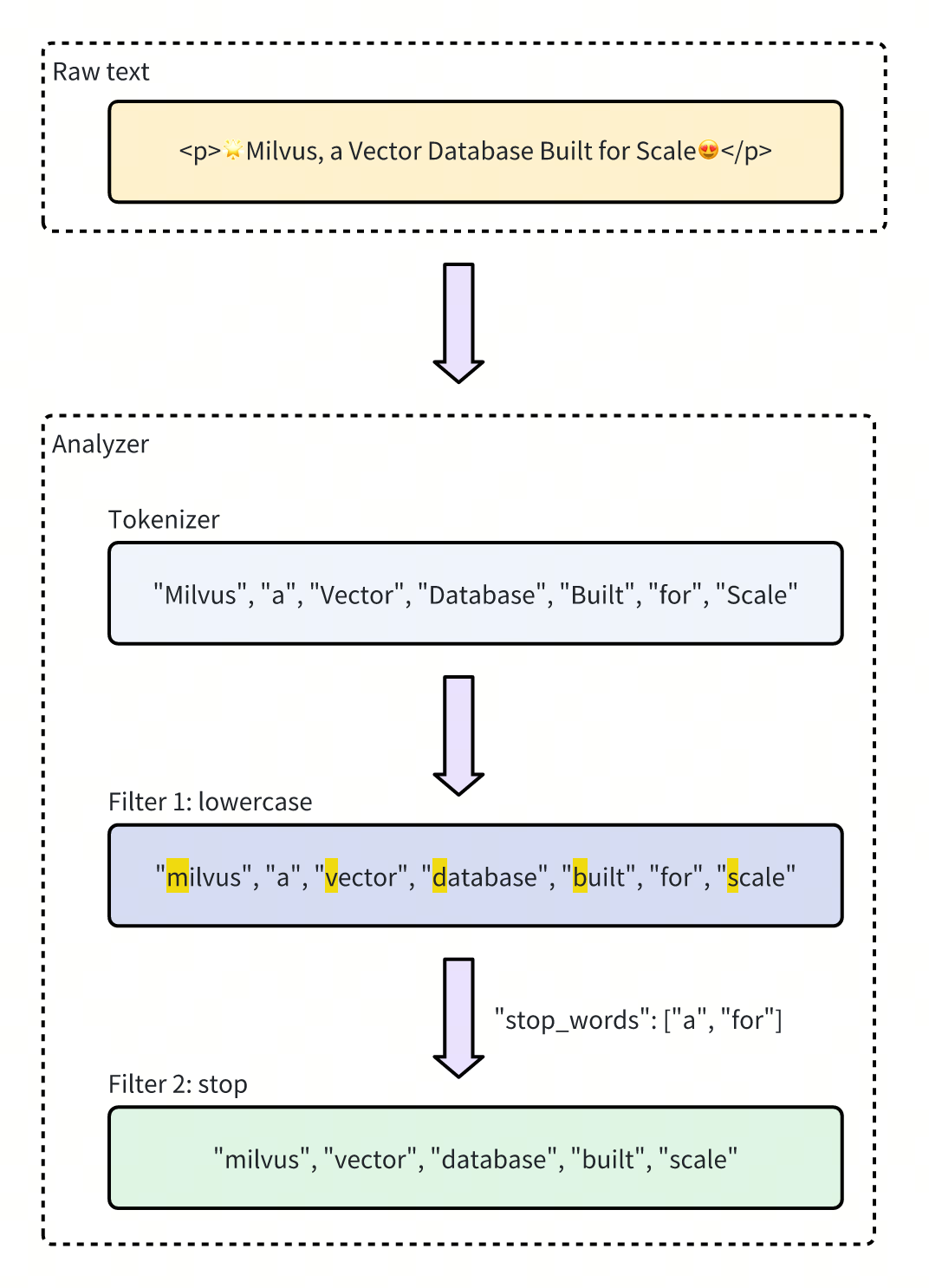 Рисунок - Токенизатор и анализатор в Milvus
Рисунок - Токенизатор и анализатор в Milvus
Рисунок: Токенизатор и анализатор в Milvus
Эта диаграмма иллюстрирует поток обработки текста, в котором исходный текст подвергается токенизации. Затем анализатор применяет фильтры для преобразования лексем в строчные буквы и удаления стоп-слов, в результате чего получается уточненный список значимых лексем.
