




Dimensionality Reduction: Упрощение сложных данных для удобства анализа
TL;DR: Снижение размерности - это процесс, используемый в науке о данных и машинном обучении для уменьшения количества переменных, или "измерений", в наборе данных при сохранении максимально возможного количества релевантной информации. Такое сокращение упрощает анализ, визуализацию и обработку данных, особенно в высокоразмерных наборах данных. Такие методы, как анализ главных компонент (PCA) и t-Distributed Stochastic Neighbor Embedding (t-SNE), позволяют выявить закономерности и взаимосвязи внутри данных, проецируя их на меньшее количество измерений. Отбрасывая менее значимые признаки, уменьшение размерности помогает повысить эффективность вычислений и предотвратить чрезмерную подгонку, что делает его важным для управления сложными данными, особенно в таких областях, как анализ изображений и текстов.
Dimensionality Reduction: Упрощение сложных данных для удобства анализа
Уменьшение размерности упрощает набор данных, сокращая количество входных переменных или признаков, сохраняя при этом важную информацию. Оно играет важную роль в науке о данных и машинном обучении. Оно делает работу с большими наборами данных более управляемой, повышает производительность моделей и экономит ценные вычислительные ресурсы.
Представьте себе большую, сложную электронную таблицу, заполненную множеством столбцов с данными. Если некоторые из этих столбцов бесполезны или нуждаются в уточнении для анализа, уменьшение размерности обрезает их для облегчения распознавания образов.
Проклятие размерности
Проклятие размерности" (https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning) относится к проблемам, возникающим при анализе и организации данных в высокоразмерных пространствах. При увеличении числа признаков (или размерностей) объем пространства расширяется настолько быстро, что доступные данные становятся разреженными. Эта разреженность затрудняет алгоритмам поиск значимых закономерностей, делая анализ данных неэффективным и ненадежным.
Чтобы понять последствия, представьте, что вы пытаетесь измерить расстояние между точками в одномерном пространстве, например прямой линией. Точки находятся достаточно близко, чтобы их можно было легко измерить. Если расширить это пространство до двух измерений, например до плоского листа бумаги, точки раздвинутся еще дальше. При увеличении до трех измерений, например до комнаты, они становятся еще более разнесенными. По мере увеличения размерности точки становятся настолько далекими друг от друга, что кажутся почти изолированными, и вычисление расстояния становится менее полезным. Это происходит в высокоразмерных данных, где обычные методы анализа данных могут работать неэффективно, поскольку связи между точками данных становятся размытыми, как показано на рисунке.
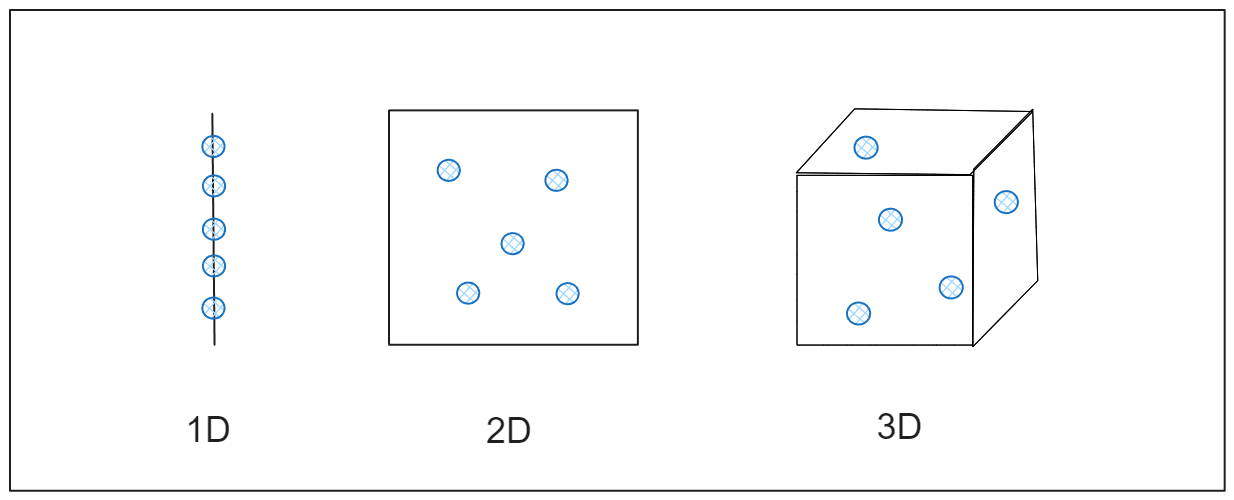 Рисунок - Как данные расширяются по измерениям.png
Рисунок - Как данные расширяются по измерениям.png
Иллюстрация: Как данные расширяются по измерениям
Простая аналогия - поиск друзей в парке. Вы можете быстро найти друг друга, если вы и ваши друзья разбросаны по небольшому парку. Но представьте, что парк разросся до размеров огромного города. Теперь, даже при том же количестве друзей, найти одного из них становится проблематично, потому что все находятся слишком далеко друг от друга. Аналогично, в высокоразмерных пространствах точки данных становятся разрозненными, что затрудняет алгоритмам их эффективную организацию и анализ.
