




Milvus на GPU с NVIDIA RAPIDS cuVS
Введение
Производительность в производстве - критический фактор успеха нашего приложения искусственного интеллекта. Чем быстрее мы сможем вернуть результаты пользователю, тем лучше. Такая срочность обуславливает необходимость оптимизации.
Рассмотрим реальный пример - приложение Retrieval Augmented Generation (RAG). В системе RAG векторный поиск - это двигатель, который обеспечивает работу пользователя, предоставляя релевантные результаты на основе его запросов. Однако мы прекрасно понимаем, что векторный поиск - это ресурсоемкая задача. Чем больше данных мы храним, тем более дорогими и трудоемкими становятся вычисления.
Необходимо найти решение для оптимизации производительности наших приложений ИИ в таких случаях. В недавнем выступлении на Unstructured Data Meetup, организованном Zilliz, Кори Нолет, главный инженер в NVIDIA, рассказал о последних достижениях NVIDIA в решении этой проблемы, которые мы рассмотрим в этой статье. Вы также можете посмотреть выступление Кори на YouTube.
.В частности, мы сосредоточимся на cuVS, библиотеке, разработанной NVIDIA, которая содержит несколько алгоритмов, связанных с векторным поиском, и использует возможности ускорения графических процессоров. Мы увидим, как эта библиотека может повысить производительность операций векторного поиска и оптимизировать общие операционные расходы. Итак, без лишних слов, давайте погрузимся в работу!
Векторный поиск и роль векторной базы данных в нем
Векторный поиск - это метод информационного поиска, при котором запрос пользователя и искомые документы представляются в виде векторов. Чтобы выполнить векторный поиск, нам необходимо преобразовать запрос и документы (которые могут быть изображениями, текстами и т. д.) в векторы.
Вектор имеет определенную размерность, которая зависит от метода, используемого для его генерации. Например, если мы используем модель HuggingFace под названием all-MiniLM-L6-v2 для преобразования нашего запроса в вектор, мы получим вектор с размерностью 384. Векторы несут в себе семантическое значение данных или документов, которые они представляют. Поэтому, если два фрагмента данных похожи друг на друга, соответствующие им векторы располагаются близко друг к другу в векторном пространстве.
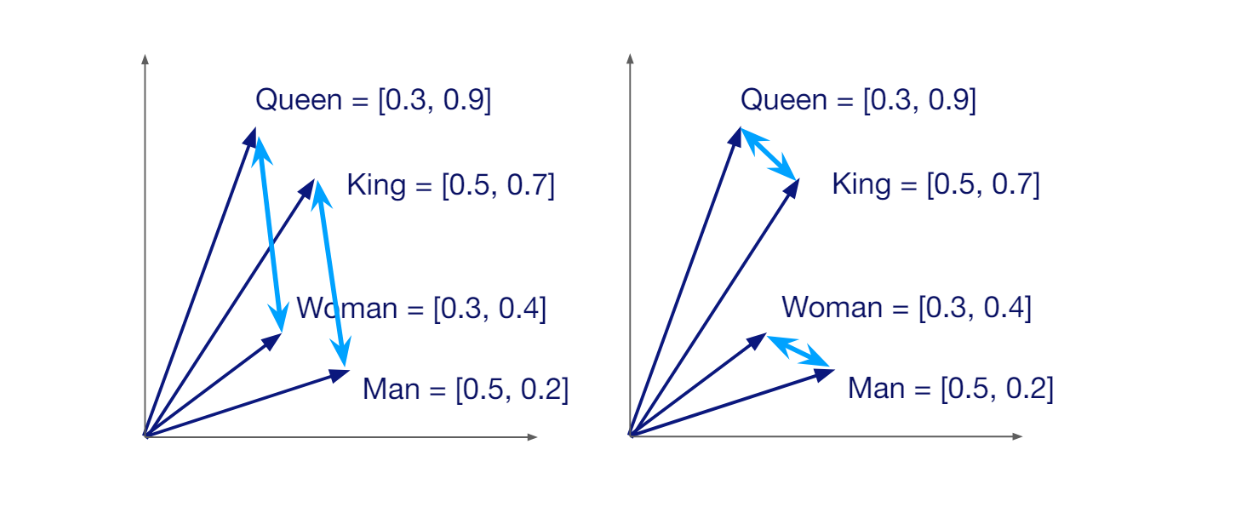 Семантическое сходство между векторами в векторном пространстве..png
Семантическое сходство между векторами в векторном пространстве..png
Семантическое сходство между векторами в векторном пространстве.
Тот факт, что каждый вектор несет в себе семантическое значение данных, которые он представляет, позволяет нам вычислить сходство между любой случайной парой векторов. Если они похожи, то оценка сходства будет высокой, и наоборот. Основная цель векторного поиска - найти векторы, наиболее похожие на вектор нашего запроса.
Реализация векторного поиска относительно проста при работе с несколькими документами. Однако сложность возрастает по мере увеличения количества документов и необходимости хранения большего количества векторов. Чем больше векторов, тем больше времени требуется для выполнения векторного поиска. Кроме того, операционные расходы значительно возрастают по мере хранения большего количества векторов в локальной памяти. Таким образом, нам необходимо масштабируемое решение, и именно здесь на помощь приходят [векторные базы данных] (https://zilliz.com/learn/what-is-vector-database).
Векторные базы данных представляют собой эффективное, быстрое и масштабируемое решение для хранения огромной коллекции векторов. Они обеспечивают передовые методы индексирования для ускорения поиска векторов, а также легкую интеграцию с популярными ИИ-фреймворками для упрощения процесса разработки наших ИИ-приложений. В векторных базах данных, таких как Milvus и Zilliz Cloud (управляемая Milvus), мы также можем хранить метаданные векторов и выполнять расширенные процессы фильтрации во время поисковых операций.