Типы токенизации
Методы токенизации зависят от степени детализации текста и конкретных требований задачи. Ниже приведены распространенные типы токенизации:
1. Токенизация символов: Она разбивает текст на отдельные символы. Это может быть полезно для языков со сложной морфологией и таких задач, как исправление орфографии или обработка зашумленного текста.
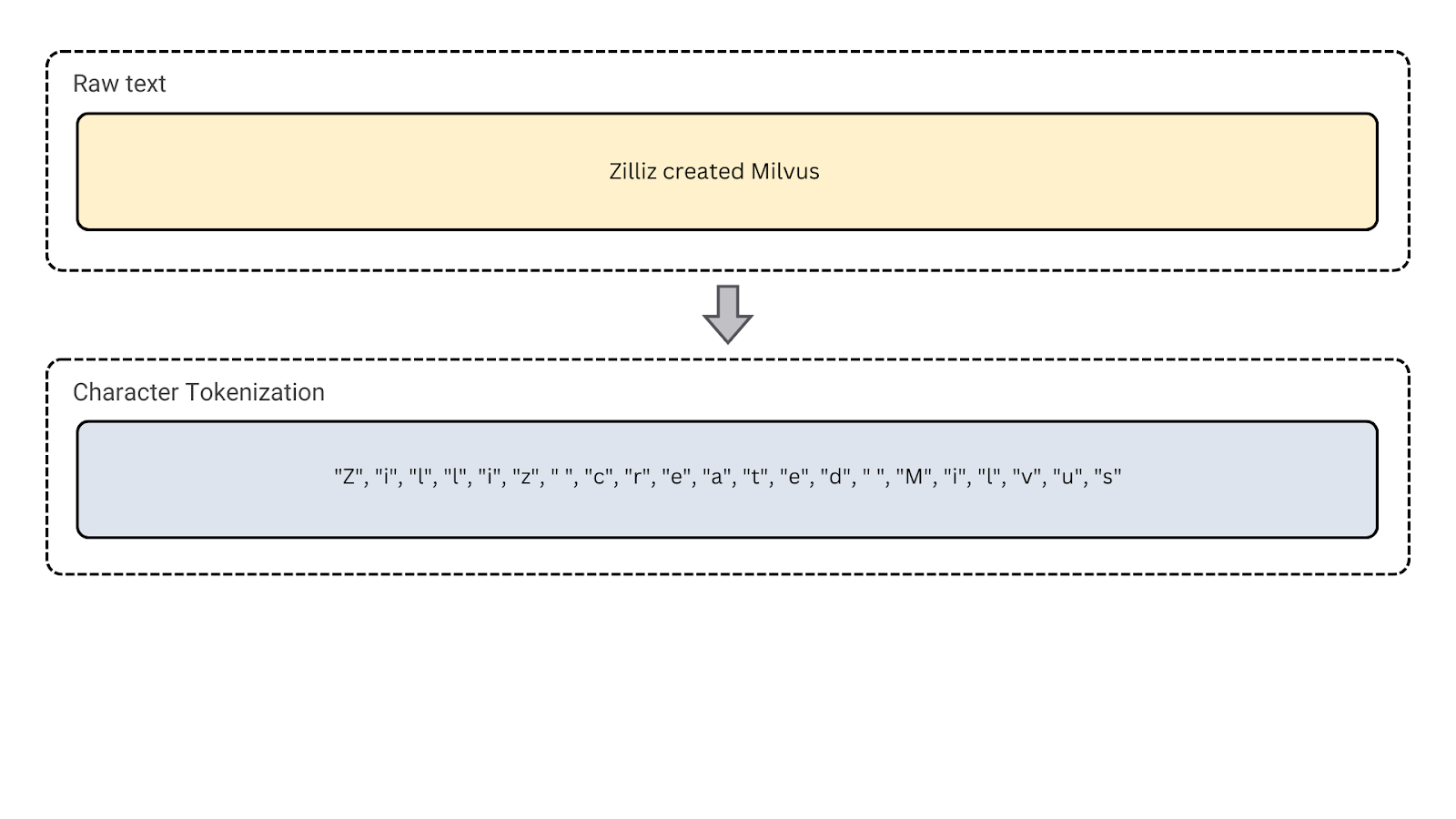 Рисунок - Токенизация символов
Рисунок - Токенизация символов
Рисунок: Токенизация символов
2. Токенизация слов: Это наиболее распространенный тип токенизации, при котором текст разбивается на отдельные слова. Он полезен для языкового моделирования, тегирования частей речи и распознавания именованных сущностей, которые опираются на анализ на уровне слов.
