




次元削減:複雑なデータを簡素化して分析を容易にする
TL;DR:次元削減とは、データ・サイエンスや機械学習で使用されるプロセスで、データセット内の変数、つまり「次元」の数を減らし、関連する情報をできるだけ保持することである。この次元削減は、特に高次元のデータセットにおいて、データ分析、視覚化、処理を単純化する。主成分分析(PCA)やt-Distributed Stochastic Neighbor Embedding(t-SNE)のような技術は、データ内のパターンや関係を特定し、より少ない次元に投影する。次元削減は、あまり重要でない特徴を捨てることで、計算効率を向上させ、オーバーフィッティングを軽減するのに役立ち、特に画像解析やテキスト解析のような分野で、複雑なデータを管理するのに不可欠です。
<br
次元削減:複雑なデータを簡素化して分析を容易にする
次元削減は、重要な情報を保持したまま、入力変数や特徴の数を減らすことによってデータセットを単純化する。データサイエンスや機械学習において重要な役割を果たす。大規模なデータセットをより管理しやすくし、モデルのパフォーマンスを向上させ、貴重な計算リソースを節約します。
多くの列のデータで埋め尽くされた、大きくて複雑なスプレッドシートを想像してみてほしい。それらの列の一部が分析に役立たなかったり、明確にする必要がある場合、次元削減はパターン認識を容易にするためにそれらを切り捨てる。
次元の呪い
次元の呪い](https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning)とは、高次元空間のデータを分析・整理する際に生じる問題を指す。特徴(または次元)の数が増えるにつれて、空間の体積は急速に拡大し、利用可能なデータは疎になる。このスパース性は、アルゴリズムが意味のあるパターンを見つけることを困難にし、データ分析を非効率で信頼性の低いものにしてしまう。
この影響を理解するために、直線のような一次元空間の点間の距離を測定しようとしていると想像してほしい。点は十分に近いので簡単に測定できる。これを平らな紙のように2次元に拡大すると、点はさらに広がる。部屋のように3次元に拡大すると、点はさらに広がる。次元が増え続けるにつれ、点は離れすぎてほとんど孤立しているように見え、距離の計算はあまり役に立たなくなる。これは高次元のデータで起こり、図のようにデータ点間の関係が希薄になるため、一般的なデータ分析手法が有効に機能しなくなる可能性がある。
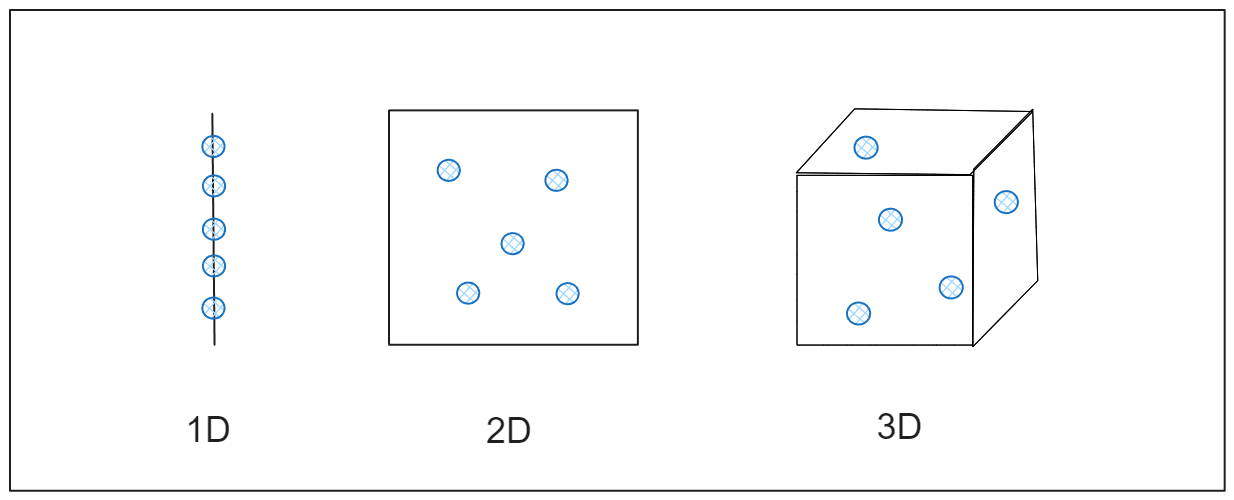 図-データはどのように次元を越えて拡大するか.png
図-データはどのように次元を越えて拡大するか.png
図:データはどのように次元を越えて拡張されるか