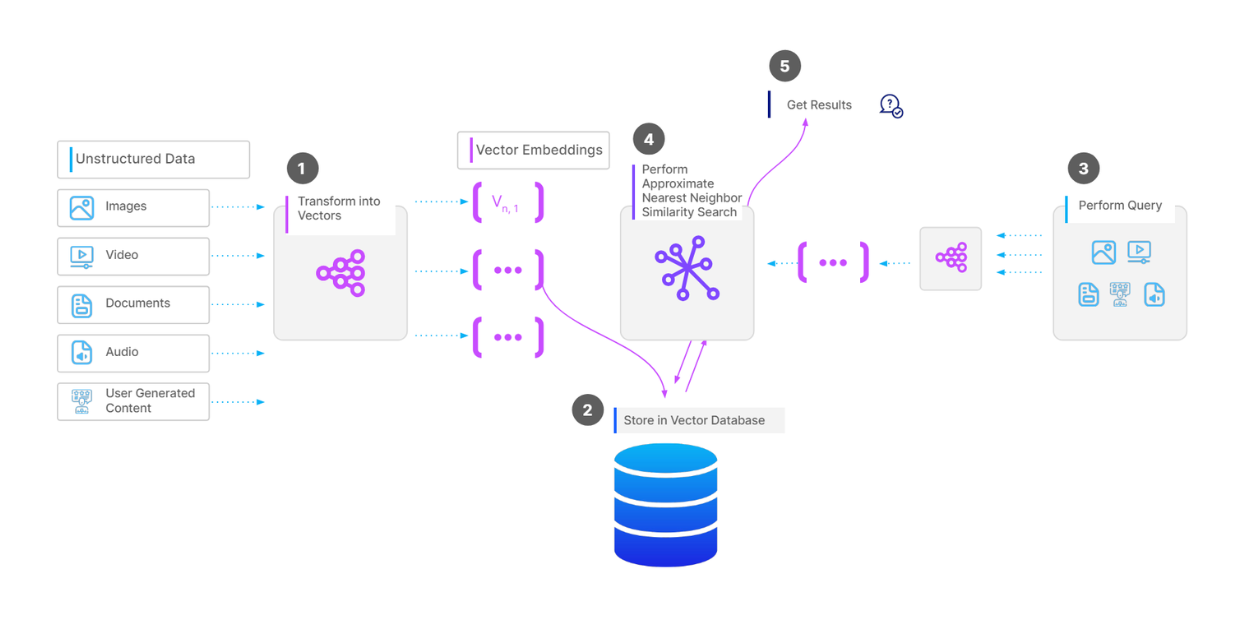 Полный рабочий процесс операции поиска векторов..png
Полный рабочий процесс операции поиска векторов..png
Полный рабочий процесс операции векторного поиска._
Чтобы сохранить коллекцию векторов в векторной базе данных, такой как Milvus, первым шагом будет предварительная обработка данных, в зависимости от типа данных. Например, если наши данные представляют собой коллекцию документов, мы можем разделить текст каждого документа на фрагменты. Затем мы преобразуем каждый фрагмент в вектор с помощью модели встраивания по нашему выбору. Затем мы помещаем все векторы в нашу векторную базу данных и создаем индекс для ускорения поиска при векторном поиске.
Когда у нас есть запрос и мы хотим выполнить операцию векторного поиска, мы преобразуем запрос в вектор с помощью той же модели встраивания, которая использовалась ранее, а затем вычисляем его сходство с векторами в базе данных. В итоге нам возвращаются наиболее похожие векторы.
Операция векторного поиска на процессоре
Операции векторного поиска требуют интенсивных вычислений, и стоимость вычислений возрастает по мере того, как мы храним больше векторов в базе данных векторов. На стоимость вычислений напрямую влияют несколько факторов, таких как построение индекса, общее количество векторов, размерность вектора и желаемое качество результатов поиска.
Центральные процессоры являются наиболее распространенными вычислительными устройствами для операций векторного поиска из-за их экономичности и легкой интеграции с другими компонентами в приложениях ИИ. Многие алгоритмы векторного поиска полностью оптимизированы для центральных процессоров, наиболее популярным из них является Hierarchical Navigable Small World (HNSW).
По своей сути HNSW объединяет концепции списков пропусков и Navigable Small World (NSW). В алгоритме NSW граф строится путем случайной перестановки точек данных. Затем точки данных вставляются одна за другой, при этом каждая точка соединяется через заранее определенное количество ребер со своими ближайшими соседями.