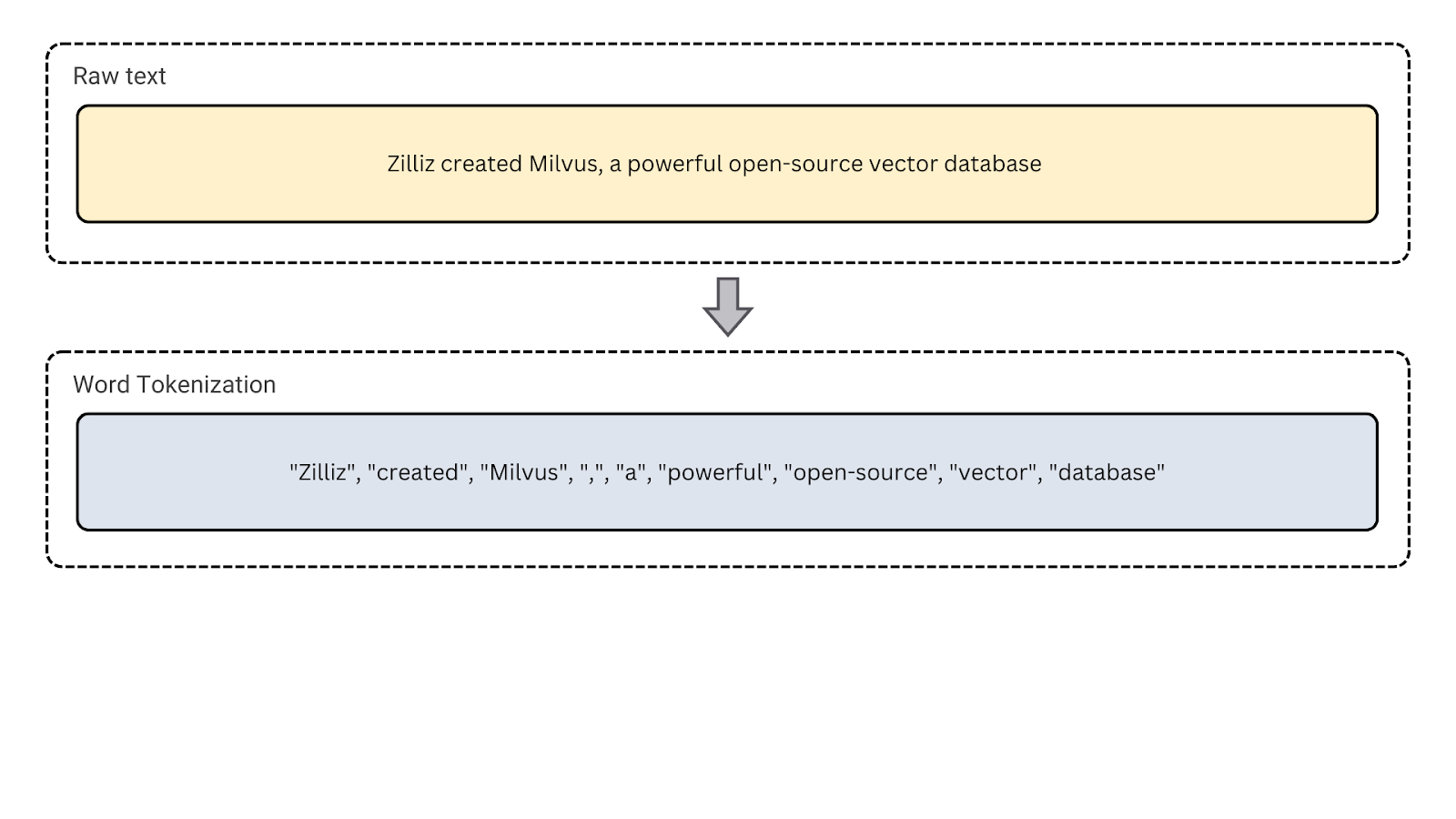 Рисунок - Токенизация слов
Рисунок - Токенизация слов
Рисунок: Токенизация слов.
