




From Text to Speech: A Deep Dive into TTS Technologies
Explore the evolution of Text-to-Speech technology from mechanical devices to neural networks. Learn how TTS works, compare popular models, and implement it using Google Cloud Platform.
Read the entire series
- Top 10 Most Used Embedding Models for Audio Data
- Unlocking Pre-trained Models: A Developer’s Guide to Audio AI Tasks
- Choosing the Right Audio Transformer: An In-depth Comparison
- From Text to Speech: A Deep Dive into TTS Technologies
- Getting Started with Audio Data: Processing Techniques and Key Challenges
- Enhancing Multimodal AI: Bridging Audio, Text, and Vector Search
- Scaling Audio Similarity Search with Vector Databases
Introduction
Text-to-Speech (TTS) technology has evolved into a key player in the world of audio AI, enabling machines to convert written text into human-like speech. With continuous advancements in artificial intelligence, machine learning, and deep learning, these systems have drastically improved in naturalness and clarity. As a result, it is not only making digital content more accessible but also enhancing how machines interact with humans, bridging the gap between technology and the user experience.
Today, TTS technology has become indispensable across a wide range of sectors. Virtual assistants like Siri, Alexa, and Google Assistant rely on text-to-speech (TTS) technology) to deliver spoken responses, while accessibility tools help visually impaired individuals by convert text into audible speech to understand the written text. Content creators, too, leverage this technology for audiobooks, automated news reading, and synthetic voices for podcasts and videos. Furthermore, the ability to generate realistic, customizable voices has opened up exciting possibilities, such as voice cloning and multilingual speech synthesis.
In this blog, we’ll explore the evolution of TTS technologies and analyze the mechanics behind them. We will break down the basic pipeline, examine different synthesis techniques, and discuss its challenges and ethical concerns. Finally, we will implement a TTS solution using the Google Cloud Platform.
Understanding Text-to-Speech (TTS)
Text-to-Speech is an AI-driven technology that converts written text into natural-sounding spoken words. Unlike Automatic Speech Recognition (ASR), which translates spoken language into text, TTS works in the opposite direction by transforming text into speech. Modern TTS systems typically follow a two-stage architecture: first, a text analysis frontend that converts text into linguistic and prosodic features, and second, a speech synthesis backend that generates the actual audio.
First Stage: Frontend
Text Processing: The first step involves preparing the text for synthesis. This includes techniques like expanding abbreviations, handling special characters or converting numbers into their spoken form. These steps ensure that the text is clean and ready for the next stages.
Phonetic Transcription: Once the text is processed, the system converts it into phonemes, the distinct sounds that make up words. This step is essential for accurately capturing how the text should sound when spoken.
Prosody Modeling: To make the speech sound more natural, prosody modeling is introduced. This step adds rhythm, stress, and intonation to the speech, mimicking the flow of human speech. Without prosody, the speech would sound monotonous and robotic.
Second Stage: Backend
- Speech Synthesis: Finally, the system generates the audio waveforms from the processed text, creating the spoken voice that users hear. This is the culmination of all the previous steps and results in a seamless audio output.