簡単な例えは、公園で友達を見つけることです。あなたやあなたの友人が小さな公園に散らばっていれば、お互いをすぐに見つけることができます。しかし、その公園が巨大な都市の規模にまで拡大したとしよう。同じ数の友だちがいても、みんなが離れすぎているため、友だちを見つけるのが難しくなる。同様に、高次元空間ではデータポイントが散在し、アルゴリズムがそれらを効率的に整理・分析することが難しくなる。
主要な次元削減テクニック
次元削減には様々な戦略がありますが、大きく2つのタイプに分類することができます:特徴選択と特徴抽出である。どちらの手法もデータを単純化することを目的としているが、その方法は異なる。
特徴選択
特徴選択は、元のデータセットから最も関連性の高い特徴のサブセットを選択すること で、次元を削減する。このアプローチでは、データを変換する代わりに、特徴をそのまま残し、分析やモデルの性能に大きく寄与しない特徴を削除する。目的は、冗長な特徴や無関係な特徴を取り除き、データセットをよりシンプルで扱いやすくすることである。
特徴選択には3つの一般的な方法がある:
フィルター法:フィルター法:統計的検定を使って、重要度に基づいて特徴をランク付けする。例えば、相関スコア、情報利得、カイ二乗検定などである。これらは簡単で、機械学習モデルとは独立して動作する。
ラッパー法**:これらは特徴の異なるサブセットを評価し、最適な組み合わせを決定するためにモデルのパフォーマンスを使用する。より正確ではあるが、計算コストがかかる。再帰的特徴除去(RFE)、前方選択、後方除去などのテクニックがこのカテゴリーに入る。
組み込み手法**:これらの手法は、モデルの学習プロセスに特徴選択を統合します。決定木、ラッソ回帰、リッジ回帰のようなモデルは、学習の一部として重要な特徴を自動的に識別します。
特徴抽出
特徴抽出は、元の特徴を低次元空間に変換し、重要な情報を捕捉したまま新しい特徴を作成します。このアプローチは、特徴間の意味のある関係を保持したままデータを圧縮する場合に便利です。特徴選択とは異なり、特徴抽出はデータのまったく新しい表現を作成します。
最も広く採用されている手法は、主成分分析(PCA)、t-分布確率的隣接埋め込み(t-SNE)、線形判別分析(LDA)です。これらについて詳しく説明しよう。
主成分分析(PCA)
主成分分析(PCA)は、次元削減によく使われる手法である。その主な目的は、大きな変数の集合を、元のデータの情報の大部分をまだ捕捉しているより小さな集合に単純化することである。
PCAを簡単に理解するには、データセットを多次元オブジェクト、つまり空間上の点の雲のようなものと考える。PCAは、データが最も変化する方向(または軸)を見つけ、これらの新しい軸にデータを投影する。主成分と呼ばれる最初の軸は、データの最も大きな分散(または広がり)を捉えます。2番目の軸は次に大きな分散をとらえ、以下同様である。最初の数成分だけに焦点を当てることで、PCAはデータの主要構造をそのままに次元数を減らす。
以下の図は、PCAがデータを単純化するためにどのように機能するかを示しています。左側は、2方向に広がった点の散布図である。PCAは、データが最も変化する主な方向を見つけ、黒い矢印で示します。右側は、この方向に沿ってデータが平坦化されていることを示している。