3. Токенизация предложений: Этот тип сегментирует текст на предложения. Он разделяет абзацы или длинные блоки текста на отдельные предложения. Используйте этот тип для таких задач, как анализ настроения и резюмирование текста, где требуется анализ структуры на уровне предложений.
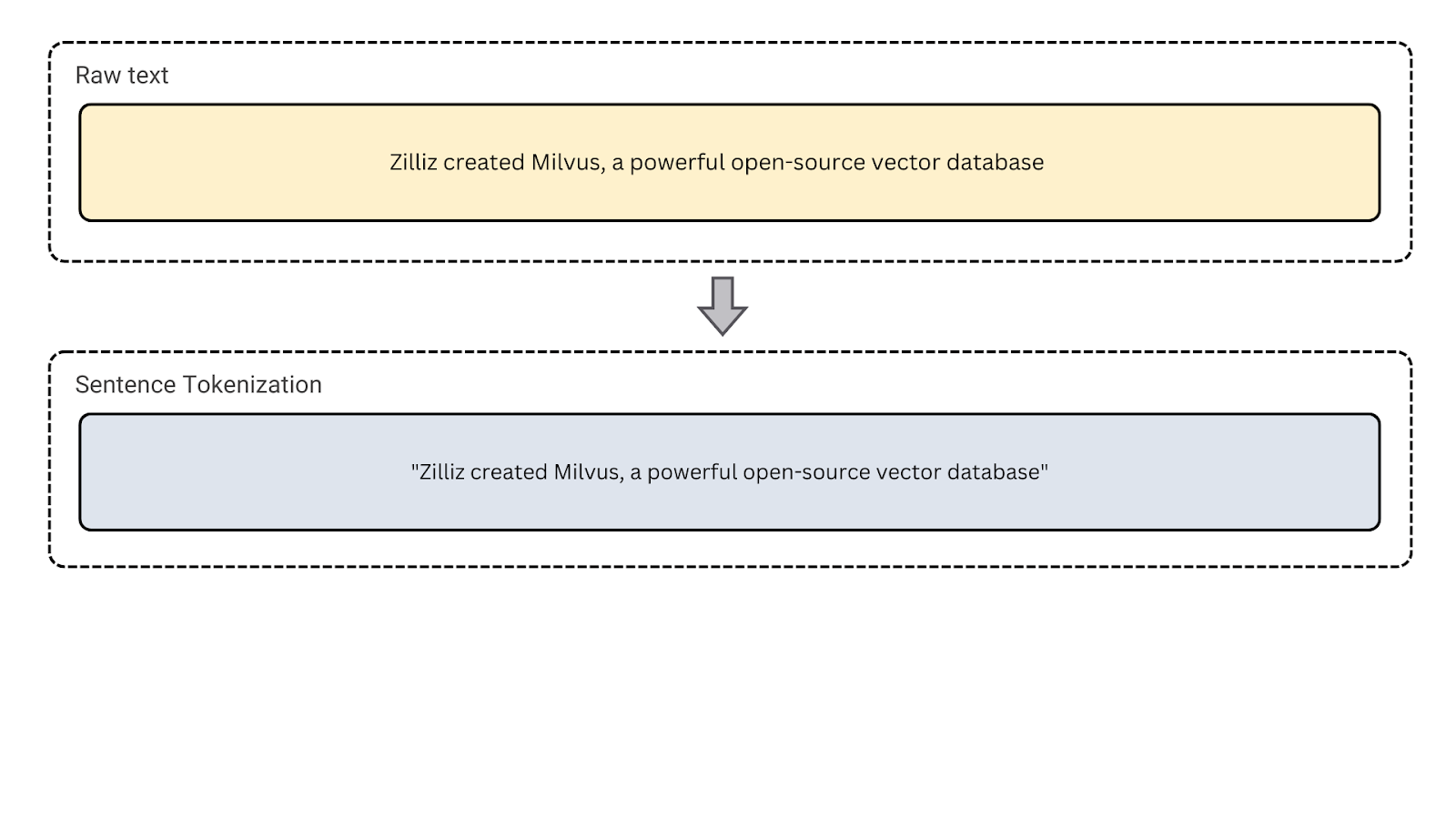 Рисунок - Токенизация предложений
Рисунок - Токенизация предложений
Рисунок: Токенизация предложений.