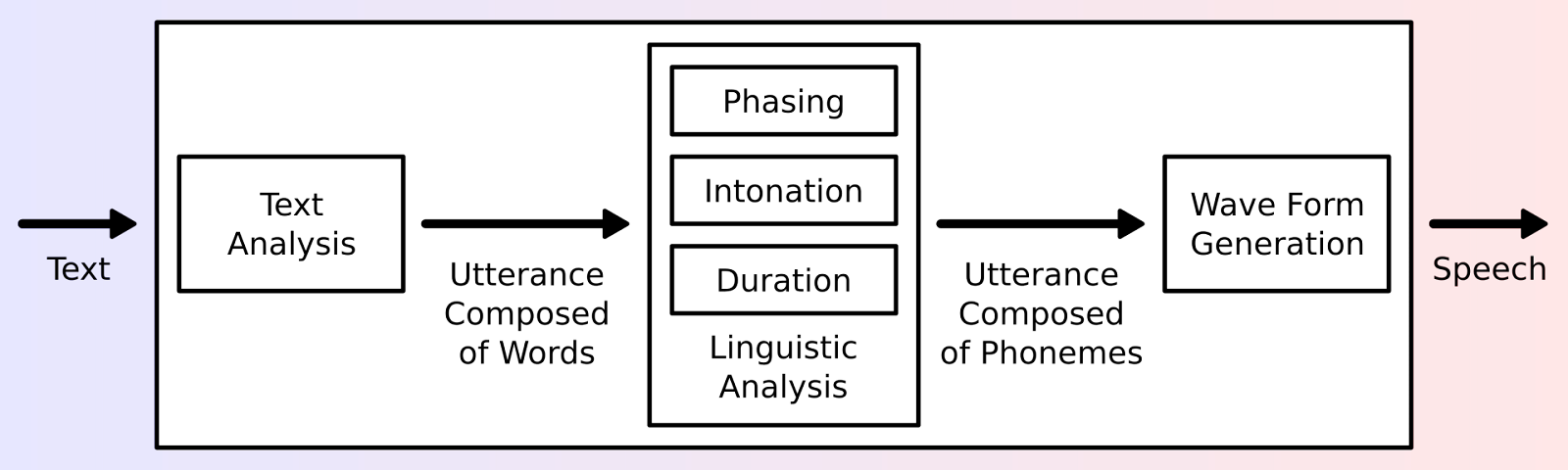
Figure 1: Overview of a typical TTS system (Source)
Together, these components create speech that is not only intelligible but also sounds natural and realistic.
The Evolution of TTS Technology
The development of TTS technology has been marked by continuous advancements from mechanical devices to cutting-edge deep learning models. Let's explore how TTS technology has evolved over the years.
Early Developments
1930s: The First Mechanical Speech Synthesizer - Voder
One of the earliest significant developments in TTS was the creation of the Voder (Voice Operation Demonstrator) in the 1930s by Homer Dudley at Bell Laboratories. The Voder was a mechanical speech synthesizer that used a keyboard to generate human-like speech sounds. It was a groundbreaking invention at the time and set the foundation for future advancements in speech synthesis. The Voder's output, however, sounded quite robotic, as it was based on mechanical sound generation rather than digital or phonetic approaches.
Mid-20th Century: Rule-Based Systems
In the mid-20th century, rule-based systems started to emerge as a method of creating speech synthesis. These systems relied on fixed pronunciation rules (e.g., phonetic rules, stress patterns) that would be applied to text in order to generate speech. The rules were often based on linguistic and phonological principles, but the systems lacked the ability to handle complex variations in language, leading to robotic and monotonous speech.
Late 20th Century: Statistical Methods and Hidden Markov Models (HMMs)
As computing power advanced, statistical methods began to play a key role in improving TTS quality. One of the most significant breakthroughs came in the form of Hidden Markov Models (HMMs). HMMs are statistical models that estimate the probabilities of sequences of speech sounds and use these probabilities to generate more natural-sounding speech. They allowed TTS systems to more effectively handle variability in human speech, such as pitch, speed, and tone, which led to more intelligible and fluid speech output compared to rule-based systems. HMM-based synthesis significantly improved the quality of synthetic speech, especially in applications like automated phone systems and early voice assistants, though the resulting speech still lacked the expressiveness and naturalness of human speech.
Modern Neural Network-Based TTS Technologies
As Text-to-Speech (TTS) technology has advanced, a variety of synthesis techniques have emerged, each offering different benefits in terms of speech quality, flexibility, and application. The introduction of deep learning brought a new era of systems that rely on neural networks to directly generate high-quality speech. Key models like Tacotron, WaveNet, and FastSpeech have revolutionized TTS by using end-to-end deep learning processes.
Advantages: They produce highly natural, expressive, and intelligible speech with significant improvements in prosody and rhythm. They also offer greater flexibility for generating voices that can express different emotions, accents, and speech patterns.
Disadvantages: They often require vast amounts of training data and computational resources.
Key Models:
WaveNet: A deep generative model developed by Google DeepMind that directly generates raw audio waveforms. When used as a vocoder, it converts spectrograms into natural-sounding speech by capturing detailed temporal dependencies, such as intonation, pitch variations, and breathing sounds.