Основные методы снижения размерности
Хотя существуют различные стратегии сокращения размерности, в целом их можно разделить на два основных типа: Выбор признаков и извлечение признаков. Оба метода направлены на упрощение данных, но разными способами.
Выбор признаков
Отбор признаков уменьшает размерность путем выбора подмножества наиболее значимых признаков из исходного набора данных. Вместо того чтобы преобразовывать данные, этот подход сохраняет признаки в том виде, в котором они есть, но отбрасывает те, которые не вносят существенного вклада в анализ или работу модели. Цель - удалить избыточные или нерелевантные признаки, чтобы сделать набор данных более простым и удобным для работы.
Существует три распространенных метода, используемых для отбора признаков:
Методы фильтров: В них используются статистические тесты для ранжирования признаков по степени их важности. Примерами могут служить оценки корреляции, информационный выигрыш и тесты хи-квадрат. Они просты и работают независимо от модели машинного обучения.
Оболочечные методы: Они оценивают различные подмножества признаков и используют производительность модели для определения наилучшей комбинации. Хотя они более точны, их использование требует больших вычислительных затрат. К этой категории относятся такие методы, как рекурсивное исключение признаков (RFE), прямой отбор и обратное исключение.
Встроенные методы: Эти методы интегрируют отбор признаков в процесс обучения модели. Такие модели, как деревья решений, регрессия Лассо и гребневая регрессия, автоматически определяют важные признаки в процессе обучения.
Извлечение признаков
Извлечение признаков преобразует исходные признаки в более низкоразмерное пространство, создавая новые признаки, которые по-прежнему отражают важную информацию. Такой подход полезен при сжатии данных с сохранением значимых связей между признаками. В отличие от выбора признаков, извлечение признаков создает совершенно новые представления данных.
Наиболее распространенными методами являются анализ главных компонент (PCA), t-распределенное стохастическое встраивание соседей (t-SNE) и линейный дискриминантный анализ (LDA). Давайте обсудим их подробнее.
Анализ главных компонент (PCA)
Анализ главных компонент (PCA) - это популярная техника, используемая для снижения размерности. Его основная цель - упростить большой набор переменных до меньшего набора, который все еще захватывает большую часть информации в исходных данных.
Чтобы понять суть PCA, представьте себе набор данных как многомерный объект, подобный облаку точек в пространстве. PCA находит направления (или оси), по которым данные изменяются сильнее всего, и проецирует их на эти новые оси. Первая ось, называемая главным компонентом, отражает наибольшую дисперсию (или разброс) в данных. Вторая ось фиксирует следующую по величине дисперсию и так далее. Сосредоточившись только на нескольких первых компонентах, PCA сокращает количество измерений, сохраняя при этом основную структуру данных.
На следующих диаграммах показано, как PCA работает для упрощения данных. Слева показана диаграмма рассеяния точек, разбросанных в двух направлениях. PCA находит основное направление, в котором данные изменяются сильнее всего, что показано черной стрелкой. Справа показано, как данные сглаживаются по этому направлению.