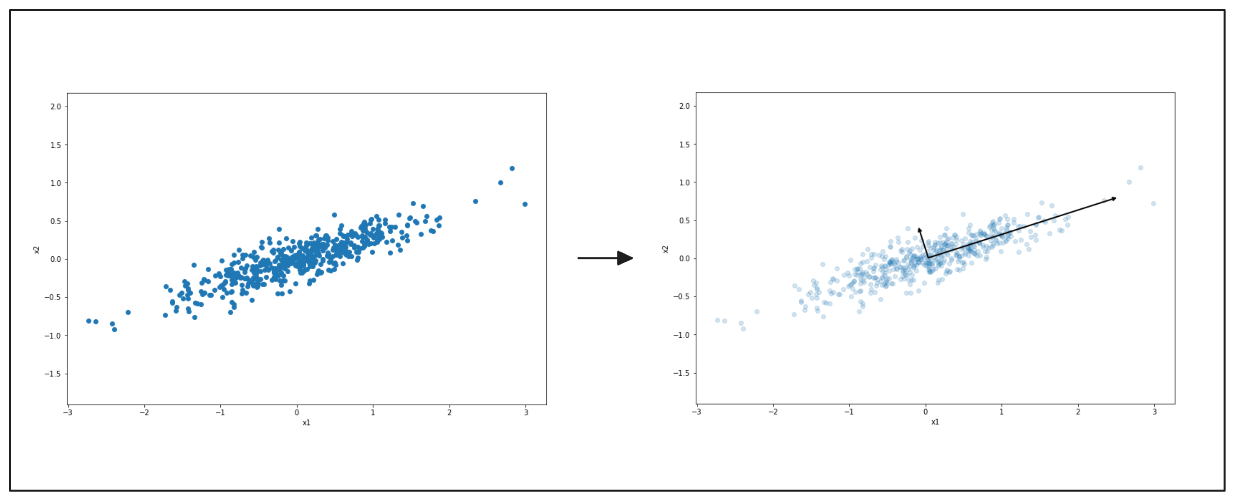 図- PCAがデータの変動の主な方向を強調する.png
図- PCAがデータの変動の主な方向を強調する.png
図:* PCAによるデータ変動の主な方向の強調。
ここでも左側で、データが2次元に広がっているのがわかる。黒い矢印は変動の主な方向を指している。右側では、データはこの線上に圧縮され、より単純な形に縮小される。この処理によってデータは扱いやすくなるが、主要なパターンは維持される。
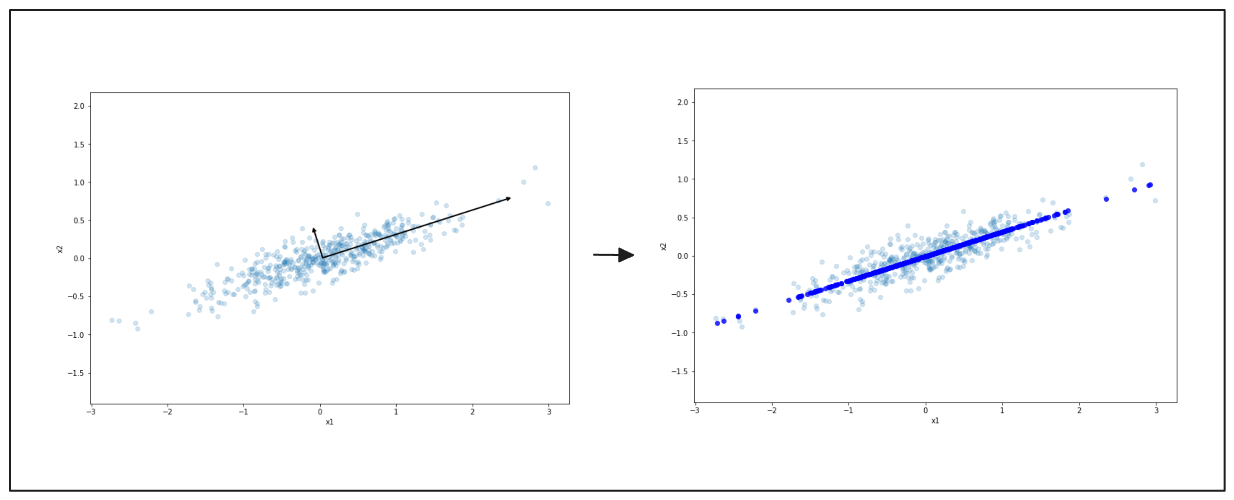 図- PCAによる単純化されたデータ表現.png
図- PCAによる単純化されたデータ表現.png
図: PCAによる簡略化されたデータ表現
**PCAを使う利点
複雑さの軽減:多くの変数を含むデータセットを単純化することで、分析がより迅速かつ効率的になる。
ノイズの除去PCAは、最も分散が大きい成分を保持することで、ノイズや無関係な情報をフィルタリングします。
可視化の向上**:PCAは、2次元または3次元の高次元データの可視化に役立ち、他の方法では隠れてしまうパターンを明らかにします。
**PCAを使うことの短所
情報の損失次元削減中にデータが失われ、モデルの性能に影響を与える可能性がある。
解釈しにくい**:PCAによって作成される新しい特徴は、元の特徴の組み合わせであるため、意味のある解釈が難しくなります。
直線性が前提**:PCAは、変数間の関係が線形である場合に最もよく働きますが、必ずしもそうとは限りません。
**実用的なアプリケーション
画像圧縮**:主要な視覚的特徴を保持しながら、画像ファイルサイズを縮小します。
金融**:複雑なデータセットを簡素化し、株価の動きのパターンを特定します。
遺伝学大規模なゲノムデータセットを分析し、意味のあるデータ構造を明らかにする。
汎用性様々な分野の高次元データの簡素化と解釈に有用。
t-分散確率的近傍埋め込み(t-SNE)
t-Distributed Stochastic Neighbor Embedding (t-SNE) は,高次元データを可視化します.t-SNEは、データ点間の局所的な関係を維持する能力が広く評価されており、データセットの根本的な構造を明らかにするのに役立っている。この手法は3次元空間のデータセットにより適している。
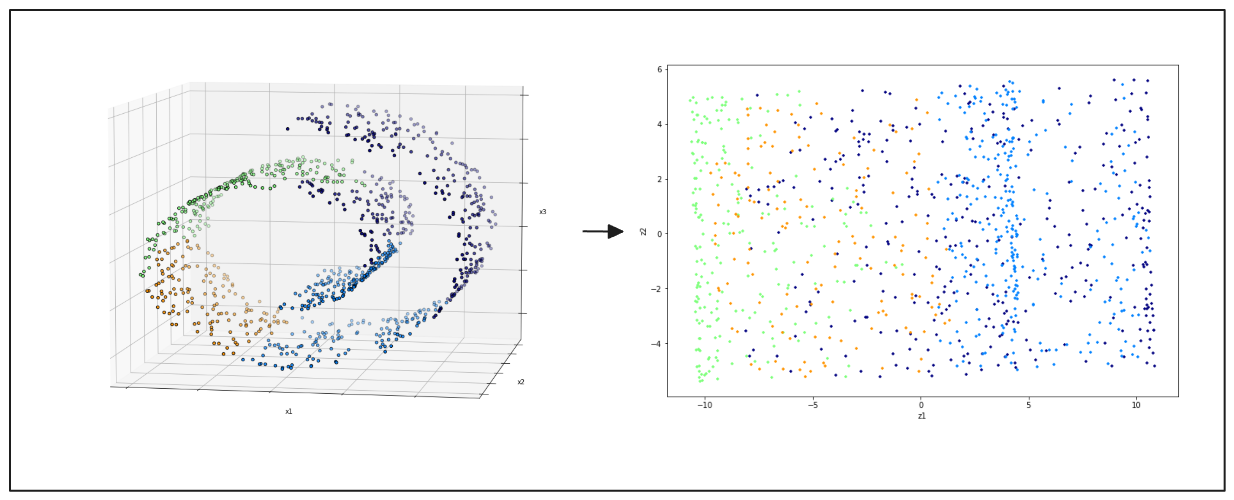 図- 左- スイスロール3Dデータ点、右- PCAによる2D投影結果.png
図- 左- スイスロール3Dデータ点、右- PCAによる2D投影結果.png
**図:左:スイスロール3Dデータ点、右:PCAによる2D投影結果
t-SNEを使用する利点
局所構造の保持**: t-SNEは、低次元空間において近傍のデータ点を近接させることに優れており、クラスターを視覚化するのに有効である。
複雑なデータに有効**:非線形関係を扱い、データの複雑なパターンを探索することに特に優れています。
可視化に最適**: t-SNEは、データのレイアウトを理解するのに役立つ、視覚的に直感的で魅力的な散布図を作成します。
**t-SNEを使用することの短所
計算集約的**:t-SNEの実行は、特に大規模なデータセットの場合、時間がかかり、リソースを大量に消費します。
パラメータの調整が必要**:複雑度や学習率などのパラメータを注意深く設定する必要があり、これらの設定によって結果が大きく変わる可能性がある。
グローバルな構造を歪める**:t-SNEは局所的な関係はよく保存するが、データの大域的な構造を歪め、大規模な関係を理解するのに有用でなくなる可能性がある。
**実用的なアプリケーション
高次元データの可視化:クラスター構造の探索に有用。
画像認識**:画像特徴の分布を可視化
自然言語処理** (NLP)](https://zilliz.com/learn/A-Beginner-Guide-to-Natural-Language-Processing):単語の埋め込みを調べます。
ゲノミクス**:意味のある遺伝子データクラスターを特定する。
人気**:制約があるにもかかわらず、視覚的な洞察のためにデータ科学者に広く使用されている。
線形判別分析 (LDA)
PCAとは異なり、LDAはデータ内の異なるクラス間の分離を最大化することを目的とする。これは、ラベルに基づいてカテゴリーを最適に分離する低次元空間にデータを投影することによって行われる。
LDAは、データの分類が主な目標であるシナリオで一般的に使用される。特に、明確なクラス境界を持つデータセットを扱う場合に有用である。実用的なアプリケーションとしては、顔認識、医療診断、テキスト分類などがある。
LDAはPCAとどう違うのか?
目的LDAはクラス分離可能性を最大化することに重点を置くが、PCAはクラスラベルを考慮せずにデータの分散を最大化することを目的とする。
教師あり vs. 教師なし**:LDAは教師あり手法で、計算にクラス・ラベルを使用する。一方、PCAは教師なし手法であり、ラベル情報を使用しない。
データ分散**:LDAは、各クラス内の広がりを最小にしながら、異なるクラスの平均間の距離を最大にする軸を見つけることによって次元を削減する。PCAはクラス情報を考慮せず、その唯一の目的はデータの冗長性を減らすことである。
その他のテクニックと新しい手法
PCA、t-SNE、LDAのような伝統的な次元削減手法に加え、いくつかの他の手法や新たなトレンドがデータ分析で人気を集めています。
オートエンコーダ
オートエンコーダは、教師なし学習に使われるニューラルネットワークで、データを低次元表現に圧縮し、それを元の形に再構成することを目的としている。このネットワークは、次元を削減するエンコーダーと、圧縮された表現から入力を再構成するデコーダーで構成される。オートエンコーダは、データの非線形な関係を扱うのに有効で、複雑な特徴表現を学習することができる。
独立成分分析 (ICA)
独立成分分析(ICA)は、多変量信号を加法的な独立成分に分離するための計算技法です。分散に注目するPCAとは異なり、ICAは統計的に独立したソースを探します。この方法は、混合録音から異なるオーディオソースを分離するような、ブラインドソース分離のようなアプリケーションでよく使用されます。
一様多様体近似と投影 (UMAP)
Uniform Manifold Approximation and Projection (UMAP)は、比較的新しい次元削減手法で、データの局所構造と大域構造の両方を保持する。これは多様体学習に基づいており、次元削減の過程でデータ点間の関係を維持することを目的としている。UMAPはt-SNEに比べて高速であり、多くの場合、より優れた可視化が得られる。
次元削減の利点
次元削減は、複雑なデータセットの分析を強化するいくつかの重要な利点を提供する:
単純化されたモデル:単純化されたモデル: 特徴量が少ないほど、学習と分析が容易な、より単純なモデルになります。
ストレージと計算要件の削減**:低次元のデータを扱うことで、ストレージの容量が減り、処理時間が短縮されるため、特に大規模なデータセットでは運用コストを削減できます。
モデル性能の向上**:最も重要な特徴を考慮することで、無関係なデータの影響を受けにくくなり、モデルの精度と堅牢性が向上します。
解釈可能性の向上**:次元を削減することで、データの本質的な関係を強調することができ、利害関係者がモデルの決定とその根底にあるパターンを理解するのに役立ちます。
データの可視化を促進します:高次元のデータを2次元または3次元に変換することで、より明確な視覚的表現が可能になり、高次元では明らかにならない洞察を発見するのに役立ちます。
ノイズの低減**:重要度の低い次元を削除することで、次元削減はノイズの量を減らし、より信頼性の高い分析に貢献するクリーンなデータセットをもたらします。
フィーチャーエンジニアリングの向上**をサポートします:このプロセスは、最も影響力のある特徴を特定するのに役立ち、より良いモデル性能につながる強化された特徴を作成する機会を提供します。
より迅速なプロトタイピング**を可能にします:考慮すべき次元が少ないため、データサイエンティストは、モデルの迅速なテストと改良のために、モデル開発を迅速に繰り返すことができます。
次元削減の課題
次元削減技術には、慎重な検討が必要ないくつかの課題がある:
重要な情報を失うリスク:重要な情報を失うリスク: 次元削減は、不注意に重要な特徴を捨ててしまう可能性があり、モデルの性能に悪影響を及ぼし、結果の誤った解釈につながる可能性がある。
正しい手法の選択**:次元削減手法の有効性は、データセットの性質や特定の分析目標によって異なります。この多様性により、効果のない結果を避けるためには、各手法の長所と限界を理解することが極めて重要になります。
