




Scalable and Reliable: Простое руководство по распределенным вычислениям

Scalable and Reliable: Простое руководство по распределенным вычислениям
Распределенные вычисления - это практика выполнения задач или процессов на нескольких подключенных компьютерах для повышения производительности, масштабируемости и надежности. Вместо того чтобы полагаться на одну мощную машину, рабочая нагрузка распределяется между несколькими узлами, которые могут обрабатывать большие массивы данных и вычисления более эффективно. Такой подход лежит в основе многих современных приложений, основанных на данных, включая платформы электронной коммерции, конвейеры машинного обучения, аналитику в реальном времени, сенсорные сети IoT и высокопроизводительные исследовательские симуляции.
 Распределенные вычисления
Распределенные вычисления
Иллюстрация: Распределенные вычисления
От отдельных серверов к распределенным системам: Эволюция
Долгое время многие организации использовали для работы своих приложений большие централизованные серверы, часто называемые монолитными архитектурами. Однако такая система имела ряд очевидных недостатков:
Ограниченная масштабируемость: Для увеличения мощности требовалось покупать более мощные серверы, что было дорого и отнимало много времени.
Одиночная точка отказа: Вся система останавливалась, если выходил из строя главный сервер.
Сложные обновления: Внесение изменений или обновлений было сопряжено с риском, поскольку все хранилось в одном месте.
Кластеры, объединяющие меньшие серверы, приносили некоторое облегчение, но все равно не решали полностью проблемы масштабирования и надежности. Именно тогда на помощь пришли распределенные вычисления. Распределяя задачи и данные между несколькими соединенными узлами, распределенные системы:
Масштабируются быстрее и доступнее: Вы можете добавлять новые узлы вместо замены одного большого сервера.
Улучшают отказоустойчивость: Если один узел выходит из строя, другие могут поддерживать систему в рабочем состоянии.
Управление тяжелыми рабочими нагрузками: Несколько узлов, работающих вместе, могут более эффективно обрабатывать большие объемы данных.
Современные решения, такие как Milvus от Zilliz, основаны на этих принципах для управления огромными объемами высокоразмерных данных. Milvus поддерживает крупномасштабный поиск по сходству, распределяя данные между несколькими узлами, и сохраняет высокую производительность даже в сложных условиях.
Как работают распределенные вычисления?
Распределенные вычисления - это модель, в которой несколько машин (или узлов) работают вместе для выполнения задач, которые трудно или неэффективно решать на одной машине. Каждый узел в распределенной системе может выполнять определенные функции, такие как хранение данных или обработка вычислений, а система координирует эти задачи, чтобы работать как единое целое. Следовательно, такой подход обеспечивает более высокую производительность, лучшую отказоустойчивость и гибкие возможности масштабирования.
Основные принципы
Распределение задач: Основная идея распределенных вычислений заключается в том, чтобы разбить большие задания на более мелкие и распределить их между различными узлами. Благодаря разделению нагрузки каждый узел может работать над своей частью параллельно, что ускоряет обработку и предотвращает перегрузку одной машины.
Разбиение данных: Данные разбиваются на сегменты (часто называемые "осколками"). Каждый узел хранит один или несколько таких сегментов для параллельного чтения и записи. Это ускоряет доступ к данным и позволяет легко масштабировать систему: при увеличении объема данных вы добавляете больше узлов и разбиваете их еще больше.
Синхронизация и координация: Поскольку задачи и данные распределены, становится критически важно, чтобы узлы синхронизировались, чтобы предотвратить конфликтующие обновления. Распределенные системы используют протоколы и алгоритмы, такие как механизмы консенсуса, для обеспечения того, чтобы каждый узел поддерживал согласованное представление данных. Эти методы помогают всем частям системы согласовывать изменения, даже если они происходят одновременно.