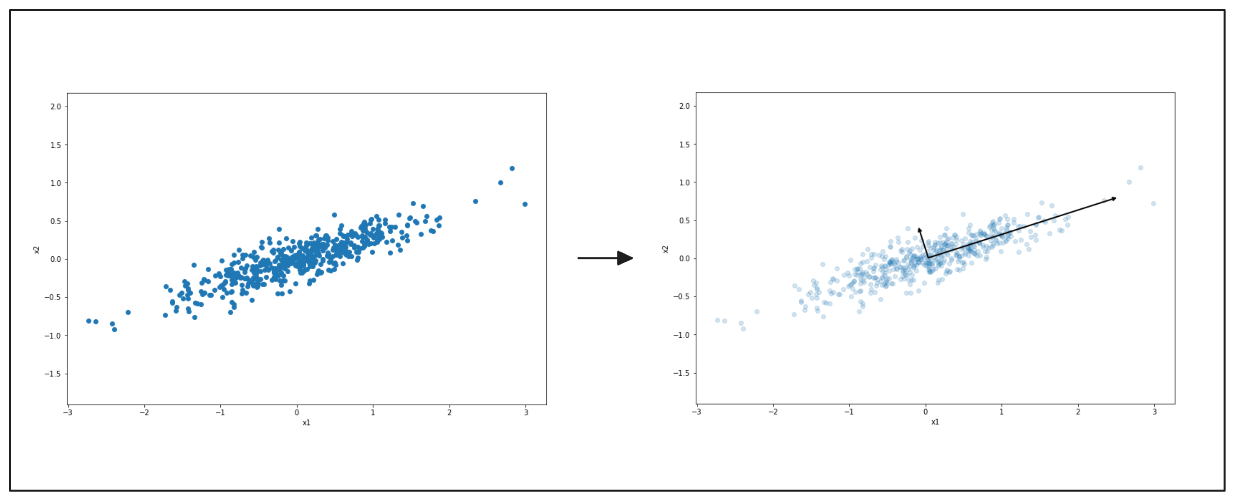 Рисунок - PCA, выделяющий основное направление вариации данных..png
Рисунок - PCA, выделяющий основное направление вариации данных..png
Рисунок: PCA выделяет основное направление вариации данных.
Опять же, слева вы видите данные, разбросанные в двух измерениях. Черная стрелка указывает на основное направление вариации. Справа данные сжимаются до этой линии, уменьшая их до более простой формы. Этот процесс облегчает работу с данными, но сохраняет основные закономерности.
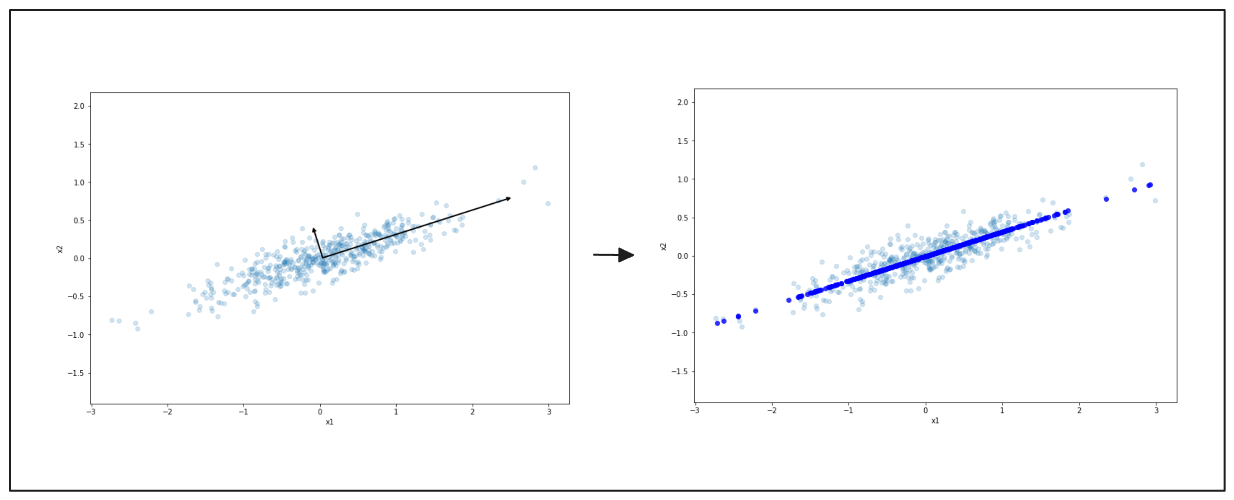 Рисунок - Упрощенное представление данных с помощью PCA.png
Рисунок - Упрощенное представление данных с помощью PCA.png
Иллюстрация: Упрощенное представление данных с помощью PCA
**Плюсы использования PCA
Уменьшение сложности**: Упрощение наборов данных с большим количеством переменных делает анализ более быстрым и эффективным.
