




Melhores práticas na implementação de aplicações RAG (Retrieval-Augmented Generation)
A [Geração de Recuperação-Aumentada] (https://zilliz.com/learn/Retrieval-Augmented-Generation) (RAG) é um método que se tem revelado muito eficaz na melhoria das respostas dos LLMs e na abordagem das [alucinações dos LLMs] (https://zilliz.com/glossary/ai-hallucination). Em poucas palavras, o RAG fornece aos LLMs um contexto que pode ajudá-los a gerar respostas mais precisas e contextualizadas. Os contextos podem vir de qualquer lugar: dos seus documentos internos, bases de dados vectoriais, ficheiros CSV, ficheiros JSON, etc.
O RAG é uma abordagem inovadora que consiste em muitos componentes que funcionam em conjunto. Estes componentes incluem o processamento de consultas, context chunking, a recuperação de contextos, context reranking, e o próprio LLM para gerar a resposta. Cada componente influencia a qualidade da resposta final gerada a partir de uma aplicação RAG. O problema é que é difícil encontrar a melhor combinação de métodos em cada componente que conduza ao melhor desempenho do RAG.
Neste artigo, discutiremos várias técnicas habitualmente utilizadas em todos os componentes do RAG, avaliaremos a melhor abordagem para cada componente e, em seguida, encontraremos a melhor combinação que conduz à resposta gerada pelo RAG mais optimizada, de acordo com este documento. Assim, sem mais demoras, comecemos por uma introdução aos componentes RAG.
Componentes RAG
Como mencionado, o RAG é um método poderoso para aliviar os problemas de alucinação dos LLMs, que geralmente ocorrem quando fazemos perguntas além de seus dados de treinamento ou quando exigem conhecimento especializado. Por exemplo, se fizermos uma pergunta a um LLM sobre os nossos dados internos, é provável que obtenhamos uma resposta incorrecta. O RAG resolve este problema fornecendo ao nosso LLM um contexto que pode ajudar a responder à nossa pergunta.
O RAG é constituído por uma cadeia de componentes que formam um fluxo de trabalho. Os componentes típicos do RAG incluem:
Classificação da consulta: para determinar se a nossa consulta necessita de recuperação de contextos ou se pode ser processada diretamente pelo LLM.
Recuperação de contextos**: para obter os k melhores candidatos nos contextos mais relevantes para a nossa consulta.
Ordenação de contextos**: ordenar os k melhores candidatos obtidos a partir da componente de recuperação, começando pelo mais semelhante.
Reempacotamento de contextos: para organizar os contextos mais relevantes num formato mais estruturado para uma melhor geração de respostas.
Resumir o contexto: extrair informações-chave dos contextos relevantes para melhorar a geração de respostas.
Geração de resposta:** para gerar uma resposta com base na consulta e nos contextos relevantes.
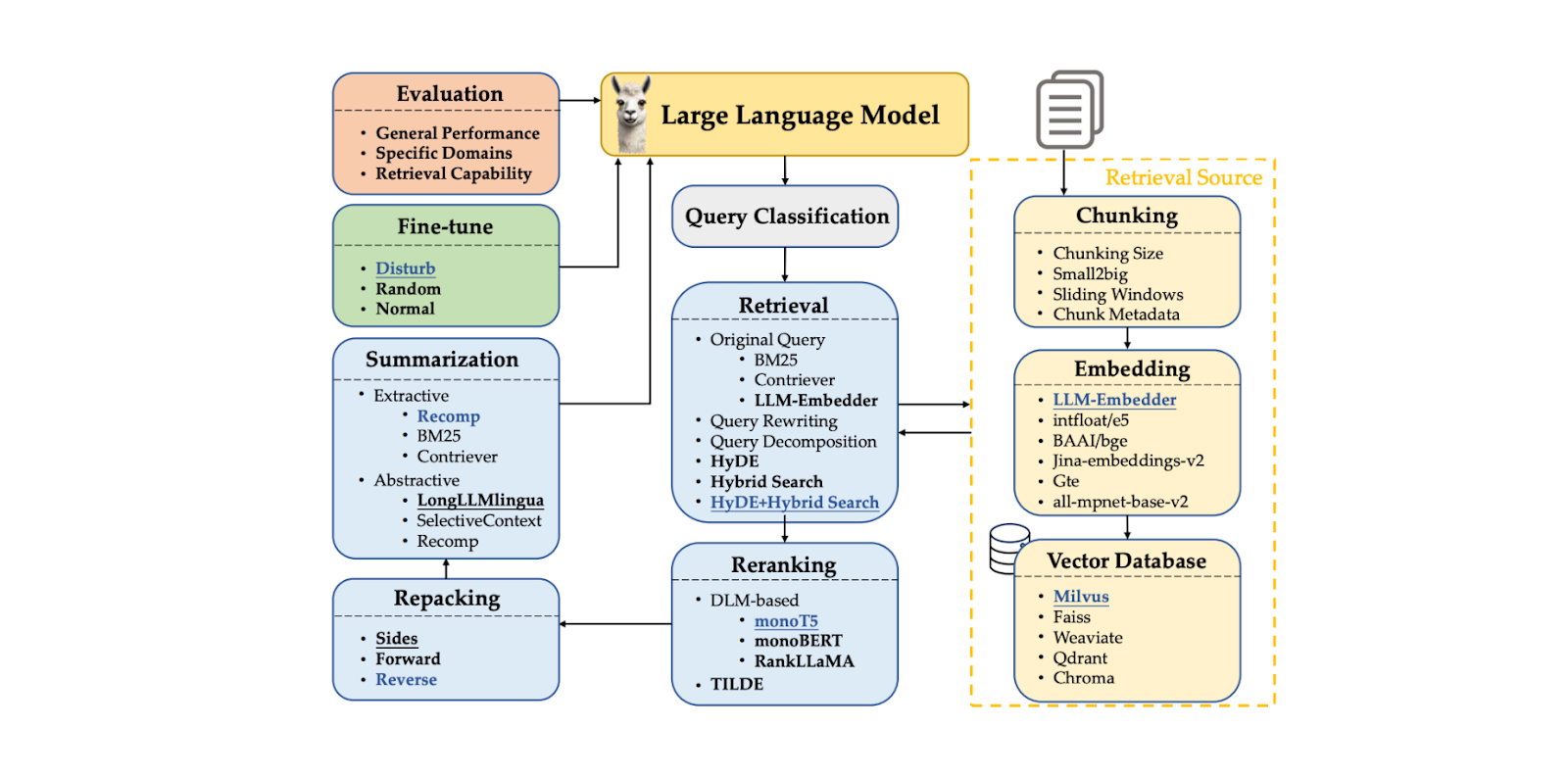 Figura - Componentes RAG..png
Figura - Componentes RAG..png
Figura: Componentes RAG. Fonte
Embora esses componentes RAG sejam úteis durante o processo de geração de resposta (ou seja, quando já armazenamos todos os contextos e eles estão prontos para serem buscados), vários outros fatores devem ser considerados antes de implementar um método RAG.
Precisamos de transformar os nossos documentos de contexto em embeddings vectoriais para tornar os nossos documentos de contexto úteis numa abordagem RAG. Por conseguinte, é crucial escolher[ o modelo de incorporação mais adequado] (https://zilliz.com/blog/choosing-the-right-embedding-model-for-your-data) e a estratégia para representar os nossos documentos de entrada como incorporação.