Компоненты распределенных систем
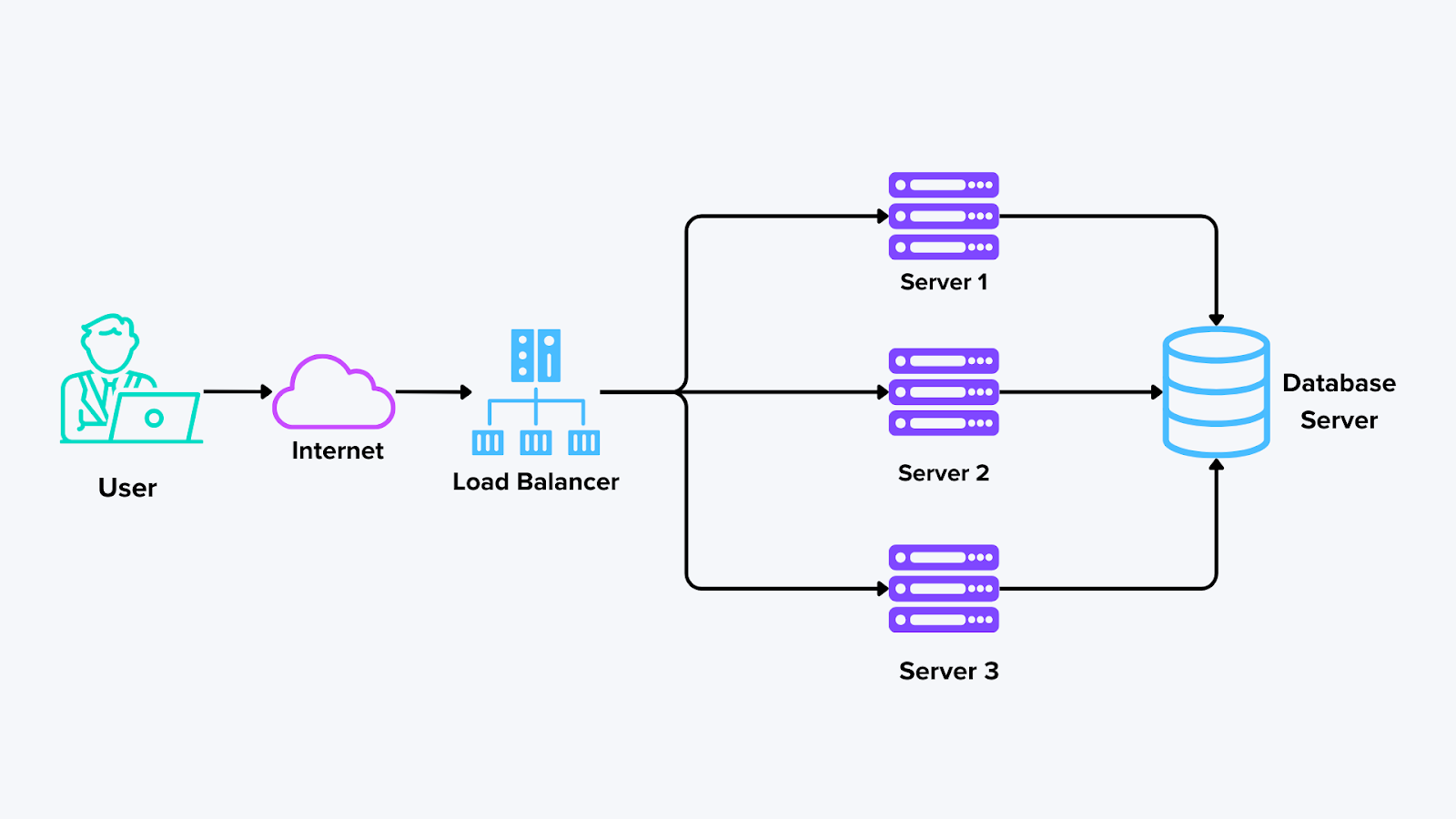 Компоненты распределенной системы
Компоненты распределенной системы
Рисунок: Компоненты распределенной системы
Узлы (или хосты): Каждый узел выполняет задачи или хранит данные. Во многих случаях узлами могут быть физические серверы, виртуальные машины или контейнеры. При использовании такой системы, как Milvus, каждый узел может содержать сегмент векторного индекса, что позволяет осуществлять распределенный поиск в больших массивах данных, не перегружая ни одну отдельную машину.
Сеть: Сеть - это клей, соединяющий все узлы. По ней передаются данные и сообщения между машинами для обмена результатами и обновления друг друга. Надежные и быстрые сетевые соединения необходимы для бесперебойной связи.
Балансировщики нагрузки:Когда несколько узлов готовы принять входящие запросы, балансировщики нагрузки равномерно распределяют трафик. Это предотвращает одновременную обработку узлом слишком большого количества запросов. Распределяя нагрузку, система может справляться со скачками трафика и поддерживать стабильную производительность.
Сервер базы данных: Сервер базы данных отвечает за хранение, управление и поиск структурированных и неструктурированных данных на нескольких узлах. В распределенной архитектуре базы данных могут быть разделены на части (разделение данных на более мелкие фрагменты на разных узлах) или реплицированы (хранение копий данных на разных узлах для обеспечения отказоустойчивости).
Очереди сообщений и координационные службы**: Распределенные системы часто полагаются на инструменты обмена сообщениями (например, Apache Kafka или NATS) или координационные службы (например, ZooKeeper) для управления взаимодействием узлов. Эти инструменты помогают планировать задачи, отслеживать ход их выполнения и следить за тем, чтобы два узла не выполняли одну и ту же работу одновременно. Они также обрабатывают общесистемные объявления, например, когда узел выходит в сеть или отключается, чтобы остальная часть системы могла адаптироваться.