4. Токенизация подслова: Этот метод разбивает слова на более мелкие, значимые единицы (например, префиксы, суффиксы или стебли). Он помогает уменьшить объем словарного запаса и особенно полезен для таких задач, как генерация текста.
 Рисунок - Токенизация подслова
Рисунок - Токенизация подслова
Рисунок: Токенизация подслова
Токенизация подслова разбивает предложение на лексемы подслова. Редкие слова, такие как "Zilliz" и "Milvus", разбиты на более мелкие единицы. Также слово "open-source" разбивается на ["open", "-", "source"], рассматривая дефис как отдельную лексему.
Пример кода
Здесь приведен пример на языке Python с использованием [BERT-токенизатора] Hugging Face (https://huggingface.co/docs/transformers/v4.47.1/en/model_doc/bert#transformers.BertTokenizer). Он демонстрирует, как предложение токенизируется с использованием токенизации подслова с помощью алгоритма WordPiece:
from transformers import AutoTokenizer
# Загрузите предварительно обученный токенизатор
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
# Токенизировать предложение
предложение = "Зиллиз создал Milvus, мощную векторную базу данных с открытым исходным кодом"
tokens = tokenizer.tokenize(sentence)
print(tokens)
Вывод
['z', '##ill', '##iz', 'created', 'mil', '##vus', ',', 'a', 'powerful', 'open', '-', 'source', 'vector', 'database']
Сравнение между токенизацией и встраиванием слов
Токенизация и встраивание слов - это фундаментальные методы обработки естественного языка (NLP), но они служат разным целям. Токенизация разбивает текст на более мелкие единицы, а вкрапления преобразуют эти единицы в числовую форму.
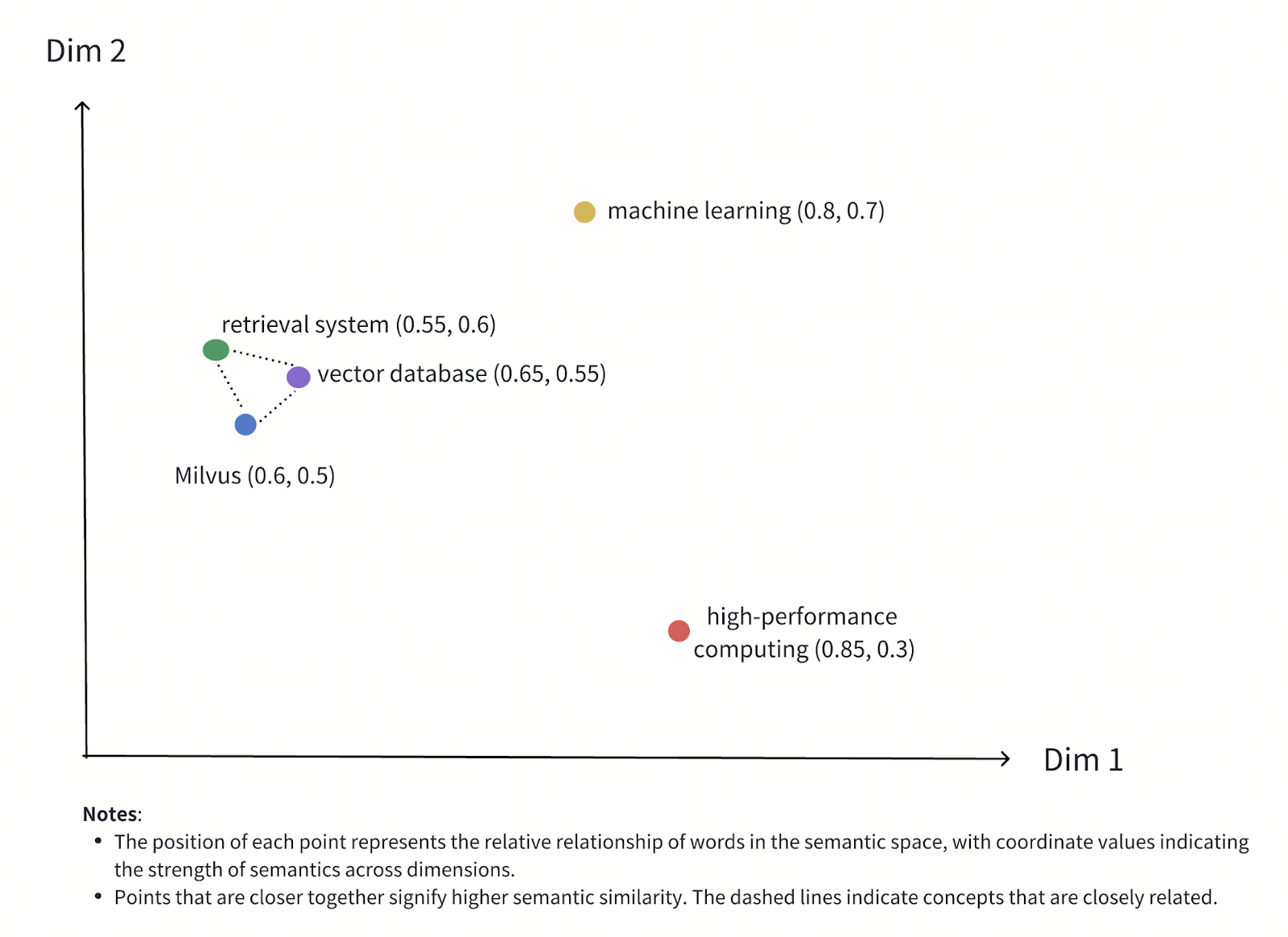 Рисунок - Семантические отношения между словами в векторном пространстве
Рисунок - Семантические отношения между словами в векторном пространстве
Рисунок: Семантические отношения между словами в векторном пространстве
Вот сравнение токенизации и встраивания слов:
| Аспект | Токенизация | Встраивание слов | Встраивание слов. | --------------- | ------------------------------------------------------------------------------- | -------------------------------------------------------------------------------- | | Определение | Процесс разбиения текста на более мелкие единицы (лексемы) | Метод представления лексем в виде плотных векторов в векторном пространстве высокой размерности | | Цель | Разбить текст на единицы, которые можно обрабатывать | Захватить семантический смысл и отношения между словами в векторном представлении | | Примеры | Приговор: "Токенизация имеет решающее значение "Токены: ["Tokenization", "is", "crucial"] | Слово: "Milvus "Вложение: [0.23, 0.56, -0.12, ...] | | Преимущества | Преобразует неструктурированный текст в структурированный формат, который может обрабатывать компьютер | Улавливает семантику слов, отношения и контекст | | Ограничения | Не отражает семантику лексем | Требует больших вычислительных мощностей для генерации вкраплений |
Преимущества и проблемы токенизации
Токенизация имеет решающее значение для обработки текстов. Она дает различные преимущества для языкового моделирования и анализа, но также имеет свои проблемы. Давайте рассмотрим оба аспекта.
Преимущества
Эффективная обработка текста: Токенизация является основой подготовки текстовых данных для задач NLP. Она делает текст более подходящим для моделей машинного обучения.
Управление гранулярностью: Токенизация обеспечивает контроль над уровнем гранулярности, позволяя модели работать со словами, подсловами или даже символами в зависимости от поставленной задачи. Различные задачи имеют разные требования, и конкретная гранулярность может повысить производительность.
Независимость от языка:** Методы токенизации могут адаптироваться к различным языкам и сценариям, чтобы соответствовать различным языкам.
Облегчает моделирование языка: Токенизация имеет решающее значение для моделирования языка. Она определяет основные единицы (лексемы), которые обрабатывает модель, что позволяет лучше понимать и генерировать текст.