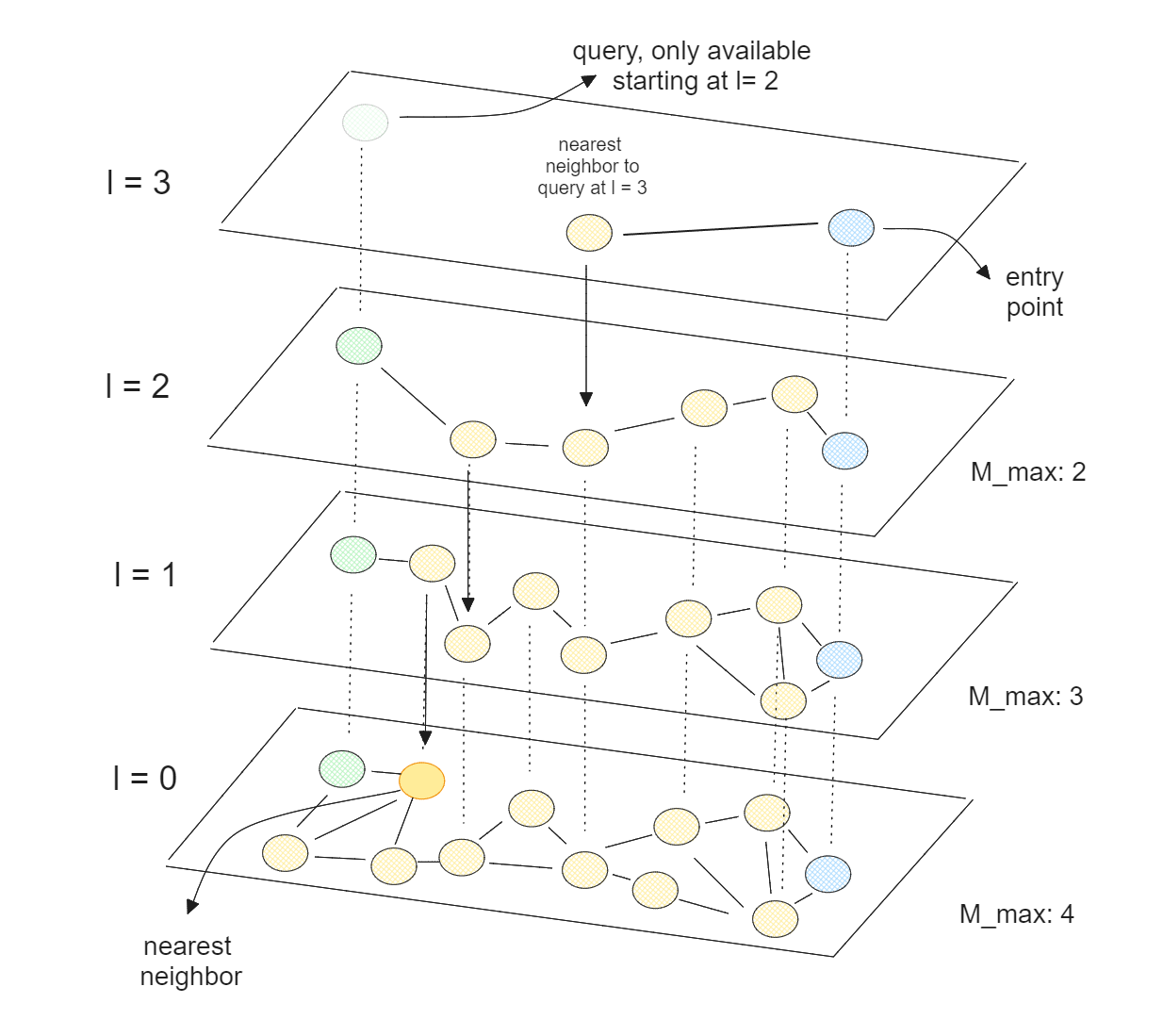 Векторный поиск с использованием HNSW..png
Векторный поиск с использованием HNSW..png
Векторный поиск с использованием HNSW.
HNSW - это многослойный NSW, где самый нижний слой содержит все точки данных, а самый верхний - только небольшое подмножество точек данных. Это означает, что чем выше слой, тем больше точек данных мы пропускаем, что соответствует теории списков пропусков.
В HNSW мы имеем граф, в котором большинство узлов могут быть достигнуты из любого другого узла за небольшое количество итераций. Это свойство позволяет HNSW эффективно перемещаться по графу и быстро находить приблизительных ближайших соседей. Поскольку HNSW оптимизирован для центральных процессоров, мы также можем распараллелить его выполнение на нескольких ядрах процессора, чтобы еще больше ускорить процесс векторного поиска.
Однако время вычислений HNSW все равно страдает, когда мы храним больше данных в базе векторов. Это может стать еще хуже, если размерность наших векторов очень высока. Поэтому нам нужно другое решение для случаев, когда у нас есть огромное количество векторов с высокой размерностью.
Операция поиска векторов на GPU
Одним из решений для повышения производительности векторного поиска при работе с огромным количеством векторов высокой размерности является работа на GPU. Для этого мы можем использовать библиотеку NVIDIA RAPIDS cuVS, содержащую несколько реализаций векторного поиска, оптимизированных для GPU. Она упрощает использование GPU как для операций векторного поиска, так и для построения индексов.
cuVS предлагает на выбор несколько алгоритмов ближайших соседей, включая:
Brute-force: Исчерпывающий поиск ближайших соседей, при котором запрос сравнивается с каждым вектором в базе данных.
IVF-Flat: Алгоритм приближенного поиска ближайших соседей (ANN), который разбивает векторы в базе данных на несколько непересекающихся разделов. Запрос сравнивается только с векторами в тех же (и, по желанию, соседних) разделах.
IVF-PQ: Квантованная версия IVF-Flat, которая уменьшает объем памяти, занимаемой векторами в базе данных.
CAGRA: Алгоритм на GPU, аналогичный HNSW.
