




Compreendendo o Deep Reinforcement Learning (DRL): Um Guia Abrangente

Resposta curta: Deep Reinforcement Learning (DRL) é um campo da IA em que um agente aprende a tomar decisões interagindo com um ambiente e melhorando ao longo do tempo com base em feedback ou "recompensas." O DRL combina reinforcement learning (RL), um método de aprendizado por tentativa e erro, com deep learning, que permite ao agente lidar com dados complexos, como imagens ou leituras de sensores. O DRL pode usar redes neurais profundas para ensinar agentes a navegar por tarefas complicadas com entradas de alta dimensionalidade. É amplamente usado em aplicações como robótica e jogos, onde métodos tradicionais de aprendizado têm dificuldade devido à complexidade e variabilidade do ambiente.
Compreendendo o Deep Reinforcement Learning (DRL): Um Guia Abrangente
Em 2016, quando AlphaGo derrotou o campeão mundial Lee Sedol no Go—um jogo com mais movimentos possíveis do que átomos no universo—isso marcou um momento decisivo na tecnologia empresarial. O segredo por trás dessa vitória? Deep Reinforcement Learning—um método que treina computadores para melhorar por meio da prática, assim como um tenista que aperfeiçoa seu saque após anos em quadra. Onde programas de computador tradicionais têm dificuldade com mudanças inesperadas, essa tecnologia se destaca em situações que mudam constantemente—desde orientar robôs em armazéns movimentados até tomar decisões rápidas em negociações de ações. Essa nova abordagem de machine learning abre portas para empresas, enfrentando problemas que antes eram complexos demais para softwares comuns resolverem.
Este guia oferece uma exploração aprofundada do deep reinforcement learning, destacando conceitos-chave, suas diversas aplicações, suas vantagens e os desafios que podem surgir em sua implementação.
O que é Deep Reinforcement Learning?
Deep Reinforcement Learning (DRL) combina duas técnicas eficazes de IA, Reinforcement Learning (RL) e Deep Learning, permitindo que agentes de IA aprendam ações ideais por tentativa e erro em ambientes complexos. No RL, um agente interage com seu ambiente e ajusta seu comportamento com base em recompensas e estratégias de aprendizado para maximizar recompensas de longo prazo. O deep learning acrescenta a capacidade de lidar com representações detalhadas de estado usando redes neurais.
Por exemplo, um robô navegando por um labirinto se move aleatoriamente no início, mas, com o tempo, aprende a alcançar o objetivo de forma eficiente por meio de feedback. O DRL ajuda agentes a se adaptarem a ambientes dinâmicos e a resolver problemas complexos sem instruções detalhadas. É útil em videogames, carros autônomos e recomendações pessoais. Ao combinar Reinforcement Learning e Deep Learning, agentes de DRL conseguem lidar efetivamente com tarefas complicadas do mundo real.
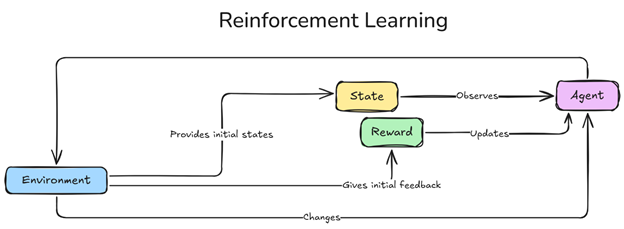 Figure 1 Reinforcement Learning Framework.png
Figure 1 Reinforcement Learning Framework.png
Como o Deep Reinforcement Learning Funciona
Para entender como o DRL funciona, é importante conhecer seus componentes principais:
Agente
Ambiente
Estado
Ações e Recompensas
Política
Agente
O agente é o tomador de decisões encarregado de navegar pelo ambiente e fazer escolhas para maximizar recompensas cumulativas ao longo do tempo. Por meio de interações repetidas (episódios de aprendizado), o agente refina sua estratégia com base em feedback, ajustando seu comportamento para alcançar sucesso de longo prazo. Assim como um jogador em um jogo, as ações do agente são guiadas por uma política—um conjunto de regras aprendido ao longo do tempo para melhorar o desempenho e alcançar resultados ideais.
Ambiente
O ambiente é o espaço estruturado dentro do qual o agente opera, definindo estados, ações e recompensas possíveis. Ele reage a cada ação do agente, fornecendo feedback que influencia as decisões futuras do agente e molda seu processo de aprendizado.
Estado
O estado representa um instantâneo do ambiente em um momento específico, contendo informações importantes para a tomada de decisões do agente. Por exemplo, um estado pode incluir a posição de um agente e obstáculos em um labirinto ou a velocidade de um veículo e a proximidade de outros carros. Cada estado ajuda o agente a avaliar sua situação e selecionar a ação mais vantajosa.
Ações e Recompensas
As ações representam as escolhas de um agente em cada estado, direcionando seu caminho pelo ambiente. As ações podem ser:
Ações Discretas: Opções limitadas, como mover para cima, para baixo, para a esquerda ou para a direita, em ambientes de grade facilitam a exploração e o desenvolvimento de políticas pelos agentes.
Ações Contínuas: Estas incluem uma faixa de valores, como ajustar a velocidade ou o ângulo, que exigem modelos avançados para lidar com o aumento da complexidade.
O agente busca realizar ações ideais ao longo do tempo e maximizar as recompensas.
As recompensas fornecem feedback para orientar o aprendizado do agente. Recompensas positivas sinalizam ações bem-sucedidas, enquanto recompensas negativas penalizam erros. As recompensas podem incluir:
Recompensas Imediatas: Estas são dadas diretamente após uma ação, como marcar pontos por capturar uma peça do oponente no xadrez.
Recompensas Atrasadas: Obtidas após concluir uma sequência de ações, como navegar por um labirinto.
É importante projetar a estrutura de recompensas, conhecida como modelagem de recompensas. Por exemplo, recompensas intermediárias ao longo de um caminho complexo podem acelerar o aprendizado, motivando o agente a tomar medidas específicas em direção ao objetivo final.
 Figura- arquitetura de Aprendizado por Reforço.png
Figura- arquitetura de Aprendizado por Reforço.png
Figura: arquitetura de Aprendizado por Reforço
O Processo de Aprendizado
O processo de aprendizado ou treinamento do aprendizado por reforço profundo é um ciclo iterativo de interação, feedback e melhoria que envolve:
Exploração
Exploitação
Redes Neurais Profundas
Retropropagação
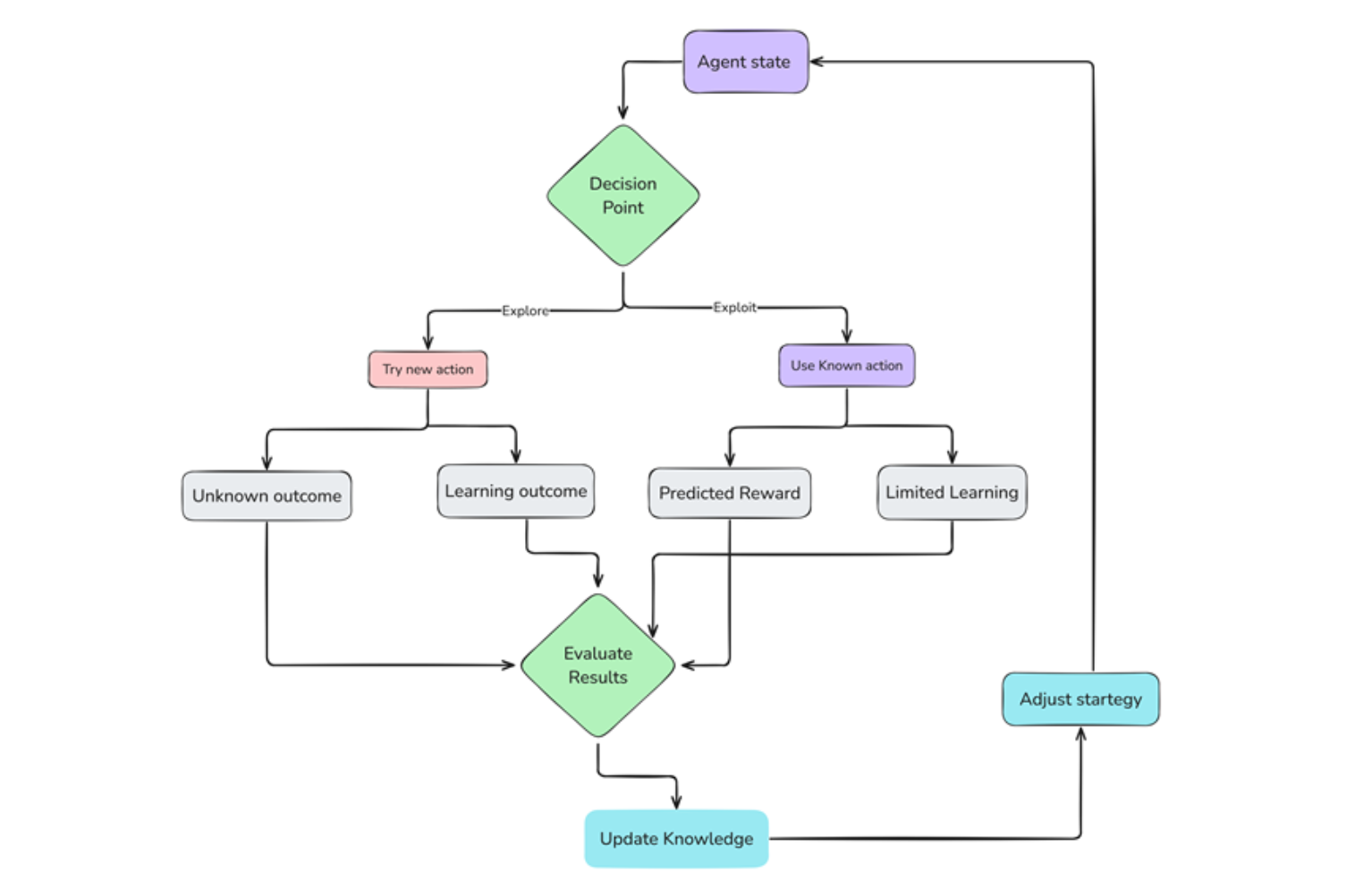
Exploração
Inicialmente, o agente não conhece o ambiente. Ele começa explorando aleatoriamente, testando diferentes ações e observando as consequências. Essa fase de exploração é importante para coletar informações ambientais e descobrir ações recompensadoras.
Exploitação
À medida que o agente explora e acumula experiência, ele começa a identificar ações que levam a recompensas positivas. Então, ele explora esse conhecimento, escolhendo essas ações com mais frequência para maximizar suas recompensas.
Redes Neurais Profundas
O agente usa redes neurais profundas para aproximar a política e a função de valor do agente.
Rede de Política: Esta rede recebe o estado atual como entrada e produz a probabilidade de executar diferentes ações.
Rede de Valor: Esta rede estima o valor de longo prazo de estar em um estado específico, ajudando o agente a tomar decisões que levam a recompensas cumulativas maiores. Essas redes neurais permitem que o agente aprenda padrões e relações ambientais complexas, ajudando a tomar decisões mais inteligentes.
 Processo de Exploração vs Exploitação .png
Processo de Exploração vs Exploitação .png
Figura 3 Processo de Exploração vs Exploitação
Retropropagação
Retropropagação, abreviação de "propagação retroativa de erros," é um algoritmo fundamental no treinamento de redes neurais. Ela ajusta os pesos em uma rede neural para minimizar o erro nas previsões.
A retropropagação ajuda os agentes a melhorar seus modelos de tomada de decisão por meio do aprendizado a partir de feedback. Quando um agente realiza uma ação, ele recebe feedback sobre quão boa ou ruim foi essa ação (na forma de uma recompensa). A retropropagação então ajusta os pesos da rede neural, reduzindo o erro entre os resultados previstos e as recompensas reais. Ao aplicar a retropropagação repetidamente, a rede neural aprende a aproximar melhor as funções de valor ou de política, levando a decisões mais precisas. Esse processo permite que o agente melhore gradualmente sua compreensão do ambiente e tome decisões cada vez mais ótimas ao longo do tempo, o que é essencial para dominar tarefas complexas em ambientes dinâmicos e de alta dimensionalidade.
Algoritmos populares em aprendizado por reforço profundo
O DRL emprega uma variedade de algoritmos, cada um projetado para enfrentar diferentes desafios no processo de aprendizado. Aqui estão alguns dos métodos mais amplamente utilizados:
Q-Learning: O Q-Learning é um dos algoritmos fundamentais de aprendizado por reforço. Ele estima o valor de pares estado-ação, chamados de valores Q, ajudando o agente a determinar quais ações são preferíveis em determinados estados. O algoritmo atualiza esses valores Q com base em recompensas imediatas e recompensas futuras esperadas, refinando gradualmente as escolhas do agente para favorecer ações com maior valor a longo prazo.
Deep Q-Networks (DQN): O DQN aprimora o Q-learning ao utilizar redes neurais para aproximar valores Q. Essa abordagem torna as DQNs eficazes em ambientes complexos, como IA para jogos, navegação robótica e direção autônoma.
Policy Gradients: Ao contrário dos métodos baseados em valor, os algoritmos de gradiente de política otimizam diretamente a política de um agente ajustando os pesos de uma rede neural com base nas recompensas recebidas. Essa abordagem permite que o agente melhore o desempenho aumentando a probabilidade de ações bem-sucedidas, o que é especialmente importante em tarefas de controle que exigem ajustes precisos, como a manipulação de braços robóticos.
Actor-Critic Methods: Abordagens híbridas combinam os pontos fortes dos métodos baseados em política, que visam estimar o valor de cada ação em um determinado estado, e dos métodos baseados em valor, que se concentram em aprender diretamente a política ideal. Nesse arcabouço, o ator é responsável por selecionar ações, enquanto o crítico avalia essas ações e fornece feedback. Esse feedback permite melhorias contínuas na política.
Comparação do aprendizado por reforço profundo com outros conceitos
O aprendizado por reforço profundo (DRL) é frequentemente comparado com outras abordagens de IA. Para esclarecer diferenças e semelhanças, vamos detalhar os principais aspectos:
| Aspecto | Aprendizado por Reforço Profundo (DRL) | Aprendizado por Reforço Regular (RL) | Aprendizado Supervisionado | Aprendizado Não Supervisionado | |
| Conceito Central e Tratamento de Dados | Combina RL com redes neurais profundas; processa dados complexos e de alta dimensionalidade | Foca em RL com modelos mais simples; funciona bem em ambientes de baixa dimensionalidade | Aprende a partir de dados rotulados com saídas predefinidas; depende de conjuntos de dados rotulados | Encontra padrões em dados não rotulados; trabalha com conjuntos de dados não rotulados | |
| Processo de Aprendizado | Tentativa e erro por meio da interação com o ambiente. | Tentativa e erro por meio do feedback do ambiente. | Aprende padrões a partir de pares entrada-saída rotulados. | Identifica clusters ou estruturas em dados. | |
| Objetivo | Maximizar recompensas cumulativas ao longo do tempo. | Maximizar recompensas cumulativas ao longo do tempo. | Prever saídas com base nos dados de entrada. | Descobrir padrões ocultos ou agrupamentos nos dados. | |
| Aplicações | Tarefas complexas: IA para jogos, robótica, veículos autônomos. | Sistemas de controle básicos e tarefas simples de tomada de decisão. | Classificação, regressão, modelagem preditiva. | Agrupamento, redução de dimensionalidade, detecção de anomalias. |
Benefícios e Desafios da Aprendizagem por Reforço Profundo
A aprendizagem por reforço profundo tem muitas possibilidades, mas é importante saber no que ela é boa e onde pode deixar a desejar. Vamos analisar alguns dos principais benefícios e desafios do DRL.
Benefícios:
Adaptabilidade: Um benefício fundamental do DRL é sua adaptabilidade. Agentes de DRL conseguem lidar com situações novas e inesperadas sem exigir programação adicional. Por exemplo, um veículo autônomo alimentado por DRL pode responder a mudanças repentinas na estrada, como obstáculos ou condições climáticas adversas, ajustando seu comportamento para navegar com segurança.
Tomada de Decisão Otimizada: O DRL também permite uma tomada de decisão mais inteligente e, muitas vezes, mais eficaz. Ao contrário dos sistemas tradicionais baseados em regras, os modelos de DRL podem descobrir estratégias que até mesmo projetistas humanos poderiam deixar passar. Em finanças, por exemplo, o DRL tem sido aplicado com sucesso para criar bots de negociação que frequentemente tomam decisões mais lucrativas do que sistemas convencionais.
Potencial de Automação: O DRL permite a automação de tarefas em áreas como movimentação de mercadorias, cuidados médicos e atendimento a clientes. Nessas áreas frequentemente complicadas e em constante mudança, o DRL ajuda a tornar as coisas mais fáceis ao automatizá-las.
Desafios:
Eficiência de Amostras: Um dos maiores desafios do DRL é sua demanda por enormes quantidades de dados de treinamento. Modelos de DRL normalmente exigem dados extensos para ter bom desempenho, o que pode ser caro e demorado de coletar. Técnicas como experience replay ajudam ao permitir que os modelos aprendam com dados passados, mas melhorias na eficiência de dados ainda são necessárias para tornar o DRL mais prático.
Design de Recompensa: Outro desafio está em projetar funções de recompensa eficazes. Definir as recompensas corretas é crucial porque recompensas mal projetadas podem levar a comportamentos não intencionais e, às vezes, problemáticos dos agentes. Como resultado, o design de recompensa em DRL exige planejamento cuidadoso para garantir que os agentes ajam de maneiras alinhadas com seus objetivos pretendidos.
Estabilidade e Convergência: Por fim, o treinamento de DRL pode ser instável. Às vezes, os modelos ficam presos em estratégias abaixo do ideal ou não conseguem alcançar uma solução estável. Melhorar a estabilidade do treinamento é essencial para tornar os modelos de DRL mais confiáveis, especialmente para aplicações de alto risco, em que a consistência é fundamental.
Aplicações Reais da Aprendizagem por Reforço Profundo
Agora que exploramos o funcionamento da aprendizagem por reforço profundo (DRL), vamos mudar nosso foco para suas aplicações práticas. O DRL está sendo usado para resolver problemas do mundo real em diversos domínios. Incluindo:
Jogos: O DRL possibilitou a criação de agentes de IA avançados que se destacam em jogos como Chess, Go e Dota 2. Para aqueles interessados em exploração prática, Unity ML-Agents fornece um kit de ferramentas acessível para experimentar com aprendizagem baseada em jogos.
Robótica: Na robótica, o DRL ensina habilidades às máquinas, como navegar e manipular objetos. O DRL se mostra altamente eficaz em armazéns, permitindo que robôs se adaptem a novos layouts e tarefas em mudança, aumentando a eficiência das operações.
Veículos Autônomos: Em carros autônomos, o DRL desempenha um papel crucial na tomada de decisões em frações de segundo para mudanças de faixa, desvio de obstáculos ou ajuste de velocidade. Waymo, por exemplo, usa DRL para ajudar seus veículos a fazer escolhas seguras em situações de tráfego complexas.
Negociação Financeira: O DRL também é amplamente usado em finanças para desenvolver bots de negociação que respondem a mudanças no mercado. Usando abordagens como Deep Q-Learning, bots de negociação alimentados por DRL analisam tendências históricas e dados em tempo real para tomar decisões informadas de compra, manutenção ou venda, frequentemente alcançando resultados melhores do que estratégias de negociação manuais.
Recomendações personalizadas: O DRL impulsiona sistemas de recomendação cada vez mais avançados. Para fornecer recomendações sob medida, os algoritmos de DRL analisam o comportamento e as preferências dos usuários em serviços de streaming, lojas online e plataformas de mídia social. Ao observar as ações dos usuários, o DRL pode recomendar conteúdo ou produtos que se alinham mais estreitamente às preferências individuais.
Perguntas frequentes sobre Deep Reinforcement Learning
- Como um agente aprende em deep reinforcement learning?
No DRL, um agente aprende realizando ações em um ambiente e recebendo feedback na forma de recompensas. O agente usa exploração (experimentar novas ações) para descobrir estratégias eficazes e aproveitamento (usar ações conhecidas) para maximizar recompensas. Redes neurais profundas ajudam o agente a generalizar a partir de suas experiências e a se adaptar a cenários complexos.
- Como os modelos de deep reinforcement learning equilibram exploração e aproveitamento?
Os modelos de DRL equilibram exploração (experimentar novas ações para descobrir estratégias melhores) e aproveitamento (usar ações conhecidas para maximizar recompensas) por meio de algoritmos como epsilon-greedy ou Thompson Sampling. Essas técnicas ajudam a manter um equilíbrio, garantindo que o agente descubra novas estratégias enquanto maximiza recompensas conhecidas.
- Como as funções de valor funcionam em deep reinforcement learning?
As funções de valor estimam a recompensa esperada de estar em um determinado estado (função de valor de estado) ou de realizar uma ação específica em um determinado estado (função de valor de ação). Elas ajudam o agente a priorizar estados e ações que levam a recompensas mais altas, orientando a tomada de decisões.
- Como o DRL pode ser usado com o Milvus para aplicações de IA?
O Milvus pode armazenar e gerenciar as representações de estado de alta dimensionalidade geradas por agentes de DRL. Ele pode servir como um buffer de repetição para experiências passadas ou auxiliar no armazenamento de representações de estado, aumentando a eficiência da otimização de políticas e da estimativa de valor.
- Quais são as preocupações éticas do uso de deep reinforcement learning?
As preocupações éticas incluem possíveis vieses nos dados de treinamento, comportamentos não intencionais decorrentes de funções de recompensa mal projetadas e questões de justiça em aplicações sensíveis. Para mitigar esses riscos, é crucial implementar testes robustos, transparência e IA explicável.
Recursos relacionados
Para explorar mais, considere estes recursos:
Artigo: [1811.12560] An Introduction to Deep Reinforcement Learning
Entendendo a regularização de redes neurais e as principais técnicas de regularização
Tornando o machine learning mais acessível para desenvolvedores
Evolução da busca: da correspondência de palavras-chave à busca vetorial e GenAI
Introdução à busca por similaridade vetorial - blog da Zilliz
Modelos de IA de melhor desempenho para seus aplicativos GenAI | Zilliz
- O que é Deep Reinforcement Learning?
- Como o Deep Reinforcement Learning Funciona
- Algoritmos populares em aprendizado por reforço profundo
- Comparação do aprendizado por reforço profundo com outros conceitos
- Benefícios e Desafios da Aprendizagem por Reforço Profundo
- Aplicações Reais da Aprendizagem por Reforço Profundo
- Perguntas frequentes sobre Deep Reinforcement Learning
- Recursos relacionados
Conteúdo
Comece grátis, escale facilmente
Experimente o banco de dados totalmente gerenciado, construído para seus aplicativos GenAI.
Experimente o Zilliz Cloud grátis