Uma incorporação contém uma representação semanticamente rica do nosso documento de entrada. No entanto, se o documento utilizado como contexto for demasiado longo, pode confundir o LLM ao gerar uma resposta adequada. Uma abordagem comum para resolver este problema é aplicar um método de fragmentação (chunking), em que dividimos o nosso documento de entrada em vários pedaços e, em seguida, transformamos cada pedaço numa incorporação. É crucial escolher o melhor método e tamanho de chunking, uma vez que os chunks demasiado curtos conterão provavelmente informação insuficiente.
 Figure- RAG workflow.png
Figure- RAG workflow.png
Figura: Fluxo de trabalho do RAG
Temos de considerar o armazenamento adequado para estas incorporações depois de transformarmos cada pedaço numa incrustação. Se não estiver a lidar com muitos embeddings, pode armazená-los diretamente na memória local do seu dispositivo. No entanto, na prática, é comum lidar com centenas ou mesmo milhões de embeddings. Neste caso, é necessária uma base de dados vetorial como Milvus ou o seu serviço gerido, Zilliz Cloud, para os armazenar, e a escolha da base de dados vetorial correta é crucial para o sucesso da nossa aplicação RAG.
A última consideração é o próprio LLM. Se for caso disso, podemos afinar o LLM para responder com maior precisão às nossas necessidades específicas. No entanto, o ajuste fino é dispendioso e desnecessário na maioria dos casos, especialmente se estivermos a utilizar uma LLM de elevado desempenho com muitos parâmetros.
Nas secções seguintes, discutiremos as melhores abordagens para cada componente das RAG. Em seguida, exploraremos as combinações dessas melhores abordagens e sugeriremos várias estratégias para implantar o RAG que equilibram desempenho e eficiência.
Classificação da consulta
Como mencionado na secção anterior, o RAG é útil para garantir que o LLM gere respostas precisas e contextualizadas, especialmente quando é necessário conhecimento especializado dos nossos dados internos. No entanto, o RAG também aumenta o tempo de execução do processo de geração de respostas. O que acontece é que nem todas as consultas requerem o processo de recuperação, e muitas delas podem ser processadas diretamente pelo LLM. Por conseguinte, saltar o processo de recuperação de contexto seria mais vantajoso se uma consulta não necessitasse dele.
Podemos implementar um modelo de [classificação] de consultas (https://zilliz.com/glossary/classification) para determinar se uma consulta precisa de recuperação de contexto antes do processo de geração de resposta. Esse modelo de classificação consiste normalmente num modelo supervisionado, como o BERT, com o objetivo principal de prever se uma consulta necessita ou não de recuperação. No entanto, tal como outros modelos supervisionados, é necessário treiná-lo antes de o utilizar para inferência. Para treinar o modelo, precisamos de gerar um conjunto de dados com exemplos de mensagens e as respectivas etiquetas binárias, incluindo se a mensagem precisa de ser recuperada ou não.
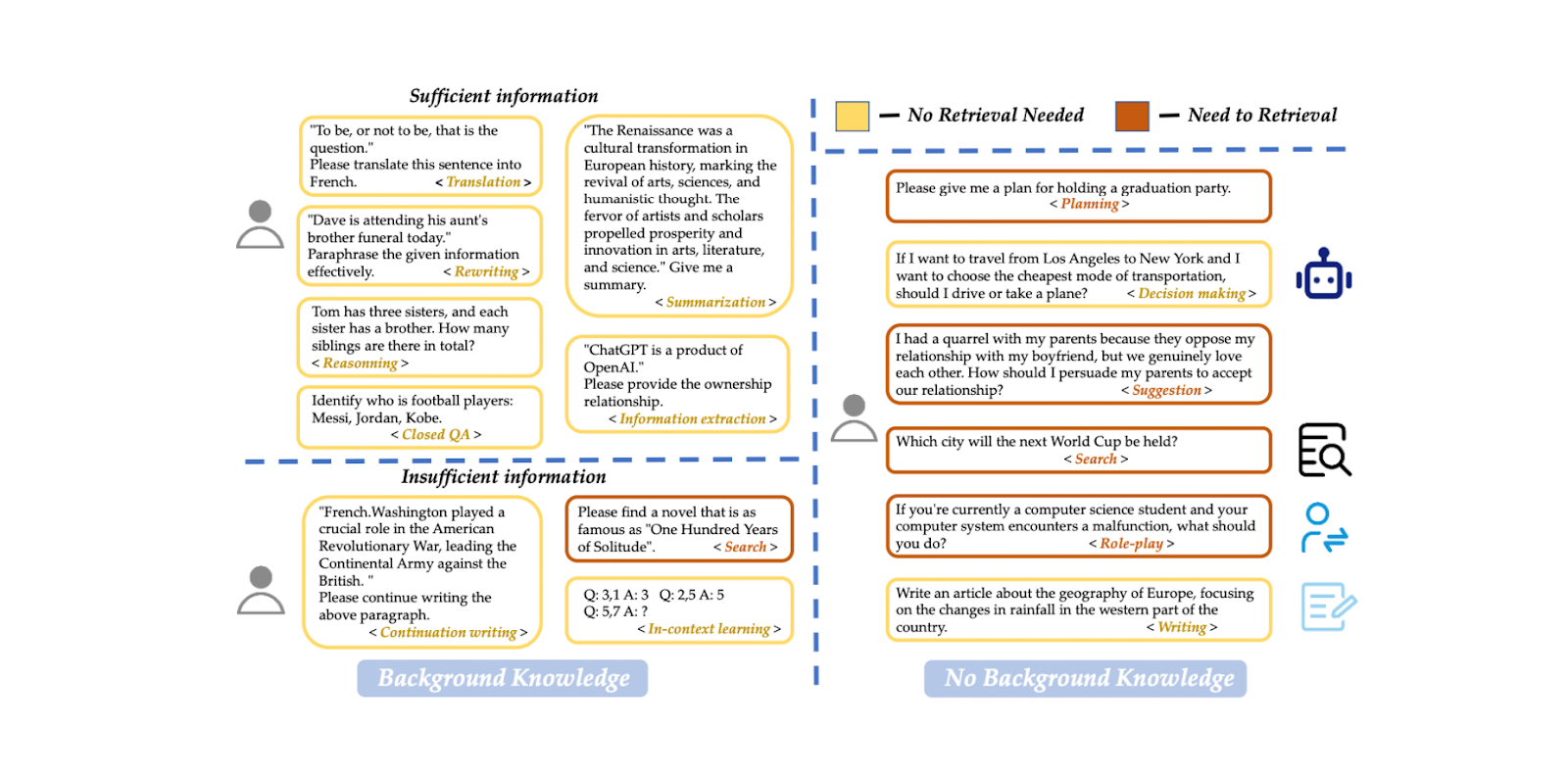 Figura - Exemplo de conjunto de dados de classificação de consultas..png
Figura - Exemplo de conjunto de dados de classificação de consultas..png
Figura: Exemplo de conjunto de dados de classificação de consultas. Source
No artigo, é utilizado um modelo BERT-multilingue para a classificação de consultas. Os dados de treino incluem um total de 15 tipos de pedidos, tais como tradução, resumo, reescrita, aprendizagem no contexto, etc. Existem duas etiquetas distintas: "suficiente" se o pedido for inteiramente baseado em informações fornecidas pelo utilizador e não necessitar de recuperação, e "insuficiente" se as informações do pedido estiverem incompletas, necessitarem de informações especializadas e exigirem um processo de recuperação. Utilizando esta abordagem, o modelo atingiu 95% de exatidão e de pontuação F1.