計算コスト計算コスト**:t-SNEのような手法はリソースを大量に消費し、大規模なデータセットでは実行可能性が低くなる可能性がある。時間とメモリが必要なため、時間制約のあるシナリオでは適用が大幅に制限される。
削減と精度のバランス**:モデルが正確な予測のために十分な情報を保持しながら、適切なレベルの次元削減を達成することは、常に課題となります。過剰な削減はデータを単純化しすぎ、必要な複雑性を捉えるモデルの能力に影響を与えます。
様々な業界における次元削減の応用例
次元削減技術は様々な分野で応用され、データ分析を強化し、モデルのパフォーマンスを向上させます。ここでは、これらの手法が一般的に使用される実用的なシナリオをいくつか紹介します:
画像処理**:コンピュータビジョンのような分野では、次元削減は重要な特徴を保持しながら画像データを圧縮するのに役立ちます。例えば、顔認識では、PCAにより何千ものピクセル値をより小さな特徴に削減し、重要な詳細を失うことなく処理を高速化することができます。同様に、医療用画像処理では、次元削減によってMRIスキャンで重要な領域が強調され、より迅速な分析が可能になります。
自然言語処理次元削減は、単語の埋め込みなど、高次元のテキストデータを単純化するために使用されます。t-SNEのような方法は、単語の関係やクラスターを視覚化し、感情分析やトピックモデリングを支援します。
ゲノミクスバイオインフォマティクスにおいて、次元削減技術は、変数(遺伝子)の数が非常に多くなる遺伝子データの分析に不可欠である。次元削減は、病気に関連する主要な遺伝子マーカーを特定するのに役立つ。
金融次元削減は、金融指標の大規模なデータセットを単純化することにより、リスク管理やポートフォリオの最適化を支援する。アナリストは市場行動に影響を与える最も関連性の高い特徴を選択することができる。
レコメンデーションシステム**](https://zilliz.com/learn/Introduction-to-Recommendation-systems):協調フィルタリングやコンテンツベースフィルタリングにおいて、次元削減は、ユーザーの嗜好やアイテムの特性における根本的なパターンを特定することで、より効率的な推薦アルゴリズムを作成するのに役立つ。
ヘルスケア**:患者データの分析には、しばしば高次元のデータセットが含まれる。次元削減は、患者の転帰に影響する重要な因子を特定し、病気の進行予測モデリングを改善するのに役立つ。
マーケティング分析マーケティングでは、顧客の行動を理解することが重要です。次元削減により、企業は顧客データの複雑さを軽減することで容易に顧客をセグメント化し、ターゲットを絞ったマーケティング戦略につなげることができます。
製造と品質管理**:産業アプリケーションでは、次元削減は、パターンや異常を識別するために機械センサーデータを分析するのに役立ち、より良い品質管理と予知保全につながります。
次元削減はベクターデータベースのパフォーマンスをどのように向上させるか?