Вызовы
** Неоднозначность:** Токенизация сталкивается с проблемами, связанными с неоднозначностью языка. Например, слово "банк" может означать финансовое учреждение или берег реки, в зависимости от контекста. Аналогично, такие фразы, как "средняя школа", могут быть обозначены двумя отдельными словами или одной единицей, что влияет на интерпретацию.
Потеря лексем: Некоторые методы токенизации могут терять информацию, разбивая слова на более мелкие лексемы, что затрудняет понимание моделями полного контекста или смысла исходного текста.
Обработка пунктуации: Сегментирование лексем, включающих знаки препинания, такие как апострофы или тире, иногда может быть сложным для алгоритмов NLP.
Языки без четких границ: Токенизация может быть особенно сложной в языках без четких границ слов, таких как китайский или японский, где пробелы не всегда разделяют слова. Эти языки требуют более сложных методов токенизации для точного разделения текста.
Случаи использования токенизации
Токенизация широко используется в различных задачах НЛП, помогая системам обрабатывать и анализировать текстовые данные. Ниже приведены некоторые из основных случаев использования токенизации:
Поисковые системы: Токенизация позволяет поисковым системам быстро индексировать и извлекать релевантный контент, разбивая термины запроса и документы на токены, обеспечивая точные результаты по запросам пользователей.
Машинный перевод: Токенизация имеет решающее значение для машинного перевода, помогая разбить исходный и целевой языки на лексемы, которые модель может отобразить и эффективно перевести с одного языка на другой.
Распознавание речи:** Токенизация помогает преобразовать устную речь в текст, сегментируя аудиоданные на лексемы для обработки, что позволяет системам понимать устную речь в структурированном виде.
Анализ настроений: Токенизация необходима для анализа настроений, когда она разбивает текст на лексемы для дальнейшей обработки, чтобы определить, является ли выраженное настроение позитивным, негативным или нейтральным.
Чатботы и виртуальные помощники: Токенизация позволяет чатботам и виртуальным помощникам понимать и обрабатывать запросы пользователей, разбивая текст на управляемые единицы. Это позволяет им интеллектуально реагировать на вводимые данные.
Инструменты для токенизации
Для токенизации в НЛП обычно используется несколько инструментов:
NLTK: Это мощная библиотека Python для обработки естественного языка, предоставляющая инструменты для токенизации, стемминга, лемматизации, POS-тегирования и многого другого.
SpaCy: Быстрая библиотека NLP с мощным токенизатором для слов и предложений и настраиваемой токенизацией, что делает ее основным инструментом для промышленных приложений.
Hugging Face Tokenizer: Токенизирует модели на основе трансформаторов, такие как BERT и GPT, с обработкой подслова.
Gensim: Популярный инструмент для тематического моделирования, включает функции предварительной обработки и токенизации текста.
Токенизация в векторной базе данных Milvus
Векторная база данных](https://zilliz.com/learn/what-is-vector-database) предназначена для хранения, индексирования и поиска неструктурированных данных - таких как текст, изображения и видео - с использованием высокоразмерных векторных вкраплений. Эти вкрапления позволяют быстро находить семантическую информацию и осуществлять поиск на основе сходства, что делает векторные базы данных незаменимыми для таких приложений, как рекомендательные системы, поисковые системы и рабочие процессы искусственного интеллекта.
Токенизация - это первый шаг в этом процессе. Она разбивает необработанный текст на более мелкие единицы, такие как слова, фразы или подслова, которые затем преобразуются в числовые представления (векторные вложения) с помощью моделей машинного обучения. Milvus, база данных векторов с открытым исходным кодом, разработанная Zilliz, хранит эти вкрапления в высокоразмерном пространстве, где они могут быть эффективно запрошены на предмет сходства.
Встроенная токенизация в Milvus
Milvus упрощает токенизацию с помощью встроенных анализаторов, которые адаптированы к различным языкам и случаям использования. Эти анализаторы объединяют токенизаторы и фильтры для обработки текстовых данных с целью эффективного индексирования и поиска:
Стандартный анализатор: Анализатор по умолчанию для обработки текстов общего назначения. Он выполняет грамматическую токенизацию, преобразует лексемы в строчные буквы и поддерживает поиск без учета регистра.