Типы архитектур распределенных вычислений
Распределенные вычисления могут принимать различные формы, в зависимости от того, как узлы взаимодействуют и распределяют обязанности. Ниже приведены некоторые распространенные архитектуры, а также примеры их работы в различных сценариях, включая базу данных Milvus. Выбор правильной распределенной архитектуры зависит от объема рабочей нагрузки, требований к задержкам и ограничений по стоимости.
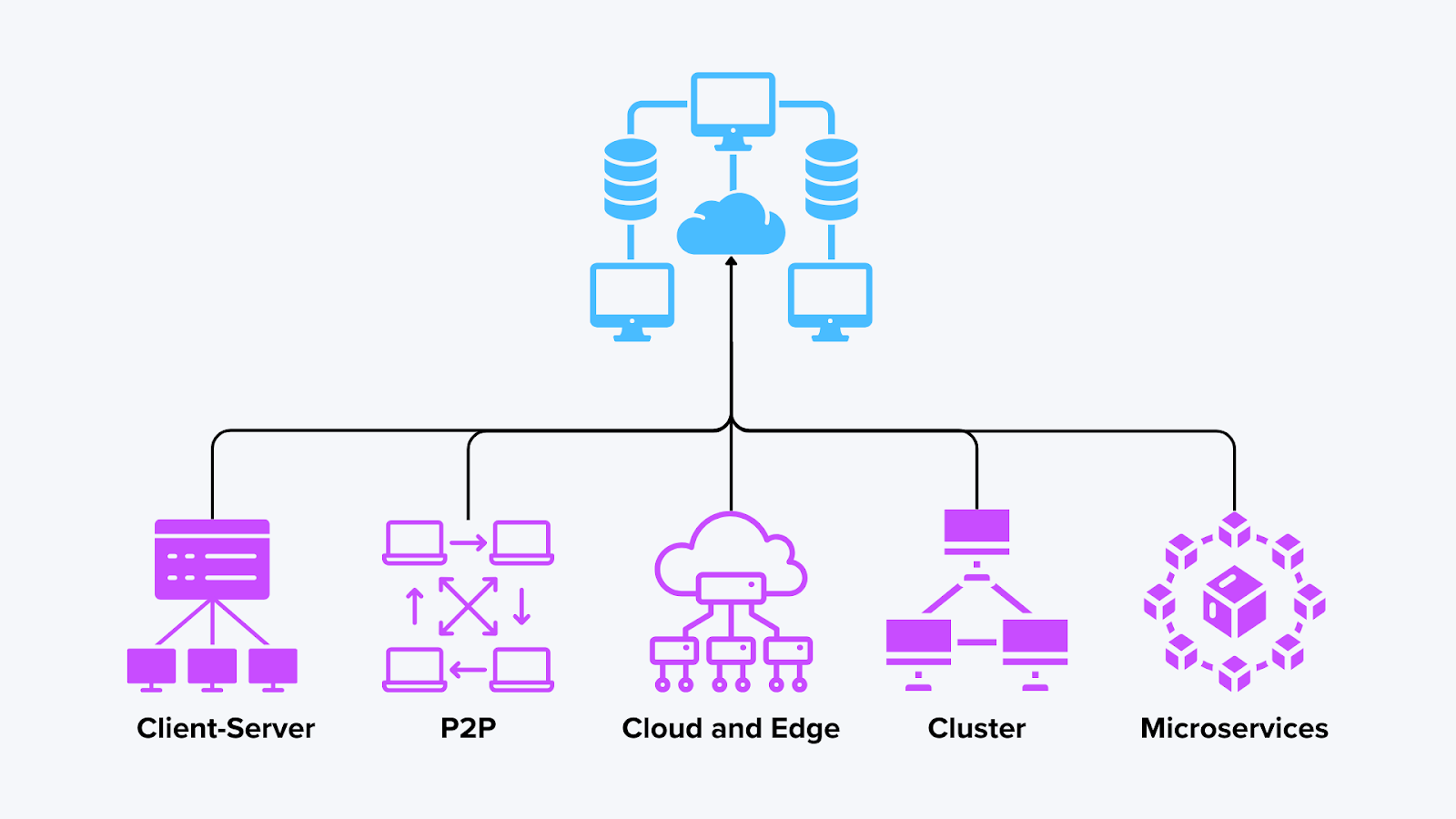 Типы распределенных вычислений
Типы распределенных вычислений
Рисунок: Типы распределенных вычислений
1. Модель клиент-сервер
В модели клиент-сервер один или несколько центральных серверов обрабатывают запросы от множества клиентских устройств. Каждый сервер, как правило, мощнее отдельного клиента и содержит основную бизнес-логику или хранилище данных. Клиенты отправляют запросы (например, на получение данных или выполнение вычислений), а серверы отвечают на них, предоставляя запрашиваемую информацию или результаты.
