




Локальная агентурная RAG с LangGraph и Llama 3.2
Обновлено 25 сентября 2024 года с версией Llama 3.2.
В этом посте мы покажем, как построить агентов, которые могут интеллектуально вызывать инструменты для выполнения определенных задач, используя LangGraph и Llama 3, а также используя Milvus Lite для эффективного хранения данных. Эти агенты объединяют несколько важных возможностей, включая планирование, память и вызов инструментов, чтобы улучшить производительность систем с расширенным поиском (RAG).
Введение в LangGraph и Llama 3
LangGraph - это расширение LangChain, предназначенное для создания надежных многоакторных приложений с большими языковыми моделями (LLMs). В то время как LangChain предлагает основу для интеграции LLM в различные рабочие процессы, LangGraph развивает эту идею, моделируя задачи как узлы и ребра в графовой структуре. Это позволяет создавать более сложные потоки управления, позволяя LLM планировать, обучаться и адаптироваться к поставленной задаче. LangGraph обеспечивает гибкость для реализации систем, в которых агенты используют многоэтапные рассуждения, динамически выбирая нужные инструменты для каждого этапа. Кроме того, LangGraph можно использовать для создания надежных агентов RAG, которые при каждом запуске следуют заданному пользователем потоку управления, обеспечивая согласованность и предсказуемость своих ответов.
LangGraph также позволяет реализовать более сложное поведение агентов за счет включения циклов в рабочие процессы. Эти циклы позволяют агентам при необходимости возвращаться к предыдущим шагам, динамически корректируя свои действия на основе новой информации или размышлений. В результате получаются более интеллектуальные агенты, способные со временем совершенствовать свои рассуждения, создавая более надежные и адаптивные системы RAG.
Llama 3, большая языковая модель с открытым исходным кодом, служит основным механизмом рассуждений в памяти агента. В сочетании с LangGraph Llama 3 может анализировать входные данные, решать, какие действия следует предпринять, и вызывать необходимые инструменты. Вместо того чтобы просто генерировать текст, Llama 3 на основе LangGraph позволяет агентам планировать, выполнять и обдумывать свои действия, делая их более интеллектуальными и способными.
В этом посте мы покажем, как создать систему langgraph agentic rag, используя LangGraph с Llama 3 и Milvus Lite. Эта настройка позволяет запускать все локально, без использования внешних серверов, что делает ее идеальной для пользователей, заботящихся о конфиденциальности, и оффлайновых сред.
Создание агента вызова инструментов с помощью LangGraph
Рабочий процесс LangGraph построен на концепции узлов, где каждый узел представляет собой определенную задачу или инструмент. Эти задачи могут включать вызов LLM, извлечение информации или вызов пользовательских инструментов. В агенте вызова инструмента участвуют два ключевых компонента:
Узел LLM: Этот узел решает, какой инструмент использовать, основываясь на данных, полученных от пользователя. Он анализирует запрос и выводит название инструмента и соответствующие аргументы.
Узел инструмента: Этот узел получает имя инструмента и аргументы от узла LLM, вызывает соответствующий инструмент и возвращает результат в LLM.
Структурируя задачи (например, веб-поиск) в виде узлов и ребер, LangGraph позволяет создавать интеллектуальные многоэтапные рабочие процессы, в которых LLM могут рассуждать о том, какие действия следует предпринять, какие инструменты использовать, какие ответы дать и как уточнить свои ответы. Milvus Lite играет здесь ключевую роль, обеспечивая эффективное хранение и поиск векторизованных данных локально.
Как Milvus Lite улучшает работу локальных агентов по вызову инструментов.
Milvus Lite - это облегченная локальная версия Milvus, для работы которой не требуется Docker или Kubernetes. Это позволяет легко запускать Milvus на ноутбуке, Jupyter-ноутбуке или даже в Google Colab. Локальное развертывание Milvus Lite позволяет хранить векторы, сгенерированные из различных веб-источников или документов, без необходимости полагаться на внешние базы данных. Он легко интегрируется с LangGraph для работы с векторным поиском, что делает его идеальным решением для локальных RAG систем.
Например, Milvus Lite можно использовать для хранения проиндексированных документов, которые агент извлекает во время веб-поиска. Когда агент запрашивает информацию, векторная база данных позволяет быстро и точно находить нужные документы.
Создание локальной RAG-системы с помощью LangGraph и Llama 3
Мы используем LangGraph для создания собственного локального RAG-агента на базе Llama 3.2, в котором применяются различные подходы:
Мы реализуем каждый подход в виде потока управления в LangGraph:
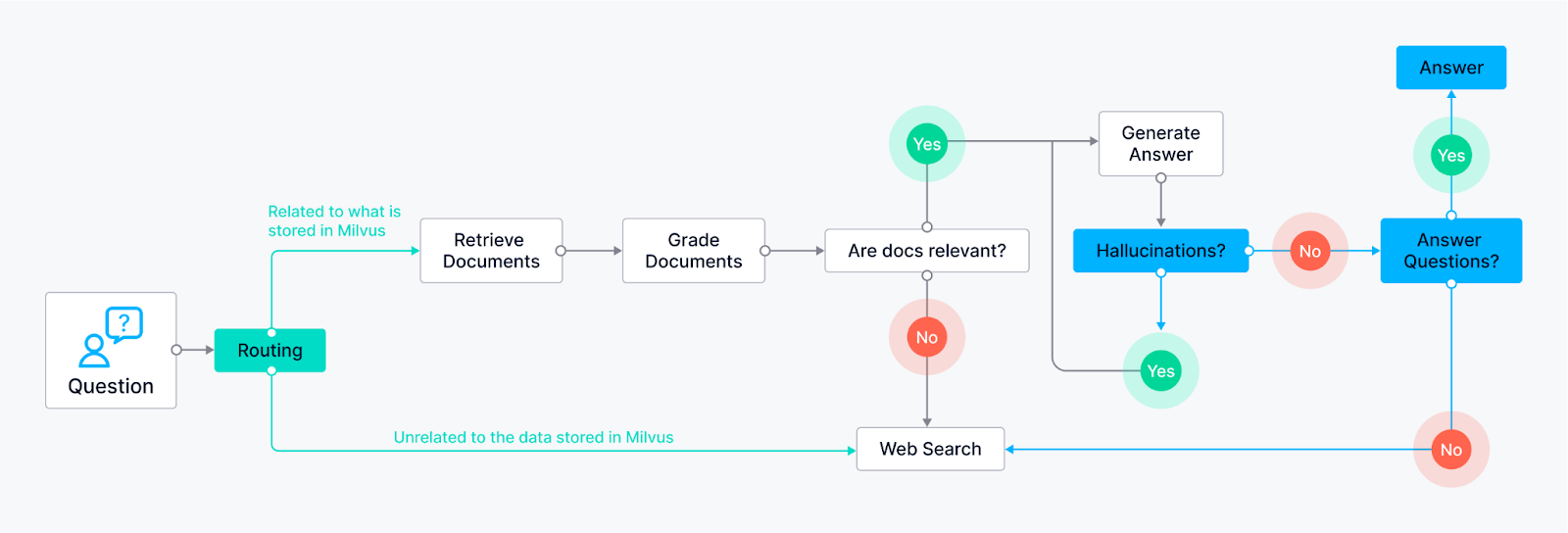
Маршрутизация (Adaptive RAG) - Позволяет агенту интеллектуально направлять запросы пользователя к наиболее подходящему методу поиска, основываясь на самом вопросе. Узел LLM анализирует запрос и, основываясь на ключевых словах или структуре вопроса, направляет его в определенные поисковые узлы.
Пример 1: Вопросы, требующие фактических ответов, могут быть направлены на узел поиска документов, осуществляющий поиск в предварительно проиндексированной базе знаний (на базе Milvus).
Пример 2: Открытые, творческие вопросы могут быть направлены в LLM для решения задач генерации.
Fallback (Corrective RAG) - Обеспечивает наличие у агента резервного плана, если его первоначальные методы поиска не дают релевантных результатов. Предположим, что начальные узлы поиска (например, поиск документов из базы знаний) не дают удовлетворительных ответов (на основе оценки релевантности или пороговых значений доверия). В этом случае агент возвращается к узлу веб-поиска.
- Узел веб-поиска может использовать внешние поисковые API.
Самокоррекция (Self-RAG) - позволяет агенту выявлять и исправлять собственные ошибки или вводящие в заблуждение результаты. Узел LLM генерирует ответ, а затем направляет его в другой узел для оценки. Этот узел оценки может использовать различные техники:
Отражение: Агент может сверить свой ответ с исходным запросом, чтобы убедиться, что в нем учтены все аспекты.
Анализ баллов доверия: LLM может присвоить ответу балл доверия. Если оценка ниже определенного порога, ответ направляется обратно в LLM для пересмотра.
Общие идеи для агентов
Отражение- Механизм самокоррекции - это форма отражения, когда агент LangGraph размышляет о своих поисках и генерациях. Он возвращает информацию обратно для оценки и позволяет агенту проявлять рудиментарную рефлексию, улучшая качество своего вывода с течением времени.
Планирование - Поток управления, представленный в графе, является формой планирования. Агент не просто реагирует на запрос, он разрабатывает пошаговый процесс получения или генерации наилучшего ответа.
Использование инструментов- Поток управления агента LangGraph включает в себя специальные узлы для различных инструментов. Они могут включать узлы поиска для базы знаний (например, Milvus), демонстрируя его способность работать с огромным объемом информации, и узлы веб-поиска для получения внешней информации.
Примеры агентов
Чтобы продемонстрировать возможности наших агентов LLM, давайте рассмотрим два ключевых компонента: Hallucination Grader и Answer Grader. Хотя полный код доступен в нижней части этого поста, эти фрагменты позволят лучше понять, как эти агенты работают в рамках фреймворка LangChain.
Hallucination Grader
Агент Hallucination Grader пытается решить распространенную проблему LLM: галлюцинации, когда модель генерирует ответы, которые звучат правдоподобно, но не имеют под собой фактической основы. Этот агент выступает в роли проверяющего факты, оценивая, соответствует ли ответ LLM предоставленному набору документов, извлеченных из Milvus.
### Оценщик галлюцинаций
# LLM
llm = ChatOllama(model=local_llm, format="json", temperature=0)
# Подсказка
prompt = PromptTemplate(
template="""Вы являетесь оценщиком, оценивающим, насколько
ответ обоснован / подкреплен набором фактов. Дайте бинарную оценку "да" или "нет", чтобы указать
обоснован ли ответ / подкреплен ли он набором фактов. Предоставьте бинарную оценку в виде JSON с
единственным ключом 'score' и без преамбулы или объяснения.
Вот факты:
{documents}
Вот ответ:
{поколение}
""",
input_variables=["generation", "documents"],
)
hallucination_grader = prompt | llm | JsonOutputParser()
hallucination_grader.invoke({"documents": docs, "generation": generation})
Грейдер ответов
Вслед за оценщиком галлюцинаций в дело вступает другой агент. Этот агент проверяет еще один важный аспект: соответствие ответа LLM исходному вопросу пользователя. Он использует тот же LLM, но с другой подсказкой, специально разработанной для оценки соответствия ответа вопросу.
def grade_generation_v_documents_and_question(state):
"""
Определяет, обоснована ли генерация в документе и отвечает ли на вопросы.
Args:
state (dict): Текущее состояние графа
Возвращает:
str: Решение для следующего узла для вызова
"""
print("---ПРОВЕРИТЬ ХАЛЯВУ---")
вопрос = state["вопрос"]
документы = state["documents"]
поколение = state["generation"]
score = hallucination_grader.invoke({"documents": documents, "generation": generation})
оценка = score['score']
# Проверьте галлюцинацию
if grade == "yes":
print("--- РЕШЕНИЕ: GENERATION IS GROUNDED IN DOCUMENTS---")
# Проверяем ответы на вопросы
print("---GRADE GENERATION vs QUESTION---")
score = answer_grader.invoke({"вопрос": question, "поколение": generation})
оценка = score['score']
if grade == "yes":
print("--- РЕШЕНИЕ: ГЕНЕРАЦИЯ УДОВЛЕТВОРЯЕТ ВОПРОСУ---")
return "useful"
else:
print("---РЕШЕНИЕ: ГЕНЕРАЦИЯ НЕ УДОВЛЕТВОРЯЕТ ВОПРОСУ---")
возврат "не полезно"
else:
pprint("---РЕШЕНИЕ: ГЕНЕРАЦИЯ НЕ ПОДТВЕРЖДАЕТСЯ ДОКУМЕНТАМИ, повторите попытку---")
возврат "не поддерживается"
В приведенном выше коде видно, что мы проверяем предсказания LLM, который мы используем в качестве классификатора.
Компиляция графа LangGraph
Это скомпилирует все агенты, которые мы определили, и позволит использовать различные инструменты для вашей системы RAG.
# Компиляция
app = workflow.compile()
# Тест
из pprint import pprint
inputs = { "Вопрос": "Что такое оперативное проектирование?"}
for output in app.stream(inputs):
for key, value in output.items():
pprint(f "Завершено выполнение: {ключ}:")
pprint(value["generation"])
'Finished running: generate:'
('Проектирование подсказок - это процесс взаимодействия с большими языковыми '
'моделями (LLM), чтобы направить их поведение к желаемому результату без '
'обновления весов модели. Он фокусируется на выравнивании и управляемости модели, '
'требуя экспериментов и эвристики из-за различий в эффектах '
'моделей. Цель - улучшить управляемую генерацию текста, оптимизировав '
'подсказки для конкретных приложений').
Заключение
В этом блоге мы показали, как построить систему RAG с использованием агентов LangChain/ LangGraph, Llama 3.2 и Milvus. Эти агенты позволяют LLM иметь возможности планирования, памяти и использования различных инструментов, что может привести к более надежным и информативным ответам.
Следующие шаги по улучшению
Хотя текущая реализация системы agentic RAG эффективна для локальных, одноагентных рабочих процессов, есть несколько интересных направлений для дальнейшего совершенствования и инноваций.
Многоагентная координация: В настоящее время LangGraph используется для проектирования одноагентных систем, которые работают в рамках предопределенного потока управления, например, веб-поиска. Однако естественным шагом будет расширение этой системы для поддержки нескольких агентов, работающих параллельно или в координации. В сценариях, когда задача требует специальных знаний или нескольких источников поиска, агенты могут совместно обрабатывать различные части задачи. Например, один агент может сосредоточиться на поиске фактической информации, другой - на решении творческих задач или взаимодействии с пользователем, а третий - на оценке общего качества результата. Такие мультиагентные системы позволят выполнять более сложные операции, что приведет к повышению эффективности и точности обработки разнообразных запросов.
Real-Time Data** Updates:** Еще одним потенциальным улучшением может стать предоставление агентам возможности обновлять свои источники данных в режиме реального времени. В настоящее время Milvus Lite служит статичной базой знаний, однако в динамичных областях информация может быстро устаревать. Агенты могут быть спроектированы таким образом, чтобы постоянно отслеживать и обновлять свое локальное хранилище векторов свежими данными из Интернета или других API, гарантируя, что результаты работы системы остаются актуальными и свежими. Например, если агента спрашивают о последних ценах на акции или срочных новостях, он может автоматически получить самые свежие данные, что делает систему гораздо более адаптируемой и полезной в быстро меняющихся средах.
Усовершенствованная рефлексия и самосовершенствование: Хотя текущий механизм рефлексии полезен, есть возможности для улучшения самокоррекции. В будущих версиях агента могут быть использованы более продвинутые техники, такие как обучение с подкреплением или механизмы непрерывного обучения, позволяющие агенту со временем учиться на своем прошлом опыте и ошибках. Позволив агенту работать с памятью, чтобы итеративно улучшать качество своих ответов, мы сможем создать систему, которая не только будет находить и генерировать высококачественные ответы, но и совершенствовать свои процессы на основе обратной связи.
Реализовав эти следующие шаги, мы сможем значительно расширить возможности агентных RAG-систем, сделав их более гибкими, адаптивными и эффективными при решении сложных задач в различных отраслях.
Не стесняйтесь проверять код, доступный в репозитории Milvus Bootcamp.
Если вам понравилась эта статья в блоге о том, как построить агентурную систему langgraph, поставьте нам звезду на сайте , а также поделитесь своим опытом с сообществом, присоединившись к нашей группе
Это вдохновлено Github Repository от Meta с рецептами по использованию Llama 3

Читать далее

Zilliz Cloud Just Landed in Claude Code
The Zilliz Cloud Plugin brings the full power of Zilliz Cloud directly into your Claude Code terminal as natural-language conversations.

Smarter Autoscaling in Zilliz Cloud: Always Optimized for Every Workload
With the latest upgrade, Zilliz Cloud introduces smarter autoscaling—a fully automated, more streamlined, elastic resource management system.

Zilliz Cloud Launches in AWS Australia, Expanding Global Reach to Australia and Neighboring Markets
We're thrilled to announce that Zilliz Cloud is now available in the AWS Sydney, Australia region (ap-southeast-2).