Анализатор английского языка: Разработан специально для английского текста. Он включает в себя стемминг (сокращение слов до их корневых форм) и удаление распространенных стоп-слов, фокусируясь на значимых терминах.
Китайский анализатор: Оптимизирован для обработки китайского текста, с токенизацией, разработанной для обработки уникальных языковых структур.
Эти встроенные анализаторы позволяют разработчикам вводить необработанный текст непосредственно в Milvus без необходимости внешней предварительной обработки, оптимизируя рабочие процессы и снижая сложность.
Как Milvus обрабатывает токенизацию
Начиная с Milvus 2.5, база данных включает встроенные полнотекстовый поиск возможности, позволяющие ей обрабатывать необработанный текст внутри. Когда вы вставляете текстовые данные, Milvus использует указанный анализатор для токенизации текста в отдельные термины, пригодные для поиска. Затем эти термины преобразуются в разреженные векторные представления с помощью алгоритмов типа BM25 и сохраняются для эффективного поиска.
Этот гибридный подход позволяет Milvus работать как с плотными векторами (семантическими вкраплениями), так и с разреженными векторами (представлениями на основе ключевых слов). В результате Milvus поддерживает расширенные гибридные сценарии поиска, сочетающие семантическое понимание с точностью до ключевого слова, при этом управление токенизацией и векторизацией осуществляется в рамках базы данных.
Преимущества встроенной токенизации в Milvus
Упрощенный рабочий процесс: Встроенные анализаторы Milvus устраняют необходимость во внешних инструментах токенизации, упрощая прямой ввод необработанных текстовых данных.
Расширенные возможности поиска: Сочетая полнотекстовый поиск с поиском по векторному сходству, Milvus предоставляет высокоточные и релевантные результаты для различных приложений.
Масштабируемость: Внутренняя обработка токенизации и векторизации гарантирует, что Milvus может эффективно обрабатывать большие текстовые данные в различных случаях использования.
Благодаря этим функциям Milvus позволяет разработчикам легче создавать приложения для интеллектуального поиска и анализа, уделяя больше внимания инновациям, а не тонкостям предварительной обработки текста. Независимо от того, работаете ли вы над поиском на естественном языке, рекомендациями на основе искусственного интеллекта или гибридными поисковыми системами, Milvus предоставляет надежную и удобную для разработчиков платформу для работы с вашими приложениями.
Часто задаваемые вопросы о токенизации
**01. Почему токенизация важна в НЛП?
Токенизация преобразует неструктурированный текст в управляемые единицы, позволяя компьютерам обрабатывать язык. Она помогает моделям НЛП присваивать лексемам числовые представления, что позволяет выполнять математические операции и извлекать значимые закономерности.
**02. В чем разница между токенизацией слов и токенизацией символов?
Токенизация слов разбивает текст на отдельные слова, рассматривая каждое слово как отдельный токен. С другой стороны, символьная токенизация разбивает текст на отдельные символы.
**03. Что такое лемматизация и токенизация?
Токенизация разбивает текст на более мелкие единицы, такие как слова или предложения, что облегчает его обработку компьютером. Лемматизация сокращает слова до их базовой формы, например, преобразует "бег" в "бег", обеспечивая последовательность в понимании языка.
04. Как токенизация влияет на производительность модели?
Токенизация влияет на то, как текст разбивается на части и понимается моделью. Правильная токенизация может повысить производительность модели за счет точного определения связей между словами, в то время как плохая токенизация может привести к неправильной интерпретации или потере смысла.
05. Какую роль играет токенизация в анализе настроения или классификации текстов?
При анализе настроения и классификации текстов токенизация разбивает текст на более мелкие единицы, такие как слова или фразы, которые можно анализировать на предмет закономерностей или настроения. Этот процесс позволяет алгоритмам обрабатывать отдельные лексемы и точно классифицировать или определять настроение текста.
Связанные ресурсы
- TL; DR
- Введение
- Что такое токенизация?
- Зачем нужна токенизация?
- Ключевые понятия в токенизации
- Типы токенизации
- Сравнение между токенизацией и встраиванием слов
- Преимущества и проблемы токенизации
- Случаи использования токенизации
- Инструменты для токенизации
- Токенизация в векторной базе данных Milvus
- Часто задаваемые вопросы о токенизации
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно