




Por que criamos o Vector Lakebase: repensando a arquitetura de dados não estruturados para IA
Recentemente, lançamos o Zilliz Vector Lakebase, a próxima evolução do Zilliz Cloud, de um sistema puramente de banco de dados vetorial para uma base de dados unificada, nativa de lake, para cargas de trabalho de IA. O anúncio gerou muito interesse. Também trouxe à tona, quase imediatamente, perguntas sobre para onde a Zilliz estava indo.
A Zilliz estava se afastando dos bancos de dados vetoriais? Ou, de forma mais direta: os bancos de dados vetoriais já estão se tornando obsoletos?
Entendo por que essas perguntas surgiram. Por anos, a Zilliz ficou conhecida por construir sistemas de bancos de dados vetoriais prontos para produção (o open-source Milvus e o totalmente gerenciado Zilliz Cloud). Então, quando começamos a falar sobre evoluir para uma base de dados nativa de lake para IA, algumas pessoas naturalmente se perguntaram se isso significava uma mudança de direção.
A resposta curta é NÃO. Absolutamente NÃO. Na verdade, o Vector Lakebase é a nossa resposta ao que acontece depois que os bancos de dados vetoriais dão certo.
Nos últimos anos, os bancos de dados vetoriais se tornaram uma das camadas fundamentais de infraestrutura da stack de IA. A adoção cresceu mais rápido do que poderíamos imaginar quando começamos o Milvus há quase uma década. A categoria é real, e a necessidade de recuperação semântica só está se tornando mais importante.
Mas outra coisa também ficou clara para nós: a recuperação vetorial não é mais o problema inteiro.
À medida que os sistemas de IA passam de assistentes estáticos para agentes em execução contínua, as empresas estão pedindo algo mais amplo de sua infraestrutura de dados não estruturados. Elas não querem apenas um sistema capaz de recuperar informações. Querem um sistema que possa melhorar os dados, reorganizá-los, analisá-los, refiná-los e realimentar essas melhorias na produção. Isso muda a arquitetura.
Essa mudança me lembra um ciclo anterior na história da infraestrutura: a evolução dos bancos de dados durante a era da internet móvel. Os detalhes são diferentes, mas o padrão é familiar. Um novo tipo de aplicação cria um novo tipo de pressão sobre os dados. A primeira geração de infraestrutura resolve o problema imediato de serving. Então, à medida que os dados crescem, a arquitetura precisa se expandir.
Acredito que os bancos de dados vetoriais estão entrando agora nesse próximo estágio.
A internet móvel já passou por esse ciclo uma vez
Por volta de 2010, à medida que as aplicações móveis explodiam, o MongoDB se tornou um dos produtos de infraestrutura definidores daquele período.
O motivo era simples. As aplicações móveis geravam enormes volumes de dados semiestruturados: eventos de usuário, atividade social, telemetria de dispositivos, sinais comportamentais, logs de produto. Nada disso se encaixava perfeitamente nos padrões de bancos de dados relacionais que a maioria das equipes usava na época. As equipes de produto lançavam rapidamente, os esquemas mudavam constantemente, e o primeiro problema era simplesmente aceitar os dados sem desacelerar a aplicação. O MongoDB resolveu muito bem esse problema imediato: ingerir os dados primeiro. A estrutura e a análise poderiam vir depois.

Vários anos depois, a indústria começou a fazer uma pergunta diferente. Depois que todos esses dados existiam, como as empresas poderiam realmente usá-los? Essa mudança ajudou a impulsionar a ascensão de data warehouses modernos, como Snowflake e Redshift. O foco passou do armazenamento operacional para o insight analítico. As empresas queriam relatórios de BI, coortes de usuários, atribuição, previsão e análise de crescimento. Os dados deixaram de ser apenas um subproduto operacional e se tornaram um ativo de negócio.
Então surgiu outro gargalo.
A divisão entre sistemas transacionais e sistemas analíticos tornou-se cada vez mais dolorosa. Os pipelines de dados entre ambientes OLTP e OLAP eram frágeis, caros e operacionalmente exaustivos. Os mesmos conjuntos de dados eram copiados repetidamente entre sistemas, muitas vezes com atrasos de sincronização e inconsistências sutis.
Esse foi o ambiente que deu origem à arquitetura Lakehouse. Databricks, Iceberg, Hudi e sistemas relacionados convergiram todos em torno da mesma ideia básica: uma única cópia lógica dos dados deveria oferecer suporte a múltiplos modelos de computação sem exigir movimentação interminável entre sistemas.
Olhando para trás, a progressão parece quase inevitável. Mas, na época, nada disso era óbvio. A ascensão do MongoDB não previu o Snowflake. O Snowflake não previu o Lakehouse. Cada transição surgiu porque a geração anterior de infraestrutura teve sucesso em escala e, então, expôs uma nova classe de restrições.
Esse padrão importa porque a infraestrutura de IA cada vez mais parece estar seguindo um caminho semelhante.
A recuperação resolveu o primeiro problema, não o definitivo
Quando os grandes modelos de linguagem entraram na adoção mainstream em 2023, os bancos de dados vetoriais se tornaram uma das primeiras categorias de infraestrutura de grande destaque. O motivo era prático. Sistemas RAG precisavam de uma forma nativa de armazenar embeddings e realizar recuperação semântica. A maioria dos bancos de dados tradicionais não foi projetada para busca vetorial de alta dimensionalidade, índices ANN, recuperação híbrida e filtragem de baixa latência em escala.
De muitas formas, os bancos de dados vetoriais resolveram o mesmo tipo de problema que o MongoDB havia resolvido antes. Um novo padrão de aplicação criou uma nova abstração de dados, e os desenvolvedores precisavam de infraestrutura capaz de dar suporte a ela. Desta vez, a abstração era a representação semântica: embeddings gerados a partir de dados não estruturados por modelos neurais.
Essa primeira fase de adoção aconteceu muito rapidamente. Mas, apenas alguns anos depois, as perguntas que ouvimos dos clientes se tornaram muito mais complexas. Eles já não perguntam apenas como recuperar vetores com eficiência. Eles perguntam:
- Como deduplicamos e refinamos continuamente os dados de treinamento?
- Como analisamos bilhões de embeddings em busca de problemas de agrupamento e qualidade?
- Como identificamos drift, viés ou redundância em conjuntos de dados multimodais?
- Como rastreamos e otimizamos históricos de execução de agentes?
- Como reprocessamos e melhoramos os dados à medida que os modelos evoluem?
- Como buscamos dados frios sem manter toda a computação em execução o tempo todo?
- Como usamos dados que já estão em Iceberg, Lance, Parquet e armazenamento de objetos para múltiplas cargas de trabalho de IA?
Esses já não são problemas puramente de recuperação. Eles exigem processamento offline em larga escala, fluxos de trabalho iterativos de descoberta, governança de dados, exploração analítica e ciclos contínuos de feedback entre sistemas online e computação offline. Cada vez mais, percebemos algo importante entre equipes avançadas de IA: o gargalo já não era apenas a capacidade do modelo. Era a velocidade de iteração.
Uma experiência tornou isso dolorosamente óbvio. Vimos equipes tentando reprocessar grandes conjuntos de dados vetoriais: reagrupar embeddings, remover duplicação, regenerar índices, reembeddar corpora inteiros. Em alguns casos, simplesmente mover um bilhão de vetores de um sistema para outro podia levar dias. Não horas. Dias.
Enquanto isso, os ciclos de iteração dentro das principais equipes de IA estão se movendo na direção oposta. Pesquisadores querem experimentar continuamente. Engenheiros de dados estão sob pressão para limpar, avaliar e atualizar conjuntos de dados mais rapidamente. Modelos melhoram. Modelos de embedding mudam. Agentes criam novos rastros todos os dias. Mas a pilha de infraestrutura por baixo deles não foi projetada para ciclos contínuos de refinamento em dados não estruturados.
Foi nesse ponto que começamos a pensar que o setor estava enquadrando o problema de forma estreita demais.
A infraestrutura de dados não estruturados não é meramente uma camada de recuperação. Ela está se tornando um sistema continuamente operacional.
De sistemas de recuperação a sistemas contínuos: CS/CD
Internamente, começamos a descrever essa arquitetura como um ciclo contínuo entre serving e descoberta. Com o tempo, começamos a chamá-la de CS/CD: Continuous Serving e Continuous Discovery.
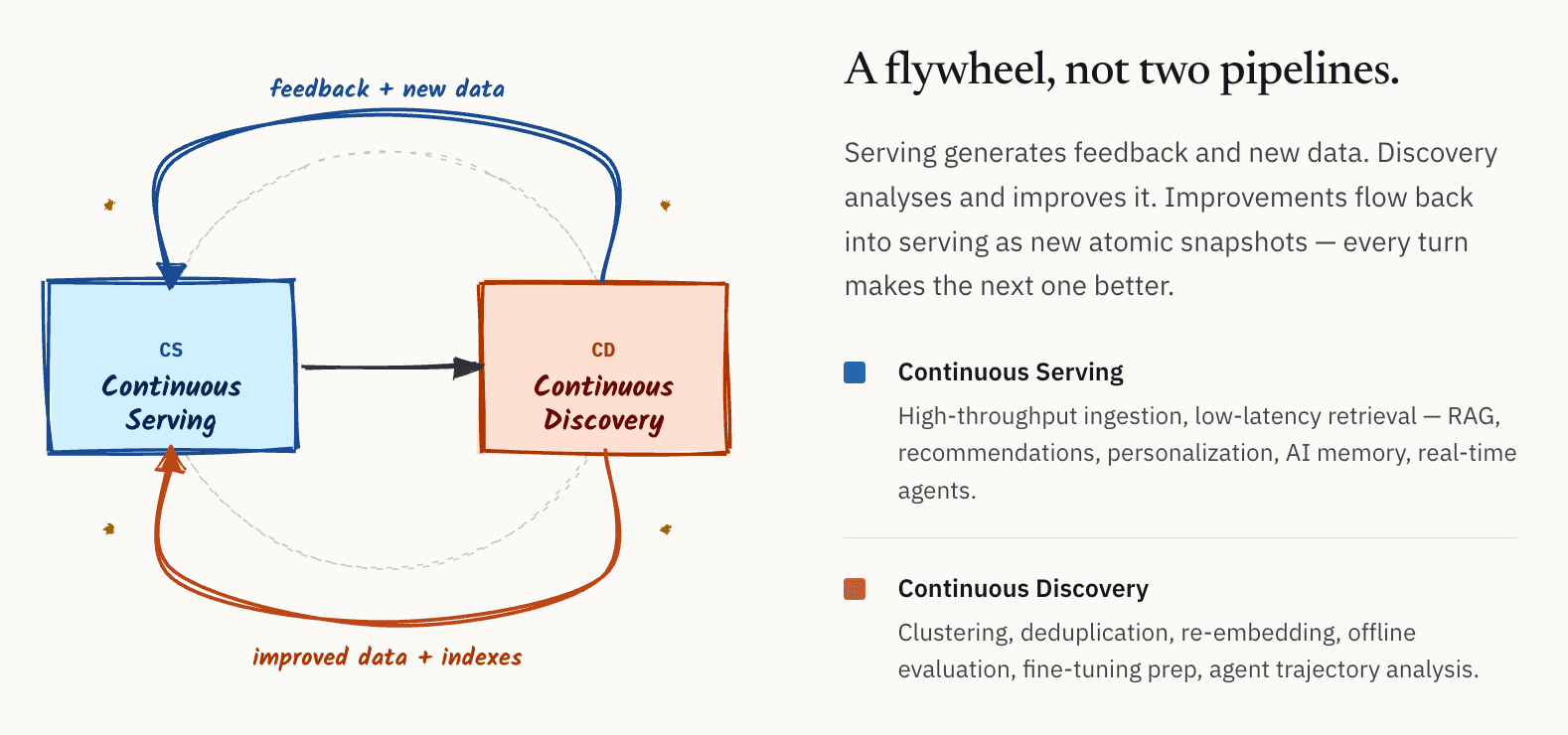
A ideia é conceitualmente simples.
- De um lado, há a camada de serviço: ingestão de alto throughput, recuperação de baixa latência para sistemas RAG online, sistemas de recomendação, personalização, memória de IA e agentes em tempo real.
- Do outro lado, há a camada de descoberta: clustering, deduplicação, re-embedding, avaliação offline, análise de qualidade, preparação para fine-tuning de modelos e análise de trajetórias de agentes.
O ponto importante é que esses não são fluxos de trabalho independentes. Eles formam um flywheel. Sistemas de serviço geram continuamente feedback e novos dados. Sistemas de descoberta analisam e melhoram esses dados. As melhorias resultantes, incluindo melhores embeddings, conjuntos de dados mais limpos, índices aprimorados e metadados refinados, então retornam para a camada de serviço.
Cada iteração deve melhorar a próxima. Pelo menos em teoria.
Na prática, a maioria das organizações ainda não consegue operar esse ciclo com eficiência porque a infraestrutura subjacente permanece fragmentada.
Hoje, se uma equipe quer realizar processamento offline em larga escala sobre dados vetoriais de produção, o fluxo de trabalho típico ainda é dolorosamente manual. Os dados precisam primeiro ser exportados do banco de dados vetorial para um lake ou ambiente batch. Índices geralmente não podem ser reutilizados. Pipelines de sincronização tornam-se frágeis. Atualizações incrementais são difíceis. Os resultados processados precisam eventualmente ser reimportados para o sistema de serviço, muitas vezes sem nenhuma garantia de consistência atômica entre os novos dados e os novos índices.
O resultado é um fluxo de trabalho lento, frágil e caro. E, por ser tão caro de manter, muitas organizações simplesmente evitam fazer descoberta contínua. Os dados ficam ali, recuperáveis, mas em grande parte inexplorados.
Isso nos lembrou cada vez mais da lacuna histórica entre sistemas OLTP e OLAP, exceto que agora a fragmentação está entre recuperação semântica online e processamento offline de dados não estruturados.
Por que as arquiteturas existentes eventualmente atingem seus limites
Uma coisa da qual ficamos cada vez mais convencidos é que nenhum dos lados da pilha de infraestrutura atual está errado.
Bancos de dados vetoriais e sistemas Lakehouse ambos resolvem problemas importantes. A questão é que cada arquitetura foi otimizada em torno de apenas metade da carga de trabalho emergente.
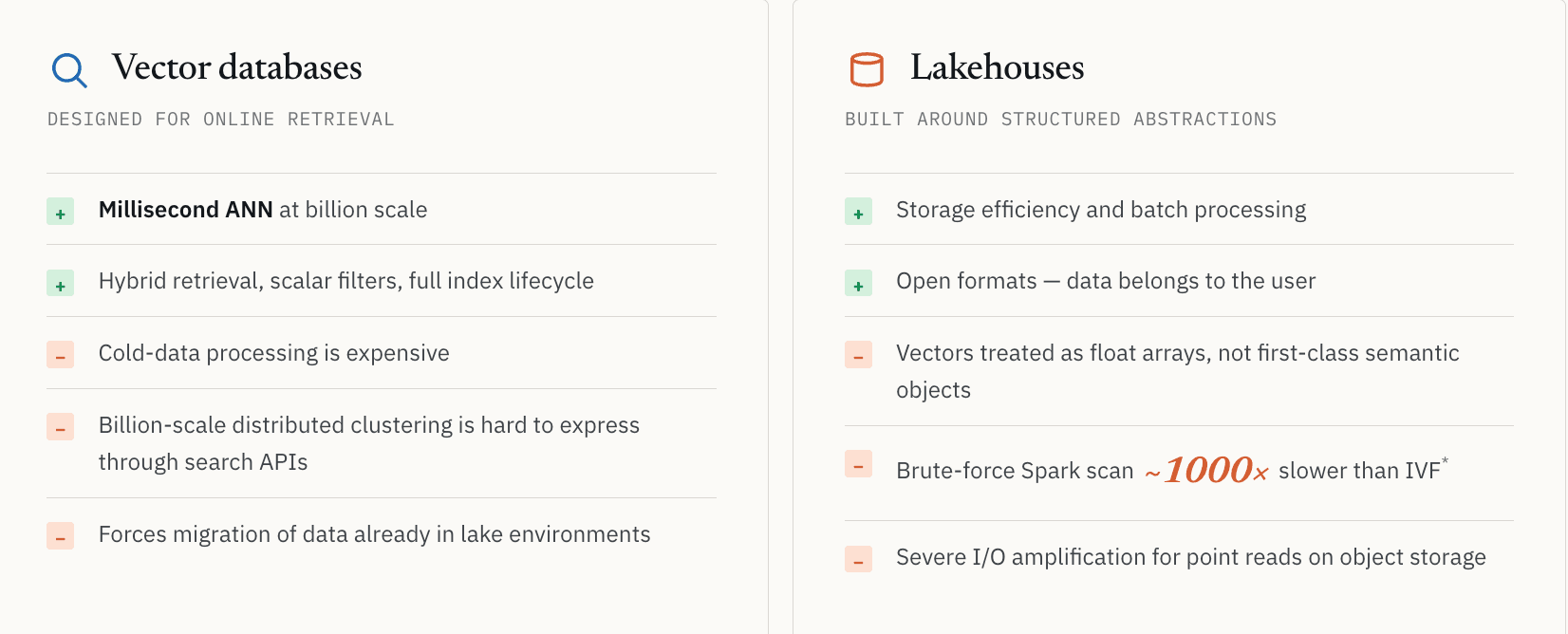
Bancos de dados vetoriais foram projetados principalmente para recuperação online.
Tome o Milvus open-source como exemplo. Ele resolve a busca vetorial em escala extremamente bem. Mas quando as cargas de trabalho vão além do serviço e entram na descoberta em larga escala, limites arquiteturais naturais aparecem.
O processamento de dados frios torna-se caro. Clustering distribuído em escala de bilhões é difícil de expressar por meio de APIs de busca online. Muitos sistemas assumem que os dados precisam permanecer carregados na infraestrutura online para continuarem consultáveis. Empresas que já armazenam enormes conjuntos de dados não estruturados em ambientes lake enfrentam custos de migração e fragmentação de governança quando são solicitadas a mover tudo para um sistema de recuperação dedicado.
Esses não são bugs de implementação. São consequências de otimizar para recuperação online de baixa latência.
Lakehouses resolvem eficiência de armazenamento e processamento batch, mas foram projetados em torno de abstrações de dados estruturados
A abordagem oposta, começando pelo lado do Lakehouse, introduz um conjunto diferente de tradeoffs.
Lakehouses resolvem a eficiência de armazenamento e o processamento batch de forma elegante. Mas foram projetados em torno de abstrações de dados estruturados. Na maioria das arquiteturas lake, vetores ainda são tratados como longos arrays de floats em vez de objetos semânticos de primeira classe. Formatos de arquivo como Parquet não foram projetados em torno de índices ANN, índices invertidos ou caminhos de recuperação semântica de baixa latência.
Vimos isso diretamente com um cliente farmacêutico realizando busca por similaridade molecular. Uma varredura Spark de força bruta em dados no lake foi aproximadamente 1000x mais lenta do que a recuperação vetorial indexada usando busca baseada em IVF. O número exato depende da distribuição dos dados, dos parâmetros do índice e do hardware, mas a lição é estável: sem o índice certo, muitas cargas de trabalho semânticas não são economicamente viáveis.
Há também um problema de armazenamento mais básico. O armazenamento de objetos pode introduzir uma amplificação severa de I/O para cargas de trabalho orientadas à recuperação. A busca semântica frequentemente encontra um pequeno número de IDs, mas a aplicação ainda precisa dos registros completos por trás desses IDs. Com formatos colunares tradicionais, recuperar alguns registros pequenos pode exigir a leitura de grandes blocos de armazenamento. Isso é adequado para varreduras. É uma má opção para serving de baixa latência.
Com o tempo, nossa conclusão tornou-se difícil de evitar: a indústria não deveria ter que escolher entre bancos de dados vetoriais e arquiteturas de lake. Ela precisa de uma arquitetura em que a recuperação e a descoberta em larga escala sejam partes nativas do mesmo sistema operacional.
O que queremos dizer com Vector Lakebase
Essa percepção nos levou ao que agora chamamos de Vector Lakebase. A ideia central não é “um banco de dados vetorial mais um data lake.” Acho que esse enquadramento perde o ponto arquitetural mais profundo.
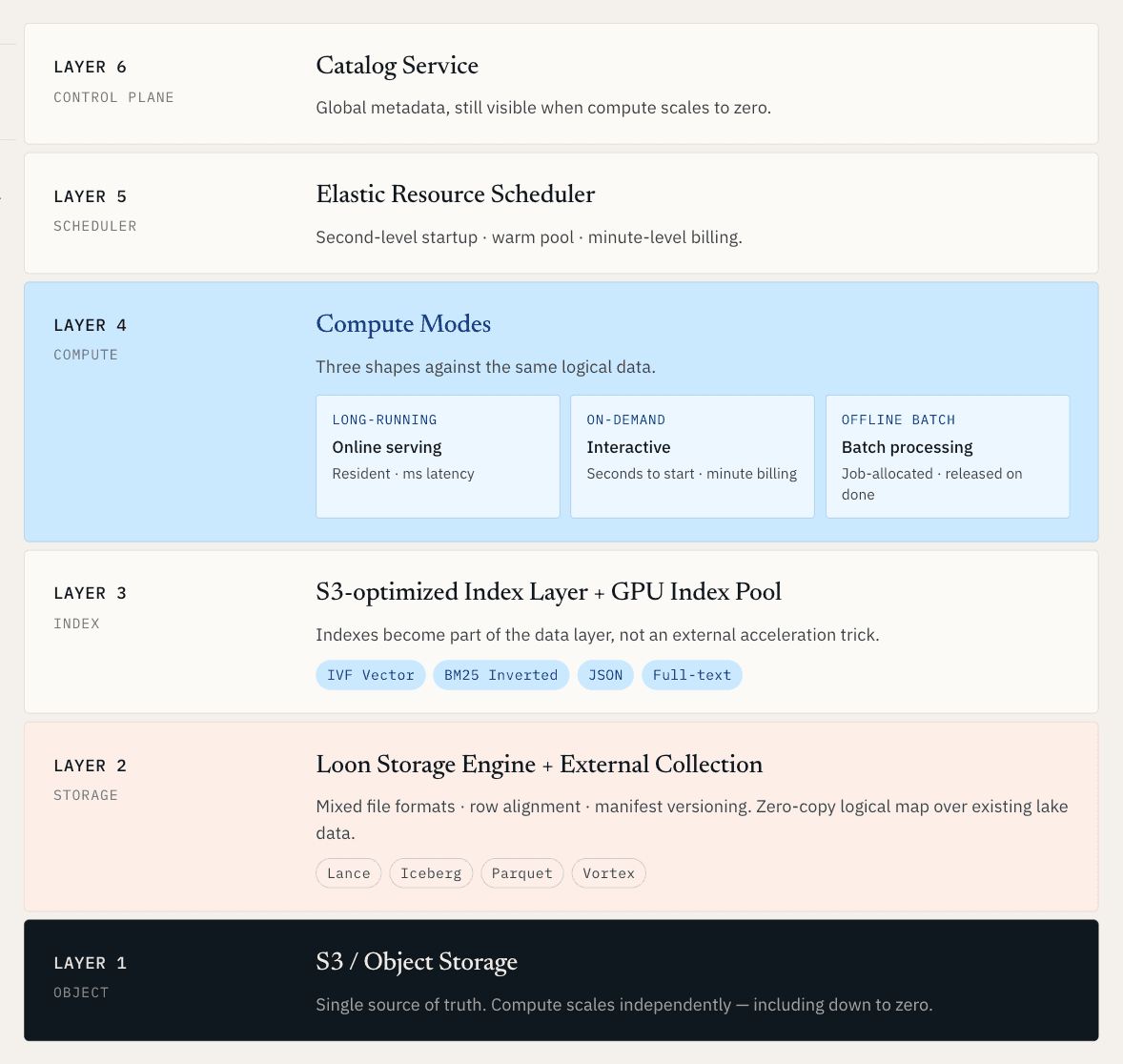
O objetivo é criar uma camada operacional unificada para dados não estruturados, na qual o serving online, a descoberta offline e a computação elástica operem todos sobre a mesma base lógica de dados.
Para dados brutos, isso significa que vetores, documentos, metadados, logs e índices são gerenciados juntos em armazenamento nativo de lake. Para dados que já vivem em Iceberg, Lance, Parquet ou armazenamento de objetos, significa que o sistema pode mapear e indexar esses dados sem forçar uma migração completa.
Uma vez que você parte desse requisito, a arquitetura precisa resolver vários problemas difíceis ao mesmo tempo. A computação precisa escalar independentemente do armazenamento. Os índices precisam se tornar parte da camada de dados, não um truque externo de aceleração. Novos dados e novos índices precisam ser publicados juntos como snapshots consistentes. E os dados de lake existentes precisam se tornar pesquisáveis sem criar outra cópia.
Essas ideias parecem simples. Fazê-las funcionar preservando o desempenho que as pessoas esperam de um banco de dados vetorial é a parte difícil. É aí que as decisões de engenharia de nível mais baixo começam a importar.
O custo de separar armazenamento e computação e como o abordamos
A separação entre armazenamento e computação é necessária para o loop CS/CD, mas não é gratuita.
Inicialização a frio lenta
Se a computação pode escalar até zero, a primeira consulta em um fluxo de trabalho sob demanda ou offline pode atingir dados puramente frios. O nó não tem índice local, nem cache aquecido, nem dados residentes. Tudo precisa vir do armazenamento de objetos.
Para conjuntos de dados pequenos, isso é gerenciável. Para grandes cargas de trabalho vetoriais, rapidamente se torna inaceitável. Considere um bilhão de vetores de 768 dimensões. Um índice HNSW convencional pode ter cerca de 340 GB. Puxar esse índice completo do S3 pode levar mais de quatro minutos. Ninguém quer esperar quatro minutos antes que uma busca possa começar.
Nossa resposta é tornar o caminho frio muito menor. Usando quantização de 1+3 bits ao estilo RaBitQ, podemos comprimir esse índice de aproximadamente 340 GB para cerca de 13 GB. A busca é executada em duas etapas. A primeira etapa usa uma representação de 1 bit para filtragem grosseira, com aproximadamente 85 a 90 por cento de recall, reduzindo o tamanho dos dados para cerca de um trigésimo do original. A segunda etapa usa a representação de 1+3 bits para reclassificar e refinar os resultados para cerca de 95 por cento de recall. Isso reduz a inicialização a frio de minutos para aproximadamente 5 a 10 segundos.
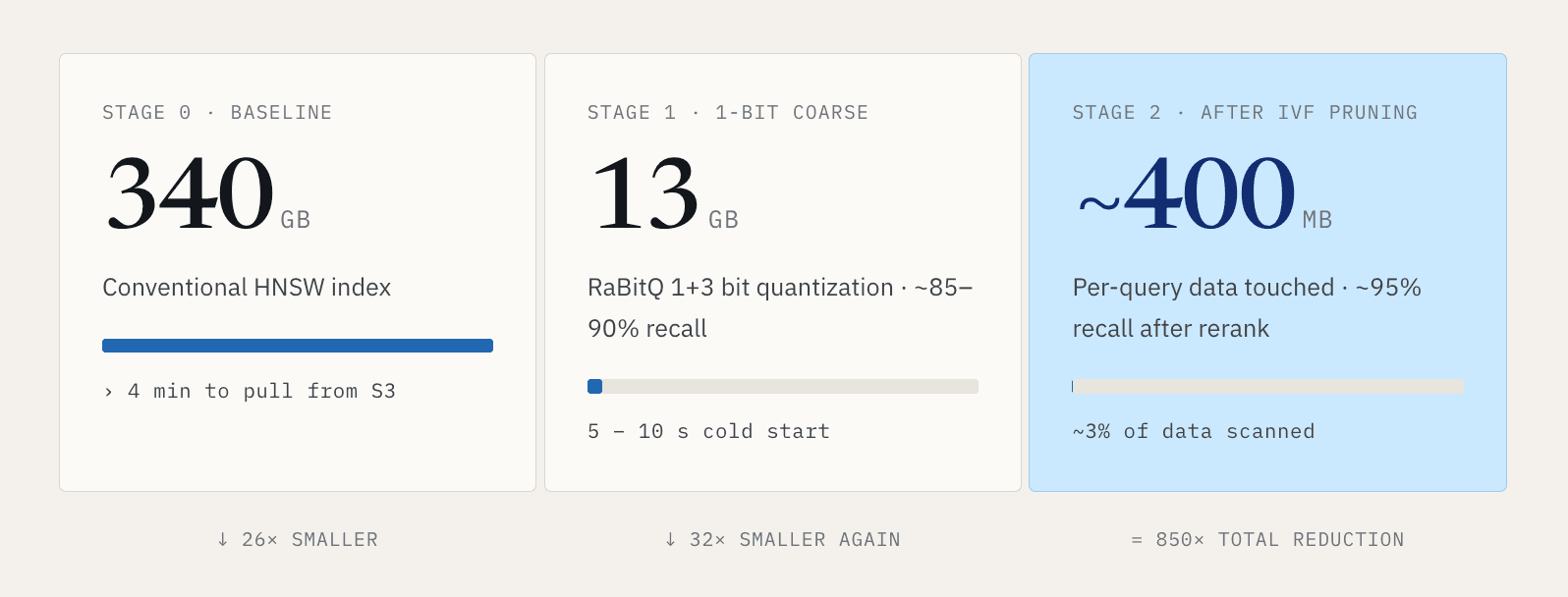
Em seguida, usamos clustering IVF para reduzir a quantidade de dados acessados por consulta. Em uma configuração representativa, cada consulta varre cerca de 3 por cento dos dados. O caminho se torna: 340 GB de índice convencional, comprimidos para 13 GB, com uma única consulta acessando aproximadamente 400 MB após a poda.
Essa é a diferença entre busca vetorial elástica como ideia e busca vetorial elástica como um sistema utilizável.
Amplificação de E/S
A inicialização a frio é apenas um lado do problema. O outro lado é o acesso a registros.
A busca vetorial retorna IDs. Mas as aplicações precisam de registros completos: trechos de texto, metadados, ponteiros de documentos, permissões, timestamps, atributos de imagem ou outros campos. Em um layout Parquet padrão, uma pequena leitura pontual pode forçar o sistema a baixar um grande grupo de linhas. Uma consulta pode precisar de apenas alguns kilobytes de dados úteis, mas acabar puxando dezenas de megabytes do armazenamento de objetos. Reduzir os grupos de linhas ajuda nas leituras pontuais, mas prejudica a compressão e a eficiência da varredura.
É por isso que criamos o Loon, o mecanismo de armazenamento reconstruído por trás do Zilliz Vector Lakebase.
O Loon usa formatos de arquivo mistos, alinhamento de linhas e versionamento baseado em manifestos. Campos escalares podem usar layouts colunares que permanecem eficientes para filtragem e varreduras. Campos vetoriais e dados com muitas consultas pontuais podem usar layouts mais adequados para recuperação de baixa latência. Grupos de colunas alinham IDs de linhas para que o sistema possa buscar os campos de que precisa sem arrastar grandes blocos não relacionados pela rede.
Por baixo dos panos, o Loon usa Vortex, um formato de arquivo open-source sob a Linux Foundation. O Vortex suporta layouts flexíveis e codificações aninhadas, incluindo consultas pontuais sem descomprimir grandes blocos irrelevantes.
Em um teste interno com 3 milhões de linhas, vetores de 128 dimensões, armazenamento S3 e 256 leitores simultâneos, as leituras pontuais do Parquet baixaram cerca de 9,4 MB por leitura. O Vortex baixou cerca de 0,07 MB. Isso representa uma redução de 135x nos dados baixados. A taxa de transferência de varredura completa também foi maior nessa configuração.
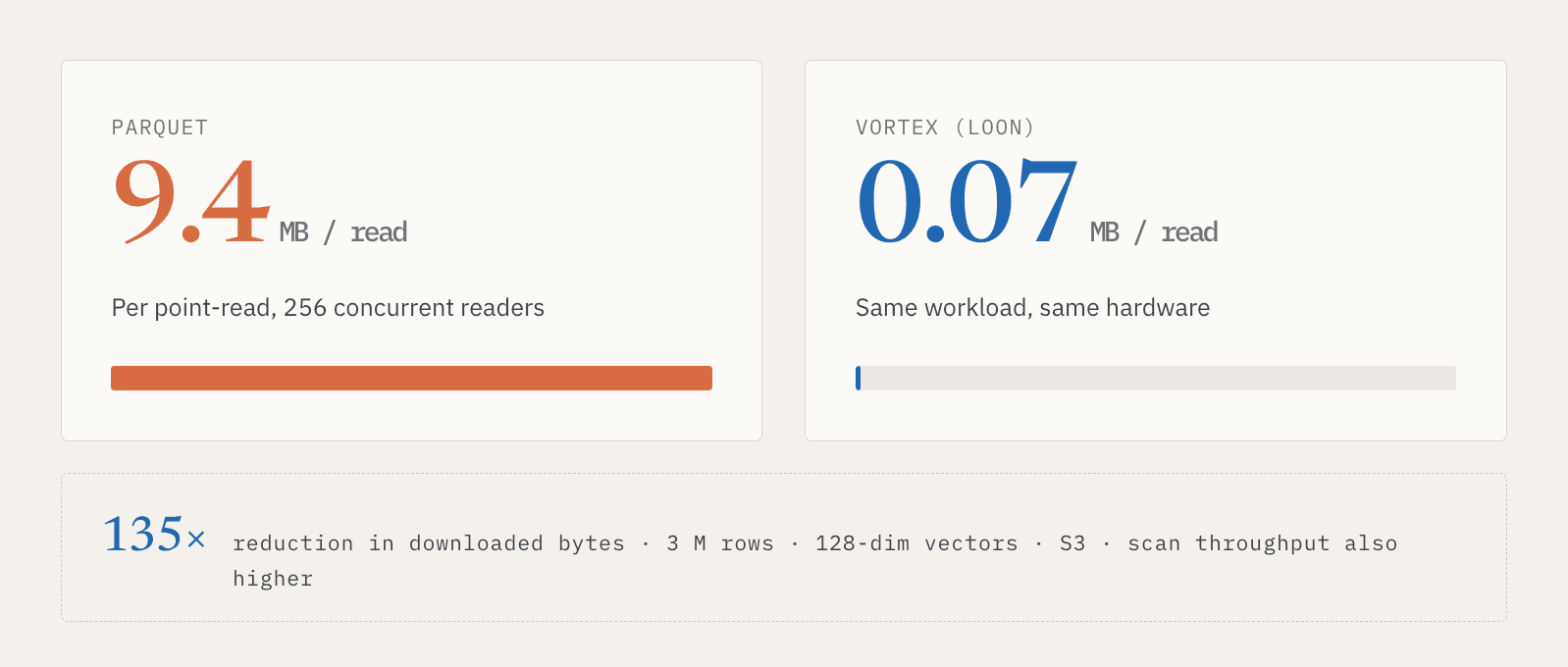
O ponto não é apenas que um formato é mais rápido para um benchmark. O ponto é que serving e discovery precisam de diferentes padrões de acesso sobre os mesmos dados lógicos. Sistemas online precisam de leituras pontuais rápidas. Sistemas em lote precisam de varreduras eficientes. Um Vector Lakebase precisa oferecer suporte a ambos sem forçar os usuários a manter duas cópias dos dados.
Vector Lakebase: uma base de dados, vários modos de computação
Depois que a camada de dados é compartilhada, a computação não pode ser um modelo único para tudo.
Diferentes workloads de IA têm formatos muito diferentes. Algumas precisam de baixa latência previsível o dia todo. Algumas precisam de uma sessão de busca interativa por dez minutos. Algumas precisam de um grande job em lote que roda durante a noite e depois desaparece.
É por isso que Zilliz Vector Lakebase suporta três modos de computação.
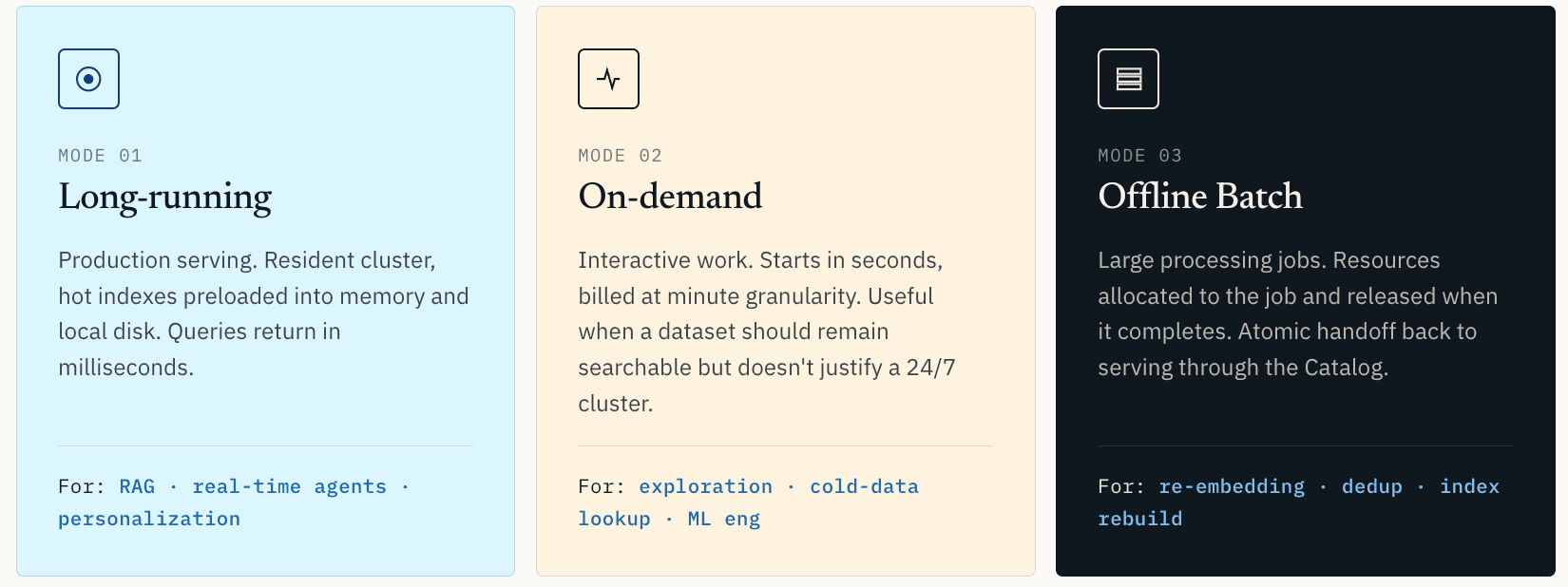
- Computação de longa duração é para serving em produção. O cluster permanece residente. Índices e dados quentes são pré-carregados na memória e no disco local. As consultas retornam em milissegundos. Este é o modo certo para RAG em produção, recomendação em tempo real, personalização, agentes online e qualquer workload em que a latência faça parte da experiência do usuário.