Tacotron Series: Uses sequence-to-sequence learning to generate mel-spectrograms (a perceptually-scaled representation that better matches how humans perceive sound frequencies) from text, which are then transformed into waveforms by a vocoder like WaveNet. Tacotron 2 is known for its high-quality, natural-sounding speech with strong prosody, rhythm, and emotional expressiveness.
FastSpeech Series: These models, compared to the Tacotron Series, replaces the autoregressive nature of Tacotron with a non-autoregressive approach, leading to faster training and inference times but potentially sacrificing some expressiveness.
How TTS Works: Breaking Down the Process
TTS follows a multi-step pipeline to generate high-quality speech. Let’s break down each part of the above two-stages described process with code examples and visualizations to show how each stage works.
Text Preprocessing
Text preprocessing transforms raw input text into a format suitable for speech synthesis. Below is an example of how to normalize text, including some of the most common techniques:
Abbreviation expansion (e.g., "Dr." → "doctor")
Number conversion (e.g., "50.00" → "fifty")
Special characters handling (e.g., "$50.00" → "fifty dollars")
def preprocess_for_tts(text):
# Basic abbreviations dictionary
abbreviations = {
'dr.': 'doctor',
}
# Convert text to lowercase for easier matching
words = text.lower().split()
processed_words = []
for word in words:
# Handle dollar amounts
if word.startswith('$'):
number = float(word.replace('$', ''))
processed_words.append(num2words(number) + " dollars")
# Expand abbreviations
elif word in abbreviations:
processed_words.append(abbreviations[word])
# Convert plain numbers
elif word.replace('.', '').isdigit():
processed_words.append(num2words(float(word)))
else:
processed_words.append(word)
return ' '.join(processed_words)
# Example
text = "Dr. Smith paid $50.00"
processed_text = preprocess_for_tts(text)
print(f"Processed: {processed_text}")
Output:
Processed: doctor smith paid fifty dollars
By performing these preprocessing steps, we ensure that the text is normalized, and ready for further analysis or synthesis in the TTS pipeline.
Phonetic Conversion
Phonemes are the smallest units of sound in speech, and converting text into phonemes is essential for accurate pronunciation. This step allows the system to map written words into their corresponding sounds, making speech generation more natural and intelligible. While we can demonstrate basic phonetic conversion using the phonemizer library, production TTS systems typically use more sophisticated transformer-based grapheme-to-phoneme (G2P) models that consider context and language-specific rules. Here's a basic example using phonemizer.
import phonemizer
# Phonetic transcription of the text
text = "Hello, world!"
phonemes = phonemizer.phonemize(text)
print("Phonetic Transcription:", phonemes)
Output:
Phonetic Transcription: həloʊ wɜːld
Prosody Modeling
In traditional TTS systems like rule-based, prosody was added separately to make speech sound more natural by adjusting pitch, stress, and intonation. These elements are essential for producing human-like speech, as they help convey emotions, emphasis, and conversational flow. However, modern neural TTS models like Tacotron 2 take an end-to-end approach, learning to handle both phonetic conversion and prosody modeling internally during training. Instead of relying on separate rules for phoneme conversion and prosody, these models learn to generate natural-sounding speech directly from text.
from TTS.api import TTS
# Load pre-trained Tacotron model that handles both phonemes and prosody
model = TTS(model_name="tts_models/en/ljspeech/tacotron2-DDC")
# Generate speech with natural pronunciation and prosody
model.tts_to_file(text="Hello, world! How are you today?", file_path="output_with_prosody.wav")
Waveform Generation
After generating the speech features, the next critical step in the TTS pipeline is to convert these features into an actual audio waveform that can be played or saved as an audio file. There are several synthesis techniques for generating waveforms, including:
Concatenative Synthesis: This technique involves putting together pre-recorded speech segments. While it can produce high-quality output, it may sound robotic if the concatenation isn't seamless.
Formant Synthesis: This technique uses mathematical models to simulate the human vocal tract and generate speech. It provides more control over speech characteristics but typically sounds more artificial.
Neural Synthesis: This is the most recent and advanced method, which uses deep learning models to generate highly natural-sounding speech. Modern neural TTS typically follows a two-stage approach: first, a neural network like Tacotron 2 generates mel-spectrograms from text, then a neural vocoder like WaveNet converts these spectrograms into actual audio waveforms. While Tacotron 2 is often paired with WaveNet, other vocoders like HiFi-GAN can also be used, each offering different trade-offs between speed and quality.