Удаление шума: PCA отфильтровывает шум и нерелевантную информацию, сохраняя компоненты с наибольшей дисперсией.
Улучшает визуализацию: PCA помогает визуализировать высокоразмерные данные в двух или трех измерениях, выявляя закономерности, которые в противном случае могли бы быть скрыты.
Минусы использования PCA.
Потеря информации: Часть данных может быть потеряна при уменьшении размерности, что влияет на производительность модели.
Трудная интерпретируемость: Новые признаки, созданные с помощью PCA, являются комбинациями исходных признаков, что затрудняет их осмысленную интерпретацию.
Предполагает линейность: PCA лучше всего работает, когда отношения между переменными линейны, что не всегда верно.
Практические применения.
Сжатие изображений**: Уменьшает размер файла изображения, сохраняя при этом основные визуальные характеристики.
Финансы: Упрощение сложных наборов данных для выявления закономерностей в движении цен на акции.
Генетика: Анализирует большие геномные массивы данных для выявления значимых структур данных.
Версальность: Применяется для упрощения и интерпретации высокоразмерных данных в различных областях.
t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-Distributed Stochastic Neighbor Embedding (t-SNE) визуализирует высокоразмерные данные. Он проецирует данные в два или три измерения, чтобы выявить кластеры и закономерности. t-SNE широко ценится за способность сохранять локальные связи между точками данных, что помогает выявить глубинную структуру набора данных. Этот метод больше подходит для наборов данных в трехмерном пространстве.
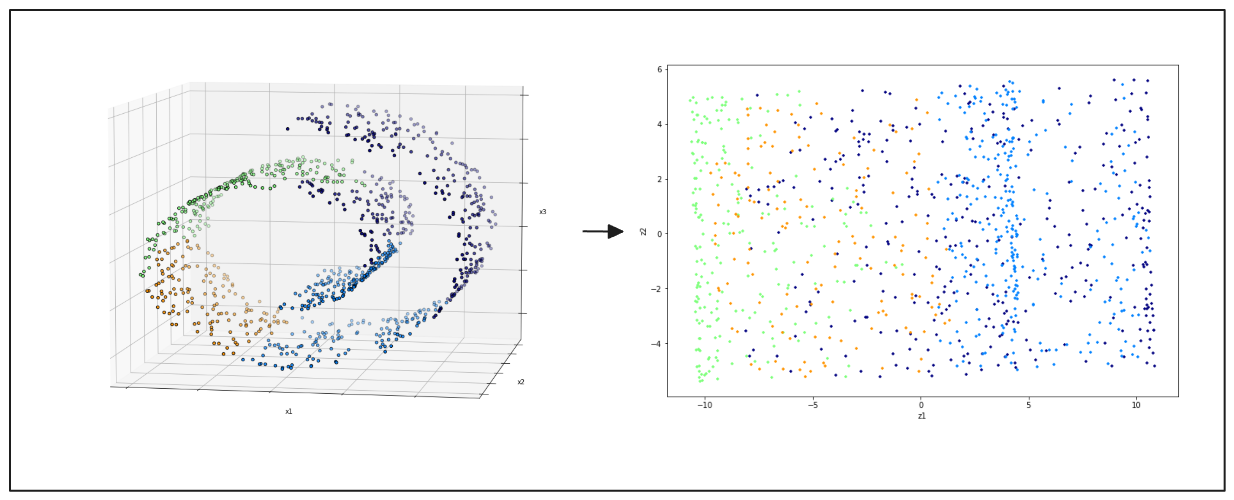 Рисунок - слева - 3D-точки данных, справа - результат 2D-проекции из PCA.png
Рисунок - слева - 3D-точки данных, справа - результат 2D-проекции из PCA.png
Иллюстрация: Слева: 3D-точки данных "швейцарского валика", справа: 2D-проекция, полученная с помощью PCA
Преимущества использования t-SNE
Сохранение локальной структуры: t-SNE отлично справляется с удержанием близких точек данных в низкоразмерном пространстве, что делает его эффективным для визуализации кластеров.
Полезен для сложных данных: Он особенно хорошо справляется с нелинейными зависимостями и позволяет исследовать сложные закономерности в данных.
Отлично подходит для визуализации: t-SNE создает интуитивно понятные и привлекательные диаграммы рассеяния, которые помогают понять расположение данных.
Минусы использования t-SNE.
Вычислительная интенсивность: Выполнение t-SNE может быть медленным и ресурсоемким, особенно для больших наборов данных.
Требуется настройка параметров**: Такие параметры, как сложность и скорость обучения, должны быть тщательно настроены, и результаты могут значительно отличаться в зависимости от этих настроек.
Искажает глобальную структуру: Хотя t-SNE хорошо сохраняет локальные связи, он может исказить глобальную структуру данных и сделать ее менее полезной для понимания крупномасштабных связей.
Практические применения.
Визуализация высокоразмерных данных**: Полезно для изучения кластерных структур.
Распознавание изображений: Визуализация распределения признаков изображения.
Обработка естественного языка (NLP): Изучает вкрапления слов.
Геномика: Выявляет значимые кластеры генетических данных.
Популярность: Широко используется учеными, изучающими данные, для визуального анализа, несмотря на ограничения.
Линейный дискриминантный анализ (LDA)
В отличие от PCA, LDA стремится максимизировать разделение между различными классами в данных. Для этого он проецирует данные на более низкоразмерное пространство, которое наилучшим образом разделяет категории на основе их меток.
LDA обычно используется в сценариях, где классификация данных является основной целью. Она особенно полезна при работе с наборами данных, которые имеют четкие границы классов. Некоторые практические приложения включают распознавание лиц, медицинскую диагностику и классификацию текстов.
Чем LDA отличается от PCA?
Цель: LDA фокусируется на максимизации разделимости классов, в то время как PCA стремится уловить наибольшую дисперсию в данных без учета меток классов.
Наблюдаемый и ненаблюдаемый: LDA - это контролируемая методика, которая использует метки классов в своих вычислениях. PCA, с другой стороны, является неконтролируемой и не использует никакой информации о метках.
Дифференциация данных: LDA уменьшает размерность путем нахождения осей, которые максимизируют расстояние между средними различных классов, минимизируя при этом разброс внутри каждого класса. PCA не учитывает информацию о классах, и его единственной целью является сокращение избыточности данных.
Другие техники и новые методы
Помимо традиционных методов уменьшения размерности, таких как PCA, t-SNE и LDA, в анализе данных набирают популярность и другие методы и новые тенденции.
Автокодировщики
Автокодировщики - это нейронные сети, используемые для неконтролируемого обучения, целью которого является сжатие данных в более низкоразмерное представление, а затем восстановление их в исходной форме. Сеть состоит из кодера, который уменьшает размерность, и декодера, который восстанавливает входные данные из сжатого представления. Автокодировщики полезны для работы с нелинейными связями в данных и могут изучать сложные представления признаков.
Независимый компонентный анализ (ICA)
Анализ независимых компонент (ICA) - это вычислительная техника для разделения многомерного сигнала на аддитивные, независимые компоненты. В отличие от PCA, который фокусируется на дисперсии, ICA ищет статистически независимые источники. Этот метод часто используется в таких приложениях, как слепое разделение источников, например, для выделения различных источников звука из смешанной записи.
Равномерная аппроксимация и проекция многообразия (UMAP)
Равномерная аппроксимация и проекция многообразия (UMAP) - это относительно новая техника уменьшения размерности, которая сохраняет как локальные, так и глобальные структуры в данных. Она основана на изучении многообразий и направлена на сохранение связей между точками данных в процессе сокращения. UMAP работает быстрее и часто дает лучшие визуализации по сравнению с t-SNE.
Преимущества уменьшения размерности
Снижение размерности дает несколько ключевых преимуществ, которые улучшают анализ сложных наборов данных:
Упрощенные модели: Меньшее количество признаков приводит к созданию более простых моделей, которые легче обучать и анализировать, что может иметь решающее значение для приложений, чувствительных к времени.