Este passo de classificação da consulta pode melhorar significativamente a eficiência do processo RAG, evitando recuperações desnecessárias de consultas que podem ser tratadas diretamente pelo LLM. Actua como um filtro, garantindo que apenas as consultas que requerem contexto adicional são enviadas através do processo de recuperação mais demorado.
 Figura - Resultado do classificador de consultas..png
Figura - Resultado do classificador de consultas..png
Figura: Resultado do classificador de consultas. Fonte
Técnica de fragmentação
Chunking refere-se ao processo de divisão de documentos de entrada longos em segmentos mais pequenos. Este processo é muito útil para fornecer ao LLM um contexto mais granular. Existem vários métodos de fragmentação, incluindo abordagens ao nível dos tokens e ao nível das frases. A fragmentação ao nível da frase conduz frequentemente a um bom equilíbrio entre simplicidade e preservação semântica do contexto. Ao escolher um método de fragmentação, é necessário ter cuidado com o tamanho dos pedaços, uma vez que os pedaços demasiado curtos podem não fornecer um contexto útil para a LLM.
 Figura - Dividir um documento longo em pedaços mais pequenos.png
Figura - Dividir um documento longo em pedaços mais pequenos.png
Figura: Dividir um documento longo em pedaços mais pequenos
Para encontrar o tamanho ideal dos pedaços, foi efectuada uma avaliação do documento Lyft 2021. As primeiras 60 páginas do documento foram escolhidas como corpus e divididas em vários tamanhos. Em seguida, foi utilizado um LLM para gerar 170 consultas com base nestas 60 páginas. O modelo text-embedding-ada-002 foi utilizado para os embeddings, enquanto o modelo Zephyr 7B foi utilizado como LLM para gerar respostas com base nas consultas escolhidas.
Para avaliar o desempenho do modelo em diferentes tamanhos de pedaços, foi utilizado o GPT-3.5 Turbo. Duas métricas foram utilizadas para avaliar a qualidade da resposta: fidelidade e relevância. A fidelidade mede se a resposta é alucinada ou corresponde aos contextos recuperados, enquanto a relevância mede se os contextos recuperados e as respostas correspondem às consultas.
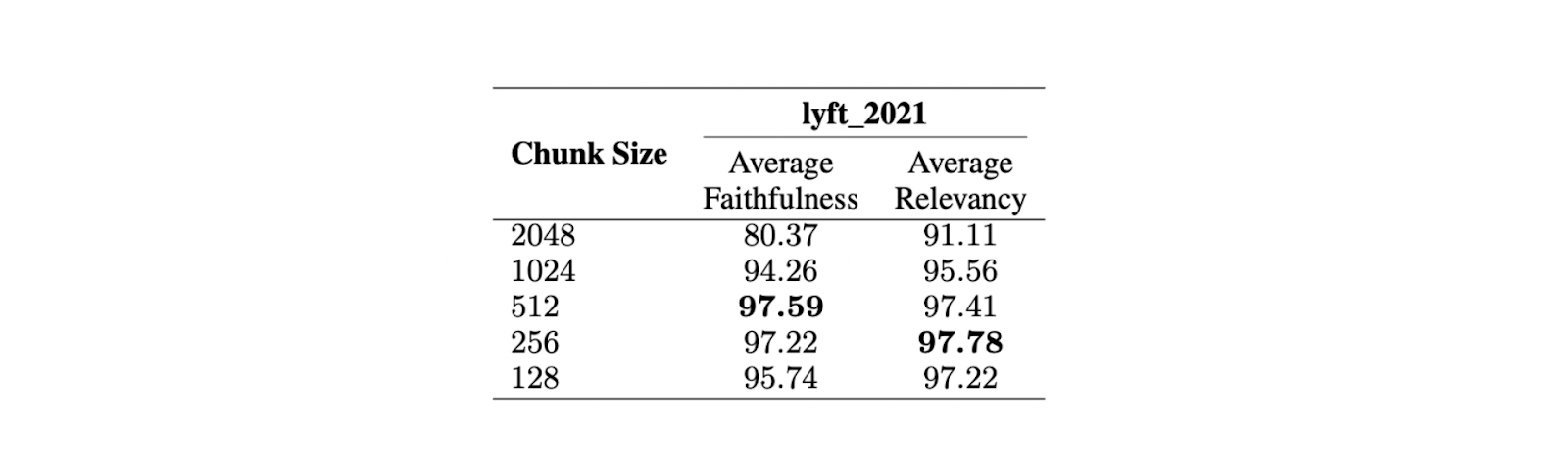 Figura - Comparação de diferentes tamanhos de pedaços. .png
Figura - Comparação de diferentes tamanhos de pedaços. .png
Figura: Comparação de diferentes tamanhos de blocos. Fonte
Os resultados mostram que um tamanho máximo de 512 tokens é preferível para a geração de respostas altamente relevantes a partir do LLM. Os tamanhos mais curtos, como 256 tokens, também têm um bom desempenho e podem melhorar o tempo de execução geral da aplicação RAG. Podem ser utilizadas técnicas avançadas de fragmentação, como small2big e janelas deslizantes, para combinar as vantagens de diferentes tamanhos de fragmentos.
O small2big é uma abordagem de chunking que organiza as relações entre blocos de pedaços. Os blocos de tamanho pequeno são utilizados para fazer corresponder as consultas e os blocos maiores, que contêm a informação dos mais pequenos, são utilizados como contexto final para a LLM. Uma janela deslizante é um método de fragmentação que fornece sobreposições de tokens entre blocos para preservar a informação de contexto.
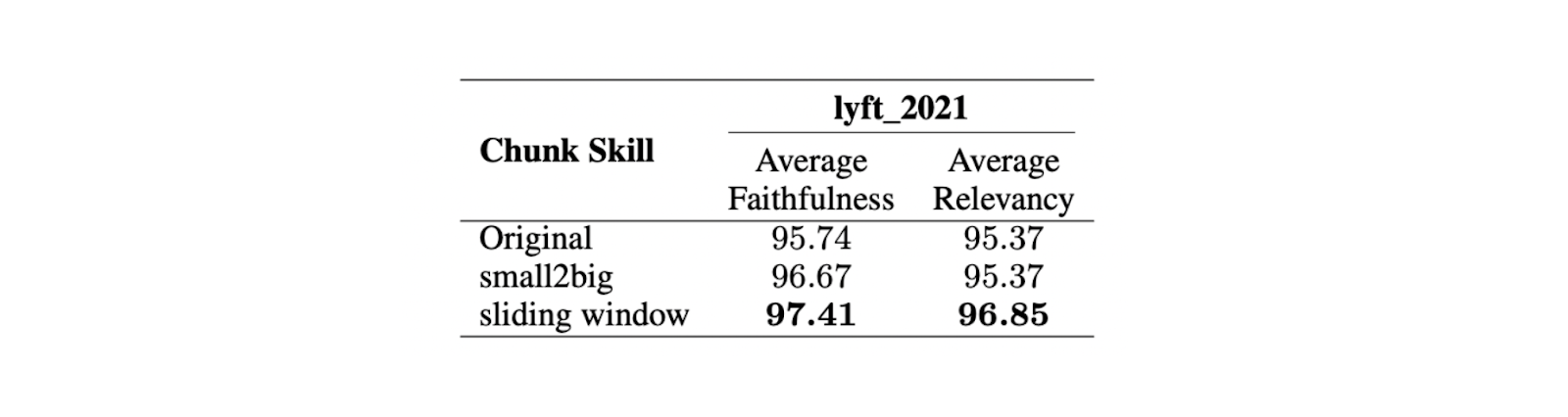 Figura - Comparação de diferentes técnicas de fragmentação..png
Figura - Comparação de diferentes técnicas de fragmentação..png
Figura: Comparação de diferentes técnicas de fragmentação. Fonte
As experiências mostram que, com um tamanho de fragmento mais pequeno de 175 tokens, um tamanho de fragmento maior de 512 tokens e uma sobreposição de fragmento de 20 tokens, ambas as técnicas de fragmentação melhoram as pontuações de fidelidade e relevância das respostas LLM.