In the previous code, we saved the synthesized speech as a Waveform Audio File Format (.wav). To better understand the audio output, we can visualize both the mel-spectrogram and the waveform by plotting the frequency and amplitude of the audio signal over time. By looking at the plots, we can observe how the sound changes in intensity over time, giving us a visual understanding of the speech patterns.
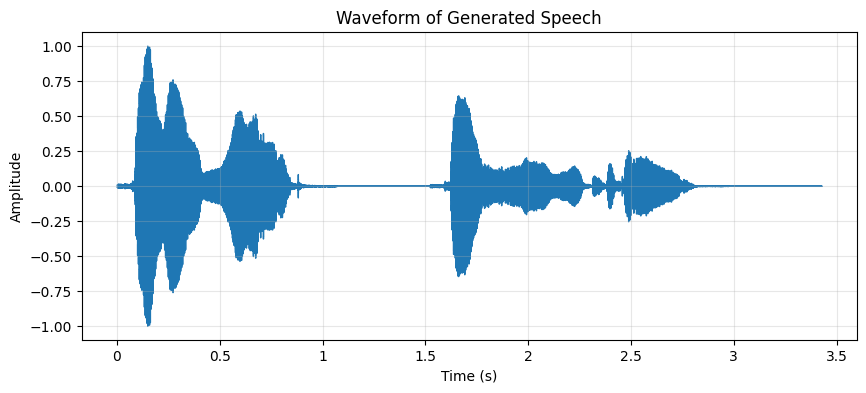
Figure 2: Waveform showing amplitude variations over time
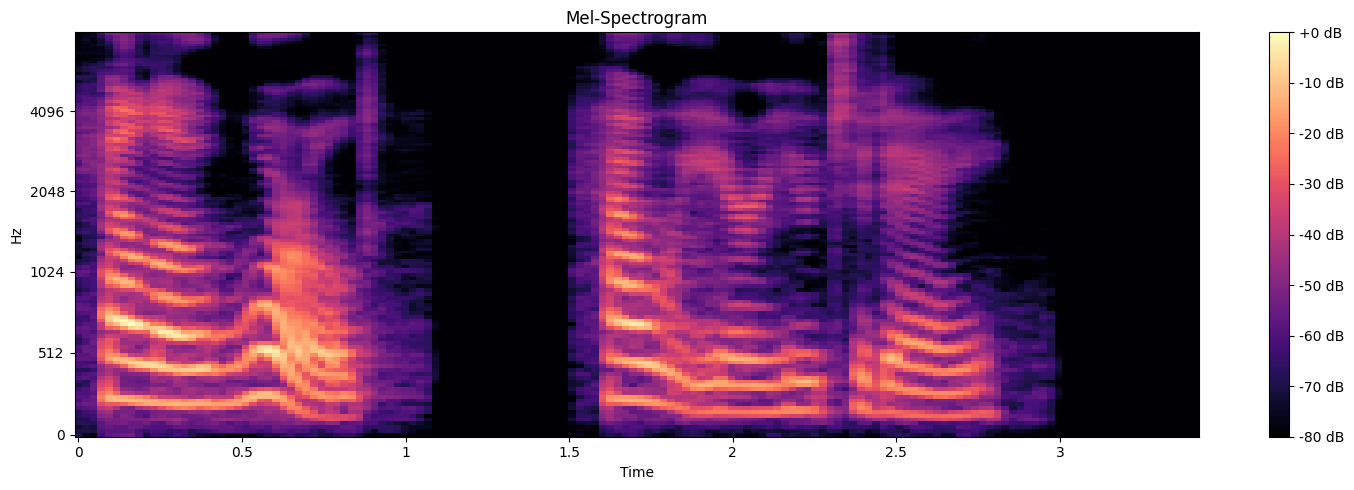
Figure 3: Mel spectrogram showing frequency (Hz) and its intensity (dB) over time
Choosing the Right TTS Model for Your Application
When selecting a Text-to-Speech (TTS) model for your application, it's crucial to consider a variety of factors that can impact the effectiveness of the speech synthesis in your specific use case. Below are some key considerations, followed by an overview of popular TTS models and platforms.
