




スケーラブルで信頼できる分散コンピューティングへのシンプルなガイド
スケーラブルで信頼できる分散コンピューティングへのシンプルなガイド
分散コンピューティングとは、パフォーマンス、スケーラビリティ、信頼性を高めるために、接続された複数のコンピューター間でタスクやプロセスを実行することである。1台の強力なマシンに依存する代わりに、作業負荷を複数のノードに分割することで、より大きなデータセットや計算をより効率的に処理することができる。このアプローチは、電子商取引プラットフォーム、機械学習パイプライン、リアルタイム分析、IoTセンサーネットワーク、高性能研究シミュレーションなど、多くの最新データ駆動型アプリケーションのバックボーンを形成している。
分散コンピューティング](https://assets.zilliz.com/Distributed_Computing_a477b8ca7c.png)
図:分散コンピューティング
シングルサーバーから分散システムへ:進化
長い間、多くの組織がアプリケーションを実行するために、しばしばモノリシック・アーキテクチャと呼ばれる大規模な集中型サーバーに依存していた。しかし、このセットアップにはいくつかの明確な欠点があった:
限られたスケーラビリティ:限られたスケーラビリティ:容量を増やすことは、より大きなサーバーを購入することを意味し、それは高価で時間のかかることでした。
単一障害点**:メインサーバーがダウンすると、システム全体が停止してしまう。
複雑なアップデート**:すべてが一箇所に収容されているため、変更やアップグレードを行うのは危険だった。
より小さなサーバーをグループ化したクラスターは、ある程度の救済にはなりましたが、それでもスケーリングと信頼性の問題を完全に解決することはできませんでした。そこで登場したのが分散コンピューティングだ。複数の接続ノードにタスクとデータを分割することで、分散システムが実現する:
より速く、より安価に**スケールすることができます:大規模なサーバーを1台置き換える代わりに、ノードを増やすことができます。
フォールトトレランスの向上**:1つのノードに障害が発生しても、他のノードがシステムをオンラインに保つことができます。
重いワークロードの処理**:複数のノードが連携することで、大量のデータをより効率的に処理できます。
Zilliz](http://zilliz.com)のMilvusのような最新のソリューションは、膨大な量の高次元データを管理するために、これらの原則に基づいて構築されている。Milvusは複数のノードにデータを分散することで大規模な類似検索をサポートし、厳しい条件下でも高いパフォーマンスを維持する。
分散コンピューティングはどのように機能するのか?
分散コンピューティングとは、複数のマシン(またはノード)が協力して、単一のマシンでは困難または非効率なタスクを達成するモデルです。分散システム内の各ノードは、データの保存や計算処理など特定の機能を実行することができ、システムはこれらのタスクを統合して全体として動作します。したがって、このアプローチは、より高いパフォーマンス、より優れたフォールトトレランス、柔軟なスケーリングオプションにつながる。
コア・プリンシプル
タスク分散](https://zilliz.com/ai-faq/how-does-data-distribution-work-in-a-distributed-database):**分散コンピューティングの主な考え方は、大きなジョブを小さなタスクに分割し、様々なノードに割り当てることです。ワークロードを分割することで、各ノードが並行して作業を行うことができ、処理を高速化し、1台のマシンが過負荷になるのを防ぎます。
データ分割](https://zilliz.com/ai-faq/what-is-data-partitioning-and-why-is-it-important-in-distributed-databases):**データはセグメント(しばしば「シャード」と呼ばれる)に分割される。各ノードは1つ以上のセグメントを保存し、並列読み書きを行う。これにより、データアクセスが高速化され、スケーリングが容易になります。データが大きくなったら、ノードを追加してさらに分割します。
同期と調整: タスクとデータが分散しているため、ノードの同期を維持し、競合する更新を防ぐことが重要になります。分散システムは、各ノードが一貫したデータビューを維持するために、コンセンサスメカニズムなどのプロトコルやアルゴリズムを使用します。これらの方法は、システムのすべての部分が同時に発生した場合でも、変更に同意するのに役立ちます。
分散システムの構成要素
分散システムの構成要素](https://assets.zilliz.com/Components_of_Distributed_System_2acfc078bf.png)
図:分散システムの構成要素
ノード(またはホスト)***:各ノードはタスクを実行したり、データを保存したりする。多くの場合、ノードは物理サーバ、仮想マシン、コンテナである。Milvusのようなシステムを使用する場合、各ノードはベクトルインデックスのセグメントを保持することができ、単一のマシンに負担をかけることなく、大規模なデータセットを分散検索することができる。
ネットワークネットワークはすべてのノードをつなぐ接着剤である。結果を共有し、互いに更新するために、マシン間でデータとメッセージを伝送します。シームレスな通信には、信頼性が高く高速なネットワーク接続が不可欠です。
ロードバランサー**:複数のノードが入ってくるリクエストを受け入れる準備ができたら、ロードバランサーがトラフィックを均等に分散します。これにより、どのノードも一度に多くのリクエストを処理することを防ぎます。負荷を分散することで、システムはトラフィックの急増に対応し、安定したパフォーマンスを維持することができます。
データベース・サーバーデータベースサーバーは、複数のノードにまたがる構造化または非構造化データの保存、管理、検索を担当します。分散アーキテクチャーでは、データベースはシャード化(さまざまなノードでデータをより小さなチャンクに分割)したり、複製(フォールトトレランスのためにノード間でデータのコピーを保持)したりすることができる。
メッセージキューと調整サービス**:分散システムは、しばしばメッセージングツール(Apache KafkaやNATSのような)や、ノード通信を管理するための調整サービス(ZooKeeperのような)に依存する。これらのツールは、タスクのスケジューリング、進捗の追跡、2つのノードが同時に同じ作業を実行しないことを確認するのに役立つ。また、システム全体のアナウンス(ノードがオンラインになったときやオフラインになったときなど)を処理し、システムの他の部分が適応できるようにします。
分散コンピューティングアーキテクチャの種類
分散コンピューティングは、ノードがどのように相互作用し、責任を分担するかによって、多くの形態をとることができます。以下は、Milvusデータベースを含む様々なシナリオでの動作例とともに、一般的なアーキテクチャをいくつか紹介します。適切な分散アーキテクチャの選択は、ワークロードのサイズ、レイテンシ要件、およびコスト制約に依存します。
分散コンピューティングの種類](https://assets.zilliz.com/Types_of_Distributed_Computing_524a467d73.png)
**図:分散コンピューティングの種類
**1.クライアント・サーバーモデル
クライアント・サーバー・モデルでは、1つ以上の中央サーバーが複数のクライアント・デバイスからのリクエストを処理する。各サーバーは通常、個々のクライアントよりも強力で、主要なビジネスロジックやデータストレージをホストしている。クライアントはリクエスト(データのフェッチや計算の実行など)を送信し、サーバーはリクエストされた情報や結果で応答する。
長所明確な役割分担、集中管理、簡素化されたセキュリティ管理。
短所サーバーがダウンした場合、クライアントがサービスにアクセスできなくなる可能性がある。また、リクエストがサーバーの容量を超えた場合、スケーリングが困難になる可能性がある。
**2.ピアツーピア(P2P)ネットワーク
ピアツーピア・アーキテクチャは、すべてのノードを対等に扱います。各ノードはクライアントとしてもサーバーとしても機能し、中央サーバーに依存せずにリソースやファイルを共有します。このアーキテクチャでは、ノードは互いに直接接続します。単一の権威あるサーバーにデータを要求する代わりに、ピア同士でデータを交換します。
長所単一障害点がないため、ピア数を増やすことによるスケーリングが容易です。
短所完全に分散化された環境では、データの一貫性とサービス品質の管理が難しくなる可能性がある。
**3.クラスター・コンピューティング
クラスタ](https://docs.zilliz.com/docs/cluster)は、1つのシステムのように見えるほど密接に連携して動作するサーバーのグループです。タスクはノード間で分割して並列処理できるため、クラスター コンピューティングは高性能なワークロードに適しています。クラスタ内のサーバーはストレージを共有することが多く、タスクはスケジューリングシステムやロードバランサーによってサーバー間で分割される。1台のサーバーに障害が発生しても、他のサーバーは稼働を継続できます。
Milvusアーキテクチャ](https://zilliz.com/blog/introduction-to-milvus-architecture):** Milvusはクラスタ化されたノードを使用して大量のベクトルデータを管理する。ベクトルインデックスを複数のマシンに分散することで、数十億の高次元ベクトルを効率的に処理することができます。このクラスタリング・アプローチは、特に大規模な検索やレコメンデーション・ワークロードを扱う際のパフォーマンスと耐障害性を向上させます。
長所**:並列処理と耐障害性に優れている。
短所管理が複雑で、ハードウェアへの投資額が高くなる可能性がある。
**4.クラウドとエッジ・コンピューティング
クラウド・コンピューティングは、インターネット上でオンデマンドのリソース(仮想マシン、ストレージ、サービスなど)を提供する。エッジ・コンピューティング は、処理とデータ・ストレージをデータ・ソース(IoT デバイスなど)の近くに配置し、待ち時間を短縮する。クラウド・コンピューティングでは、組織はクラウド・プロバイダーが管理するリモート・サーバー上でアプリケーションを実行する。容量は通常、短期間で拡張可能である。エッジコンピューティングでは、デバイスによって生成されたデータはローカルまたは近くのエッジデータセンターで処理され、すべてを中央のクラウドに送信する必要性が減少する。
長所弾力的なスケーリング、柔軟性、潜在的な運用コストの削減。また、エッジ・セットアップにより、一刻を争うタスクの応答性が向上する。
短所クラウドコンピューティングの場合)安定したネットワーク接続が必要。
**5.マイクロサービス
マイクロサービスは、アプリケーションをより小さく、疎結合のサービスに分割し、ネットワーク上で通信する。各サービスは、ユーザー認証やデータのインデックス作成など、特定の機能を処理する。サービスは別々のマシンやコンテナ上で実行できる。サービスは通信用のAPIを公開し、特定のワークロードに合わせて独立して拡張することができる。