- Computação sob demanda é para trabalho interativo. Ela inicia em segundos e é cobrada com granularidade em nível de minuto. Isso é útil para exploração de similaridade, inspeção de anomalias, recuperação de dados frios ou workflows de engenharia de ML em que o dataset deve permanecer pesquisável, mas não justifica um cluster 24/7.
- Computação Offline Batch é para grandes jobs de processamento: clustering vetorial, deduplicação de dados de treinamento, re-embedding completo, reconstrução de índices e varreduras de qualidade de dados. Recursos são alocados para o job e liberados quando o job é concluído.
A transferência de volta para o serving acontece por meio do Catálogo como um novo snapshot. O serving continua lendo o snapshot antigo até que os novos dados e índices estejam prontos. Então, a nova versão se torna visível de forma atômica. Essa troca atômica importa. A descoberta só é útil se as melhorias puderem retornar à produção sem expor índices pela metade ou dados inconsistentes.
 architecture.png
architecture.png
Um exemplo de cliente mostra por que a distinção importa. Um cliente de direção autônoma tinha um bilhão de vetores de 768 dimensões, mas precisava de apenas cerca de 20 minutos de tempo de consulta online por dia. Executar a carga de trabalho como um cluster de longa duração custava aproximadamente $7.000 por mês. Movê-la para o modo sob demanda reduziu o custo mensal para cerca de $500. O mesmo cliente tinha um fluxo de trabalho de deduplicação que anteriormente gastava cerca de 70 horas fazendo buscas ANN uma por uma. Reformulá-lo como um job em lote offline reduziu o tempo de computação para cerca de 10 horas na mesma classe de recurso.

A lição não é que um modo de computação seja melhor do que outro. A lição é que as cargas de trabalho de dados de IA não têm um único formato, e a arquitetura não deve forçá-las a caber em um só.
O agendamento de recursos passa a fazer parte do Vector Lakebase
Os três modos de computação só funcionam se o agendamento de recursos for tão elástico quanto a própria computação.
Escalonadores de bancos de dados tradicionais geralmente pressupõem um pool fixo de máquinas. Dados esses nós, o sistema decide onde colocar os dados e como balancear as cargas. Esse modelo funciona bem quando a carga de trabalho é estável. Ele se ajusta mal a cargas de trabalho de IA que aparecem em rajadas: uma sessão de busca sob demanda, uma inspeção rápida de dados frios, um job de deduplicação durante a noite, depois horas sem nada.
Nesse mundo, a melhor pergunta não é apenas onde os dados devem ser executados. É se a computação deveria estar em execução.
É por isso que o Vector Lakebase precisa agendar dados e recursos juntos. Na prática, isso significa manter um Warm Pool de nós preparados, anexar dados rapidamente quando o trabalho chega, manter os recursos aquecidos por um breve período após a solicitação e liberá-los quando eles não forem mais úteis.
Isso também muda a economia. Isso não é o mesmo que precificação serverless por solicitação, e não é o mesmo que capacidade mensal dedicada. Para muitas cargas de trabalho de dados de IA, o uso em nível de minuto é a unidade mais natural: pague pela computação enquanto o loop estiver em execução, depois deixe-a desaparecer.
Há uma mudança arquitetural maior por trás disso, de um plano de controle que gerencia um kernel majoritariamente estático para um kernel que entende recursos, estado de cache, snapshots e custo. Isso merece seu próprio post. Para este artigo, o ponto importante é mais simples: sem esse modelo de recursos, Long-running, On-demand e Offline Batch seriam três escolhas de implantação separadas, não três partes do mesmo sistema de dados elástico.
External Collection: encontrando os dados onde eles já estão
Há mais uma realidade para a qual tivemos que projetar.
A maioria das empresas já tem grandes quantidades de dados não estruturados em ambientes de lake: tabelas Lance, tabelas Iceberg, conjuntos de dados Parquet e diretórios de armazenamento de objetos. Pedir que elas movam tudo para um novo sistema antes que possam usá-lo não é realista.
É por isso que criamos External Collection dentro do Zilliz Vector Lakebase. External Collection não é apenas um mapeamento zero-copy. Ele cria uma camada de indexação independente sobre dados externos. Os dados originais permanecem onde estão e continuam sendo governados pela plataforma existente do cliente, enquanto a Zilliz cria e gerencia os índices vetoriais, índices invertidos e índices JSON necessários para tornar esses dados pesquisáveis pelo mesmo caminho de recuperação dos dados nativos.
Nosso princípio interno se tornou simples: Um dado. Um índice. Sem armazenamento duplicado. Sem pipelines de dual-write. Sem caminhos de descoberta fragmentados.
Isso significa que o ciclo CS/CD pode cobrir mais do que os dados já importados para um banco de dados vetorial. Ele pode incluir os ativos de dados não estruturados que as empresas já têm em seus lakes.
O que define a primeira geração do Vector Lakebase
Essas ideias não são apenas arquitetura no papel. Já as estamos lançando no Zilliz Vector Lakebase, e o processo de construí-lo tornou nossa visão da categoria muito mais concreta.
Um Vector Lakebase de primeira geração precisa acertar algumas coisas ao mesmo tempo.