Key Factors to Consider
Voice Quality: The most important factor in many applications is the quality of the generated voice. High-quality TTS systems produce natural, clear, and expressive speech.
Latency: Latency refers to the speed at which the TTS model generates speech. For real-time applications (e.g., virtual assistants, customer service bots), low latency is essential to ensure a smooth user experience.
Language Support: If your application targets users from different linguistic backgrounds, it's important to choose a TTS model that supports a wide range of languages and accents. Some platforms offer a broader selection of voices in different dialects or regional accents.
Popular TTS Models and Platforms
TTS solutions can be broadly categorized into two types: cloud-based services and open-source models. Cloud services like Google Cloud TTS, Amazon Polly, and Microsoft Azure Speech provide production-ready APIs with high reliability but less flexibility. Open-source models like Mozilla TTS allow for custom training and modification but require more technical expertise and computational resources.
| Model | Provider | Features |
| Google Cloud TTS | Supports multiple voices and languages, high-quality neural voices. | |
| Amazon Polly | AWS | Offers customizable voice parameters such as speech rate, pitch, and volume. |
| Microsoft Azure Speech | Microsoft | Provides neural TTS capabilities with a variety of expressive voices. |
| Mozilla TTS | Open-source | Free, open-source, and customizable for developers who want more control. |
These platforms provide a range of options depending on your specific needs, whether you need high-quality natural speech, customization capabilities, or a free and open-source solution for more flexibility.
Challenges and Limitations
While TTS technology has made significant improvements in recent years, several challenges and limitations persist, impacting its overall effectiveness and adoption across diverse applications. These challenges require attention to ensure that TTS systems are both reliable and responsible.
Naturalness and Expressiveness
Despite significant advancements in TTS, naturalness and expressiveness remain areas of concern. While modern models like Tacotron 2 and FastSpeech can generate highly intelligible and clear speech, they still fall short when it comes to conveying emotions as fluidly as a human speaker. Speech may sound robotic or lack the subtle emotional nuances present in human speech.
Multilingual Challenges
Handling multiple languages and accents presents another major hurdle. Languages vary greatly in their phonetic structures, grammatical rules, and speech patterns, making it challenging to create a single model that handles all languages equally well. Additionally, regional accents within the same language often require unique training data to ensure accurate pronunciation and natural sounding speech. TTS models may struggle with underrepresented dialects or languages, leading to issues in global applications where diverse user bases are involved.
Ethical Concerns
As TTS technology becomes more advanced, the ethical implications are a growing concern. One of the primary risks is the potential misuse of TTS for deepfake technology, where synthetic voices are used to impersonate individuals without consent. This could be employed in malicious activities such as spreading misinformation or committing fraud. Furthermore, bias in TTS models is a critical issue. If a model is trained on a skewed or non-representative dataset, it may perpetuate racial, gender, or accent biases, leading to discriminatory outcomes in voice interactions.
Computational Cost
Finally, generating high-quality, natural-sounding speech using advanced neural networks comes with substantial computational costs. Deep learning models like WaveNet and Tacotron 2 require vast amounts of training data and powerful computing resources, often making them inaccessible for smaller companies or personal developers. As a result, optimizing models for both quality and efficiency is an ongoing challenge.
Implementing a TTS Application with Google Cloud
Google Cloud provides a Text-to-Speech API, which makes it easy to integrate high-quality, neural-network-based speech synthesis into applications. This API offers a variety of pre-trained voices, supports multiple languages and accents, and allows customization through features like SSML (Speech Synthesis Markup Language) and voice tuning.
One of the biggest advantages of using Google Cloud's TTS API is that it is not resource-intensive, as all the processing is handled in the cloud. This makes it suitable for applications ranging from virtual assistants and customer support bots to audiobooks and accessibility tools.
Setting Up Your Environment
- Install the Required Libraries: To use Google Cloud's Text-to-Speech API in your Python application, you need to install the
google-cloud-texttospeechlibrary.
pip install google-cloud-texttospeech
Set Up Google Cloud Account and Authentication
Follow these steps to set up your Google Cloud Project and authenticate the API.
Create a Google Cloud project.
Enable the Text-to-Speech API.