Плюсы**: Четкое разделение ролей, централизованный контроль и упрощенное управление безопасностью.
Минусы**: Клиенты могут потерять доступ к сервису, если сервер выйдет из строя. Масштабирование также может быть затруднено, если запросы превышают возможности сервера.
2. Одноранговые (P2P) сети.
В одноранговых архитектурах все узлы рассматриваются как равные. Каждый узел может выступать и как клиент, и как сервер, обмениваясь ресурсами или файлами, не полагаясь на центральный сервер. В этой архитектуре узлы подключаются непосредственно друг к другу. Вместо того чтобы запрашивать данные у единого авторитетного сервера, узлы обмениваются данными между собой.
Плюсы**: Нет единой точки отказа, и масштабирование путем добавления новых пиров может быть проще.
Минусы**: Управление согласованностью данных и качеством обслуживания может быть затруднено в полностью децентрализованных средах.
3. Кластерные вычисления
Кластер [https://docs.zilliz.com/docs/cluster] - это группа серверов, работающих настолько тесно, что они воспринимаются как единая система. Задачи могут быть разделены между узлами для параллельной обработки, что делает кластерные вычисления популярными для высокопроизводительных рабочих нагрузок. Серверы в кластере часто используют общее хранилище, а задачи между ними распределяются системой планирования или балансировщиком нагрузки. Если один сервер выходит из строя, остальные могут продолжать работу.
Архитектура Milvus: Milvus использует кластерные узлы для управления большими объемами векторных данных. Распределение векторных индексов по нескольким машинам позволяет эффективно обрабатывать миллиарды высокоразмерных векторов. Такой подход к кластеризации повышает производительность и отказоустойчивость, особенно при работе с массивными поисковыми или рекомендательными нагрузками.
Плюсы**: Отлично подходит для параллельной обработки и отказоустойчивости.
Минусы**: Может быть сложна в управлении и требует больших инвестиций в оборудование.
4. Облачные и граничные вычисления.
Облачные вычисления предоставляют ресурсы по требованию (например, виртуальные машины, хранилища и сервисы) через Интернет. Пограничные вычисления размещают обработку и хранение данных ближе к источнику данных (например, IoT-устройствам), чтобы уменьшить задержки. При облачных вычислениях организации запускают приложения на удаленных серверах, обслуживаемых поставщиками облачных услуг. Мощность обычно масштабируется в короткие сроки. При пограничных вычислениях данные, генерируемые устройствами, обрабатываются локально или в близлежащих пограничных центрах обработки данных, что снижает необходимость отправлять все в центральное облако.
Плюсы**: Эластичное масштабирование, гибкость и потенциально низкие операционные расходы. Пограничные системы также повышают скорость реагирования на задачи, чувствительные ко времени.
Минусы**: Требуется стабильное сетевое соединение (в случае облачных вычислений), а граничные устройства могут иметь ограниченные ресурсы.
5. Микросервисы.
Микросервисы разбивают приложение на более мелкие, слабосвязанные сервисы, которые взаимодействуют по сети. Каждый сервис выполняет определенную функцию, например аутентификацию пользователя или индексирование данных. Сервисы могут работать на отдельных машинах или в контейнерах. Они предоставляют API-интерфейсы для взаимодействия и могут масштабироваться независимо друг от друга в соответствии с конкретной рабочей нагрузкой.
Плюсы**: Это упрощает обновление, поскольку каждый сервис можно изменить, не затрагивая всю систему. Кроме того, это позволяет осуществлять специализированное масштабирование, когда только наиболее интенсивно используемые сервисы получают дополнительные узлы.
Минусы**: усложняется управление множеством сервисов при обеспечении бесперебойной работы. Мониторинг, ведение журналов и развертывание обновлений требуют тщательного планирования.
Примеры использования распределенных вычислений
Распределенные вычисления имеют широкий спектр современных решений. Ниже приведены некоторые из наиболее распространенных сценариев, в которых организации выигрывают от разделения рабочих нагрузок и данных между взаимосвязанными узлами:
Аналитика больших данных и обработка в реальном времени: Организации запускают большие наборы данных параллельно на нескольких узлах, чтобы ускорить анализ. Данные продолжают поступать, и обновления происходят практически мгновенно. Это очень важно для финансового сектора, здравоохранения и электронной коммерции, где решения принимаются быстро.
Машинное обучение и обучение моделей ИИ: Обучение сложных моделей происходит быстрее, когда вычисления выполняются на многих машинах одновременно. Такая схема позволяет эффективно обрабатывать большие наборы функций и сокращать общее время обучения. Это часто встречается в распознавании образов, НЛП и персонализированных рекомендациях.
Веб-приложения с высоким трафиком и электронная коммерция: Запросы распределяются между несколькими серверами, поэтому ни одна машина не перегружается. Если один сервер выходит из строя, остальные продолжают работать, чтобы избежать серьезных простоев. Благодаря гибкому масштабированию можно легко справиться с внезапными всплесками, например, праздничными распродажами.