長所システム全体に影響を与えることなく各サービスを変更できるため、アップデートが簡素化される。また、最も使用頻度の高いサービスのみにノードを追加することで、特化したスケーリングが可能になる。
短所は**、スムーズな機能を確保しながら多くのサービスを管理するために複雑さが増すことです。アップデートの監視、ロギング、デプロイには慎重な計画が必要です。
分散コンピューティングの使用例
分散コンピューティングには、幅広い最新のソリューションがあります。以下は、相互接続されたノード間でワークロードとデータを分割することで組織が恩恵を受ける、最も一般的なシナリオの一部です:
ビッグデータ解析とリアルタイム処理:** 組織は大規模なデータセットを複数のノードで並行して実行し、分析を高速化します。データは流入し続け、更新はほぼ瞬時に行われます。これは、迅速な洞察が意思決定の指針となる金融、ヘルスケア、電子商取引の分野で極めて重要です。
機械学習とAIモデルのトレーニング:** 複雑なモデルは、多くのマシンで同時に計算が実行されることで、より速くトレーニングされます。このセットアップは、大規模な特徴セットを効率的に処理し、全体的なトレーニング時間を短縮します。画像認識、NLP、パーソナライズされたレコメンデーションなどで一般的です。
トラフィックの多いウェブ・アプリケーションと電子商取引:*** リクエストは複数のサーバーに分散されるため、1台のマシンが圧倒されることはありません。1台のサーバーに障害が発生しても、残りのサーバーが稼働し続けるため、大きなダウンタイムを回避できます。柔軟なスケーリングにより、ホリデーセールのような突然の急増にも簡単に対応できます。
モノのインターネット(IoT)とセンサー・ネットワーク:***多数のセンサーが分散ノードにデータを供給し、分散ノードは迅速な対応のために発信源の近くでデータを処理する。このローカライズされたアプローチは監視を向上させ、リアルタイムのアラートに役立つ。スマート・シティ、製造業、コネクテッド・カーなどで広く採用されている。
科学研究および高性能コンピューティング(HPC):** 気候シミュレーションのような重いタスクは、並行して実行される小さなジョブに分割されます。これにより、計算時間が大幅に短縮され、グローバルな科学的共同研究がサポートされます。研究者はモデルをより速く改良し、イノベーションを推進することができます。
コンテンツ・デリバリー・ネットワーク(CDN):**世界中のサーバーにファイルやメディアを保存し、ユーザーが最も近いノードからコンテンツにアクセスできるようにします。このセットアップにより、ロード時間やネットワーク遅延が短縮されるため、ストリーミング・サービスや大容量ファイルのダウンロード、トラフィックの多いウェブサイトには不可欠です。
分散システムの利点
組織は、増え続けるデータや計算タスクを処理するために分散システムを利用しています。以下は、チームのスケールアップ、回復力の維持、および効率的な作業を支援する主な利点です:
スケーラビリティとリソース共有: **分散アーキテクチャは、組織が1台の大型サーバーに依存するのではなく、ワークロードの増加に応じてマシンを追加することを可能にします。システムはボトルネックを回避し、データとタスクを複数のノードに分割することでスループットを向上させます。
フォールトトレランスと冗長性:** 重要なデータとタスクが複数のノードに複製されている場合、1つのノードに障害が発生してもシステムは稼働し続けることができます。この設計により、ダウンタイムを短縮し、ユーザーアクセスを維持します。
柔軟でモジュール化された設計:** 分散システムは多くの場合、タスクをより小さく独立したモジュールに分割します。各ノードが特定のタスクを処理するため、環境全体を中断することなく、コンポーネントの更新や交換が容易になります。
一貫性と可用性のバランス (CAP定理):**分散システムにとって、特にネットワーク問題が発生したときに、一度に完全な一貫性と常時可用性を保つことは難しい。正確なトレードオフは、それぞれのユースケースにおいて、即時の一貫性がどれだけ重要であるかによって決まります。
分散システムはタスクを並列に実行することで、より多くの処理をより短時間で処理することができます。これは、ビッグデータ分析やリアルタイムのベクトル検索に不可欠です。
課題と考察
分散システムには多くの利点がある一方で、独特の複雑さもある。以下は、分散インフラを構築・維持する際に留意すべき一般的な障害や要因である:
ネットワーク遅延と帯域幅の制限:** ネットワーク接続が弱かったり、過負荷であったりすると、離れたサーバーにまたがるタスクが遅くなることがある。帯域幅が制限されている場合、大きなデータ転送がボトルネックになる可能性があります。ユーザーの近くにノードを配置したり、データをキャッシュすることで、レイテンシを減らすことができます。
データの一貫性とパーティション耐性: データが複数のノードに保存されている場合、すべてを同期させることは困難な場合があります。ネットワーク障害やノードの停止は、慎重な処理を必要とする競合を引き起こす。迅速な更新を好むシステムもあれば、厳密な正確さを優先するシステムもある。
セキュリティとデータプライバシー:***データはマシン間を移動するため、漏洩や不正アクセスのリスクが高まる。暗号化と厳格なアクセス制御が機密情報の保護に役立ちます。定期的な監査とコンプライアンス・チェックにより、ユーザー・データは確実に保護されます。
分散トランザクションの管理:** 1つのトランザクションに複数のサービスやノードが関与することがあり、調整が複雑になります。二相コミットやトランザクションマネージャのようなプロトコルは、これらのステップを追跡する。注意深いロールバック戦略により、部分的な失敗によるデータの破損を防ぐことができる。
Milvusの紹介: クラウドネイティブな分散ベクターデータベース
Milvusは、高次元のベクトルデータを管理するためのクラウドネイティブ、分散システムとして一から設計されています。データと処理を複数のノードに分割することで、Milvusは分散コンピューティングの中核的な利点であるスケーラビリティ、フォールトトレランス、並列実行を実現し、AIモデルのトレーニング、リアルタイムのレコメンデーションシステム、複雑な分析に適しています。
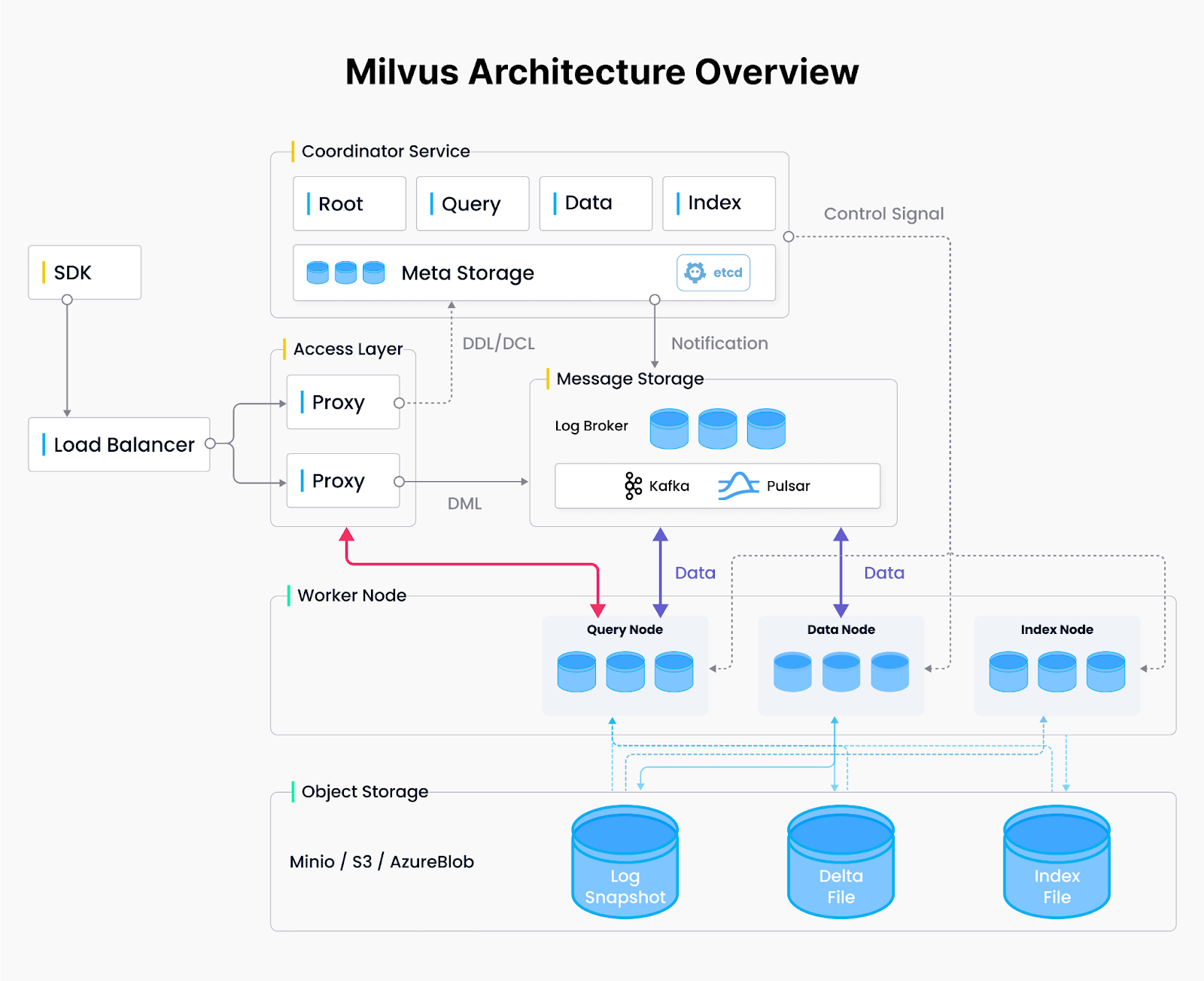 Milvusアーキテクチャ.png
Milvusアーキテクチャ.png
図: Milvusアーキテクチャ
Milvus分散アーキテクチャ:4層設計
Milvusは広く使われているベクトルデータベースであり、4つのレイヤーからなる分散システムアーキテクチャを採用し、リソースを最も必要な場所に動的に割り当てる。
アクセス・レイヤ:***ステートレス・アクセス・ノードは、システムへのエントリー・ポイントとして、入ってくるリクエストを処理する。
調整レイヤー:** ノードの割り当てとリソース管理を調整し、必要に応じてワーカーをスピンアップまたはスピンダウンします。
ワーカー層:*** スケーラブルなステートレスノード上でクエリ、データ取り込み、インデックス構築のコアタスクを実行します。
ストレージ層:*** ノードのフォールトトレランスと永続性のためにベクターデータとシステムメタデータを保持する。
Milvus分散アーキテクチャにおけるスケーラビリティと一貫性