- Primeiro, separação entre armazenamento e computação com cache em múltiplas camadas. Os dados ficam em armazenamento de objetos, e a computação pode escalar de forma independente, inclusive até zero. Mas a separação por si só não é suficiente. A busca vetorial online ainda precisa de memória, disco local, nós aquecidos e execução ciente de cache para manter consultas frequentes rápidas em nível de ms.
- Segundo, gerenciamento unificado para dados não estruturados multimodais. O sistema deve gerenciar não apenas vetores, mas também documentos de origem, imagens, áudio, vídeo, embeddings, metadados escalares, permissões e índices. Um sistema que armazena apenas vetores é um serviço de índice, não uma base de dados.
- Terceiro, recursos nativos de banco de dados vetorial. Busca ANN em milissegundos, gerenciamento do ciclo de vida de índices, busca híbrida, filtragem escalar, recuperação de texto completo, filtragem JSON e múltiplas métricas de similaridade devem estar integrados. Conectar um Lakehouse a um banco de dados vetorial externo não elimina a fragmentação. Apenas cria outro pipeline.
- Quarto, múltiplos modos de computação. Serviço online, interação sob demanda e processamento em lote offline precisam operar sobre os mesmos dados lógicos. A computação sob demanda é especialmente importante porque se torna a ponte entre o serviço de produção e o processamento offline em larga escala.
- Quinto, formatos abertos e nenhuma migração forçada. A camada de armazenamento deve ser legível por mecanismos externos como Spark, Ray e Daft. Tabelas Iceberg existentes, conjuntos de dados Lance e arquivos Parquet devem poder se integrar ao sistema sem cópias desnecessárias. Os dados pertencem ao usuário, não ao mecanismo.
- Sexto, os recursos devem seguir os dados. A computação pode desaparecer quando não é necessária, enquanto os metadados permanecem visíveis e consultáveis. Uma solicitação pode trazer recursos de volta em segundos. Tenants ociosos não devem pagar por computação dedicada que não estão usando. Isso não é apenas autoscaling; exige que o mecanismo tome decisões de recursos junto com decisões de dados.
Essas são nossas crenças atuais, não a palavra final. Continuaremos a revisá-las à medida que o sistema amadurece. Mas uma pressão parece improvável de mudar: os dados não estruturados continuarão crescendo, enquanto os orçamentos de infraestrutura não crescerão no mesmo ritmo. Isso significa que os sistemas de IA precisam se tornar mais iterativos, mais eficientes e mais continuamente adaptativos.
Bancos de dados vetoriais não estão desaparecendo
Então, voltando à pergunta original: isso significa que os bancos de dados vetoriais vão desaparecer? De forma alguma.
Na verdade, a recuperação semântica se torna mais importante nessa arquitetura. Mas seu papel muda.
Os bancos de dados vetoriais se tornam o mecanismo de serviço dentro de um sistema maior de dados não estruturados, muito parecido com a forma como os bancos de dados transacionais permaneceram essenciais dentro da era mais ampla do Lakehouse. Sistemas OLTP não foram substituídos por Lakehouses. Eles se tornaram uma camada dentro de uma pilha de arquitetura maior. Acredito que os bancos de dados vetoriais estão passando pela mesma transição agora.
A mudança mais ampla que acontece por baixo da infraestrutura de IA não é simplesmente sobre recuperação. Trata-se de construir ciclos operacionais contínuos em torno dos próprios dados não estruturados. O serviço gera feedback. A descoberta melhora a qualidade dos dados. Essas melhorias retornam à produção. Cada volta do ciclo torna o sistema melhor.
Todo o resto, incluindo formatos de armazenamento, hierarquias de cache, sistemas de indexação, modelos de computação elástica e agendamento de recursos, existe para tornar esse flywheel economicamente viável em escala.
Ainda não sabemos exatamente o que o Vector Lakebase se tornará nos próximos cinco anos. Quando começamos o Milvus há quase uma década, também não poderíamos ter previsto aonde os bancos de dados vetoriais nos levariam.
Mas uma coisa parece clara agora. Dados não estruturados continuarão crescendo. Modelos continuarão mudando. Agentes gerarão mais rastros, feedback e estado. As equipes precisarão melhorar seus dados mais rapidamente sem permitir que o custo da infraestrutura cresça sem limites.
Os sistemas que tiverem sucesso serão aqueles que fazem o serving contínuo e a descoberta contínua parecerem parte da mesma máquina. Essa é a direção em que estamos construindo.
Zilliz Vector Lakebase está disponível em preview público
Lançamos o preview público do Zilliz Vector Lakebase — uma grande evolução do Zilliz Cloud de um banco de dados vetorial gerenciado para uma plataforma unificada de dados semânticos, combinando serving vetorial de baixa latência com a abertura, escalabilidade e economia de um data lake.
Principais capacidades do Zilliz Vector Lakebase:
- Serving em camadas otimizado para diferentes trade-offs de desempenho-custo em tempo real
- Busca sob demanda para workloads exploratórios ou de grande escala sem computação sempre ativa
- Busca em data lake externo — indexe e pesquise diretamente sobre seus dados existentes no lake
- Busca de espectro completo em vetores, texto, JSON e dados geoespaciais com recuperação híbrida e reranking
- Armazenamento unificado lake-native criado sobre o Vortex, um formato aberto com leituras aleatórias mais rápidas e baratas do que Lance ou Parquet
Se sua stack atual separa serving e descoberta em sistemas distintos, vale a pena dar uma olhada no Vector Lakebase. Experimente no Zilliz Cloud — novos cadastros com e-mail profissional recebem $100 em créditos gratuitos — ou fale conosco sobre seu caso de uso.
Nota: Os números de desempenho e custo neste artigo vêm de resultados do VectorDB Benchmark open source, testes internos e cenários anonimizados de clientes. Os resultados reais variam conforme a escala dos dados, distribuição, parâmetros de índice, formato do workload e configuração de recursos.

Continue lendo

Migrating from S3 Vectors to Zilliz Cloud: Unlocking the Power of Tiered Storage
Learn how Zilliz Cloud bridges cost and performance with tiered storage and enterprise-grade features, and how to migrate data from AWS S3 Vectors to Zilliz Cloud.

Zilliz Cloud Enterprise Vector Search Powers High-Performance AI on AWS
Zilliz Cloud on AWS powers secure, scalable, ultra-fast vector search for enterprise AI apps, with BYOC, sub-10ms latency, and zero-DevOps simplicity.

How to Use Anthropic MCP Server with Milvus
MCP + Milvus: Streamline AI agent development with standardized data access, eliminating integration hassles while enhancing context and flexibility.