Снижение требований к хранению и вычислениям: Работа с низкоразмерными данными требует меньше места для хранения и ускоряет обработку, что позволяет снизить операционные расходы, особенно при работе с большими массивами данных.
Улучшение производительности моделей: Благодаря учету наиболее значимых характеристик модели становятся более точными и надежными, поскольку на них с меньшей вероятностью могут повлиять нерелевантные данные.
Улучшает интерпретируемость: Сокращение размерности позволяет выделить существенные взаимосвязи в данных, что помогает заинтересованным сторонам понять решения модели и лежащие в их основе закономерности.
Улучшает визуализацию данных: Преобразование высокоразмерных данных в двух- или трехмерные позволяет получить более четкие визуальные представления, помогая обнаружить идеи, которые могут быть неочевидны в более высоких измерениях.
Помогает снизить уровень шума: Удаляя менее важные измерения, снижение размерности позволяет уменьшить количество шума, что приводит к созданию более чистых наборов данных, способствующих более надежному анализу.
Помогает улучшить разработку характеристик: Этот процесс помогает выявить наиболее значимые признаки, предоставляя возможности для создания улучшенных признаков, которые могут привести к повышению производительности модели.
Позволяет быстрее создавать прототипы: Учитывая меньшее количество измерений, ученые, занимающиеся изучением данных, могут быстро итеративно разрабатывать модели для их быстрого тестирования и доработки.
Проблемы снижения размерности
Методы снижения размерности сопряжены с рядом проблем, которые требуют тщательного рассмотрения:
Риск потери важной информации: Уменьшение размерности может привести к случайному отбрасыванию важных характеристик, что может негативно повлиять на производительность модели и привести к неправильной интерпретации результатов.
Выбор правильной методики: Эффективность методов снижения размерности зависит от характера набора данных и конкретных аналитических целей. Эта вариативность делает крайне важным понимание сильных сторон и ограничений каждого метода, чтобы избежать неэффективных результатов.
Вычислительные затраты: Такие методы, как t-SNE, могут быть ресурсоемкими и менее целесообразными для больших наборов данных. Требования к времени и памяти могут существенно ограничить их применимость в сценариях, чувствительных ко времени.
Баланс между сокращением и точностью: Достижение нужного уровня сокращения размерности при сохранении в модели достаточного количества информации для точного прогнозирования является постоянной проблемой. Чрезмерное сокращение может слишком сильно упростить данные, что негативно скажется на способности модели отражать необходимую сложность.
Применение сокращения размерности в различных отраслях
Методы снижения размерности находят применение в различных областях, улучшая анализ данных и повышая производительность моделей. Вот несколько практических сценариев, в которых часто используются эти методы:
Обработка изображений: В таких областях, как компьютерное зрение, снижение размерности помогает сжимать данные изображений, сохраняя при этом основные характеристики. Например, при распознавании лиц PCA позволяет свести тысячи значений пикселей к более мелким характеристикам, ускоряя обработку без потери важных деталей. Аналогично, в медицинской визуализации уменьшение размерности позволяет выделить важные области на снимках МРТ для более быстрого анализа.
Обработка естественного языка: Снижение размерности используется для упрощения высокоразмерных текстовых данных, таких как вкрапления слов. Такие методы, как t-SNE, помогают визуализировать связи между словами и кластеры, что способствует анализу настроений и моделированию тем.
Геномика: В биоинформатике методы снижения размерности необходимы для анализа генетических данных, где число переменных (генов) может быть чрезвычайно велико. Снижение размерности помогает выявить ключевые генетические маркеры, связанные с заболеваниями.
Финансы: Снижение размерности помогает в управлении рисками и оптимизации портфеля за счет упрощения больших наборов данных о финансовых показателях. Аналитики могут выбрать наиболее значимые характеристики, влияющие на поведение рынка.
Рекомендательные системы: В системах совместной и контентной фильтрации уменьшение размерности помогает создавать более эффективные алгоритмы рекомендаций, выявляя основные закономерности в предпочтениях пользователей и характеристиках товаров.
Здравоохранение: При анализе данных о пациентах часто используются высокоразмерные наборы данных. Снижение размерности помогает выявить значимые факторы, влияющие на результаты лечения пациентов, и улучшить прогностическое моделирование развития заболевания.