Интернет вещей (IoT) и сенсорные сети: Многочисленные датчики передают данные на распределенные узлы, которые обрабатывают их в непосредственной близости от источника для более быстрого реагирования. Такой локализованный подход улучшает мониторинг и помогает получать оповещения в режиме реального времени. Он широко применяется в "умных" городах, на производстве и в подключенных автомобилях.
Научные исследования и высокопроизводительные вычисления (HPC): Тяжелые задачи, такие как моделирование климата, разбиваются на более мелкие задания, которые выполняются параллельно. Это значительно сокращает время вычислений и поддерживает глобальное научное сотрудничество. Исследователи могут быстрее совершенствовать модели и продвигать инновации.
Сети доставки контента (CDN): Хранят файлы и мультимедиа на серверах по всему миру, позволяя пользователям получать доступ к контенту с ближайшего узла. Такая система сокращает время загрузки и сетевые задержки, что делает ее жизненно важной для потоковых сервисов, загрузки больших файлов и веб-сайтов с высокой посещаемостью.
Преимущества распределенных систем
Организации обращаются к распределенным системам, чтобы справиться с постоянно растущим объемом данных и вычислительных задач. Ниже перечислены основные преимущества, которые помогают командам масштабироваться, сохранять устойчивость и работать более эффективно:
Масштабируемость и совместное использование ресурсов: Распределенные архитектуры позволяют организациям добавлять больше машин по мере роста рабочих нагрузок, а не полагаться на один большой сервер. Система позволяет избежать узких мест и повысить пропускную способность за счет разделения данных и задач между несколькими узлами.
Отказоустойчивость и избыточность:** Когда критически важные данные и задачи реплицируются на нескольких узлах, система может продолжать работать даже при отказе одного узла. Такая конструкция сокращает время простоя и сохраняет доступ пользователей.
Гибкая и модульная конструкция:** Распределенные системы часто разделяют задачи на более мелкие, независимые модули. Каждый узел выполняет определенные функции, что позволяет обновлять или заменять компоненты, не нарушая работу всей среды.
Баланс между согласованностью и доступностью (CAP Theorem): Распределенным системам сложно быть полностью согласованными и всегда доступными одновременно, особенно при возникновении сетевых проблем. Точный компромисс зависит от того, насколько критична немедленная согласованность для каждого случая использования.
Повышенная производительность и пропускная способность: Благодаря параллельному выполнению задач распределенные системы могут выполнять больше операций за меньшее время. Это очень важно для анализа больших данных или векторного поиска в реальном времени.
Проблемы и соображения
Хотя распределенные системы имеют множество преимуществ, они также создают уникальные сложности. Ниже приведены некоторые общие препятствия и факторы, о которых следует помнить при создании и обслуживании распределенных инфраструктур:
** Задержки в сети и ограничения пропускной способности:** Задачи, выполняемые на удаленных серверах, могут замедлиться, если сетевые соединения слабы или перегружены. Если пропускная способность ограничена, передача больших объемов данных может столкнуться с узкими местами. Размещение узлов ближе к пользователям или кэширование данных может помочь уменьшить задержку.
Согласованность данных и устойчивость к разделам: Поддерживать синхронизацию данных на нескольких узлах может быть непросто. Сбои в сети или перебои в работе узлов приводят к конфликтам, требующим тщательной обработки. Некоторые системы предпочитают быстрые обновления, в то время как для других приоритетом является строгая точность.
Безопасность и конфиденциальность данных: Данные перемещаются между машинами, что повышает риск утечки или несанкционированного доступа. Шифрование и строгий контроль доступа помогают защитить конфиденциальную информацию. Регулярные аудиты и проверки на соответствие нормативным требованиям обеспечивают защиту данных пользователей.
Управление распределенными транзакциями: В одной транзакции может участвовать несколько сервисов или узлов, что усложняет координацию. Такие протоколы, как двухфазная фиксация или менеджеры транзакций, отслеживают эти шаги. Тщательно продуманные стратегии отката предотвращают повреждение данных при частичных сбоях.
Представляем Milvus: распределенную, облачную векторную базу данных
Milvus разработана с нуля как облачно-нативная, распределенная система для управления высокоразмерными векторными данными. Разделяя данные и обработку на нескольких узлах, Milvus обеспечивает основные преимущества распределенных вычислений - масштабируемость, отказоустойчивость и параллельное выполнение, что делает ее хорошо подходящей для обучения моделей ИИ, рекомендательных систем в реальном времени и сложной аналитики.