Em seguida, é crucial encontrar o melhor [modelo de incorporação] (https://zilliz.com/ai-models) para representar cada fragmento como um vetor de incorporação. Para o efeito, foi realizado um teste no namespace-Pt/msmarco. Os resultados mostram que os modelos LLM Embedder e bge-large-en têm o melhor desempenho. No entanto, uma vez que o LLM Embedder é três vezes mais pequeno do que o bge-large-en, foi escolhido como a incorporação predefinida para a experiência.
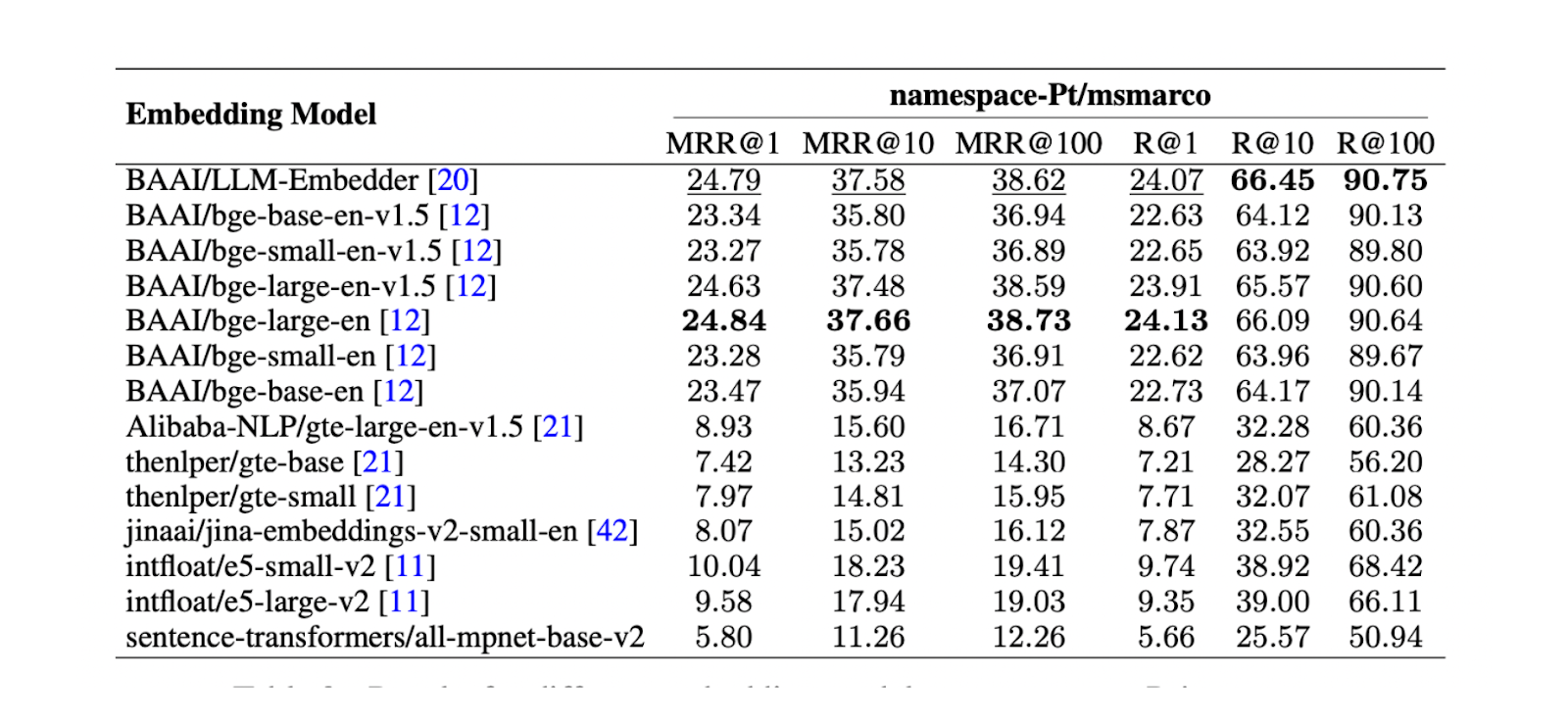 Figura - Resultados de diferentes modelos de incorporação no espaço de nomes-Pt:msmarco. .png
Figura - Resultados de diferentes modelos de incorporação no espaço de nomes-Pt:msmarco. .png
Figura: Resultados de diferentes modelos de incorporação no espaço de nomes-Ptmsmarco. Fonte
Bases de dados vectoriais
[As bases de dados vectoriais (https://zilliz.com/learn/what-is-vetor-database) desempenham um papel crucial nas aplicações RAG, nomeadamente no armazenamento e recuperação de contextos relevantes. Nas aplicações RAG comuns do mundo real, lidamos com uma enorme quantidade de documentos, o que leva a um grande número de contextos que precisam de ser armazenados. Nestes casos, o armazenamento destas incorporações na memória local é insuficiente e a recuperação de contextos relevantes entre grandes colecções de incorporações demoraria muito tempo.
As bases de dados vectoriais foram concebidas para resolver estes problemas. Com uma base de dados de vectores, podemos armazenar milhões ou mesmo milhares de milhões de embeddings de vectores e efetuar a recuperação de contextos numa fração de segundo. Ao escolher a melhor base de dados vetorial para o seu caso de utilização, é necessário ter em conta vários factores, como o suporte do tipo de índice, o suporte de vectores à escala de mil milhões, o suporte de [pesquisa híbrida] (https://zilliz.com/blog/a-review-of-hybrid-search-in-milvus) e as capacidades nativas da nuvem.
Entre estes critérios, Milvus destaca-se como a melhor base de dados vetorial de código aberto em comparação com os seus concorrentes como Weaviate, Chroma, Faiss, Qdrant, etc.
 Comparação de várias bases de dados vectoriais..png
Comparação de várias bases de dados vectoriais..png
Comparação de várias bases de dados vectoriais. Fonte.
Em termos de suporte de tipo de índice, o Milvus oferece vários métodos de indexação para satisfazer várias necessidades, como o índice plano ingénuo (FLAT) ou outros tipos de indexação concebidos para acelerar o processo de recuperação, como o índice de ficheiro invertido(IVF-FLAT) e o Hierarchical Navigable Small World (HNSW). Para comprimir a memória necessária para armazenar os contextos, pode também implementar product quantization (PQ) durante o processo de indexação dos embeddings.
O Milvus também suporta uma abordagem de pesquisa híbrida. Esta abordagem permite-nos combinar dois métodos diferentes durante o processo de recuperação de contexto. Por exemplo, podemos combinar a incorporação densa com a incorporação esparsa para recuperar contextos relevantes, aumentando a relevância do contexto recuperado em relação à consulta. Isto, por sua vez, também melhora a resposta gerada pelo LLM. Além disso, podemos combinar a incorporação densa com a filtragem de metadados, se desejado.
