




観測可能性監視を超えた追跡
観測可能性監視を超えた追跡
観測可能性とは何か?
観測可能性とは、システムが生成するデータに基づいて、システム内部で何が起きているかを理解することを意味する。ソフトウェア・システムの「内部を見る」能力であり、その状態や動作を理解する能力だと考えてほしい。これは、"すべてが期待通りに動いているのか?"とか、"なぜ何かが間違っているのか?"といった質問に答えるのに役立つ。何が問題を引き起こしているのかを推測する代わりに、観測可能性はログ、メトリクス、トレースなどのデータを通じて明確な洞察を提供する。
なぜ観測性が重要なのか?
現代のソフトウェアシステムは複雑化している。マイクロサービス](https://zilliz.com/glossary/edge-computing)、クラウド・コンピューティング、コンテナ化などのテクノロジーの台頭により、システムは現在、相互に接続された多くのパーツで構成され、さまざまな場所に分散している。そのため、監視やトラブルシューティングが難しくなっている。
従来のモニタリング・ツールでは、何か問題があることはわかるかもしれないが、その理由はわからない。Observabilityは、システムの内部状態を可視化することで、このギャップを埋め、問題を迅速に特定します。
オブザーバビリティの柱
Observabilityには、システム内部で何が起きているかを明確に把握するための3つの柱がある。それらを分解してみよう:
図- 観測性の柱.png](https://assets.zilliz.com/Figure_Pillars_of_Observability_3f46671e09.png)
図観測可能性の柱
メトリクス
**メトリクスは、システムのパフォーマンスに関する迅速な洞察を提供する数値データポイントです。一般的なメトリクスには、CPU 使用率、メモリ消費量、要求率、応答時間などがあります。例えば、CPU使用率が異常に急上昇していることに気づいたら、それは注意が必要な問題を示している可能性があります。メトリクスは、傾向を特定し、システムの経時的な挙動を確認するのに適しています。
ログ
**ログは、ソフトウェア内部で起こったことを記録する日記のようなものだと考えてください。エラーが発生したり、ユーザーがログインしたり、トランザクションが処理されたりすると、通常、ログに記録されます。ログは、問題を診断し、システムの動作を理解するためのコンテキストを提供します。例えば、何か問題が発生したとき、ログは問題が発生した直前と直後に何が起こったかを突き止めるのに役立ちます。
トレース
**複数のサービスが一緒に動作する複雑なセットアップの場合、トレースは1つのリ クエストがたどった経路と、各サービスでどれだけの時間を費やしたかを示します。トレースはプロセスのボトルネックや遅延を特定します。あるリクエストに予想以上の時間がかかっている場合、トレースはどこで減速が起きているかを知るのに役立ちます。
どのようにObservabilityが機能するか?
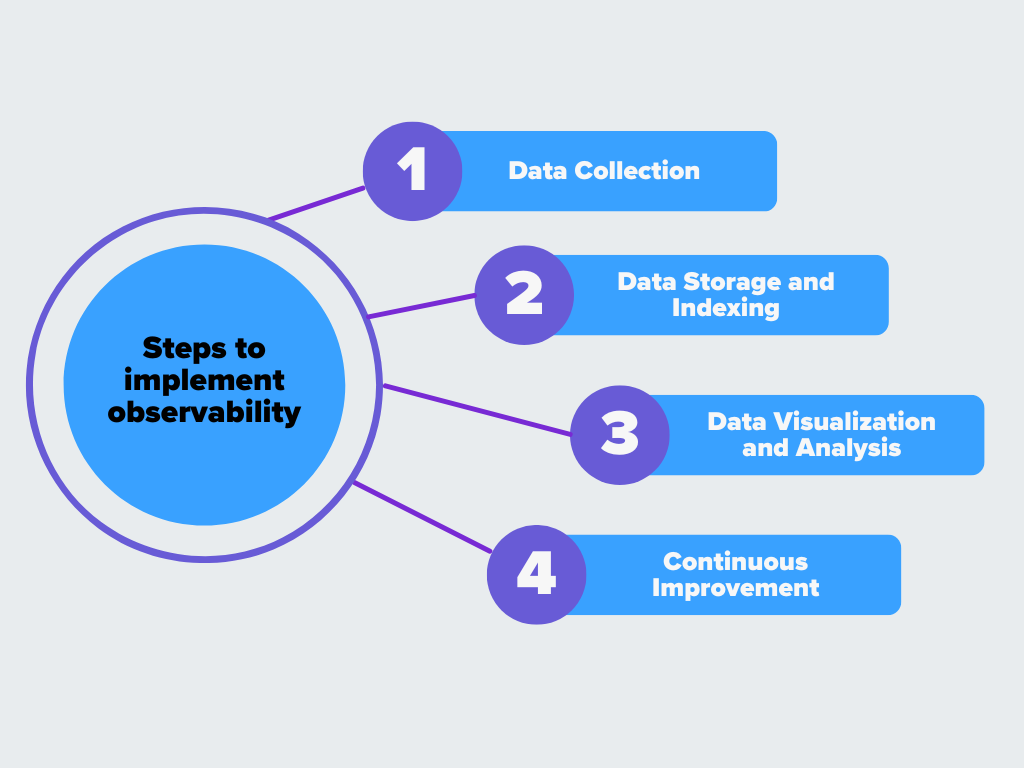
Observabilityはいくつかの重要なステップを踏みます。以下がその仕組みだ:
{kind=link}
図観測可能性を実装するためのステップ
データ収集
最初のステップは、システムのあらゆる部分からデータを収集することである。これには、メトリクス(例えば
CPU使用率)、ログ(詳細なイベント記録)、およびトレース(サービスを 通過したリクエストの経路)を収集することが含まれます。目標は、システムのパフォーマンス、問題、または一般的な動作に関する洞察を提供することができるすべてのものをキャプチャすることです。このデータは、サーバー、アプリケーション、データベース、ユーザーとのやり取りなど、さまざまなソースから得られます。
データの保存とインデックス作成
データを収集した後は、効率的に保管する必要があります。適切に保管することで、必要なときに素早くデータを見つけ、利用することができる。データにインデックスを付けることで、特定の情報を素早く検索して取り出すことができます。例えば、問題が発生した場合、エンジニアはそのインシデントに関連するログやメトリクスを遅延なく簡単に引き出せるようにする必要があります。データを整理し、アクセスしやすくするためには、適切な保管方法が不可欠です。
データの可視化と分析
データを収集することと、それを理解することは別のことである。可視化ツールとダッシュボードはここで重要な役割を果たす。これらのツールは、生データを理解しやすいグラフ、チャート、アラートに変える。可視化することで、チームはシステムのトレンドやパターン、異常な動作を素早く確認することができる。ダッシュボードを使えば、パフォーマンス上の問題を簡単に発見でき、何かおかしいと感じたら、詳細を掘り下げることができます。アラートシステムは、メトリクスが特定のしきい値を超えたときやエラーが発生したときに、リアルタイムでチームに通知することもできます。
継続的改善
観測可能性から得られるデータは、問題を修正するためだけでなく、システムを改善するためでもあります。収集したデータを定期的にレビューすることで、チームは改善や最適化が必要な領域を特定することができる。継続的なフィードバックのループは、システムがより効率的に動作するように機能強化を組み込んでいく。オブザーバビリティのデータは、リソースのスケーリングに関する意思決定の指針となり、ユーザー・エクスペリエンスを向上させ、将来の問題を防止する。
オブザーバビリティの使用例
可観測性は、実世界のアプリケーションに強い影響を与えます。ここでは、観測可能性がどのような違いをもたらすかを示す実用的な使用例をいくつか紹介します:
分散システムにおけるパフォーマンス・モニタリング
複数のサービスが一緒に動作する分散システムでは、パフォーマンスの問題を特定するのが難しい場合があります。Observabilityは、異なるサービスがどのように相互作用しているかを明確に示すメトリクス、ログ、トレースを提供することで役立ちます。例えば、1つのマイクロサービスがアプリケーション全体をスローダウンさせた場合、Observabilityツールはどのサービスがラグを引き起こしているのかを素早く強調することができます。
故障のデバッグとトラブルシューティング
システムが壊れたとき、チームは何が問題だったのかを突き止めます。Observabilityは、イベントの詳細なログとトレースを提供することで、このプロセスをはるかに容易にします。例えば、サーバーがクラッシュしたり、リクエストが失敗したりした場合、ログは失敗の直前に何が起こったかを正確に示すことができます。トレースは、チームが異なるサービス間で問題がどのように移動したかを確認するのに役立つ。
信頼性と可用性
観測可能性は、サービスレベル目標(SLO)とサービスレベル合意(SLA)を満たす上で大きな役割を果たします。これらは、システムの信頼性と可用性を約束するものです。メトリクスとアラートによってシステムの健全性を追跡することで、チームはこれらの目標を達成することができます。例えば、レスポンス・タイムが遅くなり始めた場合、ユーザーが影響を受ける前にチームが対応することで、信頼性の高いサービスを維持することができます。
キャパシティ・プランニングとスケーリング
システムが成長するにつれて、サーバーやメモリなど、より多くのリソースが必要になります。観測可能性は、システムがどのように使用されているかを示すメトリクスを追跡することで、キャパシティ・プランニングに役立ちます。たとえば、CPU 使用率や データベースの負荷を時系列で監視することで、より多くの容量が必要になる時期を予測できます。キャパシティ・プランニングとスケーリングによって、システムは驚くことなくうまく機能する。
プロアクティブな問題検出
観測可能性の最も優れた活用法の1つは、問題が大きな問題になる前にキャッチすることです。リアルタイムのモニタリングとアラートにより、チームはエラー率や応答時間の増加のような異常なパターンやスパイクを検出することができます。プロアクティブなアプローチは、ダウンタイムを防ぎ、スムーズなユーザー・エクスペリエンスを維持することができる。例えば、観測可能性ツールが早期にメモリ・リークを検出した場合、チームはシステムがクラッシュする前に修正することができる。
ユーザー・エクスペリエンス・モニタリング
Observabilityはバックエンドだけでなく、ユーザーのインタラクションや行動も追跡することができる。ページのロード時間、ボタンのレスポンスタイム、エラーメッセージのようなユーザーエクスペリエンスのメトリクスをモニタリングすることで、チームはユーザー向けの問題を素早く特定し、修正することができます。例えば、新しい機能によってページの読み込みが遅くなった場合、オブザーバビリティのデータによってすぐにそれがわかります。
クラウド環境におけるコストの最適化
クラウド環境では、使用したリソースに対して課金される従量課金が行われることがよくあります。Observabilityは、システムのどの部分が最もリソースを使用しているかを追跡することで、チームがコストを最適化するのに役立ちます。例えば、あるマイクロサービスが大量の帯域幅を消費している場合、Observabilityツールはこれを特定することができ、チームはコストを削減するためにサービスを最適化またはリファクタリングすることができる。
観測可能性のためのツールとテクノロジー
Prometheus](https://prometheus.io/)は、メトリクスを時系列データとして収集・保存するオープンソースのモニタリングツールである。柔軟なクエリ機能により、システムやアプリケーションのパフォーマンス監視に広く利用されています。
Grafana](https://grafana.com/)は、Prometheusとよく組み合わされる可視化ツールです。Prometheusのメトリクス](https://zilliz.com/glossary/prometheus-metrics)を視覚化し、データを簡単に解釈し、傾向を監視し、システムの動作に対するアラートを設定するのに役立つインタラクティブなダッシュボードを作成します。
Jaeger](https://www.jaegertracing.io/)は分散トレーシングツールで、マイクロサービスを流れるリクエストを追跡するのに役立ちます。また、複雑な分散システムにおける待ち時間の追跡やボトルネックの特定にも役立ちます。
AWS CloudWatch](https://aws.amazon.com/cloudwatch/) はAmazonの監視・観測ツールで、メトリクスを追跡し、ログを収集し、AWSクラウドリソースのアラートを提供する。他のAWSサービスとうまく統合し、インフラストラクチャを監視・管理することができる。
Google Cloud Monitoring](https://cloud.google.com/monitoring)は、Google Cloud上で動作するアプリケーションやサービスの可視性を提供する。メトリックス、ダッシュボード、アラートを提供し、クラウドリソースの健全性とパフォーマンスを監視します。
Azure Monitor](https://azure.microsoft.com/en-us/products/monitor)は、Azureクラウドのリソースとアプリケーションに完全な可視性を提供するツールです。メトリクス、ログ、トレースを収集し、チームがパフォーマンスを分析し、問題を迅速に解決するのに役立ちます。
最新の観測可能性ツールは、AIと機械学習を使用して異常を検出し、将来の問題を予測する。これらの高度なツールは、自動的にパターンを特定し、異常な動作をチームに警告することができます。
観測可能性の課題
スケーラビリティとデータ量
大量のメトリクス、ログ、トレースを収集、保存、処理することは、成長するシステムにおいて困難となる可能性があります。効率的なデータ管理とスケーラブルなストレージ・ソリューションは、この成長に対応するための鍵です。
データの過負荷
データが多すぎるとチームは圧倒され、有用な洞察を見出すことが難しくなります。ノイズを避けるためには、細かなデータまで追跡するのではなく、問題の診断と解決に直接役立つ実用的なデータにフィルタリングして焦点を当てることが重要だ。
サービス間の統合
最近のシステムは、複数のツールやコンポーネントを使用することが多い。これらの異なるサービス間でシームレスな観測性を維持するには、適切な統合が必要です。これがないと、重要な情報を見逃す可能性があり、ツール間を行き来する時間が無駄になります。
##観測可能性のベストプラクティス
オブザーバビリティの利点を最大限に活用するためには、以下のようなベストプラクティスに従うようにしてください:
観察可能性を念頭に置いた構築
最初から、簡単に観測できるようにシステムを設計する。メトリクス、ログ、トレースをアーキテクチャに組み込み、システムの動作の追跡と理解を容易にします。この積極的なアプローチにより、将来のトラブルシューティングとパフォーマンスチューニングが簡単になります。
システム全体の統一ビュー
すべての観測可能性データを1つのプラットフォームまたはダッシュボードに統合します。統一されたビューは、チームが問題を迅速に特定し、異なるサービスがどのように相互作用しているかを全体的に理解するのに役立ち、複数のソースから情報をつなぎ合わせるのに費やす時間を短縮します。
アラートと通知戦略
明確で意味のある、実用的なアラートを設定します。特定の必要なアクションに結びついた重要なイベントのみを対象とすることで、アラート疲労を回避する。目標は、チームをノイズで圧倒するのではなく、効果的に通知することです。
観測可能性 vs. 監視
よく一緒くたに語られるが、観察可能性とモニタリングは同じではない。以下の表は、この2つの主な違いを示しています:
| アスペクト(Aspect) | ------------------ | ------------------------------------------------------------------------ | -------------------------------------------------------------------- | | 目的|システムの内部状態をより深く理解する。 | 特定のメトリクスを追跡し、問題や異常を検出する。 | | 収集されるデータ:詳細な分析のために、メトリクス、ログ、およびトレースを収集します。 | CPU使用率、メモリ、エラーなどの定義済みメトリクスを収集します。 | | アプローチ|探索的:問題が「なぜ」起こったのかを理解するのに役立ちます。 | リアクティブ:既知の問題が発生したときに通知します。 | | 対象範囲|システム全体の動作とパフォーマンスに関する洞察に焦点を当てます。 | システムの健全性を測定するための個々のメトリクスに焦点を当てる。 | | 未知の問題や根本原因の迅速な特定を支援。 | 既知の問題に対するアラート。 | | リアルタイム分析|システム動作をライブで追跡するリアルタイムデータ分析をサポートします。 | 事前に設定されたチェックとしきい値に依存し、多くの場合、コンテキストが遅れる。| | データの柔軟性|あらかじめ定義された指標を超えた、柔軟で深いデータの探索を可能にします。| より広範なコンテキストを持たずに、事前に選択された特定のメトリクスを監視します。 |
観測可能性とモニタリングの違い
MilvusとZilliz Cloudにおける観測可能性:ベクターデータベースのパフォーマンス追跡
Milvusは、億単位の非構造化データを効率的に扱うために設計されたオープンソースのベクトルデータベースである。セマンティック検索](https://zilliz.com/glossary/semantic-search)、類似検索、GenAIアプリに最適です。観測可能性は、Milvusのパフォーマンスを管理・最適化する上で重要な役割を果たします。オブザーバビリティを実践することで、リアルタイムのレコメンデーションやRAG(retrieval-augmented generation)タスクなど、ベクターデータベースがスムーズかつ効果的に動作することを保証することができます。
オープンソースのMilvusは、Prometheusを統合してパフォーマンスを監視し、Grafanaを統合してすべてのメトリクスを可視化する。MilvusはPrometheusとシームレスに統合されている:
Prometheus Endpoint:様々なエクスポーターからデータを収集します。
プロメテウス・オペレーターPrometheusモニタリングのセットアップ管理を効率化します。
Kube-Prometheus:Kubernetesクラスタ全体の監視を簡素化し、堅牢な運用を実現します。
Prometheusを利用することで、クエリの応答時間やリソースの使用状況(CPU、GPU、メモリ)など、Milvusのパフォーマンスに関する重要なメトリクスを追跡することができ、プロアクティブな問題解決とシステムの最適化が可能になります。さらに、PrometheusをGrafanaと統合することで、モニタリングフレームワークがさらに強化され、GenAIや類似検索アプリケーションに合わせたMilvusデプロイの詳細な分析と効率的なメンテナンスのための詳細なダッシュボードを提供します。
Prometheus for MilvusのセットアップとGrafanaによるメトリックの可視化に関する包括的なガイダンスについては、以下のリソースを参照してください:
PrometheusとGrafanaを使用してベクトルデータベースの検索パフォーマンスのボトルネックを見つける方法](https://zilliz.com/learn/how-to-spot-search-performance-bottleneck-in-vector-databases)
PrometheusでMilvusを監視する|Milvusドキュメント](https://milvus.io/docs/monitor_overview.md)
GrafanaでMilvusのメトリクスを可視化する|Milvusドキュメント](https://milvus.io/docs/visualize.md)
Zilliz Cloudは、Milvusのマネージド版で、より高度な機能と10倍の高いパフォーマンスを備えています。より明確で簡単な監視・観測機能を提供します。Zilliz Cloudは最近、ユーザーがベクターデータベースのパフォーマンスを追跡できるよう、堅牢な監視・観測機能を導入しました。Metricsダッシュボードは、リソース使用量(CPU、メモリ、ストレージ)、パフォーマンス(QPS、VPS、レイテンシ)、データメトリクス(コレクションとエンティティカウント)を含むクラスタの健全性の概要を提供し、これらはすべて、より深い分析のためにカスタマイズ可能です。ダッシュボードは、迅速な洞察のために非常に直感的な方法でメトリクスを表示します。
図:Zillizクラウド監視メトリクス](https://assets.zilliz.com/Figure_1_Screenshots_of_Zilliz_Cloud_Monitoring_Metrics_baec7e105e.png)
図:Zillizクラウド監視メトリクス
Zilliz Cloudでは、問題を早期に発見するために、課金に関するOrganization Alertsと、CU使用量やレイテンシーなどの運用要因に関するProject Alertsを、柔軟な閾値と重大度設定で提供しています。
図:Zilliz Cloudの組織アラート](https://assets.zilliz.com/Figure_2_Screenshot_of_Organization_Alerts_493efb0dbc.png)
図: Zilliz Cloudの組織アラート
図:Zilliz Cloudのプロジェクトアラート](https://assets.zilliz.com/Figure_3_Screenshot_of_Project_Alerts_1d2299185f.png)
図:Zilliz Cloudのプロジェクトアラート
主な機能
リアルタイムモニタリング**によるクラスタパフォーマンスの即時フィードバック
カスタマイズ可能なダッシュボード** 主要なメトリクスに合わせてカスタマイズできます。
柔軟なアラート**により、潜在的な問題を早期に検出します。
複数の通知チャネル**(電子メール、Slack、PagerDuty)。
長期的な計画のためのパフォーマンスの傾向を分析するための履歴データ。
結論
Observabilityは、最新の複雑なシステムの健全性を理解し、維持するためのアプローチです。メトリクス、ログ、トレースを使用することで、チームは信頼できるパフォーマンスを確保し、問題を迅速に解決し、ユーザー体験を向上させることができます。システムの成長と進化に伴い、観測可能性のベストプラクティスを採用することは、問題を先取りし、効率的にスケーリングするために重要である。分散マイクロサービスを実行する場合でも、Milvusのようなツールを使用してAI駆動型アプリケーションを構築する場合でも、可観測性はすべてをスムーズかつ確実に実行し続けるために必要な可視性を提供します。
##オブザーバビリティに関するFAQ
Observabilityとは、メトリクス、ログ、トレースなどのデータを収集・分析することで、システムの内部状態を把握することです。特にマイクロサービスやクラウドネイティブ・アプリケーションのような複雑な最新のセットアップでは、問題の診断、パフォーマンスの監視、システムの信頼性の維持のために重要です。
モニタリングが特定のメトリクスを追跡して問題を検出するのに対して、オブザベイラビリティは問題の背後にある「なぜ」についての洞察を提供することで、より深く掘り下げます。モニタリングはチェックリストのようなものであるのに対して、オブザベイラビリティはシステムの動作や状態を完全に調査するようなものだ。
可観測性のコア・コンポーネントは何ですか?*** 可観測性の3つの柱は、メトリクス(システム・パフォーマンスに関する数値データ)、ログ(詳細なイベント記録)、およびトレース(サービス間のリクエストがたどった経路)です。これらを組み合わせることで、システムの健全性とパフォーマンスの包括的なビューを提供します。
マイクロサービスやクラウドプラットフォームで構築されたような分散システムには、複数の相互作用するコンポーネントがあります。Observabilityは、これらのコンポーネントにまたがる問題の監視とデバッグを支援し、パフォーマンス問題の追跡、ボトルネックの特定、システムの健全性の維持を容易にします。
その他のリソース
- Zilliz Cloudにおける包括的なモニタリングとObservabilityの紹介](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)
ベクター・データベースとは何か、どのように機能するか](https://zilliz.com/learn/what-is-vector-database)
PrometheusとGrafanaを使ったベクターデータベースの検索パフォーマンスのボトルネックの見つけ方](https://zilliz.com/learn/how-to-spot-search-performance-bottleneck-in-vector-databases)
データ分析における時系列の埋め込み](https://zilliz.com/learn/time-series-embedding-data-analysis)