次元削減は、大規模な非構造化データとその高次元ベクトル表現を管理するために設計されたMilvus(Zillizのエンジニアによって作成された)のようなベクトルデータベースのパフォーマンスを大幅に向上させます。これらの相互関係は以下の通りである:
効率的なデータストレージ**: Milvusは、機械学習モデルによって生成された高次元ベクトルデータを保存することができる。PCAやt-SNEなどの次元削減技術を適用することで、これらのベクトルを圧縮し、必要なストレージ容量を削減し、検索速度を向上させることができます。
クエリー性能の向上**:ベクトル・データベースでは、高次元データの検索に計算量がかかることがあります。次元削減はベクトルの次元を最小化し、類似検索や最近傍検索を高速化します。
データの可視化の強化**:データ分析にZillizやMilvusを利用する場合、次元削減技術により複雑なデータセットの可視化が容易になります。これにより、ユーザーはデータベースに保存された高次元データの分布、関係、パターンをより良く理解することができる。
機械学習ワークフローの促進:機械学習パイプラインにおいて、次元削減はデータの前処理の効率化に役立ちます。入力特徴の複雑さを軽減することで、機械学習モデルのトレーニングが強化され、パフォーマンスと解釈可能性の向上につながります。
結論
次元削減は、データサイエンスや機械学習において、重要な情報を保持しながら複雑なデータセットを単純化する重要なテクニックである。特徴数を減らすことで、モデルの性能が向上し、可視化が容易になり、様々な分野でのデータ分析が容易になる。重要な情報が失われるリスクや慎重な手法選択の必要性など、その課題にもかかわらず、次元削減の利点は、洞察の発見や分析プロセスの効率化にとって非常に貴重である。
##次元削減に関するFAQ
- 次元削減とは何ですか?
次元削減とは、データセットの特徴や次元の数を減らし、関連する情報を可能な限り保存するために使われる手法です。この単純化により、複雑なデータの分析、視覚化、モデリングが容易になります。
- なぜデータサイエンスにおいて次元削減が重要なのか?
次元削減は、モデルのパフォーマンスを向上させ、ストレージと計算機要件を削減し、データの可視化を強化し、モデルの解釈を単純化するのに役立ち、様々なアプリケーションにおける効率的なデータ分析に不可欠です。
- 次元削減の一般的なテクニックは何ですか?
一般的な手法には、主成分分析(PCA)、t-distributed Stochastic Neighbor Embedding (t-SNE)、線形判別分析(LDA)、特徴選択法、オートエンコーダやUMAPのような新しい手法があります。
- 次元削減にはどのような課題がありますか?
課題には、重要な情報が失われるリスク、特定のデータセットに適した手法を選択する難しさ、特定の手法の計算コスト、次元削減とモデルの精度のバランスなどがあります。
- 次元削減はMilvusのようなベクトルデータベースにどのような利益をもたらすのか?
次元削減は、データストレージの最適化、クエリパフォーマンスの向上、データの可視化の促進、機械学習ワークフローの合理化により、ベクトルデータベースのパフォーマンスを向上させます。
関連リソース
ベクトルデータベースにおける高度なクエリ技術](https://zilliz.com/learn/advanced-querying-techniques-in-vector-databases)
データの効率化:次元を減らす効果的な戦略](https://zilliz.com/learn/streamlining-data-strategies-for-reducing-dimensionality)
機械学習における次元の呪縛](https://zilliz.com/glossary/curse-of-dimensionality-in-machine-learning)
バッチとレイヤーの正規化 - ニューラルネットワークの効率を引き出す](https://zilliz.com/learn/layer-vs-batch-normalization-unlocking-efficiency-in-neural-networks)
Milvusとは](https://zilliz.com/what-is-milvus)