




WhyHow
Build more controlled retrieval workflows within your RAG pipeline with WhyHow and Milvus or Zilliz Cloud
この統合を無料で利用するWhyHowとは何か?
WhyHowは、複雑な検索拡張生成(RAG)を実行するために、非構造化データを整理し、文脈化し、確実に検索するためのビルディングブロックを開発者に提供するプラットフォームです。ルールベース検索パッケージ](https://github.com/whyhow-ai/rule-based-retrieval)は、WhyHowによって開発されたPythonパッケージで、高度なフィルタリング機能を追加することで、開発者がRAG内でより正確な検索ワークフローを構築するのに役立ちます。このパッケージは、テキスト生成のためにOpenAIと統合され、効率的なベクトルストレージと類似検索のためにMilvusとZilliz Cloud (フルマネージドMilvus)と統合されている。
なぜWhyHowとMilvus/Zillizを統合するのか?
RAG(Retrieval Augmented Generation)は、より正確な回答を得るために文脈に沿ったクエリ情報を提供することで、大規模言語モデル(LLMs)を強化する先進技術である。しかし、単純なRAGパイプラインでは、正しいデータチャンクを一貫して取得できないことがある。この問題は、検索とLLM応答生成のブラックボックス的な性質、ベクターデータベースから最適とは言えない結果をもたらすユーザクエリの言い回し、あるいは文脈的には関連するが意味的には異なるデータを応答に含める必要性などに起因する可能性がある。
このような課題を克服するためには、生のデータチャンクの検索をより詳細に制御する必要がある。WhyHowとMilvus/Zillizを統合することで、ルールベースの検索ソリューションを構築することができます。このアプローチでは、類似検索を実行する前に、関連するデータチャンクに特定のルールを定義してマッピングすることができ、検索ワークフローの制御を強化することができます。これらのルールを実装することで、クエリの範囲をより的を絞ったチャンクセットに絞り込み、正確なレスポンスを生成するための関連データを取得する可能性を高めます。さらにプロンプトとクエリのチューニングを行うことで、出力品質は継続的に向上させることができる。
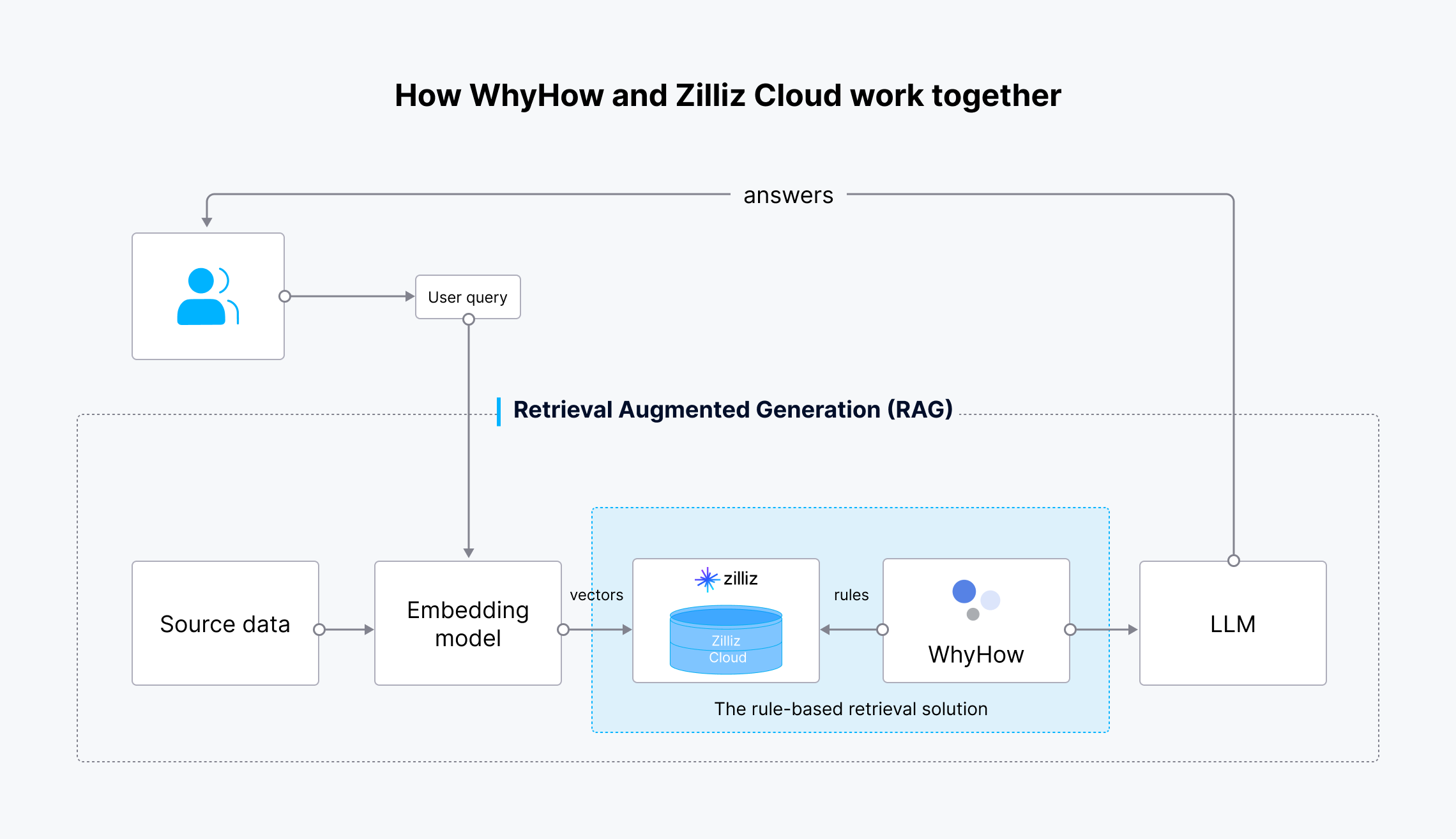
WhyHowとMilvus/Zillizの統合の仕組み
WhyHowとMilvus/Zillizで構築されたルールベースの検索ソリューションは、以下のタスクを実行する:
ベクターストアの作成:** この統合はチャンクの埋め込みを保存するMilvusコレクションを作成します。
分割、チャンキング、埋め込み**:ドキュメントをアップロードすると、MilvusまたはZilliz Cloudに取り込む前に、自動的にドキュメントの分割、チャンキング、埋め込みを行います。このルールベースの検索パッケージは現在、PDF処理、メタデータ抽出、チャンキングのためにLangChainのPyPDFLoaderとRecursiveCharacterTextSplitterをサポートしています。埋め込みについては、OpenAIのtext-embedding-3-small modelをサポートしています。
埋め込みとメタデータをMilvusまたはZilliz Cloudにアップロードします。
自動フィルタリング:** ユーザー定義のルールを使用して、統合は自動的にベクトルストアに対するクエリを絞り込むためにメタデータフィルタを構築します。
この統合のワークフローは以下の通りです:
- ソースデータはOpenAIの埋め込みモデルを用いてベクトル埋め込みデータに変換される。
- ベクトル埋め込みデータは、MilvusまたはZilliz Cloudに取り込まれ、保存・検索される。
- ユーザーのクエリもベクトル埋め込みに変換され、MilvusまたはZilliz Cloudに送られ、最も関連性の高い結果を検索します。
- WhyHowはベクトル検索にルールを設定し、フィルタを追加する。
- 検索された結果と元のユーザークエリはLLMに送られる。
- LLMはより正確な結果を生成し、ユーザーに送信する。
WhyHowとMilvus/Zilliz Cloudの使い方
{kind=link}