Create a service account and a json key.
Download the credentials.json key file.
Set the environment variable to point to the credentials file.
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "credentials.json"
Implement TTS Application
Now that your environment is set up, you can start implementing the text-to-speech functionality using the Google Cloud API.
The
text_to_speech()function takes the input text and converts it to speech using the Google Cloud Text-to-Speech service.You can customize the language, gender (FEMALE, MALE, or NEUTRAL), and specify an optional voice name. For example, voice_name='en-US-Wavenet-C' uses one of the high-quality Wavenet voices.
The speech is saved as an MP3 file.
from google.cloud import texttospeech
# Set up the client for Text-to-Speech API
def setup_tts_client():
# Ensure the environment variable for authentication is set
if 'GOOGLE_APPLICATION_CREDENTIALS' not in os.environ:
raise EnvironmentError("GOOGLE_APPLICATION_CREDENTIALS is not set.")
client = texttospeech.TextToSpeechClient()
return client
# Convert text to speech using Text-to-Speech API
def text_to_speech(text, language_code='en-US', gender='FEMALE', voice_name=None):
client = setup_tts_client()
# Set up the synthesis input and voice parameters
synthesis_input = texttospeech.SynthesisInput(text=text)
# Choose the voice based on gender and language
voice_params = texttospeech.VoiceSelectionParams(
language_code=language_code,
ssml_gender=texttospeech.SsmlVoiceGender[gender],
name=voice_name
)
# Set the audio configuration (audio encoding format)
audio_config = texttospeech.AudioConfig(
audio_encoding=texttospeech.AudioEncoding.MP3,
speaking_rate=1.0,
pitch=0.0
)
# Request speech synthesis
response = client.synthesize_speech(input=synthesis_input, voice=voice_params, audio_config=audio_config)
# Save the audio to an MP3 file
with open('output.mp3', 'wb') as out:
out.write(response.audio_content)
print("Speech saved as output.mp3")
# Example usage
text = "Hello, welcome to the world of text to speech with Zilliz!"
text_to_speech(text, gender='FEMALE', voice_name='en-US-Wavenet-C')
Conclusion
Text-to-Speech (TTS) technology has come a long way, evolving from basic mechanical systems to the advanced neural networks of today. These innovations have significantly improved the naturalness of synthetic voices, making them more human-like and easier to understand. TTS is now widely used in applications such as virtual assistants, accessibility tools, and content generation, offering greater convenience and interaction for users.
The technology's growth has unlocked new possibilities, enhancing user experience in fields like education, entertainment, and customer service. TTS allows for hands-free interactions with devices, helps visually impaired individuals access content, and powers automated systems like chatbots and voice assistants. As AI continues to advance, TTS systems are becoming even more sophisticated, providing more dynamic and personalized voices to meet specific user needs.
Looking ahead, we can expect TTS to become even more seamless, adaptive, and efficient. Innovations in AI will lead to more expressive voices, with enhanced emotion and context sensitivity, making the interactions feel more natural. This will transform how we interact with devices, further enhancing accessibility, communication, and the way we generate and consume content.
Check out the next deep dive: “Choosing the Right Audio Transformer: An In-depth Comparison”
 Benito Martin
Benito MartinFreelance Technical Writer
- Introduction
- Understanding Text-to-Speech (TTS)
- The Evolution of TTS Technology
- How TTS Works: Breaking Down the Process
- Choosing the Right TTS Model for Your Application
- Challenges and Limitations
- Implementing a TTS Application with Google Cloud
- Conclusion
Content
Start Free, Scale Easily
Try the fully-managed vector database built for your GenAI applications.
Try Zilliz Cloud for FreeKeep Reading

Top 10 Most Used Embedding Models for Audio Data
Explore the 10 most popular audio embedding models including Wav2Vec 2.0, VGGish, and OpenL3. Learn how they transform sound into vectors for AI applications

Enhancing Multimodal AI: Bridging Audio, Text, and Vector Search
In this article, we will explore how multimodal AI enhances AI systems by bridging audio, text, and vector search.

Scaling Audio Similarity Search with Vector Databases
Discover how vector databases like Milvus and Zilliz Cloud enable efficient audio similarity search at scale, transforming music recommendations and audio retrieval applications.