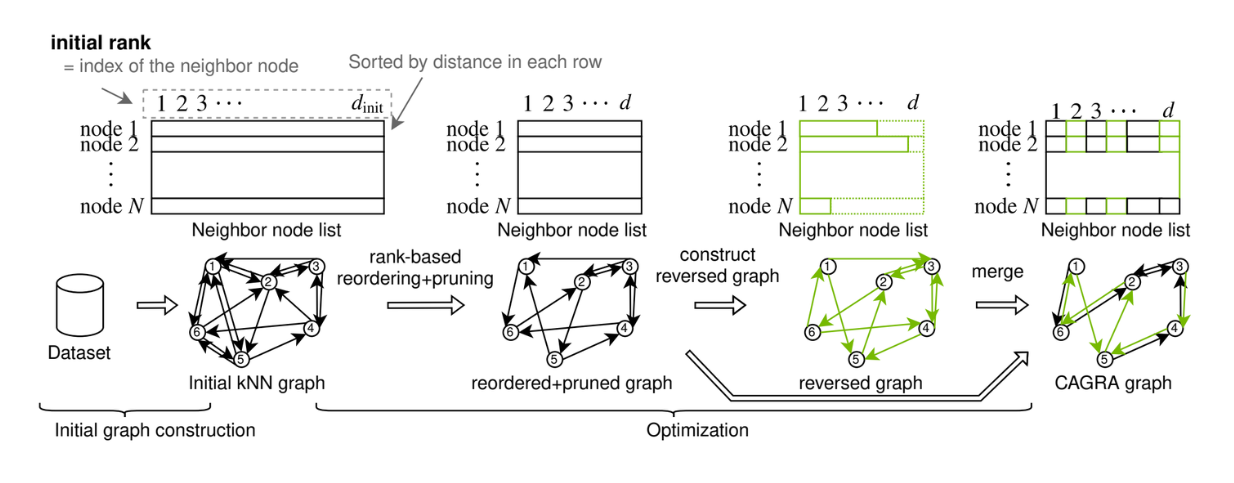 CAGRA graph construction. .png
CAGRA graph construction. .png
Построение графа CAGRA. Источник.
Среди этих алгоритмов ближайших соседей мы остановимся на CAGRA.
CAGRA - это алгоритм на основе графов, представленный компанией NVIDIA для быстрого и эффективного поиска ближайших соседей с использованием параллельной вычислительной мощности графических процессоров.
Граф в CAGRA может быть построен либо методом IVF-PQ, либо методом NN-DESCENT:
Метод IVF-PQ: Использует индекс для создания начального графа, занимающего мало памяти, путем соединения каждой точки с множеством соседей.
Метод NN-DESCENT: Использует итерационный процесс для построения графа путем расширения и уточнения связей между точками.
По сравнению с HNSW, методы построения графов CAGRA легче распараллеливаются и содержат меньше взаимодействия данных между задачами, что значительно увеличивает время построения графа или индекса. Если вы хотите узнать больше о CAGRA, ознакомьтесь с его официальным документом или статьей CAGRA.
CAGRA установила передовую производительность в операциях векторного поиска. Чтобы продемонстрировать это, в следующем разделе мы сравним ее производительность с HNSW.
Сравнение производительности CAGRA и HNSW
В векторном поиске есть две критические операции, где производительность имеет решающее значение: построение индекса и сам поиск. Мы сравним производительность CAGRA и HNSW в этих двух операциях.
Начнем с построения индекса.
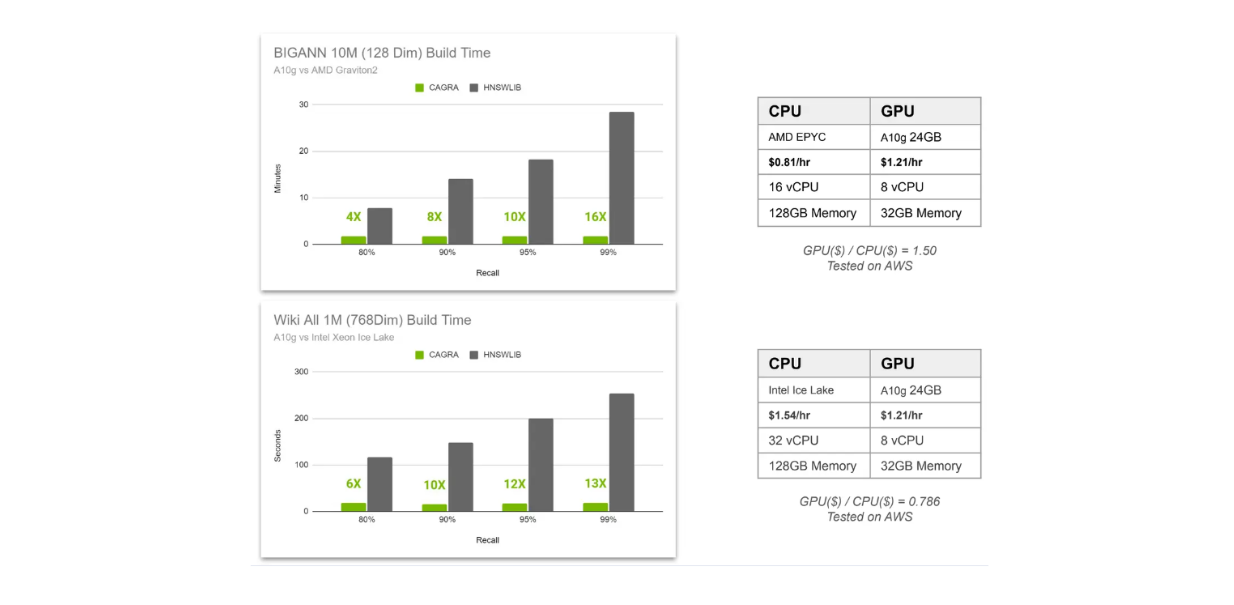 Сравнение времени построения индекса CAGRA vs HNSW..png
Сравнение времени построения индекса CAGRA vs HNSW..png
Сравнение времени построения индекса CAGRA vs HNSW._
В приведенной выше визуализации мы сравниваем время построения индексов CAGRA и HNSW в двух различных сценариях. Во-первых, у нас есть 10 М 128-мерных векторов, хранящихся в векторной базе данных, а во-вторых, у нас есть 1 М 768-мерных векторов. В первом сценарии в качестве CPU для HNSW используется AMD Graviton2, а для CAGRA - A10G GPU, а во втором - Intel Xeon Ice Lake в качестве CPU для HNSW и A10G GPU для CAGRA.