Se pretender utilizar o Milvus na nuvem, seja no GCP ou no AWS, para armazenar milhares de milhões de embeddings, pode optar pelo seu serviço gerido: Zilliz Cloud.
Com o Zilliz Cloud, é possível criar unidades de cluster (CUs) optimizadas em termos de capacidade e desempenho para armazenar embeddings em grande escala. Por exemplo, é possível criar 256 CUs optimizadas em termos de desempenho que servem 1,3 mil milhões de vectores de 128 dimensões ou 128 CUs optimizadas em termos de capacidade que servem 3 mil milhões de vectores de 128 dimensões.
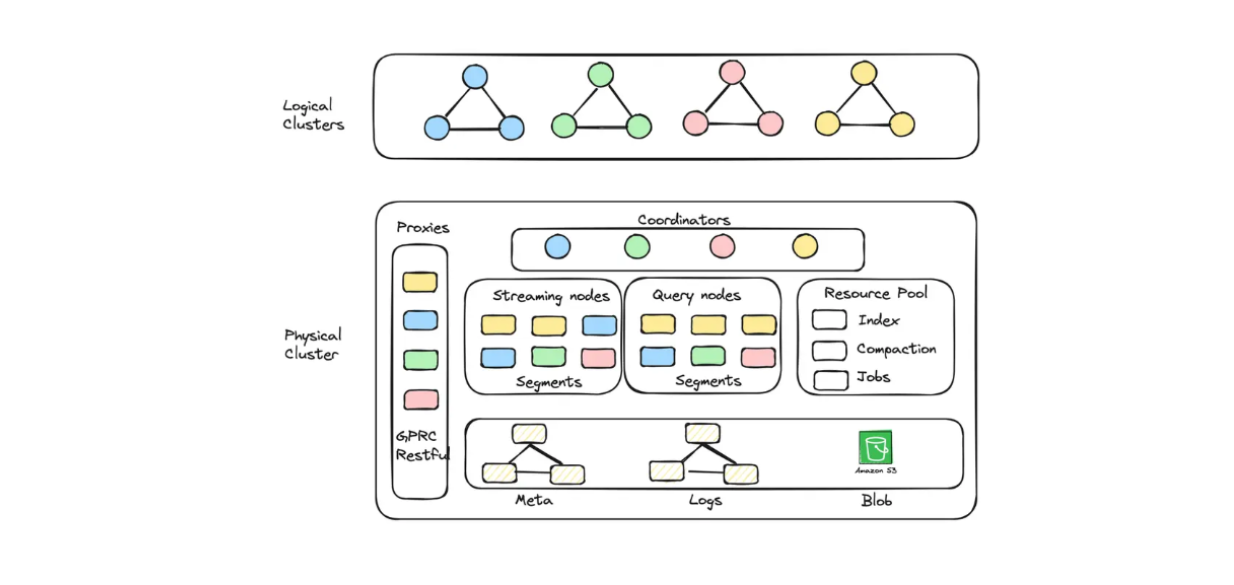 Diagrama de cluster lógico e escalonamento automático implementado no Zilliz Cloud Serverless..png
Diagrama de cluster lógico e escalonamento automático implementado no Zilliz Cloud Serverless..png
Diagrama de cluster lógico e auto-escalonamento implementado no Zilliz Cloud Serverless.
Se quiser construir uma aplicação RAG com Milvus mas também quiser poupar nos custos operacionais, pode optar por Zilliz Cloud Serverless. Este serviço fornece uma funcionalidade de auto-escalonamento no Milvus, com custos que aumentam apenas à medida que o seu negócio cresce. A opção sem servidor também é perfeita para a poupança de custos, porque só paga quando utiliza o serviço e não quando este está inativo.
O Zilliz Cloud lançou recentemente várias actualizações interessantes, incluindo um novo serviço de migração, várias réplicas, uma nova integração com conectores Fivetran, capacidade de escalonamento automático e muitas outras funcionalidades de preparação para a produção. Veja mais detalhes abaixo:
Atualização do Zilliz Cloud: serviços de migração, conectores Fivetran, várias réplicas e muito mais
Desbloqueie a pesquisa alimentada por IA com Fivetran e Milvus
5 principais razões para migrar do Milvus de código aberto para o Zilliz Cloud
Técnicas de recuperação
O principal objetivo da componente de recuperação é obter os k contextos mais relevantes para uma determinada consulta. No entanto, um desafio significativo nesta componente que pode afetar a qualidade geral do nosso RAG vem da própria consulta. As consultas originais são muitas vezes mal escritas ou expressas, não possuindo a informação semântica necessária para que as aplicações RAG possam ir buscar contextos relevantes.
Várias técnicas comummente aplicadas para resolver este problema incluem:
Reescrita de consultas: Solicita ao LLM que reescreva a consulta original para melhorar a sua clareza e informação semântica.
Decomposição da consulta:** Decompõe a consulta original em subconsultas e efectua a recuperação com base nessas subconsultas.
Geração de pseudo-documentos: Gera documentos hipotéticos ou sintéticos com base na consulta original e depois utiliza esses documentos hipotéticos para recuperar documentos semelhantes na base de dados. A implementação mais conhecida desta abordagem é o HyDE (Hypothetical Document Embeddings).
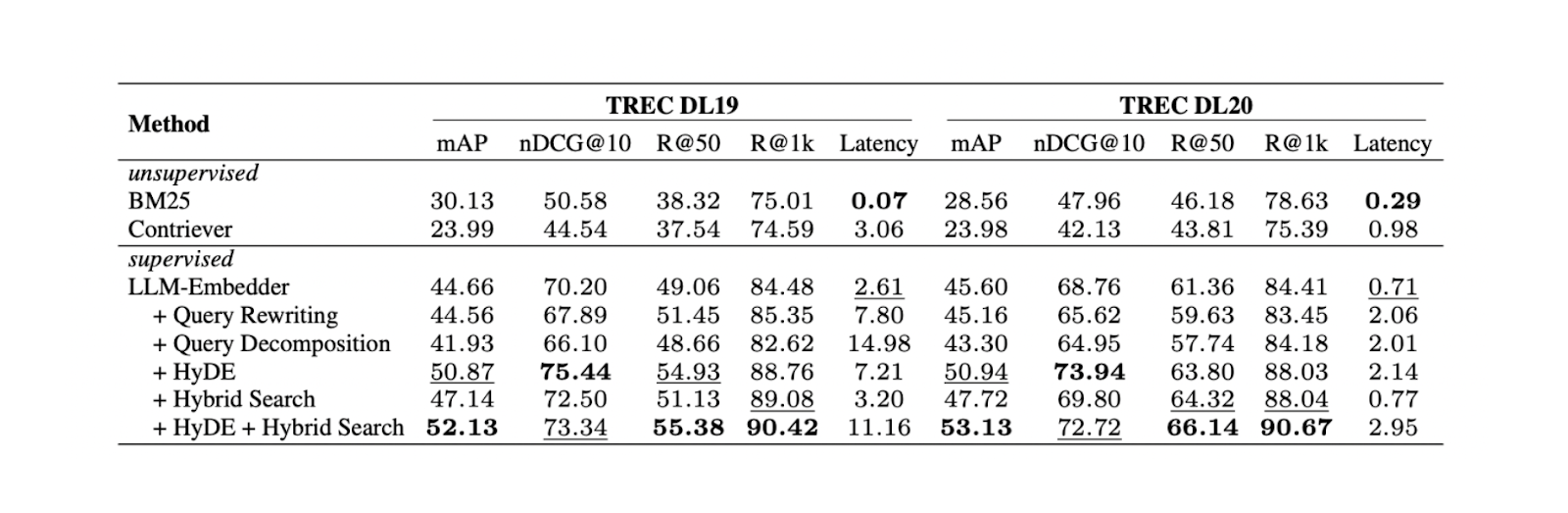
As experiências mostram que a combinação da HyDE e da pesquisa híbrida produz os melhores resultados no TREC DL19/20 em comparação com a reescrita e a decomposição de consultas. A pesquisa híbrida mencionada na experiência combina o LLM Embedder para obter embeddings densos e BM25 para obter embeddings esparsos.
O fluxo de trabalho do HyDe + pesquisa híbrida é o seguinte: primeiro, geramos um documento hipotético que responde à consulta com o HyDE. De seguida, este documento hipotético é concatenado com a consulta original antes de ser transformado em dense and sparse embeddings utilizando LLM Embedder e BM25, respetivamente.
 Resultados para diferentes métodos de recuperação. .png
Resultados para diferentes métodos de recuperação. .png
Resultados de diferentes métodos de recuperação. Fonte
Embora a combinação de HyDE e pesquisa híbrida produza os melhores resultados, também acarreta custos computacionais mais elevados. Com base em mais testes efectuados em vários conjuntos de dados de NLP, tanto a pesquisa híbrida como a utilização apenas de embeddings densos resultam num desempenho comparável ao do HyDE + pesquisa híbrida, mas com uma latência quase 10 vezes inferior. Por conseguinte, a utilização de uma pesquisa híbrida seria mais recomendada.
Uma vez que estamos a utilizar uma pesquisa híbrida, os contextos recuperados baseiam-se na [pesquisa de vectores] (https://zilliz.com/learn/vetor-similarity-search) a partir de embeddings densos e esparsos. Por conseguinte, é também interessante examinar o impacto do valor de ponderação entre as incorporações densas e esparsas na pontuação global de relevância de acordo com esta equação:
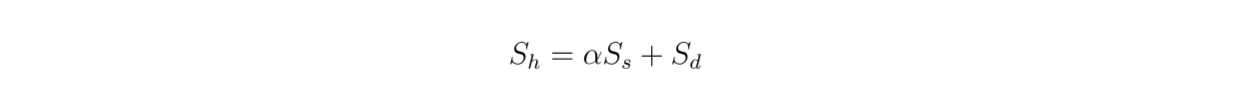 formula.png
formula.png
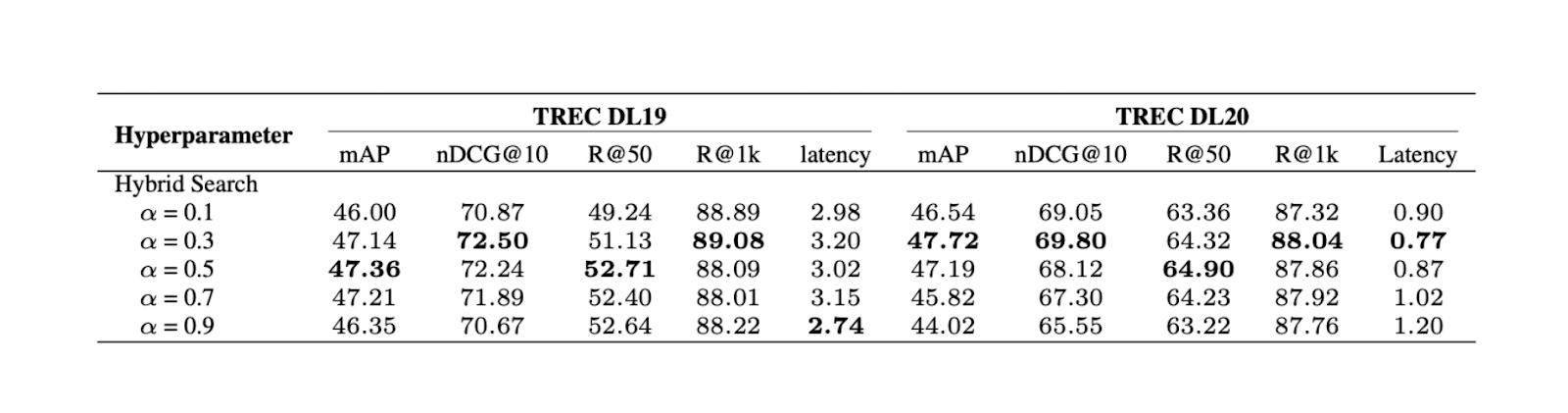 Figura- Resultados da pesquisa híbrida com diferentes valores de alfa..png
Figura- Resultados da pesquisa híbrida com diferentes valores de alfa..png
Figura: Resultados da pesquisa híbrida com diferentes valores alfa. Fonte.
A experiência mostra que um valor de ponderação de 0,3 produz a melhor pontuação global de relevância no TREC DL19/20.
Técnicas de reposicionamento e reempilhamento
O principal objetivo das [técnicas de reordenamento] (https://zilliz.com/learn/what-are-rerankers-enhance-information-retrieval) é reordenar os k contextos mais relevantes obtidos a partir do método de recuperação para garantir que o contexto mais semelhante é devolvido no topo da lista. Há duas abordagens comuns para reordenar os contextos:
DLM Reranking: Este método utiliza um modelo de aprendizagem profunda para a reclassificação. O modelo é treinado com um par constituído pela consulta original e um contexto como entrada e um rótulo binário "verdadeiro" (se o par for relevante um para o outro) ou "falso" como saída. Os contextos são então ordenados com base na probabilidade que o modelo devolve quando prevê um par de consultas e contexto como "verdadeiro".
TILDE Reranking: Esta abordagem utiliza a probabilidade de cada termo na consulta original para fazer a classificação. Durante o tempo de inferência, podemos utilizar apenas a componente de verosimilhança da consulta (TILDE-QL) para uma reavaliação mais rápida ou a combinação de TILDE-QL com a sua componente de verosimilhança do documento (TILDE-DL) para melhorar o resultado da reavaliação com um custo computacional mais elevado.
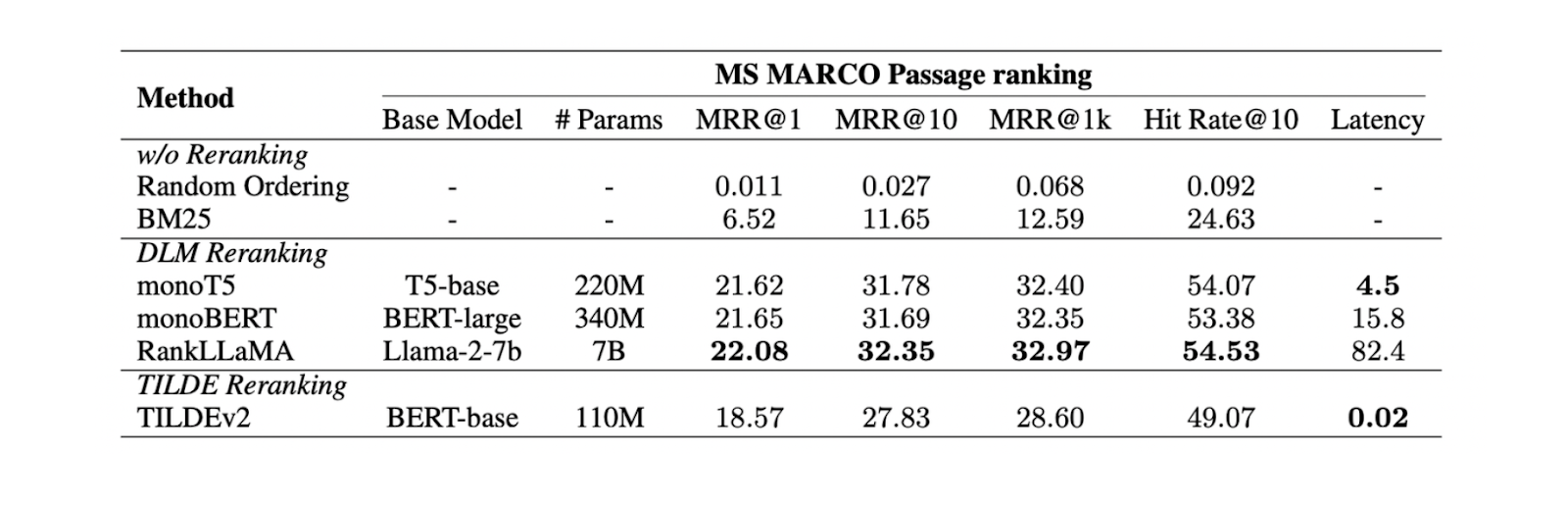 Figura - Resultados de diferentes métodos de reordenação..png
Figura - Resultados de diferentes métodos de reordenação..png
Figura: Resultados de diferentes métodos de classificação... Fonte
As experiências com o conjunto de dados de classificação MS MARCO Passage mostram que o método de reordenação DLM com o modelo Llama 27B produz o melhor desempenho de reordenação. No entanto, como se trata de um modelo grande, a sua utilização implica um custo computacional significativo. Por conseguinte, a utilização do mono T5 é mais recomendada para a reclassificação DLM, uma vez que proporciona um equilíbrio entre desempenho e eficiência computacional.
Após a fase de reordenamento, também precisamos de considerar como apresentar os contextos reordenados ao nosso LLM: se por ordem descendente ("forward") ou ascendente ("reverse"). Com base nas experiências efectuadas neste trabalho, pode concluir-se que a melhor qualidade de resposta é gerada utilizando a configuração "inversa". A hipótese é que o posicionamento do contexto mais relevante mais próximo da consulta conduz a resultados óptimos.
Técnicas de Sumarização
Nos casos em que temos contextos longos recuperados de componentes anteriores, podemos querer torná-los mais compactos e remover informações redundantes. Para atingir este objetivo, são normalmente implementadas abordagens de resumo.
Existem duas técnicas diferentes de sumarização de contextos: extractiva e abstractiva.
A sumarização extractiva divide o documento de entrada em segmentos mais pequenos, depois classificados com base na importância. Entretanto, o método abstrativo gera um novo resumo de contexto que contém apenas informações relevantes.
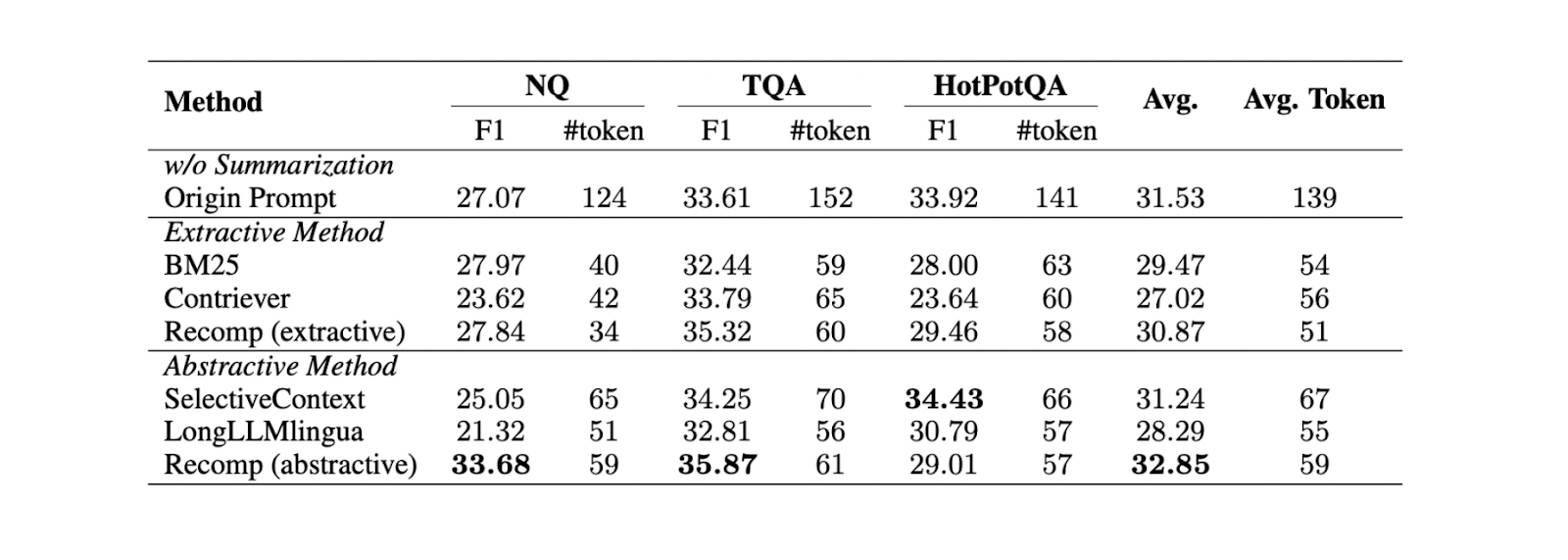 Figura - Comparação entre diferentes métodos de resumo..png
Figura - Comparação entre diferentes métodos de resumo..png
Figura: Comparação entre diferentes métodos de resumo. Fonte
Com base em experiências realizadas em três conjuntos de dados diferentes (NQ, TriviaQA e HotpotQA), a sumarização abstractiva com Recomp apresenta o melhor desempenho em comparação com outros métodos abstractos e extractivos.
O resumo das melhores técnicas de RAG
Agora que sabemos qual é a melhor abordagem para cada componente das RAG para conjuntos de dados de referência específicos, podemos testar todas as abordagens mencionadas nas secções anteriores em mais conjuntos de dados. Os resultados mostram que cada componente contribui para o desempenho geral da nossa aplicação RAG. Segue-se um resumo dos resultados de cada abordagem em cada componente, com base em cinco conjuntos de dados diferentes:
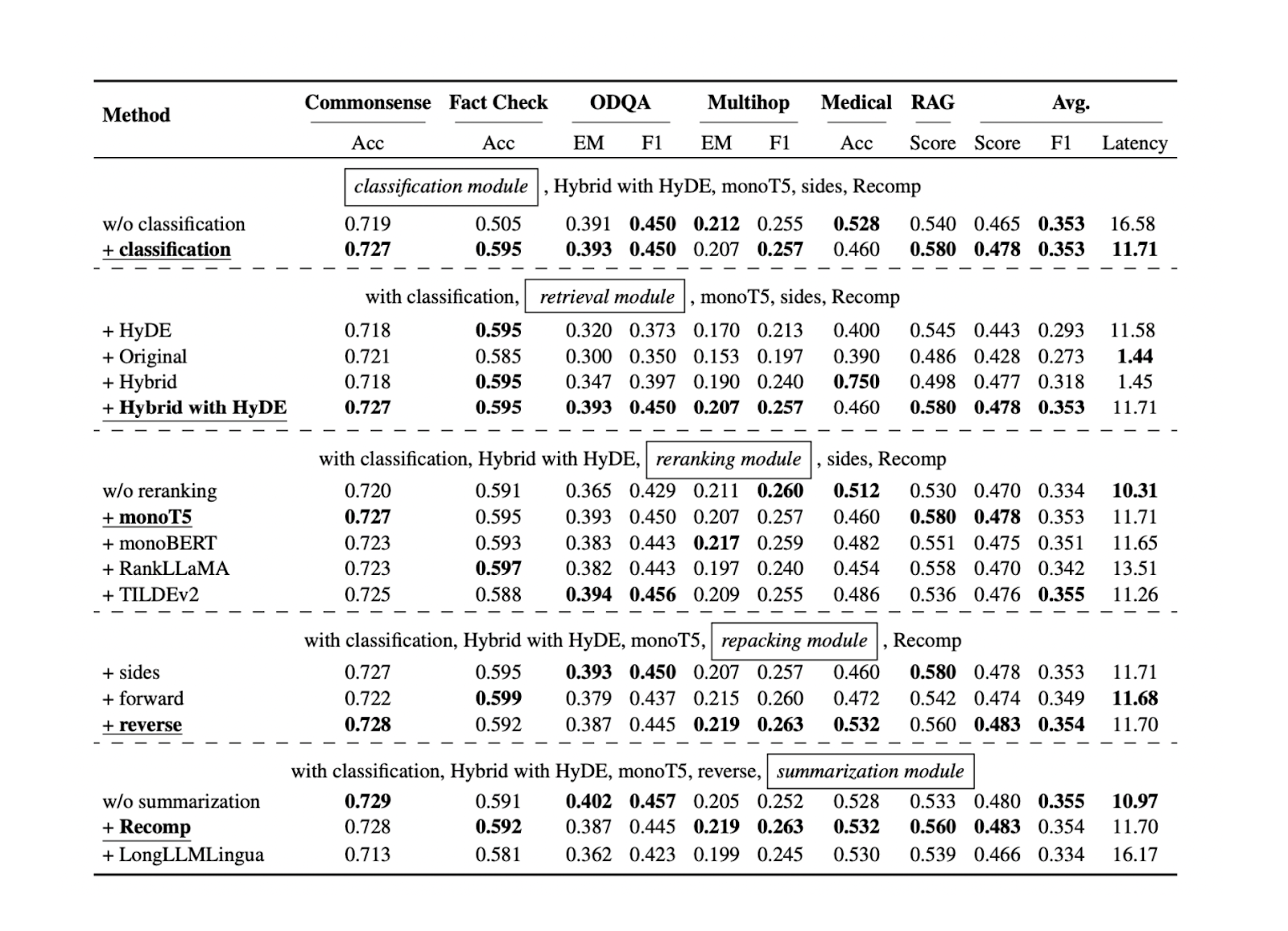 Figura - Resultados da procura de práticas RAG óptimas..png
Figura - Resultados da procura de práticas RAG óptimas..png
Figura: Resultados da pesquisa de práticas RAG óptimas. Fonte
A componente de classificação da consulta ajuda a melhorar a exatidão das respostas e a reduzir a latência global do tempo de execução. Este passo inicial ajuda a determinar se uma consulta requer recuperação de contexto ou pode ser processada diretamente pelo LLM, optimizando assim a eficiência do sistema.
O componente de recuperação é crucial para garantir que obtemos candidatos de contexto relevantes em relação à consulta. Para esta componente, recomenda-se uma base de dados vetorial mais escalável e com melhor desempenho, como a Milvus ou o seu serviço gerido, Zilliz Cloud. Além disso, recomenda-se a pesquisa híbrida ou a pesquisa de incorporação densa. Estes métodos conseguem um equilíbrio entre a correspondência de contexto abrangente e a eficiência computacional.
O componente de reordenação garante que obtemos os contextos mais relevantes, reordenando os k contextos de topo recuperados do componente de recuperação. O modelo monoT5 é recomendado para a reordenação devido ao seu equilíbrio entre desempenho e custo computacional. Este passo refina a seleção de contextos, dando prioridade aos contextos mais relevantes para a consulta.
O método inverso é recomendado para reempacotar o contexto. Esta abordagem posiciona o contexto mais relevante mais próximo da consulta, conduzindo potencialmente a respostas mais exactas e coerentes do LLM.
Finalmente, o método abstrativo com Recomp mostrou o melhor desempenho para a sumarização do contexto. Essa técnica ajuda a condensar contextos longos, preservando informações importantes, facilitando o processamento e a geração de respostas relevantes pelo LLM.
Ajuste fino do LLM
Na maioria dos casos, o ajuste fino do LLM não é necessário, especialmente se você estiver usando um LLM de alto desempenho com muitos parâmetros. No entanto, se tiver restrições de hardware e só puder usar LLMs mais pequenos, poderá ter de os afinar para os tornar mais robustos ao gerar respostas relacionadas com o seu caso de utilização. Antes de fazer o ajuste fino de uma LLM, é necessário considerar os dados que serão usados como dados de treinamento.
Durante a preparação dos dados, pode recolher dados de treino no prompt e no contexto como um par de entradas, com um exemplo de texto gerado como saída. As experiências mostram que aumentar os seus dados com uma mistura de contextos relevantes e selecionados aleatoriamente durante a formação resultará no melhor desempenho. A intuição por detrás disto é que a mistura de contextos relevantes e aleatórios durante o ajuste fino pode melhorar a robustez do nosso LLM.
Conclusão
Neste artigo, explorámos vários componentes do RAG, desde a classificação de consultas à sumarização de contextos. Discutimos e destacámos as abordagens com o melhor desempenho em cada componente.
Estes componentes optimizados trabalham em conjunto para melhorar o desempenho global do sistema RAG. Estão a melhorar a qualidade e a relevância das respostas geradas, mantendo a eficiência computacional. Ao implementar estas melhores práticas em cada componente, podemos criar um sistema RAG mais robusto e eficaz, capaz de lidar com uma vasta gama de consultas e tarefas.
Leitura adicional
Modelos de IA com melhor desempenho para seus aplicativos GenAI | Zilliz](https://zilliz.com/ai-models)
Construir aplicações de IA com Milvus: tutoriais e cadernos de notas
Como construir um RAG multilingue com Milvus, LangChain e OpenAI
Construir um RAG Multimodal com Gemini, BGE-M3, Milvus e LangChain
O que é o GraphRAG? Melhorar o RAG com gráficos de conhecimento ](https://zilliz.com/blog/graphrag-explained-enhance-rag-with-knowledge-graphs)
Como avaliar aplicações RAG ](https://zilliz.com/learn/How-To-Evaluate-RAG-Applications)
Continue lendo

My Wife Wanted Dior. I Spent $600 on Claude Code to Vibe-Code a 2M-Line Database Instead.
Write tests, not code reviews. How a test-first workflow with 6 parallel Claude Code sessions turns a 2M-line C++ codebase into a daily shipping pipeline.

8 Latest RAG Advancements Every Developer Should Know
Explore eight advanced RAG variants that can solve real problems you might be facing: slow retrieval, poor context understanding, multimodal data handling, and resource optimization.

1 Table = 1000 Words? Foundation Models for Tabular Data
TableGPT2 automates tabular data insights, overcoming schema variability, while Milvus accelerates vector search for efficient, scalable decision-making.