




LlamaIndexを始める
大規模言語モデル(LLM)は、2022年のGPTのリリースでAIシーンに大きな波紋を投げかけた。それ以来、多くの人々がLLMアプリケーションを通じて次の大きなものを作ろうと競い合っている。また、LLMアプリケーションをより簡単に、より良く、より速く、より堅牢にするためのツールを作っている人たちもいる。LlamaIndexは、LLMのユースケースを加速し、拡大するための最良のツールの一つである。
Auto-GPTを使用したエージェントによってLLMをより良くする方法の一つをすでに説明しました。次に、LlamaIndexの使い方を見てみましょう。この投稿では、以下を取り上げます:
- LlamaIndexとは?
- LlamaIndexのインデックス
- リスト・インデックス
- ベクターストアインデックス
- ツリーインデックス
- キーワードインデックス
- LlamaIndexの基本的な使い方
- LlamaIndexベクターストアインデックスの問い合わせ
- インデックスの保存と読み込み
- LlamaIndexで何が作れるか?
- LlamaIndexとLangchainの比較
- LlamaIndex概要のまとめ
LlamaIndexとは?
ChatGPT + Vector Database + Prompt as Code (CVP)スタック](https://zilliz.com/blog/ChatGPT-VectorDB-Prompt-as-code)についての投稿の中で、LLMを使う上での多くの課題の一つがドメイン固有の知識の欠如であることを指摘しています。そこで、LLMアプリケーションにドメイン知識を注入するために、CVPスタックを導入します。CVPスタックと同様に、LlamaIndexもデータを注入することで、LLMのドメイン固有知識の欠如に対処するのに役立ちます。
LlamaIndex は、カスタマイズされたプライベートなデータ・ソースを大規模言語モデル(LLM)に接続する、使いやすく柔軟なデータ・フレームワークです。ブラックボックスを少し開けると、LlamaIndexはあなたとLLMの間の管理された相互作用と考えることができます。LlamaIndexは、あなたが提供する入力データを受け取り、その周りにインデックスを構築する。そして、そのインデックスを使って、入力データに関連する質問に答える手助けをする。LlamaIndexは、手元のタスクに応じて様々なタイプのインデックスを構築することができる。ベクトル・インデックス、ツリー・インデックス、リスト・インデックス、キーワード・インデックスを作成することができます。
LlamaIndex のインデックス
LlamaIndexで構築できるインデックスとその仕組み、そしてそれぞれに最適な使用例について詳しく見ていきましょう。LlamaIndexのインデックスタイプはすべて「ノード」で構成されています。ノードはドキュメントのテキストの塊を表すオブジェクトです。
リスト・インデックス
 List index
List index
その名の通り、リスト・インデックスはリストのように表現されるインデックスである。まず、入力データがノードにチャンクされる。次に、ノードを順番に並べます。クエリ時に追加のパラメータを指定しなければ、ノードも順次クエリされます。基本的な逐次クエリに加えて、キーワードや埋め込みを使ってノードをクエリすることもできます。
リスト・インデックスは、入力に沿って順次クエリを実行する方法を提供します。LlamaIndexは、LLMのトークン制限を超えても、入力データ全体を自動的に使用するインターフェイスを提供します。その仕組みは?LlamaIndexは、各ノードのテキストを使ってクエリーを行い、リストの下に行くにつれて、追加データに基づいて答えを絞り込んでいきます。
ベクターストアインデックス
 Vector Store Index
Vector Store Index
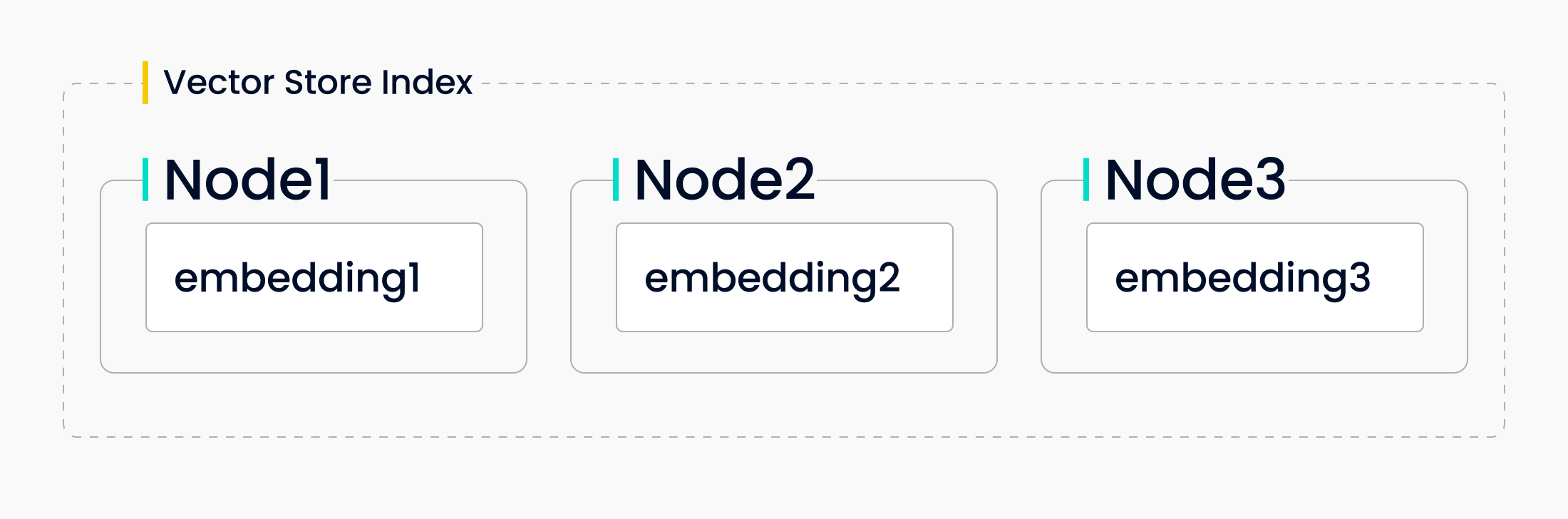
LlamaIndexが提供する次のインデックスは、ベクトルストアインデックスです。このタイプのインデックスは、ノードをベクトル埋め込みとして格納します。LlamaIndexは、これらのベクトル埋め込みをローカルに、あるいはMilvusのような専用のベクトルデータベースに格納する方法を提供します。クエリーされると、LlamaIndexはtop_k個の最も類似したノードを見つけ、それをレスポンスシンセサイザに返す。
ベクトルストア・インデックスを使うことで、LLMアプリケーションに類似性を導入することができる。これは、ワークフローで ベクトル検索 を使って意味的な類似性を求めてテキストを比較する場合に最適なインデックスです。例えば、特定の種類のオープンソースソフトウェアについて質問する場合、ベクトルストア・インデックスを使用します。
ツリーインデックス
 Tree Index
Tree Index
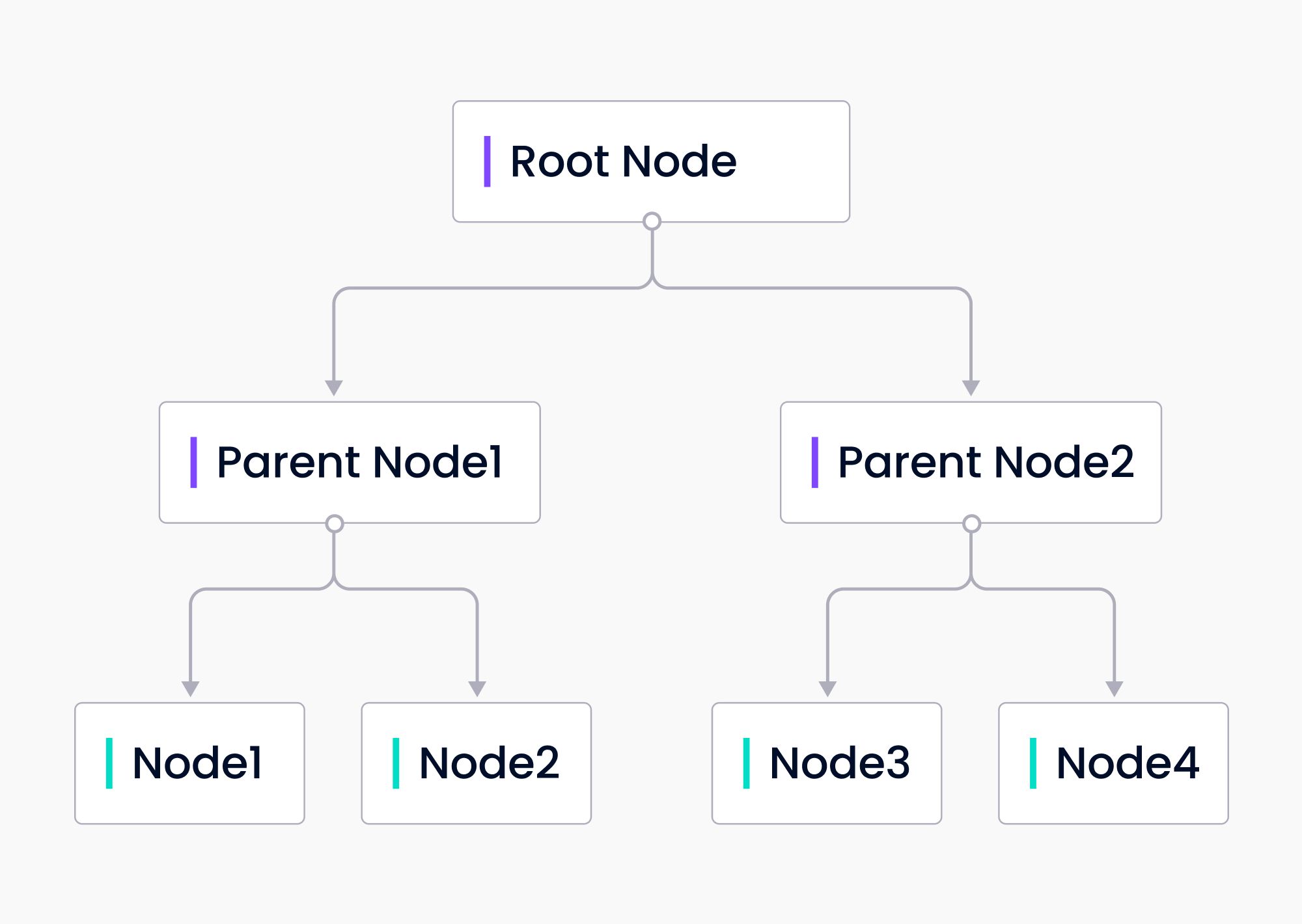
ツリー・インデックスは入力データからツリーを構築します。ツリー・インデックスは、元の入力データの塊であるリーフ・ノードからボトムアップで構築されます。 各親ノードはリーフノードの要約です。LlamaIndexはGPTを使ってノードを要約し、ツリーを構築します。その後、クエリに対する応答を構築する際に、ツリーインデックスはルートノードからリーフノードにトラバースダウンするか、選択したリーフノードから直接構築することができます。
ツリーインデックスは、長いテキストの塊をクエリするための効率的な方法を提供します。また、テキストのさまざまな部分から情報を抽出するために使用することもできます。リストインデックスとは異なり、ツリーインデックスは逐次クエリする必要はありません。
キーワード・インデックス
 Keyword index
Keyword index
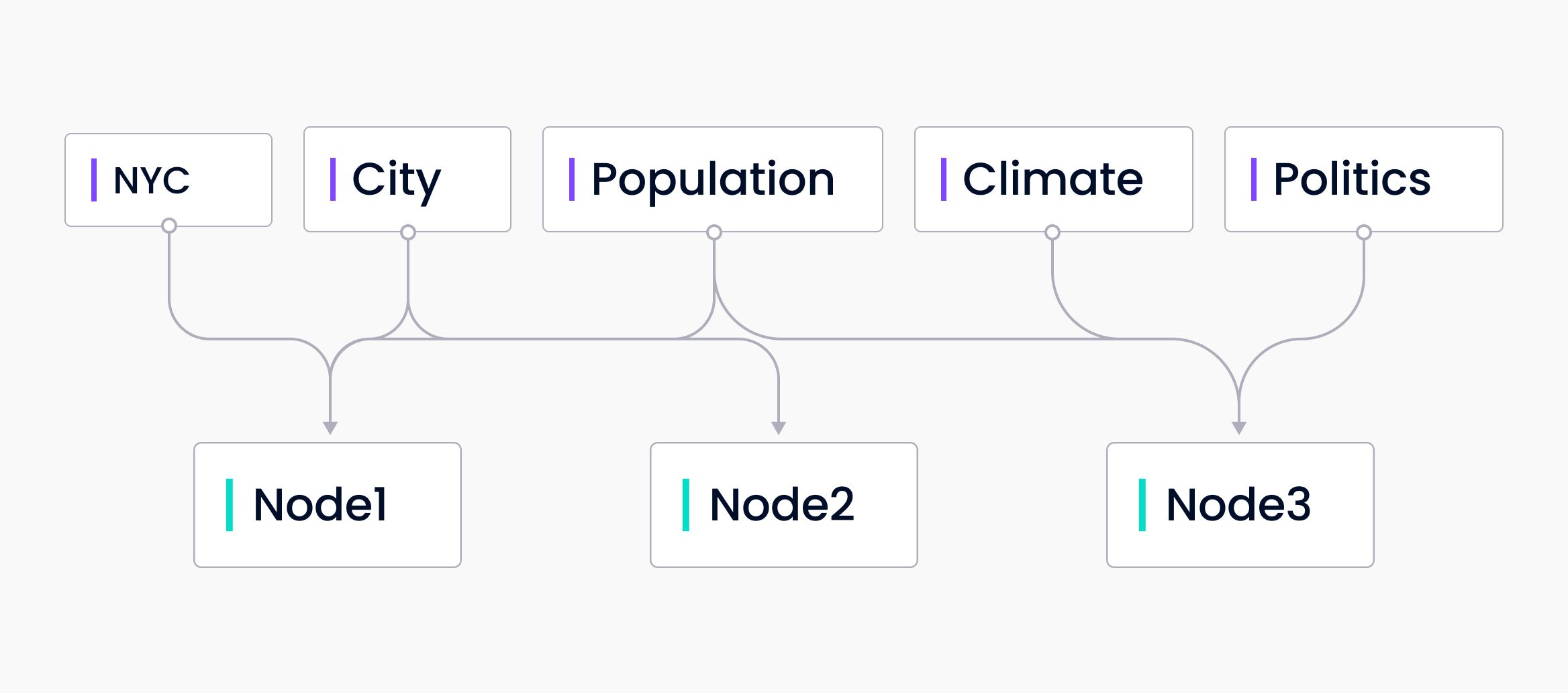
最後に、キーワード・インデックスについて説明する。キーワード・インデックスは、キーワードとそのキーワードを含むノードのマップである。これは多対多のマッピングである。各キーワードは複数のノードを指す可能性があり、各ノードはそれにマップされる複数のキーワードを持つ可能性がある。クエリ時に、キーワードはクエリから抽出され、マッピングされたノードのみがクエリされます。
キーワード・インデックスは、特定のキーワードについて大量のデータをクエリする、より効率的な方法を提供します。これは、ユーザが何のためにクエリを実行しているかが分かっている場合に最も便利です。たとえば、ヘルスケア関連のドキュメントをクエリしていて、COVID 19に関連するドキュメントだけに関心がある場合です。
LlamaIndexの使い方
LlamaIndexの "index "が何を指すかを理解したところで、ベクターストアインデックスの使い方を見てみましょう。このセクションでは、LlamaIndexにテキストファイルをロードする方法、ファイルにクエリーする方法、インデックスを保存する方法の基本を説明します。このコードをすぐに入手したい場合は、こちらのGoogle Colab Notebookを参照してください。提供されているデータを取得するか、LlamaIndex repo をクローンして examples/paul_graham_essay に移動し、提供されているサンプルコードを使用することができます。
LlamaIndexを使う前に、LLMにアクセスする必要があります。デフォルトでは、LlamaIndexはGPTを使う。OpenAI API key](https://platform.openai.com/docs/api-reference)をウェブサイトから入手できます。サンプルコードでは、.envファイルからOpenAI APIキーを読み込んでいます。しかし、お望みであれば、直接ローカルにキーを入力しても構いません。しかし、どこかにアップロードする前に、コードからキーを削除してください!
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
from dotenv import load_dotenv
import os
load_dotenv()
open_api_key = os.getenv("OPENAI_API_KEY")
基本的なことを始めるには、LlamaIndexから2つのライブラリをインポートするだけでよい。GPTVectorStoreIndexとSimplyDirectoryReaderである。この例では、LlamaIndexのレポで提供されている[Paul Graham Essay example](https://github.com/jerryjliu/llama_index/tree/main/examples/paul_graham_essay/data)のデータとフォルダ構造を使用します。レポをクローンしていない場合は、作業ディレクトリにdata` というフォルダを作成してください。
最初のステップはデータをロードすることである。データが格納されているディレクトリ名を指定して SimpleDirectoryReader の load_data() 関数を呼び出す。この例では data である。ここには絶対パスまたは相対パスを渡すことができる。
次にインデックスが必要である。先ほど読み込んだドキュメントに対して GPTVectorStoreIndex から from_documents を呼び出すことで、インデックスを作成することができる。
documents = SimpleDirectoryReader('data').load_data()
index = GPTVectorStoreIndex.from_documents(documents)
LlamaIndex ベクトルストアインデックスのクエリ
上述したように、類似検索を行う必要がある場合、ベクトルストア・インデックスはとても便利です。この例では、テキストの背後にある意味を理解する必要があるクエリをLlamaIndexに与えます。著者は幼少期に何をしていたのか」と尋ねている。これは、LlamaIndexにテキストと「成長すること」の意味を解釈することを要求している。
query_engine = index.as_query_engine()
response=query_engine.query("What did the author do growing up?")
print(response)
レスポンスが表示されるはずです:
著者は短編小説を書いて育ち、IBM1401でプログラミングをし、父親にTRS-80マイクロコンピュータを買うよう口うるさく言った。...
インデックスの保存と読み込み
例題の作業では、インデックスの保存は重要ではありません。実用的な目的では、ほとんどの場合インデックスを保存したい。インデックスを保存することで、GPTトークンを節約し、LLMコストを下げることができます。インデックスの保存は非常に簡単です。インデックスで .storage_context.persist() を呼び出します。
index.storage_context.persist()
 ストレージ
ストレージ
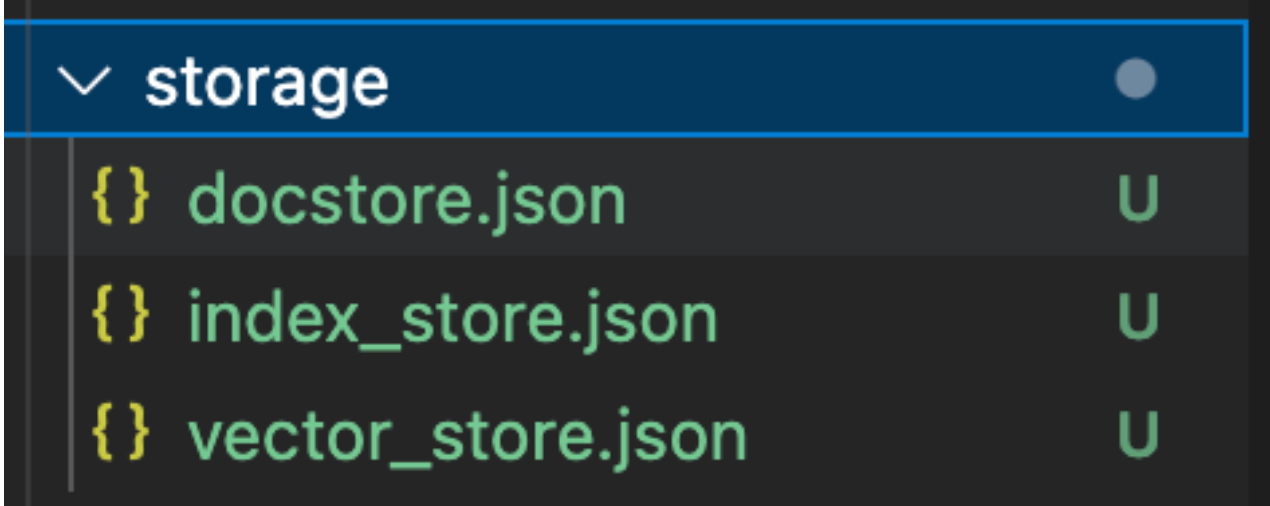
これで storage というフォルダが作成され、3つのファイルが格納される:このフォルダには docstore.json、index_store.json、vector_store.json の3つのファイルが格納される。これらのファイルには、ドキュメント、インデックスのメタデータ、ベクトルの埋め込みデータがそれぞれ格納されている。よりスケーラブルなものが必要な場合は、vector database をベクターインデックスストアとして使用するとよいだろう。
インデックスを保存する意味は、後でロードできるようにするためです。インデックスをロードするには、 llama_index からさらに2つのインポートが必要である。StorageContextとload_index_from_storageである。ストレージコンテキストを再構築するには、StorageContextクラスに永続ストレージディレクトリを渡す。ストレージコンテキストをロードしたら、load_index_from_storage` 関数を呼び出してインデックスを再ロードする。
from llama_index import StorageContext, load_index_from_storage
# ストレージコンテキストを再構築する
storage_context = StorageContext.from_defaults(persist_dir="./storage")
# インデックスのロード
index = load_index_from_storage(storage_context)
LlamaIndexで何が作れるか?
上記のセクションは、LlamaIndexの機能を示すほんの一部に過ぎません。LlamaIndex を使って様々なプロジェクトを作ることができます。LlamaIndexを使って作ることができるプロジェクトの例としては、Q/Aアプリケーション、フルスタックのWebアプリケーション、テキスト分析プロジェクトなどがあります。
LlamaIndexアプリ・ショーケース](https://docs.llamaindex.ai/en/stable/understanding/putting_it_all_together/apps/fullstack_app_guide/)はこちらです。
##LlamaIndexとLangChainの比較
LangChainはLLMを中心としたフレームワークで、チャットボット、Generative Question-Answering (GQA)、要約など幅広いアプリケーションを提供している。このフレームワークの基本的なコンセプトは、様々なコンポーネントを連鎖させ、LLMに基づく洗練された機能やユースケースの作成を可能にする能力である。これらの連鎖は、LLM、メモリ、エージェント、プロンプトテンプレートなど、複数のモジュールからの複数のコンポーネントで構成することができる。
LlamaIndexは、エージェント、チャットボット、プロンプト管理などを利用するのではなく、LLMのインデックス作成と効率的な情報検索に重点を置いています。LlamaIndexはLangChainの検索/ツールとして使うことができ、LangChainエージェントと一緒にLlamaIndexクエリーエンジンを使うことができるように、ツールの抽象化を提供します。また、LlamaIndexコア・リポジトリやLlamaHubにあるデータ・ローダを、LangChainエージェント内の "オンデマンド "データ・クエリ・ツールとして使うこともできます。
LLamaIndex の概要
この投稿では、LlamaIndexにおける "インデックス "とは何かについて学び、LlamaIndexの基本的な使い方のチュートリアルを行い、いくつかの使用例について学びました。また、LlamaIndexのインデックスには、リストインデックス、ベクトルストアインデックス、ツリーインデックス、キーワードインデックスがあります。このため、Zillizのようなベクトル・データベースと非構造化データ、あるいは構造化データや半構造化データ・ソースを接続し、大規模で迅速なクエリを実行するのに理想的である。
基本チュートリアルでは、入力データからインデックスを作成する方法、ベクトルストアのインデックスに問い合わせる方法、インデックスの保存と読み込みの方法を紹介しました。最後に、LlamaIndexで作成できるプロジェクトの例として、チャットボットやウェブアプリなどを紹介しました。
 Yujian Tang
Yujian TangYujian Tang is a Developer Advocate at Zilliz. He has a background as a software engineer working on AutoML at Amazon. Yujian studied Computer Science, Statistics, and Neuroscience with research papers published to conferences including IEEE Big Data. He enjoys drinking bubble tea, spending time with family, and being near water.