Мы сравниваем время построения индекса при четырех различных значениях отзыва, варьирующихся от 80 до 99 %. Как вы, наверное, уже знаете, чем выше отзыв, тем более интенсивные вычисления требуются.
Это связано с тем, что в векторном поиске на основе графа мы можем точно настроить два фактора: количество соседей, рассматриваемых для поиска ближайшего соседа на каждом слое, и количество ближайших соседей, рассматриваемых в качестве точки входа на каждом слое. Чем выше отзыв, тем больше соседей будет рассматриваться, что приведет к повышению точности поиска, но и к увеличению вычислительных затрат.
Из приведенной выше визуализации видно, что использование GPU более целесообразно, когда мы хотим получить результаты с высоким уровнем запоминания. Кроме того, ускорение от использования GPU увеличивается по мере увеличения количества высокоразмерных векторов, хранящихся в нашей векторной базе данных.
Далее давайте сравним производительность HNSW и CAGRA с помощью двух метрик, часто используемых в векторном поиске:
Throughput: количество запросов, которые могут быть выполнены за определенный промежуток времени.
Задержка: время, необходимое алгоритму для выполнения одного запроса.
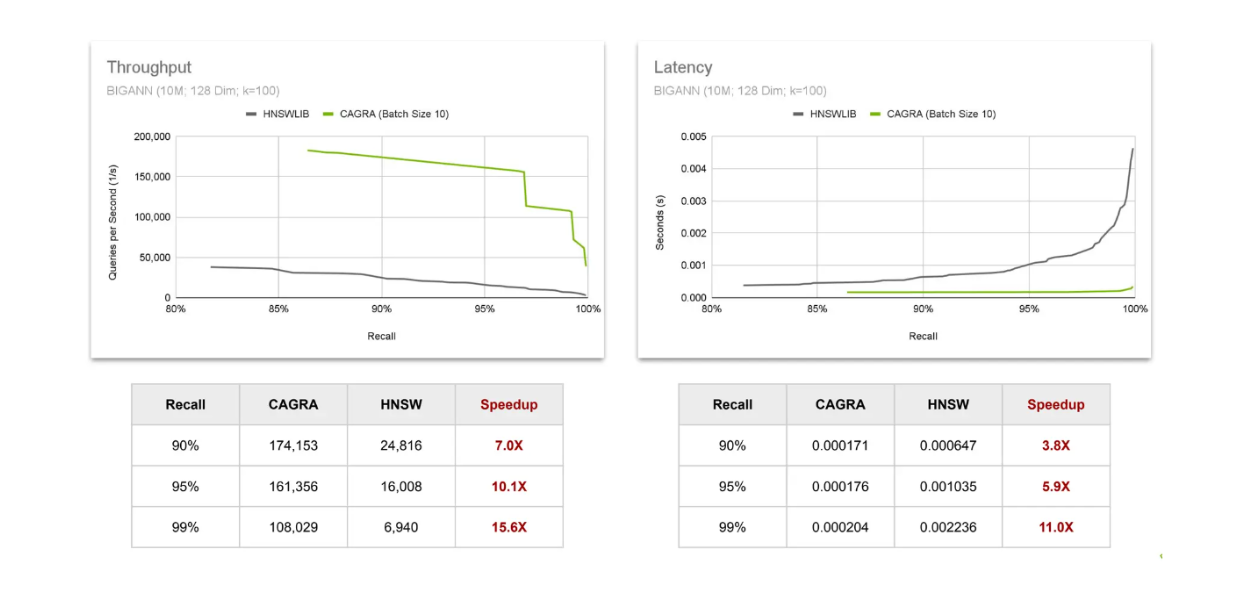 Сравнение пропускной способности и латентности CAGRA vs HNSW..png
Сравнение пропускной способности и латентности CAGRA vs HNSW..png
Сравнение пропускной способности и латентности CAGRA и HNSW._
Для оценки пропускной способности мы наблюдаем за количеством запросов, которые могут быть выполнены за секунду. Результаты показывают, что ускорение от использования CAGRA на GPU увеличивается по мере того, как нам требуются результаты с более высокими значениями recall. Аналогичная тенденция наблюдается и в отношении задержки, где ускорение увеличивается по мере роста значения recall. Это подтверждает, что ценность использования GPU возрастает по мере того, как мы ищем более точные результаты векторного поиска.
Однако иногда мы все же хотим использовать CPU при векторном поиске из-за его простоты и легкой интеграции с другими компонентами нашего ИИ-приложения. В этом случае реализация алгоритмов ближайших соседей с помощью CAGRA по-прежнему полезна, поскольку мы можем выполнять векторный поиск как на GPU, так и на CPU.
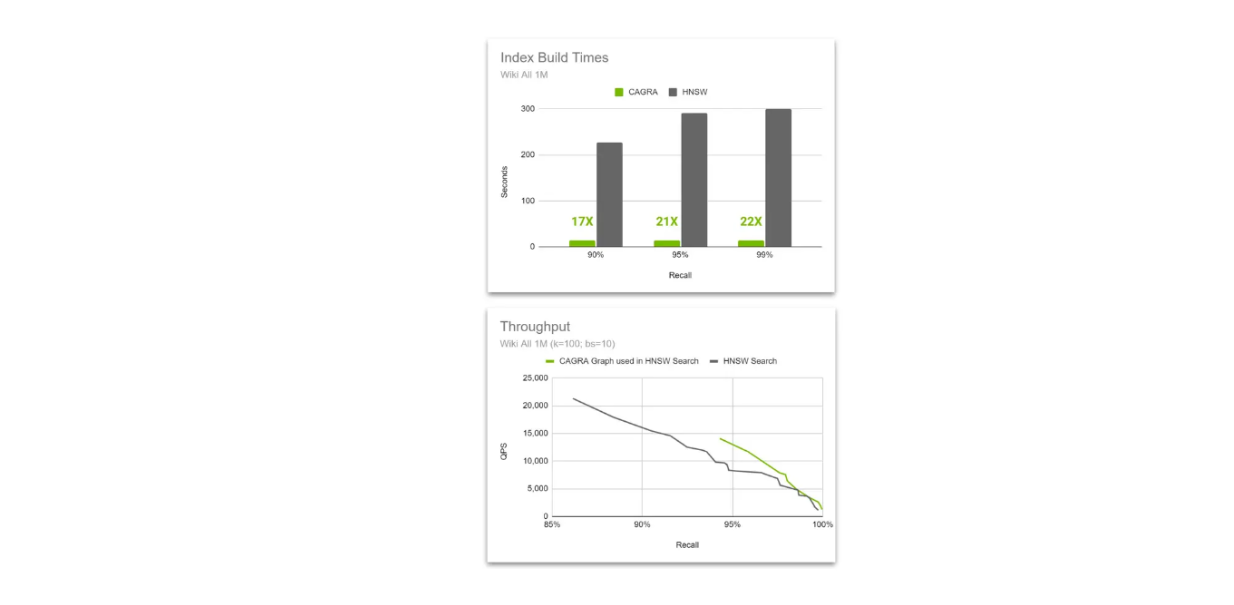 Сравнение пропускной способности нативного графа HNSW и графа CAGRA, используемого в поиске HNSW..png
Сравнение пропускной способности нативного графа HNSW и графа CAGRA, используемого в поиске HNSW..png
Сравнение пропускной способности графа HNSW native и графа CAGRA, используемого в HNSW-поиске.
Идея заключается в том, чтобы использовать ускорение CAGRA и GPU при построении индексов, а затем переключиться на HNSW при векторном поиске. Этот метод возможен потому, что алгоритм HNSW может выполнять поиск с использованием графа, построенного CAGRA, и его производительность даже лучше, чем у графа, построенного с помощью HNSW, при увеличении размерности вектора.
CAGRA также предлагает метод квантования под названием CAGRA-Q для дальнейшего сжатия памяти хранимых векторов. Это особенно полезно для более эффективного распределения памяти и позволяет хранить квантованные векторы в меньшем объеме памяти устройства для более быстрого извлечения.
Допустим, у нас есть память устройства, которая имеет меньший размер по сравнению с памятью хоста. Первые бенчмарки производительности от NVIDIA показали, что квантованные векторы, хранящиеся в памяти устройства, с графом, хранящимся в памяти хоста, будут иметь схожую производительность по сравнению с оригинальными неквантованными векторами и графом, хранящимися в памяти устройства, при более высокой скорости вызова.
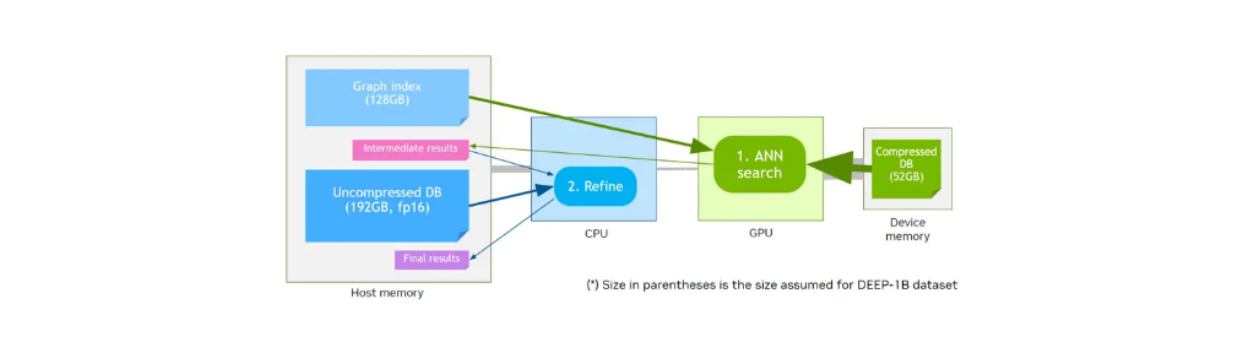 Рабочий процесс векторного поиска с использованием памяти устройства и CAGRA-Q..png
Рабочий процесс векторного поиска с использованием памяти устройства и CAGRA-Q..png
Рабочий процесс поиска векторов с использованием памяти устройства и CAGRA-Q._
Milvus на GPU с CuVS
Milvus поддерживает интеграцию с библиотекой cuVS, что позволяет нам объединить Milvus с CAGRA для создания приложений искусственного интеллекта. Архитектура Milvus состоит из нескольких узлов, таких как узлы индекса, узлы запроса и узлы данных. cuVS оптимизирует производительность Milvus, ускоряя процессы в узлах запроса и узлах индекса.
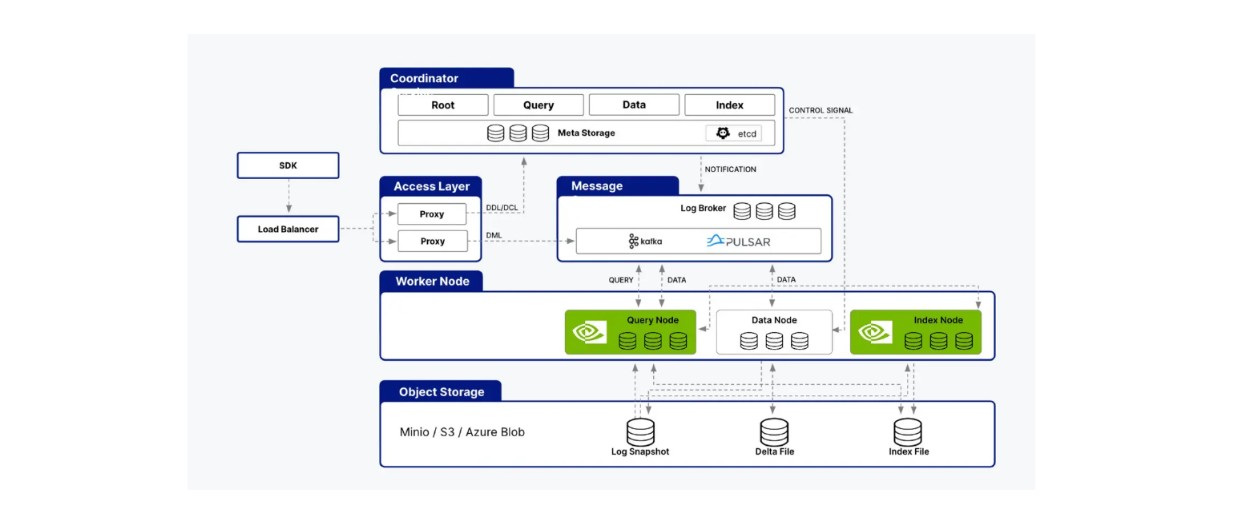 cuVS поддерживает как узлы запросов, так и узлы индексов архитектуры Milvus..png
cuVS поддерживает как узлы запросов, так и узлы индексов архитектуры Milvus..png
cuVS поддерживает как узлы запросов, так и узлы индексов архитектуры Milvus.
Как вы уже знаете, индексные узлы отвечают за создание индексов, а узлы запросов обрабатывают запросы пользователей, выполняют векторный поиск и возвращают результаты пользователю. В предыдущем разделе мы видели, как CAGRA улучшает все эти аспекты по сравнению с собственными процессорными алгоритмами, такими как HNSW.
Теперь давайте рассмотрим производительность создания индексов с помощью cuVS и локального Milvus. В частности, мы рассмотрим время построения индекса с помощью CAGRA и IVF-PQ для разного количества векторов: 10, 20, 40 и 80 миллионов.
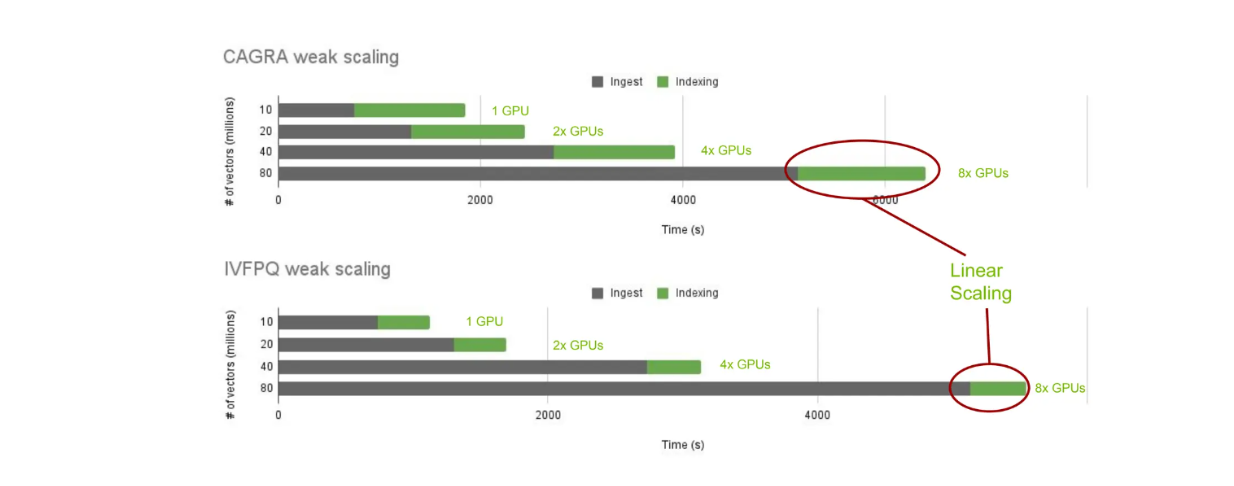 Масштабирование времени построения индекса с помощью cuVS для различных алгоритмов ближайших соседей..png
Масштабирование времени построения индекса с помощью cuVS для различных алгоритмов ближайших соседей..png
cuVS масштабирование времени построения индекса для различных алгоритмов ближайших соседей.
Как и ожидалось, время индексации увеличивается с ростом числа хранимых векторов. Однако время построения индекса остается постоянным, поскольку мы линейно добавляем больше GPU в зависимости от количества хранимых векторов. Это позволяет нам масштабировать и сравнивать время построения индекса для различных алгоритмов ближайших соседей с помощью cuVS.
Мы знаем, что графические процессоры обеспечивают более быстрые вычислительные операции по сравнению с центральными процессорами. Однако операционные затраты на использование GPU также выше. Поэтому нам необходимо сравнить соотношение затрат и производительности при использовании GPU и CPU в Milvus, как показано ниже.