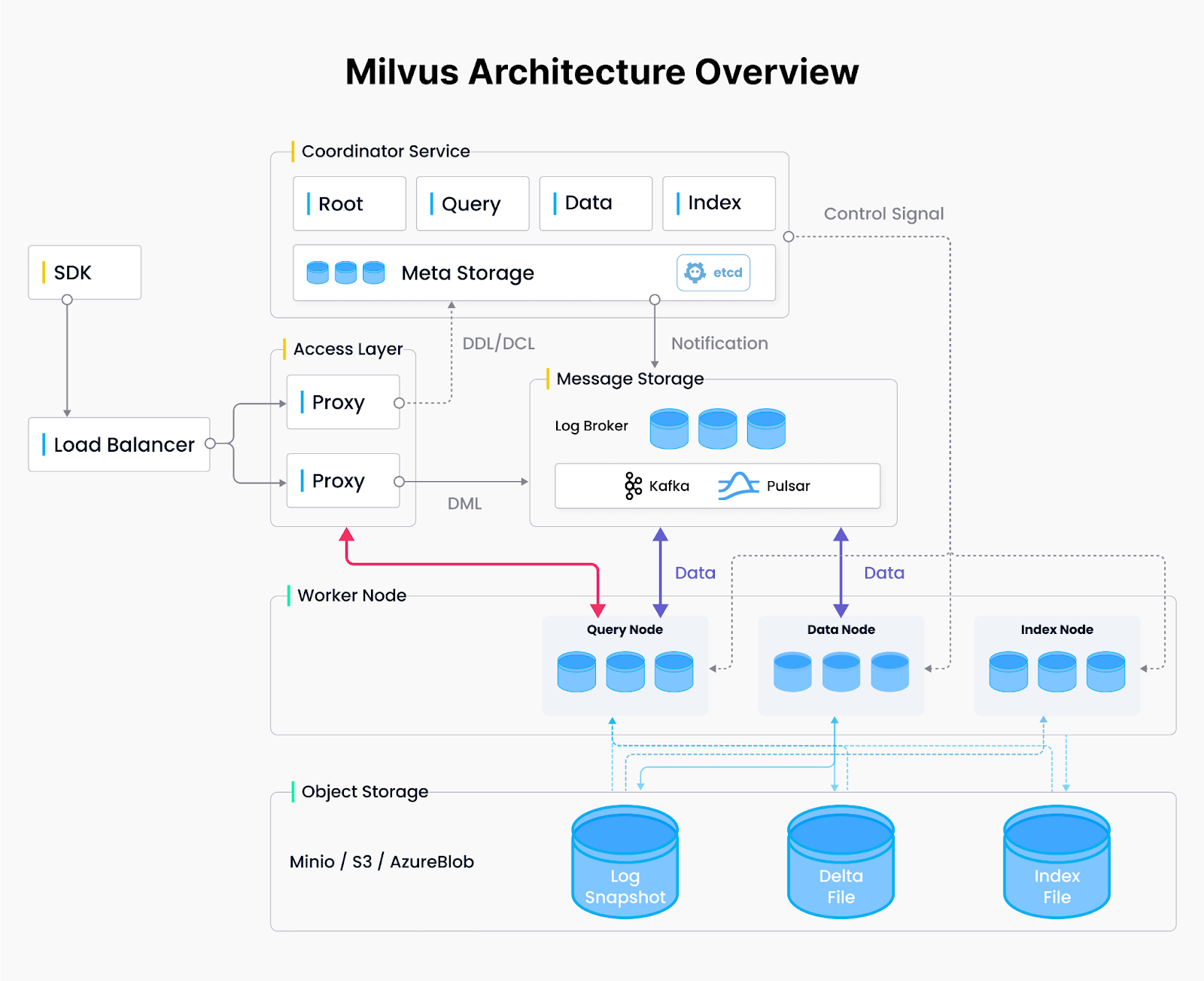 Архитектура Milvus.png
Архитектура Milvus.png
Иллюстрация: Архитектура Milvus
Распределенная архитектура Milvus: Четырехслойная конструкция
Milvus - это широко используемая векторная база данных, которая использует архитектуру распределенной системы, состоящую из четырех уровней, чтобы динамически распределять ресурсы там, где они наиболее необходимы - будь то вычислительная мощность для крупномасштабного индексирования или дополнительная память для параллельной обработки сложных запросов.
Уровень доступа:** Нестационарные узлы доступа обрабатывают входящие запросы, выступая в качестве точки входа в систему.
Координационный уровень:** Координирует назначение узлов и управление ресурсами, по мере необходимости поднимая или опуская рабочих.
Рабочий уровень:** Выполняет основные задачи по обработке запросов, вводу данных и созданию индексов на масштабируемых узлах без статических устройств.
Уровень хранения:** Хранит векторные данные и системные метаданные для обеспечения отказоустойчивости и постоянства узлов.
Масштабируемость и согласованность в распределенной архитектуре Milvus
В Milvus применяются принципы распределенных вычислений для обработки массивных векторных наборов данных с сохранением их согласованности. Ниже перечислены ключевые особенности конструкции, которые помогают ей горизонтально масштабироваться, минимизировать узкие места и предлагать настраиваемые уровни согласованности:
Горизонтальное масштабирование: Milvus разделяет большие наборы данных на управляемые фрагменты. Каждый сегмент индексируется независимо, поэтому по мере роста данных вы можете добавлять новые узлы без перестройки существующей инфраструктуры.
Независимые узлы для запросов, данных и индексов: Для масштабирования специфических функций запросы, прием данных и индексирование выполняются независимо на узлах разных типов. Такое разделение помогает избежать узких мест и гарантирует, что система сможет обрабатывать миллиарды векторов.
Настраиваемая согласованность и** Sharding: Данные распределяются по нескольким узлам для одновременной записи, а настраиваемые уровни согласованности Milvus позволяют сбалансировать производительность и точность в зависимости от потребностей приложения.
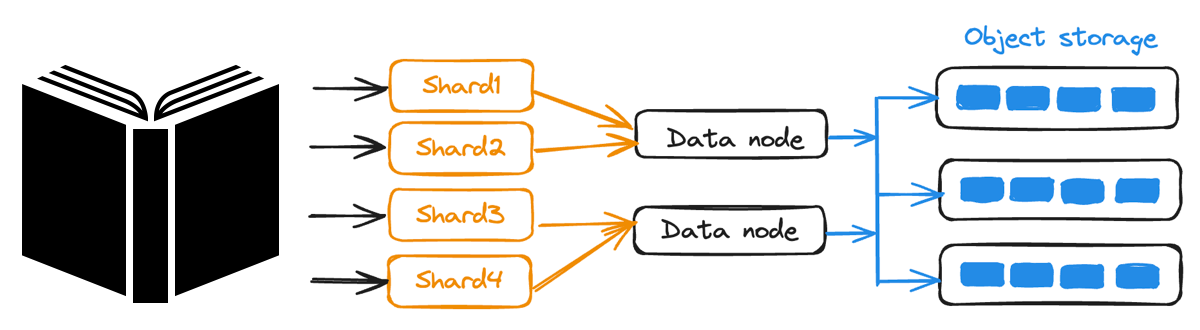 Шардинг данных в Milvus
Шардинг данных в Milvus
Рисунок: Разделение данных в Milvus
Несколько режимов развертывания для различных нужд
Milvus предлагает несколько вариантов развертывания для различных масштабов данных и требований к производительности. Будь то тестирование на одной машине или запуск крупномасштабной производственной системы, эти режимы позволяют подобрать ресурсы и сложность в соответствии с потребностями проекта. Ниже показан уровень масштабирования данных для каждой векторной базы данных. Видно, что распределенная база Milvus предназначена для работы с данными масштабом в десятки миллионов и более.
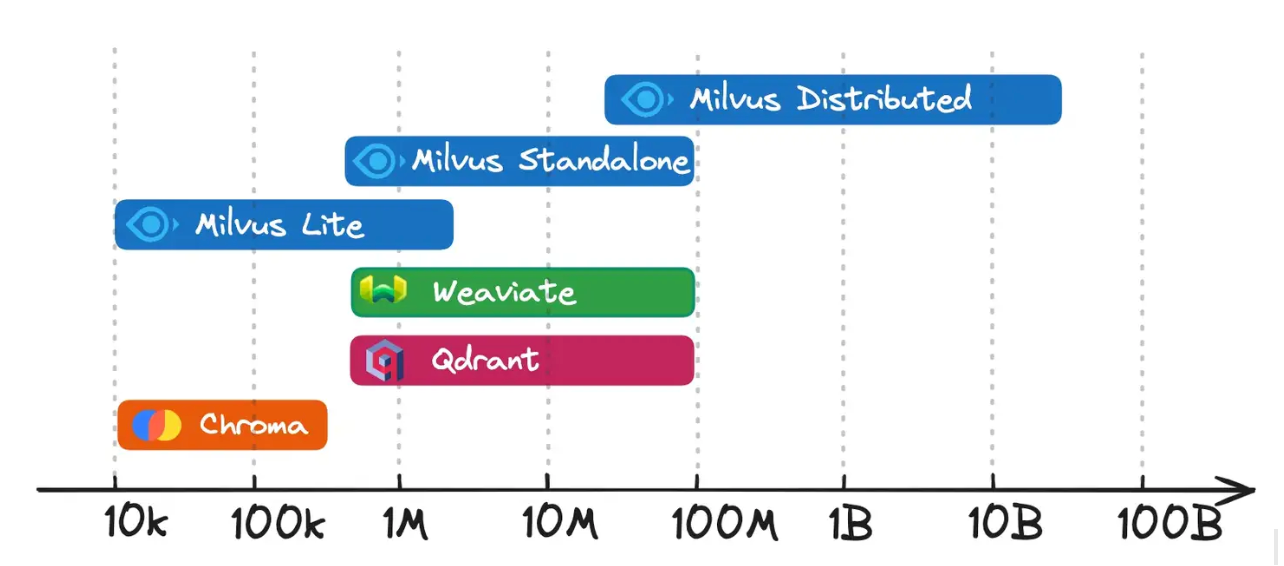 Режимы развертывания Milvus
Режимы развертывания Milvus
Рисунок: Режимы развертывания Milvus
Milvus Lite: Легкая библиотека Python, которая предоставляет основные функциональные возможности Milvus, не требуя отдельного серверного процесса. Она идеально подходит для небольших экспериментов, быстрого создания прототипов или быстрых демонстраций в локальном окружении. Milvus Lite позволяет быстро начать работу с минимальными настройками, если вы создаете пробный вариант концепции или тестируете новые функции в ноутбуке.