Milvusは、分散コンピューティングの原則を適用し、データの一貫性を維持しながら膨大なベクトルデータセットを処理します。以下は、水平方向に拡張し、ボトルネックを最小化し、一貫性レベルを調整できる主な設計上の特徴です:
水平スケーリング](https://zilliz.com/ai-faq/what-is-horizontal-scaling-in-distributed-databases):** Milvusは大規模なデータセットを管理可能な塊に分割します。各セグメントは独立してインデックスが作成されるため、データが増大しても既存のインフラを見直すことなくノードを追加することができます。
クエリ、データ、インデックスの独立ノード:** 特定の機能を拡張するために、クエリ、データ取り込み、インデックス作成は、それぞれ独立したノードタイプで実行されます。この分離により、ボトルネックを回避し、システムが何十億ものベクトルを処理できることを保証します。
調整可能な一貫性と** シャーディング: データは複数のノードにシャーディングされ、同時書き込みが可能です。Milvusの調整可能な一貫性レベルにより、アプリケーションのニーズに応じてパフォーマンスと精度のバランスを取ることができます。
Milvusにおけるデータのシャーディング](https://assets.zilliz.com/Data_Sharding_in_Milvus_397b4e6307.png)
図: Milvusにおけるデータシャーディング
様々なニーズに対応する複数のデプロイメント・モード
Milvusは様々なデータスケールやパフォーマンス要件に対応するため、複数のデプロイオプションを提供しています。1台のマシンでテストする場合でも、大規模なプロダクションシステムを実行する場合でも、これらのモードにより、リソースと複雑さをプロジェクトのニーズに合わせることができます。以下は、各ベクターデータベースのデータスケーリングレベルの説明図です。Milvusは数千万以上のデータスケールに対応できるように設計されています。
Milvusの展開モード](https://assets.zilliz.com/Milvus_Deployment_Modes_63d691a4d6.png)
図: Milvusの展開モード
Milvus Lite: 独立したサーバプロセスを必要とせずにMilvusのコア機能を提供する軽量なPythonライブラリです。小規模な実験、迅速なプロトタイピング、ローカル環境での迅速なデモに最適です。Milvus Liteを使えば、概念実証の構築やノートブックでの新機能のテストなど、最小限のセットアップで素早く始めることができます。
Milvus Distributed:** エンタープライズスケールの需要向けに設計された完全なマルチノードアーキテクチャです。タスクをアクセスノード、コーディネータ、ワーカー、ストレージレイヤーに分離することで、数十億(あるいは数百億)のベクトルを高可用性と耐障害性で処理します。このモデルは、データの急速な増大が予想され、並行クエリに対する堅牢なパフォーマンスが要求され、ワークロードに応じてノードの追加や削除を柔軟に行いたい組織に最適です。
Milvusスタンドアロン:** Milvusの全コンポーネントを1つの環境にバンドルしたシングルノードのデプロイメントで、多くの場合Dockerイメージで配布されます。これにより、インストールとメンテナンスが容易になると同時に、中程度のデータ量に十分な容量を提供します。大規模なスケーラビリティや複雑なフェイルオーバーメカニズムを必要としないプロダクションワークロードの実行を検討しているチームは、このオプションがコスト効率と信頼性の両方に優れていることを実感できるでしょう。
Milvusの導入の詳細については、ガイドをお読みください:AIアプリケーションに適したMilvusデプロイメントモードの選択方法をご覧ください。
結論
分散コンピューティングは、組織がデータを処理し、アプリケーションを拡張する方法を再形成し、モノリシックなサーバーから、相互接続されたノードの柔軟で耐障害性の高いクラスタへと移行している。タスクとデータを複数のマシンに分割することで、チームはより高速な処理、より高い可用性、より効率的なリソース利用を実現している。Zillizのような最新のソリューションは、これらの原則を適用し、何十億ものベクトルを並列処理できるクラウドネイティブなベクトルデータベースを提供します。データ量が増え続け、ユースケースが複雑化する中、アナリティクス、機械学習、リアルタイムのレコメンデーションなど、分散型アプローチの採用は、データ主導の今日の世界で競争力を維持するための重要な戦略であり続けている。
分散コンピューティングに関するFAQ
単一の強力なサーバーではなく、分散システムを選択する理由は何ですか?分散システムでは、単一のサーバーをアップグレードする代わりに、ワークロードの増加に応じてマシンを追加できます。この柔軟性がパフォーマンスを高め、コストを削減し、単一障害点による影響を軽減します。
分散システムでは、プロトコルやアルゴリズム(コンセンサスメカニズムなど)を使用して、複数のノード間でデータの同期を保ちます。正確なアプローチはシステムによって異なりますが、目標は更新が衝突せず、各ノードが正しいデータビューを持つようにすることです。
分散インフラのメンテナンスは難しいですか?分散システムでは、ネットワーク通信、ノードの調整、レプリケーションなど、より多くの可動部分が発生しますが、適切なツールとベストプラクティスによって複雑さを緩和することができます。Kubernetesや監視プラットフォームのようなツールは、オーケストレーションと観測可能性を簡素化する。
Milvusは大規模な類似検索用に設計された、クラウドネイティブな分散ベクトルデータベースです。データをセグメントに分割し、並列インデックスを活用することで、Milvusはスピードや信頼性を犠牲にすることなく、複数のノードで数十億のベクトルを扱うことができます。
データの収集が必要になった場合や、トラフィックが突然急増した場合はどうすればよいですか?追加ノードやリソースを迅速にスピンアップできるため、マシンの過負荷を防ぎ、使用量がピークに達する時間帯でも一貫したパフォーマンスを維持できます。
関連リソース
あなたのGenAIアプリのためのトップパフォーマンスAIモデル|Zilliz](https://zilliz.com/ai-models)
Change Data Capture: Keep Your Systems Synchronized in Real-Time](https://zilliz.com/glossary/change-data-capture-(cdc))
クラウドからエッジへの非構造化データ処理](https://zilliz.com/blog/unstructured-data-processing-from-cloud-to-edge)
オープンソースのベクトルデータベース比較](https://zilliz.com/comparison)
データ通信の最適化:MilvusがNATSメッセージングを採用](https://zilliz.com/blog/optimizing-data-communication-milvus-embraces-nats-messaging)
Zillizクラウドにおける包括的なモニタリングと観測可能性の導入](https://zilliz.com/blog/introducing-monitoring-and-observability-in-zilliz-cloud)