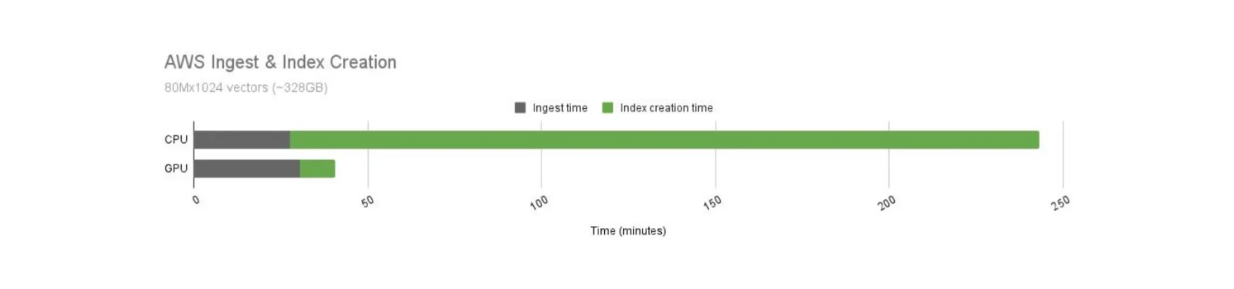 Сравнение времени построения индекса Milvus между GPU и CPU..png
Сравнение времени построения индекса Milvus между GPU и CPU..png
Сравнение времени построения индекса Milvus на GPU и CPU.png
Время построения индекса на GPU значительно быстрее, чем на CPU. В данном случае Milvus с GPU-ускорением обеспечивает 21-кратное ускорение по сравнению с аналогом на CPU. Однако эксплуатационные расходы на GPU также дороже, чем на CPU. Стоимость часа работы GPU составляет 16,29 доллара, а CPU - 9,68 доллара.
При нормализации соотношения затрат и производительности GPU и CPU использование GPU для построения индексов все равно дает лучшие результаты. При тех же затратах время построения индекса на GPU в 12,5 раз быстрее.
В другом эталонном тесте мы построили индекс для 635M 1024-мерных векторов. При использовании 8 графических процессоров DGX H100 время построения индекса методом IVF-PQ занимает около 56 минут. Для сравнения, при использовании CPU на выполнение той же задачи ушло бы примерно 6,22 дня.
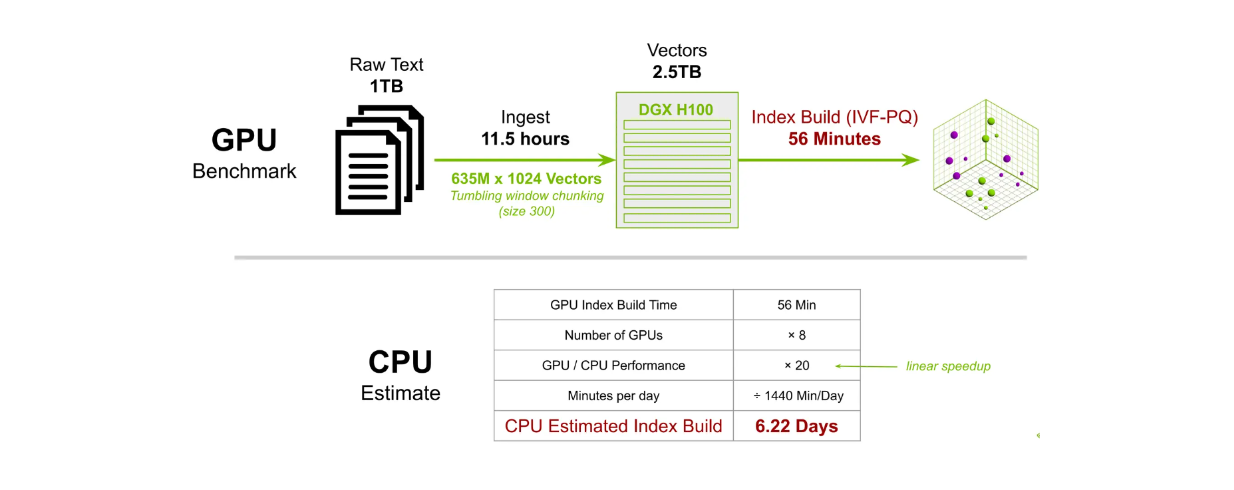 Сравнение времени построения индекса Milvus на GPU и CPU в крупном масштабе..png
Сравнение времени построения индекса Milvus на GPU и CPU в крупном масштабе..png
Сравнение времени построения индекса Милвуса между GPU и CPU._
Заключение
Усовершенствования в векторном поиске с GPU-ускорением благодаря библиотеке NVIDIA cuVS и алгоритму CAGRA очень полезны для оптимизации производительности приложений ИИ в производстве. В частности, GPU обеспечивают значительное улучшение по сравнению с CPU в случаях с высоким значением recall, высокой размерностью вектора и большим количеством векторов.
Благодаря возможностям интеграции Milvus мы теперь можем легко включить cuVS в нашу векторную базу данных Milvus. Хотя эксплуатационные расходы на GPU выше, чем на CPU, соотношение производительности и затрат часто все же благоприятствует GPU в крупномасштабных приложениях, как показано в приведенных выше бенчмарках. Если вы хотите узнать больше о cuVS, вы можете обратиться к полной документации, предоставленной командой NVIDIA.
Дополнительные ресурсы
Читать далее

Introducing Zilliz MCP Server: Natural Language Access to Your Vector Database
Developers can easily manage and query vector databases with natural language via Zilliz MCP Server in AI-native environments.

Why AI Databases Don't Need SQL
Whether you like it or not, here's the truth: SQL is destined for decline in the era of AI.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.