Аналитика маркетинга: В маркетинге понимание поведения клиентов имеет решающее значение. Снижение размерности позволяет компаниям легко сегментировать клиентов, уменьшая сложность данных о них, что приводит к разработке целевых маркетинговых стратегий.
Производство и контроль качества: В промышленных приложениях уменьшение размерности помогает анализировать данные датчиков машин для выявления закономерностей и аномалий, что позволяет улучшить контроль качества и предиктивное обслуживание.
Как уменьшение размерности улучшает производительность векторных баз данных?
Снижение размерности значительно повышает производительность векторных баз данных, таких как Milvus (созданная инженерами Zilliz), которая предназначена для управления масштабными неструктурированными данными и их высокоразмерными векторными представлениями. Вот как они взаимосвязаны:
Эффективное хранение данных: Milvus может хранить высокоразмерные векторные данные, генерируемые моделями машинного обучения. Применение методов снижения размерности, таких как PCA или t-SNE, помогает сжимать эти векторы, уменьшая требования к хранению и повышая скорость поиска.
Повышенная производительность запросов: Поиск по высокоразмерным данным в векторной базе данных может потребовать больших вычислительных затрат. Снижение размерности минимизирует размерность векторов, что ускоряет поиск по сходству и запросы ближайших соседей.
Улучшенная визуализация данных: При использовании Zilliz или Milvus для анализа данных методы снижения размерности могут облегчить визуализацию сложных наборов данных. Это позволяет пользователям лучше понять распределение данных, взаимосвязи и закономерности в высокоразмерных данных, хранящихся в базе данных.
Упрощение рабочих процессов машинного обучения: В конвейерах машинного обучения снижение размерности помогает упростить предварительную обработку данных. Снижение сложности входных признаков улучшает процесс обучения моделей машинного обучения, что приводит к повышению производительности и интерпретируемости.
Заключение
Снижение размерности - важная техника в науке о данных и машинном обучении, которая упрощает сложные наборы данных, сохраняя при этом важную информацию. Сокращение числа признаков повышает производительность модели, облегчает визуализацию и помогает легко анализировать данные в различных областях. Несмотря на сложности, такие как риск потери важной информации и необходимость тщательного подбора методов, преимущества сокращения размерности делают его неоценимым для раскрытия сути и повышения эффективности аналитических процессов.
Часто задаваемые вопросы о снижении размерности
- **Что такое снижение размерности?
Снижение размерности - это техника, используемая для уменьшения количества признаков или измерений в наборе данных с сохранением как можно большего количества релевантной информации. Такое упрощение облегчает анализ, визуализацию и моделирование сложных данных.
- Почему сокращение размерности важно для науки о данных?
Оно помогает повысить производительность моделей, снизить требования к хранению и вычислениям, улучшить визуализацию данных и упростить интерпретацию моделей, что делает его необходимым для эффективного анализа данных в различных приложениях.
- Каковы некоторые распространенные методы сокращения размерности?
К распространенным методам относятся анализ главных компонент (PCA), t-распределенное стохастическое встраивание соседей (t-SNE), линейный дискриминантный анализ (LDA), методы выбора признаков, а также новые методы, такие как автоэнкодеры и UMAP.
- **Какие проблемы связаны с уменьшением размерности?
К проблемам относятся риск потери важной информации, сложность выбора правильной методики для конкретных наборов данных, вычислительные затраты на некоторые методы и баланс между уменьшением размерности и точностью модели.
- **Как сокращение размерности помогает векторным базам данных типа Milvus?
Снижение размерности повышает производительность векторных баз данных, оптимизируя хранение данных, повышая производительность запросов, облегчая визуализацию данных и оптимизируя рабочие процессы машинного обучения.
Связанные ресурсы
- Проклятие размерности
- Основные методы снижения размерности
- Другие техники и новые методы
- Преимущества уменьшения размерности
- Проблемы снижения размерности
- Применение сокращения размерности в различных отраслях
- Как уменьшение размерности улучшает производительность векторных баз данных?
- Заключение
- Часто задаваемые вопросы о снижении размерности
- Связанные ресурсы
Контент
Начните бесплатно, масштабируйтесь легко
Попробуйте полностью управляемую векторную базу данных, созданную для ваших GenAI приложений.
Попробуйте Zilliz Cloud бесплатно