Milvus Distributed: Полностью многоузловая архитектура, рассчитанная на корпоративные требования. Разделяя задачи между узлами доступа, координаторами, рабочими узлами и уровнями хранения, она обрабатывает миллиарды (или даже десятки миллиардов) векторов с высокой доступностью и отказоустойчивостью. Эта модель - оптимальный выбор для организаций, которые ожидают быстрого роста объема данных, нуждаются в высокой производительности при одновременном выполнении запросов и хотят иметь возможность добавлять или удалять узлы в зависимости от рабочей нагрузки.
Milvus Standalone: развертывание на одном узле, объединяющее все компоненты Milvus в единую среду, часто распространяемую через образ Docker. Это упрощает установку и обслуживание, обеспечивая достаточную емкость для работы с умеренными объемами данных. Команды, которым нужны производственные рабочие нагрузки, не требующие огромной масштабируемости или сложных механизмов обхода отказа, найдут этот вариант экономически эффективным и надежным.
Чтобы узнать больше о развертывании Milvus, прочитайте наше руководство: [Как выбрать правильный режим развертывания Milvus для ваших приложений искусственного интеллекта] (https://zilliz.com/blog/choose-the-right-milvus-deployment-mode-ai-applications).
Заключение
Распределенные вычисления изменили методы работы организаций с данными и масштабирования приложений, перейдя от монолитных серверов к гибким, отказоустойчивым кластерам взаимосвязанных узлов. Разделяя задачи и данные между несколькими машинами, команды добиваются ускорения обработки, повышения доступности и более эффективного использования ресурсов. Современные решения, такие как Zilliz, используют эти принципы для создания облачной векторной базы данных, способной параллельно обрабатывать миллиарды векторов. Поскольку объемы данных продолжают расти, а сценарии использования становятся все более сложными, применение распределенного подхода - будь то аналитика, машинное обучение или рекомендации в режиме реального времени - остается ключевой стратегией для сохранения конкурентоспособности в современном мире, основанном на данных.
Часто задаваемые вопросы о распределенных вычислениях
Почему стоит выбрать распределенную систему, а не один мощный сервер? Распределенная система позволяет добавлять новые машины по мере роста рабочих нагрузок, а не обновлять один сервер. Такая гибкость повышает производительность, снижает затраты и уменьшает влияние любой единой точки отказа.
Распределенные системы используют протоколы и алгоритмы (например, механизмы консенсуса) для синхронизации данных на нескольких узлах. Точный подход зависит от конкретной системы, но цель состоит в том, чтобы обновления не конфликтовали и каждый узел имел правильное представление данных.
Хотя в распределенных системах появляется больше движущихся частей, таких как сетевая связь, координация узлов и репликация, правильные инструменты и лучшие практики могут уменьшить сложность. Такие инструменты, как Kubernetes, и платформы мониторинга упрощают оркестровку и наблюдение.
Milvus - это облачная распределенная векторная база данных, предназначенная для крупномасштабного поиска по сходству. Благодаря разделению данных на сегменты и параллельному индексированию Milvus может обрабатывать миллиарды векторов на нескольких узлах без ущерба для скорости и надежности.
Распределенные системы идеально подходят для работы с внезапными изменениями спроса. Вы можете быстро подключить дополнительные узлы или ресурсы, предотвращая перегрузку любой машины и поддерживая стабильную производительность даже в периоды пиковой нагрузки.
Связанные ресурсы
- От отдельных серверов к распределенным системам: Эволюция
- Как работают распределенные вычисления?
- Типы архитектур распределенных вычислений
- Примеры использования распределенных вычислений
- Преимущества распределенных систем
- Проблемы и соображения
- Представляем Milvus: распределенную, облачную векторную базу данных
- Заключение
- Часто задаваемые вопросы о распределенных вычислениях
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно